Bởi Anoop Saha, Aman Shanbhag, and Trevor Harvey on 10 APR 2025 in Amazon Machine Learning, Amazon SageMaker, Amazon SageMaker AI, Artificial Intelligence, Foundation models, Generative AI
Huấn luyện một mô hình tiên tiến (frontier model) đòi hỏi năng lực tính toán cực kỳ cao, cần đến một hệ thống phân tán gồm hàng trăm hoặc hàng nghìn máy chủ tăng tốc (accelerated instances) hoạt động liên tục trong nhiều tuần hoặc thậm chí nhiều tháng chỉ để hoàn thành một tác vụ huấn luyện duy nhất.
Ví dụ, giai đoạn tiền huấn luyện của mô hình Llama 3 70B với 15 nghìn tỷ token dữ liệu huấn luyện đã tiêu tốn 6,5 triệu giờ GPU H100. Nếu chạy trên 256 Amazon EC2 P5 instances (p5.48xlarge, mỗi máy có 8 GPU NVIDIA H100), thì quá trình này sẽ kéo dài khoảng 132 ngày.
Các tác vụ huấn luyện phân tán (distributed training workloads) được thực thi theo cách đồng bộ (synchronous), nghĩa là mọi máy chủ tham gia phải hoàn tất bước tính toán của mình trước khi mô hình có thể chuyển sang bước huấn luyện tiếp theo. Điều này có nghĩa là nếu chỉ một máy gặp sự cố, toàn bộ quá trình huấn luyện sẽ bị dừng lại.
Khi quy mô cụm máy (cluster) tăng lên, xác suất xảy ra lỗi phần cứng cũng tăng, do có nhiều thành phần cần phối hợp hoạt động cùng lúc. Mỗi sự cố phần cứng có thể dẫn đến lãng phí hàng nghìn giờ GPU và yêu cầu kỹ sư phải mất nhiều thời gian để khắc phục, gây gián đoạn tiến độ và trì hoãn thời gian hoàn thành.
Để đánh giá độ tin cậy của hệ thống, các nhóm kỹ sư thường sử dụng chỉ số MTBF (Mean Time Between Failures – thời gian trung bình giữa các lần hỏng hóc), đo lường thời gian hoạt động trung bình giữa hai lỗi phần cứng và là một thước đo quan trọng phản ánh độ bền vững của hệ thống.
Trong bài viết này, chúng ta sẽ tìm hiểu những thách thức trong việc huấn luyện các mô hình tiên tiến quy mô lớn, tập trung vào các lỗi phần cứng và những lợi ích mà Amazon SageMaker HyperPod mang lại — một giải pháp linh hoạt, đáng tin cậy giúp giảm gián đoạn, nâng cao hiệu quả và cắt giảm chi phí huấn luyện.
Tỷ lệ lỗi của các máy chủ
Để hiểu được thời gian trung bình giữa các lần hỏng hóc (MTBF) trong quá trình huấn luyện các mô hình tiên tiến quy mô lớn, trước hết cần xem xét tỷ lệ lỗi của các máy chủ (instance failure rate) thông qua ba ví dụ tiêu biểu sau:
- Khi huấn luyện mô hình OPT-175B trên 992 GPU A100, nhóm nghiên cứu của Meta AI đã gặp nhiều thách thức về độ tin cậy phần cứng. Trong 2 tháng, nhóm đã phải khởi động lại thủ công 35 lần và thay thế hơn 100 máy chủ do sự cố phần cứng; ngoài ra, hệ thống tự động cũng kích hoạt hơn 70 lần khởi động lại. Khi vận hành 124 máy chủ (mỗi máy có 8 GPU) liên tục trong 1.440 giờ, Meta đã tích lũy tổng cộng 178.560 giờ hoạt động máy chủ (instance-hours). Tỷ lệ lỗi quan sát được trong giai đoạn này khoảng 0,0588% trên mỗi giờ hoạt động, cho thấy những khó khăn lớn về độ ổn định khi huấn luyện các mô hình tiên tiến ở quy mô này.
