Amazon Redshift là dịch vụ lưu trữ dữ liệu trên đám mây nhanh, dễ sử dụng, an toàn và kinh tế được thiết kế cho việc phân tích dữ liệu. AWS đã công bố Amazon Redshift Serverless chính thức sẵn sàng sử dụng vào tháng 7 năm 2022, cung cấp trải nghiệm dễ dàng hơn để vận hành Amazon Redshift. Amazon Redshift Serverless giúp bạn dễ dàng chạy và mở rộng phân tích mà không cần quản lý cơ sở hạ tầng kho dữ liệu của bạn. Amazon Redshift Serverless tự động cung cấp và tự động điều chỉnh khả năng lưu trữ cơ sở dữ liệu thông minh để cung cấp hiệu suất nhanh cho các tải công việc đòi hỏi kết quả cao nhất và không thể dự đoán, và bạn chỉ trả tiền cho những gì bạn sử dụng.
Amazon Redshift Serverless đo lường khả năng lưu trữ kho dữ liệu theo đơn vị xử lý Redshift (RPUs). Bạn trả tiền cho các công việc bạn chạy theo RPU-hours trên cơ sở theo giây (với mức phí tối thiểu là 60 giây), bao gồm các truy vấn truy cập dữ liệu bên ngoài trong định dạng tệp mở như CSV và Parquet được lưu trữ trong Amazon S3. Để biết thêm thông tin về giá RPUs, xem Amazon Redshift pricing..
AWS Data Exchange giúp bạn dễ dàng tìm, đăng ký và sử dụng dữ liệu bên thứ ba trên đám mây. Với AWS Data Exchange cho Amazon Redshift, khách hàng có thể bắt đầu truy vấn, đánh giá, phân tích và kết hợp dữ liệu bên thứ ba với dữ liệu bên đầu tiên của mình mà không cần yêu cầu bất kỳ trích xuất, chuyển đổi và tải (ETL) nào. Nhà cung cấp dữ liệu có thể liệt kê và cung cấp sản phẩm chứa các bộ dữ liệu Amazon Redshift trong danh mục AWS Data Exchange, cấp cho người đăng ký truy cập trực tiếp chỉ để đọc vào các dữ liệu được lưu trữ trong Amazon Redshift. Tính năng này giúp khách hàng nhanh chóng truy vấn, phân tích và xây dựng ứng dụng với các bộ dữ liệu bên thứ ba này.
TPC-DS là một bài kiểm tra thường được sử dụng để đo hiệu suất truy vấn của các giải pháp kho dữ liệu như Amazon Redshift. Bài kiểm tra này hữu ích trong việc chứng minh khả năng truy vấn của việc thực hiện các truy vấn đơn giản đến phức tạp trong thời gian hợp lý. Nó cũng được sử dụng để đo hiệu suất của các cấu hình cơ sở dữ liệu khác nhau, các tải công việc đồng thời khác nhau và cũng so sánh với các sản phẩm cơ sở dữ liệu khác.
Bài đăng trên blog này sẽ hướng dẫn bạn các bước cần thiết để thiết lập Amazon Redshift Serverless và chạy các truy vấn SQL được lấy từ bài kiểm tra TPC-DS với dữ liệu từ AWS Data Exchange.
Tổng quan về giải pháp
Chúng ta sẽ bắt đầu bằng cách tạo một workgroup và namespace Amazon Redshift Serverless. Namespace là một bộ sưu tập các đối tượng cơ sở dữ liệu và người dùng trong khi workgroup là một bộ sưu tập các tài nguyên tính toán. Để đơn giản hóa việc thực thi các truy vấn kiểm tra, một EC2 instance Linux cũng sẽ được triển khai.
Tiếp theo, chúng ta sẽ sử dụng một repo GitHub chứa các truy vấn được dẫn xuất từ TPC-DS. TPC-DS benchmark thường được sử dụng để đánh giá hiệu suất và chức năng của các kho dữ liệu đám mây. Benchmark TPC-DS bao gồm các bước và yêu cầu bổ sung để được coi là chính thức, nhưng đối với bài đăng blog này, chúng tôi tập trung chỉ vào việc thực thi các truy vấn SQL SELECT từ benchmark này.
