Tác giả: Chris Riggin và Cees Molenaar | ngày 31 tháng 3 năm 2025 | Chuyên mục: Advanced (300), Amazon Aurora, Best Practices | Permalink | Comments | Share
Amazon Aurora, dịch vụ cơ sở dữ liệu quan hệ (relational database service) từ Amazon Web Services (AWS), mang đến hiệu năng và khả năng sẵn sàng vượt trội ở quy mô toàn cầu, trở thành lựa chọn hàng đầu cho các tổ chức đang tìm kiếm một giải pháp cơ sở dữ liệu cạnh tranh. Là một cơ sở dữ liệu được xây dựng dành riêng cho đám mây, Aurora được thiết kế để tận dụng tối đa khả năng của hạ tầng cloud, cung cấp độ bền, hiệu năng và khả năng mở rộng ở cấp độ doanh nghiệp cho hai trong số các engine cơ sở dữ liệu mã nguồn mở đáng tin cậy nhất: MySQL và PostgreSQL. Một yếu tố quan trọng góp phần tạo nên thành công của Aurora là kiến trúc sáng tạo của nó — bao gồm cụm lưu trữ (storage cluster) được tách rời và phân phối trên nhiều Availability Zone, mang đến một giải pháp độc đáo, có tính chịu lỗi cao, đồng thời giảm thiểu tổng chi phí vận hành. Mặc dù khách hàng thường kỳ vọng sẽ tiết kiệm chi phí khi chuyển từ các cơ sở dữ liệu thương mại sang Aurora, nhiều người lại ngạc nhiên một cách thú vị khi nhận ra những lợi ích tài chính tương tự khi chuyển từ MySQL và PostgreSQL tự quản lý sang Aurora.
Trong bài viết này, chúng tôi làm nổi bật những thiết kế kiến trúc thường bị bỏ qua và các tính năng sẵn có trong Aurora giúp tối ưu chi phí khi triển khai cơ sở dữ liệu mã nguồn mở. Các phần tiếp theo sẽ phân tích nhiều trường hợp sử dụng (use case) khác nhau, so sánh giữa các cấu hình cơ sở dữ liệu tự quản lý điển hình và chi phí liên quan với giải pháp tương đương trên Aurora, qua đó chỉ ra tiềm năng tiết kiệm chi phí và nâng cao hiệu quả vận hành. Chúng tôi cũng cung cấp các so sánh chi phí chi tiết dựa trên tiêu chí cụ thể được xác định trong từng trường hợp sử dụng, sử dụng mức giá on-demand tại khu vực US East (Ohio), có hiệu lực tại thời điểm bài viết này được công bố. Chúng tôi khuyến khích độc giả tham khảo AWS Pricing Calculator hoặc liên hệ đội ngũ phụ trách tài khoản của mình để nhận được mức giá cập nhật và phân tích chi phí phù hợp hơn với từng nhu cầu cụ thể.
Trường hợp sử dụng: Kiến trúc cơ sở dữ liệu có khả năng chịu lỗi cơ bản với khả năng mở rộng đọc (scaled reads)
Một trong những trường hợp sử dụng phổ biến nhất dựa trên kiến trúc có khả năng chịu lỗi (resilient architecture) cơ bản với khả năng mở rộng đọc. Kiến trúc tự quản lý (self-managed architecture) dưới đây bao gồm một primary instance phục vụ lưu lượng đọc/ghi (read/write traffic), một secondary logical replica đảm nhận hai vai trò — cung cấp khả năng sẵn sàng cao (high availability) với Recovery Point Objective (RPO) thấp, đồng thời đóng vai trò là nguồn sao chép (replication source) cho các downstream read replicas, cùng với hai read-only instances nơi lưu lượng đọc có thể được phân phối và mở rộng theo chiều ngang (scaled horizontally). Cấu trúc này tối ưu hóa khả năng mở rộng đọc bằng cách phân phối khối lượng công việc đọc (read workloads) qua nhiều bản sao (replicas), đồng thời tránh gây tải sao chép lên primary, vì secondary replica chịu trách nhiệm xử lý luồng sao chép (replication stream) đến các downstream read replicas. Trong trường hợp xảy ra failover, secondary replica có thể được promote lên làm primary, giúp duy trì hoạt động kinh doanh liên tục, trong khi các read replica vẫn tiếp tục phục vụ truy vấn đọc, giờ đây sao chép dữ liệu từ primary mới được promote. Kiến trúc này sử dụng secondary instance như một failover target, vì theo thông lệ trong ngành, các bản sao đọc (read replicas) thường không được sử dụng cho failover trong MySQL và PostgreSQL do có nguy cơ replication lag và mất dữ liệu trong quá trình promote. Hạn chế này đòi hỏi phải có thêm một secondary instance, dẫn đến việc tăng tổng chi phí của toàn bộ giải pháp.
