Tác giả: Philipp Karg, Cizer Pereira và Selman Ay
Ngày đăng: ngày 29 tháng 4, 2025
Danh mục: Amazon Athena, Amazon QuickSight, Analytics, Customer Solutions
Bài đăng này được viết dưới sự hợp tác của Philipp Karg từ BMW Group.
Trong bối cảnh doanh nghiệp ngày càng đòi hỏi các kiến trúc có khả năng mở rộng linh hoạt và tối ưu chi phí để xử lý và chuyển đổi các bộ dữ liệu lớn, đội Cloud Efficiency Analytics (CLEA) tại BMW Group đã phát triển giải pháp FinOps nhằm tối ưu chi phí cho hơn 10.000 tài khoản đám mây. Trong khi mang lại hiệu quả toàn tổ chức, nhóm cũng áp dụng những nguyên tắc tiết kiệm này vào chính kiến trúc dữ liệu của mình, đảm bảo CLEA vận hành một cách “tiết kiệm” nhất. Sau khi đánh giá nhiều công cụ, họ đã xây dựng pipeline biến đổi dữ liệu không máy chủ (serverless) sử dụng Amazon Athena và dbt.
Bài đăng này khám phá hành trình của chúng tôi, từ những thách thức ban đầu đến kiến trúc hiện tại của chúng tôi, và chi tiết về các bước chúng tôi đã thực hiện để đạt được thiết lập chuyển đổi dữ liệu không có máy chủ hiệu quả cao.
Thách thức: Bắt đầu từ một thiết lập cứng nhắc và tốn kém
Trong giai đoạn đầu, chúng tôi đã gặp phải một số bất cập khiến việc mở rộng gặp rất nhiều khó khăn. Chúng tôi phải quản lý các lược đồ phức tạp với những bảng có rất nhiều cột, đòi hỏi nỗ lực đáng kể để bảo trì. Ban đầu, chúng tôi sử dụng Terraform để tạo các bảng và view trong Athena, cho phép quản lý hạ tầng dữ liệu dưới dạng mã (IaC) và tự động hóa triển khai qua các pipeline CI/CD. Tuy nhiên, phương pháp này làm chậm tiến độ mỗi khi thay đổi mô hình dữ liệu hoặc xử lý các thay đổi schema, dẫn đến chi phí phát triển rất cao.
Khi giải pháp của chúng tôi phát triển, hiệu năng truy vấn và chi phí trở thành thách thức lớn. Mỗi truy vấn đều phải quét một khối lượng lớn dữ liệu thô, làm tăng thời gian xử lý và chi phí Athena. Chúng tôi dùng các view để tạo ra một lớp trừu tượng (abstraction layer) rõ ràng, nhưng điều này lại che giấu đi sự phức tạp bên dưới: những truy vấn tưởng chừng đơn giản trên view lại phải quét toàn bộ dữ liệu, trong khi chiến lược phân vùng chưa được tối ưu cho các mẫu truy cập đó. Khi kích thước và số lượng cột của bộ dữ liệu tăng lên, việc thiếu tính mô-đun trong thiết kế dữ liệu càng làm gia tăng độ phức tạp, khiến việc mở rộng và bảo trì trở nên ngày càng khó khăn. Chúng tôi cần một giải pháp để tổng hợp trước, tính toán và lưu trữ kết quả của những phép biến đổi tốn tài nguyên. Đồng thời, việc thiếu các giải pháp kiểm thử và theo dõi dòng dữ liệu (data lineage) mạnh mẽ khiến việc xác định nguyên nhân gốc rễ của các sự thiếu nhất quán trong dữ liệu trở nên đầy thách thức.
Trong phần giải pháp BI, chúng tôi sử dụng Amazon QuickSight để xây dựng dashboard, mang lại cái nhìn trực quan về dữ liệu chi phí đám mây. Tuy nhiên, kiến trúc dữ liệu ban đầu đã gây ra nhiều vấn đề. Chúng tôi xây dựng dashboard trên các bộ dữ liệu lớn, nhiều cột, trong đó có những bộ đã chạm giới hạn SPICE 1 TB cho mỗi dataset. Thêm vào đó, khi nạp dữ liệu lên SPICE, những dataset lớn nhất mất đến 4–5 giờ xử lý vì phải quét toàn bộ dữ liệu-thường trên một terabyte mỗi lần. Kiến trúc này không giúp chúng tôi linh hoạt và nhanh nhẹn hơn khi cần mở rộng. Thời gian xử lý kéo dài và hạn chế về lưu trữ đã cản trở khả năng cung cấp insight kịp thời và mở rộng năng lực phân tích.
