Tác giả: Rielah De Jesus, Nitin Surya, Sai Guruju, and Srikanta Prasad
Ngày xuất bản: ngày 17 tháng 04 năm 2025
Danh mục: Amazon SageMaker, Amazon SageMaker AI, Artificial Intelligence, Best Practices, Customer Solutions, Experience-Based Acceleration
Bài đăng này là sự hợp tác chung giữa Salesforce và AWS và đang được xuất bản chéo trên cả Salesforce Engineering Blog và Blog Machine Learning AWS.
Nhóm Phục vụ Mô hình Salesforce AI đang làm việc để vượt qua ranh giới của khả năng xử lý ngôn ngữ tự nhiên và AI cho các ứng dụng doanh nghiệp. Các lĩnh vực trọng tâm chính của họ bao gồm tối ưu hóa các mô hình ngôn ngữ lớn (LLM) bằng cách tích hợp các giải pháp tiên tiến, hợp tác với các nhà cung cấp công nghệ hàng đầu và thúc đẩy các cải tiến hiệu suất ảnh hưởng đến các tính năng dựa trên AI của Salesforce. Nhóm Phục vụ Mô hình AI hỗ trợ nhiều mô hình cho cả máy học (ML) truyền thống và generative AI bao gồm LLM, mô hình nền tảng đa phương thức (FM), nhận dạng giọng nói và mô hình dựa trên thị giác máy tính. Thông qua đổi mới và quan hệ đối tác với các nhà cung cấp công nghệ hàng đầu, nhóm này nâng cao hiệu suất và khả năng, giải quyết các thách thức như tối ưu hóa thông lượng và độ trễ cũng như triển khai mô hình an toàn cho các ứng dụng AI thời gian thực. Họ thực hiện điều này thông qua việc đánh giá các mô hình ML trên nhiều môi trường và kiểm tra hiệu suất mở rộng để đạt được khả năng mở rộng và độ tin cậy cho suy luận trên AWS.
Nhóm chịu trách nhiệm về quy trình từ đầu đến cuối để thu thập các yêu cầu và mục tiêu hiệu suất, lưu trữ, tối ưu hóa và mở rộng các mô hình AI, bao gồm cả LLM, được xây dựng bởi các nhóm nghiên cứu và khoa học dữ liệu của Salesforce. Điều này bao gồm tối ưu hóa các mô hình để đạt được thông lượng cao và độ trễ thấp cũng như triển khai chúng nhanh chóng thông qua các quy trình tự phục vụ, tự động trên nhiều khu vực AWS.
Trong bài đăng này, chúng tôi chia sẻ cách nhóm AI Model Service đạt được triển khai mô hình hiệu suất cao bằng cách sử dụng Amazon SageMaker AI.
Các thách thức chính
Đội ngũ phải đối mặt với một số thách thức trong việc triển khai mô hình cho Salesforce. Một ví dụ chính là cân bằng độ trễ và thông lượng trong khi đạt được hiệu quả chi phí khi mở rộng các mô hình này dựa trên nhu cầu. Duy trì hiệu suất và khả năng mở rộng đồng thời giảm thiểu chi phí phục vụ là quan trọng trong toàn bộ vòng đời suy luận. Tối ưu hóa suy luận là một khía cạnh quan trọng của quy trình này vì mô hình và môi trường lưu trữ của nó phải được tinh chỉnh để đáp ứng các yêu cầu về hiệu năng trên giá (price-performance) trong các ứng dụng AI thời gian thực. Đổi mới AI nhịp độ nhanh của Salesforce yêu cầu đội ngũ phải liên tục đánh giá các mô hình mới (độc quyền, mã nguồn mở, hoặc bên thứ ba) trên các trường hợp sử dụng đa dạng. Sau đó họ phải nhanh chóng triển khai các mô hình này để đồng bộ với các chiến lược go-to-market của các đội sản phẩm. Cuối cùng, các mô hình phải được lưu trữ an toàn, và dữ liệu khách hàng phải được bảo vệ để duy trì cam kết của Salesforce trong việc cung cấp một nền tảng đáng tin cậy và an toàn.
