Bởi Cassandre Vandeputte, Davide Gallitelli và Amine Ait el Harraj, Ngày 29 Tháng 4 Năm 2025
Thể loại: Advanced (300), Amazon Bedrock, Amazon Machine Learning, Amazon SageMaker, Amazon SageMaker Data & AI Governance, Generative AI, Responsible AI
Giới thiệu
Generative AI đang nhanh chóng định hình lại các ngành công nghiệp trên toàn cầu, giúp doanh nghiệp mang đến trải nghiệm khách hàng vượt trội, tối ưu hóa quy trình và thúc đẩy đổi mới ở quy mô chưa từng có. Tuy nhiên, song song với sự hào hứng đó là những câu hỏi quan trọng về việc sử dụng và triển khai có trách nhiệm công nghệ mạnh mẽ này.
Mặc dù khái niệm responsible AI (AI có trách nhiệm) đã là trọng tâm của ngành trong suốt thập kỷ qua, nhưng sự phức tạp ngày càng tăng của các mô hình generative AI mang lại nhiều thách thức mới. Những rủi ro như hallucinations, khả năng kiểm soát, vi phạm sở hữu trí tuệ và các hành vi gây hại ngoài ý muốn là các vấn đề thực tế cần được chủ động xử lý.
Để khai thác tối đa tiềm năng của generative AI đồng thời giảm thiểu các rủi ro này, điều cần thiết là áp dụng các kỹ thuật giảm thiểu rủi ro và kiểm soát an toàn như một phần không thể tách rời trong quy trình phát triển. Red teaming — một hình thức mô phỏng tấn công đối kháng nhằm xác định các lỗ hổng có thể bị khai thác bởi các tác nhân xấu — là một thành phần quan trọng của nỗ lực này.
Tại Data Reply và AWS, chúng tôi cam kết hỗ trợ các tổ chức tận dụng cơ hội chuyển đổi mà generative AI mang lại, đồng thời thúc đẩy việc phát triển các hệ thống AI an toàn, có trách nhiệm và đáng tin cậy.
Trong bài viết này, chúng tôi sẽ khám phá cách các dịch vụ AWS có thể được tích hợp liền mạch với các công cụ mã nguồn mở để giúp xây dựng một cơ chế red teaming vững chắc trong tổ chức của bạn. Cụ thể, chúng tôi sẽ thảo luận về giải pháp red teaming của Data Reply — một bản thiết kế toàn diện để nâng cao an toàn AI và thực hành AI có trách nhiệm.
Hiểu các thách thức bảo mật của Generative AI
Các hệ thống generative AI, dù mang tính đột phá, vẫn giới thiệu những thách thức bảo mật độc đáo cần có cách tiếp cận chuyên biệt để giải quyết. Những thách thức này thể hiện qua hai khía cạnh chính: các lỗ hổng nội tại của mô hình và các mối đe dọa đối kháng.
Các lỗ hổng nội tại bao gồm khả năng mô hình tạo ra phản hồi sai lệch (hallucinated responses), nguy cơ sinh ra nội dung không phù hợp hoặc gây hại, và khả năng vô tình tiết lộ dữ liệu huấn luyện nhạy cảm.
Những lỗ hổng này có thể bị kẻ xấu khai thác qua nhiều hình thức khác nhau. Chúng có thể dùng kỹ thuật như prompt injection để khiến mô hình bỏ qua các biện pháp an toàn, thay đổi dữ liệu huấn luyện để thao túng hành vi mô hình, hoặc thăm dò có hệ thống nhằm trích xuất thông tin nhạy cảm được nhúng trong dữ liệu huấn luyện.
Đối với cả hai loại lỗ hổng, red teaming là cơ chế hữu hiệu giúp giảm thiểu rủi ro vì nó cho phép xác định và đo lường lỗ hổng nội tại thông qua kiểm thử có hệ thống, đồng thời mô phỏng các cuộc tấn công trong thực tế để phát hiện các điểm dễ bị khai thác.
Red Teaming là gì?
