Bởi Nameet Dutia và Dr. Jennifer Andreoli-Fang, 27 FEB 2025
Thể loại: Amazon Bedrock, Amazon Bedrock Guardrails, AWS Identity and Access Management (IAM), AWS Lambda, Industries, Telecommunications
Giới thiệu
Data Over Cable Service Interface Specification (DOCSIS®) là tiêu chuẩn công nghệ quan trọng trong các mạng băng thông rộng cáp hiện đại, cho phép các nhà cung cấp dịch vụ cáp cung cấp internet tốc độ cao, thoại và dịch vụ video IP qua hạ tầng hybrid fiber-coaxial (HFC) hiện có. Được xuất bản bởi CableLabs, công nghệ DOCSIS hỗ trợ hàng trăm triệu khách hàng băng thông rộng dân dụng và doanh nghiệp trên toàn cầu. Mạng DOCSIS cũng đóng vai trò trong việc truyền dẫn dữ liệu di động (mobile backhaul) và triển khai Wi-Fi công cộng, mở rộng phạm vi và tầm quan trọng của nó trong ngành viễn thông.
Khi nhu cầu băng thông tăng mạnh với các ứng dụng như thực tế tăng cường (AR), game đám mây (cloud gaming) và video 8K, các nhà khai thác cần mở rộng dung lượng mạng đồng thời duy trì chất lượng dịch vụ. Mặc dù DOCSIS 4.0 hứa hẹn dung lượng downstream lên tới 10 Gbps, việc nâng cấp hạ tầng HFC và quản lý mạng dự kiến sẽ thúc đẩy hiệu năng cao hơn nữa. Khi các Multiple Service Operators (MSO) muốn tiến tới mạng DOCSIS 4.0 và xa hơn, trí tuệ nhân tạo (AI) được coi là thành phần quan trọng để cải thiện kết nối, hiệu suất mạng và hỗ trợ vận hành.
Bài viết này phác thảo một khung thực tiễn để tích hợp generative AI vào vận hành DOCSIS 4.0 sử dụng các dịch vụ AWS. Việc dùng Amazon Bedrock với các mô hình nền tảng (Foundation Models – FMs) hiện đại như Amazon Nova giúp MSO tối ưu quản lý mạng DOCSIS 4.0 đồng thời nâng cao khả năng quan sát và hiệu quả mạng. Mặc dù nhiều trường hợp sử dụng AI có thể áp dụng trong vận hành mạng DOCSIS, bài viết tập trung vào các yếu tố kiến trúc chính của generative AI, bao gồm: nâng cao Knowledge Base hoặc Retrieval Augmented Generation (RAG) thông qua chiến lược chunking tiên tiến, phát triển trí thông minh Agentic có khả năng suy luận và thực hiện hành động thông qua công cụ, và thực hành Responsible AI với các kiểm soát bảo mật và quản trị vững chắc.
Bối cảnh DOCSIS 4.0 và thách thức của MSO
Khi ngành cáp tăng tốc triển khai mạng DOCSIS 4.0, việc áp dụng tiêu chuẩn mới đặt ra nhiều thách thức đa chiều về con người, quy trình và công nghệ. MSO phải đối mặt với các quyết định phức tạp về dự báo dung lượng, bảo trì liên tục, khắc phục sự cố giữa mạng truy cập và lõi mạng, đồng thời không ngừng cải thiện trải nghiệm khách hàng cuối.
Lập kế hoạch dung lượng mạng bao gồm quyết định thời điểm tách node, phân bổ phổ tần và cân bằng băng thông upstream/downstream. Nhóm kỹ sư cần xử lý lượng lớn tài liệu phân mảnh như tiêu chuẩn ngành, hướng dẫn vận hành thiết bị của nhà cung cấp và hướng dẫn nội bộ; trích xuất thông tin; và áp dụng chuyên môn kỹ thuật để đưa ra quyết định dự đoán. Các Trung tâm vận hành mạng (NOC) quản lý lượng lớn dữ liệu đo lường, cảnh báo và hiệu suất, đòi hỏi chẩn đoán bất thường nhanh chóng.