Để khắc phục, chúng tôi đã nâng cấp kiến trúc dữ liệu bằng cách kết hợp AWS Lambda, AWS Step Functions, AWS Glue và dbt. Bộ công cụ này đã gia tăng mạnh mẽ tính nhanh nhẹn trong phát triển, cho phép chúng tôi nhanh chóng điều chỉnh và đưa vào sử dụng các mô hình dữ liệu mới. Đồng thời, chúng tôi cải thiện hiệu quả xử lý dữ liệu tổng thể nhờ chiến lược nạp gia tăng (incremental loads) và quản lý schema tốt hơn.
Tổng quan giải pháp
Kiến trúc hiện tại của chúng tôi bao gồm một pipeline không máy chủ (serverless) và mô-đun, được điều phối bởi các workflow trên GitHub Actions. Chúng tôi chọn Athena làm engine truy vấn chính vì những lý do chiến lược sau: nó hoàn toàn phù hợp với chuyên môn SQL của đội, xuất sắc trong việc truy vấn trực tiếp dữ liệu Parquet ngay trong data lake, và loại bỏ nhu cầu về tài nguyên compute riêng. Điều này khiến Athena trở thành lựa chọn lý tưởng cho kiến trúc CLEA, nơi chúng tôi xử lý khoảng 300 GB dữ liệu mỗi ngày từ một data lake 15 TB, với bộ dữ liệu lớn nhất chứa 50 tỷ dòng và lên đến 400 cột. Khả năng của Athena trong việc truy vấn hiệu quả dữ liệu Parquet quy mô lớn, kết hợp với đặc tính serverless, cho phép chúng tôi tập trung vào viết các phép biến đổi tối ưu thay vì quản lý hạ tầng.
Sơ đồ sau đây minh họa kiến trúc giải pháp.

Sử dụng kiến trúc này, chúng tôi đã tinh gọn quy trình biến đổi dữ liệu bằng dbt. Trong dbt, một data model đại diện cho một phép biến đổi SQL đơn lẻ tạo ra hoặc một table hoặc một view-về cơ bản là một building block của pipeline biến đổi dữ liệu của chúng tôi. Việc triển khai của chúng tôi bao gồm khoảng 400 model như vậy, 50 data source và khoảng 100 data test. Cấu hình này cho phép cập nhật liền mạch-dù là tạo model mới, cập nhật schema hay sửa đổi view-chỉ cần tạo một pull request trong kho mã nguồn của chúng tôi, phần còn lại được xử lý tự động.
Quy trình tự động hóa của chúng tôi bao gồm các tính năng sau:
- Pull request – Khi chúng tôi tạo một pull request, nó được triển khai lên môi trường testing trước. Sau khi vượt qua bước validation và được approved hoặc merged, nó được triển khai lên production thông qua GitHub workflows. Thiết lập này cho phép tạo model, cập nhật schema hoặc thay đổi view một cách liền mạch-được kích hoạt chỉ bằng việc tạo pull request, phần còn lại tự động xử lý.
- Cron scheduler – Để chạy hàng đêm hoặc nhiều lần trong ngày nhằm giảm độ trễ dữ liệu, chúng tôi sử dụng scheduled GitHub workflows. Thiết lập này cho phép chúng tôi cấu hình các model cụ thể với các chiến lược cập nhật khác nhau dựa trên nhu cầu dữ liệu. Chúng tôi có thể thiết lập các model cập nhật theo kiểu gia tăng (incrementally) (chỉ xử lý dữ liệu mới hoặc đã thay đổi), dưới dạng view (truy vấn mà không cần hiện thực hóa – materializing dữ liệu), hoặc tải toàn bộ (full loads) (làm mới hoàn toàn dữ liệu). Sự linh hoạt này tối ưu thời gian xử lý và sử dụng tài nguyên. Chúng tôi có thể chỉ nhắm vào các thư mục cụ thể-như source, prepared hoặc semantic layers—và chạy dbt test sau đó để validate chất lượng model.