- Trong quá trình huấn luyện Llama 3.1 405B trên 16.000 GPU H100, đã xảy ra tổng cộng 417 lỗi phần cứng ngoài kế hoạch trong 54 ngày. Tỷ lệ lỗi tương ứng khoảng 0,0161% trên mỗi giờ hoạt động.
- Mô hình MPT-7B được huấn luyện trên 1 nghìn tỷ token trong 9,5 ngày, sử dụng 440 GPU A100-40GB. Trong thời gian này, quá trình huấn luyện đã gặp 4 lỗi phần cứng, dẫn đến tỷ lệ lỗi hiệu dụng khoảng 0,0319% trên mỗi giờ hoạt động.
Từ các ví dụ trên, có thể thấy rằng trong một giờ huấn luyện phân tán quy mô lớn, xác suất một máy chủ gặp lỗi dao động trong khoảng 0,02% – 0,06%.
Cụm máy càng lớn, số lỗi càng nhiều, thời gian trung bình giữa các lần hỏng hóc (MTBF) càng ngắn
Các chương trình sàng lọc ung thư phổi cấp quốc gia phải đối mặt với nhiều thách thức phức tạp trong quá trình triển khai và vận hành.
Sự gia tăng nhanh chóng số người đủ điều kiện tham gia sàng lọc đã gây áp lực lớn lên các bệnh viện, đặc biệt là khoa chẩn đoán hình ảnh và nguồn nhân lực bác sĩ chẩn đoán hình ảnh. Nhiều bệnh viện thiếu thiết bị chụp chiếu hoặc chuyên gia đọc kết quả, buộc họ phải thuê ngoài dịch vụ để duy trì liên tục công tác chăm sóc.
Tính không đồng nhất của các hệ thống hình ảnh y tế trong toàn bộ hệ thống NHS, cùng với sự khác biệt trong quy trình vận hành giữa các bệnh viện, làm tăng thêm độ phức tạp. Các nhà cung cấp dịch vụ phải thích ứng với những yêu cầu đa dạng này trong khi vẫn phải đảm bảo tích hợp liền mạch và duy trì chất lượng chăm sóc.
Ngoài ra, việc cần lưu trữ, truyền tải và phân tích an toàn khối lượng lớn dữ liệu hình ảnh y tế giữa nhiều bên liên quan đòi hỏi hạ tầng công nghệ mạnh mẽ và tiết kiệm chi phí.
| . | Size of cluster (instances) | |||||||
| Failure rate (per instance per hour) | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| 0.01% | 2500 | 1250 | 625 | 313 | 157 | 79 | 40 | 20 |
| 0.02% | 1250 | 625 | 313 | 157 | 79 | 40 | 20 | 10 |
| 0.04% | 625 | 313 | 157 | 79 | 40 | 20 | 10 | 5 |
| 0.08% | 313 | 157 | 79 | 40 | 20 | 10 | 5 | 3 |
Bảng 1: Sự thay đổi của MTBF (tính bằng giờ) theo số lượng máy chủ trong cụm huấn luyện (với các tỷ lệ lỗi giả định thể hiện trong các cột)
Điều gì xảy ra sau khi xảy ra lỗi?
Trong một thế giới lý tưởng — không có bất kỳ sự cố nào, quá trình huấn luyện mô hình sẽ diễn ra trơn tru như được minh họa trong biểu đồ dưới đây, thể hiện tổng thời gian huấn luyện khi không có lỗi xảy ra, với tiến trình tăng tuyến tính (linear progression) theo thời gian.

Hình 1: Quá trình huấn luyện diễn ra tuyến tính trong một thế giới lý tưởng không có lỗi, vì không có bất kỳ gián đoạn nào ảnh hưởng đến việc hoàn thành.
