AWS Lake Formation giúp quản lý dữ liệu doanh nghiệp và rất quan trọng cho kiến trúc dữ liệu mạng lưới. Nó hoạt động với AWS Glue Data Catalog để thực thi quyền truy cập và quản lý dữ liệu. Cả hai dịch vụ này đều cung cấp lưu trữ dữ liệu đáng tin cậy, nhưng một số khách hàng muốn có lưu trữ, bảng tra cứu và quyền truy cập được sao chép để đảm bảo tuân thủ quy định.
Bài đăng này giải thích cách tạo một thiết kế tự động sao lưu dữ liệu Amazon Simple Storage Service (Amazon S3), AWS Glue Data Catalog và quyền Lake Formation trong các Region khác nhau và cung cấp các tùy chọn sao lưu và khôi phục để phục hồi sau thảm họa. Các cơ chế này có thể được tùy chỉnh cho các quy trình của tổ chức của bạn. Tiện ích cho việc sao chép và thử nghiệm có sẵn trên kho GitHub được chia sẻ công khai.
Giải pháp này chỉ sao chép siêu dữ liệu trong Data Catalog, chứ không phải là dữ liệu cơ bản bên dưới. Để có một hồ sơ dữ liệu dự phòng sử dụng Lake Formation và AWS Glue ở Region khác, chúng tôi khuyến khích sao chép lưu trữ dựa trên Amazon S3 bằng cách sử dụng sao chép S3, đồng bộ S3, aws-s3-copy-sync-using-batch hoặc quá trình sao chép S3 Batch. Điều này đảm bảo rằng hồ sơ dữ liệu vẫn hoạt động trong một Region khác nếu Lake Formation gặp vấn đề về khả dụng. Cài đặt Data Catalog (bảng, cơ sở dữ liệu, liên kết tài nguyên) và cài đặt Lake Formation (quyền truy cập, cài đặt) cũng phải được sao chép ở Region sao lưu.
Tổng quan về giải pháp
Bài đăng này chỉ ra cách tạo sao lưu cho phép Sao lưu quyền Lake Formation và Catalog dữ liệu AWS Glue từ một Region sang Region khác trong cùng một tài khoản. Giải pháp không tạo hoặc thay đổi vai trò quản lý truy cập IAM (AWS Identity and Access Management) có sẵn trong tất cả các Region. Có ba bước để tạo một hồ nước dữ liệu đa Region:
- Di chuyển quyền truy cập dữ liệu Lake Formation.
- Di chuyển cơ sở dữ liệu và bảng AWS Glue.
- Di chuyển dữ liệu Amazon S3.
Trong các phần tiếp theo, chúng ta sẽ xem xét chi tiết hơn về mỗi bước di chuyển.
Quyền truy cập Lake Formation
Trong Lake Formation, có hai loại quyền truy cập: quyền truy cập siêu dữ liệu và quyền truy cập dữ liệu.
Quyền truy cập siêu dữ liệu cho phép người dùng tạo, đọc, cập nhật và xóa cơ sở dữ liệu siêu dữ liệu và bảng trong Data Catalog.
Quyền truy cập dữ liệu cho phép người dùng đọc và ghi dữ liệu vào các vị trí cụ thể trên Amazon S3. Quyền truy cập dữ liệu được quản lý bằng các quyền truy cập vị trí dữ liệu, cho phép người dùng tạo và sửa đổi cơ sở dữ liệu siêu dữ liệu và bảng trỏ đến các vị trí Amazon S3 cụ thể.
Khi dữ liệu được di chuyển từ một Region sang Region khác, chỉ có các quyền truy cập siêu dữ liệu được sao chép. Điều này có nghĩa là nếu dữ liệu được chuyển từ một bucket trong Region nguồn sang một bucket khác trong Region đích, các quyền truy cập dữ liệu cần được áp dụng lại trong Region đích.
