Tác giả: Yanyan Zhang, Ishan Singh, David Yan, Shreeya Sharma, Panpan Xu, Yawei Wang và Yijun Tian
Ngày: 30 tháng 4 năm 2025
Danh mục: Amazon Bedrock, Foundation models, Generative AI, Launch
Amazon Bedrock Model Distillation đã được cung cấp rộng rãi và giải quyết thách thức cơ bản mà nhiều tổ chức phải đối mặt khi triển khai generative AI: cách duy trì hiệu suất cao, đồng thời giảm chi phí và độ trễ. Kỹ thuật này chuyển giao kiến thức từ foundation models (foundation models – FMs) lớn hơn, năng lực cao hơn (đóng vai trò mô hình thầy – teacher model), sang các mô hình nhỏ hơn, hiệu quả hơn (gọi là mô hình trò – student model), tạo ra các mô hình chuyên biệt vượt trội trong các nhiệm vụ cụ thể. Trong bài đăng này, chúng tôi nêu bật các kỹ thuật tăng cường dữ liệu nâng cao và cải tiến hiệu suất trong Amazon Bedrock Model Distillation với dòng mô hình Llama của Meta.
Khả năng gọi hàm của tác tử (agent function calling) đại diện cho một năng lực quan trọng của các ứng dụng AI hiện đại, cho phép các mô hình tương tác với các công cụ, cơ sở dữ liệu và API bên ngoài bằng cách xác định chính xác thời điểm và cách gọi các chức năng cụ thể. Mặc dù các mô hình lớn hơn thường vượt trội trong việc xác định các hàm thích hợp để gọi và xây dựng các tham số thích hợp, nhưng chúng đi kèm với chi phí và độ trễ cao hơn. Amazon Bedrock Model Distillation hiện cho phép các mô hình nhỏ hơn đạt được độ chính xác khi gọi hàm tương đương đồng thời mang lại thời gian phản hồi nhanh hơn đáng kể và chi phí vận hành thấp hơn.
Giá trị đề xuất (value proposition) rất thuyết phục: các tổ chức có thể triển khai các agent AI với độ chính xác cao trong việc lựa chọn công cụ và tạo tham số, đồng thời hưởng lợi từ dấu chân tài nguyên (footprint) nhỏ hơn và thông lượng (throughput) cao hơn của các mô hình nhỏ gọn. Sự tiến bộ này làm cho các kiến trúc agent phức tạp trở nên dễ tiếp cận hơn và khả thi về mặt kinh tế trên nhiều ứng dụng và quy mô triển khai hơn.
Điều kiện tiên quyết
Để triển khai thành công Amazon Bedrock Model Distillation, bạn cần đáp ứng một số yêu cầu. Chúng tôi khuyên bạn nên tham khảo Submit a model distillation job in Amazon Bedrock trong tài liệu chính thức của AWS để biết thông tin cập nhật và toàn diện nhất.
Các yêu cầu chính bao gồm:
- AWS account đang hoạt động
- Các mô hình thầy (teacher model) và mô hình trò (student model) đã chọn được kích hoạt trong tài khoản của bạn (xác minh trên trang Model access của console Amazon Bedrock)
- Một Bucket Amazon S3 để lưu trữ bộ dữ liệu đầu vào và các artifact đầu ra.
- IAM permissions phù hợp:
- Trust relationship cho phép Amazon Bedrock đảm nhận vai trò
- Quyền truy cập S3 cho dữ liệu đầu vào/đầu ra và nhật ký gọi
- Quyền suy luận mô hình khi sử dụng hồ sơ suy luận
Nếu bạn đang sử dụng nhật ký lệnh gọi lịch sử, hãy xác nhận xem ghi nhật ký lệnh gọi mô hình đã được bật trong cài đặt Amazon Bedrock của bạn, với S3 được chọn làm đích ghi nhật ký hay chưa.