Tuy nhiên, như đã đề cập trước đó, các lỗi phần cứng là điều không thể tránh khỏi. Việc xử lý (khắc phục sự cố) sau khi lỗi xảy ra thường bao gồm một số bước sau:
Phân tích nguyên nhân gốc rễ (Mean Time To Detect – MTTD): Việc xác định lỗi phần cứng là nguyên nhân gốc rễ gây gián đoạn quá trình huấn luyện có thể tốn nhiều thời gian, đặc biệt trong các hệ thống phức tạp với nhiều điểm có khả năng xảy ra lỗi. Thời gian cần để xác định nguyên nhân gốc rễ này được gọi là thời gian trung bình để phát hiện (MTTD – Mean Time To Detect).
Sửa chữa hoặc thay thế phần cứng (Mean Time To Replace – MTTR): Đôi khi, chỉ cần khởi động lại phiên bản (instance) là có thể khắc phục sự cố. Tuy nhiên, trong một số trường hợp khác, cần phải thay thế toàn bộ instance, điều này có thể gây ra sự chậm trễ về mặt hậu cần — đặc biệt nếu các linh kiện chuyên dụng không có sẵn ngay lập tức. Nếu không có sẵn instance thay thế khi một GPU bị hỏng, hệ thống phải chờ cho đến khi có GPU mới. Các kỹ thuật phân phối lại công việc phổ biến, chẳng hạn như PyTorch FSDP, không cho phép phân phối lại khối lượng công việc giữa các instance còn lại.
Khôi phục hệ thống và tiếp tục huấn luyện (Mean Time To Restart – MTTRestart): Sau khi khắc phục sự cố phần cứng và thay thế phiên bản (instance), cần thêm thời gian để khôi phục hệ thống về trạng thái trước đó. Phiên bản mới phải được cấu hình giống với bản gốc, và toàn bộ cụm (cluster) phải tải lại trọng số mô hình từ điểm kiểm tra (checkpoint) được lưu gần nhất.
Mỗi sự cố xảy ra đều yêu cầu nỗ lực kỹ thuật để xác định nguyên nhân gốc rễ. Khi lỗi phần cứng xuất hiện, hệ thống chẩn đoán (diagnostics) sẽ được sử dụng để xác nhận vấn đề và cô lập instance bị lỗi, dẫn đến việc tạm dừng quá trình huấn luyện và tăng thời gian ngừng hoạt động (downtime). Tác động của những sự cố này được minh họa trong hình bên dưới và có thể được đo lường thực nghiệm trong các tác vụ huấn luyện phân tán quy mô lớn. Hình đó mô tả các bước khắc phục sự cố được thực hiện sau khi lỗi xảy ra.
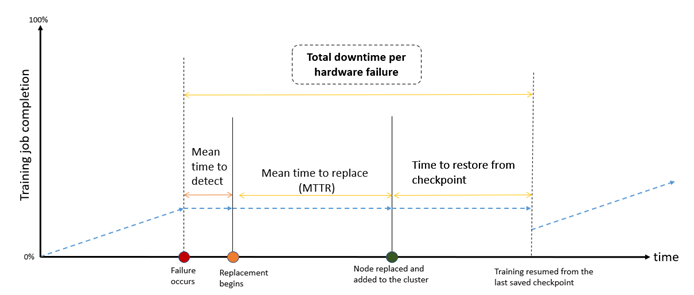
Hình 2: Ảnh hưởng của các sự cố đối với quá trình huấn luyện phân tán. Khi một sự cố xảy ra, thời gian (GPU bị nhàn rỗi) sẽ được sử dụng cho các giai đoạn phát hiện lỗi (MTD – Mean Time to Detect), thay thế (MTT Replace – Mean Time to Replace) và khởi động lại (MTR Restart – Mean Time to Restart) quá trình huấn luyện, thường dẫn đến lãng phí thời gian và tài nguyên đắt tiền.