Thành phần cuối cùng của giải pháp là dữ liệu. Benchmark TPC-DS bao gồm các tệp nhị phân để tạo dữ liệu, nhưng việc này tốn thời gian để chạy. Chúng tôi đã tránh vấn đề này bằng cách tạo dữ liệu, và chúng tôi đã đưa nó miễn phí lên AWS Data Exchange.
Tự động thiết lập: CloudFormation

Nhấp vào liên kết Launch Stack ở trên để khởi chạy CloudFormation stack, nó sẽ tự động triển khai các tài nguyên cần thiết cho bản demo. Mẫu này triển khai các tài nguyên sau trong VPC mặc định của bạn:
- Một instance Amazon Compute Cloud (Amazon EC2) với phiên bản mới nhất của Amazon Linux
- Một workgroup và namespace Amazon Redshift Serverless
- Một vai trò IAM được cấp quyền hành động redshift-serverless:GetWorkgroup ; nó được gán vào instance EC2 để một lệnh giao diện dòng lệnh (CLI) có thể chạy để hoàn tất cấu hình instance
- Một nhóm bảo mật với cổng nhập (inbound port) 22 (ssh) và kết nối giữa instance EC2 và workgroup Amazon Redshift Serverless
- Kho lưu trữ GitHub được tải xuống trong instance EC2
Thông số mẫu
- Stack: thuật ngữ CloudFormation được sử dụng để xác định tất cả các tài nguyên được tạo bởi mẫu.
- KeyName: Đây là tên của một cặp khóa hiện có. Nếu bạn chưa có một cặp khóa nào, hãy tạo một cặp khóa được sử dụng để kết nối bằng SSH đến EC2 instance. Thêm thông tin về key pairs.
- SSHLocation: Đây là CIDR mask cho các kết nối đến EC2 instance. Giá trị mặc định là 0.0.0.0/0, có nghĩa là bất kỳ địa chỉ IP nào đều được phép kết nối bằng SSH đến EC2 instance, miễn là máy khách có khóa riêng tư của cặp khóa. Thực tiễn tốt nhất để đảm bảo an toàn là giới hạn phạm vi này cho một loạt các địa chỉ IP nhỏ hơn. Ví dụ, bạn có thể sử dụng các trang web như www.whatismyip.com để lấy địa chỉ IP của mình.
- RedshiftCapacity: Đây là số RPUs cho workgroup Amazon Redshift Serverless. Giá trị mặc định là 128 và được khuyến nghị cho việc phân tích các tập dữ liệu lớn TPC-DS. Bạn có thể cập nhật dung lượng RPU sau khi triển khai nếu muốn hoặc triển khai lại với giá trị dung lượng khác.
Thiết lập thủ công
Nếu bạn không muốn sử dụng mẫu CloudFormation, bạn có thể triển khai EC2 instance và Amazon Redshift Serverless theo hướng dẫn sau. Các bước sau chỉ cần thiết nếu bạn triển khai tài nguyên một cách thủ công thay vì sử dụng mẫu CloudFormation được cung cấp.
Thiết lập Amazon Redshift
Dưới đây là các bước chính để tạo một nhóm làm việc Amazon Redshift Serverless. Bạn có thể tìm thêm thông tin chi tiết từ bài đăng trên News Blog.
Để tạo nhóm làm việc của bạn, hãy thực hiện các bước sau:
- Trên bảng điều khiển Amazon Redshift, điều hướng đến bảng điều khiển Amazon Redshift Serverless.
- Chọn Tạo nhóm làm việc. (Create workgroup)
- Với Tên nhóm làm việc (Workgroup name), nhập một tên.
- Chọn Tiếp theo. (Next)
- Với Namespace, nhập một tên duy nhất.
