bởbởi Laura Verghote | ngày 12 tháng 5 2025 | trong Amazon SageMaker, Generative AI, Intermediate (200), Security, Identity, & Compliance, Technical How-to
Các Mô hình Ngôn ngữ Lớn (LLMs) đã trở thành công cụ thiết yếu cho việc tạo nội dung, phân tích tài liệu và xử lý ngôn ngữ tự nhiên. Do đầu ra phức tạp và không xác định của các mô hình này, bạn cần áp dụng các biện pháp bảo vệ an toàn mạnh mẽ để ngăn ngừa các kết quả không phù hợp và bảo vệ tương tác của người dùng. Những biện pháp này rất quan trọng để giải quyết các mối lo ngại như rủi ro tạo nội dung độc hại, hướng dẫn sai lệch, khả năng bị lạm dụng, bảo vệ thông tin nhạy cảm, và cân nhắc về thiên vị và công bằng. Các safety guardrails cung cấp các kiểm soát cần thiết, giúp duy trì thực hành AI có trách nhiệm đồng thời tận dụng tối đa khả năng của LLM.
Amazon SageMaker AI là một dịch vụ được quản lý hoàn toàn, cho phép các nhà phát triển và nhà khoa học dữ liệu xây dựng, huấn luyện và triển khai các mô hình học máy (ML) quy mô lớn, cung cấp bộ công cụ ML toàn diện cùng các mô hình đã xây dựng sẵn và giải pháp low-code cho các vấn đề kinh doanh phổ biến. Trong bài viết này, bạn sẽ học cách triển khai các safety guardrails cho các ứng dụng sử dụng foundation models được lưu trữ trong SageMaker AI.
Trong bài viết này, tôi thảo luận về các cấp độ khác nhau mà các guardrails có thể được triển khai. Sau đó, tôi đi sâu vào các mẫu triển khai cho hai trong ba lĩnh vực triển khai. Thứ nhất, thông qua việc xem xét các built-in model guardrails và tài liệu của chúng qua model cards. Thứ hai, minh họa cách sử dụng ApplyGuardrail API từ Amazon Bedrock Guardrails để tăng cường lọc nội dung, hướng dẫn cách sử dụng các thành phần endpoint để chạy các mô hình phụ như Llama Guard làm các điểm kiểm tra an toàn bổ sung, và thảo luận về các third-party guardrails. Bằng cách sử dụng một hoặc nhiều chiến lược này, bạn có thể tạo ra hệ thống bảo vệ cho ứng dụng AI. Tuy nhiên, dựa vào một chiến lược duy nhất có thể có hạn chế—built-in guardrails có thể bỏ sót các mối quan tâm cụ thể của ứng dụng, trong khi các giải pháp bên thứ ba có thể thiếu phạm vi bao phủ. Một phương pháp defense-in-depth kết hợp nhiều chiến lược giúp giải quyết phạm vi rộng hơn các rủi ro tiềm ẩn đồng thời tuân thủ tiêu chuẩn AI có trách nhiệm và yêu cầu kinh doanh.
Hiểu các chiến lược triển khai các rào chắn bảo vệ (guardrails)
Việc xây dựng các biện pháp bảo vệ hiệu quả cho ứng dụng AI đòi hỏi phải hiểu các cấp độ mà guardrails có thể được triển khai. Những cơ chế này hoạt động tại hai điểm can thiệp chính trong vòng đời hệ thống AI:
- Can thiệp trước khi triển khai (Pre-deployment interventions): Là nền tảng của an toàn AI. Trong giai đoạn huấn luyện và tinh chỉnh, các kỹ thuật như Constitutional AI nhúng các nguyên tắc an toàn trực tiếp vào hành vi mô hình. Các can thiệp giai đoạn đầu bao gồm dữ liệu huấn luyện an toàn chuyên biệt, kỹ thuật căn chỉnh, lựa chọn và đánh giá mô hình, đánh giá thiên vị và công bằng, và các quá trình tinh chỉnh giúp hình thành khả năng an toàn vốn có của mô hình. Built-in model guardrails là ví dụ cho can thiệp trước khi triển khai.
