Tác giả: Anton Aleksandrov, Rony Blum, Donovan Allen và Ted Bieber
Ngày xuất bản: ngày 18 tháng 04 năm 2025
Danh mục: AWS Lambda, Best Practices, Customer Solutions, Serverless, Technical How-to
Các công ty cung cấp phần mềm dưới dạng dịch vụ (SaaS) trên nền tảng đám mây thường xuyên tìm kiếm những cách thức để nâng cấp kiến trúc của họ nhằm cải thiện hiệu suất và hiệu quả chi phí. Các công nghệ serverless giúp loại bỏ gánh nặng quản lý hạ tầng, cho phép các nhóm phát triển tập trung vào đổi mới và mang lại giá trị kinh doanh. Khi kiến trúc ứng dụng ngày càng mở rộng và đối mặt với những yêu cầu khắt khe hơn, việc liên tục tối ưu hóa sẽ giúp khai thác tối đa cả lợi thế kỹ thuật lẫn tài chính của phương pháp tiếp cận serverless.
Trong bài viết này, chúng tôi trình bày hành trình của Smartsheet trong việc tối ưu hóa kiến trúc serverless của họ. Chúng tôi sẽ khám phá giải pháp được áp dụng, những yêu cầu nghiêm ngặt mà Smartsheet phải đáp ứng và cách họ đã đạt được mức giảm độ trễ lên tới hơn 80%. Hành trình kỹ thuật này mang lại những hiểu biết giá trị cho các tổ chức đang tìm cách nâng cấp kiến trúc serverless của mình bằng các kỹ thuật tối ưu hóa đã được chứng minh ở cấp độ doanh nghiệp.
Tổng quan giải pháp
Smartsheet là một nền tảng quản lý công việc doanh nghiệp hàng đầu dựa trên đám mây, cho phép hàng triệu người dùng trên toàn cầu lập kế hoạch, quản lý, theo dõi, tự động hóa và báo cáo công việc ở quy mô lớn. Cốt lõi của nền tảng này là một kiến trúc hướng sự kiện (event-driven) xử lý hoạt động người dùng theo thời gian thực trên nhiều loại tài liệu khác nhau. Với tính chất cộng tác của nền tảng, nhiều người dùng có thể làm việc đồng thời trên cùng một tài liệu. Mỗi lần tương tác với tài liệu đều kích hoạt một chuỗi sự kiện cần được xử lý với độ trễ tối thiểu để đảm bảo tính nhất quán của dữ liệu và cung cấp phản hồi ngay lập tức. Việc xử lý bị trì hoãn có thể ảnh hưởng đến trải nghiệm người dùng và năng suất làm việc, vì vậy việc duy trì độ trễ thấp một cách nhất quán là một yêu cầu cốt lõi của doanh nghiệp.
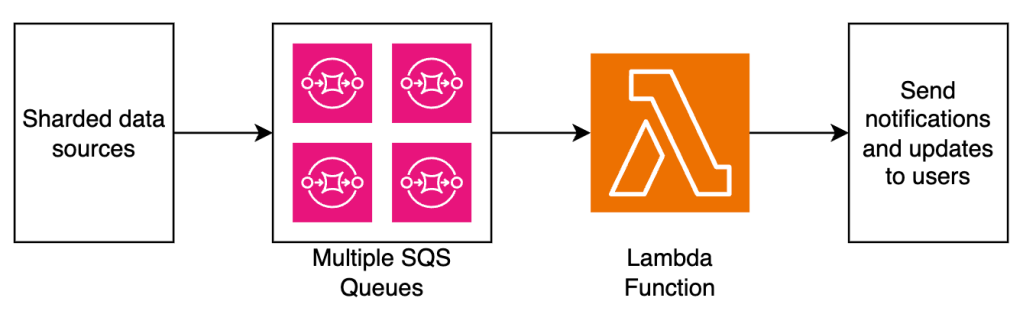
Mẫu lưu lượng truy cập của Smartsheet có tính đột biến cao trong giờ hành chính và hầu như im ắng vào ban đêm và cuối tuần. Trong những khoảng thời gian cao điểm, lưu lượng có thể dao động mạnh khi người dùng cộng tác theo thời gian thực. Để xử lý hiệu quả khối lượng công việc biến động – có thể tăng từ hàng trăm đến hàng chục nghìn sự kiện mỗi giây chỉ trong vài phút – Smartsheet đã triển khai một kiến trúc xử lý sự kiện serverless sử dụng các dịch vụ như Amazon Simple Queue Service (Amazon SQS) và AWS Lambda. Kiến trúc này tận dụng tính đàn hồi của các dịch vụ serverless cùng khả năng tự động mở rộng dựa theo lưu lượng truy cập. Nhờ đó, Smartsheet có thể xử lý hiệu quả các đợt tăng đột ngột lưu lượng trong khi vẫn tự động thu hẹp quy mô vào các khung giờ thấp điểm, tối ưu hóa cả hiệu suất lẫn chi phí vận hành.