AWS Glue Data Catalog
AWS Glue Data Catalog là một kho lưu trữ trung tâm của siêu dữ liệu về dữ liệu được lưu trữ trong hồ dữ liệu của bạn. Nó chứa các tham chiếu đến dữ liệu được sử dụng như nguồn và đích trong các công việc AWS Glue ETL (giải nén, biến đổi và tải) và lưu trữ thông tin về vị trí, schema và chỉ số thời gian chạy của dữ liệu của bạn. Data Catalog tổ chức thông tin này dưới dạng các bảng siêu dữ liệu và cơ sở dữ liệu. Một bảng trong Data Catalog là một định nghĩa siêu dữ liệu đại diện cho dữ liệu trong hồ dữ liệu, và cơ sở dữ liệu được sử dụng để tổ chức các bảng siêu dữ liệu này.
Quyền của Lake Formation chỉ có thể được áp dụng cho các đối tượng đã tồn tại trong Data Catalog ở Region đích. Do đó, để áp dụng các quyền này, cơ sở dữ liệu và bảng AWS Glue cơ bản phải đã tồn tại trong Region đích. Để đáp ứng yêu cầu này, tiện ích này di chuyển cả cơ sở dữ liệu và bảng AWS Glue từ Region nguồn sang Region đích.
Amazon S3 data
Dữ liệu nằm dưới một bảng AWS Glue có thể được lưu trữ trong một bucket S3 ở bất kỳ Region nào, do đó việc sao chép dữ liệu thực tế không cần thiết. Tuy nhiên, nếu dữ liệu đã được sao chép sang Region đích, tiện ích này có tùy chọn để cập nhật vị trí của bảng để trỏ đến dữ liệu đã được sao chép ở Region đích. Nếu vị trí của dữ liệu thay đổi, tiện ích cập nhật tên bucket S3 và giữ nguyên phần còn lại của cấu trúc tiền tố.
Tiện ích này không bao gồm việc di chuyển dữ liệu từ Region nguồn sang Region đích. Việc di chuyển dữ liệu phải được thực hiện riêng bằng các phương pháp như sao chép S3, đồng bộ S3, aws-s3-copy-sync-using-batch hoặc quá trình sao chép S3 Batch.
Tiện ích này có hai chế độ để sao chép siêu dữ liệu Lake Formation và Data Catalog: chế độ yêu cầu và chế độ thời gian thực. Chế độ yêu cầu là một sao chép lô được thực hiện tại một điểm cụ thể trong thời gian và sử dụng nó để đồng bộ hóa siêu dữ liệu. Chế độ thời gian thực sao chép các thay đổi được thực hiện trên quyền Lake Formation hoặc Data Catalog gần như trong thời gian thực.
Chế độ yêu cầu của tiện ích này được đề xuất để tạo các quyền Lake Formation và Catalog Data hiện có vì nó sao chép một bản chụp của siêu dữ liệu. Sau khi Lake Formation và Catalog Data được đồng bộ hóa, bạn có thể sử dụng chế độ thời gian thực để sao chép bất kỳ thay đổi đang diễn ra. Điều này tạo ra một hình ảnh đối xứng của Region nguồn trong Region đích và giữ nó luôn cập nhật khi có thay đổi được thực hiện trong Region nguồn. Hai chế độ này có thể sử dụng độc lập với nhau, và các hoạt động đều là idempotent.
Mã cho các chế độ yêu cầu và thời gian thực có sẵn trong kho GitHub. Hãy xem từng chế độ chi tiết hơn.
Chế độ theo yêu cầu
Chế độ yêu cầu được sử dụng để sao chép các quyền Lake Formation và Catalog dữ liệu vào một điểm thời gian cụ thể. Mã được triển khai bằng AWS Cloud Development Kit (AWS CDK). Sơ đồ giải pháp cho chế độ này được hiển thị trong biểu đồ sau.