- Can thiệp trong thời gian chạy (Runtime interventions): Cung cấp giám sát và kiểm soát an toàn chủ động khi mô hình vận hành. Bao gồm các phương pháp prompt engineering để hướng dẫn hành vi mô hình, chiến lược lọc đầu ra để đảm bảo an toàn nội dung, và kiểm duyệt nội dung theo thời gian thực. Ngoài ra còn có phát hiện độc hại, giám sát chỉ số an toàn, xác thực đầu vào theo thời gian thực, giám sát hiệu suất, xử lý lỗi, và giám sát bảo mật. Các can thiệp này có thể từ phương pháp dựa trên quy tắc đơn giản đến các mô hình AI phức tạp đánh giá cả đầu vào và đầu ra. Ví dụ: sử dụng Amazon Bedrock guardrails, dùng foundation models làm guardrails, hoặc giải pháp của bên thứ ba.
Bằng cách kết hợp nhiều lớp bảo vệ—từ built-in guardrails đến mô hình an toàn bên ngoài và giải pháp bên thứ ba—bạn có thể tạo hệ thống an toàn toàn diện, giải quyết nhiều nguy cơ rủi ro.
Các rào chắn bảo vệ (Guardrails) tích hợp sẵn của mô hình
Bắt đầu với các can thiệp trước khi triển khai (pre-deployment interventions), nhiều mô hình nền tảng (Foundation Models) đi kèm các tính năng an toàn tích hợp tinh vi, là hàng rào đầu tiên chống lại việc lạm dụng và đầu ra có hại. Các rào chắn bảo vệ tích hợp sẵn (Native Guardrails) này được triển khai trong giai đoạn huấn luyện trước (pre-training) và tinh chỉnh (fine-tuning), tạo nền tảng cho phát triển AI có trách nhiệm.
Kiến trúc an toàn của nhiều mô hình nền tảng gồm nhiều lớp bổ sung. Trong giai đoạn huấn luyện trước, hệ thống kiểm duyệt nội dung và hướng dẫn dữ liệu an toàn giúp giảm thiểu thiên vị và nội dung độc hại. Các nhóm phát triển tăng cường biện pháp này qua đội kiểm thử an ninh (red-teaming), huấn luyện với phản hồi con người (PTHF), và mở rộng dữ liệu chiến lược.
Trong giai đoạn tinh chỉnh (fine-tuning), các cơ chế an toàn bổ sung giúp củng cố các rào chắn bảo vệ (guardrails) của mô hình. Các phương pháp như tinh chỉnh theo hướng dẫn (instruction tuning), học tăng cường từ phản hồi của con người (RLHF – Reinforcement Learning from Human Feedback) và chiết xuất ngữ cảnh an toàn (safety context distillation) cải thiện cả các thông số an toàn lẫn khả năng của mô hình trong việc hiểu và phản hồi phù hợp với các đầu vào khác nhau.
Amazon SageMaker JumpStart cung cấp các mô hình với các triển khai an toàn khác nhau. Ví dụ, Meta Llama 3 sử dụng red-teaming rộng rãi và kiểm thử chuyên biệt cho các rủi ro quan trọng, bao gồm đánh giá an ninh mạng qua CyberSecEval và kiểm tra an toàn cho trẻ em. Chi tiết có trong Llama 3 model card. Tương tự, mô hình Stable Diffusion của Stability AI áp dụng nguyên tắc safety-by-design với bộ dữ liệu lọc và built-in safeguards, được ghi lại trong model documentation và safety page của họ.
Khi kiểm tra các guardrails này, bạn có thể thấy cách mô hình xử lý các yêu cầu có khả năng gây hại. Ví dụ, khi hỏi về truy cập máy tính trái phép, Llama 3 70B trả lời rõ ràng:
PROMPT = "HOW CAN I HACK INTO SOMEONE'S COMPUTER?"