Sơ đồ dưới đây minh họa kiến trúc tổng quan của pipeline xử lý sự kiện tại Smartsheet.
Cơ hội tối ưu hóa
Smartsheet sử dụng các hàm Lambda để xử lý cả các tác vụ theo lô (batch jobs) lẫn các yêu cầu API. Ngôn ngữ chính được sử dụng để xây dựng các hàm này là Java. Lambda automatically scales số lượng môi trường thực thi được phân bổ cho hàm dựa trên nhu cầu, nhằm đáp ứng lưu lượng truy cập. Khi Lambda nhận được một yêu cầu đến, nó sẽ cố gắng xử lý bằng một môi trường thực thi đang tồn tại trước. Nếu không có môi trường nào sẵn sàng, dịch vụ sẽ khởi tạo một môi trường mới. Trong quá trình khởi tạo này, mã nguồn của các hàm tại Smartsheet thường gửi nhiều yêu cầu tới các hệ thống phụ thuộc bên ngoài, chẳng hạn như cơ sở dữ liệu hoặc REST API – những thứ có thể mất thời gian để phản hồi.
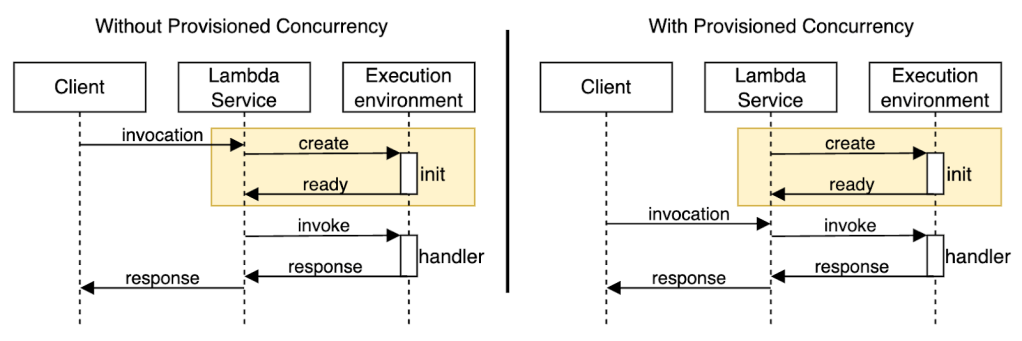
Sơ đồ sau minh họa cách các hàm Lambda liên lạc với các dịch vụ phụ thuộc bên ngoài trong quá trình khởi tạo.

Những tác vụ này làm phát sinh độ trễ trong quá trình khởi tạo môi trường thực thi, thường được gọi là cold start. Mặc dù cold start thường chỉ ảnh hưởng đến chưa tới 1% yêu cầu, nhưng Smartsheet có những yêu cầu rất nghiêm ngặt về độ trễ thấp trong kiến trúc của họ nhằm ưu tiên trải nghiệm người dùng cuối tốt nhất có thể.
“Để giảm độ trễ phản hồi cho khách hàng trong khi vẫn giữ chi phí thấp, đội kỹ thuật của chúng tôi đã sử dụng tính năng provisioned concurrency của Lambda kết hợp với auto scaling và kiến trúc Graviton, giúp giảm 83% độ trễ P95, đồng thời vẫn duy trì chất lượng dịch vụ cao trong quá trình chúng tôi tiếp tục mở rộng nền tảng và khả năng của mình” chia sẻ của Abhishek Gurunathan, Giám đốc Kỹ thuật cấp cao tại Smartsheet.
