Bởi Julian Wood | on 31 AUG 2021
Ngày 12 tháng 2 năm 2024: Amazon Kinesis Data Firehose được đổi tên thành Amazon Data Firehose. Đọc bài viết Có gì mới của AWS để tìm hiểu thêm.
Ngày 8 tháng 9 năm 2021: Amazon Elasticsearch Service được đổi tên thành Amazon OpenSearch Service. Xem chi tiết.
Loạt bài viết này sử dụng AWS Well-Architected Tool với Serverless Lens để hỗ trợ khách hàng xây dựng và vận hành ứng dụng bằng cách sử dụng các best practices. Trong mỗi bài viết, mình sẽ đề cập đến các câu hỏi cụ thể về serverless được xác định bởi Serverless Lens cùng với các best practices được đề xuất. Xem post này để biết thêm về việc xây dựng ứng dụng well-architected serverless.
PERF 1. Tối ưu hóa hiệu suất của ứng dụng serverless của bạn
Bài đăng này tiếp tục phần 2 của vấn đề bảo mật này. Trước đây, chúng ta đã xem xét việc thiết kế hàm để tận dụng tính năng đồng thời thông qua các lệnh gọi dựa trên luồng và bất đồng bộ. Chúng ta đã đề cập đến việc đo lường, đánh giá và lựa chọn các capacity units tối ưu.
Thực hành Cách thực hành tốt nhất: Tích hợp các dịch vụ được quản lý trực tiếp hơn là sử dụng các function
Hãy xem xét việc sử dụng native integrations giữa các dịch vụ quản lý thay vì sử dụng các hàm AWS Lambda khi không cần logic tùy chỉnh hoặc biến đổi dữ liệu. Điều này có thể giúp cải thiện hiệu suất tối ưu, yêu cầu ít tài nguyên để quản lý, và tăng cường bảo mật. Ngoài ra, cũng có một số application integration services của AWS cho phép giao tiếp giữa các thành phần decoupled với kiến trúc microservices.
Sử dụng services integration của native cloud
Khi sử dụng API Gateway của Amazon, bạn có thể sử dụng loại `AWS` integration để kết nối với các dịch vụ AWS khác một cách tự nhiên. Với loại integration này, API Gateway sử dụng Apache Velocity Template Language (VTL) và HTTPS để tích hợp trực tiếp với các dịch vụ AWS khác.
Thời gian chờ và lỗi phải được quản lý bởi API consumer. Để biết thêm thông tin về việc sử dụng VTL, xem “Tham chiếu Apache Velocity Template Language của Amazon API Gateway“. Để xem một ứng dụng ví dụ sử dụng API Gateway để đọc và ghi trực tiếp Amazon DynamoDB, xem “Xây dựng một ứng dụng serverless rút gọn URL không dùng AWS Lambda“.
Services integration trực tiếp API Gateway
Đã có hướng dẫn cho điều này, Xây dựng một API gateway REST API với AWS integration.
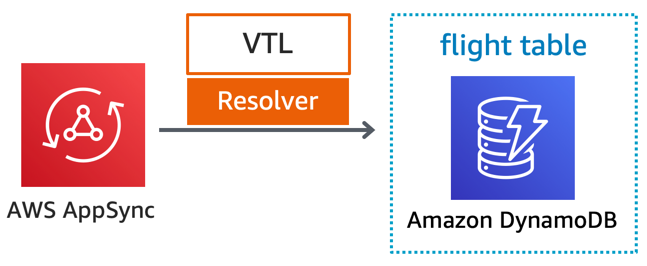
Khi sử dụng AWS AppSync, bạn có thể sử dụng VTL, tích hợp trực tiếp với Amazon Aurora, Amazon Elasticsearch Service, và bất kỳ HTTP endpoint công khai nào. AWS AppSync có thể sử dụng nhiều loại tích hợp và có thể tối đa hóa lưu lượng tại data field level. Ví dụ, bạn có thể chạy tìm kiếm full-text trên trường `orderDescription` trên Elasticsearch trong khi lấy dữ liệu còn lại từ DynamoDB. Để biết thêm thông tin, xem các hướng dẫn giải quyết vấn đề tại AWS AppSync.
