Tác giả: Christian Bock, Luca Franceschi, Laurent Callot, Martin Wistuba, Shihab Rashid, Prabhu Teja, Simon Valentin, Woojung Kim, Giovanni Zappella, và Yuan Zhuang
Ngày đăng: 23/04/2025
Danh mục: Announcements, Artificial Intelligence, Thought Leadership
Các tác nhân mã hóa (Coding agents) được hỗ trợ bởi các mô hình ngôn ngữ lớn (large language models) đã cho thấy những khả năng ấn tượng trong các tác vụ kỹ thuật phần mềm, nhưng việc đánh giá hiệu suất của chúng trên các ngôn ngữ lập trình đa dạng và các kịch bản thực tế vẫn còn là một thách thức. Điều này dẫn đến sự bùng nổ gần đây trong việc tạo ra các benchmark (chuẩn đánh giá) để đo lường hiệu quả mã hóa của các hệ thống nói trên trong môi trường được kiểm soát. Cụ thể, SWE-Bench—vốn đo lường hiệu suất của các hệ thống trong bối cảnh các “issue” (vấn đề) trên GitHub—đã thúc đẩy sự phát triển của các tác nhân mã hóa có năng lực, dẫn đến hơn 50 lượt đệ trình lên bảng xếp hạng (leaderboard), qua đó trở thành tiêu chuẩn de-facto (thực tế) để đánh giá các tác nhân mã hóa. Mặc dù có tác động đáng kể với tư cách là một benchmark tiên phong, SWE-Bench, và cụ thể là tập hợp con “đã được xác minh” (verified) của nó, cũng cho thấy một số hạn chế. Nó chỉ chứa các repository (kho lưu trữ) Python, phần lớn các tác vụ là sửa lỗi (bug fixes), và với hơn 45% tổng số tác vụ, repository Django bị chiếm tỷ lệ quá cao (over-represented).
Hôm nay, Amazon giới thiệu SWE-PolyBench, benchmark (chuẩn đánh giá) công nghiệp đầu tiên để đánh giá khả năng của các tác nhân mã hóa AI trong việc điều hướng (navigate) và hiểu các codebase (cơ sở mã) phức tạp, đồng thời giới thiệu các chỉ số (metrics) phong phú để nâng cao hiệu suất AI trong các kịch bản thực tế. SWE-PolyBench chứa hơn 2.000 “issue” (vấn đề) được tuyển chọn kỹ lưỡng bằng bốn ngôn ngữ. Ngoài ra, nó còn chứa một tập hợp con được phân tầng (stratified subset) gồm 500 “issue” (SWE-PolyBench500) cho mục đích thử nghiệm nhanh. SWE-PolyBench đánh giá hiệu suất của các tác nhân mã hóa AI thông qua một bộ chỉ số toàn diện: tỷ lệ vượt qua (pass rates) ở các ngôn ngữ lập trình và mức độ phức tạp của tác vụ khác nhau, cùng với các phép đo precision (độ chính xác) và recall (độ phủ) để xác định bối cảnh mã/tệp. Các chỉ số đánh giá này có thể giúp cộng đồng giải quyết các thách thức trong việc hiểu rõ mức độ các tác nhân mã hóa AI có thể điều hướng và hiểu các codebase phức tạp.