Kiến trúc tự quản lý:
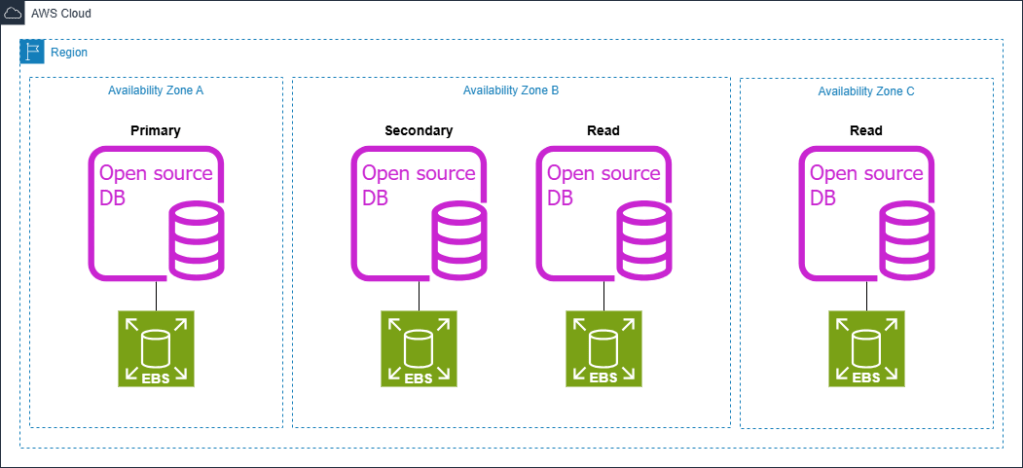
Kiến trúc Amazon Aurora dưới đây minh họa cách cùng một khối lượng công việc (workload) có thể được duy trì với hiệu năng tương đương hoặc tốt hơn, đồng thời đơn giản hóa kiến trúc và giảm lượng tài nguyên sử dụng, từ đó hạ thấp tổng chi phí. Kiến trúc của Aurora được tích hợp các tính năng chuyên biệt nhằm nâng cao khả năng sẵn sàng (availability) và hỗ trợ disaster recovery. Không giống như các cơ sở dữ liệu mã nguồn mở tự quản lý truyền thống, nơi việc đạt được zero RPO thường dẫn đến chi phí và tải hiệu năng cao hơn, Aurora mặc định cung cấp khả năng failover với RPO bằng 0. Điều này đạt được nhờ thiết kế sáng tạo của Aurora, cho phép các read replicas đóng vai trò như các failover targets có tính sẵn sàng cao mà không cần cấu hình bổ sung hay ảnh hưởng đến hiệu năng.
Kiến trúc Aurora:

Trong trường hợp sử dụng này, lợi thế kiến trúc của Aurora loại bỏ nhu cầu phải duy trì một secondary instance riêng biệt chỉ để phục vụ mục đích failover replication. Kết quả là, khi chuyển từ kiến trúc tự quản lý sang Aurora, quy mô cụm (cluster footprint) được giảm từ bốn nodes xuống còn ba. Mặc dù việc giảm bớt tài nguyên tính toán (compute resources) này mang lại một phần tiết kiệm chi phí, nhưng đây không phải là nguồn lợi ích kinh tế chính trong kịch bản này. Phần lớn hiệu quả chi phí đạt được nhờ vào kiến trúc lưu trữ (storage architecture) mang tính cách mạng của Aurora.
Trái ngược với các thiết lập cơ sở dữ liệu truyền thống, nơi mỗi node thường có vùng lưu trữ độc lập chứa một bản sao riêng của dữ liệu được sao chép từ source instance, Aurora áp dụng một cách tiếp cận hoàn toàn khác biệt. Trong kiến trúc tự quản lý, việc sao chép dữ liệu không chỉ làm giảm hiệu năng do replication overhead, mà còn khiến chi phí lưu trữ tăng gấp bốn lần trong trường hợp này. Ngược lại, tất cả các Aurora instances — bao gồm cả primary và read replicas — đều kết nối đến cùng một shared storage volume. Cụm lưu trữ của Aurora (Aurora storage cluster) tự động đảm bảo khả năng chịu lỗi (resilience) bằng cách phân phối sáu bản sao dữ liệu (six copies of data) trên ba Availability Zones. Khách hàng chỉ bị tính phí cho một bản sao dữ liệu duy nhất, giúp giảm chi phí lưu trữ trong kiến trúc này từ bốn xuống còn một một cách hiệu quả.
Giả sử các loại instance được sử dụng tương đương nhau giữa hai kiến trúc, self-managed và Aurora (ví dụ: r6g.xlarge, db.r6g.xlarge), với 2 TB ổ lưu trữ io2 provisioned IOPS SSD ở mức 64,000 IOPS trong kiến trúc tự quản lý, và Aurora I/O-Optimized (một tùy chọn lưu trữ được thiết kế nhằm cải thiện hiệu năng/chi phí và tính ổn định cho các ứng dụng có cường độ I/O cao) trong kiến trúc Aurora, sự khác biệt về chi phí trở nên rõ ràng. Hãy cùng so sánh chi phí hàng tháng giữa kiến trúc tự quản lý và giải pháp Aurora:
| Kiến trúc | Số lượng DB Nodes (bao gồm writer) | Loại Instance | Dung lượng lưu trữ mỗi Volume | Số lượng Storage Volumes | Tổng chi phí |
| Self-Managed | 4 | r6g.xlarge | 2 Tb | 4 | $15,756.67 |
| Amazon Aurora | 3 | db.r6g.xlarge | 2 Tb | 1 | $1,939.05 |
Như có thể thấy, kiến trúc tự quản lý, với yêu cầu bốn compute nodes và vùng lưu trữ riêng biệt cho từng node, có tổng chi phí 15.756,67 USD mỗi tháng. Ngược lại, giải pháp Aurora với ba compute nodes và lưu trữ hợp nhất (unified storage) chỉ tốn 1.939,05 USD mỗi tháng, tương đương giảm 87,7% chi phí. Khoản tiết kiệm đáng kể này chủ yếu đến từ kiến trúc lưu trữ hiệu quả của Aurora, giúp loại bỏ nhu cầu lưu trữ nhiều bản sao dữ liệu dư thừa, đồng thời vẫn duy trì hiệu năng cao và độ sẵn sàng (high availability) vượt trội.
