Bài viết này được viết bởi Mansi Y Doshi, Nhà tư vấn và Aditya Goteti, Chuyên viên cấp cao.
Các doanh nghiệp đang hiện đại hóa và di chuyển ứng dụng của mình lên AWS Cloud để cải thiện tính mở rộng, giảm chi phí, đổi mới và giảm thời gian ra mắt các tính năng mới. Các ứng dụng kế thừa thường được xây dựng với RDBMS là giải pháp backend duy nhất.
Hiện đại hóa các ứng dụng Java kế thừa bằng microservices đòi hỏi phải phân tách một ứng dụng đơn điệu thành nhiều dịch vụ độc lập. Mỗi microservice thực hiện một công việc cụ thể và yêu cầu một cơ sở dữ liệu riêng để lưu trữ dữ liệu, nhưng một cơ sở dữ liệu không phù hợp cho tất cả các trường hợp sử dụng. Các ứng dụng hiện đại yêu cầu các cơ sở dữ liệu được xây dựng với mục đích cụ thể phù hợp với nhu cầu và mô hình dữ liệu của chúng.
Bài viết này sẽ thảo luận về một số trường hợp sử dụng phổ biến cho một trong những kho dữ liệu này, Amazon MemoryDB cho Redis, được xây dựng để cung cấp tính bền vững và tốc độ đọc và ghi nhanh hơn.
Các trường hợp sử dụng
Các bộ công cụ công nghệ hiện đại thường bắt đầu với backend tương tác với cơ sở dữ liệu bền vững như MongoDB, Amazon Aurora hoặc Amazon DynamoDB để đáp ứng nhu cầu lưu trữ dữ liệu của họ.
Tuy nhiên, khi lưu lượng truy cập tăng lên, thường có ý nghĩa để giới thiệu một lớp caching như ElastiCache. Điều này được điền vào dữ liệu bởi logic dịch vụ mỗi khi một lần đọc cơ sở dữ liệu xảy ra, để cho các lần đọc tiếp theo của cùng dữ liệu trở nên nhanh hơn. Mặc dù ElastiCache rất hiệu quả, bạn phải quản lý và trả tiền cho hai nguồn dữ liệu riêng biệt cho cùng một dữ liệu. Bạn cũng phải viết logic tùy chỉnh để xử lý các lần đọc / ghi cache bên cạnh logic đọc / ghi hiện có được sử dụng cho cơ sở dữ liệu bền vững.
Trong khi các cơ sở dữ liệu truyền thống như MySQL, Postgres và DynamoDB cung cấp tính bền vững dữ liệu với chi phí tốc độ, các cửa hàng dữ liệu tạm thời như ElastiCache đổi tính bền vững lấy tốc độ đọc / ghi nhanh hơn (thường trong vài micro giây). ElastiCache cung cấp các lần ghi và đọc mạnh trên nút chính của mỗi shard và đọc có tính nhất quán cuối cùng từ các bản sao đọc. Có khả năng dữ liệu mới nhất được viết vào nút chính bị mất trong quá trình chuyển đổi, làm cho ElastiCache trở nên nhanh nhưng không bền vững.
MemoryDB giải quyết cả hai vấn đề này. Nó cung cấp tính nhất quán mạnh trên nút chính và đọc có tính nhất quán cuối cùng trên các nút sao chép. Mô hình tính nhất quán của MemoryDB giống như ElastiCache cho Redis. Tuy nhiên, trong MemoryDB, dữ liệu không bị mất qua các failover, cho phép các khách hàng đọc viết của họ từ các nút chính mà không phụ thuộc vào các lỗi nút. Chỉ có dữ liệu được lưu trữ thành công trong nhật ký giao dịch Multi-AZ mới được hiển thị. Các nút sao chép vẫn có độ nhất quán cuối cùng. Nhờ mô hình giao dịch phân tán, MemoryDB có thể cung cấp cả tính bền vững và thời gian phản hồi microsecond.