Chuẩn bị dữ liệu của bạn
Việc chuẩn bị dữ liệu hiệu quả rất quan trọng để chắt lọc thành công khả năng gọi chức năng agent. Amazon Bedrock cung cấp hai phương pháp chính để chuẩn bị dữ liệu đào tạo của bạn: tải tệp JSONL lên Amazon S3 hoặc sử dụng nhật ký gọi lịch sử. Dù chọn phương pháp nào, bạn cũng cần chuẩn bị định dạng phù hợp cho đặc tả công cụ (tool specifications) để việc chưng cất (distillation) khả năng gọi hàm của tác tử (agent function calling) diễn ra thành công.
Yêu cầu định dạng thông số kỹ thuật công cụ
Đối với chưng cất gọi chức năng agent, Amazon Bedrock yêu cầu cung cấp thông số kỹ thuật của công cụ như một phần của dữ liệu đào tạo của bạn. Các thông số kỹ thuật này phải được mã hóa dưới dạng văn bản trong hệ thống hoặc thông báo người dùng về dữ liệu đầu vào của bạn. Ví dụ được hiển thị là sử dụng định dạng gọi hàm của họ mô hình Llama:
system: ‘You are an expert in composing functions. You are given a question and a set of possible functions. Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
Here is a list of functions in JSON format that you can invoke.
[
{
"name": "lookup_weather",
"description": "Lookup weather to a specific location",
"parameters": {
"type": "dict",
"required": [
"city"
],
"properties": {
"location": {
"type": "string",
},
"date": {
"type": "string",
}
}
}
}
]'
user: "What's the weather tomorrow?"Cách tiếp cận này cho phép mô hình học cách diễn giải định nghĩa của công cụ và thực hiện các lệnh gọi hàm phù hợp dựa trên truy vấn của người dùng.Sau đó, khi chạy suy luận (inference) trên mô hình đích đã chắt lọc, chúng tôi khuyên bạn nên giữ định dạng lời nhắc (prompt) nhất quán với dữ liệu đầu vào dùng để chắt lọc. Điều này cung cấp hiệu suất tối ưu bằng cách duy trì cùng một cấu trúc mà mô hình đã được đào tạo.
Chuẩn bị dữ liệu bằng cách tải lên Amazon S3 JSONL
Khi tạo tệp JSONL để chưng cất, mỗi bản ghi phải tuân theo cấu trúc sau:
{
"schemaVersion": "bedrock-conversation-2024",
"system": [
{
"text": 'You are an expert in composing functions. You are given a question and a set of possible functions. Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
Here is a list of functions in JSON format that you can invoke.
[
{
"name": "lookup_weather",
"description": "Lookup weather to a specific location",
"parameters": {
"type": "dict",
"required": [
"city"
],
"properties": {
"location": {
"type": "string",
},
"date": {
"type": "string",
}
}
}
}
]'
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": "What's the weather tomorrow?"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "[lookup_weather(location=\"san francisco\", date=\"tomorrow\")]"
}
]
}
]
}Mỗi bản ghi phải bao gồm trường schemaVersion với giá trị là bedrock-conversation-2024. Trường system chứa các hướng dẫn cho mô hình, bao gồm cả các công cụ có sẵn. Trường messages chứa cuộc hội thoại, với đầu vào bắt buộc từ người dùng và phản hồi tùy chọn của trợ lý.
Sử dụng nhật ký gọi lịch sử
Ngoài ra, bạn có thể sử dụng nhật ký lời gọi (invocation logs) lịch sử của mô hình trên Amazon Bedrock cho việc chưng cất. Cách tiếp cận này sử dụng dữ liệu sản xuất thực tế từ ứng dụng của bạn, nắm bắt các kịch bản gọi hàm trong thực tế. Để sử dụng phương pháp này:
- Bật tính năng ghi nhật ký lệnh gọi trong cài đặt tài khoản Amazon Bedrock của bạn, chọn S3 làm đích ghi nhật ký của bạn.
