bởi Yunfei Bai, Anupam Dewan, Kashif Imran, and Shuai Wang |ngày 29 tháng 4 năm 2025 | trong Amazon Bedrock, Amazon Nova, Generative AI, Thought Leadership
Trong kỷ nguyên của Trí tuệ nhân tạo sinh (Generative AI), các mô hình ngôn ngữ lớn (Large Language Models – LLMs) mới liên tục xuất hiện, mỗi mô hình đều có khả năng, kiến trúc và tối ưu hóa riêng biệt. Trong số đó, các Mô hình nền tảng Amazon Nova (Amazon Nova Foundation Models) mang đến trí tuệ tiên tiến cùng hiệu quả chi phí hàng đầu, và chỉ khả dụng độc quyền trên Amazon Bedrock. Kể từ khi ra mắt vào năm 2024, nhiều nhóm tại Amazon và các chuyên gia về Generative AI đã bắt đầu chuyển khối lượng công việc của họ sang các mô hình Amazon Nova.
Tuy nhiên, khi di chuyển giữa các mô hình nền tảng khác nhau, các prompt được thiết kế cho mô hình ban đầu có thể không hoạt động hiệu quả trên Amazon Nova nếu không có quy trình kỹ thuật và tối ưu hóa prompt phù hợp. Amazon Bedrock Prompt Optimization cung cấp công cụ để tự động tối ưu hóa prompt cho mô hình đích (trong trường hợp này là Amazon Nova). Nó có thể chuyển đổi các prompt ban đầu sang định dạng được điều chỉnh tối ưu cho Amazon Nova. Trong quá trình di chuyển, một thách thức quan trọng là đảm bảo rằng hiệu suất sau khi di chuyển ít nhất cũng tương đương, nếu không muốn nói là tốt hơn, so với trước đó. Để đạt được điều này, bạn cần tiến hành đánh giá mô hình, đo lường và tối ưu hóa dựa trên dữ liệu – quá trình này giúp so sánh hiệu suất của Amazon Nova với mô hình trước đó và tinh chỉnh prompt để đạt hoặc vượt hiệu năng cũ.
Trong bài viết này, chúng tôi trình bày một mô hình và kiến trúc di chuyển LLM bao gồm quy trình liên tục gồm: đánh giá mô hình, tạo prompt bằng Amazon Bedrock và tối ưu hóa prompt nhận thức dữ liệu (data-aware prompt optimization). Giải pháp này đánh giá hiệu năng mô hình trước khi di chuyển và dần tối ưu hóa các prompt trên Amazon Nova bằng tập dữ liệu và tiêu chí đánh giá do người dùng cung cấp. Chúng tôi minh họa quy trình di chuyển thành công sang Amazon Nova cho ba tác vụ LLM: tóm tắt văn bản (text summarization), phân loại văn bản đa lớp (multi-class text classification) và hỏi – đáp dựa trên RAG (Retrieval-Augmented Generation). Cuối cùng, chúng tôi chia sẻ những bài học kinh nghiệm và các thực hành tốt nhất để giúp bạn áp dụng giải pháp này cho các trường hợp sử dụng của riêng mình.
Di chuyển khối lượng công việc Generative AI sang Amazon Nova
Di chuyển mô hình từ khối lượng công việc Generative AI sang Amazon Nova đòi hỏi một cách tiếp cận có cấu trúc để đạt được tính nhất quán và cải thiện hiệu suất. Quá trình này bao gồm đánh giá và so sánh mô hình cũ và mới, tối ưu hóa prompt trên mô hình mới, và kiểm thử và triển khai các mô hình mới trong môi trường production của bạn. Trong phần này, chúng tôi trình bày một quy trình làm việc gồm bốn bước và kiến trúc giải pháp, như minh họa trong sơ đồ kiến trúc sau.

Quy trình làm việc bao gồm các bước sau:
- Đánh giá mô hình nguồn và thu thập các chỉ số hiệu năng chính dựa trên trường hợp sử dụng kinh doanh của bạn, chẳng hạn như độ chính xác của phản hồi, độ đúng định dạng của phản hồi, độ trễ và chi phí, để thiết lập một mức cơ sở hiệu năng làm mục tiêu di chuyển mô hình.