Bảng xếp hạng (leaderboard) có thể được truy cập tại đây. Bộ dữ liệu SWE-PolyBench có sẵn trên Hugging Face và bài báo khoa học (paper) tại arxiv. Việc đánh giá có thể được chạy bằng cách sử dụng codebase của SWE-PolyBench.
Dưới đây, chúng tôi mô tả các tính năng chính, đặc điểm và quy trình tạo bộ dữ liệu của chúng tôi cùng với các chỉ số đánh giá mới và hiệu suất của các tác nhân mã nguồn mở (open source agents) từ các thử nghiệm của chúng tôi.
Sơ lược về các tính năng chính của SWE-PolyBench
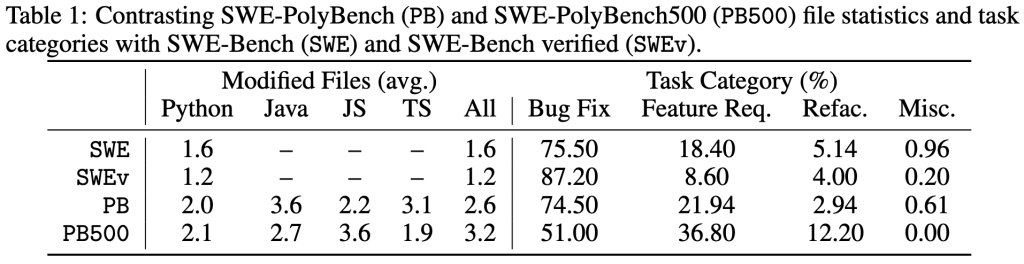
- Hỗ trợ đa ngôn ngữ: Java (165 tác vụ), JavaScript (1017 tác vụ), TypeScript (729 tác vụ), và Python (199 tác vụ).
- Bộ dữ liệu mở rộng: 2110 trường hợp (instances) từ 21 repository (kho lưu trữ) trải dài từ các web framework đến các trình biên tập mã (code editors) và công cụ ML, ở cùng quy mô với SWE-Bench (bản đầy đủ) với nhiều repository hơn.
- Đa dạng tác vụ: Bao gồm sửa lỗi (bug fixes), yêu cầu tính năng (feature requests), và tái cấu trúc mã (code refactoring).
- Thử nghiệm nhanh hơn: SWE-PolyBench500 là một tập hợp con được phân tầng (stratified subset) để thử nghiệm hiệu quả.
- Bảng xếp hạng: Một bảng xếp hạng (leaderboard) với bộ chỉ số phong phú để đánh giá (benchmarking) một cách minh bạch.
Xây dựng một bộ dữ liệu toàn diện
Việc tạo ra SWE-PolyBench bao gồm một quy trình thu thập và lọc dữ liệu được thiết kế để đảm bảo chất lượng và mức độ liên quan của các tác vụ benchmark. SWE-Bench, một benchmark để tạo mã Python, đánh giá các tác nhân dựa trên các tác vụ lập trình trong thực tế bằng cách sử dụng các “issue” (vấn đề) trên GitHub và các sửa đổi mã (code) và kiểm thử (test) tương ứng. Chúng tôi đã mở rộng quy trình (pipeline) thu thập dữ liệu của SWE-Bench để hỗ trợ thêm 3 ngôn ngữ ngoài Python và sử dụng nó để thu thập và xử lý các thách thức mã hóa từ các repository trong thực tế như trong Hình 1.
Một sơ đồ quy trình (flowchart) mô tả quy trình phát triển phần mềm. Bắt đầu với một “issue” (#3039) và “pull request” (#3147) ở bên trái, đi qua một bộ lọc metadata ở giữa, sau đó chia thành giai đoạn thiết lập runtime và kiểm thử ở bên phải. Giai đoạn kiểm thử đưa vào một bộ lọc dựa trên kiểm thử ở cuối. Sơ đồ bao gồm các biểu tượng cho các ngôn ngữ lập trình như JavaScript, TypeScript, Python, và Java.