Trong một tình huống mà một tác vụ huấn luyện phân tán đang chạy trên cụm Amazon Elastic Kubernetes Service (Amazon EKS) với n phiên bản được đặt trước và nhóm Auto Scaling được thiết lập để duy trì tối thiểu n phiên bản, một sự cố phần cứng — chẳng hạn như lỗi GPU — có thể khiến tác vụ huấn luyện bị lỗi. Phiên bản bị ảnh hưởng sẽ được bộ giám sát tình trạng của Kubernetes (ví dụ như Node Problem Detector) đánh dấu là Unhealthy (không khỏe mạnh), và Amazon EKS sẽ cố gắng lên lịch lại (reschedule) các pod huấn luyện sang những phiên bản khỏe mạnh khác. Tuy nhiên, nếu không có phiên bản nào còn đủ tài nguyên, các pod sẽ vẫn ở trạng thái Pending (đang chờ), và vì số lượng phiên bản bị giới hạn ở n, nên không có phiên bản mới nào được tự động cung cấp.
Trong những trường hợp như vậy, tác vụ bị lỗi phải được xác định thủ công thông qua nhật ký của pod hoặc Kubernetes API và sau đó bị xóa. Phiên bản bị lỗi cũng cần được cách ly và chấm dứt thủ công, thông qua AWS Management Console, AWS Command Line Interface (AWS CLI), hoặc các công cụ như kubectl hay eksctl. Để khôi phục dung lượng của cụm, người dùng phải tăng kích thước cụm bằng cách sửa đổi nhóm Auto Scaling hoặc cập nhật nhóm phiên bản. Sau khi phiên bản mới được cấp phát, khởi tạo (bootstrapped) và thêm vào cụm, tác vụ huấn luyện phải được khởi động lại thủ công. Nếu tính năng checkpointing được bật, tác vụ có thể tiếp tục từ trạng thái đã lưu gần nhất. Tổng thời gian ngừng hoạt động phụ thuộc vào thời gian cần thiết để cấp phát một phiên bản mới và khởi động lại tác vụ bằng cách sắp xếp lại (reschedule) các pod.
Phát hiện lỗi nhanh hơn (rút ngắn MTTD), thời gian thay thế ngắn hơn (rút ngắn MTTR) và khả năng khôi phục nhanh sẽ góp phần giảm tổng thời gian huấn luyện. Tự động hóa các quy trình này với sự can thiệp tối thiểu của người dùng là một lợi thế quan trọng của Amazon SageMaker HyperPod.
Cơ sở hạ tầng huấn luyện có khả năng chịu lỗi cao của Amazon SageMaker HyperPod
SageMaker HyperPod là một môi trường tính toán được tối ưu hóa cho việc huấn luyện các mô hình tiên tiến quy mô lớn. Điều này có nghĩa là người dùng có thể xây dựng các cụm máy có khả năng chịu lỗi cao cho khối lượng công việc machine learning (ML) và phát triển hoặc tinh chỉnh các mô hình tiên tiến hàng đầu, như được minh chứng bởi các tổ chức như Luma Labs và Perplexity AI. SageMaker
HyperPod chạy các tác nhân giám sát tình trạng (health monitoring agents) ở chế độ nền cho từng phiên bản. Khi phát hiện lỗi phần cứng, SageMaker HyperPod sẽ tự động sửa chữa hoặc thay thế phiên bản bị lỗi và tiếp tục huấn luyện từ điểm kiểm tra (checkpoint) được lưu gần nhất. Quy trình tự động này giúp loại bỏ nhu cầu quản lý thủ công, cho phép khách hàng huấn luyện trong môi trường phân tán suốt nhiều tuần hoặc tháng với mức gián đoạn tối thiểu. Lợi ích này đặc biệt đáng kể đối với các khách hàng triển khai cụm có trên 16 phiên bản (instances).
