Tác giả: Satish Nandi and Jon Handler
Ngày đăng: Ngày 2 Tháng 8, 2024
Danh mục: Amazon OpenSearch Service, Announcements, AWS Big Data, Foundational (100), Price Reduction
Chúng tôi rất vui mừng thông báo mức chi phí đầu vào thấp hơn cho Amazon OpenSearch Serverless. Với việc hỗ trợ 0.5 Đơn vị tính toán OpenSearch (OpenSearch Compute Units – OCU) cho việc lập chỉ mục và các workload tìm kiếm, chi phí đầu vào được giảm một nửa. Amazon OpenSearch Serverless là một tùy chọn serverless deployment cho Amazon OpenSearch Service, cho phép bạn chạy các workload tìm kiếm và phân tích mà không phải quản lý phức tạp về hạ tầng, điều chỉnh shard (shard tuning) hay quản lý vòng đời dữ liệu. OpenSearch Serverless tự động cấp phát và mở rộng tài nguyên để cung cấp tốc độ nhập dữ liệu ổn định và thời gian phản hồi truy vấn ở mức mili giây (millisecond) ngay cả khi mẫu sử dụng và yêu cầu ứng dụng thay đổi.
OpenSearch Serverless cung cấp ba loại tập hợp (collection) để đáp ứng nhu cầu của bạn: Time-series, search, và vector. Mức chi phí đầu vào thấp hơn mới mang lại lợi ích cho tất cả các loại tập hợp. Các tập hợp vector trở nên nổi bật như một khối công việc chính khi sử dụng OpenSearch Serverless làm cơ sở kiến thức Amazon Bedrock. Với việc giới thiệu một nửa OCUs, chi phí cho các workload vector nhỏ giảm một nửa. Các Time-series và các tập hợp time-series và tìm kiếm cũng được hưởng lợi, đặc biệt đối với các workload nhỏ như triển khai proof-of-concept và môi trường phát triển, kiểm thử.
Một OCU đầy đủ bao gồm một vCPU, 6GB RAM và 120GB lưu trữ. Một nửa OCU cung cấp nửa vCPU, 3GB RAM, và 60GB lưu trữ. OpenSearch Serverless mở rộng một nửa OCU trước thành một OCU đầy đủ, sau đó tăng theo các bước một OCU. Mỗi OCU cũng sử dụng Amazon Simple Storage Service (Amazon S3) làm kho lưu trữ nền (backing store); bạn sẽ trả phí cho dữ liệu lưu trữ trên Amazon S3 bất kể kích thước OCU. Số lượng OCU cần cho triển khai phụ thuộc vào loại tập hợp, cũng như các mẫu nhập dữ liệu (ingestion) và tìm kiếm. Chúng tôi sẽ đi vào chi tiết sau trong bài viết và so sánh cách mà mức OCU cơ bản (base) mới (là 0.5 OCU) mang lại lợi ích.
OpenSearch Serverless tách riêng tài nguyên tính toán cho việc lập chỉ mục và tài nguyên tính toán cho tìm kiếm, triển khai các bộ OCU cho từng nhu cầu tính toán. Bạn có thể triển khai OpenSearch Serverless theo hai hình thức: 1) Triển khai có dự phòng cho môi trường sản xuất, và 2) Triển khai không có dự phòng cho phát triển hoặc kiểm thử.
Lưu ý: OpenSearch Serverless triển khai gấp đôi tài nguyên tính toán cho cả lập chỉ mục và tìm kiếm trong các triển khai có dự phòng.
Loại triển khai OpenSearch Serverless
Hình dưới đây minh họa kiến trúc của OpenSearch Serverless trong chế độ dự phòng.