Hình 1: Tổng quan về quy trình (pipeline) tạo dữ liệu của SWE-PolyBench, minh họa quy trình thu thập, lọc, và xác thực các tác vụ mã hóa.
Quy trình (pipeline) thu thập dữ liệu sẽ thu thập các pull request (PR) mà đóng (close) các “issue” (vấn đề) từ các repository phổ biến trên các ngôn ngữ Java, JavaScript, TypeScript, và Python. Các PR này trải qua quá trình lọc và được thiết lập trong các môi trường được container hóa (containerized environments) để thực thi kiểm thử (test execution) một cách nhất quán. Quy trình này phân loại các kiểm thử là fail-to-pass (F2P – từ thất bại đến thành công) hoặc pass-to-pass (P2P – từ thành công đến thành công) dựa trên kết quả của chúng trước và sau khi áp dụng bản vá (patch). Chỉ các PR có ít nhất một kiểm thử F2P mới được đưa vào bộ dữ liệu cuối cùng, đảm bảo rằng mỗi tác vụ đại diện cho một thách thức mã hóa có ý nghĩa. Cách tiếp cận tinh gọn này tạo ra một bộ dữ liệu mô phỏng sát với các kịch bản mã hóa trong thực tế, cung cấp một nền tảng vững chắc để đánh giá các trợ lý mã hóa AI (AI coding assistants).
Đặc điểm bộ dữ liệu
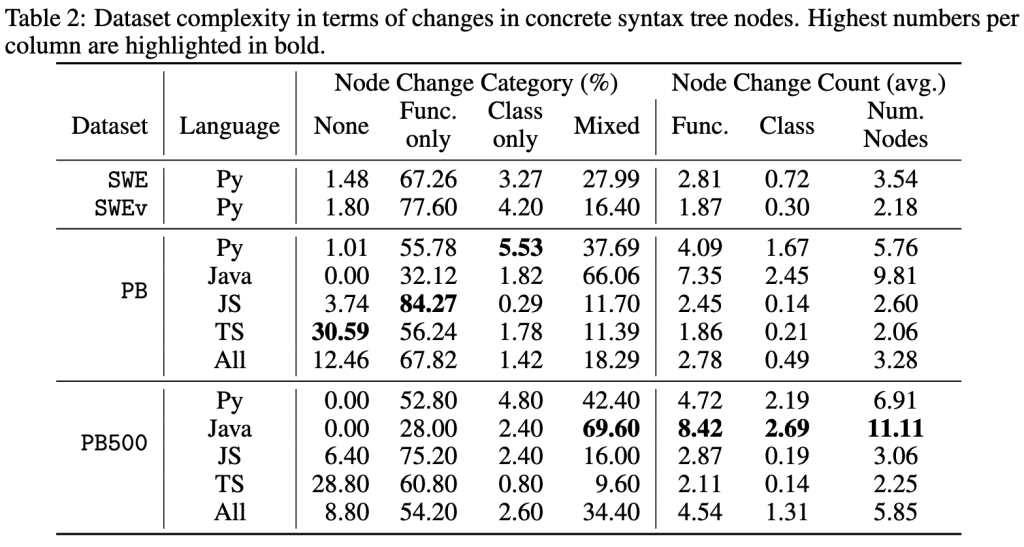
Khi xây dựng SWE-PolyBench, chúng tôi hướng đến việc thu thập các “issue” (vấn đề) trên GitHub đại diện cho các kịch bản lập trình đa dạng: các “issue” liên quan đến sửa đổi trên nhiều tệp mã và trải rộng trên các loại tác vụ khác nhau (như sửa lỗi, yêu cầu tính năng, và tái cấu trúc). Bảng 1 và 2 cung cấp các thống kê mô tả về thành phần và độ phức tạp của SWE-PolyBench (bản đầy đủ – PB) và SWE-PolyBench500 (PB500). Để cung cấp một điểm tham chiếu, chúng tôi so sánh các số liệu thống kê này với SWE-Bench (SWE) và SWE-Bench verified (SWEv). Các tác vụ trong SWE-PolyBench trung bình yêu cầu sửa đổi nhiều tệp hơn và thay đổi nhiều “node” (nút) hơn, điều này cho thấy chúng có độ phức tạp cao hơn và gần gũi hơn với các tác vụ trong các dự án thực tế. Sự phân bổ của các tác vụ cũng đa dạng hơn, đặc biệt là đối với SWE-PolyBench500.
Các chỉ số đánh giá mới
Để đánh giá toàn diện các trợ lý mã hóa AI (AI coding assistants), SWE-Polybench giới thiệu nhiều chỉ số (metrics) mới bên cạnh tỷ lệ vượt qua (pass rate). Tỷ lệ vượt qua là tỷ lệ các tác vụ được giải quyết thành công, được đo bằng việc bản vá (patch) được tạo ra vượt qua tất cả các kiểm thử (tests) liên quan. Đây là chỉ số chính để đánh giá hiệu suất của tác nhân mã hóa, nhưng nó không cung cấp một bức tranh toàn cảnh về khả năng của một tác nhân. Cụ thể, nó không cung cấp nhiều thông tin về khả năng điều hướng (navigate) và hiểu các repository (kho lưu trữ) mã phức tạp. SWE-PolyBench giới thiệu một bộ chỉ số mới dựa trên phân tích node (nút) của Cây Cú pháp Cụ thể (Concrete Syntax Tree – CST) và chỉ số “định vị cấp độ tệp” (file-level localization) đã được thiết lập:
- Định vị cấp độ tệp (File-level Localization): đánh giá khả năng của tác nhân trong việc xác định đúng các tệp cần được sửa đổi trong một repository. Giả sử chúng ta cần sửa đổi file.py để giải quyết vấn đề. Nếu tác nhân mã hóa của chúng ta thực hiện một thay đổi trong bất kỳ tệp nào khác, nó sẽ nhận được điểm truy xuất tệp (file retrieval score) là 0.
- Truy xuất cấp độ Node CST (CST Node-level Retrieval): đánh giá khả năng của tác nhân trong việc xác định các cấu trúc mã cụ thể đòi hỏi thay đổi. Nó sử dụng biểu diễn Cây Cú pháp Cụ thể (CST) của mã để đo lường mức độ chính xác mà tác nhân có thể định vị các hàm (functions) hoặc lớp (classes) chính xác cần sửa đổi.
