Bởi Julian Wood | on 24 AUG 2021
Loạt bài viết này sử dụng AWS Well-Architected Tool với Serverless Lens để hỗ trợ khách hàng xây dựng và vận hành ứng dụng bằng cách sử dụng các best practices. Trong mỗi bài viết, mình sẽ đề cập đến các câu hỏi cụ thể về serverless được xác định bởi Serverless Lens cùng với các best practices được đề xuất. Xem post này để biết thêm về việc xây dựng ứng dụng well-architected serverless.
PERF 1. Tối ưu hóa hiệu suất của ứng dụng serverless của bạn
Bài viết này tiếp tục phần 1 của vấn đề bảo mật này. Trước đó, mình đã đề cập đến việc đo lường và tối ưu hóa thời gian khởi động function. Mình giải thích về cold start và warm start, cũng như cách tái sử dụng môi trường thực thi Lambda để cải thiện hiệu suất. Mình cũng đã trình bày một số cách để phân tích và tối ưu thời gian khởi động initialization. Mình cũng đã giải thích làm thế nào việc import các libraries và dependencies cần thiết giúp tăng hiệu suất ứng dụng.
Cách làm tốt: Thiết kế function của bạn để tận dụng tính năng concurrency thông qua các lệnh gọi không đồng bộ và dựa trên luồng
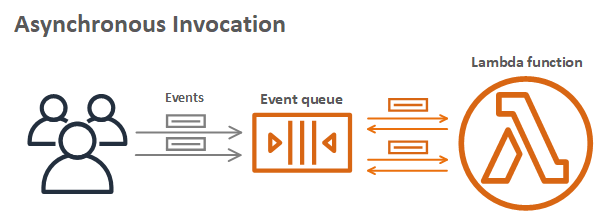
Các AWS Lambda function có thể được gọi đồng bộ (synchronously) và bất đồng bộ (asynchronously).
Ưu tiên xử lý bất đồng bộ hơn xử lý request-response đồng bộ.
Hãy xem xét việc sử dụng xử lý sự kiện bất đồng bộ thay vì xử lý request-response đồng bộ. Bạn có thể sử dụng xử lý bất đồng bộ để tổng hợp hàng đợi, luồng hoặc sự kiện để tăng hiệu suất xử lý mỗi lần gọi. Điều này giảm thời gian chờ đợi và độ trễ từ các request của ứng dụng và function.
Khi bạn gọi một Lambda function với một synchronous invocation, bạn phải đợi cho function xử lý sự kiện và trả về một response.

Lời gọi đồng bộ
Khi xử lý đồng bộ liên quan đến mô hình request-response, client cũng cần đợi response từ một downstream service. Nếu downstream service sau đó cần gọi một dịch vụ khác, bạn sẽ kết thúc chuỗi call khi bị time out, điều này ảnh hưởng tới độ tin cậy của dịch vụ.
Ví dụ, request với POST /order phải đợi phản hồi từ request POST /invoice trước khi response cho client.

Ví dụ xử lý đồng bộ
Càng tích hợp nhiều dịch vụ, thời gian phản hồi càng lâu, và bạn không thể duy trì các luồng công việc phức tạp bằng các giao dịch đồng bộ.
Xử lý bất đồng bộ cho phép bạn tách rời request-response bằng cách sử dụng các sự kiện mà không cần chờ response từ function code. Điều này cho phép bạn thực hiện xử lý dưới background mà không yêu cầu client chờ response, cải thiện hiệu suất máy khách. Bạn chuyển sự kiện đến hàng đợi Lambda nội bộ để xử lý và Lambda sẽ xử lý phần còn lại. Một quy trình bên ngoài, tách biệt với function, quản lý việc gửi và thử lại. Sử dụng phương pháp bất đồng bộ này cũng có thể giúp xử lý lưu lượng truy cập không thể đoán trước với khối lượng đáng kể dễ dàng hơn.

Lệnh gọi bất đồng bộ
Ví dụ, client thực hiện một request POST /order đến order service. Order service chấp nhận yêu cầu và trả về rằng nó đã được nhận, mà không cần đợi invoice service. Sau đó, order service thực hiện một yêu cầu bất đồng bộ POST /invoice đến invoice service, dịch vụ này có thể xử lý độc lập với order service. Nếu client cần nhận dữ liệu từ invoice service, nó có thể xử lý riêng thông qua một yêu cầu GET /invoice.

