Tác giả: Anuj Patel và Domen Jemec
Ngày đăng: 02 tháng 04 năm 2025
Danh mục: Amazon Aurora, Amazon DynamoDB, Amazon EventBridge, Amazon Simple Storage Service (S3), AWS HealthImaging, AWS HealthLake, AWS HealthOmics, Healthcare, Industries Permalink
Các tổ chức khoa học đời sống và chăm sóc sức khỏe (HCLS) đang tạo ra nhiều dữ liệu hơn bao giờ hết khi họ tích hợp dữ liệu phân tử (molecular data) vào quá trình khám phá thuốc, phát triển lâm sàng, chẩn đoán phân tử và phân tích sức khỏe dân số. Do lượng dữ liệu lớn, khách hàng đang tìm kiếm kho lưu trữ tiết kiệm chi phí được tổ chức tốt, hỗ trợ khám phá và tích hợp dễ dàng vào hệ sinh thái phân tích của họ. Khách hàng cũng muốn tổng hợp siêu dữ liệu về các tệp được lưu trữ thành định dạng có thể truy vấn để hỗ trợ các công cụ khám phá và phân nhóm dữ liệu của họ.
Amazon Web Services (AWS) HealthOmics là một dịch vụ được quản lý tập trung vào việc đẩy nhanh các đột phá khoa học với các kho dữ liệu sinh học và quy trình làm việc được quản lý hoàn toàn. Các kho lưu trữ được quản lý của HealthOmics được xây dựng có mục đích để sắp xếp và gán nhãn (annotate) cho các file dữ liệu phân tử nhằm tăng cường khả năng khám phá (discoverability). Chúng cũng giúp các tệp có thể truy cập thông qua API của Amazon Simple Storage Service (Amazon S3) để enable seamless integration vào hệ sinh thái phân tích của người dùng. Điều này được kết hợp với phân tầng theo mức sử dụng và nén để giúp thúc đẩy cost savings bổ sung . Vì tất cả các khả năng này đều có sẵn được xây dựng sẵn với HealthOmics, nên khách hàng đã áp dụng các kho lưu trữ được xây dựng có mục đích cho bộ lưu trữ dữ liệu phân tử của họ.
Chúng tôi đã lắng nghe khách hàng về cách họ muốn truy vấn trên siêu dữ liệu để cung cấp năng lượng cho các công cụ khám phá và nhóm của họ. Các công cụ này được xây dựng để tích hợp với cơ sở dữ liệu nhằm hỗ trợ tổng hợp siêu dữ liệu từ nhiều nguồn và truy vấn dựa trên bất kỳ phần siêu dữ liệu nào có sẵn. Một dịch vụ mà họ áp dụng để cung cấp năng lượng cho các công cụ này là Amazon DynamoDB , một dịch vụ cơ sở dữ liệu NoSQL được quản lý hoàn toàn, không cần máy chủ.
Chúng tôi sẽ trình bày một khuôn khổ giúp sao chép (mirror) siêu dữ liệu từ sequence store sang một bảng Amazon DynamoDB. Điều này cho phép khách hàng sử dụng sức mạnh của DynamoDB để xác định động nhóm của họ nhằm khám phá nhanh dữ liệu được lưu trữ trên tất cả các kho lưu trữ chuỗi trong một vùng.
Nhu cầu về siêu dữ liệu có thể khám phá
Các tổ chức HCLS đang sử dụng các kỹ thuật phòng thí nghiệm tiên tiến, thông lượng cao để quan sát các tương tác tế bào với mục tiêu khám phá các liệu pháp mới và cải thiện sức khỏe con người. Dữ liệu được tạo ra bởi các kỹ thuật này chỉ hữu ích cho tổ chức nếu có thể khám phá được. Là một phần của ngăn xếp lưu trữ, nhiều tổ chức HCLS đã kết hợp kho lưu trữ trình tự AWS HealthOmics. Các Sequence store lưu trữ đối tượng và siêu dữ liệu dưới dạng các read set. Siêu dữ liệu của read set bao gồm ID chủ thể, ID mẫu, nguồn gốc, mối quan hệ đối tượng và thông tin khác về các đối tượng.
Trong khi HealthOmics có API để tìm các tập dữ liệu quan tâm, một số người dùng bày tỏ nhu cầu về khả năng truy vấn và lọc dữ liệu phong phú hơn trên siêu dữ liệu. Ngoài ra, người dùng đã yêu cầu các bảng cơ sở dữ liệu bao gồm siêu dữ liệu, do đó thông tin có thể nhanh chóng được tích hợp với các hồ dữ liệu có cấu trúc rộng hơn thường là về mẫu và chủ thể.
Những thách thức này làm giảm năng suất và gia tăng chi phí vận hành và tăng chi phí hoạt động, với các tổ chức báo cáo lên đến 60 percent of researcher’s time spent on cleaning and organizing data và sự chậm trễ trung bình 2-3 tuần trong việc bắt đầu các dự án nghiên cứu mới do các vấn đề về khả năng truy cập dữ liệu. Một giải pháp đồng bộ hóa siêu dữ liệu tự động trở nên quan trọng đối với các tổ chức quản lý quy trình làm việc dữ liệu bộ gen quy mô lớn.