Trong ví dụ của serverless airline được sử dụng trong loạt bài viết này, dịch vụ catalog sử dụng AWS AppSync để cung cấp một API GraphQL để tìm kiếm chuyến bay. AWS AppSync sử dụng DynamoDB như một cơ sở dữ liệu, và tất cả logic tính toán được chứa trong Apache Velocity Template (VTL).

Dịch vụ catalog của serverless airline sử dụng VTL
AWS Step Functions tích hợp với nhiều dịch vụ AWS bằng cách sử dụng service Integrations. Ví dụ, điều này cho phép bạn truy xuất và đưa dữ liệu vào DynamoDB, hoặc chạy một AWS Batch job. Bạn cũng có thể publish messages đến các chủ đề Amazon Simple Notification Service (SNS), và gửi messages đến hàng đợi Amazon Simple Queue Service (SQS). Để biết thêm chi tiết về các tích hợp có sẵn, xem “Sử dụng AWS Step Functions với các dịch vụ khác“.
Sử dụng Amazon EventBridge, bạn có thể kết nối ứng dụng của mình với dữ liệu từ nhiều nguồn khác nhau. Bạn có thể kết nối với các dịch vụ AWS khác nhau một cách tự nhiên và hoạt động như một bus sự kiện trên nhiều tài khoản AWS để dễ dàng tích hợp. Bạn cũng có thể sử dụng tính năng API destination để định tuyến sự kiện đến các dịch vụ bên ngoài của AWS. EventBridge xử lý xác thực, thử lại và lưu lượng thông tin. Để biết thêm chi tiết về các EventBridge targets có sẵn, xem tài liệu.

Amazon EventBridge
Thực hành tốt Good practice: Tối ưu hóa các access patterns và áp dụng bộ nhớ đệm nếu có
Hãy xem xét việc lưu trữ cache khi các khách hàng có thể không cần dữ liệu mới nhất. Tối ưu hóa các access patterns để chỉ truy xuất dữ liệu cần thiết với cho người dùng cuối. Điều này cải thiện khả năng phản hồi workload của bạn và tận dụng hiệu quả hơn các tài nguyên tính toán và dữ liệu trên các components.
Triển khai bộ nhớ đệm (caching) cho các access patterns phù hợp
Đối với các API REST, bạn có thể sử dụng lưu trữ cache của API Gateway để giảm số lần gọi số lượng cuộc gọi đến endpoint điểm cuối của bạn và cải thiện độ trễ của các yêu cầu đến API của bạn. Khi bạn kích hoạt lưu trữ cache cho một stage hoặc method, API Gateway sẽ caches responses trong một khoảng time-to-live (TTL) chỉ định. Sau đó, API Gateway phản hồi yêu cầu bằng cách tra cứu phản hồi của endpoint từ bộ nhớ cache, thay vì thực hiện một yêu cầu đến endpoint của bạn.

API Gateway caching
Để biết thêm thông tin, xem “Kích hoạt API caching để tăng khả năng phản hồi“.
Đối với các client được phân tán theo địa lý, Amazon CloudFront hoặc CDN bên thứ ba của bạn có thể lưu trữ kết quả tại các đỉnh và giảm thêm độ trễ của vòng tròn mạng.
Đối với các API GraphQL, AWS AppSync cung cấp tính caching tích hợp sẵn ở mức API. Điều này làm giảm việc cần phải truy cập trực tiếp vào các nguồn dữ liệu bằng cách làm cho dữ liệu có sẵn trong bộ nhớ cache tốc độ cao. Điều này cải thiện hiệu suất và giảm độ trễ. Đối với các truy vấn có các đối số phổ biến hoặc một tập hợp hạn chế các đối số, bạn cũng có thể kích hoạt caching ở resolver level để cải thiện khả năng phản hồi tổng thể. Để biết thêm thông tin, xem “Cải thiện hiệu suất và tính nhất quán của GraphQL API với AWS AppSync Caching“.