- On demand – Khi thêm cột mới hoặc thay đổi business logic, chúng tôi cần cập nhật dữ liệu lịch sử để duy trì tính nhất quán. Để làm việc này, chúng tôi sử dụng một quy trình điền ngược dữ liệu (backfill), vốn là một GitHub workflow tùy chỉnh do đội ngũ của chúng tôi tạo ra. Workflow cho phép chúng tôi chọn các model cụ thể, bao gồm cả upstream dependencies, và đặt các tham số như start và end dates. Điều này đảm bảo rằng các thay đổi được áp dụng chính xác trên toàn bộ tập dữ liệu lịch sử, duy trì tính nhất quán và integrity của dữ liệu.
Pipeline của chúng tôi được tổ chức thành ba giai đoạn chính-Source, Prepared và Semantic-mỗi giai đoạn phục vụ một mục đích cụ thể trong hành trình biến đổi dữ liệu. Giai đoạn Source giữ dữ liệu thô ở dạng nguyên thủy. Giai đoạn Prepared làm sạch và chuẩn hóa dữ liệu, xử lý các tác vụ như deduplication và data type conversions. Giai đoạn Semantic biến đổi dữ liệu đã chuẩn hóa thành các model sẵn sàng cho phân tích nghiệp vụ. Một bước QuickSight bổ sung xử lý các yêu cầu trực quan hóa. Để đạt được chi phí thấp và hiệu năng cao, chúng tôi sử dụng dbt models và SQL code để quản lý tất cả các phép biến đổi và thay đổi schema. Bằng cách triển khai các chiến lược incremental processing, các model của chúng tôi chỉ xử lý dữ liệu mới hoặc đã thay đổi thay vì tái xử lý toàn bộ dataset mỗi lần chạy.
Giai đoạn Semantic (không nhầm lẫn với tính năng semantic layer của dbt) giới thiệu business logic, biến dữ liệu thành các aggregated dataset có thể tiêu thụ trực tiếp bởi BMW’s Cloud Data Hub, internal CLEA dashboards, data APIs hoặc In-Console Cloud Assistant (ICCA) chatbot. Bước QuickSight tối ưu hóa dữ liệu hơn nữa bằng cách chỉ chọn các cột cần thiết thông qua một giải pháp column-level lineage và thiết lập dynamic date filter với sliding window để ingest chỉ dữ liệu “hot” liên quan vào SPICE, tránh dữ liệu không dùng trong dashboards hoặc reports.
Cách tiếp cận này phù hợp với chiến lược dữ liệu rộng hơn của BMW Group, bao gồm việc đơn giản hóa truy cập dữ liệu bằng AWS Lake Formation để kiểm soát truy cập chi tiết.
Nhìn chung chúng tôi đã tự động hóa hoàn toàn việc thay đổi schema, cập nhật dữ liệu và kiểm thử thông qua GitHub pull requests và lệnh dbt. Cách tiếp cận này cho phép triển khai có kiểm soát với version control mạnh mẽ và change management. Các workflow kiểm thử và giám sát liên tục đảm bảo tính chính xác, độ tin cậy và chất lượng dữ liệu qua các phép biến đổi, hỗ trợ việc lặp lại model hiệu quả và cộng tác suôn sẻ.
Lợi ích của kiến trúc dbt–Athena
Để thiết kế và quản lý các dbt model một cách hiệu quả, chúng tôi sử dụng một phương pháp nhiều lớp kết hợp với tối ưu chi phí và hiệu năng. Trong phần này, chúng tôi thảo luận cách tiếp cận của mình đã mang lại những lợi ích đáng kể trong năm lĩnh vực chính.
Môi trường dựa vào SQL, thân thiện với nhà phát triển
Đội ngũ của chúng tôi đã có kỹ năng SQL vững chắc, vì vậy phương pháp tập trung vào SQL của dbt trở nên rất phù hợp. Thay vì phải học một ngôn ngữ hoặc framework mới, các developer có thể ngay lập tức bắt đầu viết các phép biến đổi bằng cú pháp SQL quen thuộc trong dbt. Sự quen thuộc này kết hợp hoàn hảo với giao diện SQL của Athena và, cùng với các tính năng bổ sung của dbt, đã gia tăng năng suất của cả đội.