- Tự động cập nhật cấu trúc, hướng dẫn và ngôn ngữ của các prompt để thích ứng với mô hình Amazon Nova, nhằm tạo ra các đầu ra chính xác, phù hợp và trung thực. Chúng tôi sẽ thảo luận chi tiết hơn về nội dung này trong phần tiếp theo.
- Đánh giá các prompt đã được tối ưu hóa trên mô hình Amazon Nova sau khi di chuyển, để đảm bảo đáp ứng mục tiêu hiệu năng được xác định ở Bước 1. Bạn có thể thực hiện quá trình tối ưu hóa ở Bước 2 theo cách lặp lại cho đến khi các prompt tối ưu hóa đáp ứng tiêu chí kinh doanh của bạn.
- Thực hiện kiểm thử A/B để xác nhận hiệu năng của mô hình Amazon Nova trong môi trường kiểm thử và sản xuất của bạn. Khi đã đạt yêu cầu, bạn có thể triển khai mô hình Amazon Nova cùng các thiết lập và prompt trong môi trường sản xuất.
Quy trình bốn bước này cần được chạy liên tục, để thích ứng với biến động cả về mô hình và dữ liệu, do sự thay đổi trong các trường hợp sử dụng kinh doanh. Việc thích ứng liên tục này cung cấp tối ưu hóa liên tục và giúp tối đa hóa hiệu suất mô hình tổng thể.
Tối ưu hóa prompt nhận thức dữ liệu trên Amazon Nova
Trong phần này, chúng tôi trình bày một phương pháp tối ưu hóa toàn diện gồm hai bước. Bước đầu tiên là sử dụng tính năng tối ưu hóa prompt của Amazon Bedrock để tinh chỉnh cấu trúc prompt của bạn, sau đó áp dụng phương pháp tối ưu hóa prompt nhận thức dữ liệu (data-aware prompt optimization) mang tính sáng tạo để tiếp tục cải thiện prompt, giúp nâng cao hiệu suất của mô hình Amazon Nova.
Tối ưu hóa prompt trong Amazon Bedrock
Amazon Bedrock cung cấp tính năng tối ưu hóa prompt, cho phép viết lại các prompt để cải thiện hiệu suất cho các trường hợp sử dụng của bạn. Tính năng này đơn giản hóa cách các nhà phát triển AWS tương tác với các mô hình nền tảng (Foundation Models – FMs) trên Amazon Bedrock, tự động điều chỉnh prompt cho phù hợp với mô hình đã chọn và tạo ra các đầu ra có hiệu năng cao hơn.
Ở bước đầu tiên, bạn có thể sử dụng tính năng tối ưu hóa prompt để điều chỉnh prompt của mình cho phù hợp với Amazon Nova. Bằng cách phân tích prompt bạn cung cấp, tính năng này diễn giải nhiệm vụ, prompt hệ thống và hướng dẫn trong prompt, sau đó tự động tạo lại prompt với định dạng riêng cho Amazon Nova cùng các từ, cụm từ và câu phù hợp. Ví dụ sau đây minh họa cách mà tính năng tối ưu hóa prompt chuyển đổi một prompt thông thường cho tác vụ tóm tắt trên Claude Haiku của Anthropic thành một prompt có cấu trúc chặt chẽ cho mô hình Amazon Nova, với các phần bắt đầu bằng các thẻ markdown đặc biệt như ## Task, ### Summarization Instructions, và ### Document to Summarize.