- Chọn Tiếp theo.(Next)
- Chọn Tạo. (Create)
Các bước này sẽ tạo một nhóm làm việc Amazon Redshift Serverless với 128 RPUs. Đây là giá trị mặc định, bạn có thể dễ dàng điều chỉnh nó lên hoặc xuống dựa trên khối lượng công việc và hạn chế ngân sách của bạn.
Cài đặt Linux EC2 instance
- Triển khai một máy ảo trong cùng khu vực AWS với cơ sở dữ liệu Amazon Redshift của bạn bằng cách sử dụng Amazon Linux 2 AMI.
- AMI Amazon Linux 2 (64 bit x86) với loại instance t2.micro là một cấu hình rẻ tiền và đã được thử nghiệm.
- Thêm security group được cấu hình cho cơ sở dữ liệu Amazon Redshift của bạn vào EC2 instance của bạn.
- Cài đặt psql với lệnh sudo yum install postgresql.x86_64 -y
- Tải xuống GitHub repo này.
git clone –depth 1 https://github.com/aws-samples/redshift-benchmarks /home/ec2-user/redshift-benchmarks
- Thiết lập các biến môi trường sau cho Amazon Redshift:
- PGHOST: Đây là điểm cuối cho cơ sở dữ liệu Amazon Redshift.
- PGPORT: Đây là cổng mà cơ sở dữ liệu lắng nghe. Giá trị mặc định của Amazon Redshift là 5439.
- PGUSER: Đây là tên người dùng cơ sở dữ liệu Amazon Redshift của bạn.
- PGDATABASE: Đây là tên cơ sở dữ liệu nơi các schema bên ngoài được tạo ra. Đây KHÔNG phải là cơ sở dữ liệu được tạo ra cho chia sẻ dữ liệu. Chúng tôi đề xuất sử dụng cơ sở dữ liệu “dev” mặc định.
Ví dụ:
export PGUSER=“awsuser”
export PGHOST=“default.01.us-east-1.redshift-serverless.amazonaws.com”
export PGPORT=“5439”
export PGDATABASE=“dev”
Cấu hình tập tin .pgpass để lưu trữ thông tin đăng nhập cơ sở dữ liệu của bạn. Định dạng cho tập tin .pgpasslà: hostname:port:database:user:password
Ví dụ:
default.01.us-east-1.redshift-serverless.amazonaws.com:5439:*:user1:user1P@ss
Thiết lập AWS Data Exchange
AWS Data Exchange cung cấp dữ liệu của bên thứ ba trong nhiều định dạng dữ liệu, bao gồm Amazon Redshift. Bạn có thể đăng ký đăng ký các danh mục trong nhiều vị trí lưu trữ như Amazon S3 và chia sẻ dữ liệu Amazon Redshift. Chúng tôi khuyến khích bạn khám phá danh mục AWS Data Exchange bởi vì có nhiều bộ dữ liệu có sẵn có thể được sử dụng để cải thiện dữ liệu của bạn trong Amazon Redshift.
Đầu tiên, đăng ký đăng ký danh mục AWS Marketplace cho Dữ liệu Thử nghiệm TPC-DS. Chọn nút Tiếp tục để đăng ký (Continue to subscribe) từ danh mục AWS Data Exchange. Sau khi bạn đã xem xét đề xuất và các Điều khoản và Điều kiện của sản phẩm dữ liệu, hãy chọn Đăng ký. Lưu ý rằng bạn cần các quyền IAM thích hợp để đăng ký cho AWS Data Exchange trên Marketplace. Thêm thông tin có thể được tìm thấy tại Chính sách quản lý AWS cho AWS Data Exchange.
TPC-DS sử dụng 24 bảng trong một mô hình chiều mô phỏng hệ thống hỗ trợ quyết định. Nó có bảng chứa thông tin về cửa hàng, danh mục và bán hàng trên web cũng như bảng sự thật về việc trả hàng cửa hàng, danh mục và bán hàng trên web. Nó cũng có các bảng chiều để hỗ trợ các bảng sự thật này.