Việc phát triển virtual cable modem termination system (vCMTS) sẽ tăng cường khối lượng dữ liệu đo lường với luồng dữ liệu liên tục chỉ vài giây một lần, so với việc polling truyền thống qua Simple Network Management Protocol (SNMP) có thể cách nhau 15–30 phút. Không phải tất cả kỹ sư NOC đều có kiến thức sâu về DOCSIS 4.0. Việc tìm kiếm quy trình khắc phục sự cố có thể làm chậm việc áp dụng và cản trở hỗ trợ liên tục. Các thử nghiệm mẫu của chúng tôi cho thấy, việc sử dụng các mô hình ngôn ngữ lớn (LLM) phổ biến đôi khi cho kết quả không đáng tin cậy, nhầm lẫn giữa tiêu chuẩn châu Âu và Bắc Mỹ, dẫn đến hướng dẫn mâu thuẫn hoặc sai lệch.
Khung Generative AI cho trí tuệ DOCSIS
Generative AI cung cấp cho các MSO một nền tảng để tối ưu hóa việc lập kế hoạch DOCSIS, tăng tốc quá trình khắc phục sự cố và phổ cập kiến thức chuyên môn trong lĩnh vực này. Trong bài viết này, chúng tôi sẽ trình bày ba khái niệm nền tảng: bắt đầu bằng việc cải thiện knowledge base của generative AI, xây dựng các AI Agents và sử dụng các Agents để kết hợp RAG Agentic cùng việc sử dụng công cụ, và thiết lập các guardrails cho Responsible AI. Chúng tôi tin rằng ba lĩnh vực này là nền tảng để xây dựng một nền tảng vận hành DOCSIS mạnh mẽ dựa trên generative AI.
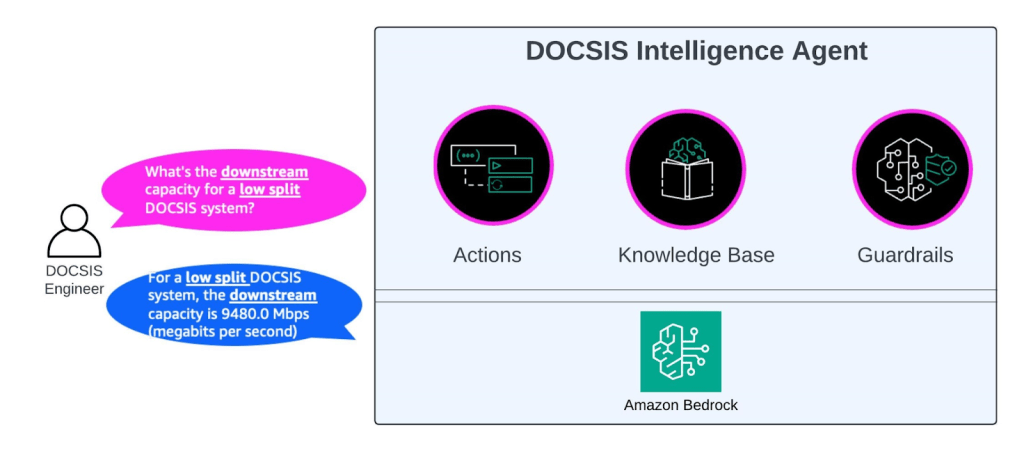
Hình 1: DOCSIS Intelligence – một khái niệm Agentic cấp cao
Knowledge bases
Hầu hết các MSO có thể đã thử nghiệm với các prototype proof of concept (POC) về tìm kiếm kiến thức sử dụng một số dạng mô hình RAG. Một trong những ứng dụng trực tiếp của generative AI là xây dựng các trợ lý thông minh để tham khảo các tài nguyên chuyên ngành, chẳng hạn như các đặc tả DOCSIS của CableLabs, các whitepaper và các hướng dẫn kỹ thuật nội bộ. Nhờ được hỗ trợ bởi Amazon Bedrock, các MSO có thể nhanh chóng mở rộng các trợ lý prototype lên môi trường sản xuất để thực hiện các tác vụ truy xuất và tóm tắt thông tin, cũng như Q&A, ví dụ như xác định thời điểm tách node, phân bổ kênh và băng thông, diễn giải các chỉ số chất lượng tín hiệu, hoặc thu thập các yêu cầu bảo mật đối với Cable Modem và CMTS. Khi một số dự án POC đã bao quát các khả năng RAG cơ bản, chúng tôi chỉ nhấn mạnh các yếu tố chính của RAG đã nổi lên như những điểm khác biệt trong thử nghiệm của chúng tôi.
