Để đáp ứng nhu cầu của người dùng, các ứng dụng dựa trên HTTP động yêu cầu phải thường xuyên mở rộng các pod Kubernetes. Đối với các ứng dụng được tiết lộ thông qua đối tượng ingress của Kubernetes, AWS Application Load Balancer (ALB) phân phối lưu lượng đến các bản sao mới được mở rộng một cách tự động. Khi các ứng dụng Kubernetes giảm tỷ lệ do sự suy giảm về nhu cầu, một số tình huống sẽ dẫn đến gián đoạn ngắn cho người dùng cuối. Trong bài đăng này, chúng tôi sẽ chỉ cho bạn cách tạo kiến trúc cho phép tài nguyên của ứng dụng mở rộng một cách trôi chảy và giảm thiểu tác động đến người dùng.
Để đạt được việc đóng ứng dụng trôi chảy, yêu cầu phải kết hợp các cấu hình của ứng dụng, Kubernetes và target group. AWS Load Balancer Controller hỗ trợ chú thích kiểm tra sức khỏe để phù hợp với đợt kiểm tra sẵn sàng của pod để chỉ ra rằng địa chỉ IP của pod được đăng ký làm mục tiêu ALB là khỏe mạnh để nhận lưu lượng.
Trong bài đăng này, chúng tôi sẽ giới thiệu cách sử dụng endpoint ứng dụng riêng biệt như một kiểm tra sức khỏe Amazon Load Balancer kèm theo Kubernetes readiness probe và PreStop hooks giúp đóng ứng dụng trôi chảy. Ngoài ra, chúng tôi sẽ mô phỏng một tải lớn với hàng ngàn phiên đồng thời ở đỉnh và chứng minh rằng việc thực hiện các bước này sẽ loại bỏ tỷ lệ lỗi HTTP 50X mà người dùng cuối trải nghiệm.
Kiến trúc mô phỏng
Mẫu mã code triển khai một ứng dụng web đằng sau ALB và thể hiện việc chuyển đổi tuyệt đối giữa các pod trong sự kiện thu nhỏ quy mô. Ứng dụng sử dụng cơ sở dữ liệu backend để lưu trữ các đơn đặt hàng vận chuyển. Chúng tôi sẽ tạo một cụm Amazon Elastic Kubernetes Service (Amazon EKS), sử dụng VPC CNI cho mạng pod và cài đặt tiện ích bổ sung AWS Load Balancer Controller. Tiếp theo, chúng tôi sẽ triển khai một ứng dụng Django đơn giản chấp nhận các yêu cầu giả tạo từ một bộ mô phỏng tải và sửa đổi ReplicaSet của một Kubernetes deployment. Ngoài ra, chúng tôi sẽ triển khai cluster autoscaler, thay đổi Auto scaling group size để phù hợp với nhu cầu của các pod ứng dụng Django. Chúng tôi sẽ giám sát sức khỏe của ứng dụng trong sự kiện thu nhỏ quy mô.

Mã nguồn
Chúng tôi đã cung cấp đầy đủ các tài liệu triển khai trong kho mã aws-samples. Ngoài ra, kho chứa hướng dẫn để thiết lập cơ sở hạ tầng và logistics-db cần thiết. Để bắt đầu, triển khai ứng dụng Django Ingress mà không có kiểm tra sức khỏe và ứng dụng giả lập. Cho phép trình giả lập chạy khoảng 30 phút. Điều này phải tạo ra đủ dữ liệu để tạo đồ thị, như được miêu tả trong phần sau.
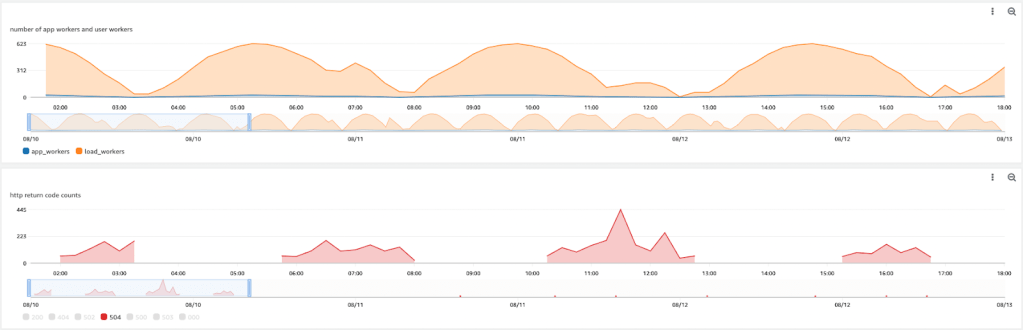
Đánh giá
Hãy tạo một bảng điều khiển Amazon CloudWatch trong namespace “appsimulator” để giám sát các chỉ số được báo cáo bởi trình giả lập. Đồ thị đầu tiên đại diện cho tổng số pod ứng dụng và pod giả lập tải. Hai đồ thị tiếp theo cho thấy số lượng mã lỗi HTTP chung trong suốt giai đoạn giảm quy mô. Các đồ thị dưới đây mô tả số lượng nút cụm tại một thời điểm nhất định. Trong đỉnh điểm, tổng cộng 623 pod giả lập đang chạy trên 30 nút EC2 loại t4g.xlarge, như được hiển thị trong đồ thị sau. Quan sát tỷ lệ lỗi HTTP 50x tăng lên trong suốt sự kiện giảm quy mô do yêu cầu của người dùng dao động.
Trong phần tiếp theo, chúng tôi sẽ giới thiệu cách chúng tôi có thể sử dụng Kubernetes PreStop hook, kiểm tra sẵn sàng và kiểm tra sức khỏe được hỗ trợ bởi AWS Load Balancer Controller để xử lý các tín hiệu SIGTERM do kết thúc pod và cho phép một lối ra nhẹ nhàng mà không ảnh hưởng đến người dùng cuối.
Các bước mà chúng tôi đã thực hiện để loại bỏ các lỗi:
Chúng tôi đã triển khai một chức năng sức khỏe ứng dụng mới với một trình xử lý tín hiệu. Sau đó, chúng tôi đã cấu hình nhóm mục tiêu của bộ cân bằng tải và kubelet để sử dụng chỉ báo sức khỏe mới.