TPC-DS bao gồm một tiện ích để tạo ra dữ liệu cho bài đánh giá với một yếu tố quy mô cho trước. Yếu tố quy mô nhỏ nhất là 1 GB (không nén). Hầu hết các bài kiểm tra chuẩn cho các kho lưu trữ đám mây được chạy với 3-10 TB dữ liệu vì bộ dữ liệu đủ lớn để căng thẳng hệ thống nhưng cũng nhỏ đủ để hoàn thành toàn bộ bài kiểm tra trong một khoảng thời gian hợp lý.
Có sáu lược đồ cơ sở dữ liệu được cung cấp trong đăng ký Dữ liệu đánh giá chuẩn TPC-DS với các yếu tố tỷ lệ 1; 10; 100; 1,000; 3,000; và 10,000. Yếu tố tỷ lệ tham chiếu đến kích thước dữ liệu không nén được đo bằng GB. Mỗi lược đồ đề cập đến một bộ dữ liệu với yếu tố tỷ lệ tương ứng.
| Scale factor (GB) | ADX schema | Amazon Redshift SAmazon Redshift Serverless external schemaerverless external schemaAmazon Redshift Serverless external schema (Mô hình schema bên ngoài không cần server của Amazon Redshift) |
| 1 | tpcds1 | ext_tpcds1 |
| 10 | tpcds10 | ext_tpcds10 |
| 100 | tpcds100 | ext_tpcds100 |
| 1,000 | tpcds1000 | ext_tpcds1000 |
| 3,000 | tpcds3000 | ext_tpcds3000 |
| 10,000 | tpcds10000 | ext_tpcds10000 |
Các bước sau sẽ tạo các external schema trong cơ sở dữ liệu Amazon Redshift Serverless để ánh xạ với các schema được tìm thấy trên AWS Data Exchange.
- Đăng nhập vào EC2 instance và tạo kết nối cơ sở dữ liệu.
psql
- Chạy truy vấn sau:
select share_name, producer_account, producer_namespace from svv_datashares;
- Sử dụng kết quả truy vấn này để chạy lệnh tiếp theo:
create database tpcds_db from datashare <share_name> of account ‘<producer_account>’ namespace ‘<producer_namespace>’;
- Cuối cùng, bạn tạo các external schema trong Amazon Redshift:
create external schema ext_tpcds1 from redshift database tpcds_db schema tpcds1;
create external schema ext_tpcds10 from redshift database tpcds_db schema tpcds10;
create external schema ext_tpcds100 from redshift database tpcds_db schema tpcds100;
create external schema ext_tpcds1000 from redshift database tpcds_db schema tpcds1000;
create external schema ext_tpcds3000 from redshift database tpcds_db schema tpcds3000;
create external schema ext_tpcds10000 from redshift database tpcds_db schema tpcds10000;
- Bây giờ bạn có thể thoát khỏi psql với lệnh này:
\q
Bài kiểm tra dẫn xuất từ TPC-DS
Bài kiểm tra dẫn xuất từ TPC-DS bao gồm 99 truy vấn trong bốn loại chính:
- Các truy vấn báo cáo
- Các truy vấn tùy ý
- Các truy vấn OLAP lặp lại
- Các truy vấn khai thác dữ liệu
Ngoài việc chạy 99 truy vấn, bài kiểm tra còn thử nghiệm độ tương thích. Trong phần thử nghiệm độ tương thích, có n phiên (mặc định là 5) chạy các truy vấn. Mỗi phiên chạy 99 truy vấn với các tham số khác nhau và theo thứ tự khác nhau một chút. Thử nghiệm độ tương thích này tải lực tài nguyên của cơ sở dữ liệu và thường mất nhiều thời gian hơn so với chỉ có một phiên chạy 99 truy vấn.
Một số sản phẩm lưu trữ dữ liệu phiên dịch được cấu hình để tối ưu hiệu suất của người dùng đơn, trong khi các sản phẩm khác có thể không có khả năng quản lý tải công việc hiệu quả. Đây là một cách tuyệt vời để thể hiện việc quản lý công việc và sự ổn định của Amazon Redshift.