Mặc dù không phải là trọng tâm của bài viết này, nhưng cũng đáng đề cập đến Amazon Relational Database Service (Amazon RDS), một dịch vụ cơ sở dữ liệu được quản lý (managed database service) giúp đơn giản hóa các tác vụ quản trị cơ sở dữ liệu. RDS Multi-AZ với hai readable standby loại bỏ nhu cầu duy trì một secondary/standby instance riêng biệt. Mặc dù tùy chọn triển khai này vẫn yêu cầu các ổ lưu trữ độc lập, mỗi ổ chứa một bản sao dữ liệu riêng, nhưng nó cung cấp một giải pháp high-availability mạnh mẽ. Tuy nhiên, kiến trúc lưu trữ độc đáo của Aurora mang lại lợi ích tối ưu chi phí bổ sung nhờ mô hình shared storage, và đó chính là lý do tại sao bài viết này tập trung vào khả năng của Aurora.
Trường hợp sử dụng: Tải đọc biến động (Variable read loads)
Bây giờ, hãy cùng xem xét một kịch bản trong đó các ứng dụng có sự dao động về lưu lượng đọc (read traffic), với các tải đỉnh (peak loads) có thể yêu cầu dung lượng lớn hơn đáng kể so với những gì kiến trúc chịu lỗi cơ bản có thể cung cấp hiệu quả. Thiết kế kiến trúc tự quản lý dưới đây xử lý lưu lượng đọc biến động thông qua bốn read-only instances. Cấu hình này được thiết kế dựa trên nhu cầu trong giai đoạn tải đỉnh, một thông lệ phổ biến trong các kiến trúc truyền thống. Hệ thống sử dụng tài nguyên được cấp sẵn (pre-provisioned resources) để đáp ứng các đợt tăng đột biến trong lưu lượng đọc, nhưng lại không được tận dụng hết trong giai đoạn hoạt động bình thường. Cách tiếp cận tĩnh này giúp hệ thống luôn sẵn sàng cho các tình huống lưu lượng cao, nhưng đồng thời dẫn đến dung lượng nhàn rỗi (idle capacity) và chi phí tăng trong các giai đoạn không phải cao điểm, từ đó tạo ra cơ hội tối ưu hóa chiến lược quản lý cơ sở dữ liệu.
Kiến trúc tự quản lý:
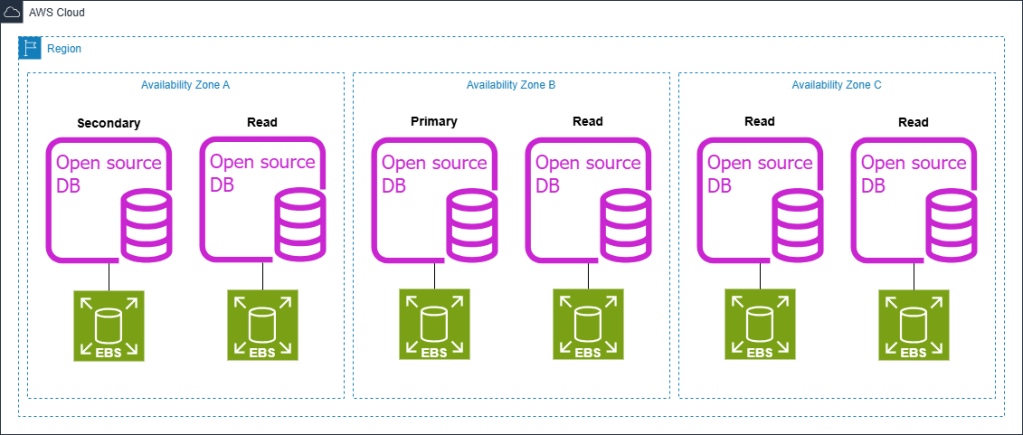
Hình minh họa dưới đây thể hiện kiến trúc Aurora cho trường hợp sử dụng này. Tương tự như ví dụ đầu tiên, chúng ta có thể chứng minh khả năng tiết kiệm chi phí thông qua những thay đổi chiến lược trong thiết kế kiến trúc, những yếu tố vốn có trong Aurora. Nhờ kiến trúc lưu trữ dùng chung (shared storage architecture) và khả năng để bất kỳ replica nào cũng có thể được promote lên writer mà không gây mất dữ liệu (zero RPO), chúng ta có thể loại bỏ secondary instance riêng biệt vốn thường được sử dụng cho high availability trong các hệ thống truyền thống. Sau khi xảy ra failover giữa các Availability Zone, Aurora sẽ tự động tạo một read replica mới để thay thế cho primary instance trước đó, từ đó duy trì dung lượng mong muốn (desired capacity) cho toàn bộ cluster.