Chúng tôi trình bày một giải pháp không cần máy chủ, tiết kiệm chi phí, tự động đồng bộ hóa siêu dữ liệu lưu trữ chuỗi AWS HealthOmics vào bảng Amazon DynamoDB. Việc trích xuất siêu dữ liệu trong bảng DynamoDB cho phép truy vấn với thời gian phản hồi dưới một giây, bất kể khối lượng dữ liệu. Giải pháp này cải thiện khả năng truy cập dữ liệu thông qua các lệnh gọi API được sắp xếp hợp lý và duy trì các bản cập nhật siêu dữ liệu gần như theo thời gian thực. Điều này đảm bảo rằng các nhà nghiên cứu có thể truy cập ngay lập tức vào thông tin mẫu quan trọng, giảm thời gian bắt đầu dự án từ nhiều tuần xuống còn nhiều giờ, đồng thời duy trì chi phí vận hành tối thiểu thông qua đồng bộ hóa tự động.
Cách truy vấn metadata của HealthOmics read set bằng Amazon DynamoDB
Giải pháp này giả định rằng bạn có tài khoản AWS với các quyền phù hợp, kho lưu trữ trình tự AWS HealthOmics hiện có và hiểu biết cơ bản về các dịch vụ và API của AWS.
Các thành phần chính của giải pháp bao gồm:
- Amazon EventBridge để ghi lại các sự kiện thay đổi trạng thái tập đọc
- Dịch vụ hàng đợi đơn giản của Amazon ( Amazon SQS ) cung cấp khả năng đệm sự kiện và thử lại đáng tin cậy
- AWS Lambda để xử lý sự kiện và cập nhật siêu dữ liệu
- Amazon DynamoDB để lưu trữ siêu dữ liệu có thể truy vấn
Hình sau đây cung cấp cái nhìn tổng quan về giải pháp.
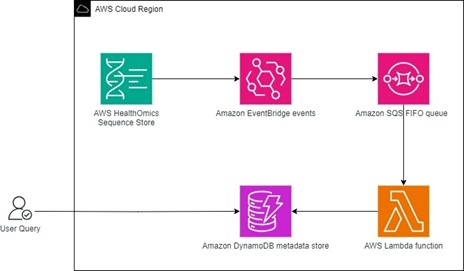
Hình 1: Kiến trúc giải pháp cho giải pháp đồng bộ hóa siêu dữ liệu lưu trữ chuỗi AWS HealthOmics
Giải pháp này hoạt động như sau.
1. Kho lưu trữ chuỗi AWS HealthOmics tạo ra read set status update events.
2. Quy tắc Amazon EventBridge định tuyến sự kiện đến hàng đợi FIFO của Amazon SQS. Hàng đợi FIFO ưu tiên thứ tự tin nhắn và xác nhận khả năng mở rộng, xử lý chính xác một lần.
3. Chức năng AWS Lambda xử lý các sự kiện dựa trên trạng thái:
- HOẠT ĐỘNG: Làm mới toàn bộ siêu dữ liệu của tập dữ liệu đã đọc.
- ĐANG KÍCH HOẠT/LƯU TRỮ/XÓA: Cập nhật trạng thái và dấu thời gian của bộ dữ liệu đã đọc.
- ĐÃ XÓA: Xóa mục nhập của tập hợp đã đọc.
- Mọi trạng thái khác đều bị bỏ qua.
4. Amazon DynamoDB duy trì trạng thái hiện tại của tất cả siêu dữ liệu trên tất cả các kho lưu trữ trình tự trong một vùng ở cấp độ tập hợp đọc.
Giải pháp mẫu và các chi tiết kỹ thuật bổ sung có sẵn dưới dạng open-source CDK application. Giải pháp này cũng bao gồm các tùy chọn triển khai linh hoạt và một tập lệnh tiện ích để điền trước thông tin read set hiện có vào bảng dynamo.
Những cân nhắc bổ sung cho giải pháp
1. Giới hạn API:
Giải pháp dựa vào việc gọi các API GetReadSetMetadata , ListTagsForResource và GetSequenceStore để xây dựng siêu dữ liệu tập đọc. Nếu bạn gặp phải tình trạng giới hạn hàm Lambda, có thể yêu cầu tăng giới hạn dịch vụ thông qua support request.
2. Tối ưu hóa hiệu suất:
- Đặt thời gian chờ hiển thị phù hợp cho hàng đợi Amazon SQS của bạn. Thời gian này phải dài hơn thời gian chờ Lambda của bạn.
- Sử dụng Amazon SQS batching, tối đa 10 sự kiện, cho mỗi lần gọi Lambda để tối ưu hóa nhu cầu tính toán.
- DynamoDB theo yêu cầu cung cấp trải nghiệm cơ sở dữ liệu thực sự không cần máy chủ, tự động mở rộng để đáp ứng nhu cầu đọc/ghi khắt khe mà không cần lập kế hoạch dung lượng. Hãy cân nhắc chiến lược lấp đầy hiệu quả cho dữ liệu hiện có trong kho lưu trữ chuỗi AWS HealthOmics của bạn.