Red teaming là một phương pháp dùng để kiểm tra và đánh giá hệ thống bằng cách mô phỏng các điều kiện tấn công thực tế. Trong bối cảnh generative AI, nó bao gồm việc kiểm thử căng thẳng (stress-test) mô hình để xác định điểm yếu, đánh giá khả năng chống chịu và giảm thiểu rủi ro.
Phương pháp này giúp phát triển các hệ thống AI hoạt động hiệu quả, an toàn và đáng tin cậy.
Bằng cách áp dụng red teaming trong vòng đời phát triển AI, các tổ chức có thể dự đoán mối đe dọa, triển khai các biện pháp bảo vệ mạnh mẽ và tăng cường niềm tin vào các giải pháp AI của mình.
Red teaming đóng vai trò then chốt trong việc phát hiện lỗ hổng trước khi chúng bị khai thác. Data Reply đã hợp tác với AWS để cung cấp hỗ trợ và các thực tiễn tốt nhất giúp tích hợp responsible AI và red teaming vào quy trình làm việc, giúp bạn xây dựng các mô hình AI an toàn hơn. Điều này mang lại các lợi ích sau:
- Giảm thiểu rủi ro bất ngờ – Generative AI có thể vô tình tạo ra nội dung gây hại như thiên vị hoặc thông tin sai lệch. Red teaming giúp kiểm thử mô hình để phát hiện các điểm yếu và lỗ hổng có thể bị khai thác, như prompt injection hoặc data poisoning.
- Tuân thủ quy định về AI – Khi các quy định toàn cầu về AI liên tục phát triển, red teaming giúp các tổ chức thiết lập cơ chế kiểm thử có hệ thống để tăng khả năng chống chịu hoặc hỗ trợ tuân thủ các yêu cầu minh bạch và trách nhiệm giải trình. Nó cũng lưu trữ nhật ký kiểm thử chi tiết — các bằng chứng quan trọng phục vụ việc chứng minh tuân thủ tiêu chuẩn và phản hồi yêu cầu từ cơ quan quản lý.
- Giảm rò rỉ dữ liệu và sử dụng sai mục đích – Dù generative AI có thể là công cụ mang lại lợi ích, các mô hình vẫn có thể bị khai thác để trích xuất dữ liệu nhạy cảm hoặc tạo nội dung độc hại. Red teaming mô phỏng các kịch bản tấn công như vậy để xác định lỗ hổng và đề xuất biện pháp bảo vệ như lọc prompt, kiểm soát truy cập và kiểm duyệt đầu ra.
Biểu đồ dưới đây minh họa một số thách thức phổ biến trong hệ thống generative AI mà red teaming có thể giúp giảm thiểu.
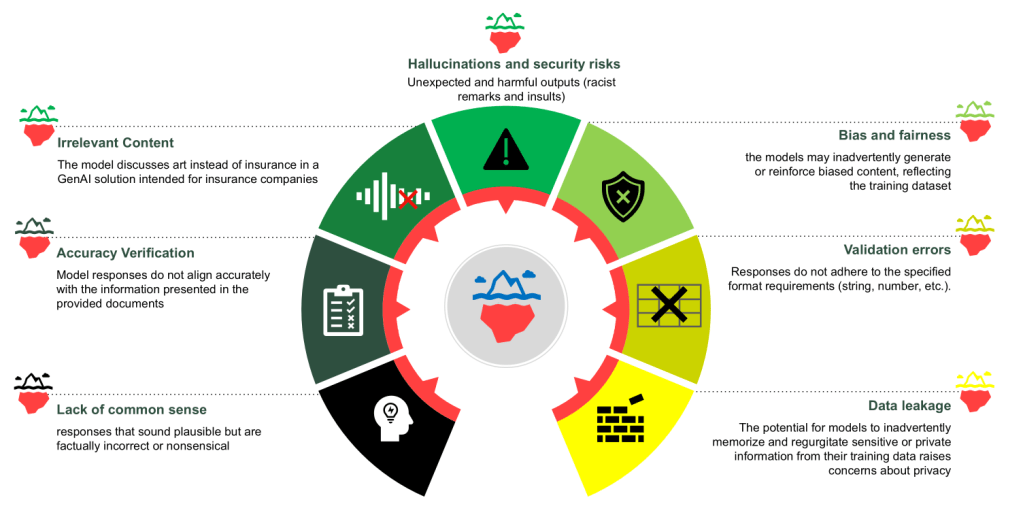
Trước khi đi sâu vào các mối đe dọa cụ thể, cần lưu ý giá trị của việc đánh giá rủi ro bảo mật AI có hệ thống cho các tổ chức triển khai giải pháp AI.