Ngoài dữ liệu, ba yếu tố nổi bật trong quá trình thực hiện là: triển khai tiền xử lý dữ liệu, chọn (và lặp lại) chiến lược chunking phù hợp, và thiết lập các guardrail cho quản trị (trình bày trong phần sau của bài viết này).
Data preprocessing
Chúng tôi nhận thấy phần lớn các đặc tả DOCSIS 4.0 và các nguồn dữ liệu liên quan trong knowledge base đều có header và footer riêng biệt trên mỗi trang. Thông tin bổ sung này, mặc dù có vẻ vô hại, đôi khi dẫn đến việc làm nhiễu bối cảnh tìm kiếm. Việc loại bỏ thông tin header/footer thừa nhấn mạnh tầm quan trọng của các bước tiền xử lý dữ liệu nhỏ, góp phần cải thiện kết quả chất lượng. Tuy nhiên, tiền xử lý dữ liệu không chỉ dừng lại ở việc loại bỏ header và footer; nó đòi hỏi một phương pháp linh hoạt, được điều chỉnh theo đặc thù riêng của từng nguồn dữ liệu.
Chunking strategy
Vì hầu hết các tài liệu đều dài, việc chunking là rất quan trọng để chia nhỏ tài liệu thành các phần nhỏ, dễ quản lý, phù hợp với cửa sổ ngữ cảnh. Chia đầu vào thành các chunk nhỏ giúp hệ thống generative AI xử lý thông tin hiệu quả và nhanh hơn. Chunking phá vỡ văn bản thành các phân đoạn nhỏ trước khi nhúng vào nguồn kiến thức của bạn. Điều này quan trọng để đảm bảo rằng bạn chỉ truy xuất nội dung thực sự liên quan đến truy vấn, giảm nhiễu, cải thiện tốc độ truy xuất, và mang đến bối cảnh phù hợp hơn như một phần của quá trình truy xuất trong RAG. Lĩnh vực, nội dung, mẫu truy vấn và hạn chế của LLM ảnh hưởng mạnh đến kích thước và phương pháp chunk lý tưởng.
Trong trường hợp của chúng tôi, với các đặc tả kỹ thuật DOCSIS 4.0, chúng tôi đã thử nghiệm bốn phương pháp chunking khác nhau do Amazon Bedrock Knowledge Bases cung cấp. Mỗi phương pháp mang lại những ưu điểm và hạn chế riêng trong việc xử lý nội dung kỹ thuật phức tạp, các đặc tả chi tiết, các mối quan hệ tinh vi trong tài liệu DOCSIS và các yếu tố chi phí.
Fixed-size chunking là phương pháp đơn giản nhất để phân đoạn tài liệu, trong đó nội dung được chia thành các chunk có kích thước cố định đo bằng token (ví dụ, 512 token mỗi chunk đối với mô hình Cohere Embed English v3). Phương pháp này bao gồm một tỷ lệ chồng lắp giữa các chunk để duy trì sự liên tục. Mặc dù có ưu điểm về kích thước chunk dự đoán được (và do đó chi phí cũng dự đoán được), nhược điểm chính là nó có thể chia nội dung giữa câu hoặc tách rời thông tin liên quan. Fixed-size chunking đặc biệt hữu ích nếu dữ liệu tương đối đồng nhất về độ dài và cấu trúc, với nhận thức ngữ cảnh hạn chế và ưu tiên chi phí thấp.