Khi sử dụng cơ sở dữ liệu, lưu kết quả vào bộ đệm và chỉ kết nối cũng như tìm nạp dữ liệu khi cần. Điều này giảm tải trên cơ sở dữ liệu phía dưới và cải thiện hiệu suất. Bao gồm cơ chế hết hạn bộ nhớ đệm để ngăn chặn việc cung cấp các bản ghi cũ. Để biết thêm thông tin về patterns và xem xét về triển khai lưu trữ cache, xem “Caching Best Practices”.
Đối với DynamoDB, bạn có thể kích hoạt caching với Amazon DynamoDB Accelerator (DAX). DAX cho phép bạn tận dụng hiệu suất đọc nhanh trong bộ nhớ trong vài micro giây, thay vì mili giây. DAX thích hợp cho các trường hợp sử dụng có thể không yêu cầu đọc nhất quán cao. Một số ví dụ bao gồm đặt giá thầu theo thời gian thực, trò chơi xã hội và ứng dụng giao dịch. Để biết thêm thông tin, đọc “Các trường hợp sử dụng cho DAX“.
Đối với mục đích caching chung, Amazon ElastiCache cung cấp một môi trường lưu trữ cache dữ liệu hoặc cache phân tán trong bộ nhớ. ElastiCache hỗ trợ nhiều caching patterns thông qua key-value stores sử dụng các bộ máy chủ Redis và Memcache. Xác định cái gì an toàn để được caching, ngay cả khi sử dụng các caching patterns phổ biến như `lazy caching` hoặc `write-through`. Đặt một TTL và chính sách trục xuất phù hợp với hiệu suất cơ bản và các access patterns của bạn. Điều này đảm bảo rằng bạn không cung cấp các record cũ hoặc dữ liệu cache, khi cần có kết quả đọc nhất quán. Để biết thêm thông tin về ElastiCache Caching và các chiến lược time-to-live, xem tài liệu.
Đối với các gợi ý về serverless caching bổ sung, xem bài đăng trên blog AWS Serverless Hero “Tất cả những gì bạn cần biết về lưu trữ cache cho ứng dụng serverless“.
Giảm việc lấy dữ liệu quá nhiều (overfetching) và lấy dữ liệu quá ít (underfetching)
Việc lấy dữ liệu quá nhiều là khi một client tải xuống quá nhiều dữ liệu từ cơ sở dữ liệu hoặc endpoint. Điều này dẫn đến dữ liệu trong phản hồi có thể bạn sẽ không sử dụng. Với việc lấy dữ liệu quá ít là khi không có đủ dữ liệu trong phản hồi. Sau đó, khách hàng cần thực hiện các yêu cầu bổ sung để lấy thêm dữ liệu. Việc lấy dữ liệu quá nhiều và quá ít đều có thể ảnh hưởng đến hiệu suất.
Để lấy một collection các mục từ DynamoDB table, bạn có thể thực hiện một truy vấn hoặc quét. Một hoạt động quét luôn quét toàn bộ table hoặc secondary index. Sau đó, nó lọc ra các giá trị để cung cấp kết quả bạn muốn, về cơ bản là thêm một bước thêm dữ liệu vào bộ kết quả. Một hoạt động truy vấn tìm các mục trực tiếp dựa trên các giá trị khóa chính.
Để có thời gian phản hồi nhanh hơn, thiết kế table và indexes của bạn sao cho ứng dụng của bạn có thể sử dụng truy vấn thay vì quét. Sử dụng cả Global Secondary Index (GSI) cùng với các khóa sắp xếp hợp thành để giúp bạn truy vấn các mối quan hệ phân cấp trong dữ liệu của bạn. Để biết thêm thông tin, hãy xem “Best Practices cho Việc Truy Vấn và Quét Dữ Liệu“.
