Được viết bởi Mark Sailes, Senior Serverless Solutions Architect, AWS.
Tại AWS re:Invent 2022, AWS đã công bố SnapStart cho các hàm AWS Lambda chạy trên Java Corretto 11. Tính năng này cho phép khách hàng đạt tới hiệu suất khởi động hàm nhanh hơn tới 10 lần cho các hàm Java, mà không tốn thêm chi phí và thường là không cần thay đổi mã hoặc chỉ đơn giản là cần ít thay đổi.
Tổng quan
Hiện nay, trong các lần gọi hàm của Lambda, nguyên nhân gây trễ khởi động lớn nhất là thời gian dành cho việc khởi tạo một hàm. Điều này bao gồm việc tải mã hàm và khởi tạo các phụ thuộc. Đối với các khối lượng công việc tương tác mà nhạy cảm với thời gian khởi động, điều này có thể gây ra trải nghiệm người dùng kém chất lượng.
Để giải quyết vấn đề này, khách hàng phải cung cấp tài nguyên trước thời gian hoặc tốn công sức xây dựng tối ưu hóa hiệu suất tương đối phức tạp. Mặc dù những phương án tạm thời này giúp giảm thiểu độ trễ khởi động, người dùng vẫn phải tốn thời gian cho một số công việc nặng nhọc thay vì tập trung vào việc cung cấp giá trị kinh doanh. SnapStart giải quyết trực tiếp vấn đề này cho các hàm Lambda dựa trên Java.
Cách SnapStart hoạt động
Với SnapStart, khi một khách hàng xuất bản một phiên bản hàm, dịch vụ Lambda sẽ khởi tạo mã của hàm. Nó sẽ lấy một bản snapshot được mã hóa của môi trường thực thi đã được khởi tạo và lưu trữ snapshot trong bộ đệm theo tầng để truy cập với độ trễ thấp.
Khi hàm được gọi lần đầu tiên và sau đó được mở rộng, Lambda sẽ tiếp tục môi trường thực thi từ bản snapshot đã lưu trữ thay vì khởi tạo lại từ đầu. Điều này dẫn đến thời gian khởi động thấp hơn.
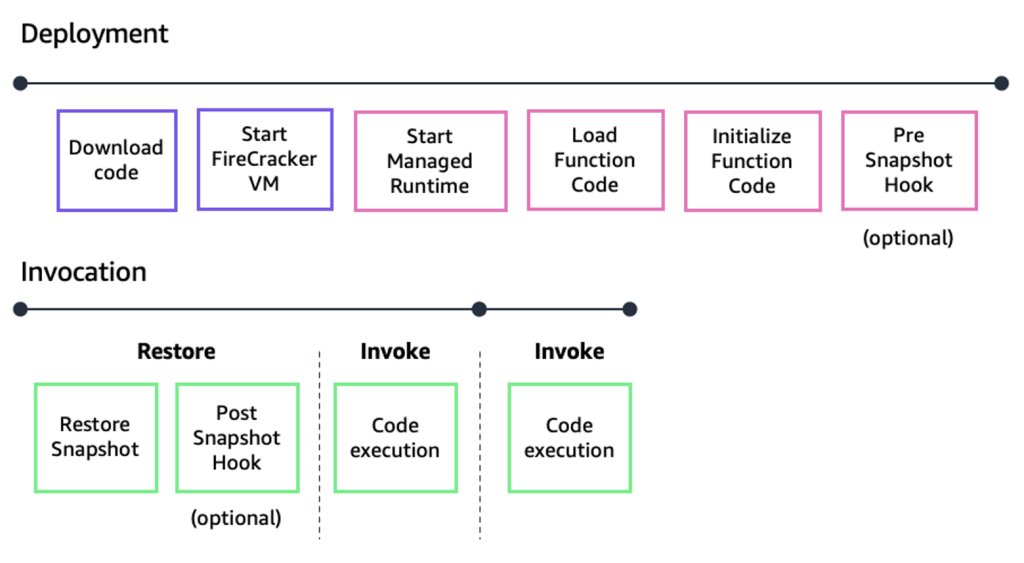
Một phiên bản hàm được kích hoạt với SnapStart sẽ chuyển sang trạng thái không hoạt động nếu nó không hoạt động trong vòng 14 ngày, sau đó Lambda sẽ xóa bản snapshot. Khi bạn cố gắng gọi một phiên bản hàm không hoạt động, cuộc gọi sẽ thất bại. Lambda gửi một SnapStartNotReadyException và bắt đầu khởi tạo một bản snapshot mới trong nền, trong khi phiên bản hàm vẫn ở trạng thái Pending. Hãy đợi cho đến khi hàm đạt trạng thái Active, sau đó gọi lại. Để tìm hiểu thêm về quy trình này và các trạng thái của hàm, hãy đọc tài liệu.