Những nhà phát triển mô hình tiên tiến có thể tiếp tục cải thiện hiệu suất mô hình bằng cách sử dụng các công cụ học máy (ML) tích hợp sẵn trong SageMaker HyperPod. Họ có thể sử dụng Amazon SageMaker AI with MLflow để tạo, quản lý và theo dõi các thí nghiệm ML, hoặc sử dụng Amazon SageMaker AI with TensorBoard để trực quan hóa kiến trúc mô hình và giải quyết các vấn đề hội tụ. Ngoài ra, việc tích hợp với các công cụ giám sát như Amazon CloudWatch Container Insights, Amazon Managed Service for Prometheus và Amazon Managed Grafana giúp cung cấp cái nhìn sâu sắc hơn về hiệu suất, tình trạng sức khỏe và mức độ sử dụng của cụm máy, từ đó tiết kiệm đáng kể thời gian phát triển. Hình dưới đây so sánh thời gian ngừng hoạt động (downtime) giữa hệ thống hạ tầng sử dụng SageMaker HyperPod và hệ thống không sử dụng SageMaker HyperPod.
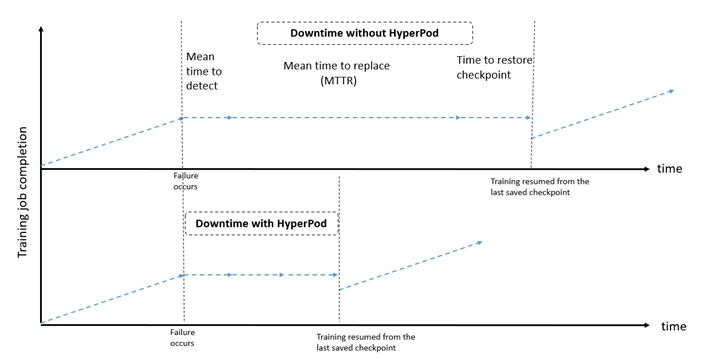
Hình 3: So sánh biểu đồ thời gian ngừng hoạt động (downtime) từ Hình 1 với thời gian ngừng hoạt động trên SageMaker HyperPod. Khi xảy ra sự cố, các tác nhân (agent) của HyperPod sẽ tự động phát hiện lỗi, thay thế phiên bản (instance) bị hỏng trong nền, và quá trình huấn luyện sẽ được tiếp tục từ điểm kiểm tra (checkpoint) gần nhất.
SageMaker HyperPod giảm thời gian ngừng hoạt động do lỗi phần cứng bằng cách tự động phát hiện sự cố phần cứng. Khi các sự cố này được phát hiện, SageMaker HyperPod sẽ tự động thay thế các nút (node) bị lỗi và tiếp tục quá trình huấn luyện từ điểm kiểm tra (checkpoint) gần nhất, với điều kiện là các checkpoint đã được ghi lại trước đó.
Để đánh giá điều này, chúng tôi đã tiến hành các thí nghiệm trên SageMaker HyperPod với các cụm có kích thước khác nhau sử dụng các phiên bản p5.48xlarge. Kết quả trong bảng dưới đây — hiển thị các phép đo thực nghiệm về thời gian khôi phục (time to resume) theo kích thước cụm — cho thấy phân vị thứ 90 (P90), tức là giá trị mà 90% trường hợp sẽ đạt được hoặc vượt qua.
| Cluster size (number of instances) | P90 time to detect (in seconds) | P90 time to replace (in seconds) | P90 time to resume (in seconds) | Total downtime per failure (in seconds) | Total downtime per failure (in minutes) |
| 16 | 83 | 912 | 1212 | 2207 | 36.8 |
| 64 | 90 | 963 | 1320 | 2373 | 39.6 |
| 256 | 89 | 903 | 1398 | 2390 | 39.8 |
| 1024 | 80 | 981 | 1440 | 2501 | 41.7 |
Bảng 2: Thời gian trung bình để khôi phục (MTTResume, tính bằng giây) trên các cụm có kích thước khác nhau.