- Thêm siêu dữ liệu (metadata) vào các lệnh gọi mô hình của bạn bằng cách sử dụng trường requestMetadata để phân loại các tương tác. Ví dụ:
"requestMetadata": {
"project": "WeatherAgent",
"intent": "LocationQuery",
"priority": "High"
}- Khi tạo công việc chưng cất của bạn, hãy chỉ định các bộ lọc để chọn những log (nhật ký) có liên quan dựa trên metadata:
"requestMetadataFilters": {
"equals": {"project": "WeatherAgent"}
}Việc sử dụng nhật ký gọi hàm lịch sử cho phép bạn chắt lọc kiến thức từ các tải công việc sản xuất (production workloads), cho phép mô hình học hỏi từ các tương tác thực của người dùng và lệnh gọi hàm.
Cải tiến chưng cất mô hình
Mặc dù quy trình cơ bản để tạo công việc chưng cất mô hình vẫn tương tự như những gì chúng tôi đã mô tả trong previous blog post, mình, nhưng Amazon Bedrock Model Distillation giới thiệu một số cải tiến khi dịch vụ chính thức ra mắt (general availability) giúp cải thiện trải nghiệm, khả năng và tính minh bạch của dịch vụ.
Hỗ trợ mô hình mở rộng
Với lần ra mắt chính thức (general availability), chúng tôi đã mở rộng các tùy chọn mô hình có sẵn để chưng cất. Ngoài các mô hình được hỗ trợ trong giai đoạn xem trước (preview), khách hàng hiện có thể sử dụng:
- Nova Premier làm mô hình thầy (teacher model) cho việc chưng cất các mô hình Nova Pro/Lite/Micro
- Anthropic Claude Sonnet 3.5 v2 làm mô hình thầy cho việc chưng cất Claude Haiku.
- Llama 3.3 70B của Meta làm mô hình thầy và 3.2 1B, 3B làm mô hình trò (student models) cho việc chưng cất mô hình Meta.
Lựa chọn rộng hơn này cho phép khách hàng tìm thấy sự cân bằng giữa hiệu suất và hiệu quả trong các trường hợp sử dụng khác nhau. Để biết danh sách các kiểu máy được hỗ trợ mới nhất, hãy tham khảo Amazon Bedrock documentation.
Công nghệ tổng hợp dữ liệu tiên tiến
Amazon Bedrock áp dụng các kỹ thuật tổng hợp dữ liệu độc quyền trong quá trình chưng cất cho một số trường hợp sử dụng nhất định. Sự đổi mới khoa học này tự động tạo thêm các ví dụ huấn luyện (training examples) để nâng cao khả năng tạo phản hồi tốt hơn của mô hình trò.
Cụ thể với việc gọi hàm của agent bằng các mô hình Llama, các phương pháp tăng cường dữ liệu (data augmentation) giúp thu hẹp khoảng cách về hiệu suất giữa mô hình thầy và mô hình trò so với phương pháp chưng cất cơ bản (vanilla distillation – tức là gán nhãn trực tiếp cho dữ liệu đầu vào bằng phản hồi của mô hình thầy, sau đó huấn luyện mô hình trò bằng phương pháp tinh chỉnh có giám sát – supervised fine-tuning). Điều này giúp hiệu suất của các mô hình trò gần tương đương với mô hình thầy sau khi chưng cất, đồng thời vẫn giữ được các lợi thế về chi phí và độ trễ của một mô hình nhỏ hơn.
Tăng cường khả năng hiển thị của quá trình huấn luyện
Chưng cất mô hình Amazon Bedrock hiện cung cấp khả năng hiển thị tốt hơn về quy trình đào tạo thông qua nhiều cải tiến:
- Minh bạch hóa dữ liệu tổng hợp (Synthetic data transparency) – Amazon Bedrock Model Distillation giờ đây cung cấp các mẫu dữ liệu huấn luyện được tạo tự động, giúp nâng cao hiệu suất của mô hình. Đối với hầu hết các dòng mô hình, tối đa 50 lời nhắc mẫu được xuất (tối đa 25 đối với mô hình Anthropic), cung cấp cho bạn cái nhìn sâu sắc về cách mô hình của bạn đã được huấn luyện, từ đó hỗ trợ đáp ứng các yêu cầu tuân thủ nội bộ (internal compliance requirements).