Ví dụ xử lý bất đồng bộ
Bạn có thể cấu hình Lambda để gửi records của các lời gọi bất đồng bộ đến một dịch vụ đích khác. Điều này giúp bạn giải quyết sự cố với các lời gọi của mình. Bạn cũng có thể gửi các messages hoặc sự kiện không thể xử lý đúng cách vào một hàng đợi dead-letter queue của Amazon Simple Queue Service (SQS) riêng để điều tra.
Bạn có thể thêm các trigger vào một function để xử lý dữ liệu tự động. Để biết thêm thông tin về mô hình xử lý nào mà Lambda sử dụng cho các trigger, xem “Sử dụng AWS Lambda với các dịch vụ khác“.
Các luồng công việc bất đồng bộ xử lý một loạt các trường hợp bao gồm việc nhập dữ liệu, các hoạt động ETL, và thực hiện order/request. Trong những trường hợp sử dụng này, dữ liệu được xử lý khi nó đến và được truy xuất khi nó thay đổi. Ví dụ về các mẫu bất đồng bộ, xem “Xử lý dữ liệu serverless” và “Gửi sự kiện serverless kèm cập nhật trạng thái“.
Để biết thêm thông tin về các lời gọi đồng bộ và bất đồng bộ của Lambda, xem bài thuyết trình “Tối ưu hóa các ứng dụng serverless của bạn” trong sự kiện AWS re:Invent.
Điều chỉnh kích thước hàng loạt, cửa sổ hàng loạt và nén dữ liệu để tăng throughput
Khi sử dụng Lambda để xử lý các records sử dụng Amazon Kinesis Data Streams hoặc SQS, có một số tham số điều chỉnh cần xem xét để tối ưu hiệu suất.
Bạn có thể cấu hình một cửa sổ hàng loạt (batch window) để buffer messages hoặc records trong tối đa 5 phút. Bạn có thể đặt một giới hạn về số lượng record tối đa mà Lambda có thể xử lý bằng cách đặt batch size. Lambda function của bạn được gọi dựa trên điều kiện nào xảy ra trước.
Đối với lưu lượng cao của SQS standard queue, Lambda có thể xử lý lên đến 1000 batch record đồng thời mỗi giây. Để biết thêm thông tin, xem “Sử dụng AWS Lambda với Amazon SQS“.
Đối với lưu lượng cao của Kinesis Data Streams, có một số tùy chọn. Cấu hình thiết lập `ParallelizationFactor`để xử lý một phân đoạn của Kinesis Data Stream với nhiều lời gọi Lambda đồng thời. Lambda có thể xử lý đến 10 batch trong mỗi phân đoạn. Để biết thêm thông tin, xem “Control scaling mới của AWS Lambda cho các nguồn sự kiện Kinesis và DynamoDB.” Bạn cũng có thể thêm nhiều phân đoạn vào luồng dữ liệu của bạn để tăng tốc độ xử lý record của function. Điều này tăng tính đồng thời của function nhưng giảm đi tính tuần tự của mỗi phân đoạn. Để biết thêm chi tiết về việc sử dụng Kinesis và Lambda, xem “Giám sát và sửa lỗi ứng dụng phân tích dữ liệu serverless“.
Kinesis enhanced fan-out có thể tối đa hóa lưu lượng thông qua việc dành một kênh 2 MB/giây, input/output, mỗi giây cho mỗi consumer thay vì 2 MB mỗi phân đoạn. Để biết thêm thông tin, xem “Tăng hiệu suất xử lý luồng với Enhanced Fan-Out và Lambda“.
Kinesis stream producers cũng có thể nén record. Điều này đòi hỏi thêm vòng lặp CPU để giải nén các record trong code Lambda function của bạn.
Yêu cầu thực hành: Đo lường, đánh giá và lựa chọn đơn vị công suất tối ưu
Capacity units là đơn vị tiêu thụ cho một dịch vụ. Chúng có thể bao gồm kích thước memory của function, số lượng phân đoạn luồng, số lần đọc/ghi cơ sở dữ liệu, các request units hoặc loại API endpoint. Đo lường, đánh giá và lựa chọn các Capacity units để cho phép cấu hình tối ưu về hiệu suất, throughput và chi phí.
Xác định và triển khai các capacity units tối ưu.
Đối với các Lambda function, memory là đơn vị dung lượng để kiểm soát hiệu suất của một function. Bạn có thể cấu hình số lượng memory được cấp cho một Lambda function, từ 128MB đến 10,240MB. Số lượng memory cũng xác định số lượng CPU ảo có sẵn cho một function. Thêm nhiều memory sẽ tăng tỷ lệ số lượng CPU, tăng cường sức mạnh tính toán tổng thể có sẵn. Nếu một function bị ràng buộc bởi CPU, mạng hoặc memory, thay đổi cài đặt memory có thể cải thiện đáng kể hiệu suất của nó.
Việc chọn số lượng memory được cấp cho các Lambda function là một quy trình tối ưu hóa cân bằng giữa hiệu suất (thời gian chạy) và chi phí. Bạn có thể chạy thử nghiệm thủ công trên các function bằng cách cấp memory khác nhau và đo thời gian hoàn thành. Hoặc, sử dụng công cụ AWS Lambda Power Tuning để tự động hóa quy trình.
Công cụ cho phép bạn kiểm tra một cách có hệ thống cùng các cấu hình với kích thước memory khác nhau và tùy thuộc vào chiến lược hiệu suất của bạn (chi phí, hiệu suất, cân bằng) nó xác định lựa chọn kích thước memory tối ưu nhất để sử dụng. Để biết thêm thông tin, xem “Vận hành Lambda: Tối ưu hiệu suất – Phần 2“.