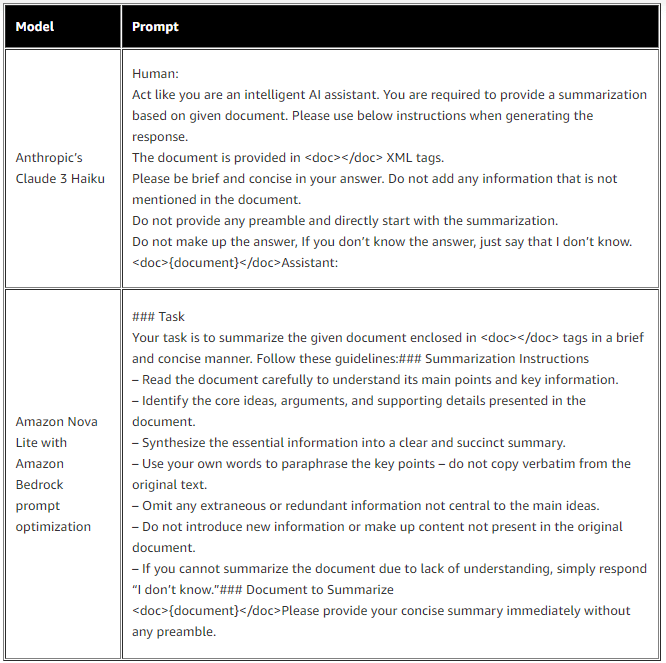
Chúng tôi đã áp dụng các prompt nêu trên lần lượt cho hai mô hình Anthropic Claude 3 Haiku và Amazon Nova Lite, sử dụng bộ dữ liệu công khai xsum. Để đánh giá hiệu năng của mô hình, do tác vụ tóm tắt không có “ground truth” (đáp án chuẩn) được xác định sẵn, chúng tôi đã thiết kế một LLM judge (một mô hình ngôn ngữ lớn đóng vai trò đánh giá) như được thể hiện trong prompt dưới đây, nhằm xác thực chất lượng bản tóm tắt:
You are an AI assistant, your task is to compare the following LLM-generated summary with the original document, rate how well it captures the key points and conveys the most critical information, on a scale of 1-5.
The score should be based on the following performance criteria:
- Consistency: characterizes the summary’s factual and logical correctness. It should stay true to the original text, not introduce additional information, and use the same terminology.
- Relevance: captures whether the summary is limited to the most pertinent information in the original text. A relevant summary focuses on the essential facts and key messages, omitting unnecessary details or trivial information.
- Fluency: describes the readability of the summary. A fluent summary is well-written and uses proper syntax, vocabulary, and grammar.
- Coherence: measures the logical flow and connectivity of ideas. A coherent summary presents the information in a structured, logical, and easily understandable manner.
Score 5 means the LLM-generated summary is the best summary fully aligned with the original document,
Score 1 means the LLM-generated summary is the worst summary completely irrelevant to the original document.
Please also provide an explanation on why you provide the score. Keep the explanation as concise as possible.
The LLM-generated summary is provided within the <summary> XML tag,
The original document is provided within the <document> XML tag,
In your response, present the score within the <score> XML tag, and the explanation within the <thinking> XML tag.
DO NOT nest <score> and <thinking> element.
DO NOT put any extra attribute in the <score> and <thinking> tag.
<document>
{document}
</document>
LLM generated summary:
<summary>
{summary}
</summary>Thí nghiệm được thực hiện với 80 mẫu dữ liệu cho thấy rằng độ chính xác của mô hình Amazon Nova Lite đã được cải thiện từ 77,75% lên 83,25% khi áp dụng tối ưu hóa prompt.
Tối ưu hóa dựa trên dữ liệu
Mặc dù tính năng tối ưu hóa prompt của Amazon Bedrock đáp ứng được các nhu cầu cơ bản của kỹ thuật prompt engineering, vẫn có các kỹ thuật tối ưu hóa prompt khác có thể được sử dụng để tối đa hóa hiệu suất của mô hình ngôn ngữ lớn (LLM), chẳng hạn như Multi-Aspect Critique, Self-Reflection, Gradient Descent và Beam Search, và Meta Prompting. Cụ thể, chúng tôi nhận thấy nhu cầu từ người dùng rằng họ cần tinh chỉnh các prompt của mình dựa trên những chỉ số mục tiêu tối ưu hóa mà họ tự xác định, chẳng hạn như ROUGE, BERT-F1, hoặc điểm đánh giá từ LLM judge, bằng cách sử dụng bộ dữ liệu do họ cung cấp. Để đáp ứng những nhu cầu này, chúng tôi đã thiết kế kiến trúc tối ưu hóa dựa trên dữ liệu, như được minh họa trong sơ đồ sau.