- Báo cáo thông tin chi tiết về lời nhắc (prompt insights): một báo cáo tóm tắt về các lời nhắc được chấp nhận để chắt lọc sẽ được cung cấp, cùng với khả năng hiển thị chi tiết về các lời nhắc đã bị từ chối và lý do cụ thể cho việc từ chối. Cơ chế phản hồi này giúp bạn xác định và khắc phục các lời nhắc có vấn đề để cải thiện tỷ lệ chưng cất thành công của bạn.
Những thông tin chi tiết này được lưu trữ trong vùng lưu trữ S3 đầu ra được chỉ định trong quá trình tạo công việc, giúp bạn có bức tranh rõ ràng hơn về quá trình chuyển giao kiến thức.
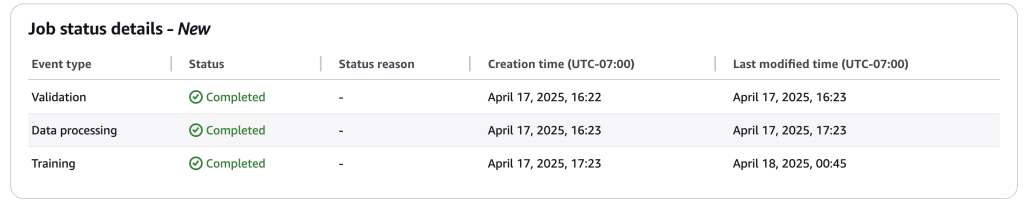
Cải thiện báo cáo trạng thái công việc
Amazon Bedrock Model Distillation cũng cung cấp báo cáo trạng thái công việc đào tạo nâng cao để cung cấp thông tin chi tiết hơn về vị trí của công việc chưng cất mô hình của bạn trong quy trình. Thay vì các chỉ báo trạng thái ngắn gọn như “Đang tiến hành” hoặc “Hoàn thành”, hệ thống hiện cung cấp các cập nhật trạng thái chi tiết hơn, giúp bạn theo dõi tốt hơn tiến độ của công việc chưng cất.
Bạn có thể theo dõi chi tiết trạng thái của công việc trong cả AWS Management Console và AWS SDK.
Cải thiện hiệu suất và lợi ích
Sau khi đã tìm hiểu về những cải tiến trong Amazon Bedrock Model Distillation, chúng ta sẽ xem xét những lợi ích mà các khả năng này mang lại, đặc biệt là cho các trường hợp sử dụng gọi hàm cho agent (agent function calling).
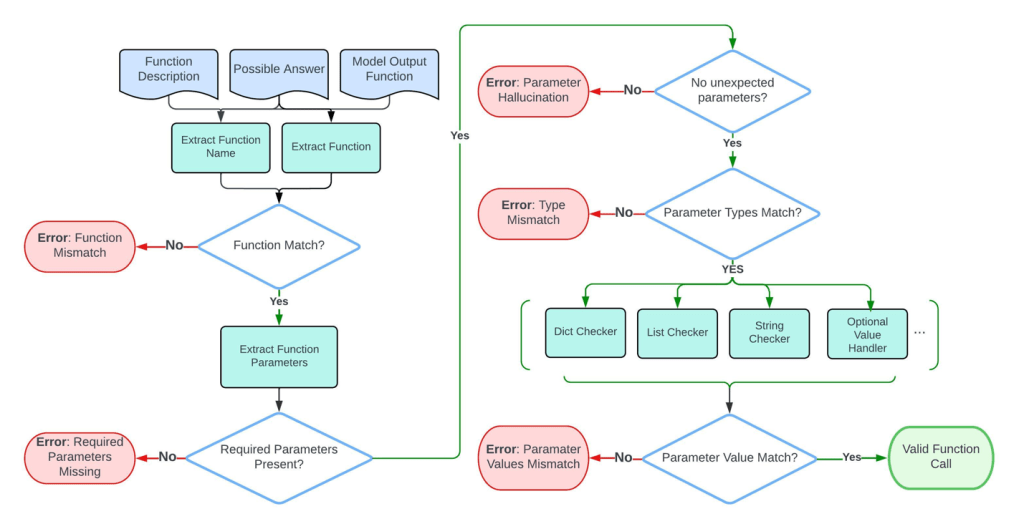
Chỉ số đánh giá
Chúng tôi sử dụng **cây cú pháp trừu tượng (abstract syntax tree – AST)** để đánh giá hiệu suất của việc gọi hàm. AST sẽ phân tích cú pháp (parse) lệnh gọi hàm được tạo và thực hiện đánh giá chi tiết về tính chính xác của tên hàm, giá trị tham số và kiểu dữ liệu được tạo ra, theo quy trình sau:
- Khớp hàm (Function matching) – Kiểm tra xem tên hàm dự đoán có phù hợp với một trong các câu trả lời có thể có hay không