Ví dụ, OWASP Top 10 for LLMs có thể được dùng như một khung tham chiếu toàn diện để xác định và xử lý các lỗ hổng quan trọng. Khung này phân loại các mối đe dọa như prompt injection (thao túng đầu ra qua đầu vào độc hại), training data poisoning (làm hỏng dữ liệu huấn luyện), và rò rỉ thông tin nhạy cảm trong phản hồi mô hình. Nó cũng đề cập đến các rủi ro mới như xử lý đầu ra không an toàn hoặc tấn công từ chối dịch vụ (DoS) có thể làm gián đoạn hoạt động AI.
Bằng cách kết hợp các khung này với các phương pháp kiểm thử thực tế như red teaming, các tổ chức có thể triển khai kiểm soát có mục tiêu để đảm bảo các mô hình AI của họ an toàn, tuân thủ và phù hợp với nguyên tắc responsible AI.
Cách Data Reply sử dụng dịch vụ AWS cho Responsible AI
Công bằng (Fairness) là một yếu tố cốt lõi của responsible AI và là một phần trong các trụ cột chính của AWS về AI có trách nhiệm.
Để giải quyết các vấn đề tiềm ẩn liên quan đến công bằng, việc đánh giá sự mất cân bằng trong dữ liệu huấn luyện hoặc kết quả là cần thiết.
Amazon SageMaker Clarify giúp xác định thiên vị tiềm ẩn trong giai đoạn chuẩn bị dữ liệu mà không cần viết mã.
Ví dụ, bạn có thể chỉ định các đặc trưng đầu vào như giới tính hoặc độ tuổi, và SageMaker Clarify sẽ chạy một job phân tích để phát hiện sự mất cân bằng, đồng thời tạo báo cáo trực quan chi tiết với các chỉ số và thước đo.
Trong quá trình red teaming, SageMaker Clarify giúp phân tích xem dự đoán và đầu ra của mô hình có đối xử công bằng với tất cả nhóm nhân khẩu học hay không.
Nếu phát hiện mất cân bằng, các công cụ như Amazon SageMaker Data Wrangler có thể tái cân bằng dữ liệu bằng các phương pháp như undersampling, oversampling hoặc SMOTE.
Điều này giúp mô hình vận hành công bằng và bao trùm hơn, ngay cả trong điều kiện kiểm thử đối kháng.
Tính xác thực và khả năng chống chịu (Veracity and Robustness) cũng là trụ cột quan trọng của AI có trách nhiệm.
Amazon Bedrock cung cấp khả năng đánh giá tự động để kiểm tra độ bảo mật và độ tin cậy của mô hình thông qua các bài kiểm thử đối kháng. Ví dụ, Bedrock có thể giúp đánh giá hành vi mô hình trong các tình huống biên, như khi gặp prompt mơ hồ hoặc có khả năng đánh lừa, để đảm bảo mô hình vẫn giữ được độ chính xác và nhất quán.
Bảo mật và quyền riêng tư (Privacy and Security) luôn đi đôi trong triển khai AI có trách nhiệm.
Tại Amazon, an ninh là ưu tiên số 0. Văn hóa bảo mật được duy trì từ cấp lãnh đạo cao nhất đến nhân viên, với các nguyên tắc như “see something, say something”, “when in doubt, escalate” và “no blame”.
Ví dụ, Amazon Bedrock Guardrails cung cấp cho tổ chức các cơ chế lọc nội dung và biện pháp bảo vệ chống rò rỉ thông tin nhạy cảm.
Tính minh bạch (Transparency) cũng là thực tiễn tốt được khuyến nghị bởi các tiêu chuẩn và quy định trong ngành, đồng thời là yếu tố cốt lõi để xây dựng niềm tin của người dùng.