Chúng tôi đã thêm một /logistics/health endpoint riêng biệt, và chúng tôi sẽ cấu hình đối tượng nhập cảnh Kubernetes để sử dụng điểm kiểm tra sức khỏe bằng cách sử dụng chú thích alb.ingress.kubernetes.io/healthcheck-path. Chúng tôi đã cấu hình một tần suất xem xét tương tự như alb.ingress.kubernetes.io/healthcheck-interval-seconds để đánh dấu container không khả dụng.
Snippet from Kubernetes ingress spec
kind: Ingress
metadata:
name: django-ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/healthcheck-path: /logistics/health
alb.ingress.kubernetes.io/success-codes: ‘200-301’
alb.ingress.kubernetes.io/healthcheck-interval-seconds: ‘3’
Snippet from Kubernetes deployment spec
readinessProbe:
httpGet:
path: /logistics/health
port: 8000
initialDelaySeconds: 3
periodSeconds: 3
Pod nhận tín hiệu SIGTERM từ kubelet do Kubernetes muốn dừng nó do sự kiện chấm dứt nút hoặc sự kiện tỉ lệ. PreStop hook cho phép bạn chạy lệnh tùy chỉnh trước khi SIGTERM được gửi đến container pod. Pod logistics bắt đầu trả về mã lỗi 500 cho GET /logistics/health để cho biết Readiness probe biết rằng nó không sẵn sàng nhận yêu cầu thêm, và Load Balancer Controller cập nhật ALB để loại bỏ các mục tiêu không khỏe mạnh.
Snippet from Kubernetes deployment spec:
:
preStop:
exec:
command: [“/bin/sh”, “-c”, “sed -i ‘s/health/nothealthy/g’ /usr/src/app/logistics/health.py && sleep 120”]
Bạn có thể áp dụng Django ingress manifest đã cập nhật với các thay đổi trên. Cho phép khoảng ba mươi phút cho mô phỏng để tạo ra tải trước khi giảm tỷ lệ ứng dụng.
Kết quả kiểm thử

Số lượng lỗi 504 giảm từ trung bình 340 trong sự kiện giảm quy mô xuống thành 0, trong khi số lượng lỗi 502 giảm từ 200 xuống còn 30. Các vấn đề 502 này được kubelet phát hiện, nhưng không được người dùng cuối truy cập vào ứng dụng thông qua ALB phát hiện.
Kết luận
Bài viết này cho thấy cách Amazon EKS và AWS Load Balancer Controller giúp bạn quản lý nhu cầu ứng dụng thay đổi mà không ảnh hưởng đến trải nghiệm của người dùng cuối. Bằng cách kết hợp Kubernetes PreStop hook và readiness probe với điểm kiểm tra sức khỏe, bạn có thể điều chỉnh tín hiệu SIGTERM cho ứng dụng của mình một cách trôi chảy. Hãy kiểm tra tài liệu AWS Load Balancer Controller để biết danh sách đầy đủ các chú thích được hỗ trợ.
