Tác giả: Adam Nemeth, Dominic Searle
Ngày xuất bản: ngày 26 tháng 06 năm 2025
Danh mục: Amazon Bedrock, Best Practices, Generative AI, Intermediate (200), Technical How-to
Lĩnh vực trí tuệ nhân tạo tạo sinh (Generative AI) đang cách mạng hóa các ngành công nghiệp thông qua việc tối ưu hóa quy trình vận hành và thúc đẩy đổi mới sáng tạo. Dù hình thức tương tác phổ biến nhất hiện nay là các cuộc trò chuyện văn bản (chat) với AI, các ứng dụng trong thực tế lại thường phụ thuộc nhiều vào dữ liệu có cấu trúc cho các API, cơ sở dữ liệu, tải công việc dựa trên dữ liệu (data-driven workloads), và các giao diện người dùng phong phú. Dữ liệu có cấu trúc cũng có thể nâng cao AI đàm thoại (conversational AI), cho phép tạo ra các kết quả đầu ra đáng tin cậy và có tính ứng dụng cao hơn. Nhưng một thách thức lớn là các Mô hình Ngôn ngữ Lớn (LLM) vốn có tính khó đoán (unpredictable), điều này khiến chúng khó tạo ra các đầu ra có cấu trúc nhất quán như JSON. Thách thức này phát sinh do dữ liệu huấn luyện của mô hình chủ yếu là văn bản phi cấu trúc, như bài viết, sách và trang web, với tương đối ít ví dụ về các định dạng có cấu trúc. Do đó, LLM có thể gặp khó khăn về độ chính xác khi tạo đầu ra JSON, trong khi đầu ra này rất quan trọng khi tích hợp vào API hoặc hệ thống dữ liệu. Khả năng hỗ trợ phản hồi có cấu trúc khác nhau tùy vào từng mô hình, bao gồm nhận dạng kiểu dữ liệu và quản lý hiệu quả các hệ thống phân cấp phức tạp. Việc hiểu rõ và tận dụng được các khả năng này là yếu tố quan trọng khi lựa chọn mô hình AI phù hợp.
Bài viết này trình bày cách Amazon Bedrock, một dịch vụ được quản lý để truy cập an toàn vào các mô hình AI hàng đầu, có thể giúp giải quyết những thách thức trên bằng cách sử dụng hai lựa chọn thay thế:
- Prompt Engineering – Kỹ thuật thiết kế Prompt: Phương pháp tiếp cận trực tiếp sử dụng các prompt được xây dựng để định hình đầu ra.
- Tool Use với Converse API: Một phương pháp nâng cao cho phép kiểm soát tốt hơn, đảm bảo tính nhất quán, và tích hợp trực tiếp (native) JSON schema.
Chúng ta sẽ dùng một ví dụ về phân tích đánh giá khách hàng để minh họa cách Amazon Bedrock có thể tạo ra dữ liệu có cấu trúc, chẳng hạn như điểm cảm xúc (sentiment scores), chỉ với vài dòng codcode Python đơn giản.
Cách xây dựng giải pháp thiết kế Prompt
Phần này sẽ hướng dẫn cách sử dụng kỹ thuật Prompt Engineering một cách hiệu quả để tạo ra các đầu ra có cấu trúc với Amazon Bedrock. Prompt Engineering là kỹ thuật xây dựng các prompt đầu vào một cách chính xác nhằm hướng dẫn các mô hình ngôn ngữ lớn (LLM) tạo ra phản hồi nhất quán và có cấu trúc. Đây là một kỹ năng cơ bản trong việc phát triển các ứng dụng AI tạo sinh (Generative AI), đặc biệt khi bạn cần kết quả theo định dạng có cấu trúc như JSON. Chúng ta sẽ thực hiện theo 5 bước chính sau để triển khai giải pháp này:
- Cấu hình Bedrock client và các tham số runtime.
- Tạo một lược đồ JSON cho đầu ra có cấu trúc.
- Thiết kế một prompt với hướng dẫn và ví dụ rõ ràng.
- Thêm dữ liệu đầu vào là đánh giá khách hàng để phân tích.
- Gọi Bedrock, thực thi mô hình và xử lý phản hồi.
Mặc dù ví dụ minh họa của chúng ta là phân tích đánh giá khách hàng để tạo ra đầu ra định dạng JSON, các phương pháp này cũng có thể áp dụng với các định dạng khác như XML hoặc CSV.