Như đã chỉ ra, thời gian trung bình để thay thế một instance là độc lập với kích thước của cụm (cluster). Đối với một cụm gồm 256 instance loại p5.48xlarge dùng để huấn luyện mô hình Meta Llama 3.1 có 70 tỷ tham số với kích thước batch = 8, việc thay thế một instance mất khoảng 940 giây (tương đương 15,7 phút). Sau khi thay thế, instance mới phải cài đặt thêm các gói phần mềm thông qua lifecycle script và chạy kiểm tra sức khỏe chuyên sâu (deep health checks) trước khi đọc từ checkpoint được lưu gần nhất. Khi instance hoạt động bình thường, quá trình huấn luyện sẽ tiếp tục từ checkpoint gần nhất, giúp giảm thiểu tổn thất tiến trình dù có sự gián đoạn. Đối với cụm 256 instance, việc tự động khôi phục quá trình huấn luyện sau mỗi lần lỗi mất khoảng 2.390 giây (tương đương 40 phút).
Nếu không sử dụng SageMaker HyperPod, khi xảy ra lỗi GPU trong quá trình huấn luyện, thời gian để tiếp tục huấn luyện có thể thay đổi đáng kể tùy thuộc vào hạ tầng và quy trình đang được áp dụng. Với việc lưu checkpoint hợp lý, tự động điều phối công việc và cấp phát phần cứng hiệu quả, thời gian khôi phục có thể được rút ngắn. Tuy nhiên, nếu không có các tối ưu này, tác động có thể nghiêm trọng hơn nhiều. Theo bằng chứng thực nghiệm từ trải nghiệm của khách hàng — bao gồm một nhà cung cấp mô hình nguồn mở hàng đầu, một startup hàng đầu về mô hình ngôn ngữ lớn (LLM), một công ty AI chuyên về mô hình tiên tiến cho doanh nghiệp, và một viện nghiên cứu khoa học hàng đầu — cho thấy rằng khi không sử dụng SageMaker HyperPod, thời gian ngừng hoạt động trung bình cho mỗi lỗi GPU có thể lên tới khoảng 280 phút (gần 4,7 giờ).Do đó, Amazon SageMaker HyperPod giúp tiết kiệm khoảng 240 phút (tức khoảng 4 giờ) thời gian ngừng hoạt động cho mỗi lỗi phần cứng:
Without SageMaker HyperPod (in minutes) | With SageMaker HyperPod (in minutes) | |
| Mean time to root-cause | 10 | 1.5 |
| Mean time to replace | 240 | 15 |
| Mean time to resume | 30 | 23.5 |
| Total downtime per failure | 280 | 40 |
Bảng 3: Thời gian sự cố điển hình tính bằng phút ( như mô tả trong phần “Điều gì xảy ra sau khi xảy ra lỗi?”, với và không có SageMaker HyperPod)
Định lượng mức tiết kiệm thời gian ngừng hoạt động
Tùy thuộc vào tần suất xảy ra sự cố, chúng ta có thể tính toán thời gian huấn luyện và chi phí tiết kiệm được khi sử dụng SageMaker HyperPod. Để minh họa cho phép tính này, giả sử việc thay thế một phiên bản (instance) mất 40 phút khi dùng SageMaker HyperPod, so với 280 phút nếu không sử dụng (như đã giải thích trước đó). Ngoài ra, trong ví dụ này, giả định rằng một tác vụ huấn luyện cần 10 triệu giờ GPU trên các phiên bản H100, chạy trên một cụm gồm 256 phiên bản P5.