- Khớp tham số bắt buộc (Required parameter matching) – Trích xuất các đối số (arguments) từ AST và kiểm tra xem mỗi tham số có khớp chính xác với một trong các câu trả lời khả thi hay không.
- Khớp kiểu và giá trị tham số (Parameter type and value matching) – Kiểm tra xem các giá trị và kiểu dữ liệu của tham số được dự đoán có chính xác hay không.
Quá trình này được minh họa trong sơ đồ sau đây từ Gorilla: Large Language Model Connected with Massive APIs.
Kết quả thử nghiệm
Để đánh giá việc chưng cất mô hình cho trường hợp sử dụng gọi hàm, chúng tôi đã dùng BFCL v2 dataset và lọc nó thành các miền cụ thể (trong trường hợp này là giải trí) để phù hợp với trường hợp sử dụng điển hình của tùy chỉnh mô hình. Chúng tôi cũng chia dữ liệu thành các tập huấn luyện (training set) và tập thử nghiệm (test set), thực hiện chưng cất trên dữ liệu huấn luyện, đồng thời chạy các đánh giá trên tập thử nghiệm. Cả bộ đào tạo và bộ thử nghiệm đều chứa khoảng 200 ví dụ. Chúng tôi đã đánh giá hiệu suất của một số mô hình, bao gồm mô hình giáo viên (Llama 405B), mô hình học sinh cơ sở (Llama 3B), phiên bản chưng cất truyền thống (vanilla distillation) trong đó Llama 405B được chưng cất thành Llama 3B mà không cần tăng cường dữ liệu và phiên bản chưng cất nâng cao được nâng cao với các kỹ thuật tăng cường dữ liệu độc quyền.
Đánh giá tập trung vào các hạng mục đơn giản (simple) và đa lựa chọn (multiple) được định nghĩa trong bộ dữ liệu BFCL V2. Như thể hiện trong biểu đồ sau, có sự chênh lệch về hiệu suất giữa mô hình thầy và mô hình trò cơ sở trên cả hai hạng mục. Phương pháp chưng cất cơ bản (vanilla distillation) đã cải thiện đáng kể hiệu suất của mô hình trò cơ sở. Ở hạng mục simple, hiệu suất tăng từ 0,478 lên 0,783, thể hiện sự cải thiện tương đối 63,8%. Trong hạng multiple , điểm số tăng từ 0,586 lên 0,742, đây là sự cải thiện tương đối 26,6%. Trung bình, phương pháp chưng cất vanilla giúp cải thiện 45,2% trên cả hai hạng mục.