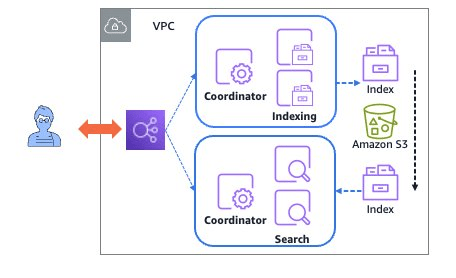
Trong chế độ dự phòng, OpenSearch Serverless triển khai hai OCU cơ bản cho mỗi tập hợp tài nguyên tính toán (lập chỉ mục và tìm kiếm) trên hai Availability Zone. Đối với các khối công việc nhỏ dưới 60GB, OpenSearch Serverless sử dụng nửa OCU làm kích thước cơ bản. Triển khai tối thiểu là bốn đơn vị cơ bản, mỗi loại hai đơn vị cho lập chỉ mục (indexing) và tìm kiếm (search). Chi phí tối thiểu khoảng 350 USD mỗi tháng (bốn nửa OCU). Tất cả giá được báo dựa trên khu vực US-East (N. Virginia) và tính cho 30 ngày một tháng. Trong quá trình vận hành bình thường, tất cả các OCU đều hoạt động để phục vụ lưu lượng. OpenSearch Serverless sẽ mở rộng từ mức cơ bản này khi cần thiết.
Đối với triển khai không dự phòng, OpenSearch Serverless triển khai một OCU cơ bản cho mỗi tập hợp tài nguyên tính toán, với chi phí 174 USD mỗi tháng (hai nửa OCU).
Cấu hình dự phòng được khuyến nghị cho triển khai sản xuất nhằm duy trì tính sẵn sàng; nếu một Availability Zone gặp sự cố, vùng còn lại vẫn có thể phục vụ lưu lượng. Triển khai không dự phòng phù hợp cho môi trường phát triển và kiểm thử để giảm chi phí. Trong cả hai cấu hình, bạn có thể thiết lập giới hạn tối đa OCU để quản lý chi phí. Hệ thống sẽ mở rộng đến giới hạn này trong thời điểm tải cao nếu cần, nhưng sẽ không vượt quá.
Các tập hợp (collection) OpenSearch Serverless và việc phân bổ tài nguyên
OpenSearch Serverless sử dụng các đơn vị tính toán khác nhau tùy thuộc vào loại tập hợp và lưu trữ dữ liệu của bạn trong Amazon S3. Khi bạn đưa dữ liệu vào, OpenSearch Serverless ghi dữ liệu vào ổ đĩa của OCU và Amazon S3 trước khi xác nhận yêu cầu, đảm bảo độ bền của dữ liệu và hiệu suất hệ thống. Tùy theo loại tập hợp, nó còn lưu dữ liệu trong bộ nhớ cục bộ (local storage) của các OCU, mở rộng để đáp ứng nhu cầu lưu trữ và tính toán.
Loại tập hợp time-series được thiết kế để tiết kiệm chi phí bằng cách giới hạn lượng dữ liệu giữ trong bộ nhớ cục bộ, còn phần còn lại lưu trong Amazon S3. Số lượng OCU cần thiết phụ thuộc vào khối lượng dữ liệu và thời hạn lưu trữ (retention period) của tập hợp. Số lượng OCU mà OpenSearch Serverless sử dụng cho workload của bạn là giá trị lớn hơn giữa số OCU tối thiểu mặc định hoặc số OCU tối thiểu cần để chứa phần dữ liệu gần đây nhất, theo chính sách vòng đời dữ liệu của OpenSearch Serverless. Ví dụ, nếu bạn nhập dữ liệu 1 TiB mỗi ngày và có thời hạn lưu trữ 30 ngày, kích thước dữ liệu gần đây nhất sẽ là 1 TiB. Bạn sẽ cần 20 OCU [10 OCU x 2] cho lập chỉ mục và 20 OCU khác [10 OCU x 2] cho tìm kiếm, dựa trên 120 GiB dung lượng lưu trữ trên mỗi OCU. Truy cập dữ liệu cũ hơn trong Amazon S3 sẽ làm tăng độ trễ của phản hồi truy vấn. Đây là sự đánh đổi (tradeoff) về độ trễ truy vấn đối với dữ liệu cũ, nhằm tiết kiệm chi phí OCU.