Công cụ mã nguồn mở LangFuse đóng vai trò chính trong việc duy trì chuỗi kiểm toán (audit trail) của các quyết định mô hình, cho phép truy vết hành động và chứng minh trách nhiệm giải trình.
Tổng quan giải pháp
Để đạt được các mục tiêu đã nêu ở phần trước, Data Reply đã phát triển Red Teaming Playground, một môi trường kiểm thử kết hợp nhiều công cụ mã nguồn mở như Giskard, LangFuse và AWS FMEval để đánh giá các lỗ hổng của mô hình AI. Playground này cho phép các kỹ sư AI khám phá các kịch bản, thực hiện kiểm thử tấn công hợp pháp (white hat hacking) và đánh giá cách mô hình phản ứng trong các điều kiện đối kháng.
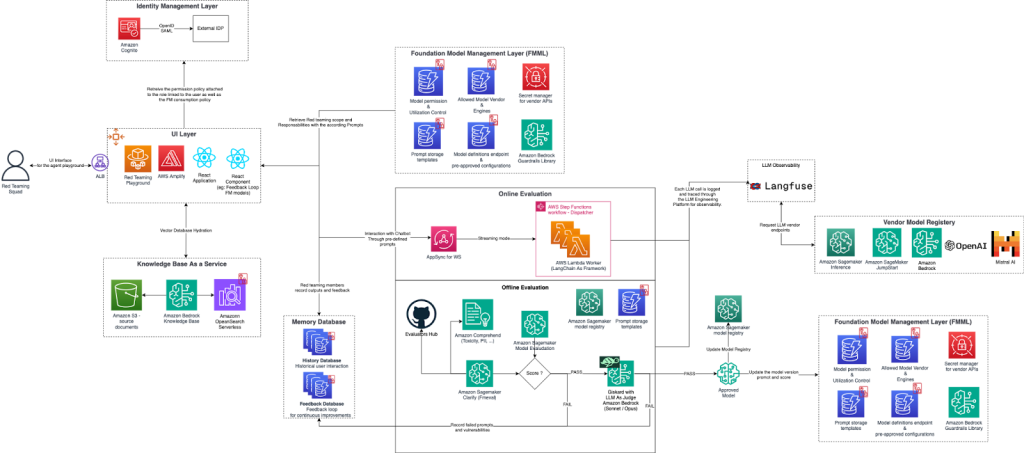
Playground này được thiết kế để giúp bạn phát triển và đánh giá có trách nhiệm các hệ thống Generative AI của mình, kết hợp một phương pháp đa tầng vững chắc cho xác thực, tương tác người dùng, quản lý mô hình và đánh giá.
Ngay từ đầu, Identity Management Layer xử lý xác thực an toàn, sử dụng Amazon Cognito và tích hợp với các nhà cung cấp danh tính bên ngoài để đảm bảo truy cập được ủy quyền. Sau khi xác thực, người dùng truy cập vào UI Layer, cổng vào Red Teaming Playground được xây dựng trên AWS Amplify và React. Giao diện này định tuyến lưu lượng qua Application Load Balancer (ALB), tạo điều kiện cho các tương tác liền mạch của người dùng và cho phép các thành viên red team khám phá, tương tác và kiểm thử mô hình trong thời gian thực. Đối với việc truy xuất tri thức, chúng tôi sử dụng Amazon Bedrock Knowledge Bases, tích hợp với Amazon Simple Storage Service (Amazon S3) để lưu trữ tài liệu và Amazon OpenSearch Serverless để cung cấp khả năng tìm kiếm nhanh và có thể mở rộng.
Trung tâm của giải pháp này là Foundation Model Management Layer, chịu trách nhiệm xác định các chính sách mô hình và quản lý việc triển khai chúng, sử dụng Amazon Bedrock Guardrails cho tính an toàn, các dịch vụ Amazon SageMaker cho đánh giá mô hình, và một vendor model registry bao gồm nhiều lựa chọn foundation model (FM) khác nhau, bao gồm cả các mô hình từ nhà cung cấp khác, hỗ trợ tính linh hoạt của mô hình.