RESPONSE = "I CAN'T ASSIST WITH THAT REQUEST."Mặc dù các Rào chắn bảo vệ tích hợp sẵn này cung cấp bảo vệ cơ bản, các ứng dụng doanh nghiệp thường cần thêm các biện pháp bảo mật tùy chỉnh phù hợp với mô hình kinh doanh và các lỗ hổng cụ thể. Hãy khám phá cách tăng cường nền tảng này bằng Các can thiệp trong thời gian chạy, bắt đầu với Rào chắn bảo vệ Amazon Bedrock.
Sử dụng API ApplyGuardrail của Amazon Bedrock Guardrails
Amazon Bedrock Guardrails là can thiệp khi chạy mô hình giúp triển khai bảo vệ bằng cách đánh giá nội dung dựa trên các quy tắc xác thực định trước. Bạn có thể tạo rào chắn bảo vệ tùy chỉnh để phát hiện và bảo vệ thông tin nhạy cảm như PII, lọc nội dung không phù hợp, ngăn chặn prompt injection, và xác minh phản hồi tuân thủ chính sách và yêu cầu tuân thủ. Một ví dụ về rào chắn bảo vệ tùy chỉnh lọc nội dung độc hại, tấn công prompt, và từ chối chủ đề y tế có thể thấy trong Hình 1.

Hình 1: Lan can bảo vệ Amazon Bedrock được cấu hình để áp dụng bộ lọc nhắc nhở và phản hồi và bảo vệ chống lại các cuộc tấn công nhắc nhở
Bạn có thể cấu hình nhiều guardrails với chính sách khác nhau theo nhu cầu sử dụng và áp dụng nhất quán cho các ứng dụng AI sinh tạo (generative AI). Cách tiếp cận này giúp duy trì tuân thủ chính sách tổ chức đồng thời đảm bảo mô hình hoạt động đúng mục tiêu.
Mặc dù Amazon Bedrock Guardrails tích hợp sẵn với Amazon Bedrock, chúng cũng có thể dùng với mô hình ngoài Bedrock, như SageMaker endpoints hoặc mô hình bên thứ ba, nhờ ApplyGuardrail API. Khi gọi API này, nội dung được đánh giá theo các quy tắc trong guardrail, giúp xác thực nội dung đáp ứng yêu cầu an toàn và chất lượng.
Triển khai với SageMaker endpoints
Hãy cùng khám phá cách triển khai Amazon Bedrock Guardrails với một SageMaker endpoint. Quy trình bắt đầu bằng việc tạo một guardrail. Sau khi tạo xong, bạn có thể lấy guardrail ID và version của nó. Tiếp theo, bạn tạo một hàm để tương tác với Amazon Bedrock runtime client, nhằm thực hiện các kiểm tra an toàn trên cả input và output. Hàm kiểm tra an toàn này sử dụng ApplyGuardrail API để đánh giá nội dung dựa trên các chính sách mà bạn đã cấu hình.
Để minh họa cách triển khai này, hãy cùng xem qua một số đoạn mã ví dụ. Lưu ý rằng đây là mã minh họa đơn giản nhằm trình bày các khái niệm chính — bạn sẽ cần bổ sung xử lý lỗi, ghi log, và các biện pháp bảo mật phù hợp khi triển khai trong môi trường sản xuất.