MemoryDB là phương án lý tưởng nhất cho các dịch vụ có tính chất đọc nhiều và nhạy cảm với độ trễ, như dịch vụ cấu hình, tìm kiếm, xác thực và bảng xếp hạng. Chúng phải hoạt động với độ trễ đọc ở mức microsecond và vẫn có thể lưu trữ dữ liệu để đảm bảo sẵn có và bền vững. Các dịch vụ như bảng xếp hạng, với hàng triệu bản ghi, thường chia nhỏ dữ liệu thành các khối/phân đoạn nhỏ hơn và xử lý chúng song song. Điều này yêu cầu một cơ sở dữ liệu có thể thực hiện tính toán ngay lập tức và lưu trữ kết quả tạm thời. Redis có thể xử lý hàng triệu hoạt động mỗi giây và lưu trữ tính toán tạm thời để tìm kiếm nhanh chóng và chạy các hoạt động khác (như tổng hợp). Vì Redis là đơn luồng, từ quan điểm thực thi lệnh, nó cũng giúp tránh các ghi và đọc bẩn.
Một trường hợp sử dụng khác là dịch vụ cấu hình, nơi người dùng lưu trữ, thay đổi và truy xuất dữ liệu cấu hình của họ. Trong các hệ thống phân tán lớn, thường có hàng trăm dịch vụ độc lập tương tác với nhau bằng các API REST được xác định rõ ràng. Những dịch vụ này phụ thuộc vào dữ liệu cấu hình để thực hiện các hành động cụ thể. Dịch vụ cấu hình phải cung cấp thông tin cần thiết với độ trễ thấp để tránh trở thành chướng ngại cho các dịch vụ phụ thuộc khác.
MemoryDB có thể đọc dữ liệu ở độ trễ microsecond và đáng tin cậy. Nó cũng duy trì dữ liệu trên nhiều Khu vực Khả dụng. Nó sử dụng nhật ký giao dịch đa Khu vực Khả dụng để cho phép khôi phục nhanh, phục hồi cơ sở dữ liệu và khởi động lại nút. Bạn có thể sử dụng nó như một cơ sở dữ liệu chính mà không cần phải duy trì bộ đệm khác để giảm độ trễ truy cập dữ liệu. Điều này cũng giảm thiểu nhu cầu duy trì dịch vụ bộ đệm bổ sung, từ đó giảm chi phí.
Những trường hợp sử dụng này là lý tưởng để sử dụng MemoryDB. Tiếp theo, bạn sẽ thấy cách truy cập, lưu trữ và lấy dữ liệu trong MemoryDB từ chức năng AWS Lambda dựa trên Java của bạn.
Tổng quan
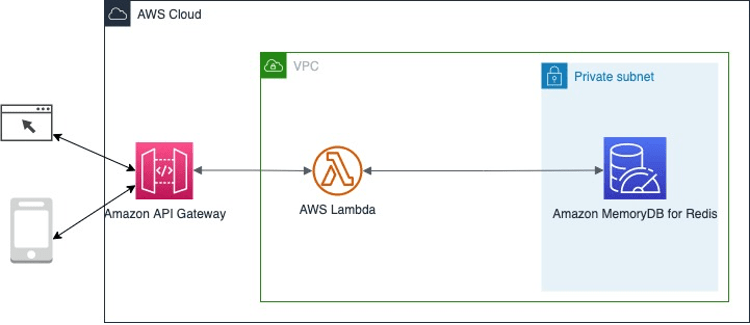
Bài đăng này hướng dẫn cách xây dựng một cụm Amazon MemoryDB và tích hợp nó với AWS Lambda. Amazon API Gateway và Lambda có thể được ghép cặp với nhau để tạo ra một ứng dụng dành cho khách hàng, có thể dễ dàng bảo trì, có khả năng mở rộng cao và bảo mật. Cả hai đều là các dịch vụ quản lý đầy đủ mà không cần cung cấp hoặc quản lý máy chủ. Chúng cũng có thể hiệu quả về chi phí so với việc chạy ứng dụng trên máy chủ cho các khối lượng công việc với chu kỳ không hoạt động lâu dài. Bằng cách sử dụng các bộ xác thực Lambda, bạn cũng có thể viết mã tùy chỉnh để kiểm soát quyền truy cập vào API của mình.
