Tác giả: Scott Friedman, Murty Chappidi và Viraj Tilva
Ngày đăng: 08 Tháng 7 Năm 2025
Danh mục: Education, High Performance Computing, Partner solutions, Public Sector, Research

Hãy tưởng tượng bạn vừa có một khám phá đầy hứa hẹn trong nghiên cứu hệ gen, có thể dẫn đến một bước đột phá trong điều trị ung thư. Kết quả sơ bộ của bạn rất thuyết phục, nhưng việc chạy toàn bộ phân tích sẽ chiếm dụng toàn bộ cụm GPU của trường đại học trong ba tuần. Trong khi đó, các nhà nghiên cứu khác cũng đang xếp hàng phía sau bạn với những dự án cấp bách không kém. Liệu bạn có nên chờ đợi, có thể mất đà cho một khám phá cấp bách? Hay bạn nên thu hẹp quy mô phân tích và có nguy cơ bỏ lỡ những hiểu biết quan trọng?
Tình huống này xảy ra hàng ngày ở các viện nghiên cứu, buộc phải đưa ra lựa chọn bất khả thi giữa tham vọng và nguồn lực sẵn có.
Bài toán khó của điện toán nghiên cứu
Nhu cầu tính toán nghiên cứu vốn dĩ mang tính “bùng nổ” – bao gồm các giai đoạn nhu cầu tính toán cao trong các đột phá, hạn chót xin tài trợ hoặc nộp hồ sơ hội nghị, sau đó là các giai đoạn phân tích đòi hỏi ít tính toán hơn. Điều này tạo ra sự không phù hợp cơ bản với cơ sở hạ tầng điện toán hiệu năng cao (high performance computing) truyền thống.
Hầu hết các hệ thống HPC của trường đại học đều thiếu hụt tài nguyên một cách có chủ đích (under-provisioned by design), do hạn chế về ngân sách buộc các tổ chức phải khấu hao chi phí hệ thống trong vòng đời 3-5 năm, nghĩa là họ chỉ có thể chi trả cho các hệ thống có quy mô đáp ứng nhu cầu trung bình, chứ không phải nhu cầu cao điểm. Tình trạng thiếu hụt này đặc biệt nghiêm trọng đối với các tài nguyên chuyên biệt như các node GPU và hệ thống bộ nhớ cao, nơi bạn thường phải chờ đợi hàng ngày hoặc hàng tuần để truy cập vào phần cứng cụ thể mà khối lượng công việc của bạn yêu cầu.
Tại sao các phương pháp tiếp cận truyền thống lại không hiệu quả
Hệ thống có dung lượng cố định (fixed-capacity) không thể đáp ứng khi hàng trăm nhà nghiên cứu trải qua các đợt bùng nổ nhu cầu tính toán (computational bursts) vào những thời điểm không thể đoán trước. Ngay cả các hệ thống hoạt động ở mức sử dụng cao cũng không thể đáp ứng các nhu cầu bùng nổ chồng chéo từ cộng đồng nghiên cứu, tạo ra tình trạng tồn đọng hàng đợi hệ thống.
Ngân sách eo hẹp buộc phải cân nhắc giữa việc phục vụ các nhà nghiên cứu hiện tại và việc theo kịp sự phát triển nhanh chóng của phần cứng. Khi phần cứng chuyên dụng cho nhu cầu cao điểm phải được cân nhắc trong nhiều năm, các tổ chức chắc chắn sẽ không đầu tư đủ vào các nguồn lực mà các nhà nghiên cứu cần nhất. Trong khi đó, bạn chứng kiến đà nghiên cứu chậm lại khi những khám phá đột phá phải chờ đợi tài nguyên tính toán. Khoảng cách hiệu suất ngày càng lớn. Trong khi các hệ thống tại chỗ vẫn giữ nguyên giữa các chu kỳ làm mới lớn cứ sau 3-5 năm, cơ sở hạ tầng đám mây liên tục phát triển với những cải tiến phần cứng mới nhất, như minh họa trong hình dưới đây.
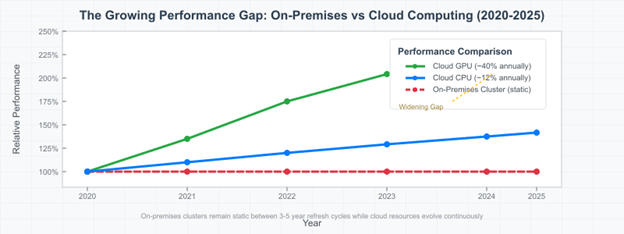
Hình 1. Sự phát triển phần cứng
HPC bursting hoạt động như thế nào
AWS đã tận dụng chuyên môn của Pariveda Solutions, một Đối tác Tư vấn Cao cấp của AWS, để phát triển một giải pháp HPC bursting linh hoạt, cho phép mở rộng động cơ sở hạ tầng tại chỗ (on-premises) của bạn lên đám mây. Phương pháp này cung cấp cơ sở hạ tầng HPC cốt lõi ổn định với khả năng linh hoạt xử lý nhu cầu cao điểm mà không cần đầu tư vốn lớn.
Chuyên môn của Pariveda về kiến trúc đám mây lai (hybrid cloud) và sự am hiểu sâu sắc về quy trình nghiên cứu học thuật cho phép giải pháp này thu hẹp khoảng cách giữa cơ sở hạ tầng tại chỗ (on-premises) và khả năng mở rộng của đám mây (cloud scalability), trong khi vẫn duy trì các công cụ và quy trình quen thuộc.
Giải pháp này tận dụng mã nguồn mở AWS Plugin for Slurm tích hợp liền mạch với Slurm để tự động hóa việc cung cấp và dọn dẹp tài nguyên đám mây. Slurm và plugin cung cấp khả năng kiểm soát ngân sách và các biện pháp bảo vệ để đảm bảo việc sử dụng đám mây có trách nhiệm.