Giống như hầu hết các trường hợp sử dụng khác, kiến trúc read replica của Aurora cho phép mở rộng tải đọc (read scaling) hiệu quả hơn nhờ mô hình lưu trữ dùng chung (shared storage model), giúp loại bỏ nhu cầu sao chép dữ liệu giữa các instances. Trong trường hợp này, hiệu quả đó được nâng cao nhờ tính năng Amazon Aurora Auto Scaling với Aurora Replicas, một giải pháp động thay thế cho việc duy trì các read-only instances cố định. Khi auto-scaling được cấu hình, hệ thống sẽ tự động khởi tạo hoặc gỡ bỏ instances tùy theo nhu cầu khối lượng công việc (workload demand), và có thể giảm xuống chỉ còn một read replica trong giai đoạn hoạt động thấp. Cách tiếp cận linh hoạt này giúp tối ưu hóa việc sử dụng tài nguyên (resource utilization), giảm chi phí do dung lượng nhàn rỗi (idle capacity), và đảm bảo bạn chỉ trả tiền cho những tài nguyên thực sự cần thiết.
Kiến trúc Aurora:
Hãy áp dụng các giả định tương tự như trong trường hợp sử dụng đầu tiên: sử dụng loại và kích thước instance tương đương (r6g.xlarge, db.r6g.xlarge), trong đó kiến trúc tự quản lý dùng 2 TB ổ SSD io2 được cung cấp 64.000 IOPS, còn đối với kiến trúc Aurora, chúng ta sử dụng Aurora I/O-Optimized. Chúng tôi chọn Aurora I/O-Optimized cho kịch bản này vì khả năng xử lý khối lượng công việc giao dịch hiệu năng cao (high-performance transactional workloads) với độ trễ I/O thấp và ổn định (consistent low-latency I/O) — điều này phù hợp với các yêu cầu được ngụ ý khi sử dụng ổ lưu trữ io2 trong cấu hình tự quản lý.
Hãy cùng so sánh chi phí hàng tháng giữa cụm tự quản lý (self-managed cluster) với các instances cố định và kiến trúc Aurora với auto-scaling được bật:
| Kiến trúc | Số lượng DB Nodes (bao gồm writer) | Loại Instance | Dung lượng lưu trữ mỗi Volume | Số lượng Storage Volumes | Tổng chi phí |
| Self-Managed | 6 | r6g.xlarge | 2 Tb | 6 | $23,635.01 |
| Amazon Aurora | 3 | db.r6g.xlarge(với Auto-Scaled Reads) | 2 Tb | 1 | $2,431.80 |
Như minh họa ở trên, cụm truyền thống với 6 instance r6g.xlarge cùng chi phí lưu trữ đi kèm có tổng chi phí 23.635,01 USD mỗi tháng. Ngược lại, kiến trúc Aurora, dù vẫn duy trì một writer và trung bình ba trong số bốn read replicas được kích hoạt trong suốt tháng, chỉ tốn 2.431,80 USD mỗi tháng — tương đương giảm 89,7% chi phí. Điều này thể hiện rõ lợi ích tài chính từ khả năng auto-scaling của Aurora. Khoản tiết kiệm này còn tăng lên khi giảm số lượng trung bình read replica đang hoạt động hàng tháng. Ví dụ, nếu giảm xuống trung bình hai read replicas, chi phí tiếp tục giảm mạnh, với mức tiết kiệm vượt quá 90%. Trong những giai đoạn hoạt động thấp, việc chỉ duy trì một read replica trung bình giúp chi phí giảm thêm nữa, chứng minh tính linh hoạt và hiệu quả về chi phí trong kiến trúc của Aurora.
Là một kiến trúc thay thế cho trường hợp sử dụng này, Amazon Aurora Serverless v2 mang đến một giải pháp linh hoạt để xử lý mô hình lưu lượng không dự đoán trước, tự động điều chỉnh cả dung lượng đọc và ghi (read/write capacity) trong thời gian thực nhằm đáp ứng nhu cầu biến động.
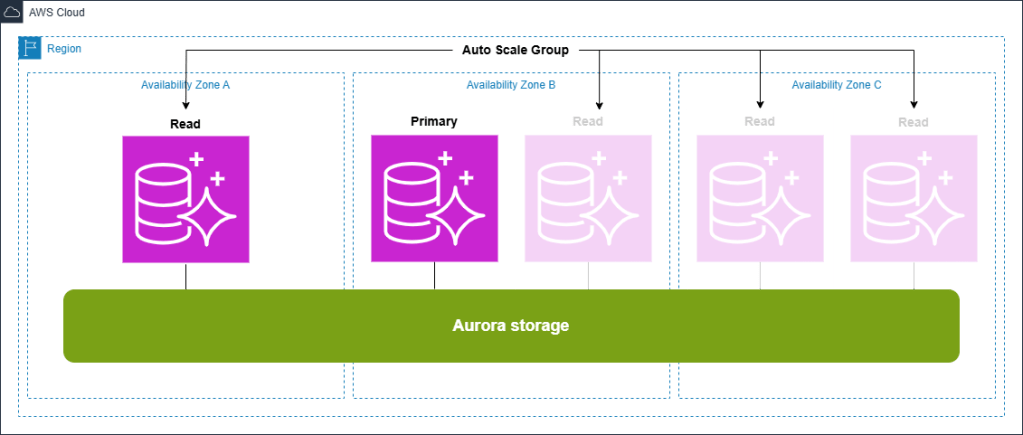
Kiến trúc Aurora thay thế:
Aurora Serverless v2 mang đến một giải pháp tối ưu để quản lý khối lượng công việc biến động (variable workloads), đảm bảo hiệu quả sử dụng tài nguyên mà vẫn duy trì hiệu năng ổn định. Kiến trúc sáng tạo này được minh họa trong hình trước, tự động phân bổ đúng lượng tài nguyên cần thiết, duy trì tốc độ và hiệu năng nhất quán bất kể biến động về nhu cầu. Trái ngược với kiến trúc tự quản lý sử dụng sáu instance được cấp sẵn (pre-provisioned), cấu hình Aurora được tối ưu hóa này có thể giảm trung bình mức phân bổ tài nguyên hàng tháng cho cả read replicas và primary instance. Cấu trúc tinh gọn này không chỉ đơn giản hóa công tác quản lý, mà còn tăng cường hiệu quả chi phí (cost-effectiveness). Trong những giai đoạn lưu lượng thấp hoặc không có tải, Aurora Serverless v2 cho phép thu nhỏ dung lượng (scaling capacity) xuống đến mức 0, giúp giảm đáng kể chi phí vận hành. Bên cạnh đó, Aurora còn cung cấp tính linh hoạt cao khi cho phép kết hợp giữa các instance dạng serverless và provisioned trong cùng một cluster, giúp tùy chỉnh chính xác tài nguyên để đáp ứng những yêu cầu khối lượng công việc đa dạng. Cách tiếp cận linh hoạt này cho phép bạn đạt được sự cân bằng giữa hiệu năng và chi phí, tối đa hóa khoản tiết kiệm ngân sách, đồng thời đảm bảo ứng dụng luôn phản hồi nhanh và hoạt động hiệu quả trong mọi thời điểm.