Tổng quan giải pháp
Để hỗ trợ chức năng quan trọng như vậy cho Salesforce AI, đội ngũ đã phát triển một khung lưu trữ trên AWS để đơn giản hóa vòng đời mô hình của họ, cho phép họ triển khai nhanh chóng và an toàn các mô hình ở quy mô lớn đồng thời tối ưu hóa chi phí. Biểu đồ bên dưới minh họa luồng hoạt động của giải pháp.
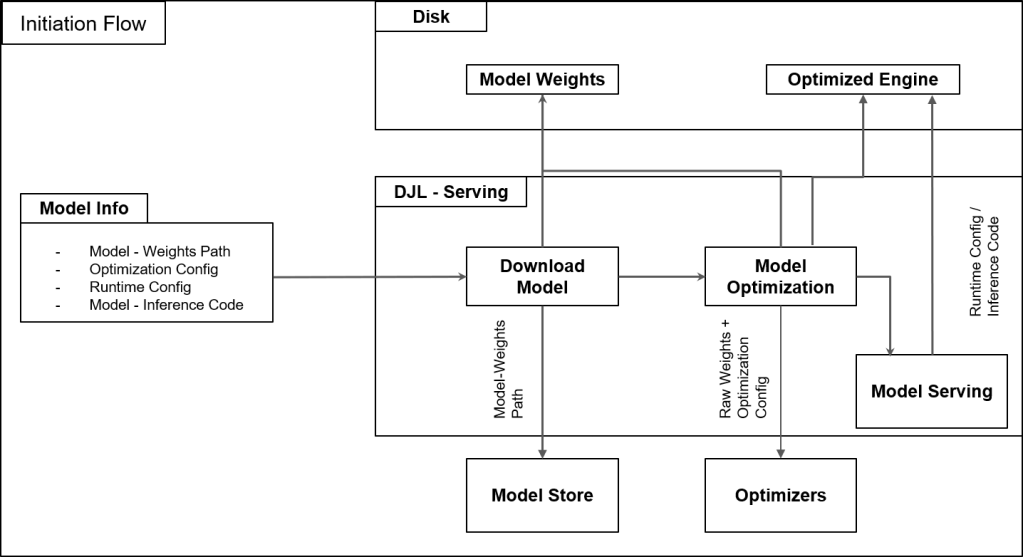
Quản lý hiệu suất và khả năng mở rộng
Quản lý khả năng mở rộng trong dự án bao gồm việc cân bằng hiệu suất với hiệu quả và quản lý tài nguyên. Với SageMaker AI, đội ngũ hỗ trợ suy luận phân tán và triển khai đa mô hình, ngăn chặn các nút thắt bộ nhớ và giảm chi phí phần cứng. SageMaker AI cung cấp quyền truy cập vào các GPU tiên tiến, hỗ trợ triển khai đa mô hình, và cho phép các chiến lược gom lô (batching) thông minh để cân bằng thông lượng với độ trễ. Tính linh hoạt này đảm bảo rằng các cải tiến hiệu suất không ảnh hưởng đến khả năng mở rộng, ngay cả trong các tình huống có nhu cầu cao. Để tìm hiểu thêm, hãy xem bài viết Revolutionizing AI: How Amazon SageMaker Enhances Einstein’s Large Language Model Latency and Throughput.
Tăng tốc phát triển với SageMaker Deep Learning Containers
SageMaker AI Deep Learning Containers (DLCs) đóng vai trò quan trọng trong việc tăng tốc phát triển và triển khai mô hình. Các container được xây dựng sẵn này đi kèm với các framework học sâu được tối ưu hóa và cấu hình thực hành tốt nhất, cung cấp một khởi đầu thuận lợi cho các đội AI. DLC cung cấp các phiên bản thư viện được tối ưu hóa, cài đặt CUDA được cấu hình trước, và các cải tiến hiệu suất khác giúp cải thiện tốc độ và hiệu quả suy luận. Điều này giảm đáng kể chi phí thiết lập và cấu hình, cho phép các kỹ sư tập trung vào tối ưu hóa mô hình thay vì lo lắng về cơ sở hạ tầng.