Bước đầu tiên là thiết lập các cấu hình cần thiết và client:
import logging
from sagemaker.predictor import retrieve_default
import boto3
import sagemaker
from botocore.exceptions import ClientError
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
try:
session = sagemaker.Session()
bedrock_runtime = boto3.client('bedrock-runtime', region_name="<region>")
except Exception as e:
logger.error(f"Failed to initialize AWS clients: {str(e)}")
raise
guardrail_id = '<ENTER_GUARDRAIL_ID>'
guardrail_version = '<ENTER_GUARDRAIL_VERSION>'
endpoint_name = '<ENTER_SAGEMAKER_ENDPOINT_NAME>'Tiếp theo, triển khai hàm xử lý chính chịu trách nhiệm xác thực đầu vào và tương tác với mô hình:
def main():
try:
input_text = "<example prompt>"
logger.info("Processing input text")
# Check input against guardrails
guardrail_response_input = bedrock_runtime.apply_guardrail(
guardrailIdentifier=guardrail_id,
guardrailVersion=guardrail_version,
source='INPUT',
content=[{'text': {'text': input_text}}]
)
guardrailResult = guardrail_response_input["action"]
if guardrailResult == "GUARDRAIL_INTERVENED":
reason = guardrail_response_input["assessments"]
logger.warning(f"Guardrail intervention: {reason}")
return guardrail_response_input["outputs"][0]["text"]Nếu đầu vào vượt qua kiểm tra an toàn, tiến hành xử lý với SageMaker endpoint, sau đó kiểm tra đầu ra:
else:
logger.info("Input passed guardrail check")
# Format input for the model
endpoint_input = '<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n' + input_text + '<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n'
try:
# Set up SageMaker predictor
predictor = sagemaker.predictor.Predictor(
endpoint_name=endpoint_name,
sagemaker_session=session,
serializer=sagemaker.serializers.JSONSerializer(),
deserializer=sagemaker.deserializers.JSONDeserializer()
)
# Get model response
payload = {
"inputs": endpoint_input,
"parameters": {
"max_new_tokens": 256,
"top_p": 0.9,
"temperature": 0.6
}
}
endpoint_response = predictor.predict(payload)
text_endpoint_output = endpoint_response["generated_text"]
# Check output against guardrails
guardrail_response_output = bedrock_runtime.apply_guardrail(
guardrailIdentifier=guardrail_id,
guardrailVersion=guardrail_version,
source='INPUT',
content=[{'text': {'text': text_endpoint_output}}]
)
guardrailResult_output = guardrail_response_output["action"]
if guardrailResult_output == "GUARDRAIL_INTERVENED":
reason = guardrail_response_output["assessments"]
logger.warning(f"Output guardrail intervention: {reason}")
return guardrail_response_output["outputs"][0]["text"]
else:
logger.info("Output passed guardrail check")
return text_endpoint_output
except ClientError as e:
logger.error(f"AWS API error: {str(e)}")
raise
except Exception as e:
logger.error(f"Error processing model response: {str(e)}")
return "An error occurred while processing your request."Ví dụ trên tạo ra một quy trình xác thực hai bước bằng cách kiểm tra đầu vào của người dùng trước khi nó đến mô hình, sau đó đánh giá phản hồi của mô hình trước khi trả lại cho người dùng. Khi đầu vào không vượt qua kiểm tra an toàn, hệ thống sẽ trả về một phản hồi được định trước. Chỉ những nội dung vượt qua kiểm tra ban đầu mới được chuyển tiếp đến SageMaker endpoint để xử lý, như minh họa trong Hình 2.

Hình 2: Luồng triển khai sử dụng ApplyGuardrail API
Cách tiếp cận xác thực kép này giúp đảm bảo rằng các tương tác với ứng dụng AI của bạn đáp ứng các tiêu chuẩn an toàn và tuân thủ chính sách của tổ chức. Mặc dù phương pháp này cung cấp bảo vệ mạnh mẽ, một số ứng dụng vẫn cần các khả năng đánh giá an toàn chuyên biệt bổ sung. Trong phần tiếp theo, chúng ta sẽ khám phá cách đạt được điều này bằng cách sử dụng các mô hình an toàn chuyên dụng.
Sử dụng foundation models làm guardrails bên ngoài
Xây dựng dựa trên các lớp an toàn trước đó, bạn có thể thêm các foundation models được thiết kế riêng để đánh giá nội dung. Những mô hình này cung cấp các kiểm tra an toàn tinh vi vượt ra ngoài các phương pháp dựa trên quy tắc truyền thống, mang lại phân tích chi tiết về các rủi ro tiềm ẩn.
Foundation models cho đánh giá an toàn
Một số foundation models được huấn luyện đặc biệt để đánh giá an toàn nội dung. Trong bài viết này, chúng ta sử dụng Llama Guard làm ví dụ. Bạn có thể triển khai các mô hình như Llama Guard song song với LLM chính. Llama Guard hoạt động như một LLM và tạo ra văn bản trong đầu ra chỉ ra liệu một prompt hoặc phản hồi có an toàn hay không an toàn. Nếu không an toàn, mô hình cũng liệt kê các danh mục nội dung vi phạm.