Bước 1: Cấu hình Bedrock
Đầu tiên, chúng ta sẽ thiết lập một số hằng số và khởi tạo đối tượng kết nối client của Amazon Bedrock bằng cách sử dụng Python Boto3 SDK for Bedrock runtime để hỗ trợ giao tiếp và tương tác với dịch vụ Bedrock:

REGION xác định vùng AWS nơi mô hình sẽ được thực thi, MODEL_ID chỉ định mô hình Bedrock cụ thể được sử dụng (Bedrock model). Hằng số TEMPERATURE điều khiển mức độ ngẫu nhiên của đầu ra, Temperature càng cao thì mô hình càng sáng tạo, trong khi giá trị Temperature thấp giúp duy trì kết quả chính xác đặc biệt quan trọng khi tạo dữ liệu có cấu trúc như JSON. MAX_TOKENS xác định độ dài tối đa của đầu ra, giúp cân bằng giữa hiệu quả chi phí (cost-efficiency) và độ đầy đủ của dữ liệu được tạo ra.
Bước 2: Định nghĩa lược đồ
Việc định nghĩa một schema là rất cần thiết để tạo điều kiện cho các đầu ra có cấu trúc và có thể dự đoán được từ mô hình, duy trì tính toàn vẹn của dữ liệu và cho phép tích hợp API liền mạch. Nếu không có schema được định nghĩa rõ ràng, các mô hình có thể tạo ra phản hồi không nhất quán hoặc không đầy đủ, dẫn đến lỗi trong các ứng dụng ở phía sau (downstream applications). JSON schema tiêu chuẩn được sử dụng trong đoạn mã dưới đây đóng vai trò như một bản thiết kế (blueprint) cho việc tạo dữ liệu có cấu trúc, hướng dẫn mô hình cách định dạng đầu ra của nó với các chỉ dẫn rõ ràng.
Chúng ta sẽ tạo một lược đồ cho dữ liệu đánh giá của khách hàng gồm ba trường: reviewId (string, tối đa 50 ký tự), sentiment (number, giá trị từ -1 đến 1), và summary (string, tối đa 200 ký tự).

Bước 3: Soạn thảo Prompt
Để tạo ra một phản hồi nhất quán, có cấu trúc và chính xác, prompt (câu lệnh đầu vào cho mô hình) cần phải rõ ràng và được xây dựng cẩn thận. Các mô hình ngôn ngữ lớn (LLM) phụ thuộc vào đầu vào chính xác để tạo một đầu ra đáng tin cậy. Prompt được thiết kế kém có thể dẫn đến việc mơ hồ về ngữ nghĩa, gây lỗi logic hoặc thông tin thiếu, sai định dạng làm phá vỡ luồng xử lý có cấu trúc, do đó, ta cần tuân theo một số nguyên tắc thiết kế prompt hiệu quả:
- Làm rõ vai trò và mục tiêu của AI để tránh gây mơ hồ về ngữ nghĩa.
- Chia nhỏ nhiệm vụ thành các bước đánh số cụ thể để quản lý các bước rõ ràng hơn.
- Chỉ ra rằng sẽ có một lược đồ JSON được cung cấp (ở Bước 5) để duy trì mô hình tuân theo một cấu trúc cụ thể và hợp lệ.
- Dùng kỹ thuật one-shot prompting (gợi mẫu một lần) bằng cách cung cấp một ví dụ đầu ra mẫu giúp mô hình học theo; có thể thêm nhiều ví dụ nếu cần tính nhất quán cao, nhưng đừng quá nhiều kẻo làm giảm khả năng xử lý linh hoạt với đầu vào mới.
- Xác định rõ cách xử lý dữ liệu thiếu hoặc không hợp lệ.

Bước 4: Tích hợp dữ liệu đầu vào
Để minh họa ở bước này, chúng ta sẽ chèn một đoạn văn bản đánh giá vào trong prompt bằng cách khai báo như một biến trong mã Python:

Tách dữ liệu đầu vào bằng thẻ <input> giúp nâng cao độ rõ ràng và dễ đọc, đồng thời giúp mô hình dễ dàng xác định và tham chiếu đến dữ liệu cần xử lý. Đây là một đoạn dữ liệu được mã hóa cứng (hardcoded) mô phỏng cho việc tích hợp dữ liệu trong thực tế. Trong môi trường sản xuất, bạn hoàn toàn có thể tự động hóa việc nhập dữ liệu đầu vào thông qua API hoặc các biểu mẫu người dùng gửi lên.