Hình 2. Tổng quan kiến trúc HPC bursting
Như minh họa trong hình trước, quy trình làm việc của bạn hầu như không thay đổi. Bạn gửi tác vụ (jobs) đến các cụm tại chỗ (on-premises) hiện có bằng các công cụ quen thuộc. Bạn quyết định có nên chuyển tiếp tác vụ lên AWS hay không dựa trên nhu cầu nghiên cứu, điều kiện hàng đợi và tài nguyên khả dụng. Khi cần tài nguyên đám mây, tác vụ sẽ được truyền qua VPN Site-to-Site an toàn hoặc AWS Direct Connect . AWS tự động cung cấp các instance Amazon Elastic Compute Cloud (Amazon EC2) được điều chỉnh theo yêu cầu tác vụ của bạn, thực thi tác vụ và tắt các instances sau khi hoàn thành để giảm thiểu chi phí.

Hình 3. So sánh luồng nghiên cứu
Vượt xa năng lực: Tiếp cận các nguồn lực tiên tiến
HPC bursting giải quyết vấn đề thiếu hụt cơ bản bằng cách cho phép “chuyển đổi thời gian” khối lượng công việc. Thay vì phải chờ đợi hàng ngày hoặc hàng tuần trong hàng đợi để có được các tài nguyên chuyên biệt, bạn có thể truy cập ngay vào quy mô khổng lồ của AWS. Ngoài ra, việc bùng nổ còn cho phép truy cập vào các tài nguyên tiên tiến thường không có sẵn tại chỗ, bao gồm:
- GPU NVIDIA mới nhất
- CPU Intel và AMD với kiến trúc mới nhất
- Bộ xử lý Graviton dựa trên ARM cho khối lượng công việc được tối ưu hóa về chi phí
- Chip AWS Trainium và Inferentia giúp tăng tốc AI/ML
- FPGA cho các tác vụ tính toán chuyên biệt
- Hệ thống máy tính lượng tử thông qua Amazon Braket
Truy cập dữ liệu liền mạch
Yếu tố then chốt cho sự thành công của HPC bursting là duy trì quyền truy cập dữ liệu nhất quán bất kể tác vụ được thực thi ở đâu. Kiến trúc này mở rộng lưu trữ tại chỗ lên đám mây thông qua nhiều phương pháp: Amazon Elastic File System (EFS) được gắn kết như một ổ đĩa mạng tại chỗ, đồng thời hỗ trợ nhiều tài khoản AWS độc lập cho hoạt động cộng tác giữa các nhóm nghiên cứu; Amazon Simple Storage Service (Amazon S3) cung cấp khả năng lưu trữ đối tượng có thể mở rộng cho các tập dữ liệu lớn; Amazon FSx for Lustre cung cấp các hệ thống tệp song song hiệu suất cao được tối ưu hóa cho khối lượng công việc HPC; hoặc gắn kết trực tiếp các hệ thống lưu trữ tại chỗ, như được mô tả trong hình sau.

Hình 4: Storage architecture với EFS integration
Tác động thực tế
HPC bursting đã mang lại tác động đáng kể cho các nhóm nghiên cứu và CNTT. Ví dụ:
- Các nhóm mô hình hóa khí hậu chạy dự báo tổng hợp theo giờ thay vì theo tuần.
- Các nhóm nghiên cứu AI tiếp cận GPU NVIDIA mới nhất, duy trì tốc độ nghiên cứu.
- Các phòng thí nghiệm hóa học tính toán có quy mô từ 100 đến 10.000 lõi để khám phá thuốc.
- Các nhà nghiên cứu khoa học vật liệu kết hợp HPC truyền thống với điện toán lượng tử.
Lợi ích cho nhóm nghiên cứu và IT
Đối với các nhà nghiên cứu, HPC bursting mang lại đường cong học tập gần như bằng không, với môi trường đám mây phản ánh các hệ thống tại chỗ quen thuộc của bạn, cho phép các tập lệnh và quy trình làm việc hoạt động mà không cần sửa đổi. Phương thức xác thực hiện tại của bạn vẫn không thay đổi.