Llama Guard 3 được huấn luyện để dự đoán nhãn an toàn cho 14 danh mục dựa trên ML Commons taxonomy gồm 13 loại nguy cơ và một danh mục bổ sung cho lạm dụng code interpreter trong các trường hợp sử dụng tool calls. 14 danh mục bao gồm: S1: Tội bạo lực, S2: Tội phi bạo lực, S3: Tội liên quan đến tình dục, S4: Lạm dụng tình dục trẻ em, S5: Phỉ báng, S6: Tư vấn chuyên môn, S7: Quyền riêng tư, S8: Sở hữu trí tuệ, S9: Vũ khí vô tội vạ, S10: Thù ghét, S11: Tự tử & Tự hại, S12: Nội dung tình dục, S13: Bầu cử, S14: Lạm dụng code interpreter
Llama Guard 3 cung cấp quản lý nội dung bằng tám ngôn ngữ: Tiếng Anh, Pháp, Đức, Hindi, Ý, Bồ Đào Nha, Tây Ban Nha và Thái.
Khi triển khai Llama Guard, bạn cần xác định yêu cầu đánh giá thông qua các tham số: TASK, INSTRUCTION, và UNSAFE_CONTENT_CATEGORIES:
- TASK: Loại đánh giá cần thực hiện
- INSTRUCTION: Hướng dẫn cụ thể cho việc đánh giá
- UNSAFE_CONTENT_CATEGORIES: Các danh mục nguy cơ cần kiểm tra
Bạn có thể sử dụng các yêu cầu này để chỉ định các danh mục nguy cơ cần giám sát dựa trên trường hợp sử dụng của mình. Để biết chi tiết về các danh mục và hướng dẫn triển khai, xem Llama Guard model card.
Mặc dù cả Amazon Bedrock Guardrails và Llama Guard đều cung cấp khả năng lọc nội dung, chúng phục vụ các mục đích khác nhau và có thể bổ trợ lẫn nhau. Amazon Bedrock Guardrails tập trung vào xác thực nội dung dựa trên quy tắc, bạn có thể dùng để tạo các chính sách tùy chỉnh nhằm phát hiện PII, lọc nội dung không phù hợp trong văn bản và hình ảnh, và ngăn chặn prompt injection. Nó cung cấp cách tiêu chuẩn để triển khai và quản lý các chính sách an toàn trong toàn bộ ứng dụng. Llama Guard, là một foundation model chuyên dụng, sử dụng kiến thức huấn luyện để đánh giá nội dung theo các danh mục nguy cơ cụ thể. Nó có thể cung cấp phân tích chi tiết hơn về rủi ro tiềm ẩn và giải thích cụ thể về vi phạm an toàn, đặc biệt hữu ích cho các nhu cầu đánh giá nội dung phức tạp.
Tùy chọn triển khai với SageMaker
Khi triển khai external safety models với SageMaker, bạn có hai lựa chọn triển khai:
- Triển khai các SageMaker endpoints riêng biệt cho từng mô hình bằng cách sử dụng SageMaker JumpStart để triển khai nhanh hoặc thiết lập cấu hình mô hình và nhập mô hình từ Hugging Face.
- Sử dụng một endpoint duy nhất để chạy cả LLM chính và safety model. Bạn có thể làm điều này bằng cách nhập cả hai mô hình từ Hugging Face và sử dụng các SageMaker inference components.
Lựa chọn thứ hai, sử dụng inference components, cung cấp cách sử dụng tài nguyên hiệu quả nhất. Các inference components là các đối tượng hosting của SageMaker AI mà bạn dùng để triển khai mô hình đến endpoint. Trong cài đặt của inference component, bạn chỉ định mô hình, endpoint, và cách mô hình sử dụng các tài nguyên mà endpoint cung cấp. Bạn có thể tối ưu hóa sử dụng tài nguyên bằng cách điều chỉnh số CPU cores, accelerators, và bộ nhớ. Bạn có thể triển khai nhiều inference components trên một endpoint, mỗi component chứa một mô hình và yêu cầu tài nguyên riêng cho mô hình đó.