Mặc dù tổng thời gian phát sinh thêm (tính bằng giờ) phụ thuộc vào quy mô của tác vụ huấn luyện, nhưng tỷ lệ chi phí phát sinh tương đối vẫn không thay đổi. Lợi ích của SageMaker HyperPod trong việc rút ngắn tổng thời gian huấn luyện được minh họa trong biểu đồ dưới đây. Ví dụ, với một cụm 256 phiên bản có tỷ lệ lỗi 0,05%, SageMaker HyperPod giúp giảm tổng thời gian huấn luyện xuống 32%.
| . | Size of cluster (instances) | |||||||
| Failure rate (per instance per hour) | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| 0.01% | 0% | 0% | 1% | 1% | 2% | 5% | 9% | 17% |
| 0.02% | 0% | 1% | 1% | 2% | 5% | 9% | 17% | 28% |
| 0.05% | 1% | 2% | 3% | 6% | 11% | 20% | 32% | 48% |
| 0.07% | 1% | 2% | 4% | 8% | 15% | 25% | 40% | 55% |
Bảng 4: Tổng phần trăm thời gian huấn luyện được rút ngắn bởi SageMaker HyperPod so với cụm P5 có quy mô tương đương.
Để chuyển đổi thành tiết kiệm thực tế, đối với một công việc huấn luyện yêu cầu 10 triệu giờ GPU trên một cụm 256 máy, SageMaker HyperPod tiết kiệm được 104 ngày thời gian huấn luyện. Do đó, khách hàng có thể rút ngắn thời gian ra thị trường xuống 3,5 tháng. Nếu không có SageMaker HyperPod, tổng thời gian huấn luyện sẽ khoảng 325 ngày, trong đó 121 ngày chỉ dành cho việc cô lập và khắc phục sự cố phần cứng. Bảng sau đây cho thấy lợi ích về thời gian huấn luyện.
| H100 GPU hours for training | 10,000,000 |
| Number of instances | 256 |
| Failure rate (per instance per hour) | 0.05% |
| Additional time to fix per failure (hours) | 4 |
| Days lost due to hardware issues (with SageMaker HyperPod) | 17 |
| Days lost due to hardware issues (without SageMaker HyperPod) | 121 |
| Time to train with SageMaker HyperPod (days) | 221 |
| Time to train without SageMaker HyperPod (days) | 325 |
| SageMaker HyperPod improvement | 32% |
| Time saved with SageMaker HyperPod (days) | 104 |
Bảng 5: Lợi ích của SageMaker HyperPod cho một lần huấn luyện yêu cầu 10 triệu giờ GPU và cụm 256 máy. SageMaker HyperPod đã tiết kiệm được 104 ngày huấn luyện, giúp đưa sản phẩm ra thị trường nhanh hơn( khoảng 3,5 tháng!).
Với cùng ví dụ đó, chúng ta có thể ước tính tổng chi phí tiết kiệm được bằng công thức:
Days lost due to hardware issues = (Number of instances) × (Failure rate per instance per hour) × (24 hours per day) × (Total training days) × (Downtime per failure in hours)Bảng sau thể hiện lợi ích về chi phí huấn luyện (cost to train benefits).
| H100 GPU hours for training | 10,000,000 |
| Number of instances | 256 |
| Failure rate (per instance per hour) | 0.05% |
| Time saved with SageMaker HyperPod (days) | 104 |
| Cost per GPU per hour | $5 |
| Total cost saving with SageMaker HyperPod | $25,559,040 |
Bảng 6: Sử dụng phép tính được mô tả ở trên, các lợi ích về chi phí huấn luyện được trình bày cho một quá trình huấn luyện yêu cầu 10 million GPU hours, 256 GPU-based instances, và failure rate giả định là 0.05% per instance per hour.
Một training job yêu cầu 10 million GPU hours và 104 ngày bổ sung để khắc phục sự cố phần cứng dẫn đến thời gian nhàn rỗi đáng kể của cụm (idle cluster time).
Giả sử chi phí GPU là $5 per hour (tương đương với giá của P5 instances trên Capacity Blocks for ML), tổng chi phí tiết kiệm được với SageMaker HyperPod lên đến $25,559,040.