Trường hợp sử dụng: Tối ưu hóa đọc (Optimized reads)
Trong trường hợp sử dụng này, chúng ta tập trung vào các khối lượng công việc có tải đọc cao và ổn định (consistent read-heavy workloads), nơi mà việc auto-scaling có thể không mang lại hiệu quả chi phí tối ưu do tính chất tĩnh (static nature) của khối lượng công việc. Trong kiến trúc tự quản lý (self-managed architecture) cho trường hợp này (như minh họa trong hình bên dưới), ứng dụng yêu cầu các instance đọc có dung lượng lớn (ví dụ: r6g.8xlarge) để đáp ứng các yêu cầu hiệu năng cụ thể. Mỗi instance trong số này cung cấp 256 GB bộ nhớ, mang lại khả năng đáp ứng nhu cầu của trường hợp sử dụng này, bao gồm bộ nhớ đệm dữ liệu độ trễ thấp (low-latency data caching) và các phép nối bảng lớn trong bộ nhớ (large in-memory table joins). Dung lượng bộ nhớ 256 GB cho phép lưu trữ dữ liệu thường xuyên được truy cập trong RAM, giúp giảm thiểu hoạt động I/O và cải thiện thời gian phản hồi truy vấn (query response times). Ngoài ra, dung lượng này còn hỗ trợ thực thi các truy vấn phức tạp liên quan đến các phép nối bảng lớn (large joins) mà không cần sử dụng đến ổ đĩa (disk-based operations), vốn làm giảm hiệu năng. Cấu hình này đảm bảo rằng cơ sở dữ liệu có thể xử lý các hoạt động đọc chuyên sâu (intensive read operations), duy trì khả năng phản hồi tốt ngay cả trong các khối lượng công việc phân tích (analytical workloads) nặng.
Kiến trúc tự quản lý:
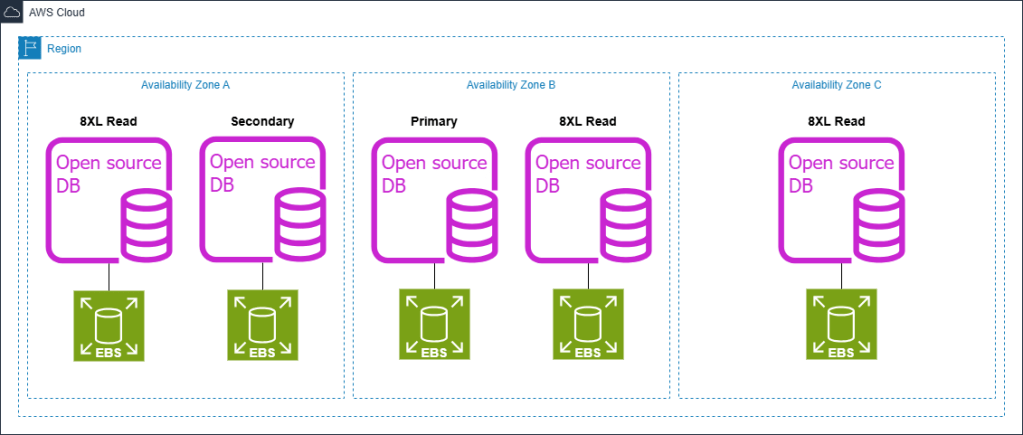
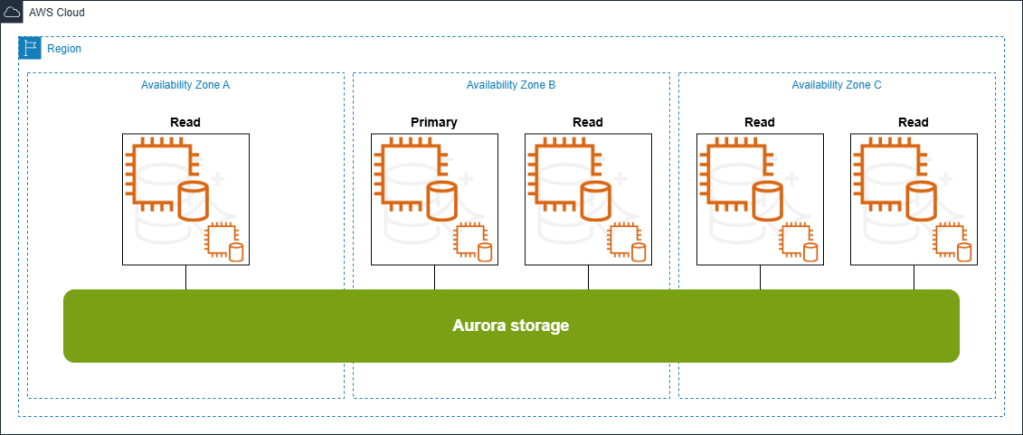
AWS đã giới thiệu Amazon Aurora Optimized Reads nhằm giải quyết những thách thức về hiệu năng trong các hoạt động cơ sở dữ liệu đọc chuyên sâu trong bộ nhớ (in-memory, read-heavy database operations). Tính năng này được sử dụng trong kiến trúc minh họa ở hình dưới và mang đến những cải tiến đáng kể cho Aurora, giúp giảm độ trễ truy vấn (query latency) lên đến tám lần và mang lại tiềm năng tiết kiệm chi phí cho các ứng dụng xử lý tập dữ liệu lớn vượt quá dung lượng bộ nhớ của instance cơ sở dữ liệu. Ngoài ra, Aurora hỗ trợ Optimized Reads trên các loại instance được trang bị lưu trữ NVMe gắn cục bộ (locally attached NVMe storage), cho phép bạn kích hoạt tính năng này để tăng hiệu năng đọc (enhanced read performance). Để tìm hiểu thêm, hãy xem Overview of Aurora Optimized Reads in PostgreSQL để có cái nhìn tổng quan, và Use cases for Aurora Optimized Reads để xem các ví dụ ứng dụng cụ thể.
Kiến trúc Aurora:

Trong ví dụ trường hợp sử dụng này, chúng tôi minh họa cách Aurora Optimized Reads cùng với lưu trữ NVMe cục bộ (local NVMe storage) có thể hỗ trợ giảm kích thước của các read-only instances. Mặc dù Aurora vẫn hỗ trợ kích thước instance tương đương với kiến trúc tự quản lý (db.r6g.8xlarge, db.r6gd.8xlarge), ví dụ này tập trung vào cách tiếp cận tối ưu chi phí (cost-optimization approach) bằng cách sử dụng các instance nhỏ hơn. Cụ thể, chúng tôi thay đổi từ r6g.8xlarge (32 vCPU, 256 GB memory) sang db.r6gd.2xlarge (8 vCPU, 64 GB memory). Việc thay đổi loại instance này khả thi nhờ Aurora Optimized Reads, cung cấp 64 GB bộ nhớ chính (primary memory) cùng với 474 GB bộ nhớ đệm phân tầng dựa trên NVMe (NVMe-based tiered cache) — mang lại tổng cộng 538 GB, hơn gấp đôi so với 256 GB có trong instance 8xlarge ban đầu. Cách tiếp cận này đặc biệt hiệu quả đối với các cơ sở dữ liệu mã nguồn mở có tải đọc cao (read-intensive open source databases) khi bộ dữ liệu làm việc (working dataset) có các đặc điểm sau:
- Dữ liệu “nóng” (hot data) – tức là dữ liệu được truy cập thường xuyên – chiếm khoảng 20–30% dung lượng bộ nhớ gốc (khoảng 50–75 GB trong trường hợp này).
- Toàn bộ bộ dữ liệu làm việc (entire working set) lớn gấp 2–3 lần dung lượng bộ nhớ ban đầu (500–750 GB).
- Mẫu truy cập đọc (read patterns) thể hiện tính cục bộ theo thời gian (temporal locality), với 80–90% các truy cập đọc tập trung vào dữ liệu nóng (hot data).
Trong những kịch bản như vậy, 64 GB bộ nhớ chính có thể cache hiệu quả những dữ liệu quan trọng nhất, trong khi 474 GB NVMe hoạt động như một phần mở rộng hiệu năng cao của hệ thống bộ nhớ, bù đắp hiệu quả cho việc giảm dung lượng bộ nhớ chính. Tuy nhiên, cần lưu ý rằng cấu hình này làm giảm số CPU sẵn có từ 32 vCPU xuống còn 8 vCPU trên mỗi instance. Mặc dù kiến trúc bộ nhớ và lưu trữ có thể đáp ứng yêu cầu của workload, cần tiến hành các bài kiểm tra hiệu năng (performance testing) cẩn thận để đảm bảo rằng khả năng CPU giảm vẫn thỏa mãn nhu cầu cụ thể của workload.
Hãy xem xét chi phí hàng tháng khi so sánh kiến trúc truyền thống với Aurora có bật Optimized Reads, giữ các giả định cấu hình giống như các ví dụ trước:
| Kiến trúc | Số lượng DB Nodes (bao gồm writer) | Loại Instance | Dung lượng lưu trữ mỗi Volume | Số lượng Storage Volumes | Tổng chi phí |
| Self-Managed | 5 | r6g.xlarge | 2 Tb | 5 | $24,846.72 |
| Amazon Aurora | 4 | db.r6g.xlarge(với Optimized Reads) | 2 Tb | 1 | $5,197.04 |
Như minh họa ở trên, kiến trúc truyền thống sử dụng các instance r6g.8xlarge có chi phí 24.846,72 USD mỗi tháng, trong khi kiến trúc Aurora với các instance db.r6gd.2xlarge và Optimized Reads chỉ tốn 5.197,04 USD mỗi tháng — tương đương giảm 79,1% chi phí. Khoản tiết kiệm này đạt được trong khi vẫn duy trì hoặc cải thiện hiệu năng và độ trễ (latency) nhờ vào cấu trúc phân tầng bộ nhớ hiệu quả (efficient memory tiering) và khả năng đọc được tối ưu hóa (optimized read capabilities) của Aurora, đặc biệt phù hợp với các khối lượng công việc (workloads) có mẫu truy cập dữ liệu (access patterns) như đã mô tả ở phần trên.