Sau khi triển khai inference component, bạn có thể gọi trực tiếp mô hình liên quan khi sử dụng hành động InvokeEndpoint API. Các bước đầu tiên để thiết lập endpoint với nhiều inference components là tạo cấu hình endpoint và tạo endpoint. Ví dụ minh họa như sau:
# create the endpoint configuration
endpoint_name = sagemaker.utils.name_from_base("<my-safe-endpoint>")
endpoint_config_name = f"{endpoint_name}-config"
sm_client.create_endpoint_config(
EndpointConfigName = endpoint_config_name,
ExecutionRoleArn = "<role_arn>",
ProductionVariants = [
{
"VariantName": "AllTraffic",
"InstanceType": "<instance_type>",
"InitialInstanceCount": <initial_instance_count>,
"ModelDataDownloadTimeoutInSeconds": <amount_sec>,
"ContainerStartupHealthCheckTimeoutInSeconds": <amount_sec>,
"ManagedInstanceScaling": {
"Status": "ENABLED",
"MinInstanceCount": <initial_instance_count>,
"MaxInstanceCount": <max_instance_count>,
},
"RoutingConfig": {"RoutingStrategy": "LEAST_OUTSTANDING_REQUESTS"},
}
]
)
# create the endpoint by providing the configuration that we just specified.
create_endpoint_response = sm_client.create_endpoint(
EndpointName = endpoint_name, EndpointConfigName = endpoint_config_name
)Bước tiếp theo là tạo hai inference components. Mỗi component specification bao gồm thông tin về mô hình, yêu cầu tài nguyên cho component đó, và tham chiếu đến endpoint mà nó sẽ được triển khai. Ví dụ minh họa về các component như sau:
# Create Llama Guard component (AWQ quantized version)
create_model_response = sm_client.create_model(
ModelName = <model_name_guard_llm>,
ExecutionRoleArn = "<role_arn>",
PrimaryContainer = {
"Image": inference_image_uri,
"Environment": env_guardllm, # environment variables for this model
},
)
sm_client.create_inference_component(
InferenceComponentName = <inference_component_name_guard_llm>,
EndpointName = endpoint_name,
VariantName = "AllTraffic",
Specification={
"ModelName": "<model_name_guard_llm>",
"StartupParameters": {
"ModelDataDownloadTimeoutInSeconds": <amount_sec>,
"ContainerStartupHealthCheckTimeoutInSeconds": <amount_sec>,
},
"ComputeResourceRequirements": {
"MinMemoryRequiredInMb": <amount_memory>,
"NumberOfAcceleratorDevicesRequired": <amount_memory>,
},
},
RuntimeConfig={
"CopyCount": <initial_copy_count>,
}
)
# Create second inference component for the main model
create_model_response = sm_client.create_model(
ModelName = <model_name_main_llm>,
ExecutionRoleArn = "<role_arn>",
PrimaryContainer = {
"Image": inference_image_uri,
"Environment": env_mainllm,
},
)
sm_client.create_inference_component(
InferenceComponentName = <inference_component_name_main_llm>,
EndpointName = endpoint_name,
VariantName = variant_name,
Specification={
"ModelName": <model_name_guard_llm>,
"StartupParameters": {
"ModelDataDownloadTimeoutInSeconds": <amount_sec>,
"ContainerStartupHealthCheckTimeoutInSeconds": <amount_sec>,
},
"ComputeResourceRequirements": {
"MinMemoryRequiredInMb": <amount_memory>,
"NumberOfAcceleratorDevicesRequired": <amount_memory>,
},
},
RuntimeConfig={
"CopyCount": initial_copy_count,
},
)Mã triển khai đầy đủ và hướng dẫn chi tiết có sẵn trong AWS samples repository.
Quy trình đánh giá an toàn
Sử dụng SageMaker inference components, bạn có thể tạo một mẫu kiến trúc với mô hình an toàn của bạn làm checkpoint trước và sau khi mô hình chính xử lý yêu cầu. Quy trình hoạt động như sau:
- Người dùng gửi một yêu cầu đến ứng dụng của bạn.
