Tác giả: Noor Dhaliwal, Tiến sĩ Kelsey Florek, và Logan Fink
Ngày đăng: 05/05/2025
Danh mục: Amazon API Gateway, Amazon Bedrock, Artificial Intelligence, AWS Lambda, Customer Solutions, Generative AI, Healthcare, Public Sector

Trong các lĩnh vực y học chính xác (precision medicine) và giám sát mầm bệnh (pathogen surveillance), giải trình tự hệ gen (genomic sequencing) đã nổi lên như một thành phần then chốt của nghiên cứu và ứng phó y tế công cộng. Tuy nhiên, sự phát triển và ứng dụng của lĩnh vực hệ gen đang đối mặt với thách thức về khả năng tương tác dữ liệu (data interoperability) và chuẩn hóa (standardization). Các phòng thí nghiệm y tế công cộng trên khắp Hoa Kỳ xử lý hàng chục nghìn mẫu hệ gen mỗi tháng, trong đó mỗi phòng thí nghiệm sử dụng các lược đồ (schemas) và định dạng tối ưu hóa cục bộ. Các định dạng này bắt buộc phải được chuẩn hóa trước khi có thể trao đổi với đối tác y tế công cộng và gửi lên các kho dữ liệu công cộng.
Quy mô của thách thức này là rất lớn. Nhân viên phòng thí nghiệm y tế công cộng có thể mất từ 2 đến 4 giờ để chuẩn bị thủ công dữ liệu trước khi gửi đến một kho dữ liệu hệ gen công cộng như Trung tâm Thông tin Công nghệ Sinh học Quốc gia (NCBI). Điều này tương đương với hơn 400 giờ mỗi năm cho một phòng thí nghiệm — khoảng thời gian có thể được dành cho các hoạt động phân tích và ứng phó quan trọng hơn. Đáng lo ngại hơn, các quy trình thủ công này có thể dẫn đến sai sót, gây ra việc từ chối hoặc yêu cầu chỉnh sửa dữ liệu nộp, làm chậm trễ việc phát hành dữ liệu hệ gen quan trọng đến cộng đồng khoa học rộng lớn hơn.
Để giải quyết thách thức ngày càng gia tăng này, Digital Transformation Hub (DxHub) tại California Polytechnic State University (Cal Poly) — được vận hành bởi Amazon Web Services (AWS) và là một phần của chương trình AWS Cloud Innovation Centers (CIC) — đã hành động. DxHub đã hợp tác với Wisconsin State Laboratory of Hygiene (WSLH) và Virginia Department of General Services Division of Consolidated Laboratory Services (DCLS) để xây dựng AI Genomic Schema Harmonizer, một ứng dụng sử dụng generative AI nhằm cách mạng hóa cách các phòng thí nghiệm chuẩn bị dữ liệu hệ gen trước khi gửi đến các kho dữ liệu công cộng.
AI Genomics Schema Harmonizer
AI Genomics Schema Harmonizer giúp giảm đáng kể gánh nặng trong báo cáo dữ liệu hệ gen. Thay vì áp dụng phương pháp truyền thống là quản lý dữ liệu bằng bảng tính, ứng dụng này khai thác sức mạnh của AI tạo sinh (generative AI) để tự động căn chỉnh các thuật ngữ phòng thí nghiệm đa dạng theo các định dạng chuẩn hóa hoặc định dạng bắt buộc. Thông qua năng lực xử lý ngôn ngữ tự nhiên (natural language processing – NLP), AI Genomics Schema Harmonizer có thể phân tích các thuật ngữ đặc thù của từng phòng thí nghiệm và ánh xạ chúng với các định nghĩa chuẩn hóa trong NCBI BioSample, qua đó bảo đảm dữ liệu được nộp một cách nhất quán và chính xác.
Tác động của giải pháp này vượt xa việc ánh xạ trường dữ liệu đơn thuần. Bằng cách đơn giản hóa quy trình chuẩn hóa, AI Genomics Schema Harmonizer thúc đẩy một sáng kiến rộng lớn hơn trong lĩnh vực chăm sóc sức khỏe và khoa học sự sống: đạt được khả năng tương tác ngữ nghĩa (semantic interoperability). Năng lực này cho phép dữ liệu hệ gen có thể được chia sẻ, hiểu và sử dụng một cách liền mạch giữa các hệ thống và tổ chức khác nhau — một yêu cầu cốt lõi đối với công tác giám sát dịch bệnh và nghiên cứu y tế công cộng hiện đại.
Tổng quan giải pháp
Kiến trúc của ứng dụng theo hướng API (API-driven), tận dụng nhiều dịch vụ được quản lý của AWS nhằm đảm bảo các yếu tố bảo mật, khả năng mở rộng (scalability), và độ tin cậy (reliability). Amazon Bedrock kết hợp cùng Anthropic Claude Sonnet 3.5 v2 foundation model (FM) cung cấp khả năng xử lý an toàn đối với siêu dữ liệu (metadata) hệ gen nhạy cảm. AWS Lambda và Amazon API Gateway đảm nhiệm logic ứng dụng ở tầng backend. Các định nghĩa ánh xạ dữ liệu (data mapping definitions) được lưu trữ an toàn trên Amazon Simple Storage Service (Amazon S3).