Ở hậu trường, dbt tự động xử lý việc đồng bộ giữa Amazon Simple Storage Service (Amazon S3), AWS Glue Data Catalog và các model của chúng tôi. Khi cần thay đổi loại materialization của một model-ví dụ từ view sang table-chỉ cần cập nhật tham số cấu hình thay vì viết lại code. Sự linh hoạt này đã giảm đáng kể thời gian phát triển, cho phép chúng tôi tập trung vào xây dựng các data model tốt hơn thay vì quản lý hạ tầng.
Tính nhanh nhẹn trong mô hình hóa và triển khai
Tài liệu là yếu tố then chốt cho sự thành công của bất kỳ nền tảng dữ liệu nào. Chúng tôi sử dụng khả năng tạo tài liệu tích hợp của dbt và xuất bản chúng lên GitHub Pages, tạo ra một kho lưu trữ các data model có thể truy cập và tìm kiếm dễ dàng. Tài liệu này bao gồm schema của các bảng, mối quan hệ giữa các model và ví dụ minh họa, giúp thành viên trong đội hiểu được cách các model kết nối với nhau và cách sử dụng chúng một cách hiệu quả.
Chúng tôi sử dụng tính năng kiểm thử tích hợp của dbt để thực hiện các kiểm tra chất lượng dữ liệu toàn diện. Các kiểm tra này bao gồm schema tests để xác minh tính duy nhất của cột, tính toàn vẹn tham chiếu và ràng buộc null, cũng như custom SQL tests để xác thực logic nghiệp vụ và tính nhất quán của dữ liệu. Framework kiểm thử tự động chạy trên mỗi pull request, xác thực các phép biến đổi dữ liệu ở mỗi bước trong pipeline. Ngoài ra, đồ thị phụ thuộc (dependency graph) của dbt cung cấp một biểu diễn trực quan về cách các model kết nối với nhau, giúp chúng tôi hiểu được tác động đầu vào (upstream) và đầu ra (downstream) của bất kỳ thay đổi nào trước khi triển khai.. Khi các bên liên quan cần điều chỉnh model, họ có thể gửi pull request; sau khi được duyệt và merge, các phép biến đổi dữ liệu cần thiết sẽ tự động được kích hoạt thông qua CI/CD pipeline. Quá trình tinh gọn này đã giúp chúng tôi tạo ra sản phẩm dữ liệu mới trong vài ngày thay vì vài tuần và giảm công sức bảo trì nhờ phát hiện sớm vấn đề trong giai đoạn phát triển.
Phân tách workgroup Athena
Chúng tôi sử dụng các Athena workgroup để tách biệt các mẫu truy vấn dựa trên trigger và mục đích thực thi. Mỗi workgroup có cấu hình và báo cáo số liệu riêng, cho phép chúng tôi giám sát và tối ưu độc lập. Workgroup dbt xử lý các phép biến đổi theo lịch hàng đêm và cập nhật on-demand kích hoạt bởi pull request qua các giai đoạn Source, Prepared và Semantic. Workgroup dbt-test thực thi kiểm tra chất lượng dữ liệu tự động khi validate pull request và build hàng đêm. Workgroup QuickSight quản lý các truy vấn ingest dữ liệu vào SPICE và workgroup Ad-hoc hỗ trợ khám phá dữ liệu tương tác của đội.
Mỗi workgroup có thể được cấu hình hạn mức sử dụng dữ liệu cụ thể, cho phép các nhóm triển khai chính sách quản trị chi tiết. Việc tách biệt này mang lại nhiều lợi ích: phân bổ chi phí rõ ràng, giám sát mẫu truy vấn riêng biệt cho từng trường hợp sử dụng, và hỗ trợ thực thi governance dữ liệu thông qua thiết lập workgroup tùy chỉnh. Việc theo dõi từng workgroup trên Amazon CloudWatch giúp chúng tôi nắm bắt mô hình sử dụng, phát hiện vấn đề hiệu năng truy vấn và điều chỉnh cấu hình theo nhu cầu thực tế.
Sử dụng QuickSight SPICE
QuickSight SPICE (Super-fast, Parallel, In-memory Calculation Engine) cung cấp khả năng xử lý in-memory mạnh mẽ mà chúng tôi đã tối ưu cho các trường hợp sử dụng cụ thể. Thay vì nạp toàn bộ bảng vào SPICE, chúng tôi tạo các view chuyên biệt trên nền các materialized semantic model. Các view này được thiết kế cẩn thận để chỉ bao gồm các cột cần thiết, các phép join metadata liên quan và bộ lọc thời gian phù hợp, đảm bảo chỉ dữ liệu gần đây xuất hiện trong dashboard.