Các tính năng bổ sung giúp tối ưu chi phí của Amazon Aurora
Khi kết thúc phần thảo luận về khả năng tối ưu chi phí của Aurora, việc xem xét một số tính năng bổ sung đáng chú ý là điều cần thiết. Trong phần này, chúng tôi sẽ giới thiệu từng tính năng cụ thể, đồng thời làm nổi bật những lợi ích và ưu điểm trong vận hành mà chúng mang lại. Những tính năng này không chỉ thể hiện cách tiếp cận toàn diện của Aurora trong quản lý cơ sở dữ liệu (comprehensive approach to database management) mà còn góp phần mang lại hiệu quả tiết kiệm chi phí đáng kể khi so sánh với các giải pháp tự quản lý (self-managed solutions).
Aurora Global Database
Aurora Global Database mở rộng khả năng của Aurora trên nhiều vùng AWS (AWS Regions), cho phép ứng dụng đọc dữ liệu với độ trễ thấp cục bộ (local latency) và cung cấp khả năng khôi phục thảm họa (disaster recovery) trong trường hợp xảy ra sự cố diện rộng ở cấp vùng (region-wide outages). Trong các triển khai MySQL và PostgreSQL truyền thống, việc thiết lập multi-region đòi hỏi phải xây dựng giải pháp sao chép tùy chỉnh (custom-built replication solutions), duy trì nhiều bản sao dữ liệu độc lập tại mỗi vùng, và quản lý hạ tầng phức tạp liên tục. Aurora Global Database loại bỏ toàn bộ những yêu cầu này bằng khả năng sao chép liên vùng (cross-region replication) được tích hợp sẵn, với độ trễ dưới 1 giây, đồng thời chỉ tính phí cho dung lượng dữ liệu thực tế một lần tại mỗi vùng.
Aurora tự động hóa quy trình sao chép liên vùng (cross-Region replication) và hỗ trợ tự động chuyển đổi vùng (regional failover) khi được người dùng kích hoạt. Sự tự động hóa này, kết hợp với khả năng mở rộng công suất đọc độc lập (independent scaling of read capacity) tại từng vùng, giúp giảm cả chi phí vận hành (operational overhead) lẫn chi phí hạ tầng (infrastructure costs) so với các giải pháp tự quản lý. Trong các cấu hình truyền thống, hệ thống thường phải duy trì hạ tầng đồng nhất ở nhiều vùng cùng nhiều bản sao dữ liệu để đảm bảo high availability, dẫn đến cấp phát dư thừa (over-provisioning) và tăng chi phí. Kiến trúc của Aurora Global Database loại bỏ những chi phí bổ sung này, đồng thời vẫn duy trì khả năng sẵn sàng cao (high availability) và khả năng khôi phục thảm họa mạnh mẽ (robust disaster recovery capabilities).
Aurora cloning và Blue/Green deployments
Database cloning và Blue/Green deployments là những thực tiễn phổ biến trong ngành được sử dụng để tạo bản sao cơ sở dữ liệu và triển khai các bản cập nhật với rủi ro tối thiểu. Aurora triển khai hai khái niệm này với những ưu điểm vượt trội so với môi trường MySQL và PostgreSQL tự quản lý.
Aurora cloning tạo các database instance mới bằng giao thức copy-on-write ở tầng lưu trữ (storage layer), trong đó các instance mới ban đầu trỏ đến cùng dữ liệu gốc (underlying data) với source instance. Cách tiếp cận này giúp giảm thiểu chi phí lưu trữ bổ sung, vì chỉ ghi nhận các thay đổi gia tăng (incremental changes), đồng thời loại bỏ tác động hiệu năng (performance impact) đối với cơ sở dữ liệu nguồn. Ngược lại, các giải pháp tự quản lý thường phải thực hiện sao chép toàn bộ dữ liệu (full data copy) tốn nhiều thời gian và phát sinh chi phí lưu trữ đáng kể.
Tính năng Aurora Blue/Green deployments cho phép cập nhật cơ sở dữ liệu và thay đổi schema với thời gian gián đoạn tối thiểu, thường chỉ vài giây trong giai đoạn cutover cuối cùng. Nếu phát hiện sự cố trong quá trình chuyển đổi (switchover) khiến quá trình chuyển sang môi trường Green không thể hoàn tất, Aurora cho phép quay lại (rollback) ngay lập tức môi trường Blue. Mặc dù phương pháp này tạo hạ tầng tính toán nhân đôi (duplicate compute infrastructure), nhưng nó sử dụng cùng giao thức copy-on-write như Aurora cloning, nghĩa là môi trường Green ban đầu trỏ đến cùng dữ liệu cơ sở với môi trường Blue và chỉ ghi nhận các thay đổi gia tăng. Trong khi đó, các quy trình cập nhật cơ sở dữ liệu truyền thống trong môi trường tự quản lý thường đòi hỏi thời gian downtime dài hoặc các thiết lập sao chép phức tạp, kéo theo chi phí bổ sung.