Một so sánh song song cho thấy hai bản “diff” (khác biệt) của kiểm soát phiên bản Git. Mỗi “diff” cho thấy một dòng bị xóa (màu đỏ, tiền tố ‘-‘) nơi my_var bằng 3, và một dòng được thêm vào (màu xanh lá, tiền tố ‘+’) nơi my_var bằng 2. Phía trên các “diff” là các chấm được kết nối với các màu khác nhau (xanh lá, hồng, xanh dương, và vàng) đại diện cho trực quan hóa lịch sử commit của Git.
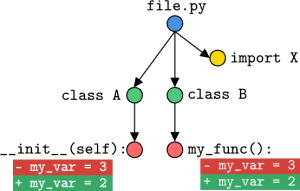
Hình 2: Minh họa về các thay đổi node (nút) CST.
Trong Hình 2, chúng ta thấy một thay đổi ở node lớp (class node) A được thể hiện bằng một thay đổi trong hàm khởi tạo (initialization function) của nó trên đường dẫn bên trái bắt đầu từ node tệp (file node). Ngược lại với thay đổi đầu tiên, thay đổi trong lớp B được coi là một thay đổi node hàm (function node change) vì nó không ảnh hưởng đến việc khởi tạo (construction) lớp.
Giả sử thay đổi có thể giải quyết vấn đề của chúng ta là thay đổi trong hàm __init__. Nếu tác nhân mã hóa của chúng ta thực hiện thay đổi trong my_func, nó sẽ nhận được điểm truy xuất (retrieval score) cho cả node lớp và node hàm là 0.
Bằng cách kết hợp đánh giá tỷ lệ vượt qua (pass rate) với cả chỉ số truy xuất cấp độ tệp và cấp độ node CST, SWE-PolyBench cung cấp một đánh giá chi tiết về khả năng của các trợ lý mã hóa AI trong các kịch bản thực tế. Cách tiếp cận này cung cấp những hiểu biết sâu sắc hơn về mức độ các tác nhân điều hướng và hiểu các codebase phức tạp, vượt ra ngoài việc hoàn thành tác vụ đơn giản để đánh giá sự hiểu biết của chúng về cấu trúc và tổ chức mã.
Hiệu suất của các tác nhân mã hóa nguồn mở
Những phát hiện chính
- Năng lực ngôn ngữ: Python là ngôn ngữ mạnh nhất đối với tất cả các tác nhân, có thể là do sự phổ biến của nó trong dữ liệu huấn luyện và các benchmark (chuẩn đánh giá) hiện có.
- Thách thức về độ phức tạp: Hiệu suất giảm khi độ phức tạp của tác vụ tăng lên, đặc biệt là khi cần sửa đổi từ 3 tệp trở lên.
- Chuyên môn hóa tác vụ: Các tác nhân khác nhau cho thấy điểm mạnh trong các loại tác vụ khác nhau (sửa lỗi, yêu cầu tính năng, tái cấu trúc).
- Tầm quan trọng của bối cảnh: Mức độ cung cấp thông tin của các mô tả vấn đề (problem statements) ảnh hưởng đến tỷ lệ thành công của tất cả các tác nhân (tham khảo Hình 5 của bài báo trong phần phụ lục để biết chi tiết về phân tích này).
Nhiều tác nhân nguồn mở hiện có được thiết kế chủ yếu cho Python. Việc điều chỉnh chúng để hoạt động cho cả bốn ngôn ngữ của SWE-PolyBench đòi hỏi phải điều chỉnh các lệnh thực thi kiểm thử (test execution commands), sửa đổi các cơ chế phân tích cú pháp (parsing mechanisms), và điều chỉnh các chiến lược container hóa (containerization strategies) cho từng ngôn ngữ. Chúng tôi đã điều chỉnh và đánh giá ba tác nhân nguồn mở trên SWE-PolyBench. Các điều chỉnh nói trên được phản ánh bằng hậu tố “-PB” được thêm vào tên tác nhân gốc.
Hai biểu đồ radar (radar charts) so sánh ba mô hình AI: Aider-PB Sonnet 3.5, Agentless-PB Sonnet 3.5, và SWE-agent-PB Sonnet 3.5. Biểu đồ bên trái hiển thị hiệu suất trên các ngôn ngữ lập trình (Java, JavaScript, TypeScript, Python). Biểu đồ bên phải hiển thị hiệu suất trong các phong cách mã hóa (coding styles) khác nhau (Chỉ hàm (Functional only), Một hàm (Single Function), Tất cả (All), Hỗn hợp (Mixed), Không có node (No nodes), Một lớp (Single Class), Chỉ lớp (Class only)). Mỗi mô hình được biểu thị bằng một đường màu khác nhau, trong đó Aider-PB nhìn chung cho thấy hiệu suất cao nhất trong các danh mục.