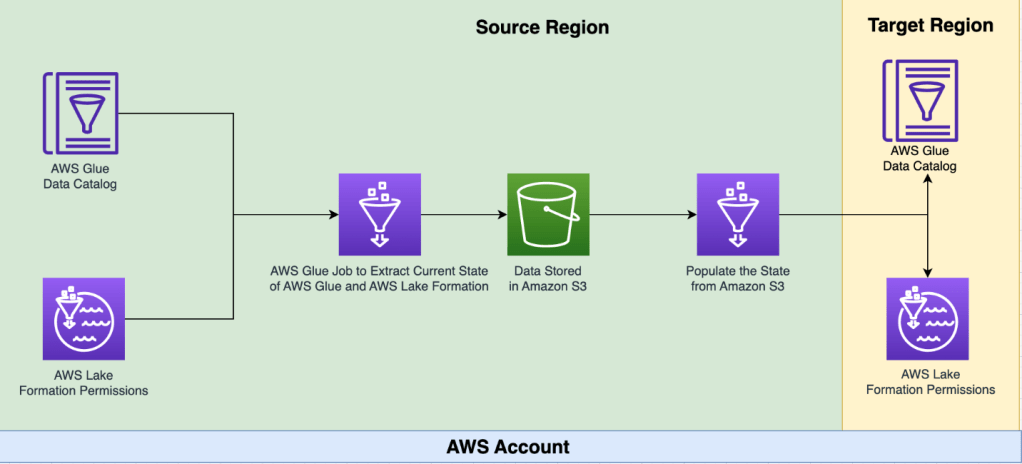
AWS CDK triển khai một công việc AWS Glue để thực hiện sao chép. Công việc lấy thông tin cấu hình từ một tệp được lưu trữ trong một bucket S3. Tệp này bao gồm chi tiết như các Region nguồn và đích, một danh sách tùy chọn các cơ sở dữ liệu để sao chép và các tùy chọn cho việc di chuyển dữ liệu đến một bucket S3 khác. Thông tin chi tiết về các tùy chọn này và hướng dẫn triển khai có sẵn trong kho GitHub
Công việc AWS Glue lấy quyền Lake Formation và đối tượng metadata Catalog dữ liệu từ Region nguồn và lưu trữ nó trong một tệp JSON trong một bucket S3. Cùng một công việc sử dụng tệp này để tạo cơ sở dữ liệu và bảng quyền Lake Formation và Catalog dữ liệu trong Region đích.
Công cụ này có thể được chạy theo yêu cầu bằng cách chạy AWS Glue job. Nó sao chép metadata Lake Formation permissions và Data Catalog từ Region nguồn đến Region đích. Nếu bạn chạy công cụ này lại sau khi thực hiện các thay đổi ở Region đích, các thay đổi sẽ được thay thế bằng phiên bản Lake Formation permissions và Data Catalog mới nhất từ Region nguồn.
Công cụ này có thể phát hiện bất kỳ thay đổi nào được thực hiện trên metadata Data Catalog, cơ sở dữ liệu, bảng và cột trong quá trình sao chép Data Catalog từ Region nguồn đến Region đích. Nếu phát hiện thay đổi ở Region nguồn, phiên bản AWS Glue mới nhất sẽ được áp dụng cho Region đích. Công cụ này báo cáo số lượng đối tượng đã được thay đổi trong quá trình chạy.
Lake Formation permissions được sao chép từ Region nguồn sang Region đích, vì vậy bất kỳ quyền mới nào cũng được sao chép sang Region đích. Nếu một quyền bị xóa khỏi Region nguồn, nó không bị xóa khỏi Region đích.
Real-time mode (Chế độ thời gian thực)
Chế độ thời gian thực sao chép các quyền Lake Formation và Data Catalog định kỳ. Khoảng thời gian mặc định là 1 phút, nhưng có thể được sửa đổi trong quá trình triển khai. Mã được triển khai bằng cách sử dụng AWS CDK. Sơ đồ kiến trúc giải pháp cho chế độ này được thể hiện bên dưới.