Kết hợp lại, Aurora cloning và Blue/Green deployments nâng cao hiệu quả quản lý, đẩy nhanh chu kỳ phát triển (development cycles), và tối ưu hóa việc sử dụng tài nguyên (resource utilization), giúp giảm rủi ro vận hành (operational risk) so với các triển khai tự quản lý, đồng thời mang lại một giải pháp quản lý hoàn chỉnh cho việc cập nhật cơ sở dữ liệu.
Aurora zero-ETL integration
Quy trình Extract, Transform, and Load (ETL) được sử dụng để tích hợp dữ liệu giữa các cơ sở dữ liệu vận hành (operational databases) và nền tảng phân tích (analytics platforms). Trong các triển khai MySQL và PostgreSQL truyền thống, việc này thường đòi hỏi hạ tầng Change Data Capture (CDC) được xây dựng thủ công, đội ngũ phát triển riêng để tạo và duy trì pipeline, tài nguyên tính toán bổ sung cho quá trình trích xuất dữ liệu, cùng với việc giám sát liên tục luồng dữ liệu và can thiệp thủ công khi có thay đổi schema.
Aurora zero-ETL integration tự động hóa quá trình di chuyển dữ liệu (data movement) giữa Aurora và các dịch vụ phân tích của AWS được hỗ trợ (chẳng hạn như Amazon Redshift), cung cấp CDC tích hợp sẵn, đồng bộ hóa schema tự động, cập nhật dữ liệu gần thời gian thực (near real-time updates), và khả năng tích hợp gốc (native integration) với các dịch vụ phân tích của AWS. Cách tiếp cận này giúp giảm chi phí hạ tầng CDC, loại bỏ chi phí phát triển pipeline, giảm nhu cầu tài nguyên tính toán cho việc di chuyển dữ liệu, đồng thời giảm tải vận hành trên Aurora. Ngoài ra, tích hợp này duy trì sự tách biệt rõ ràng giữa các khối công việc vận hành và phân tích, khi các truy vấn phân tích (analytical queries) được thực thi trên nền tảng đích (target platform) thay vì Aurora, giúp bảo toàn hiệu năng cơ sở dữ liệu trong khi vẫn đảm bảo khả năng truy cập dữ liệu phân tích kịp thời. Những tính năng này kết hợp lại để giảm chi phí hạ tầng và chi phí vận hành đáng kể so với việc duy trì các khả năng tương tự trong môi trường tự quản lý.
Kết luận
Trong bài viết này, chúng tôi đã làm rõ những lợi thế về chi phí khi triển khai và di chuyển sang Amazon Aurora. Phân tích của chúng tôi đã thách thức giả định phổ biến rằng các giải pháp mã nguồn mở tự quản lý (self-managed open source solutions) luôn mang lại giá trị kinh tế tối ưu. Thông qua các tình huống sử dụng cụ thể (use cases), chúng tôi đã chứng minh cách các tính năng độc đáo của Aurora giúp giảm chi phí trên nhiều kịch bản khác nhau. Thiết kế sáng tạo (innovative design) của Aurora kết hợp tính linh hoạt ở cấp độ thương mại (commercial-grade versatility) với mức giá cạnh tranh, mang lại giải pháp tối ưu cho các tổ chức đang tìm cách nâng cao hiệu quả vận hành cơ sở dữ liệu của mình. Khi nhu cầu về cơ sở dữ liệu tiếp tục phát triển, Aurora không chỉ mang đến hiệu năng vượt trội (high performance) mà còn đảm bảo hiệu quả chi phí (cost-efficiency).
Chúng tôi khuyến khích các doanh nghiệp đánh giá lại thiết kế và hoạt động cơ sở dữ liệu hiện tại, đồng thời khám phá cách Aurora có thể giúp cải thiện hiệu quả vận hành và tối ưu hóa lợi nhuận (bottom line). Để có đánh giá cá nhân hóa về tiềm năng tiết kiệm chi phí khi chuyển sang Aurora, hãy liên hệ với đội ngũ tài khoản AWS (AWS account teams) hoặc các Đối tác AWS (AWS Partners) của chúng tôi.
Để biết thêm thông tin về giá dịch vụ và các ví dụ ước tính chi phí, vui lòng xem Amazon Aurora Pricing.
Bạn có thể bắt đầu sử dụng Amazon Aurora ngay hôm nay bằng cách truy cập bảng điều khiển Amazon RDS console. Để tìm hiểu thêm, hãy xem Aurora User Guide.
Về tác giả

Chris Riggin là Senior Specialist Solutions Architect tại Amazon Web Services (AWS). Anh cam kết giúp khách hàng tối đa hóa khả năng tiết kiệm chi phí thông qua việc thiết kế các kiến trúc có hiệu năng cao, khả năng chịu lỗi tốt (resilient) và dễ mở rộng (scalable) bằng cách tận dụng các dịch vụ của AWS.

Cees Molenaar là Senior Specialist Sales Representative tại Amazon Web Services (AWS). Anh đam mê xây dựng các mối quan hệ hợp tác bền vững với khách hàng, bằng cách cung cấp tư vấn chuyên sâu và hỗ trợ đáng tin cậy trong việc sử dụng các dịch vụ AWS.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}