Việc áp dụng các kỹ thuật tăng cường dữ liệu (data augmentation) đã mang lại những lợi ích vượt trội so với cách chưng cất truyền thống. Trong hạng mục đơn giản (simple), hiệu suất cải thiện từ 0,783 lên 0,826, và trong hạng mục đa lựa chọn (multiple), từ 0,742 lên 0,828. Trung bình, điều này dẫn đến sự cải thiện tương đối 5,8% trên cả hai danh mục, được tính bằng giá trị trung bình của mức tăng tương đối trong mỗi loại. Những kết quả này làm nổi bật hiệu quả của cả chiến lược chưng cất và tăng cường trong việc nâng cao hiệu suất mô hình học sinh cho các nhiệm vụ gọi chức năng.

Chúng tôi trình bày so sánh độ trễ (latency) và tốc độ đầu ra (output speed) của các mô hình khác nhau trong hình dưới đây. Dữ liệu được thu thập từ Artificial Analysis , một trang web chuyên phân tích độc lập các mô hình và nhà cung cấp AI vào ngày 4 tháng 4 năm 2025. Chúng tôi nhận thấy rằng có một xu hướng rõ ràng về độ trễ và tốc độ tạo khi các mô hình Llama có kích thước khác nhau được đánh giá. Đáng chú ý, mô hình Llama 3.1 8B cho tốc độ đầu ra cao nhất, làm cho nó hiệu quả nhất về khả năng phản hồi và thông lượng. Tương tự, Llama 3.2 3B hoạt động tốt với độ trễ cao hơn một chút nhưng vẫn duy trì tốc độ đầu ra ổn định. Mặt khác, Llama 3.1 70B và Llama 3.1 405B lại có độ trễ cao hơn nhiều với tốc độ đầu ra thấp hơn đáng kể, cho thấy chi phí hiệu suất đáng kể ở kích thước mô hình cao hơn. So với Llama 3.1 405B, Llama 3.2 3B giảm 72% độ trễ và cải thiện 140% tốc độ đầu ra. Những kết quả này cho thấy rằng các mô hình nhỏ hơn có thể phù hợp hơn với các ứng dụng mà tốc độ và khả năng phản hồi là rất quan trọng.
Ngoài ra, chúng tôi cũng báo cáo so sánh chi phí trên mỗi 1 triệu token các mô Llama khác nhau. Như thể hiện trong hình sau, rõ ràng là các mô hình nhỏ hơn (Llama 3.2 3B và Llama 3.1 8B) tiết kiệm chi phí hơn đáng kể. Khi kích thước mô hình tăng lên (Llama 3.1 70B và Llama 3.1 405B), mức gía cũng tăng mạnh. Sự gia tăng đáng kể này nhấn mạnh sự đánh đổi giữa độ phức tạp của mô hình và chi phí vận hành.
Các ứng dụng agent trong thế giới thực yêu cầu các mô hình LLM có thể đạt được sự cân bằng tốt giữa độ chính xác, tốc độ và chi phí. Kết quả này cho thấy rằng việc sử dụng một mô hình đã được chưng cất cho các ứng dụng agent sẽ giúp các nhà phát triển đạt được tốc độ và chi phí của các mô hình nhỏ hơn, trong khi vẫn có được độ chính xác tương tự như một mô hình thầy lớn hơn.

Kết thúc
Amazon Bedrock Model Distillation hiện đã được hiện đã chính thức ra mắt (generally available), mang lại cho các tổ chức một lộ trình thiết thực để triển khai các trải nghiệm agent mạnh mẽ mà không phải đánh đổi hiệu suất hay hiệu quả chi phí. Như đánh giá hiệu suất của chúng tôi đã chứng minh, các mô hình đã chắt lọc để gọi hàm có thể đạt được độ chính xác tương đương với các mô hình lớn gấp nhiều lần, đồng thời mang lại tốc độ suy luận nhanh hơn đáng kể và chi phí vận hành thấp hơn. Khả năng này cho phép triển khai các agent AI có thể tương tác chính xác với các công cụ và hệ thống bên ngoài trên các ứng dụng doanh nghiệp.