Hình 3: Hiệu suất của các tác nhân mã hóa trên các ngôn ngữ lập trình và độ phức tạp của tác vụ, nêu bật các điểm mạnh và các lĩnh vực cần cải thiện.
Hình 3 cung cấp một biểu diễn trực quan về hiệu suất của tác nhân trên các khía cạnh khác nhau:
- Năng lực ngôn ngữ: Phía bên trái của biểu đồ cho thấy cả ba tác nhân đều hoạt động tốt nhất với Python, với tỷ lệ vượt qua (pass rates) thấp hơn đáng kể ở các ngôn ngữ khác. Điều này nhấn mạnh sự thiên vị (bias) hiện tại đối với Python trong nhiều tác nhân mã hóa và các mô hình ngôn ngữ lớn (large language models) nền tảng của chúng.
- Độ phức tạp của tác vụ: Phía bên phải của biểu đồ minh họa hiệu suất suy giảm như thế nào khi độ phức tạp của tác vụ tăng lên. Các tác nhân cho thấy tỷ lệ vượt qua cao hơn đối với các tác vụ liên quan đến thay đổi một lớp (single class) hoặc một hàm (single function), nhưng gặp khó khăn với các tác vụ đòi hỏi sửa đổi nhiều lớp hoặc nhiều hàm và trong các trường hợp cần cả thay đổi lớp và hàm.
Cái nhìn toàn diện về hiệu suất của tác nhân này nhấn mạnh giá trị của SWE-PolyBench trong việc xác định các điểm mạnh và điểm yếu cụ thể của các trợ lý mã hóa khác nhau, mở đường cho các cải tiến có mục tiêu trong các phiên bản tương lai.
Ngoài những hiểu biết này, việc đánh giá còn cho thấy các mô hình (patterns) thú vị trên các loại tác vụ khác nhau như trong Bảng 2. Dữ liệu hiệu suất trên các tác vụ sửa lỗi (bug fixes), yêu cầu tính năng (feature requests), và tái cấu trúc (refactoring) cho thấy các điểm mạnh khác nhau giữa các trợ lý mã hóa AI. Hiệu suất trên các tác vụ sửa lỗi là tương đối nhất quán. Có nhiều sự biến thiên (variability) hơn giữa các tác nhân khác nhau và giữa nhiều lần chạy (runs) của một tác nhân nhất định đối với các tác vụ yêu cầu tính năng và tác vụ tái cấu trúc.
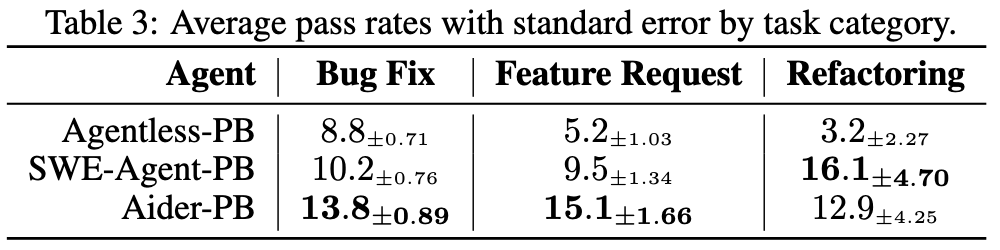
Bảng 3 hiển thị tỷ lệ vượt qua (pass rates) trung bình với sai số chuẩn (standard error) theo loại tác vụ cho ba tác nhân: Agentless-PB, SWE-Agent-PB, và Aider-PB. Các loại tác vụ là Sửa lỗi (Bug Fix), Yêu cầu Tính năng (Feature Request), và Tái cấu trúc (Refactoring). Aider-PB có tỷ lệ vượt qua cao nhất cho Sửa lỗi (13.8) và Yêu cầu Tính năng (15.1), trong khi SWE-Agent-PB dẫn đầu trong Tái cấu trúc (16.1). Sai số chuẩn được cung cấp cho mỗi giá trị.
Tham gia cộng đồng SWE-PolyBench
SWE-PolyBench và bộ khung (framework) đánh giá của nó được cung cấp công khai. Cách tiếp cận mở này mời gọi cộng đồng nhà phát triển toàn cầu xây dựng dựa trên công trình này và thúc đẩy lĩnh vực kỹ thuật phần mềm có sự hỗ trợ của AI (AI-assisted software engineering). Khi các tác nhân mã hóa tiếp tục phát triển, các benchmark (chuẩn đánh giá) như SWE-PolyBench đóng một vai trò quan trọng trong việc đảm bảo chúng có thể đáp ứng các nhu cầu đa dạng của phát triển phần mềm trong thực tế trên nhiều ngôn ngữ lập trình và loại tác vụ.
Hãy khám phá SWE-PolyBench ngay hôm nay và đóng góp cho tương lai của kỹ thuật phần mềm được hỗ trợ bởi AI (AI-powered software engineering)!
Tài nguyên
- Bộ dữ liệu (Dataset)
- Bộ công cụ đánh giá (Evaluation harness)
- Bài báo nghiên cứu (Research paper)
- Bảng xếp hạng (Leaderboard)
Tác giả