Quan trọng nhất, HPC bursting cho phép các tổ chức duy trì tốc độ nghiên cứu bằng cách đồng ý với các dự án đầy tham vọng. Thay vì buộc bạn phải thu hẹp tham vọng hoặc chờ đợi hàng tuần để nâng cấp phần cứng, đội ngũ IT có thể cung cấp ngay lập tức chính xác các tài nguyên bạn cần. Điều này giúp duy trì động lực nghiên cứu và ngăn ngừa tình trạng mất năng suất khi bạn phải chuyển đổi ngữ cảnh giữa các dự án trong khi chờ đợi tài nguyên.
Đối với các nhóm IT, điều này đồng nghĩa với việc duy trì tốc độ nghiên cứu thông qua cân bằng tải thông minh trên cả môi trường cục bộ và đám mây. Mô hình trả tiền theo mức sử dụng giúp loại bỏ việc mua phần cứng chuyên dụng đắt tiền mà đôi khi chỉ cần dùng đến, trong khi giám sát thống nhất cung cấp khả năng giám sát toàn diện các tài nguyên lai.
Hiểu về kinh tế
Burst computing thường có chi phí thấp hơn 60-80% so với việc mua phần cứng chuyên dụng tương đương, và hầu hết các tổ chức đều thấy được lợi tức đầu tư (ROI) trong vòng 6-12 tháng. Thay vì chi phí đầu tư lớn mỗi 3-5 năm, các tổ chức có thể lập kế hoạch chi phí vận hành phù hợp với hoạt động nghiên cứu.
Bắt đầu
Việc thực hiện diễn ra theo ba giai đoạn:
- Đánh giá – Xác định các nhóm nghiên cứu thí điểm, đánh giá các yêu cầu về mạng và xem xét các cân nhắc về bảo mật.
- Thiết lập cơ sở hạ tầng – Cấu hình kết nối an toàn, triển khai tích hợp đám mây và thiết lập hệ thống giám sát.
- Triển khai thử nghiệm – Bắt đầu với các nhóm nghiên cứu được chọn để xác thực quy trình làm việc và tối ưu hóa hiệu suất.
Các tác vụ thường khởi chạy trên tài nguyên đám mây trong vòng 2-3 phút, trong khi quá trình đồng bộ hóa dữ liệu diễn ra hoàn toàn tự động ở chế độ nền. Yêu cầu băng thông mạng khá khiêm tốn đối với hầu hết các khối lượng công việc, mặc dù các ứng dụng dữ liệu chuyên sâu được hưởng lợi từ AWS Direct Connect.
Tương lai của máy tính nghiên cứu
Phương pháp kết hợp này đại diện cho tương lai của điện toán nghiên cứu khi nhu cầu ngày càng đòi hỏi nhiều dữ liệu và tính toán phức tạp. Các mô hình điện toán mới nổi như lượng tử có thể được tiếp cận thông qua cloud bursting, đảm bảo tổ chức của bạn luôn dẫn đầu trong nghiên cứu điện toán.
HPC bursting giúp loại bỏ các nút thắt tính toán làm gián đoạn đà nghiên cứu, đảm bảo những khám phá đột phá không bị trì hoãn bởi hạn chế về cơ sở hạ tầng. Trong thời đại nhu cầu tính toán ngày càng tăng, việc duy trì tốc độ nghiên cứu trở thành yếu tố khác biệt quan trọng đối với các tổ chức hàng đầu.
Các nhóm nghiên cứu trước đây lập kế hoạch dự án dựa trên tính khả dụng của phần cứng thì nay lập kế hoạch dựa trên cơ hội khoa học.
Bạn đã sẵn sàng khám phá cách HPC bursting có thể chuyển đổi môi trường điện toán nghiên cứu của mình chưa? Pariveda Solutions, Đối tác Tư vấn Cao cấp của AWS với chuyên môn sâu rộng về kiến trúc đám mây lai và quy trình nghiên cứu học thuật, có thể giúp đánh giá các yêu cầu riêng biệt của tổ chức bạn và đẩy nhanh sứ mệnh nghiên cứu.
Tìm hiểu thêm về triển khai kỹ thuật thông qua kho lưu trữ GitHub của AWS Plugin for Slurm .
Tác giả
Scott Friedman