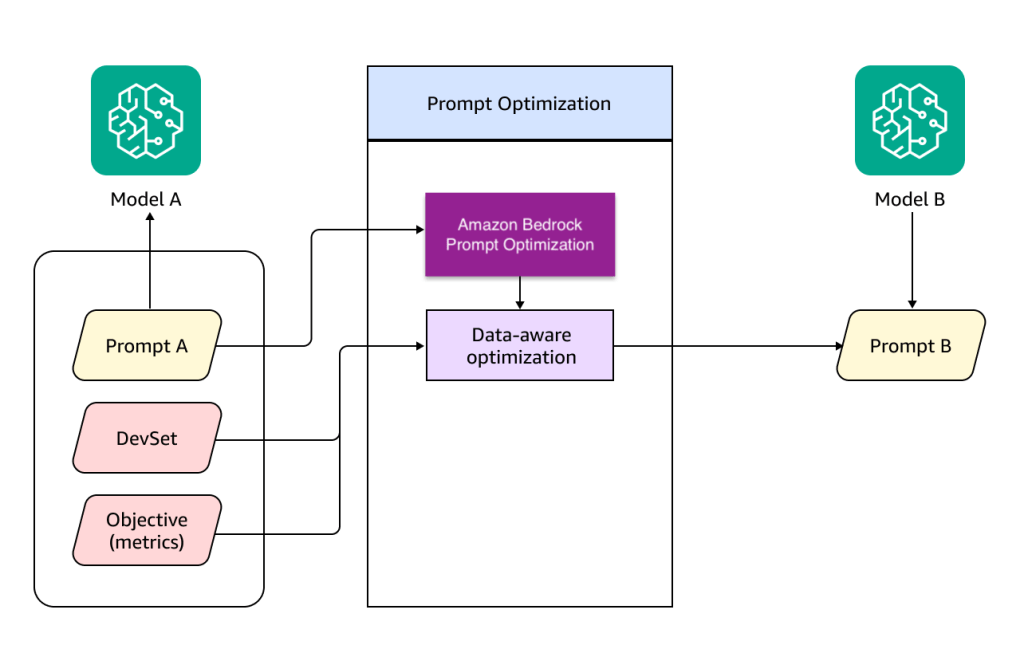
Tối ưu hóa dựa trên dữ liệu nhận các đầu vào. Đầu vào thứ nhất là các chỉ số mục tiêu tối ưu hóa do người dùng xác định; đối với tác vụ tóm tắt được đề cập trong phần trước, bạn có thể sử dụng điểm BERT-F1 hoặc tự tạo một LLM judge của riêng mình. Đầu vào thứ hai là bộ dữ liệu huấn luyện (DevSet) do người dùng cung cấp để xác thực chất lượng phản hồi, ví dụ như một mẫu dữ liệu tóm tắt có định dạng như sau.

Tối ưu hóa theo dữ liệu (data-aware optimization) sử dụng hai đầu vào này để cải thiện prompt, nhằm nâng cao chất lượng phản hồi của Amazon Nova. Trong công trình này, chúng tôi sử dụng bộ tối ưu DSPy (Declarative Self-improving Python) cho việc tối ưu hóa theo dữ liệu. DSPy là một framework phổ biến để lập trình các mô hình ngôn ngữ. Nó cung cấp các thuật toán để tối ưu prompt cho nhiều tác vụ LLM khác nhau, từ các bộ phân loại (classifier) và tóm tắt (summarizer) đơn giản đến các pipeline RAG phức tạp. Bộ tối ưu dspy.MIPROv2 khám phá một cách thông minh các hướng dẫn ngôn ngữ tự nhiên tốt hơn cho mỗi prompt bằng cách sử dụng DevSet, nhằm tối đa hóa các chỉ số mà bạn định nghĩa.