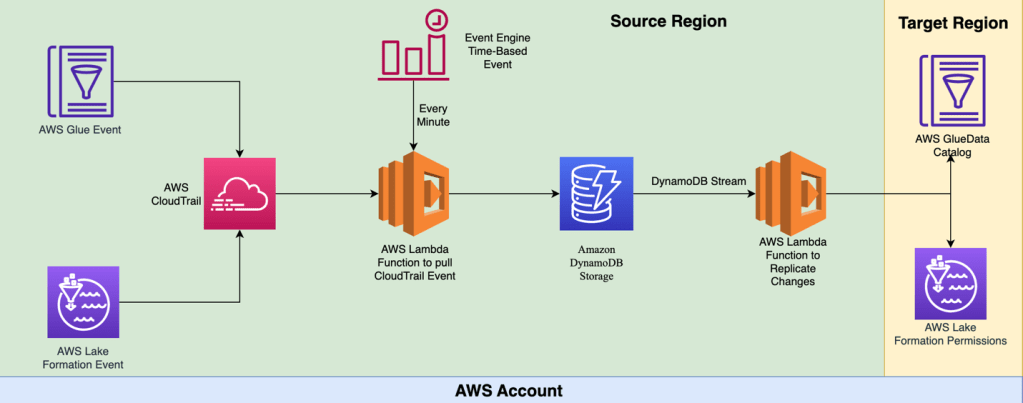
AWS CDK triển khai hai tác vụ AWS Lambda và tạo một bảng Amazon DynamoDB để lưu trữ các sự kiện AWS CloudTrail và một quy tắc Amazon EventBridge để chạy sao chép định kỳ. Các tác vụ Lambda lấy thông tin cấu hình từ tệp được lưu trữ trong một bucket S3. Tệp này bao gồm các chi tiết như Region nguồn và Region đích, các tùy chọn để di chuyển dữ liệu sang một bucket S3 khác và thời gian truy vấn cho CloudTrail trong giờ. Thêm thông tin về các tùy chọn này và hướng dẫn triển khai có sẵn trong kho GitHub.
Quy tắc EventBridge kích hoạt một tác vụ Lambda định kỳ. Tác vụ này lấy thông tin cấu hình và truy vấn các sự kiện CloudTrail liên quan đến Data Catalog và Lake Formation đã xảy ra trong giờ trước đó (thời gian này có thể được cấu hình). Tất cả các sự kiện liên quan được lưu trữ trong bảng DynamoDB.
Sau khi thông tin sự kiện được chèn vào bảng DynamoDB, một tác vụ Lambda khác được kích hoạt. Tác vụ này lấy thông tin cấu hình và truy vấn bảng DynamoDB. Sau đó, nó áp dụng tất cả các thay đổi vào Region đích. Nếu công cụ được chạy lại sau khi thực hiện thay đổi trên Region đích, các thay đổi sẽ được thay thế bằng các quyền Lake Formation và Data Catalog mới nhất từ Region nguồn. Khác với chế độ theo yêu cầu, tiện ích này còn loại bỏ bất kỳ quyền Lake Formation nào đã bị loại bỏ khỏi Region nguồn khỏi Region đích.
Giới hạn
Công cụ này được thiết kế để sao chép quyền hạn trong một tài khoản duy nhất. On-demand mode sao chép một bản chụp và không xóa các quyền hạn hiện có, vì vậy nó không thực hiện các hoạt động xóa. API hiện tại không hỗ trợ sao chép các thay đổi về quyền hạn của hàng và cột.
Kết luận
Trong bài viết này, chúng tôi đã chỉ ra cách sử dụng công cụ này để di chuyển AWS Glue Data Catalog và quyền hạn Lake Formation từ một Region đến Region khác. Nó cũng có thể giữ cho các Region nguồn và đích được đồng bộ hóa nếu có bất kỳ thay đổi nào được thực hiện trên Data Catalog hoặc quyền hạn Lake Formation. Triển khai trên nhiều Region là một lựa chọn tốt nếu bạn đang tìm kiếm sự phân tách và độc lập hoàn toàn của khối lượng công việc dữ liệu toàn cầu đa dạng của mình. Hãy xem xét các sự đánh đổi. Triển khai và vận hành chiến lược này, đặc biệt là sử dụng đa Region, có thể phức tạp hơn và đắt hơn so với các chiến lược phục hồi thảm họa khác.
Để bắt đầu, hãy kiểm tra kho lưu trữ GitHub. Để biết thêm tài nguyên, hãy tham khảo các tài nguyên sau đây:
Bài được dịch từ bài viết trên AWS Blogs, bạn có thể xem bài viết gốc tại đây.