Hướng dẫn
Các bước sau đây chỉ ra cách cung cấp một cụm Amazon MemoryDB cùng với Amazon VPC, các mạng con, các nhóm bảo mật và tích hợp nó với một hàm Lambda sử dụng Redis/Jedis Java client. Ở đây, hàm Lambda được cấu hình để kết nối với cùng một VPC nơi MemoryDB được cung cấp. Các bước bao gồm cung cấp thông qua mẫu AWS SAM.
Yêu cầu tiên quyết
- Tạo một tài khoản AWS nếu bạn chưa có và đăng nhập vào.
- Cấu hình tài khoản của bạn và thiết lập quyền truy cập vào MemoryDB.
- Java 8 trở lên
- Cài đặt Maven
- Java Client cho Redis
- Cài đặt AWS SAM nếu bạn chưa có.
Tạo cụm MemoryDB
Tham khảo mẫu serverless để thiết lập nhanh và tùy chỉnh theo yêu cầu. Mẫu AWS SAM tạo VPC, các subnet, các nhóm bảo mật, cụm MemoryDB, API Gateway và Lambda.
Để truy cập vào cụm MemoryDB từ hàm Lambda, nhóm bảo mật của hàm Lambda được thêm vào nhóm bảo mật của cụm. Cụm MemoryDB luôn được khởi chạy trong một VPC. Nếu không chỉ định mạng con, cụm được khởi chạy vào VPC Amazon mặc định của bạn.
Bạn cũng có thể sử dụng VPC và mạng con hiện có của mình và tùy chỉnh mẫu tương ứng. Nếu bạn tạo một VPC mới, bạn có thể thay đổi khối CIDR và các giá trị cấu hình khác theo nhu cầu. Hãy đảm bảo rằng tên máy chủ DNS và hỗ trợ DNS của VPC đã được bật. Sử dụng phần thông số tùy chọn để tùy chỉnh các mẫu của bạn. Tham số cho phép bạn nhập các giá trị tùy chỉnh cho mẫu của bạn mỗi khi bạn tạo hoặc cập nhật một stack.
Khuyến nghị
Khi yêu cầu công việc của bạn thay đổi, bạn có thể muốn tăng hiệu suất của cluster hoặc giảm chi phí bằng cách điều chỉnh quy mô của cluster. Để cải thiện hiệu suất đọc/ghi, bạn có thể mở rộng cluster theo chiều ngang bằng cách tăng số bản sao đọc hoặc số shard để đọc và ghi tương ứng.
Để giảm chi phí trong trường hợp các instances được cấp quá nhiều, bạn có thể thực hiện thu gọn quy mô theo chiều dọc bằng cách giảm kích thước cluster của bạn, hoặc mở rộng bằng cách tăng kích thước để vượt qua các bottleneck CPU/ áp lực bộ nhớ. Cả thu gọn theo chiều dọc và mở rộng theo chiều ngang được áp dụng mà không có thời gian chết và không yêu cầu khởi động lại cluster. Bạn có thể tùy chỉnh các tham số sau trong memoryDBCluster theo yêu cầu.
JSON
NodeType: db.t4g.small
NumReplicasPerShard: 2
NumShards: 2
Trong MemoryDB, tất cả các ghi chép đều được thực hiện trên một nút chính trong một shard và tất cả các yêu cầu đọc được thực hiện trên các nút chờ. Xác định đúng số lượng bản sao cho yêu cầu đọc, loại nút và shards trong một cluster là rất quan trọng để đạt được hiệu suất tối ưu và tránh bất kỳ chi phí bổ sung nào do quá khai thác tài nguyên. Luôn khuyến khích bắt đầu với số lượng tài nguyên yêu cầu tối thiểu và mở rộng khi cần thiết.