Chúng tôi đã áp dụng bộ tối ưu MIPROv2 trên các kết quả đã được tối ưu bởi Amazon Bedrock trong phần trước để cải thiện hiệu suất của Amazon Nova. Trong bộ tối ưu này, chúng tôi xác định số lượng ứng viên hướng dẫn trong không gian sinh (generation space), sử dụng tối ưu hóa Bayes (Bayesian optimization) để tìm kiếm hiệu quả trong không gian đó, và chạy lặp đi lặp lại để tạo ra các hướng dẫn cùng các ví dụ few-shot cho prompt ở mỗi bước:
# Initialize optimizer
teleprompter = MIPROv2(
metric=metric,
num_candidates=5,
auto="light",
verbose=False,
)Với thiết lập num_candidates=5, bộ tối ưu sẽ tạo ra năm hướng dẫn ứng viên (candidate instructions):
0: Given the fields `question`, produce the fields `answer`.
1: Given a complex question that requires a detailed reasoning process, produce a structured response that includes a step-by-step reasoning and a final answer. Ensure the reasoning clearly outlines each logical step taken to arrive at the answer, maintaining clarity and neutrality throughout.
2: Given the fields `question` and `document`, produce the fields `answer`. Read the document carefully to understand its main points and key information. Identify the core ideas, arguments, and supporting details presented in the document. Synthesize the essential information into a clear and succinct summary. Use your own words to paraphrase the key points without copying verbatim from the original text. Omit any extraneous or redundant information not central to the main ideas. Do not introduce new information or make up content not present in the original document. If you cannot summarize the document due to lack of understanding, simply respond "I don't know.
3: In a high-stakes scenario where you must summarize critical documents for an international legal case, use the Chain of Thought approach to process the question. Carefully read and understand the document enclosed in <doc></doc> tags, identify the core ideas and key information, and synthesize this into a clear and concise summary. Ensure that the summary is neutral, precise, and omits any extraneous details. If the document is too complex or unclear, respond with "I don't know.
4: Given the fields `question` and `document`, produce the fields `answer`. The `document` field contains the text to be summarized. The `answer` field should include a concise summary of the document, following the guidelines provided. Ensure the summary is clear, accurate, and captures the core ideas without introducing new information.Chúng tôi thiết lập các tham số khác cho vòng lặp tối ưu hóa, bao gồm số lượng thử nghiệm (trials), số lượng ví dụ few-shot, và kích thước lô (batch size) cho quá trình tối ưu hóa:
# Optimize program
optimized_program = teleprompter.compile(
program.deepcopy(),
trainset=trainset,
num_trials=7,
minibatch_size=20,
minibatch_full_eval_steps=7,
max_bootstrapped_demos=2,
max_labeled_demos=2,
requires_permission_to_run=False,
)Khi quá trình tối ưu hóa bắt đầu, MIPROv2 sử dụng từng hướng dẫn ứng viên cùng với mini-batch từ tập dữ liệu kiểm thử mà chúng tôi cung cấp để suy diễn (inference) trên LLM và tính toán các chỉ số mà chúng tôi đã định nghĩa. Sau khi vòng lặp kết thúc, bộ tối ưu đánh giá hướng dẫn tốt nhất bằng cách sử dụng toàn bộ tập dữ liệu kiểm thử và tính toán điểm đánh giá đầy đủ. Dựa trên các vòng lặp này, bộ tối ưu cung cấp hướng dẫn đã được cải thiện cho prompt:
Given the fields `question` and `document`, produce the fields `answer`.
The `document` field contains the text to be summarized.
The `answer` field should include a concise summary of the document, following the guidelines provided.
Ensure the summary is clear, accurate, and captures the core ideas without introducing new information.Khi áp dụng prompt đã được tối ưu, độ chính xác tóm tắt do LLM đánh giá trên mô hình Amazon Nova Lite được cải thiện từ 83,25% lên 87,75%.