Bước 5: Gọi Bedrock
Trong phần này, chúng ta sẽ xây dựng một yêu cầu gửi đến Bedrock bằng cách định nghĩa một đối tượng body gồm có lược đồ JSON, prompt, và dữ liệu đánh giá chúng ta đã xây dựng trước đó. Việc xây dựng một yêu cầu có cấu trúc như vậy đảm bảo rằng mô hình nhận được hướng dẫn rõ ràng, tuân theo lược đồ được định nghĩa trước, xử lý dữ liệu đầu vào mẫu một cách chính xác. Sau khi request đã được chuẩn bị đầy đủ, chúng ta sẽ gọi đến Amazon Bedrock để mô hình tạo ra phản hồi dưới dạng JSON có cấu trúc.

Chúng ta dùng lại các hằng số như MAX_TOKENS, TEMPERATURE, và MODEL_ID đã định nghĩa ở bước 1. Đối tượng thân sẽ chứa các cấu hình suy luận (các thông số bạn truyền vào khi gọi mô hình để mô hình biết cách xử lý yêu cầu của bạn) quan trọng như anthropic_version để đảm bảo tương thích với mô hình, và mảng messages chứa một tin nhắn duy nhất nhằm cung cấp cho mô hình các hướng dẫn nhiệm vụ, lược đồ dữ liệu và dữ liệu đầu vào cần xử lý. Trường role cho biết ai là “người nói” trong cuộc hội thoại với mô hình, với giá trị ‘user’ đại diện cho chương trình gửi yêu cầu. Ngoài ra, thay vì tách riêng chỉ dẫn, lược đồ và dữ liệu, bạn cũng có thể gộp tất cả vào một prompt văn bản duy nhất, cách làm này đơn giản để quản lý nhưng kém tính mô-đun (less modular) hơn.
Cuối cùng, chúng ta sử dụng phương thức client.invoke_model để gửi yêu cầu. Sau khi được gọi để thực thi, mô hình sẽ xử lý yêu cầu, và dữ liệu JSON cần được trích xuất một cách chính xác từ phản hồi của Bedrock (phần này không được giải thích chi tiết tại đây). Ví dụ:
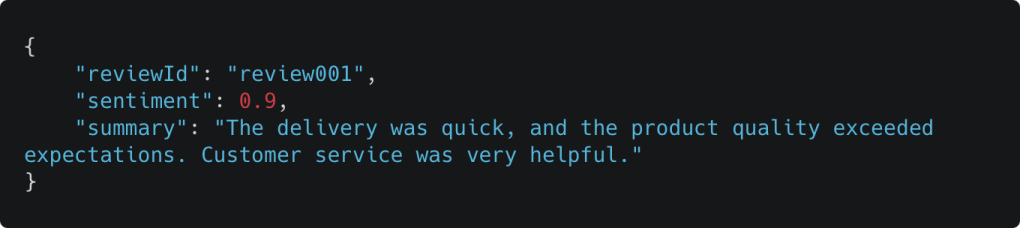
Sử dụng công cụ với Amazon Bedrock Converse API
Trong phần trước, chúng ta đã khám phá một giải pháp sử dụng Prompt Engineering với Amazon Bedrock. Bây giờ, hãy cùng tìm hiểu một cách tiếp cận thay thế để tạo ra các phản hồi có cấu trúc, sử dụng Bedrock Converse API.
Chúng ta sẽ mở rộng giải pháp trước đó bằng cách sử dụng Amazon Bedrock Converse API, một giao diện thống nhất được thiết kế để hỗ trợ các cuộc hội thoại nhiều lượt với các mô hình Generative AI. API này trừu tượng hóa các cấu hình đặc thù của từng mô hình, bao gồm các tham số suy luận (inference parameters), giúp việc tích hợp trở nên đơn giản hơn.
Một tính năng chính của Converse API là Tool Use (hay còn gọi là Function Calling), cho phép mô hình gọi và thực thi các công cụ bên ngoài, như gọi một API bên ngoài. Phương pháp này hỗ trợ tích hợp chuẩn JSON schema trực tiếp vào định nghĩa công cụ, giúp đầu ra của mô hình phù hợp chính xác với các định dạng đã xác định trước. Không phải mô hình Bedrock nào cũng hỗ trợ Tool Use, do đó, hãy đảm bảo bạn kiểm tra xem mô hình bạn chọn có tương thích với tính năng này không.
Dựa trên các dữ liệu đã được định nghĩa trước đó, đoạn code sau cung cấp một ví dụ đơn giản về Tool Use, áp dụng cho bài toán phân tích đánh giá của khách hàng:

Trong đoạn mã này, tool_list định nghĩa một công cụ phân tích đánh giá khách hàng tùy chỉnh với lược đồ đầu vào và mục đích rõ ràng, trong khi message chứa các hướng dẫn và dữ liệu đầu vào đã xác định trước đó. Khác với ví dụ về Prompt Engineering trước đó, lần này schema JSON không được nhúng vào prompt, mà được khai báo trực tiếp trong định nghĩa của tool. Cuối cùng, lệnh client.converse kết hợp các thành phần này, chỉ định công cụ sẽ sử dụng cùng với cấu hình suy luận,, để tạo ra đầu ra phù hợp với lược đồ và nhiệm vụ đã đề ra.