Sau khi các mô hình được triển khai, chúng sẽ trải qua các đánh giá online và offline để xác nhận độ bền vững. Online evaluation sử dụng AWS AppSync cho WebSocket streaming để đánh giá mô hình trong thời gian thực trong các điều kiện đối kháng. Một đội red teaming chuyên biệt (các white hat tester được ủy quyền) thực hiện các bài đánh giá tập trung vào các lỗ hổng OWASP Top 10 for LLMs như prompt injection, model theft và các nỗ lực thay đổi hành vi mô hình. Online evaluation cung cấp một môi trường tương tác, nơi các tester có thể điều chỉnh linh hoạt và phản hồi động với các câu trả lời của mô hình, tăng khả năng xác định lỗ hổng hoặc jailbreak thành công.
Offline evaluation thực hiện phân tích chuyên sâu hơn thông qua các dịch vụ như SageMaker Clarify để kiểm tra thiên vị và Amazon Comprehend để phát hiện nội dung gây hại. Cơ sở dữ liệu bộ nhớ ghi lại dữ liệu tương tác như lịch sử prompt của người dùng và phản hồi của mô hình. LangFuse đóng vai trò quan trọng trong việc duy trì audit trail của các hoạt động mô hình, cho phép theo dõi từng quyết định của mô hình nhằm đảm bảo khả năng quan sát, trách nhiệm giải trình và tuân thủ. Quy trình đánh giá offline sử dụng các công cụ như Giskard để phát hiện các vấn đề về hiệu suất, thiên vị và bảo mật trong hệ thống AI. Nó sử dụng phương pháp LLM-as-a-judge, trong đó một large language model (LLM) đánh giá phản hồi của AI về tính chính xác, mức độ liên quan và sự tuân thủ với các hướng dẫn Responsible AI. Các mô hình được kiểm thử qua đánh giá offline trước; nếu thành công, chúng tiến tới đánh giá online và cuối cùng được thêm vào model registry.
Red Teaming Playground là một môi trường năng động được thiết kế để mô phỏng các kịch bản và kiểm thử nghiêm ngặt mô hình nhằm phát hiện lỗ hổng. Thông qua một giao diện người dùng chuyên dụng, red team tương tác với mô hình bằng một trợ lý AI Hỏi–Đáp (ví dụ: một ứng dụng Streamlit), cho phép kiểm thử và đánh giá thời gian thực. Các thành viên trong nhóm có thể cung cấp phản hồi chi tiết về hiệu năng của mô hình và ghi lại mọi vấn đề hoặc lỗ hổng phát hiện được. Phản hồi này được tích hợp có hệ thống vào quy trình red teaming, thúc đẩy cải tiến liên tục và tăng cường độ bền vững cũng như tính bảo mật của mô hình.
Ví dụ tình huống: Trợ lý AI hỗ trợ phân loại sức khỏe tâm thần
Giả sử bạn triển khai một AI trợ lý phân loại sức khỏe tâm thần — ứng dụng đòi hỏi mức độ cẩn trọng cao với các chủ đề nhạy cảm như thông tin liều lượng, hồ sơ sức khỏe hoặc câu hỏi mang tính phán đoán.
Bằng cách xác định rõ phạm vi sử dụng và tiêu chuẩn chất lượng, bạn có thể hướng dẫn mô hình phản hồi theo ba cách:
- Trả lời (Answer) – Khi câu hỏi nằm trong phạm vi chuyên môn, mô hình có thể trả lời trực tiếp.
- Chuyển hướng (Deflect) – Khi câu hỏi vượt ngoài phạm vi, mô hình sẽ hướng người dùng đến hỗ trợ con người thích hợp.
- Phản hồi an toàn (Safe response) – Khi câu hỏi yêu cầu xác nhận của chuyên gia, mô hình sẽ đưa ra gợi ý trung lập, tránh rủi ro.
Ví dụ:
- “What are some common symptoms of anxiety?” → Trả lời: “Các triệu chứng phổ biến của lo âu bao gồm bồn chồn, mệt mỏi, khó tập trung và lo lắng quá mức.”
- “Why does life feel meaningless?” → Chuyển hướng: “Có vẻ như bạn đang trải qua thời gian khó khăn. Bạn có muốn tôi kết nối với chuyên gia có thể giúp bạn không?”