Các bản sao cải thiện khả năng mở rộng đọc và khuyến khích có ít nhất hai bản sao đọc cho mỗi shard nhưng tùy thuộc vào kích thước của payload và cho các tải trọng đọc nặng, nó có thể nhiều hơn hai. Thêm nhiều bản sao đọc hơn yêu cầu không cải thiện hiệu suất và thu hút chi phí bổ sung. Đánh giá hiệu suất sử dụng công cụ Redis benchmark. Đánh giá hiệu suất được thực hiện chỉ trên các yêu cầu GET để mô phỏng tải trọng đọc nặng.
Các số liệu trên cả hai cluster gần như giống nhau với 10 triệu yêu cầu với 1KB dữ liệu payload cho mỗi yêu cầu. Tăng kích thước payload lên 5KB và số yêu cầu GET lên 20 triệu, cluster với hai nút chính và hai bản sao không thể xử lý, trong khi cluster thứ hai đã xử lý thành công. Để đạt được kích thước phù hợp, kiểm tra tải trên môi trường staging/pre-production với tải trọng tương tự như production được khuyến khích.
Tạo một hàm Lambda và cho phép truy cập vào cụm MemoryDB
Trong tệp lambda-redis/HelloWorldFunction/pom.xml, thêm dependency sau đây. Điều này sẽ thêm khách hàng Java Jedis để kết nối tới cụm MemoryDB:
XML
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.2.0</version>
</dependency>
Cách đơn giản nhất để kết nối hàm Lambda với cụm MemoryDB là thông qua cấu hình trong cùng một VPC nơi cụm MemoryDB được khởi chạy.
Để tạo một hàm Lambda, thêm đoạn mã sau vào tệp template.yaml trong phần Resources:
YAML
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: HelloWorldFunction
Handler: helloworld.App::handleRequest
Runtime: java8
MemorySize: 512
Timeout: 900 #seconds
Events:
HelloWorld:
Type: Api
Properties:
Path: /hello
Method: get
VpcConfig:
SecurityGroupIds:
– !GetAtt lambdaSG.GroupId
SubnetIds:
– !GetAtt privateSubnetA.SubnetId
– !GetAtt privateSubnetB.SubnetId
Environment:
Variables:
ClusterAddress: !GetAtt memoryDBCluster.ClusterEndpoint.Address
Mã Java để truy cập MemoryDB
- Trong lớp Java của bạn, kết nối đến Redis bằng cách sử dụng Jedis client:
Java
HostAndPort hostAndPort = new HostAndPort(System.getenv(“ClusterAddress”), 6379);
JedisCluster jedisCluster = new JedisCluster(Collections.singleton(hostAndPort), 5000, 5000, 2, null, null, new GenericObjectPoolConfig (), true);
- Bây giờ bạn có thể thực hiện các hoạt động set và get trên Redis như sau:
Java
jedisCluster.set(“test”, “value”)
jedisCluster.get(“test”)
JedisCluster duy trì một bể kết nối riêng và quản lý việc ngắt kết nối. Tuy nhiên, bạn cũng có thể tùy chỉnh cấu hình cho việc đóng kết nối trống bằng đối tượng GenericObjectPoolConfig.
Dọn dẹp
Để xóa toàn bộ stack, chạy lệnh “sam delete”.
Kết luận
Trong bài viết này, bạn đã học cách cung cấp một cluster MemoryDB và truy cập nó bằng Lambda. MemoryDB phù hợp cho các ứng dụng yêu cầu đọc trong microsecond và ghi trong single-digit millisecond kết hợp với lưu trữ bền vững. Truy cập MemoryDB thông qua Lambda sử dụng API Gateway giảm thiểu nhu cầu cung cấp và duy trì máy chủ.
Để tìm hiểu thêm tài nguyên học tập về serverless, hãy truy cập Serverless Land.