Sau khi khám phá hai phương pháp Prompt Engineering và Tool Use trong các giải pháp Bedrock nhằm tạo phản hồi có cấu trúc, bây giờ chúng ta hãy đánh giá hiệu suất của các mô hình nền tảng (foundation models) khi áp dụng những phương pháp này.
Kết quả kiểm tra: Kết quả từ Claude Models trên Amazon Bedrock
Hiểu được năng lực của các mô hình nền tảng (foundation models) trong việc tạo phản hồi có cấu trúc là điều cần thiết để đảm bảo tính ổn định, tối ưu hóa hiệu suất, và có thể xây dựng các ứng dụng Generative AI quy mô lớn và bền vững trong tương lai với Amazon Bedrock. Để đánh giá mức độ hiệu quả trong việc tạo đầu ra có cấu trúc, nhóm nghiên cứu đã tiến hành kiểm thử chuyên sâu với các mô hình Claude của Anthropic, so sánh hai cách tiếp cận: prompt-based (dựa trên prompt) và tool-based (dựa trên công cụ), được thực thi 1.000 lần lặp trên mỗi mô hình. Mỗi vòng lặp thử nghiệm xử lý 100 mục được tạo ngẫu nhiên, nhằm đảm bảo phạm vi kiểm thử rộng với nhiều biến thể đầu vào khác nhau. Các ví dụ được trình bày trước đó trong blog này đã được đơn giản hóa có chủ đích để phục vụ mục đích minh họa, trong đó Amazon Bedrock hoạt động mượt mà, không gặp sự cố. để đánh giá các mô hình tốt hơn trong các thách thức thực tế, chúng tôi đã sử dụng một schema phức tạp hơn, bao gồm các cấu trúc lồng nhau, mảng và nhiều kiểu dữ liệu khác nhau nhằm phát hiện các trường hợp đặc biệt và vấn đề tiềm ẩn. Các đầu ra được kiểm tra để đảm bảo tuân thủ định dạng và cấu trúc JSON đã định nghĩa, đồng thời duy trì tính nhất quán và độ chính xác. Biểu đồ sau đây tổng hợp kết quả, thể hiện số lượng phản hồi JSON hợp lệ và thành công từ mỗi mô hình trong hai phương pháp đã trình bày: Prompt Engineering và Tool Use.
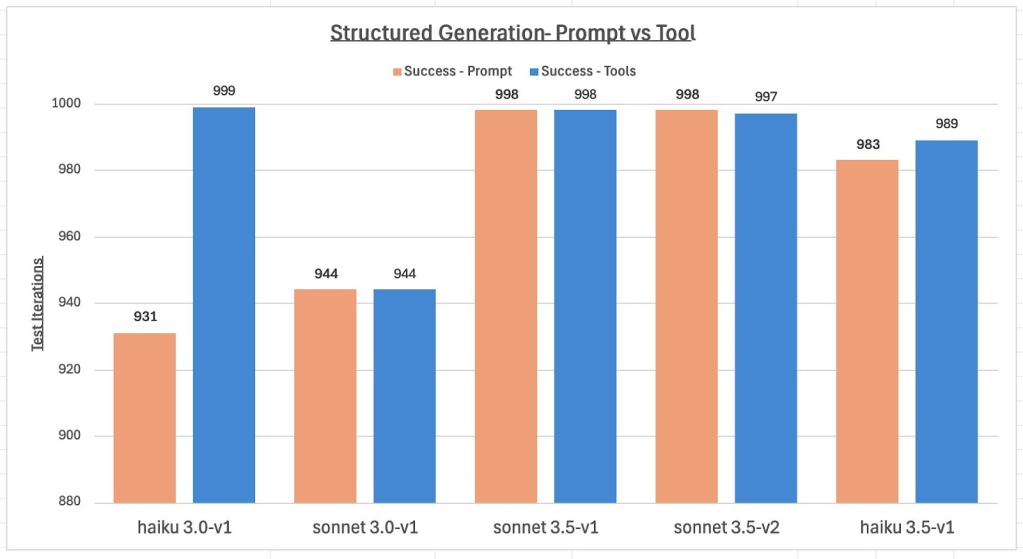
Kết quả cho thấy tất cả các mô hình đều đạt tỷ lệ thành công trên 93% ở cả hai phương pháp, trong đó phương pháp Tool Use liên tục vượt trội so với cách tiếp cận dựa trên prompt. Mặc dù bài đánh giá được thực hiện với một lược đồ JSON có cấu trúc phức tạp, nhưng với các lược đồ đơn giản hơn, số lỗi phát sinh giảm đáng kể, thậm chí gần như không có. Các bản cập nhật mô hình trong tương lai được kỳ vọng sẽ tiếp tục cải thiện hiệu suất và độ tin cậy.