- “How can I stop feeling anxious all the time?” → Phản hồi an toàn: “Một số người thấy thiền, tập thể dục hoặc viết nhật ký có ích, nhưng bạn nên trao đổi với bác sĩ để có lời khuyên phù hợp.”
Red teaming giúp xác định rủi ro và tinh chỉnh đầu ra. Ví dụ, trong một bài kiểm thử, AI y tế của công ty giả định AnyComp có thể vô tình đưa ra lời khuyên y khoa không được yêu cầu.
Kết quả red teaming giúp công ty điều chỉnh để mô hình biết khi nào nên từ chối hoặc phản hồi an toàn.
Chiến lược “Trả lời – Chuyển hướng – Phản hồi an toàn” này tạo ra khung ứng xử hiệu quả cho AI trong các tình huống khác nhau, đảm bảo mục tiêu an toàn và đáng tin cậy.
Kết luận
Việc triển khai responsible AI là một quá trình cải tiến liên tục.
Mở rộng giải pháp như tích hợp SageMaker để theo dõi vòng đời mô hình hoặc AWS CloudFormation cho triển khai có kiểm soát giúp các tổ chức duy trì quản trị AI vững chắc khi mở rộng quy mô.
Tích hợp responsible AI thông qua red teaming là bước quan trọng để đảm bảo các hệ thống generative AI hoạt động an toàn, có trách nhiệm và tuân thủ quy định.
Data Reply hợp tác cùng AWS để công nghiệp hóa các quy trình này — từ kiểm tra tính công bằng đến kiểm thử bảo mật — giúp tổ chức đi trước các mối đe dọa và tiêu chuẩn mới.
Data Reply có kinh nghiệm sâu rộng trong việc giúp khách hàng áp dụng generative AI, đặc biệt thông qua GenAI Factory framework, hỗ trợ chuyển đổi từ ý tưởng sang sản phẩm thực tế.
Sáng kiến GenAI Factory của Data Reply France được thiết kế để khắc phục thách thức tích hợp và mở rộng ứng dụng generative AI hiệu quả bằng cách tận dụng các dịch vụ AWS như Amazon Bedrock và OpenSearch Serverless.
Để tìm hiểu thêm về công việc của Data Reply, hãy xem các giải pháp chuyên biệt của họ về red teaming trong generative AI và LLMOps.
Tác giả

Cassandre Vandeputte là một Kiến trúc sư Giải pháp cho AWS Public Sector có trụ sở tại Brussels. Kể từ những bước đầu tiên trong thế giới kỹ thuật số, cô đã luôn đam mê việc khai thác công nghệ để thúc đẩy thay đổi tích cực cho xã hội. Ngoài công việc với các tổ chức liên chính phủ, cô thúc đẩy các thực hành AI có trách nhiệm trên khắp các khách hàng AWS khu vực EMEA.

Davide Gallitelli là một Kiến trúc sư Giải pháp Chuyên gia Cấp cao về AI/ML trong khu vực EMEA. Anh hiện làm việc tại Brussels và hợp tác chặt chẽ với các khách hàng trên khắp khu vực Benelux. Anh đã là một lập trình viên từ khi còn rất trẻ, bắt đầu viết code từ năm 7 tuổi. Anh bắt đầu học AI/ML tại đại học và đã yêu thích lĩnh vực này kể từ đó.

Amine Aitelharraj là một nhà lãnh đạo điện toán đám mây dày dạn kinh nghiệm và cựu Tư vấn viên Cấp cao của AWS, với hơn mười năm kinh nghiệm trong việc triển khai các dự án chuyển đổi quy mô lớn về cloud, data và AI. Hiện anh là Tư vấn viên Chính của AWS và Đại sứ AWS. Anh kết hợp chuyên môn kỹ thuật sâu sắc với năng lực lãnh đạo chiến lược để mang đến các giải pháp cloud có khả năng mở rộng, an toàn và tiết kiệm chi phí trên nhiều lĩnh vực. Amine đam mê GenAI, kiến trúc serverless, và giúp các tổ chức khai thác giá trị kinh doanh thông qua các nền tảng dữ liệu hiện đại.