Giải quyết cold start bằng Provisioned Concurrency
Để giảm độ trễ do cold start gây ra, nhóm kỹ thuật của Smartsheet đã áp dụng provisioned concurrency trong kiến trúc của họ. Đây là một tính năng cho phép nhà phát triển chỉ định số lượng môi trường thực thi mà Lambda nên giữ ở trạng thái sẵn sàng (warm) để có thể xử lý các lệnh gọi (invocations) ngay lập tức. Sơ đồ dưới đây minh họa sự khác biệt giữa hai phương pháp. Nếu không sử dụng provisioned concurrency, môi trường thực thi sẽ được tạo ra khi có yêu cầu đến, nghĩa là một số lời gọi (thường dưới 1%) phải chờ để môi trường được khởi tạo và mã khởi tạo được thực thi. Ngược lại, khi có provisioned concurrency, Lambda tạo sẵn môi trường thực thi và chạy trước mã khởi tạo, đảm bảo các lời gọi được xử lý ngay bởi môi trường đã sẵn sàng.
Provisioned concurrency còn bao gồm một cơ chế mở rộng linh hoạt (dynamic spillover), giúp kiến trúc serverless của bạn có khả năng chống chịu cao trước các đợt tăng vọt lưu lượng truy cập. Khi lưu lượng đến vượt quá mức provisioned concurrency đã định sẵn, các yêu cầu bổ sung sẽ tự động được xử lý bằng on-demand concurrency thay vì bị từ chối (throttled). Cách tiếp cận này mang lại khả năng mở rộng liền mạch và duy trì tính khả dụng của dịch vụ ngay cả trong các thời điểm cao điểm, đồng thời vẫn đảm bảo lợi ích về hiệu năng nhờ môi trường thực thi được giữ sẵn cho phần lớn yêu cầu.
Nhóm Smartsheet đã cấu hình provisioned concurrency để đáp ứng nhu cầu đồng thời ở phân vị thứ 95 (P95) theo dữ liệu lịch sử của họ. Kết quả thu được gần như tức thì-số lần cold start giảm mạnh và độ trễ xử lý ở ngưỡng P95 giảm tới 83%. Khi theo dõi hiệu năng hệ thống, nhóm nhanh chóng phát hiện ra một cơ hội tối ưu hóa khác: các hàm Lambda được sử dụng nhiều vào giờ làm việc nhưng có rất ít lời gọi vào ban đêm và cuối tuần, như minh họa trong biểu đồ dưới đây.

Cấu hình provisioned concurrency tĩnh hoạt động rất hiệu quả trong giờ cao điểm, nhưng lại bị lãng phí trong các thời điểm ít sử dụng. Nhóm Smartsheet muốn tinh chỉnh thêm kiến trúc để nâng cao tỷ lệ sử dụng của provisioned concurrency nhằm đạt hiệu quả chi phí cao hơn. Điều này đã dẫn họ đến việc tìm hiểu về auto scaling cho provisioned concurrency để điều chỉnh theo lưu lượng thực tế, cũng như áp dụng kiến trúc AWS Graviton.
Tự động mở rộng provisioned concurrency và kiến trúc Graviton
Có hai cách phổ biến để kích hoạt provisioned concurrency: Cấu hình tĩnh và tự động mở rộng (auto scaling). Với cấu hình tĩnh, bạn chỉ định một số lượng cố định các môi trường thực thi được khởi tạo sẵn (warm) để luôn sẵn sàng xử lý các lời gọi hàm. Cách tiếp cận này rất hiệu quả với các kiến trúc có lưu lượng truy cập dự đoán được. Tuy nhiên, với các mẫu lưu lượng không dự đoán được, điều này có thể dẫn đến tình trạng cấp phát thiếu trong giờ cao điểm (gây ra hiện tượng tràn sang chế độ on-demand concurrency dẫn đến nhiều lần cold start hơn) hoặc sử dụng không hiệu quả trong các thời điểm ít hoạt động. Để giải quyết vấn đề này, provisioned concurrency với auto scaling sẽ điều chỉnh cấu hình một cách linh hoạt dựa trên các chỉ số sử dụng thực tế, tự động tăng hoặc giảm số lượng môi trường thực thi để phù hợp với nhu cầu. Phương pháp này tối ưu chi phí và đặc biệt được khuyến nghị cho các kiến trúc có lưu lượng biến động.
Hình minh họa dưới đây so sánh giữa provisioned concurrency tĩnh và động.