Do dữ liệu cho mỗi tỷ lệ tỷ lệ khác nhau được lưu trữ trong các schema khác nhau, việc chạy kiểm tra với mỗi tỷ lệ yêu cầu thay đổi schema mà bạn đang tham chiếu. search_path xác định các schema cần được tìm kiếm cho các bảng khi một truy vấn chứa các đối tượng mà không có schema đi kèm. Ví dụ:
ALTER USER <username> SET search_path=ext_tpcds3000,public;
Các script của benchmark sẽ tự động thiết lập search_path
Lưu ý: Các script sẽ tạo một schema có tên là tpcds_reports, để lưu trữ kết quả chi tiết của mỗi bước trong benchmark. Mỗi lần chạy các script, schema này sẽ được tạo lại và kết quả mới nhất sẽ được lưu trữ. Nếu bạn đã có một schema có tên là tpcds_reports thì các script sẽ xóa schema này.
Chạy các truy vấn dẫn xuất từ TPC-DS
- Kết nối bằng SSH đến EC2 instance với cặp khóa của bạn.
- Thay đổi thư mục:
cd ~/redshift-benchmarks/adx-tpc-ds/
- Tuỳ chọn cấu hình các biến cho các script trong tpcds_variables.sh
Dưới đây là các giá trị mặc định cho các biến bạn có thể thiết lập:
- EXT_SCHEMA=”ext_tpcds3000″: Đây là tên của external schema được tạo ra có tập dữ liệu TPC-DS. Giá trị “3000” có nghĩa là scale factor là 3000 hoặc 3 TB (không nén).
- EXPLAIN=”false”: Nếu đặt thành false, các truy vấn sẽ được chạy. Nếu đặt thành true, các truy vấn sẽ tạo kế hoạch giải thích thay vì chạy thực sự. Mỗi truy vấn sẽ được lưu trong thư mục log. Giá trị mặc định là false.
- MULTI_USER_COUNT=”5″: 0 đến 20 người dùng đồng thời sẽ chạy các truy vấn. Thứ tự các truy vấn đã được thiết lập với dsqgen. Đặt thành 0 sẽ bỏ qua bài kiểm tra đa người dùng. Giá trị mặc định là 5.
- Chạy bài kiểm tra:
./rollout.sh > rollout.log 2>&1 &
Kết quả đo lường hiệu suất trên TPC-DS derived benchmark
Chúng tôi đã thực hiện một bài kiểm tra với bộ dữ liệu TPC-DS của ADX 3 TB trên một nhóm làm việc Amazon Redshift Serverless với 128 RPUs. Bên cạnh đó, chúng tôi đã tắt query caching để không lưu kết quả truy vấn vào bộ nhớ cache. Điều này cho phép chúng tôi đo lường hiệu suất của cơ sở dữ liệu thay vì khả năng phục vụ kết quả từ cache.
Bài kiểm tra bao gồm hai phần. Phần đầu tiên sẽ chạy 99 truy vấn tuần tự bằng một người dùng trong khi phần thứ hai sẽ bắt đầu nhiều phiên dựa trên tệp cấu hình bạn đã thiết lập trước đó. Mỗi phiên sẽ chạy đồng thời, và mỗi phiên sẽ chạy tất cả 99 truy vấn nhưng theo một thứ tự khác nhau.
Thời gian chạy tổng cộng cho các truy vấn của người dùng đơn là 15 phút 11 giây. Như được hiển thị trong biểu đồ sau đây, truy vấn chạy lâu nhất là truy vấn số 67, với thời gian đã trôi qua chỉ 101 giây. Thời gian chạy trung bình chỉ là 9,2 giây.