Scott là giám đốc phát triển kinh doanh kỹ thuật chính cho nghiên cứu giáo dục đại học tại AWS. Ông có bằng Tiến sĩ Khoa học Máy tính từ UCLA và có hơn 25 năm kinh nghiệm trong việc hỗ trợ nghiên cứu trong lĩnh vực giáo dục đại học.
Murty Chappidi

Murty là kiến trúc sư giải pháp cấp cao tại AWS với 25 năm kinh nghiệm trong ngành CNTT. Ông đóng vai trò là cố vấn đáng tin cậy cho các đối tác tích hợp hệ thống khu vực công, cung cấp hướng dẫn chiến lược về kiến trúc và hỗ trợ phát triển các bộ tăng tốc AI để tạo ra lợi thế khác biệt cho đối tác.
Viraj Tilva

Viraj là kiến trúc sư giải pháp tại Pariveda, hợp tác với các tổ chức để phát triển các chiến lược hạ tầng an toàn, có thể mở rộng nhằm hỗ trợ tăng trưởng dài hạn và khả năng thích ứng. Anh có nhiều kinh nghiệm trong việc thiết kế các giải pháp điện toán đám mây giúp triển khai thành công việc di chuyển hệ thống, hiện đại hóa và xây dựng chiến lược đám mây lai.