Kết luận
Đào tạo các mô hình biên (frontier models) là một quá trình phức tạp và tốn nhiều tài nguyên, đặc biệt dễ bị ảnh hưởng bởi các lỗi phần cứng. Trong bài viết này, chúng tôi đã xem xét tỉ lệ hỏng của các phiên bản (instance), có thể dao động khoảng 0,02%–0,07% mỗi giờ trong quá trình đào tạo phân tán quy mô lớn. Khi kích thước cụm (cluster) tăng lên, khả năng xảy ra lỗi cũng tăng theo và thời gian giữa các lần hỏng (MTBF) giảm xuống. Chúng tôi cũng phân tích những gì xảy ra sau khi có lỗi, bao gồm phân tích nguyên nhân gốc rễ, sửa chữa hoặc thay thế phần cứng, và khôi phục hệ thống để tiếp tục quá trình đào tạo.
Tiếp theo, chúng tôi xem xét Amazon SageMaker HyperPod — một cụm được thiết kế chuyên biệt, có khả năng chịu lỗi toàn diện cho việc đào tạo các mô hình biên. Bằng cách tích hợp các cơ chế chịu lỗi mạnh mẽ và giám sát sức khỏe tự động, SageMaker HyperPod giảm thiểu gián đoạn do sự cố phần cứng gây ra. Điều này không chỉ đơn giản hóa quy trình đào tạo mà còn nâng cao độ tin cậy và hiệu quả của phát triển mô hình, giúp triển khai đổi mới nhanh hơn và hiệu quả hơn. Những lợi ích này có thể đo lường được và tương quan với cả kích thước cụm và tỉ lệ hỏng. Với một cụm 256 phiên bản và tỉ lệ hỏng 0,05% mỗi phiên bản mỗi giờ, SageMaker HyperPod giảm tổng thời gian đào tạo xuống 32%, dẫn đến tiết kiệm ước tính khoảng 25,6 triệu USD cho tổng chi phí đào tạo.
Bằng cách giải quyết các thách thức về độ tin cậy trong đào tạo mô hình biên, SageMaker HyperPod cho phép các nhóm ML tập trung vào đổi mới mô hình thay vì quản lý hạ tầng. Các tổ chức giờ đây có thể tiến hành các lần đào tạo dài với sự tự tin, biết rằng các lỗi phần cứng sẽ được phát hiện và khắc phục tự động với sự gián đoạn tối thiểu cho khối lượng công việc ML của họ. Bắt đầu sử dụng Amazon SageMaker HyperPod ngay hôm nay.
Lời cảm ơn đặc biệt đến Roy Allela, Chuyên gia Giải pháp AI/ML cấp cao, đã hỗ trợ trong việc ra mắt bài viết này.
Về tác giả

Anoop Saha là Sr GTM Specialist tại Amazon Web Services (AWS), tập trung vào generative AI model training and inference. Ông hợp tác với các frontier model builders, khách hàng chiến lược, và các AWS service teams để hỗ trợ distributed training và inference at scale trên AWS, đồng thời dẫn dắt các GTM motions chung. Trước khi gia nhập AWS, Anoop từng đảm nhận nhiều vị trí lãnh đạo tại các startup và tập đoàn lớn, chủ yếu tập trung vào silicon và system architecture của AI infrastructure.

Trevor Harvey là Principal Specialist trong lĩnh vực generative AI tại Amazon Web Services (AWS) và là AWS Certified Solutions Architect – Professional. Trevor làm việc với khách hàng để thiết kế và triển khai machine learning solutions, đồng thời dẫn dắt các go-to-market strategies cho các generative AI services.

Aman Shanbhag là Specialist Solutions Architect trong nhóm ML Frameworks team tại Amazon Web Services (AWS), nơi anh hỗ trợ khách hàng và đối tác triển khai ML training và inference solutions at scale. Trước khi gia nhập AWS, Aman tốt nghiệp Rice University với các bằng về computer science, mathematics, và entrepreneurship.