Chúng tôi cũng đã áp dụng quy trình tối ưu hóa này trên các tác vụ LLM khác, bao gồm tác vụ phân loại văn bản đa lớp (multi-class text classification) và tác vụ hỏi-đáp (question-answering) sử dụng RAG. Trong tất cả các tác vụ, phương pháp của chúng tôi đã tối ưu hóa mô hình Amazon Nova sau khi di chuyển, giúp nó vượt trội so với các mô hình Anthropic Claude Haiku và Meta Llama trước khi di chuyển. Bảng và biểu đồ dưới đây minh họa kết quả tối ưu hóa.
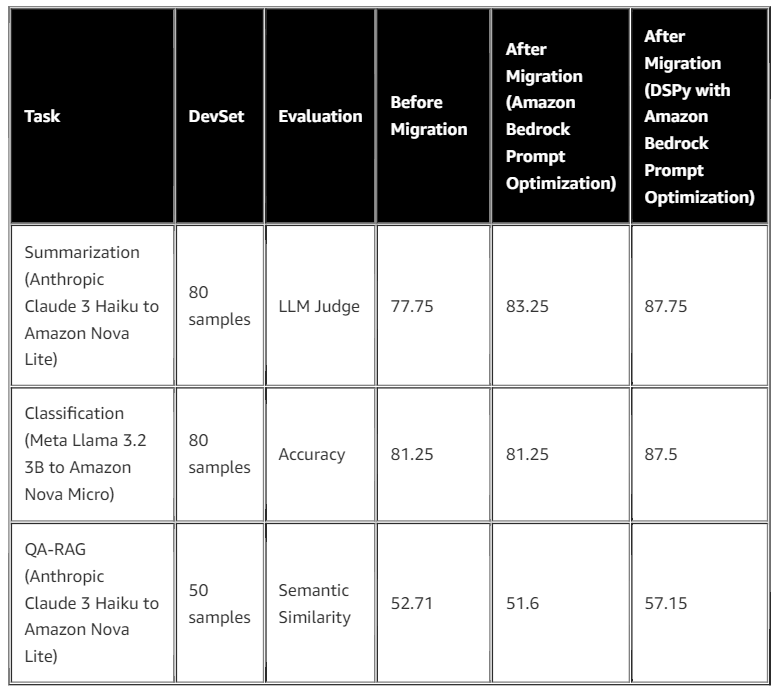

Trong trường hợp sử dụng phân loại văn bản, chúng tôi đã tối ưu hóa mô hình Amazon Nova Micro sử dụng 80 mẫu, dùng chỉ số độ chính xác (accuracy) để đánh giá hiệu suất tối ưu hóa ở mỗi bước. Sau bảy vòng lặp, prompt đã được tối ưu hóa đạt độ chính xác 87,5%, tăng từ 81,25% so với khi chạy trên mô hình Meta Llama 3.2 3B.
Trong trường hợp sử dụng hỏi-đáp, chúng tôi sử dụng 50 mẫu để tối ưu prompt cho mô hình Amazon Nova Lite trong pipeline RAG, và đánh giá hiệu suất dựa trên điểm tương đồng ngữ nghĩa (semantic similarity score). Điểm số này so sánh khoảng cách cosine giữa câu trả lời của mô hình và câu trả lời đúng. So với dữ liệu kiểm thử trên Claude 3 Haiku của Anthropic, bộ tối ưu đã cải thiện điểm số từ 52,71 lên 57,15 sau khi di chuyển sang mô hình Amazon Nova Lite và tối ưu prompt.
Chi tiết hơn về các ví dụ này có thể được tham khảo trong kho lưu trữ GitHub.
Bài học kinh nghiệm và các thực hành tốt nhất
Qua quá trình thiết kế giải pháp, chúng tôi đã xác định được những thực hành tốt nhất giúp bạn cấu hình tối ưu hóa prompt một cách hiệu quả, tối đa hóa các chỉ số mà bạn xác định cho từng trường hợp sử dụng:
- Tập dữ liệu dùng cho bộ tối ưu nên có chất lượng cao, phù hợp với nhiệm vụ, và cân bằng để bao quát các mẫu dữ liệu, các trường hợp biên, cũng như các sắc thái nhằm giảm thiểu thiên lệch (bias).