Bắt đầu sử dụng Amazon Bedrock Model Distillation ngay hôm nay thông qua Bảng điều khiển quản lý AWS hoặc API để chuyển đổi các ứng dụng AI tổng quát của bạn, bao gồm các trường hợp sử dụng agent, với sự cân bằng giữa độ chính xác, tốc độ và hiệu quả chi phí. Để biết các ví dụ triển khai, hãy xem các mẫu mã của chúng tôi trong kho lưu trữ GitHub amazon-bedrock-samples.
Phụ lục
Danh mục đơn giản BFCL V2
Định nghĩa: Danh mục đơn giản bao gồm các tác vụ trong đó người dùng được cung cấp một tài liệu hàm duy nhất (nghĩa là một định nghĩa hàm JSON) và mô hình dự kiến sẽ tạo ra chính xác một lệnh gọi hàm phù hợp với yêu cầu của người dùng. Đây là kịch bản cơ bản nhất và thường gặp phải, tập trung vào việc liệu mô hình có thể diễn giải chính xác một truy vấn người dùng đơn giản và ánh xạ nó đến hàm duy nhất có sẵn hay không, điền vào các tham số bắt buộc khi cần thiết.
# Example
{
"id": "live_simple_0-0-0",
"question": [
[{
"role": "user",
"content": "Can you retrieve the details for the user with the ID 7890, who has black as their special request?"
}]
],
"function": [{
"name": "get_user_info",
"description": "Retrieve details for a specific user by their unique identifier.",
"parameters": {
"type": "dict",
"required": ["user_id"],
"properties": {
"user_id": {
"type": "integer",
"description": "The unique identifier of the user. It is used to fetch the specific user details from the database."
},
"special": {
"type": "string",
"description": "Any special information or parameters that need to be considered while fetching user details.",
"default": "none"
}
}
}
}]
}BFCL V2 Hạng mục đa lựa chọn (multiple category)
Định nghĩa: Danh mục nhiều trình bày mô hình với một truy vấn người dùng và một số tài liệu chức năng (thường là hai đến bốn). Mô hình phải chọn hàm thích hợp nhất để gọi dựa trên ý định và ngữ cảnh của người dùng và sau đó tạo ra một lệnh gọi hàm duy nhất cho phù hợp. Danh mục này đánh giá khả năng của mô hình để hiểu ý định của người dùng, phân biệt giữa các chức năng tương tự và chọn kết quả phù hợp nhất từ nhiều tùy chọn.
{
"id": "live_multiple_3-2-0",
"question": [
[{
"role": "user",
"content": "Get weather of Ha Noi for me"
}]
],
"function": [{
"name": "uber.ride",
"description": "Finds a suitable Uber ride for the customer based on the starting location, the desired ride type, and the maximum wait time the customer is willing to accept.",
"parameters": {
"type": "dict",
"required": ["loc", "type", "time"],
"properties": {
"loc": {
"type": "string",
"description": "The starting location for the Uber ride, in the format of 'Street Address, City, State', such as '123 Main St, Springfield, IL'."
},
"type": {
"type": "string",
"description": "The type of Uber ride the user is ordering.",
"enum": ["plus", "comfort", "black"]
},
"time": {
"type": "integer",
"description": "The maximum amount of time the customer is willing to wait for the ride, in minutes."
}
}
}
}, {
"name": "api.weather",
"description": "Retrieve current weather information for a specified location.",
"parameters": {
"type": "dict",
"required": ["loc"],
"properties": {
"loc": {
"type": "string",
"description": "The location for which weather information is to be retrieved, in the format of 'City, Country' (e.g., 'Paris, France')."
}
}
}
}]
}Giới thiệu về các tác giả

Yanyan Zhang là Nhà khoa học dữ liệu AI tổng quát cấp cao tại Amazon Web Services, nơi cô đã làm việc trên các công nghệ AI/ML tiên tiến với tư cách là Chuyên gia AI tổng quát, giúp khách hàng sử dụng AI tổng quát để đạt được kết quả mong muốn. Yanyan tốt nghiệp Đại học Texas A & M với bằng Tiến sĩ Kỹ thuật Điện. Ngoài công việc, cô thích đi du lịch, tập thể dục và khám phá những điều mới.