Sơ đồ dưới đây minh họa kiến trúc giải pháp.
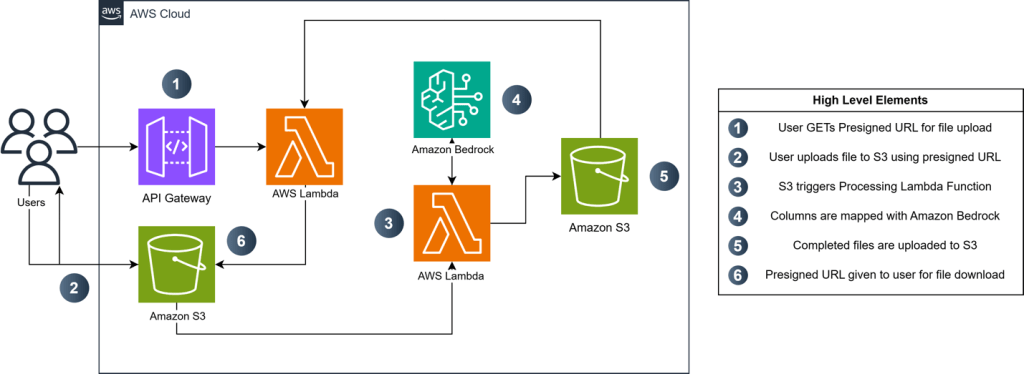
Hình 1. Sơ đồ kiến trúc giải pháp
Hệ thống với năng lực xử lý ngôn ngữ tự nhiên (natural language processing – NLP) tiên tiến cho phép phân tích cú pháp (parse) và phân tích cấu trúc dữ liệu nguồn cùng các thuật ngữ liên quan, sau đó ánh xạ các trường dữ liệu với các thuật ngữ chuẩn hóa tương ứng của NCBI bằng cách sử dụng các thư viện định nghĩa toàn diện. Các nhà khoa học thực hiện bước kiểm tra cuối cùng nhằm xác thực quá trình ánh xạ so với các yêu cầu hiện hành của NCBI và tạo ra các tệp sẵn sàng cho việc nộp, tuân thủ các tiêu chuẩn của kho dữ liệu liên bang để bảo đảm tính nhanh chóng và đúng quy chuẩn.
“AI Genomics Schema Harmonizer có tiềm năng cách mạng hóa quy trình nộp dữ liệu hệ gen,” Tiến sĩ Kelsey Florek, chuyên gia cao cấp về hệ gen và khoa học dữ liệu tại WSLH, cho biết. “Việc thay thế các thao tác thủ công trong chuyển đổi dữ liệu và duy trì các macro hay script tùy chỉnh bằng một phương pháp đơn giản, có tính áp dụng rộng rãi, cho phép nhóm của chúng tôi tập trung vào công việc cốt lõi là phân tích hệ gen thay vì xử lý định dạng dữ liệu.”
Trải nghiệm sinh viên tại DxHub
Tại Cal Poly DxHub, sinh viên làm việc cùng đội ngũ nhân viên trường đại học và nhân viên của Amazon để phát triển các giải pháp đổi mới cho những thách thức trong khu vực công, sử dụng phương pháp Amazon Working Backwards. Đối với Noor Dhaliwal, sinh viên phát triển đứng sau công cụ GenomicsMetaDataMapper, trải nghiệm này đã mở ra những chân trời mới trong ứng dụng AI.
“Làm việc tại DxHub đã cho tôi cơ hội xây dựng một giải pháp có tác động đến các phòng thí nghiệm y tế công cộng trên toàn quốc,” Dhaliwal chia sẻ. “Việc học cách khai thác các công nghệ AI tiên tiến như Amazon Bedrock đồng thời giải quyết những vấn đề thực tiễn đã mang tính bước ngoặt. Trải nghiệm xây dựng một công cụ giúp tăng tốc công việc quan trọng về y tế công cộng đã cho tôi thấy tiềm năng thực sự của điện toán đám mây và AI trong khu vực công.”
Tác động đo lường được và định hướng tương lai
Kết quả triển khai ban đầu đã chứng minh tiềm năng mang tính cách mạng của AI Genomics Schema Harmonizer. Những tác động có thể đo lường bao gồm: loại bỏ nhu cầu phát triển công thức và macro dựa trên bảng tính, tăng độ chính xác bằng cách loại bỏ lỗi đánh máy, và tiết kiệm từ 2–4 giờ mỗi tuần cho mỗi lần nộp dữ liệu. Mặc dù bản thử nghiệm khái niệm (proof of concept) này tập trung vào một vấn đề phổ biến ảnh hưởng đến việc nộp dữ liệu hệ gen, nhưng giải pháp có khả năng áp dụng rộng rãi đối với nhiều giao diện dữ liệu hệ gen khác nhau.