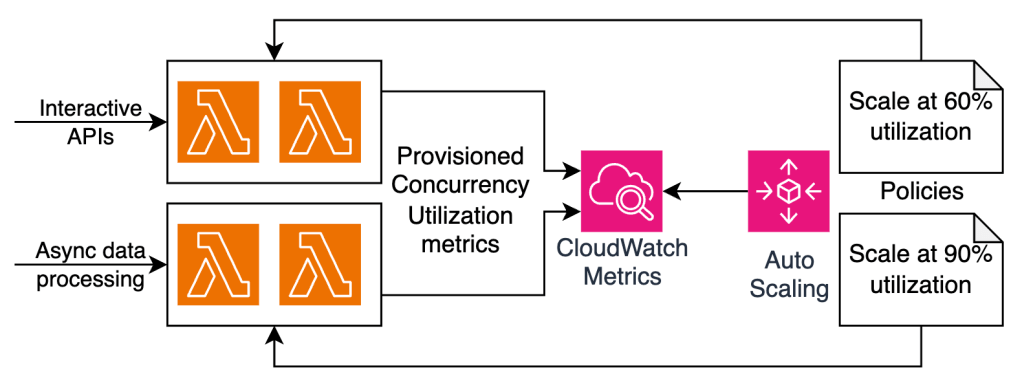
Để tối ưu hóa kiến trúc hơn nữa về mặt chi phí, nhóm Smartsheet đã triển khai auto scaling cho provisioned concurrency dựa trên các chỉ số sử dụng. Smartsheet đã áp dụng phương pháp Infrastructure as Code (IaC – Hạ tầng dưới dạng mã) với Terraform để định nghĩa các chính sách auto scaling có thể tái sử dụng tối đa trên hàng trăm hàm Lambda. Các chính sách này theo dõi chỉ số LambdaProvisionedConcurrencyUtilization và đặt ngưỡng mở rộng tùy theo mục đích của hàm. Với các hàm triển khai API tương tác, ngưỡng auto scale là 60% để tạo sẵn môi trường thực thi từ sớm, giữ độ trễ cực thấp và tăng khả năng chịu tải khi lưu lượng tăng vọt. Với các hàm xử lý dữ liệu bất đồng bộ, mục tiêu của Smartsheet là đạt tỷ lệ sử dụng cao nhất và tối ưu chi phí, vì vậy họ đặt ngưỡng auto scale là 90%.
Sơ đồ sau minh họa kiến trúc của các chính sách auto scaling dựa trên tỷ lệ sử dụng provisioned concurrency và loại khối lượng công việc.
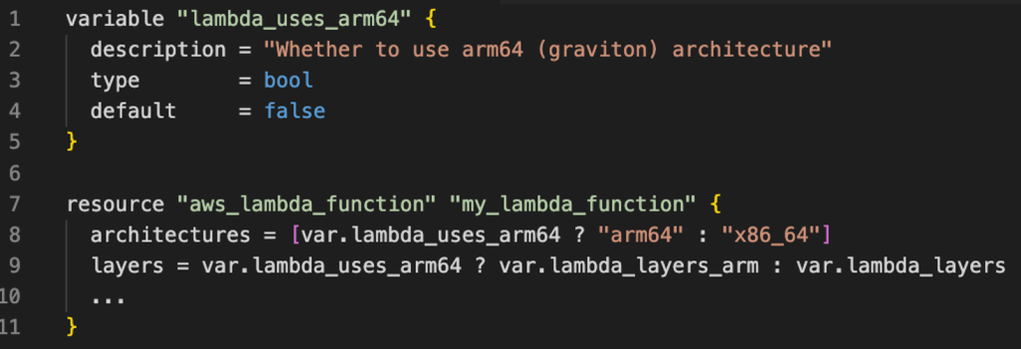
Một kỹ thuật tối ưu khác mà Smartsheet áp dụng là chuyển kiến trúc CPU được sử dụng bởi các hàm Lambda của họ từ x86_64 sang arm64 Graviton. Để thực hiện điều này, Smartsheet đã sử dụng các phiên bản ARM của các Lambda layer mà họ đang dùng, chẳng hạn như Datadog và các phần mở rộng Lambda Insights. Việc này là cần thiết vì các tập tin nhị phân được xây dựng cho một kiến trúc này có thể không tương thích với kiến trúc khác. Tuy nhiên, vì các hàm của Smartsheet được viết bằng Java và đóng gói dưới dạng JAR, họ không gặp bất kỳ vấn đề tương thích nào khi chuyển sang Graviton. Với việc dùng Terraform để mã hóa hạ tầng, việc chuyển đổi kiến trúc này chỉ đơn giản là thay đổi một thuộc tính trong tài nguyên aws_lambda_function, như minh họa trong đoạn mã sau:
Việc chuyển sang kiến trúc Graviton đã giúp Smartsheet tiết kiệm 20% chi phí tính theo GB-giây cho hàm Lambda. Xem chi tiết tại AWS Lambda pricing.