Sử dụng SnapStart
Các framework ứng dụng như Spring mang lại cho nhà phát triển một lợi ích vô cùng lớn về năng suất bằng cách giảm lượng mã boilerplate mà họ viết để thực hiện các tác vụ thông thường. Khi được tạo ra lần đầu, các framework không cần xem xét thời gian khởi động vì chúng chạy trên máy chủ ứng dụng, chạy trong một khoảng thời gian dài. Thời gian khởi động là tối thiểu so với thời gian chạy. Thông thường, bạn chỉ khởi động lại chúng khi có thay đổi phiên bản ứng dụng.
Nếu chức năng mà các framework này mang lại được thực hiện tại thời điểm chạy, thì chúng thường góp phần vào độ trễ trong thời gian khởi động. SnapStart cho phép bạn sử dụng các framework như Spring mà không ảnh hưởng đến thời gian trễ đuôi.
Để minh họa SnapStart, tôi sử dụng một ứng dụng mẫu lưu các bản ghi vào Amazon DynamoDB. Ứng dụng Spring Boot này sử dụng một REST controller để xử lý các yêu cầu CRUD. Mẫu này bao gồm cơ sở hạ tầng dưới dạng mã hạ tầng để triển khai ứng dụng bằng AWS Serverless Application Model (AWS SAM). Bạn phải cài đặt AWS SAM CLI để triển khai ví dụ này.
Để triển khai:
- Sao chép kho git và thay đổi đến thư mục dự án:
Bash
git clone https://github.com/aws-samples/serverless-patterns.git
cd serverless-patterns/apigw-lambda-snapstart
- Sử dụng AWS SAM CLI để xây dựng ứng dụng:
Bash
sam build
- Sử dụng AWS SAM CLI để triển khai tài nguyên vào tài khoản AWS của bạn:
Bash
sam deploy -g
Dự án này được triển khai với SnapStart đã được kích hoạt. Để bật hoặc tắt chức năng này trong AWS Management Console:
- Truy cập vào hàm Lambda của bạn.
- Chọn tab Cấu hình (Configuration).
- Chọn Sửa (Edit) và thay đổi thuộc tính SnapStart thành PublishedVersions.
- Chọn Lưu (Save).
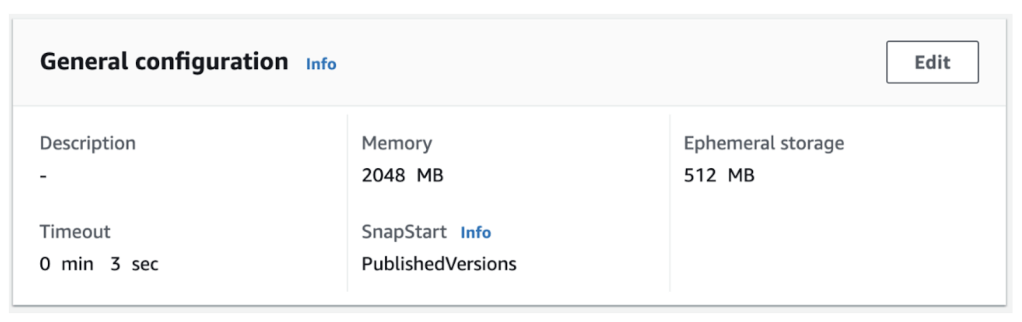
- Chọn tab Phiên bản (Versions) và chọn Phát hành phiên bản mới (Publish new).