3. Cân nhắc về chi phí:
Vì giải pháp này tận dụng kiến trúc không máy chủ, nên khách hàng chỉ trả tiền cho những gì họ sử dụng mà không cần cam kết trước. Chi phí được liên kết trực tiếp với mức sử dụng thực tế: Phí DynamoDB dựa trên mức tiêu thụ dung lượng lưu trữ và hoạt động đọc/ghi (có thể lựa chọn dung lượng theo yêu cầu hoặc được cung cấp). Giá của Amazon SQS phụ thuộc vào số lượng yêu cầu API và lưu giữ tin nhắn. Chi phí của AWS Lambda được tính cho mọi lần gọi và thời gian tính toán (tính bằng mili giây), dựa trên bộ nhớ được phân bổ. Tất cả các dịch vụ đều bao gồm một tầng miễn phí và có thể áp dụng thêm phí cho việc truyền dữ liệu, các tính năng nâng cao hoặc hoạt động liên vùng. Kiểm tra AWS pricing page.
4. Cân nhắc về siêu dữ liệu:
Nếu tập lệnh điền lại được chạy và một tập hợp đọc được lưu trữ, thông tin tệp sẽ không được điền vào. Thông tin tệp sẽ chỉ khả dụng sau khi tập hợp đọc được kích hoạt.
5. Cân nhắc về thiết kế:
Đối với việc khám phá dữ liệu đa phương thức trên dữ liệu được lưu trữ trong AWS HealthOmics, AWS HealthLake, AWS HealthImaging và Amazon storage services, hãy cân nhắc sử dụng giải pháp Multi-Modal Data Analysis with AWS Health and machine learning (ML) Services.
Amazon DynamoDB là dịch vụ cơ sở dữ liệu NoSQL được quản lý hoàn toàn. Tuy nhiên, đối với khối lượng công việc đòi hỏi chức năng cơ sở dữ liệu quan hệ và SQL, hãy khám phá các dịch vụ AWS khác như Amazon Aurora, Amazon Relational Database Service (Amazon RDS) hoặc các dịch vụ cơ sở dữ liệu thay thế phù hợp hơn với yêu cầu của bạn.
Phần kết luận
Chúng tôi đã chứng minh giải pháp đồng bộ hóa siêu dữ liệu có khả năng mở rộng và không cần máy chủ này mang lại khả năng tìm kiếm và truy cập dữ liệu được cải thiện như thế nào. Tất cả những điều này được thực hiện thông qua các truy vấn API được sắp xếp hợp lý đối với bảng Amazon DynamoDB, với các bản cập nhật siêu dữ liệu gần như theo thời gian thực, cho các tập hợp đọc lưu trữ chuỗi AWS HealthOmics. Để bắt đầu với giải pháp, hãy truy cập AWS Sample HealthOmics metadata sync GitHub.
Truy cập AWS HealthOmics hoặc AWS for Healthcare & Life Sciences để tìm hiểu thêm. Liên hệ với AWS Representative để biết cách chúng tôi có thể giúp thúc đẩy doanh nghiệp của bạn.
Đọc thêm
- Hướng dẫn phân tích dữ liệu đa phương thức với AWS Health và ML Services
- Đào tạo trước các mô hình ngôn ngữ bộ gen bằng AWS HealthOmics và Amazon SageMaker
- Tăng tốc khám phá thuốc với AWS HealthOmics và NVIDIA Blueprints
- Mở rộng quy mô hoạt động chẩn đoán lâm sàng: Đổi mới bộ gen của Natera
- Merck cải thiện thiết kế thuốc bằng các mô hình nền tảng sinh học như thế nào
Về tác giả

Anuj Patel
Anuj Patel là Senior Solutions Architect tại AWS. Anh có bằng Thạc sĩ Khoa học Máy tính và hơn 2 thập kỷ kinh nghiệm trong thiết kế và phát triển phần mềm. Anh giúp đỡ các khách hàng trong ngành Khoa học Đời sống trong hành trình AWS của họ. Đam mê của anh nằm ở việc đơn giản hóa các vấn đề phức tạp, giúp khách hàng khai phá toàn bộ tiềm năng của các giải pháp AWS.

Domen Jemec
Domen Jemec là Senior Product Manager cho AWS HealthOmics. Anh chịu trách nhiệm lắng nghe khách hàng, xác định yêu cầu và đảm bảo rằng Amazon Web Services (AWS) giúp khách hàng thúc đẩy khám phá khoa học và y học chính xác. Domen có hơn 10 năm kinh nghiệm cung cấp các giải pháp kỹ thuật và machine learning trên nhiều ngành công nghiệp bao gồm Công nghệ Sinh học, Khoa học Đời sống, Chăm sóc Sức khỏe, Dược phẩm và Thiết bị Y tế. Anh cũng tiếp tục theo đuổi nghiên cứu tại giao điểm của sinh học tính toán và machine learning.