Ishan Singh là Nhà khoa học dữ liệu AI tổng quát tại Amazon Web Services, nơi ông giúp khách hàng xây dựng các giải pháp và sản phẩm AI tổng quát sáng tạo và có trách nhiệm. Với nền tảng vững chắc về AI/ML, Ishan chuyên xây dựng các giải pháp AI tổng quát giúp thúc đẩy giá trị kinh doanh. Ngoài công việc, anh ấy thích chơi bóng chuyền, khám phá những con đường mòn dành cho xe đạp địa phương và dành thời gian cho vợ và chú chó của mình, Beau.

Yijun Tian là Nhà khoa học ứng dụng II tại AWS Agentic AI, nơi anh tập trung vào việc thúc đẩy nghiên cứu và ứng dụng cơ bản trong Mô hình ngôn ngữ lớn, Tác nhân và AI tổng quát. Trước khi gia nhập AWS, ông đã lấy bằng Tiến sĩ về Khoa học Máy tính tại Đại học Notre Dame.

Yawei Wang là Nhà khoa học ứng dụng tại AWS Agentic AI, đi đầu trong công nghệ AI tổng quát để xây dựng các sản phẩm AI thế hệ tiếp theo trong AWS. Ông cũng hợp tác với các đối tác kinh doanh của AWS để xác định và phát triển các giải pháp machine learning giải quyết các thách thức trong ngành trong thế giới thực.

David Yan là Kỹ sư nghiên cứu cấp cao tại AWS Agentic AI, dẫn đầu các nỗ lực trong việc tùy chỉnh và tối ưu hóa tác nhân. Trước đó, ông đã làm việc tại AWS Bedrock, dẫn đầu nỗ lực chắt lọc mô hình để giúp khách hàng tối ưu hóa độ trễ, chi phí và độ chính xác của LLM. Mối quan tâm nghiên cứu của ông bao gồm tác nhân AI, lập kế hoạch và dự đoán và tối ưu hóa suy luận. Trước khi gia nhập AWS, David đã làm việc về lập kế hoạch và dự đoán hành vi cho lái xe tự động trong Waymo. Trước đó, anh đã làm việc về hiểu ngôn ngữ tự nhiên cho đồ thị tri thức tại Google. David nhận bằng Thạc sĩ Kỹ thuật Điện của Đại học Stanford và bằng Cử nhân Vật lý của Đại học Bắc Kinh.

Panpan Xu là Nhà khoa học ứng dụng chính tại AWS Agentic AI, dẫn dắt một nhóm làm việc về Tùy chỉnh và Tối ưu hóa nhân viên. Trước đó, cô đã lãnh đạo một nhóm trong AWS Bedrock làm việc về nghiên cứu và phát triển các kỹ thuật tối ưu hóa suy luận cho các mô hình nền tảng, bao gồm các kỹ thuật cấp mô hình như chưng cất mô hình và thưa thớt đến tối ưu hóa nhận biết phần cứng. Mối quan tâm nghiên cứu trước đây của cô bao gồm nhiều chủ đề bao gồm khả năng diễn giải mô hình, mạng nơ-ron đồ thị, AI của con người và trực quan hóa dữ liệu tương tác. Trước khi gia nhập AWS, cô là nhà khoa học nghiên cứu hàng đầu tại Bosch Research và lấy bằng tiến sĩ khoa học máy tính tại Đại học Khoa học và Công nghệ Hồng Kông.

Shreeya Sharma là Giám đốc sản phẩm kỹ thuật cấp cao tại AWS, nơi cô đã làm việc để tận dụng sức mạnh của AI tổng quát để cung cấp các sản phẩm sáng tạo và lấy khách hàng làm trung tâm. Shreeya có bằng thạc sĩ của Đại học Duke. Ngoài công việc, cô thích đi du lịch, nhảy múa và ca hát.