- Chọn Phát hành (Publish).
Sau khi bạn đã bật SnapStart, Lambda sẽ phát hành tất cả các phiên bản tiếp theo với các bản snapshot. Thời gian để chạy phiên bản phát hành của bạn phụ thuộc vào mã init của bạn. Bạn có thể chạy init lên đến 15 phút với tính năng này.
Các yếu tố cần xem xét
Credentials cũ
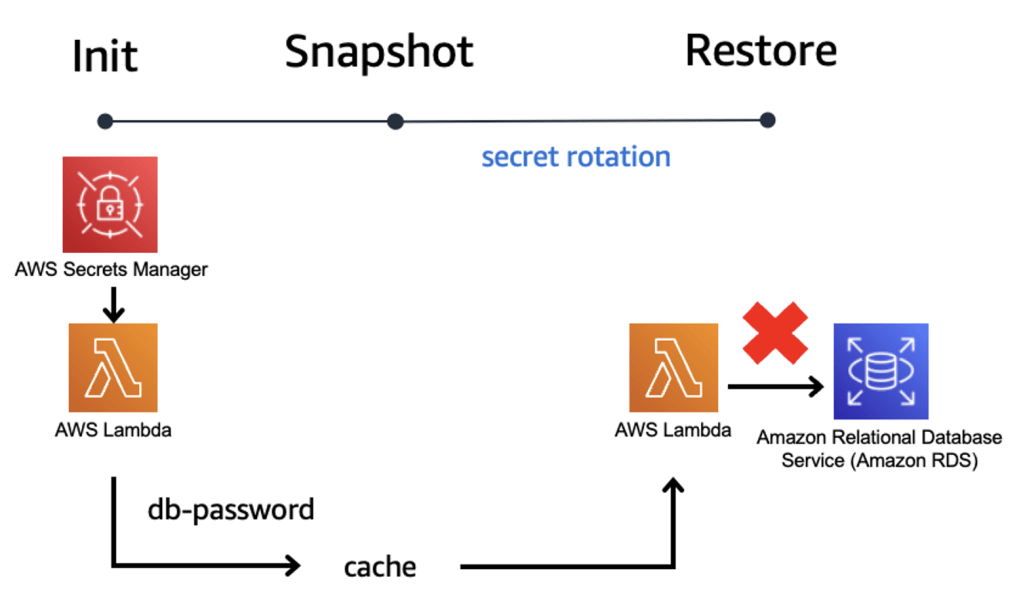
Khi sử dụng SnapStart và khôi phục từ một snapshot thì thường sẽ thay đổi cách bạn tạo ra các hàm. Với các hàm theo yêu cầu, bạn có thể truy cập dữ liệu một lần trong giai đoạn khởi tạo, sau đó sử dụng lại nó trong các lần gọi sau. Nếu dữ liệu này là tạm thời, ví dụ như mật khẩu cơ sở dữ liệu, thì có thể có khoảng thời gian giữa lần truy xuất và sử dụng dữ liệu đó, khi mật khẩu đã được thay đổi dẫn đến lỗi. Bạn phải viết mã để xử lý trường hợp lỗi này.
Với SnapStart, nếu bạn áp dụng cùng phương pháp, mật khẩu cơ sở dữ liệu của bạn sẽ được lưu giữ trong một snapshot được mã hóa. Tất cả các môi trường thực thi sau này đều có cùng trạng thái. Điều này có thể xảy ra sau vài ngày, vài tuần hoặc thậm chí cả tháng sau khi snapshot được tạo. Điều này làm cho khả năng hàm của bạn có mật khẩu không chính xác được lưu trữ. Để cải thiện điều này, bạn có thể chuyển chức năng truy xuất mật khẩu vào khối post-snapshot hook. Với mỗi phương pháp, điều quan trọng là hiểu nhu cầu của ứng dụng của bạn và xử lý lỗi khi chúng xảy ra.