- Các chỉ số bạn định nghĩa để làm mục tiêu tối ưu hóa nên cụ thể theo từng trường hợp sử dụng. Nếu tập dữ liệu có ground truth, bạn có thể dùng các chỉ số ML thống kê và lập trình như độ chính xác (accuracy) và tương đồng ngữ nghĩa (semantic similarity). Nếu tập dữ liệu không có ground truth, một LLM judge được thiết kế tốt và phù hợp với con người có thể cung cấp điểm đánh giá đáng tin cậy cho bộ tối ưu.
- Bộ tối ưu chạy với một số lượng prompt ứng viên (dspy.num_candidates) và sử dụng chỉ số đánh giá bạn đã định nghĩa để chọn prompt tối ưu. Tránh thiết lập quá ít ứng viên, vì có thể bỏ lỡ cơ hội cải thiện.
Ví dụ trong trường hợp tóm tắt, chúng tôi đặt 5 prompt ứng viên để tối ưu hóa qua 80 mẫu huấn luyện và đạt hiệu suất tối ưu hóa tốt. - Prompt ứng viên bao gồm sự kết hợp giữa hướng dẫn (prompt instructions) và các ví dụ few-shot. Bạn có thể chỉ định số lượng ví dụ (dspy.max_labeled_demos cho ví dụ từ mẫu có nhãn, dspy.max_bootstrapped_demos cho ví dụ từ mẫu chưa có nhãn). Chúng tôi khuyến nghị số lượng ví dụ không nên ít hơn 2.
- Quá trình tối ưu chạy theo vòng lặp (dspy.num_trials); bạn nên thiết lập đủ số vòng lặp để tinh chỉnh prompt dựa trên các kịch bản và chỉ số hiệu suất khác nhau, từ đó cải thiện dần độ rõ ràng, sự phù hợp và khả năng thích ứng. Nếu bạn tối ưu cả hướng dẫn và các ví dụ few-shot trong prompt, nên đặt số vòng lặp ít nhất là 2, ưu tiên từ 5–10.
Trong trường hợp prompt của bạn phức tạp, ví dụ sử dụng chain-of-thoughts, tree-of-thoughts, hướng dẫn dài trong system prompt và nhiều đầu vào trong user prompt, bạn có thể dùng một lớp task-specific để trừu tượng hóa bộ tối ưu DSPy. Lớp này giúp đóng gói logic tối ưu, chuẩn hóa cấu trúc prompt và các tham số tối ưu, đồng thời cho phép triển khai dễ dàng các chiến lược tối ưu hóa khác nhau. Dưới đây là ví dụ về lớp được tạo cho tác vụ phân loại văn bản :
class Classification(dspy.Signature):
""" You are a product search expert evaluating the quality of specific search results and deciding will that lead to a buying decision or not. You will be given a search query and the resulting product information and will classify the result against a provided classification class. Follow the given instructions to classify the search query using the classification scheme
Class Categories:
Class Label:
Category Label: Positive Search
The class is chosen when the search query and the product are a full match and hence the customer experience is positive
Category Label: Negative Search
The class is chosen when the search query and the product are fully misaligned, meaning you searched for something but the output is completely different
Category Label: Moderate Search
The class is chosen when the search query and the product may not be fully same, but still are complementing each other and maybe of similar category
"""
search_query = dspy.InputField(desc="Search Query consisting of keywords")
result_product_title = dspy.InputField(desc="This is part of Product Description and indicates the Title of the product")
result_product_description = dspy.InputField(desc="This is part of Product Description and indicates the description of the product")
…
thinking = dspy.OutputField(desc="justification in the scratchpad, explaining the reasoning behind the classification choice and highlighting key factors that led to the decision")
answer = dspy.OutputField(desc="final classification label for the product result: positive_search/negative_search/moderate_search. ")
""" Instructions:
Begin by creating a scratchpad where you can jot down your initial thoughts, observations, and any pertinent information related to the search query and product. This section is for your personal use and doesn't require a formal structure.
Proceed to examine and dissect the search query. Pinpoint essential terms, brand names, model numbers, and specifications. Assess the user's probable objective based on the query.