Báo cáo AWS Lambda Power Tuning
Amazon DynamoDB quản lý năng lực xử lý table bằng cách sử dụng các capacity units đọc và ghi. Có hai chế độ capacity khác nhau, on-demand và provisioned.
Chế độ on-demand capacity hỗ trợ lên đến 40K đơn vị yêu cầu read/write mỗi giây. Đây là lựa chọn được khuyến nghị cho lưu lượng từ ứng dụng không thể dự đoán và các bảng mới có workloads chưa biết. Đối với throughputs cao và dự đoán được, chế độ provisioned capacity cùng với DynamoDB auto scaling được khuyến nghị. Để biết thêm thông tin, xem “Chế độ capacity Read/Write“.
Đối với Amazon Kinesis Data Streams có throughput cao với nhiều consumers, xem xét việc sử dụng enhanced fan-out để cung cấp 2 MB/giây throughput trên mỗi consumer. Khi có thể, sử dụng Kinesis Producer Library và Kinesis Client Library để tổng hợp và tách record hiệu quả.
Amazon API Gateway hỗ trợ nhiều loại endpoint khác nhau. Edge-optimized APIs cung cấp một phân phối Amazon CloudFront được quản lý hoàn toàn. Đây là lựa chọn tốt hơn cho các client phân tán địa lý. Các yêu cầu API được định tuyến đến điểm gần nhất của Amazon CloudFront (POP), thường cải thiện thời gian kết nối.

Triển khai API Gateway được tối ưu hóa ở Edge
Regional API endpoints được dùng khi khách hàng ở cùng Region. Điều này giúp bạn giảm độ trễ yêu cầu và cho phép bạn thêm mạng phân phối nội dung của riêng mình nếu cần.

Triển khai API Gateway ở region endpoint
Private API endpoints là các API endpoint chỉ có thể truy cập từ Amazon Virtual Private Cloud (VPC) của bạn bằng cách sử dụng một interface VPC endpoint. Để biết thêm thông tin, xem “Tạo một private API trong Amazon API Gateway“.
Để biết thêm thông tin về các loại điểm cuối, xem “Chọn một loại endpint để thiết lập cho một API Gateway API“. Để biết thông tin tổng quan hơn về API Gateway, xem bài thuyết trình “Tôi không biết Amazon API Gateway có thể làm điều đó” trong sự kiện AWS re:Invent.
AWS Step Functions có hai loại workflow, loại standard và loại express. Các Standard Workflows có thực hiện workflow chính xác một lần và có thể chạy trong tối đa một năm. Các Express Workflows có thực hiện workflow ít nhất một lần và có thể chạy trong tối đa năm phút. Xem xét các tỷ lệ dựa trên số giây bạn cần cho cả tỷ lệ bắt đầu thực thi và tỷ lệ chuyển trạng thái. Để biết thêm thông tin, xem “Standard vs. Express Workflows“.
Việc thử nghiệm load testing được khuyến nghị ở cả tỷ lệ sustained và tỷ lệ burst để đánh giá tác động của việc điều chỉnh các đơn vị capacity units. Sử dụng dashboard dịch vụ Amazon CloudWatch để phân tích các performance metrics chính bao gồm cả kết quả load testing. Mình đề cập đến thử nghiệm hiệu suất chi tiết hơn trong “Điều chỉnh tỷ lệ inbound request – phần 1“.
Để biết thông tin tối ưu hóa serverless tổng quát, xem bài thuyết trình “Serverless khi scale: Mẫu thiết kế và tối ưu hóa” trong sự kiện AWS re:Invent.
Phần kết luận
Đánh giá và tối ưu hóa hiệu suất của ứng dụng serverless của bạn dựa trên các access patterns, cơ chế scaling và tích hợp native. Bạn có thể cải thiện trải nghiệm của mình và sử dụng nền tảng hiệu quả hơn cả về giá trị và tài nguyên.
Bài đăng này tiếp tục từ phần 1 và xem xét việc thiết kế hàm của bạn để tận dụng tính năng đồng thời thông qua các lệnh gọi dựa trên luồng và bất đồng bộ. Mình đã đề cập đến việc đo lường, đánh giá và lựa chọn các đơn vị công suất tối ưu.
Vấn đề well-architected này sẽ tiếp tục trong phần 3, nơi chúng ta xem xét việc tích hợp trực tiếp với các dịch vụ được quản lý qua các function khi có thể. Chúng ta sẽ đề cập đến việc tối ưu hóa các access patterns và áp dụng bộ nhớ đệm nếu có.
Để biết thêm tài liệu về serverless, hãy truy cập Serverless Land.
TAGS: serverless, well-architected

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}