Hãy xem xét GraphQL và AWS AppSync cho các ứng dụng web tương tác, mobile, real-time hoặc cho các trường hợp sử dụng trong đó dữ liệu điều khiển giao diện người dùng. AWS AppSync cung cấp tính linh hoạt trong việc lấy dữ liệu, cho phép khách hàng của bạn chỉ truy vấn dữ liệu mà nó cần, trong định dạng mà nó cần. Đảm bảo bạn không thực hiện quá nhiều truy vấn lồng nhau nơi một phản hồi dài có thể dẫn đến timeouts. GraphQL giúp bạn điều chỉnh các access patterns khi workload của bạn tiến triển. Điều này làm cho nó linh hoạt hơn khi cho phép bạn chuyển sang các cơ sở dữ liệu được xây dựng cho mục đích cụ thể nếu cần thiết.
Nén payload và lưu trữ dữ liệu
Một số dịch vụ của AWS cho phép bạn nén payload hoặc nén data storage. Điều này có thể cải thiện hiệu suất bằng cách gửi và nhận ít dữ liệu hơn, và có thể tiết kiệm lưu trữ dữ liệu, từ đó giảm chi phí.
Nếu nội dung của bạn hỗ trợ mã hóa deflate, gzip hoặc identity, API Gateway cho phép client của bạn gọi API với payload đã được nén. Theo mặc định, API Gateway hỗ trợ giải nén request payload. Tuy nhiên, bạn phải cấu hình API của mình để kích hoạt nén response payload . Nén ở API Gateway và giải nén ở client có thể tăng thêm độ trễ tổng thể và đòi hỏi thời gian tính toán nhiều hơn. Chạy một vài kiểm thử đối với API của bạn để xác định giá trị tối ưu. Để biết thêm thông tin, xem “Kích hoạt nén payload cho một API“.
Amazon Kinesis Data Firehose hỗ trợ nén dữ liệu streaming bằng gzip, snappy hoặc zip. Điều này giảm thiểu lượng lưu trữ được sử dụng tại destination. Các câu hỏi thường gặp về Amazon Kinesis Data Firehose thường có thêm thông tin về nén. Kinesis Data Firehose cũng hỗ trợ chuyển đổi dữ liệu streaming của bạn từ JSON sang Apache Parquet hoặc Apache ORC trước khi lưu trữ dữ liệu trong Amazon S3. Parquet và ORC là định dạng columnar data giảm không gian và cho phép các truy vấn nhanh hơn so với các định dạng row-oriented như JSON.
Phần kết luận
Đánh giá và tối ưu hóa hiệu suất của ứng dụng serverless của bạn dựa trên các access patterns, cơ chế scaling và tích hợp native. Bạn có thể cải thiện trải nghiệm tổng thể của mình và sử dụng nền tảng hiệu quả hơn cả về giá trị và tài nguyên.
Trong phần 1: Chúng ta đã đề cập đến việc đo lường và tối ưu hóa thời gian khởi động function. Mình đã giải thích cách cold start và warm start cũng như cách sử dụng lại môi trường thực thi Lambda để cải thiện hiệu suất. Mình cũng đã giải thích cách import các libraries và dependencies cần thiết sẽ tăng hiệu suất ứng dụng.
Trong phần 2: Mình xem xét việc thiết kế function để tận dụng tính năng đồng thời thông qua các lệnh gọi dựa trên luồng và bất đồng bộ. Mình cũng đã đề cập đến việc đo lường, đánh giá và lựa chọn các capacity units tối ưu.
Trong bài đăng này, chúng ta đã xem xét việc tích hợp trực tiếp với các dịch vụ được quản lý qua các function khi có thể. Mình cũng đã đề cập đến việc tối ưu hóa các access patterns và áp dụng bộ nhớ đệm nếu có.
Trong bài đăng tiếp theo của loạt bài viết này, chúng ta sẽ đề cập đến cost optimization pillar từ Well-Architected Serverless Lens.
Để biết thêm tài liệu về serverless, hãy truy cập Serverless Land.
TAGS: serverless, well-architected

{kind=link}
{kind=link}
{kind=link}
{kind=link}