Một thách thức thứ hai trong việc chia sẻ trạng thái ban đầu là về sự ngẫu nhiên và sự độc đáo. Nếu các giống ngẫu nhiên được lưu trữ trong snapshot trong giai đoạn khởi tạo, thì nó có thể dẫn đến việc các số ngẫu nhiên trở nên dễ đoán.
Mật mã học
AWS đã thay đổi runtime được quản lý để giúp khách hàng xử lý tác động của tính duy nhất và ngẫu nhiên khi khôi phục các chức năng.
Lambda đã tích hợp cập nhật cho Amazon Linux 2 và một trong các thư viện mật mã thông dụng, OpenSSL (1.0.2), để làm cho chúng chống lại hoạt động snapshot. AWS cũng đã xác nhận rằng mã Java runtime được tích hợp sẵn RNG java.security.SecureRandom giữ tính duy nhất khi khôi phục từ một snapshot.
Phần mềm luôn nhận các số ngẫu nhiên từ hệ điều hành (ví dụ như từ /dev/random hoặc /dev/urandom) đã chống lại hoạt động snapshot. Nó không cần cập nhật để khôi phục tính duy nhất. Tuy nhiên, khách hàng muốn thực hiện tính duy nhất bằng cách sử dụng mã tùy chỉnh cho các chức năng Lambda của mình phải xác nhận rằng mã của họ khôi phục tính duy nhất khi sử dụng SnapStart.
Để biết thêm chi tiết, hãy đọc Bắt đầu nhanh hơn với AWS Lambda SnapStart và tham khảo tài liệu Lambda về sự độc nhất của SnapStart.
Runtime hooks
Những pre- và post-hooks này cho phép các nhà phát triển có cách để phản ứng với quá trình chụp snapshot.
Ví dụ, một chức năng phải luôn tải trước một lượng lớn dữ liệu từ Amazon S3 thì nên thực hiện điều này trước khi Lambda thực hiện chụp snapshot. Điều này nhúng dữ liệu vào trong snapshot để không cần phải truy xuất nhiều lần. Tuy nhiên, trong một số trường hợp, bạn có thể không muốn giữ dữ liệu tạm thời. Mật khẩu cho một cơ sở dữ liệu có thể bị xoay vòng thường xuyên và gây ra lỗi không cần thiết. Tôi sẽ thảo luận về điều này chi tiết hơn ở phần sau.
Trình quản lý Java runtime sử dụng dự án Coordinated Restore at Checkpoint (CRaC) mã nguồn mở để cung cấp hỗ trợ cho hook. Runtime quản lý Java chứa một thực thi CRaC context tùy chỉnh gọi các hook của thời gian chạy Lambda trước khi hoàn tất quá trình tạo snapshot và sau khi khôi phục môi trường thực thi từ snapshot.
Ví dụ chức năng sau cho thấy cách bạn có thể tạo một trình xử lý chức năng với các hook thời gian chạy. Trình xử lý thực thi tài nguyên CRaC và giao diện Lambda RequestHandler.