Kết luận
Trong bài viết này, chúng tôi đã trình bày hai phương pháp để tạo phản hồi có cấu trúc bằng Amazon Bedrock: Prompt Engineering và Tool Use với Converse API. Prompt Engineering là một phương pháp linh hoạt, dùng được với các mô hình trên Bedrock (bao gồm cả các mô hình không hỗ trợ Tool Use), và xử lý được nhiều loại lược đồ khác nhau (như lược đồ Open API), nên rất phù hợp để bắt đầu. Tuy nhiên, phương pháp này có thể thiếu ổn định, đòi hỏi prompt phải được thiết kế chính xác và thường gặp khó khăn khi xử lý các yêu cầu phức tạp. Ngược lại, Tool Use mang lại độ tin cậy cao hơn, kết quả nhất quán hơn, tích hợp dễ dàng với API, và cho phép kiểm tra tính hợp lệ của lược đồ JSON ngay trong thời gian chạy.
Để đơn giản hóa, bài viết này không trình bày một vài lĩnh vực khác. Các kỹ thuật khác để tạo phản hồi có cấu trúc bao gồm sử dụng các mô hình có hỗ trợ tích hợp cho các định dạng phản hồi có thể cấu hình (configurable response formats), hoặc ứng dụng kỹ thuật constraint decoding (giải mã có ràng buộc) với các thư viện bên thứ ba như LMQL. Việc tạo dữ liệu có cấu trúc bằng GenAI có thể gặp một số khó khăn như JSON không hợp lệ, thiếu trường thông tin, hoặc lỗi định dạng. Để đảm bảo tính toàn vẹn dữ liệu và xử lý các lỗi không mong muốn (ví dụ: đầu ra không đúng định dạng, API lỗi), việc xây dựng cơ chế kiểm soát lỗi hiệu quả, kiểm thử toàn diện và xác thực đầu ra là rất cần thiết.
Để trải nghiệm các kỹ thuật Bedrock trong bài viết, bạn có thể làm theo hướng dẫn Run example Amazon Bedrock API requests through the AWS SDK for Python (Boto3).Với chính sách tính phí theo mức sử dụng, bạn chỉ bị tính chi phí khi thực hiện lệnh gọi API, nên hầu như không cần dọn dẹp tài nguyên sau khi thử nghiệm. Để tìm hiểu thêm về các phương pháp tối ưu, hãy tham khảo tài liệu hướng dẫn Bedrock prompt engineering guidelines và hướng dẫn sử dụng cụ thể theo từng mô hình, ví dụ như Anthropic’s best practices.
Dữ liệu có cấu trúc chính là chìa khóa để khai thác tiềm năng của Generative AI trong các kịch bản thực tế như APIs, , tác vụ phân tích dữ liệu đến giao diện người dùng phong phú, vượt xa giới hạn của trò chuyện văn bản. Hãy bắt đầu sử dụng Amazon Bedrock ngay hôm nay để tận dụng toàn diện khả năng tạo phản hồi có cấu trúc một cách đáng tin cậy.
Về các tác giả

Adam Nemeth
Adam Nemeth là Senior Solutions Architect tại AWS, nơi anh hỗ trợ các khách hàng trong ngành tài chính toàn cầu áp dụng điện toán đám mây thông qua định hướng kiến trúc và hỗ trợ kỹ thuật. Với hơn 24 năm kinh nghiệm trong lĩnh vực CNTT, Adam từng làm việc tại ngân hàng UBS trước khi gia nhập AWS. Anh hiện sống tại Thụy Sĩ cùng vợ và ba người con.

Dominic Searle
Dominic Searle là Senior Solutions Architect tại Amazon Web Services, nơi anh đồng hành cùng các khách hàng thuộc lĩnh Dịch vụ tài chính toàn cầu trong hành trình tích hợp Generative AI vào chiến lược công nghệ của họ. Dominic đam mê cung cấp hướng dẫn kỹ thuật để giúp khách hàng khai thác hiệu quả các dịch vụ AWS nhằm giải quyết các bài toán kinh doanh thực tiễn.