Chúng tôi đã triển khai chiến lược làm mới kết hợp cho các dataset SPICE: cập nhật incremental hàng ngày để dữ liệu luôn tươi mới, và full refresh hàng tuần để đảm bảo tính nhất quán. Cách tiếp cận này cân bằng giữa độ tươi mới của dữ liệu và hiệu quả xử lý. Kết quả là các dashboard phản hồi nhanh, duy trì hiệu năng cao đồng thời kiểm soát tốt chi phí xử lý.
Khả năng mở rộng và tiết kiệm chi phí
Kiến trúc serverless của Athena loại bỏ việc quản lý hạ tầng thủ công, tự động mở rộng dựa trên nhu cầu truy vấn. Vì chi phí chỉ tính dựa trên khối lượng dữ liệu bị quét bởi các truy vấn, tối ưu truy vấn để quét càng ít dữ liệu càng tốt sẽ trực tiếp giảm chi phí. Chúng tôi tận dụng khả năng thực thi truy vấn phân tán của Athena qua cấu trúc model của dbt, cho phép xử lý song song trên các phân vùng dữ liệu. Bằng cách triển khai các chiến lược phân vùng hiệu quả và sử dụng định dạng Parquet, chúng tôi giảm thiểu lượng dữ liệu quét trong khi tối đa hóa hiệu năng truy vấn.
Kiến trúc của chúng tôi linh hoạt trong cách thức materialize dữ liệu dưới dạng views, full tables hoặc incremental tables. Với incremental models và chiến lược phân vùng của dbt, chúng tôi chỉ xử lý dữ liệu mới hoặc đã thay đổi thay vì toàn bộ dataset. Cách tiếp cận này đã chứng tỏ hiệu quả cao-chúng tôi ghi nhận sự giảm đáng kể cả về khối lượng xử lý và lượng dữ liệu bị quét, đặc biệt trong workgroup QuickSight.
Hiệu quả của những tối ưu hóa này được triển khai vào cuối năm 2023 được thể hiện rõ trong sơ đồ sau, minh họa chi phí phân theo các Athena workgroup.
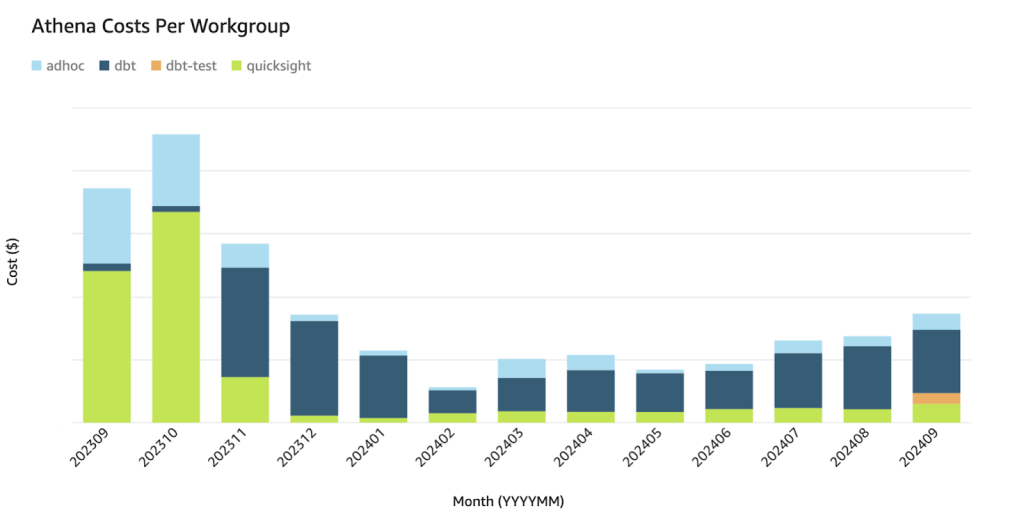
Các workgroup được minh họa như sau:
- Màu xanh lá (QuickSight): Hiển thị giảm khối lượng quét dữ liệu sau tối ưu hóa.