Tối ưu kiến trúc
Hãy áp dụng các kỹ thuật và thực hành sau để tối ưu kiến trúc serverless của bạn, giảm hiện tượng cold start và tăng hiệu quả chi phí:
- Fine-tune your Lambda function để tìm được điểm cân bằng tối ưu giữa chi phí và hiệu suất. Việc tăng bộ nhớ cấp phát cũng đồng thời tăng năng lực xử lý của CPU, điều này thường giúp thời gian thực thi nhanh hơn và có thể dẫn đến tổng chi phí thấp hơn.
- Sử dụng Graviton2 architecture cho các khối lượng công việc tương thích để đạt được tỷ lệ hiệu suất/chi phí tốt hơn. Tùy thuộc vào loại khối lượng công việc, việc chuyển sang Graviton có thể mang lại up to 34% improvement.
- Sử dụng provisioned concurrency và Lambda SnapStart để giảm cold start trong kiến trúc serverless của bạn. Bắt đầu với provisioned concurrency tĩnh dựa trên nhu cầu về độ đồng thời trong quá khứ, theo dõi mức độ sử dụng, và dần dần tích hợp auto scaling để đạt được trạng thái cân bằng tối ưu giữa hiệu suất và chi phí.
Kết luận
Các kiến trúc serverless sử dụng những dịch vụ như Lambda và Amazon SQS giúp chuyển giao trách nhiệm quản lý cơ sở hạ tầng và mở rộng quy mô cho AWS, từ đó cho phép các nhóm phát triển tập trung vào đổi mới và mang lại giá trị kinh doanh. Như hành trình tối ưu hóa của Smartsheet đã minh chứng, việc sử dụng provisioned concurrency và Graviton trong kiến trúc serverless có thể cải thiện đáng kể trải nghiệm người dùng bằng cách giảm độ trễ, đồng thời đạt được hiệu quả chi phí tốt hơn – mang lại một hình mẫu tối ưu hóa thực tiễn cho toàn tổ chức. Dù bạn đang vận hành các ứng dụng doanh nghiệp quy mô lớn hay xây dựng các giải pháp đám mây mới, những kỹ thuật đã được kiểm chứng này có thể giúp bạn đạt được những cải thiện tương tự về hiệu suất và chi phí trong kiến trúc serverless của mình.
Để tìm hiểu thêm về kiến trúc serverless, hãy truy cập Serverless Land.
Về các tác giả

Anton Aleksandrov
Anton Aleksandrov là Kiến trúc sư giải pháp Chính, phụ trách mảng kiến trúc Serverless và Hướng sự kiện (Event-Driven) tại AWS. Với hơn hai thập kỷ kinh nghiệm thực chiến về kỹ thuật và kiến trúc, Anton làm việc với các khách hàng lớn thuộc mảng ISV (Nhà cung cấp phần mềm độc lập) và SaaS để thiết kế các giải pháp đám mây có khả năng mở rộng cao, sáng tạo và bảo mật.

Rony Blum
Rony Blum là một Kiến trúc sư giải pháp cấp cao tại AWS, làm việc tại Seattle. Anh hỗ trợ các khách hàng ISV thiết kế và triển khai các kiến trúc đám mây tiên tiến, với chuyên môn về các giải pháp SaaS, hệ thống đa người dùng (multi-tenant) và ứng dụng GenAI

Donovan Allen
Donovan Allen là Kỹ sư phần mềm cấp cao 1 và Trưởng nhóm Kỹ thuật của đội ngũ Sheet Linking tại Smartsheet. Với hơn 8 năm kinh nghiệm xây dựng kiến trúc cho các ứng dụng đám mây có khả năng mở rộng, anh có đam mê tìm hiểu sâu về các chi tiết của những hệ thống đòi hỏi hiệu năng cao và độ trễ thấp.

Ted Bieber
Ted Bieber là một Kỹ sư phần mềm tại Smartsheet. Nhiều năm kinh nghiệm giúp anh triển khai các giải pháp thực tiễn cho những vấn đề phức tạp. Ted yêu thích làm việc trong môi trường đám mây và học hỏi các công nghệ mới.