Christian Bock là một Nhà khoa học Ứng dụng (Applied Scientist) tại Amazon Web Services làm việc về AI cho mã (AI for code).

Laurent Callot là một Nhà khoa học Ứng dụng Chính (Principal Applied Scientist) tại Amazon Web Services, lãnh đạo các nhóm tạo ra các tác nhân AI (AI agents) cho phát triển phần mềm.

Luca Franceschi là một Nhà khoa học Ứng dụng (Applied Scientist) tại Amazon Web Services làm việc về các mô hình ML để cải thiện hiệu quả của các tác nhân AI (AI agents) cho việc tạo mã (code generation).

Woo Jung Kim là một nhà khoa học ứng dụng (applied scientist) tại Amazon Web Services. Ông đang phát triển một công cụ tác nhân AI (AI agentic tool) được thiết kế để cải thiện năng suất của nhà phát triển.

Shihab Rashid là một Nhà khoa học Ứng dụng (Applied Scientist) tại Amazon Web Services làm việc về AI có tính tác nhân (agentic AI) để tạo mã (code generation) với trọng tâm là các hệ thống đa tác nhân (multi agent systems).

Prabhu Teja là một Nhà khoa học Ứng dụng (Applied Scientist) tại Amazon Web Services. Prabhu làm việc về tạo mã có sự hỗ trợ của LLM (LLM assisted code generation) với trọng tâm là tương tác ngôn ngữ tự nhiên (natural language interaction).

Simon Valentin là một Nhà khoa học Ứng dụng (Applied Scientist) tại Amazon Web Services làm việc về AI cho mã (AI for code).

Martin Wistuba là một nhà khoa học ứng dụng cấp cao (senior applied scientist) tại Amazon Web Services. Là một phần của Amazon Q Developer, ông đang giúp các nhà phát triển viết nhiều mã hơn trong thời gian ngắn hơn.

Giovanni Zappella là một Nhà khoa học Ứng dụng Chính (Principal Applied Scientist) làm việc về việc tạo ra các tác nhân thông minh (intelligent agents) để tạo mã (code generation). Khi ở Amazon, ông cũng đã góp phần tạo ra các thuật toán mới cho Học Liên tục (Continual Learning), AutoML và các hệ thống khuyến nghị (recommendations systems).

Yuan Zhuang là một Nhà khoa học Ứng dụng (Applied Scientist) tại Amazon Web Services làm việc về các tác nhân AI (AI agents) để tạo mã (code generation).