Subsequently, juxtapose the query with the product. Seek out precise correspondences in brand, model, and specifications. Recognize commonalities in functionality, purpose, or features. Reflect on how the product connects to or augments the item being queried.
Afterwards, employ a methodical classification approach, contemplating each step carefully
Conclude by verifying the classification. Scrutinize the selected category in relation to its description to confirm its precision. Take into account any exceptional circumstances or possible uncertainties.
"""Kết luận
Trong bài viết này, chúng tôi đã giới thiệu quy trình và kiến trúc để bạn có thể di chuyển các workload AI sinh tạo hiện tại sang các mô hình Amazon Nova, đồng thời trình bày một phương pháp tối ưu hóa prompt toàn diện bằng cách kết hợp Amazon Bedrock prompt optimization và phương pháp tối ưu hóa prompt dựa trên dữ liệu (data-aware) với DSPy.Kết quả trên ba tác vụ LLM đã minh chứng hiệu suất được tối ưu hóa của Amazon Nova trong các lớp trí tuệ của nó, với hiệu suất mô hình được cải thiện nhờ Amazon Bedrock prompt optimization sau khi di chuyển, và tiếp tục được nâng cao hơn nữa bằng phương pháp tối ưu hóa prompt dựa trên dữ liệu được trình bày trong bài viết này.
Thư viện Python và các ví dụ mã nguồn đều được công khai trên GitHub. Bạn có thể sử dụng phương pháp di chuyển LLM và giải pháp tối ưu hóa prompt này để di chuyển các workload của mình sang Amazon Nova, hoặc áp dụng trong các quy trình di chuyển mô hình khác.
Về các Tác giả

Yunfei Bai là Kiến trúc sư Giải pháp Chính (Principal Solutions Architect) tại AWS. Với nền tảng về AI/ML, khoa học dữ liệu và phân tích, Yunfei hỗ trợ khách hàng áp dụng các dịch vụ AWS để đạt được kết quả kinh doanh. Anh thiết kế các giải pháp AI/ML và phân tích dữ liệu nhằm vượt qua những thách thức kỹ thuật phức tạp và thúc đẩy các mục tiêu chiến lược. Yunfei có bằng Tiến sĩ (PhD) về Kỹ thuật Điện tử và Điện. Ngoài công việc, Yunfei thích đọc sách và nghe nhạc.

Anupam Dewan là Kiến trúc sư Giải pháp Cấp cao (Senior Solutions Architect) với niềm đam mê về AI sinh tạo (generative AI) và các ứng dụng thực tiễn của nó. Anh cùng nhóm của mình hỗ trợ các Amazon Builders phát triển các ứng dụng hướng tới khách hàng sử dụng AI sinh tạo. Anupam sống ở khu vực Seattle, và ngoài công việc, anh thích đi bộ đường dài (hiking) và tận hưởng thiên nhiên.

Shuai Wang là Nhà Khoa học Ứng dụng Cấp cao (Senior Applied Scientist) kiêm Quản lý tại Amazon Bedrock, chuyên về xử lý ngôn ngữ tự nhiên (NLP), học máy (machine learning), mô hình ngôn ngữ lớn (LLM) và các lĩnh vực AI liên quan khác. Ngoài công việc, anh thích thể thao, đặc biệt là bóng rổ, và các hoạt động cùng gia đình.

Kashif Imran là một nhà lãnh đạo giàu kinh nghiệm về kỹ thuật và sản phẩm, với chuyên môn sâu về AI/ML, kiến trúc đám mây và các hệ thống phân tán quy mô lớn. Hiện là Quản lý Cấp cao (Senior Manager) tại AWS, Kashif dẫn dắt các nhóm thúc đẩy đổi mới trong AI sinh tạo và Cloud, hợp tác với các khách hàng chiến lược để chuyển đổi doanh nghiệp của họ. Kashif có hai bằng thạc sĩ về Khoa học Máy tính (Computer Science) và Viễn thông (Telecommunications), và chuyên về chuyển đổi các khả năng kỹ thuật phức tạp thành giá trị kinh doanh có thể đo lường cho các doanh nghiệp.