Cấu hình theo phương pháp hay nhất để triển khai trong SageMaker AI
Một lợi thế chính của việc sử dụng SageMaker AI là các cấu hình được thiết lập sẵn theo phương pháp hay nhất (best practice) cho việc triển khai. SageMaker AI cung cấp các tham số mặc định để thiết lập mức sử dụng GPU và phân bổ bộ nhớ, giúp đơn giản hóa quy trình cấu hình các môi trường suy luận hiệu suất cao. Những tính năng này giúp việc triển khai các mô hình đã được tối ưu hóa trở nên đơn giản với sự can thiệp thủ công ở mức tối thiểu, đồng thời cung cấp độ sẵn sàng cao và phản hồi có độ trễ thấp.
Đội ngũ sử dụng khả năng rolling-batch của DLC, giúp tối ưu hóa việc gom lô yêu cầu (request batching) để tối đa hóa thông lượng trong khi vẫn duy trì độ trễ thấp. SageMaker AI DLC cung cấp các cấu hình cho suy luận rolling batch với các giá trị mặc định theo phương pháp hay nhất, đơn giản hóa quá trình triển khai. Bằng cách điều chỉnh các tham số như max_rolling_batch_size và job_queue_size, đội ngũ có thể tinh chỉnh hiệu suất mà không cần tùy chỉnh kỹ thuật phức tạp. Cách tiếp cận tinh gọn này giúp sử dụng GPU một cách tối ưu trong khi vẫn đáp ứng các yêu cầu về thời gian phản hồi theo thời gian thực.
SageMaker AI cung cấp các tính năng cân bằng tải linh hoạt (elastic load balancing), co giãn phiên bản (instance scaling), và giám sát mô hình theo thời gian thực, đồng thời cho phép Salesforce kiểm soát các chiến lược co giãn và định tuyến để phù hợp với nhu cầu của họ. Các biện pháp này giúp duy trì hiệu suất nhất quán trên các môi trường, đồng thời tối ưu hóa khả năng mở rộng, hiệu suất và hiệu quả chi phí.
Bởi vì đội ngũ hỗ trợ nhiều đợt triển khai đồng thời trên các dự án, họ cần đảm bảo rằng các cải tiến trong mỗi dự án không làm ảnh hưởng đến các dự án khác. Để giải quyết vấn đề này, họ đã áp dụng phương pháp phát triển theo module. Kiến trúc của SageMaker AI DLC được thiết kế với các thành phần module hóa như lớp trừu tượng hóa engine, kho lưu trữ mô hình và trình quản lý khối lượng công việc. Cấu trúc này cho phép đội ngũ cô lập và tối ưu hóa các thành phần riêng lẻ trên container, chẳng hạn như suy luận rolling batch để tăng thông lượng, mà không làm gián đoạn các chức năng quan trọng như độ trễ hoặc hỗ trợ đa framework. Điều này cho phép các nhóm dự án làm việc trên các dự án riêng lẻ như tinh chỉnh hiệu suất, đồng thời cho phép các nhóm khác tập trung vào việc kích hoạt các chức năng khác như truyền dữ liệu (streaming) một cách song song.
Sự hợp tác liên chức năng này được bổ trợ bằng việc kiểm thử toàn diện. Đội ngũ mô hình AI của Salesforce đã triển khai các quy trình tích hợp liên tục (CI) sử dụng sự kết hợp giữa các công cụ nội bộ và bên ngoài như Jenkins and Spinnaker để phát hiện sớm bất kỳ tác dụng phụ không mong muốn nào. Kiểm thử hồi quy (Regression testing) đảm bảo rằng các tối ưu hóa, chẳng hạn như triển khai mô hình với TensorRT hoặc vLLM, không ảnh hưởng tiêu cực đến khả năng mở rộng hoặc trải nghiệm người dùng. Các buổi đánh giá thường xuyên, với sự hợp tác giữa các đội ngũ phát triển, vận hành mô hình nền tảng (FMOps), và bảo mật, đảm bảo rằng các tối ưu hóa phù hợp với các mục tiêu toàn dự án.
Quản lý cấu hình cũng là một phần của quy trình CI. Cụ thể, cấu hình được lưu trữ trong git cùng với mã suy luận. Việc quản lý cấu hình bằng các tệp YAML đơn giản cho phép thử nghiệm nhanh chóng trên các bộ tối ưu hóa (optimizer) và siêu tham số (hyperparameter) mà không làm thay đổi mã nguồn cơ bản. Những phương pháp này đảm bảo rằng các cải tiến về hiệu suất hoặc bảo mật được phối hợp tốt và không gây ra sự đánh đổi ở các lĩnh vực khác.