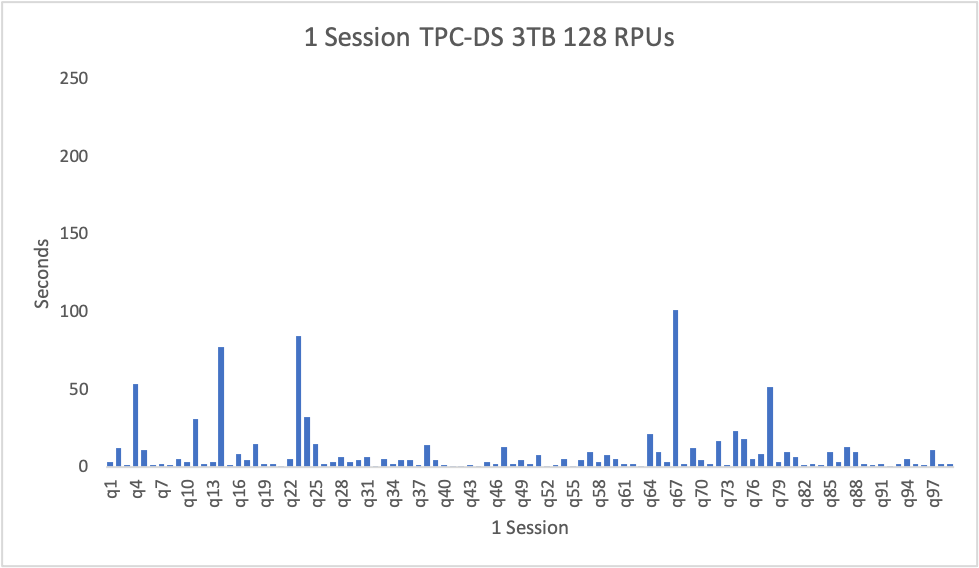
Với năm người dùng cùng chạy, thời gian chạy là 28 phút 35 giây, cho thấy Amazon Redshift Serverless hoạt động tốt cho khối lượng công việc của người dùng đơn và đồng thời.

Như bạn có thể thấy, việc triển khai Amazon Redshift Serverless, đăng ký một danh mục sản phẩm AWS Data Exchange và chạy một bài kiểm tra khá phức tạp trong một khoảng thời gian ngắn khá dễ dàng.
Các bước tiếp theo
Bạn có thể chạy lại các kịch bản kiểm tra với các kích thước tập dữ liệu khác hoặc số người dùng đồng thời khác nhau bằng cách chỉnh sửa tệp tpcds_variables.sh. Bạn cũng có thể thử thay đổi kích cỡ workgroup Amazon Redshift Serverless của mình để xem sự khác biệt hiệu suất với nhiều hoặc ít RPUs hơn. Bạn cũng có thể chạy các truy vấn riêng lẻ để xem kết quả trực tiếp.
Một điều khác để thử nghiệm là đăng ký các sản phẩm AWS Data Exchange khác và truy vấn dữ liệu này từ Amazon Redshift Serverless. Hãy tò mò và khám phá việc sử dụng Amazon Redshift Serverless và AWS Data Exchange!
Xóa bỏ
Nếu bạn triển khai các tài nguyên với giải pháp tự động, bạn chỉ cần xóa stack được tạo trong CloudFormation. Tất cả các tài nguyên được tạo bởi stack sẽ tự động bị xóa.
Nếu bạn triển khai các tài nguyên một cách thủ công, bạn cần xóa các thành phần sau:
- Cơ sở dữ liệu Amazon Redshift được tạo trước đó.
- Nếu bạn triển khai Amazon Redshift Serverless, bạn cần xóa cả workgroup và namespace.
- Instance Amazon EC2.
Tùy chọn, bạn có thể hủy đăng ký dữ liệu TPC-DS bằng cách đến Trang đăng ký AWS Data Exchange của bạn, sau đó chuyển Renewa sang Off.
Kết luận
Bài đăng blog này đã trình bày cách triển khai Amazon Redshift Serverless, đăng ký một sản phẩm AWS Data Exchange và chạy một bài kiểm tra phức tạp trong thời gian ngắn. Amazon Redshift Serverless có thể xử lý cùng lúc nhiều phiên và hoạt động vượt trội về giá và hiệu suất.
Nếu bạn có bất kỳ câu hỏi hoặc phản hồi nào, vui lòng để lại chúng trong phần bình luận.
Bài được dịch từ bài viết trên AWS Blogs, bạn có thể xem bài viết gốc tại đây.