Khi giải trình tự hệ gen ngày càng trở thành trung tâm của công tác giám sát bệnh truyền nhiễm trong y tế công cộng và chẩn đoán lâm sàng, nhu cầu về xử lý hiệu quả các quy trình chuyển đổi dữ liệu sẽ tiếp tục gia tăng. Sự hợp tác giữa DxHub và các phòng thí nghiệm y tế công cộng đã cho thấy cách mà AI tạo sinh (generative AI) có thể được sử dụng để giải quyết các thách thức phức tạp về khả năng tương tác (interoperability) dữ liệu, đồng thời vẫn duy trì các tiêu chuẩn khắt khe cần thiết cho nghiên cứu khoa học.
Để tìm hiểu thêm về AI Genomics Schema Harmonizer và cách công cụ này có thể hỗ trợ phòng thí nghiệm hoặc cơ quan của bạn, vui lòng liên hệ Tiến sĩ Kelsey Florek.
Tác giả đóng góp: Nick Osterbur, Tiến sĩ Dawn Heisey-Grove, và Darren Kraker
Về Cal Poly DxHub
Ra mắt năm 2017 với tư cách là CIC (Cloud Innovation Center) đầu tiên được đặt tại một cơ sở giáo dục đại học, Cal Poly DxHub mang lại cơ hội cho các tổ chức phi lợi nhuận, cơ quan giáo dục, và cơ quan chính phủ hợp tác giải quyết các thách thức cấp thiết nhất, thử nghiệm ý tưởng mới, và tiếp cận chuyên môn công nghệ của AWS để xây dựng các giải pháp dựa trên điện toán đám mây. Để tìm hiểu thêm về Cal Poly Digital Transformation Hub và cách tổ chức của bạn có thể tham gia, vui lòng liên hệ Nick Osterbur (nosterb@amazon.com) hoặc truy cập website của DxHub.
Tìm hiểu thêm về chương trình AWS Cloud Innovation Centers.
TAGS: Amazon API Gateway, Artificial Intelligence, AWS Cloud Innovation Center, aws Lambda, AWS Public Sector, Cal Poly, customer story, healthcare, life sciences
Noor Dhaliwal

Noor là sinh viên ngành Kỹ thuật Máy tính tại Đại học Bách khoa Bang California (California Polytechnic State University), San Luis Obispo, và hiện đang đảm nhiệm vai trò kỹ sư phần mềm thực tập tại Trung tâm Đổi mới Đám mây AWS của Cal Poly (Cal Poly AWS Cloud Innovation Center – CIC).
Công việc của anh tập trung vào phát triển các giải pháp kỹ thuật nhằm giải quyết những thách thức phức tạp mà các tổ chức khu vực công đang gặp phải.
Tiến sĩ Kelsey Florek

Kelsey là nhà khoa học cao cấp về gen học và dữ liệu, hiện điều hành Nhóm Tin sinh học (Bioinformatics Team) thuộc Đơn vị Bệnh truyền nhiễm (Communicable Disease Division) tại Phòng thí nghiệm Vệ sinh Bang Wisconsin (Wisconsin State Laboratory of Hygiene). Công trình của bà tập trung vào mở rộng khả năng tiếp cận công bằng đối với phân tích dữ liệu hệ gen (genomic data analytics) và tăng cường tích hợp hệ gen học (genomics) trong thực hành y tế công cộng. Kelsey hợp tác chặt chẽ với các đối tác y tế công cộng nhằm xây dựng năng lực nhân lực và thúc đẩy việc ứng dụng những hiểu biết về hệ gen (genomic insights) có tính thực tiễn trong giám sát và ứng phó với các bệnh truyền nhiễm.
Logan Fink

Logan là nhà khoa học trưởng phụ trách tin sinh học (bioinformatics lead scientist) tại Đơn vị Dịch vụ Phòng thí nghiệm Hợp nhất (Division of Consolidated Laboratory Services – DCLS) thuộc Cục Dịch vụ Tổng hợp (Department of General Services – DGS). Ông đồng thời đảm nhiệm vai trò Nguồn lực Khu vực về Tin sinh học (Bioinformatic Regional Resource) cho khu vực Trung-Đại Tây Dương (mid-Atlantic region) của các phòng thí nghiệm y tế công cộng cấp bang, nơi ông phối hợp đào tạo và cung cấp hỗ trợ chuyên môn trong lĩnh vực tin sinh học y tế công cộng. Logan rất tâm huyết với việc thúc đẩy các sáng kiến y tế công cộng bằng cách tìm kiếm các phương thức ứng dụng công nghệ điện toán đám mây và thúc đẩy (fostering) những phương pháp đổi mới trong giải quyết vấn đề.