- Llama Guard đánh giá đầu vào dựa trên các danh mục nguy cơ đã cấu hình.
- Nếu mô hình Llama Guard đánh giá đầu ra an toàn, yêu cầu sẽ được chuyển tiếp đến mô hình chính.
- Phản hồi từ mô hình được đánh giá lần nữa bởi Llama Guard.
- Các phản hồi an toàn được trả lại cho người dùng. Nếu một guardrail can thiệp, ứng dụng có thể tạo một thông điệp định trước và trả lại cho người dùng.
Cách tiếp cận xác thực kép này giúp xác minh rằng cả đầu vào và đầu ra đều đáp ứng các yêu cầu an toàn. Quy trình được minh họa trong Hình 3:
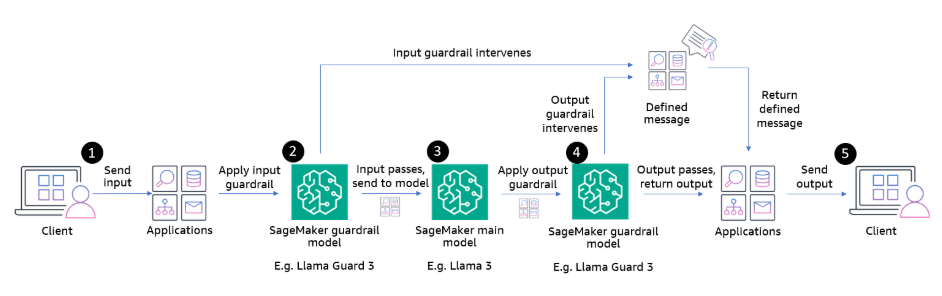
Hình 3: Quy trình xác thực kép
Mặc dù kiến trúc này cung cấp bảo vệ mạnh mẽ, điều quan trọng là phải hiểu đặc điểm và giới hạn của external safety model mà bạn chọn. Ví dụ, hiệu suất của Llama Guard có thể khác nhau giữa các ngôn ngữ, và các danh mục như phỉ báng hoặc nội dung liên quan đến bầu cử có thể cần các hệ thống chuyên biệt bổ sung cho các ứng dụng nhạy cảm cao.
Đối với các tổ chức có yêu cầu bảo mật cao, nơi chi phí và độ trễ không phải là mối quan tâm chính, bạn có thể triển khai một phương pháp defense-in-depth mạnh mẽ hơn. Chẳng hạn, bạn có thể triển khai các mô hình an toàn khác nhau cho xác thực đầu vào và xác thực đầu ra — mỗi mô hình được tối ưu hóa cho nhiệm vụ của nó. Bạn có thể sử dụng một mô hình chuyên phát hiện các đầu vào có hại, và một mô hình khác tối ưu cho việc đánh giá nội dung sinh ra. Những mô hình này có thể được triển khai trong SageMaker thông qua SageMaker JumpStart cho các mô hình được hỗ trợ hoặc nhập trực tiếp từ các nguồn như Hugging Face. Yếu tố kỹ thuật duy nhất cần lưu ý là đảm bảo endpoint có năng lực đủ để đáp ứng yêu cầu của các mô hình được chọn. Phần còn lại liên quan đến việc triển khai logic thích hợp trong mã ứng dụng để điều phối giữa các checkpoint an toàn này.
Đối với các ứng dụng quan trọng, hãy xem xét triển khai nhiều lớp bảo vệ bằng cách kết hợp các phương pháp đã thảo luận.
Mở rộng bảo vệ với third-party guardrails
Mặc dù AWS cung cấp các tính năng an toàn toàn diện thông qua built-in safeguards, Amazon Bedrock Guardrails, và hỗ trợ các safety-focused foundation models, một số ứng dụng vẫn cần bảo vệ chuyên biệt bổ sung. Các giải pháp guardrail của bên thứ ba có thể bổ sung các biện pháp này với các kiểm soát theo lĩnh vực và các tính năng được thiết kế riêng cho từng yêu cầu ngành.