Duy trì bảo mật trong quá trình triển khai nhanh
Việc cân bằng giữa triển khai nhanh và các tiêu chuẩn cao về tin cậy và bảo mật đòi hỏi phải tích hợp các biện pháp bảo mật trong suốt vòng đời phát triển và triển khai. Các nguyên tắc bảo mật từ khâu thiết kế (secure-by-design) được áp dụng ngay từ đầu, đảm bảo rằng các yêu cầu bảo mật được tích hợp vào kiến trúc. Việc kiểm thử nghiêm ngặt tất cả các mô hình được tiến hành trong môi trường phát triển song song với kiểm thử hiệu suất để đảm bảo hiệu suất có thể mở rộng và tính bảo mật trước khi đưa vào môi trường production.
Để duy trì các tiêu chuẩn cao này trong suốt quá trình phát triển, đội ngũ đã áp dụng một số chiến lược:
- Các quy trình tích hợp và phân phối liên tục (CI/CD) tự động với các bước kiểm tra được tích hợp sẵn cho lỗ hổng, xác thực tuân thủ và tính toàn vẹn của mô hình.
- Sử dụng các cơ chế mã hóa của DJL-Serving cho dữ liệu đang truyền (in-transit) và dữ liệu lưu trữ (at-rest).
- Sử dụng các dịch vụ AWS như SageMaker AI cung cấp các tính năng bảo mật cấp doanh nghiệp như kiểm soát truy cập dựa trên vai trò (RBAC) và cô lập mạng.
Việc kiểm thử tự động thường xuyên cho cả hiệu suất và bảo mật được áp dụng thông qua các đợt triển khai nhỏ theo từng bước (incremental deployments), cho phép xác định sớm các vấn đề đồng thời giảm thiểu rủi ro. Sự hợp tác với các nhà cung cấp đám mây và việc giám sát liên tục các đợt triển khai giúp duy trì sự tuân thủ các tiêu chuẩn bảo mật mới nhất, đồng thời đảm bảo quá trình triển khai nhanh chóng song hành một cách liền mạch với các yếu tố bảo mật, tin cậy và độ ổn định cao.
Tập trung vào cải tiến liên tục
Khi nhu cầu về AI tạo sinh của Salesforce mở rộng và trong bối cảnh các mô hình liên tục thay đổi, đội ngũ không ngừng làm việc để cải thiện cơ sở hạ tầng triển khai của mình. Các nỗ lực nghiên cứu và phát triển (R&D) đang diễn ra đều tập trung vào việc nâng cao hiệu suất, khả năng mở rộng và hiệu quả của các đợt triển khai LLM. Đội ngũ đang khám phá các kỹ thuật tối ưu hóa mới với SageMaker, bao gồm:
- Các phương pháp lượng tử hóa (quantization) tiên tiến (INT-4, AWQ, FP8).
- Tính toán song song tensor (Tensor parallelism), tức là chia các tensor trên nhiều GPU.
- Gom lô (batching) hiệu quả hơn bằng cách sử dụng các chiến lược lưu đệm (caching) trong DJL-Serving để tăng thông lượng và giảm độ trễ.
Đội ngũ cũng đang nghiên cứu các công nghệ mới nổi như chip AI của AWS (AWS Trainium và AWS Inferentia)và AWS Graviton để cải thiện hơn nữa hiệu quả về chi phí và năng lượng. Sự hợp tác với các cộng đồng mã nguồn mở và các nhà cung cấp đám mây công cộng như AWS đảm bảo rằng những tiến bộ mới nhất được tích hợp vào các quy trình triển khai, đồng thời tiếp tục mở rộng các giới hạn. Salesforce đang hợp tác với AWS để tích hợp các tính năng nâng cao vào DJL, giúp việc sử dụng trở nên tốt hơn và mạnh mẽ hơn, chẳng hạn như bổ sung các tham số cấu hình, biến môi trường và các chỉ số chi tiết hơn để ghi log. Một trọng tâm chính là tinh chỉnh khả năng hỗ trợ đa framework và suy luận phân tán để cung cấp sự tích hợp mô hình liền mạch trên nhiều môi trường khác nhau.