Java
…
import org.crac.Resource;
import org.crac.Core;
…
public class HelloHandler implements RequestHandler<String, String>, Resource {
public HelloHandler() {
Core.getGlobalContext().register(this);
}
public String handleRequest(String name, Context context) throws IOException {
System.out.println(“Handler execution”);
return “Hello ” + name;
}
@Override
public void beforeCheckpoint(org.crac.Context<? extends Resource> context) throws Exception {
System.out.println(“Before Checkpoint”);
}
@Override
public void afterRestore(org.crac.Context<? extends Resource> context) throws Exception {
System.out.println(“After Restore”);
}
}
Để sử dụng các lớp cần thiết để viết runtime hooks, hãy thêm phụ thuộc sau vào dự án của bạn:
Maven
XML
<dependency>
<groupId>io.github.crac</groupId>
<artifactId>org-crac</artifactId>
<version>0.1.3</version>
</dependency>
Gradle
Text
implementation ‘io.github.crac:org-crac:0.1.3’
Priming
SnapStart và runtime hooks cung cấp cho bạn cách mới để xây dựng các hàm Lambda của bạn với thời gian khởi động thấp. Bạn có thể sử dụng hook trước snapshot để chuẩn bị ứng dụng Java của bạn càng sớm càng tốt cho lần gọi đầu tiên. Làm nhiều việc nhất có thể trong hàm của bạn trước khi snapshot được lấy. Điều này được gọi là priming.
Khi bạn tải tệp zip chứa mã Java của mình lên Lambda, tệp zip chứa các tệp .class của bytecode. Điều này có thể chạy trên bất kỳ máy tính nào có JVM. Khi JVM thực thi bytecode của bạn, nó được giải thích ban đầu, sau đó được biên dịch thành mã máy cơ bản. Giai đoạn biên dịch này tương đối tốn CPU và xảy ra ngay sau đó (Trình biên dịch JIT).
Bạn có thể sử dụng hook trước snapshot để chạy các đường dẫn mã trước khi snapshot được lấy. JVM biên dịch những đường dẫn mã này và tối ưu hóa được giữ lại để phục hồi trong tương lai. Ví dụ, nếu bạn có một hàm tích hợp với DynamoDB, bạn có thể thực hiện thao tác đọc trong hook trước snapshot của mình.
Điều này có nghĩa là mã hàm của bạn, SDK AWS cho Java và bất kỳ thư viện nào được sử dụng trong hành động đó được biên dịch và giữ lại trong snapshot. JVM sau đó sẽ không cần phải biên dịch mã này khi chạy hàm của bạn, điều này có nghĩa là thời gian chờ đợi của bạn ít hơn lần đầu tiên môi trường thực thi được gọi.
Priming yêu cầu bạn hiểu rõ mã ứng dụng của mình và hậu quả của việc thực thi nó. Ứng dụng mẫu bao gồm một hook trước snapshot, giúp thiết lập sẵn ứng dụng bằng cách thực hiện thao tác đọc từ DynamoDB.
Số liệu
Đồ thị sau đây thể hiện việc gọi hàm mẫu của ứng dụng Lambda 100 lần mỗi giây trong 10 phút. Kiểm tra này dựa trên hàm này, cả khi sử dụng và không sử dụng SnapStart.
| p50 | p99.9 | |
| On-demand | 7.87ms | 5,114ms |
| SnapStart | 7.87ms | 488ms |
Kết luận
Bài viết này trình bày cách SnapStart giảm thiểu thời gian trễ khởi động (cold-start) của các hàm Lambda dựa trên Java. Bạn có thể cấu hình SnapStart bằng cách sử dụng AWS SDK, AWS CloudFormation, AWS SAM, và CDK.
Để tìm hiểu thêm, xem Configuring function options trong tài liệu AWS. Chức năng này có thể yêu cầu một số thay đổi mã tối thiểu. Trong hầu hết các trường hợp, mã hiện có đã tương thích với SnapStart. Bây giờ bạn có thể đưa các tải khối lượng công việc trên Lambda dựa trên Java có độ trễ nhạy cảm đến khối lượng công việc Lambda và chạy với các thời gian đáp ứng đuôi được cải thiện.
Tính năng này cho phép các nhà phát triển sử dụng mô hình on-demand trong Lambda với thời gian phản hồi đáp ứng được cải thiện, mà không tốn thêm chi phí. Để đọc thêm về cách sử dụng SnapStart với các framework đối tác, tìm hiểu thêm từ Quarkus và Micronaut. Để đọc thêm về tính năng này và các tính năng khác, truy cập Serverless Land.