- Màu xanh da trời nhạt (Ad-hoc): Thay đổi tùy theo nhu cầu phân tích.
- Màu xanh dương đậm (dbt): Duy trì mô hình xử lý ổn định.
- Màu cam (dbt-test): Hiển thị việc thực thi kiểm thử định kỳ và hiệu quả.
Việc tăng chi phí workload của dbt tương quan trực tiếp với việc giảm chi phí QuickSight, phản ánh sự thay đổi trong kiến trúc của chúng tôi: từ việc sử dụng các view phức tạp trong workgroup của QuickSight (vốn che giấu độ phức tạp của truy vấn nhưng dẫn đến các phép tính toán lặp lại) sang sử dụng dbt để hiện thực hóa (materialize) các phép chuyển đổi này. Mặc dù điều này làm tăng khối lượng công việc dbt, hiệu quả chi phí tổng thể đã được cải thiện đáng kể vì các bảng được materialize đã giảm thiểu tính toán thừa trong QuickSight. Điều này cho thấy các chiến lược tối ưu hóa của chúng tôi thành công trong việc quản lý khối lượng dữ liệu ngày càng tăng đồng thời đạt được giảm chi phí ròng thông qua mô hình materialization hiệu quả.
Kết luận
Kiến trúc dữ liệu của chúng tôi sử dụng dbt và Athena để cung cấp một framework có khả năng mở rộng, tiết kiệm chi phí và linh hoạt cho việc xây dựng và quản lý các pipeline biến đổi dữ liệu. Khả năng của Athena trong việc truy vấn dữ liệu trực tiếp trên Amazon S3 giúp loại bỏ nhu cầu di chuyển hoặc sao chép dữ liệu vào một kho dữ liệu riêng, và mô hình serverless cùng với xử lý incremental của dbt giảm thiểu cả chi phí vận hành lẫn chi phí xử lý. Với chuyên môn SQL vững chắc của đội ngũ, việc biểu diễn các phép biến đổi này dưới dạng SQL bằng dbt và Athena trở thành lựa chọn tự nhiên, cho phép phát triển và triển khai model nhanh chóng. Nhờ tính năng tự động sinh tài liệu và lineage của dbt, việc gỡ lỗi và xác định sự cố dữ liệu trở nên đơn giản, và tính mô-đun của hệ thống cho phép điều chỉnh nhanh chóng để đáp ứng nhu cầu kinh doanh thay đổi.
Bắt đầu với kiến trúc này rất nhanh chóng và đơn giản: tất cả những gì cần thiết là thư viện dbt-core và dbt-athena, còn Athena thì không yêu cầu bất kỳ thiết lập nào, vì nó là dịch vụ hoàn toàn serverless với tích hợp liền mạch với Amazon S3. Kiến trúc này lý tưởng cho các team muốn nhanh chóng prototype, test và deploy các data model, tối ưu hóa sử dụng tài nguyên, tăng tốc triển khai và đem lại xử lý dữ liệu chất lượng cao, chính xác.
Đối với những ai quan tâm đến giải pháp được quản lý từ dbt, hãy xem From data lakes to insights: dbt adapter for Amazon Athena now supported in dbt Cloud.
Về các tác giả

Philipp Karg là Kỹ sư FinOps chính (Lead FinOps Engineer) tại BMW Group và có nền tảng vững chắc về kỹ thuật dữ liệu, AI và FinOps. Anh tập trung vào việc thúc đẩy các sáng kiến hiệu quả về đám mây và xây dựng văn thức chú trọng về chi phí trong công ty để tận dụng đám mây một cách bền vững.

Selman Ay là Kiến trúc sư dữ liệu (Data Architect) chuyên về các giải pháp dữ liệu đầu cuối, kiến trúc và AI trên AWS. Ngoài công việc, anh thích chơi tennis và tham gia các hoạt động ngoài trời.

Cizer Pereira là Kiến trúc sư DevOps cấp cao (Senior DevOps Architect) tại AWS Professional Services. Anh làm việc chặt chẽ với các khách hàng của AWS để đẩy nhanh hành trình lên đám mây của họ. Anh có niềm đam mê sâu sắc với các giải pháp dựa trên đám mây và DevOps và trong thời gian rảnh, anh cũng thích đóng góp cho các dự án mã nguồn mở.