Loại tập hợp vector sử dụng RAM để lưu trữ đồ thị vector và sử dụng ổ đĩa để lưu các chỉ mục. Các tập hợp vector giữ dữ liệu chỉ mục trong bộ nhớ cục bộ của OCU. Khi xác định kích thước cho các workload vector, cần tính đến cả hai nhu cầu này. Giới hạn RAM của OCU đạt nhanh hơn giới hạn ổ đĩa, khiến tập hợp vector bị giới hạn bởi dung lượng RAM.
OpenSearch Serverless phân bổ tài nguyên OCU cho các tập hợp vector như sau. Khi sử dụng OCU đầy đủ, nó dùng 2 GB cho hệ điều hành, 2 GB cho Java heap, và 2 GB còn lại cho đồ thị vector (vector graphs). Nó sử dụng 120 GB bộ nhớ cục bộ cho các chỉ mục OpenSearch. RAM cần thiết cho một đồ thị vector phụ thuộc vào số chiều của vector, số lượng vector lưu trữ và thuật toán được chọn. Xem “Chọn thuật toán k-NN cho trường hợp sử dụng quy mô tỷ tỷ (billion-scale) với OpenSearch” để tham khảo công thức giúp tính trước nhu cầu RAM cho đồ thị vector trong triển khai OpenSearch Serverless của bạn.
Lưu ý: Nhiều hành vi của hệ thống được giải thích tính đến tháng 6 năm 2024. Hãy theo dõi trong những tháng tới khi các cải tiến mới tiếp tục giảm chi phí.
Các khu vực AWS được hỗ trợ
Hỗ trợ mức OCU tối thiểu mới cho OpenSearch Serverless hiện có sẵn ở tất cả các khu vực hỗ trợ OpenSearch Serverless. Xem danh sách Dịch vụ Khu vực AWS để biết thêm thông tin về khả năng sẵn có của OpenSearch Service. Xem tài liệu để tìm hiểu thêm về OpenSearch Serverless.
Kết luận
Việc giới thiệu 0.5 OCU mang lại sự giảm đáng kể chi phí cơ bản của Amazon OpenSearch Serverless. Nếu bạn có tập dữ liệu nhỏ và mức sử dụng hạn chế, bạn có thể tận dụng mức chi phí thấp hơn này. Tính tiết kiệm chi phí của giải pháp này cùng với việc quản lý đơn giản các workloads tìm kiếm và phân tích dữ liệu đảm bảo hoạt động liền mạch ngay cả khi nhu cầu về lưu lượng thay đổi.
Về các tác giả

Satish Nandi là Senior Product Manager tại Amazon OpenSearch Service. Ông tập trung vào OpenSearch Serverless và Geospatial, với nhiều năm kinh nghiệm trong mạng máy tính, bảo mật, cũng như Machine Learning (ML) và Artificial Intelligence (AI). Ông tốt nghiệp BEng ngành Khoa học Máy tính và có bằng MBA về Khởi nghiệp. Trong thời gian rảnh, ông thích lái máy bay, bay dù lượn, và đi xe máy.

Jon Handler là Senior Principal Solutions Architect tại Amazon Web Services, trụ sở tại Palo Alto, CA. Jon làm việc chặt chẽ với OpenSearch và Amazon OpenSearch Service, cung cấp hỗ trợ và hướng dẫn cho nhiều khách hàng có workloads về tìm kiếm và phân tích log muốn chuyển sang AWS Cloud. Trước khi gia nhập AWS, Jon có bốn năm kinh nghiệm lập trình cho một công cụ tìm kiếm thương mại điện tử quy mô lớn. Jon có bằng Cử nhân Nghệ thuật (Bachelor of the Arts) từ University of Pennsylvania, Thạc sĩ Khoa học (Master of Science) và Tiến sĩ (Ph.D.) ngành Khoa học Máy tính và Artificial Intelligence từ Northwestern University.