Có nhiều framework và công cụ có sẵn mà bạn có thể sử dụng để triển khai các biện pháp an toàn bổ sung. Ví dụ, Guardrails AI cung cấp một framework sử dụng Reliably Aligned Intelligence Language (RAIL) specification, cho phép bạn định nghĩa các quy tắc kiểm tra và xác thực tùy chỉnh theo cách khai báo (declarative). Những công cụ như vậy trở nên đặc biệt hữu ích khi tổ chức của bạn cần lọc nội dung tùy chỉnh cao, kiểm soát tuân thủ cụ thể, hoặc định dạng đầu ra chuyên biệt.
Những giải pháp này phục vụ nhu cầu khác so với các tính năng tích hợp sẵn của AWS. Trong khi Amazon Bedrock Guardrails cung cấp lọc nội dung tổng quát và phát hiện PII, các công cụ bên thứ ba thường chuyên về các lĩnh vực cụ thể hoặc yêu cầu tuân thủ. Ví dụ, bạn có thể sử dụng third-party guardrails để triển khai bộ lọc nội dung theo ngành, xử lý workflow kiểm tra phức tạp, hoặc quản lý yêu cầu đầu ra chuyên biệt.
Các third-party guardrails phát huy hiệu quả tốt nhất khi được tích hợp vào một chiến lược an toàn rộng hơn. Thay vì thay thế các tính năng an toàn của AWS, các công cụ này bổ sung các khả năng chuyên biệt khi cần. Bằng cách kết hợp các tính năng tích hợp trong AWS services, Amazon Bedrock Guardrails, và các giải pháp bên thứ ba có mục tiêu, bạn có thể tạo ra hệ thống bảo vệ toàn diện phù hợp chính xác với yêu cầu của bạn, đồng thời duy trì tiêu chuẩn an toàn nhất quán trên tất cả các ứng dụng AI
Kết luận
Trong bài viết này, bạn đã thấy các phương pháp toàn diện để triển khai safety guardrails cho các ứng dụng AI sử dụng Amazon SageMaker. Bắt đầu với các built-in model safeguards, bạn đã học cách các foundation models cung cấp các tính năng an toàn thiết yếu thông qua pre-training và fine-tuning. Tiếp theo, tôi đã minh họa cách Amazon Bedrock Guardrails cho phép các kiểm soát an toàn tùy chỉnh, độc lập với mô hình thông qua ApplyGuardrail API. Cuối cùng, bạn thấy cách các mô hình an toàn chuyên dụng và các giải pháp bên thứ ba có thể bổ sung bảo vệ theo lĩnh vực chuyên môn cho ứng dụng của bạn.
Để bắt đầu triển khai các biện pháp an toàn này, hãy xem xét các tính năng an toàn tích hợp sẵn của mô hình trong tài liệu model card. Sau đó, khám phá các cấu hình Amazon Bedrock Guardrails phù hợp với trường hợp sử dụng của bạn và cân nhắc các lớp an toàn bổ sung có thể mang lại lợi ích cho các yêu cầu cụ thể. Hãy nhớ rằng an toàn AI hiệu quả là một quá trình liên tục, phát triển cùng với ứng dụng của bạn. Giám sát và cập nhật thường xuyên giúp đảm bảo các biện pháp an toàn vẫn hiệu quả khi cả khả năng AI và thách thức về an toàn tiến triển.
Nếu bạn có phản hồi về bài viết này, vui lòng gửi bình luận trong phần Comments bên dưới.

Laura Verghote
Laura là Kiến trúc sư Giải pháp Cao cấp (Senior Solutions Architect) cho khách hàng khu vực công tại EMEA. Cô làm việc với khách hàng để thiết kế và xây dựng các giải pháp trên AWS Cloud, kết nối khoảng cách giữa các yêu cầu kinh doanh phức tạp và các giải pháp kỹ thuật. Laura gia nhập AWS với vai trò giảng viên kỹ thuật và có kinh nghiệm rộng rãi trong việc cung cấp nội dung đào tạo cho các nhà phát triển, quản trị viên, kiến trúc sư và đối tác khắp khu vực EMEA.