Các nỗ lực cũng đang được tiến hành để tăng cường các phương pháp vận hành mô hình nền tảng (FMOps), chẳng hạn như các quy trình kiểm thử và triển khai tự động, nhằm đẩy nhanh sự sẵn sàng cho môi trường production. Những sáng kiến này nhằm mục đích luôn đi đầu trong đổi mới AI, cung cấp các giải pháp tiên tiến phù hợp với nhu cầu kinh doanh và đáp ứng mong đợi của khách hàng. Họ đang hợp tác chặt chẽ với đội ngũ SageMaker để tiếp tục khám phá các tính năng và khả năng tiềm năng nhằm hỗ trợ các lĩnh vực này.
Kết luận
Mặc dù các chỉ số chính xác có thể thay đổi tùy theo từng trường hợp sử dụng, đội ngũ Phục Vụ Mô Hình AI của Salesforce đã nhận thấy những cải tiến đáng kể về tốc độ triển khai và hiệu quả chi phí với chiến lược của họ trên SageMaker AI. Họ có được các chu kỳ lặp nhanh hơn, có thể tính bằng ngày hoặc thậm chí bằng giờ thay vì bằng tuần. Với SageMaker AI, họ đã giảm thời gian triển khai mô hình lên đến 50%.
Để tìm hiểu thêm về cách SageMaker AI cải thiện độ trễ và thông lượng LLM của Einstein, hãy xem Revolutionizing AI: How Amazon SageMaker Enhances Einstein’s Large Language Model Latency and Throughput. Để biết thêm thông tin về cách bắt đầu với SageMaker AI, hãy tham khảo Guide to getting set up with Amazon SageMaker AI.
Về các tác giả

Sai Guruju đang làm việc với vai trò Kỹ sư Trưởng (Lead Member of Technical Staff) tại Salesforce. Anh có hơn 7 năm kinh nghiệm trong kỹ thuật phần mềm và ML với trọng tâm là các giải pháp NLP và giọng nói có thể mở rộng. Anh tốt nghiệp Cử nhân Công nghệ chuyên ngành Kỹ thuật Điện từ IIT-Delhi, và đã xuất bản các công trình tại InterSpeech 2021 và AdNLP 2024.

Nitin Surya đang làm việc với vai trò Kỹ sư Trưởng (Lead Member of Technical Staff) tại Salesforce. Anh có hơn 8 năm kinh nghiệm trong kỹ thuật phần mềm và học máy, tốt nghiệp Cử nhân Công nghệ chuyên ngành Khoa học Máy tính từ Đại học VIT, với bằng Thạc sĩ Khoa học Máy tính (chuyên ngành Trí tuệ Nhân tạo và Học máy) từ Đại học Illinois Chicago. Anh có ba bằng sáng chế đang chờ phê duyệt, và đã xuất bản và đóng góp cho các bài báo tại Hội nghị CoRL.

Srikanta Prasad là Giám đốc Cấp cao về Quản lý Sản phẩm chuyên về các giải pháp AI tạo sinh, với hơn 20 năm kinh nghiệm trong các lĩnh vực bán dẫn, hàng không vũ trụ, hàng không, truyền thông in ấn, và công nghệ phần mềm. Tại Salesforce, anh dẫn dắt các sáng kiến lưu trữ mô hình và suy luận, tập trung vào phục vụ suy luận LLM, LLMOps, và triển khai AI có thể mở rộng. Srikanta có bằng MBA từ Đại học North Carolina và bằng Thạc sĩ từ Đại học Quốc gia Singapore.

Rielah De Jesus là Kiến trúc sư Giải pháp Chính (Principal Solutions Architect) tại AWS, người đã thành công trong việc giúp đỡ nhiều khách hàng doanh nghiệp trong khu vực DC, Maryland, và Virginia chuyển đổi lên đám mây. Trong vai trò hiện tại, cô đóng vai trò là người đại diện cho khách hàng và cố vấn kỹ thuật, tập trung vào việc giúp các tổ chức như Salesforce đạt được thành công trên nền tảng AWS. Cô cũng là người ủng hộ mạnh mẽ cho phụ nữ trong ngành CNTT và rất đam mê tìm kiếm các cách sáng tạo để sử dụng công nghệ và dữ liệu nhằm giải quyết các thách thức hàng ngày.