Default chunking chia nội dung thành các chunk khoảng 300 token đồng thời tôn trọng ranh giới câu. Phương pháp này tự động đảm bảo câu được giữ nguyên, giúp xử lý văn bản tự nhiên hơn. Nó không cần cấu hình đặc biệt và cung cấp sự cân bằng tốt giữa tính đơn giản và tính toàn vẹn của nội dung. Tuy nhiên, nó hạn chế kiểm soát kích thước chunk và bảo toàn bối cảnh. Phương pháp này phù hợp với xử lý văn bản cơ bản, nơi việc duy trì câu đầy đủ là quan trọng nhưng các mối quan hệ nội dung phức tạp không quá thiết yếu.
Hierarchical chunking tạo ra một phương pháp có cấu trúc bằng cách thiết lập mối quan hệ cha-con trong nội dung. Trong quá trình truy xuất, hệ thống ban đầu lấy các chunk con, nhưng thay thế chúng bằng các chunk cha rộng hơn để cung cấp bối cảnh toàn diện hơn cho mô hình. Ví dụ, trong đặc tả DOCSIS 4.0 Physical Layer Specification, một chunk cha có thể chứa các phần rộng hơn của mục “7.2.4.12 FDX Fidelity Requirements”. Các chunk con sẽ chia nhỏ các mục phụ cụ thể như Power Requirements, Table References, và Technical Parameters. Nếu câu hỏi liên quan đến Power requirements, thì tìm kiếm trên các embedding chunk con nhỏ sẽ chính xác và nhanh hơn. Sau đó, các chunk con được thay thế bằng embedding chunk cha rộng hơn để truy xuất bối cảnh toàn diện, kết nối Power requirements với Full Duplex (FDX) Fidelity requirements. Phương pháp này xuất sắc trong việc duy trì cấu trúc tài liệu và bảo toàn các mối quan hệ ngữ cảnh giữa các cấp thông tin khác nhau. Nó hoạt động tốt nhất với nội dung có cấu trúc rõ ràng, đặc biệt hữu ích cho tài liệu kỹ thuật để duy trì các mối quan hệ phân cấp và tăng tốc độ truy xuất bối cảnh liên quan.
Semantic chunking chia văn bản dựa trên ý nghĩa và các mối quan hệ ngữ cảnh. Nó sử dụng một bộ đệm để cân nhắc văn bản xung quanh nhằm duy trì bối cảnh. Phương pháp này dùng ba tham số chính: số token tối đa mỗi chunk, kích thước bộ đệm cho các câu xung quanh, và ngưỡng phần trăm để xác định ranh giới chunk. Phương pháp này đặc biệt mạnh mẽ trong việc duy trì các mối quan hệ dựa trên ý nghĩa trong nội dung phi cấu trúc, giúp các khái niệm liên quan vẫn gắn kết ngay cả khi xuất hiện ở các vị trí khác nhau, ví dụ như trong dữ liệu hội thoại. Mặc dù phương pháp này đòi hỏi nhiều tài nguyên tính toán hơn và chi phí bổ sung cho việc sử dụng FM để xử lý ngữ nghĩa, nó nổi bật trong việc duy trì tính nhất quán của các khái niệm liên quan và các mối quan hệ của chúng. Chúng tôi nhận thấy phương pháp này phù hợp hơn với các tình huống có nội dung ngôn ngữ tự nhiên trong knowledge base, ví dụ như bản ghi hội thoại giữa nhân viên trung tâm cuộc gọi và khách hàng băng thông rộng, nơi các thông tin liên quan bị phân tán trong văn bản.
Do tính chất có tổ chức sẵn của tài liệu DOCSIS, với các mục, tiểu mục và mối quan hệ cha-con rõ ràng giữa các khái niệm kỹ thuật, chúng tôi thấy rằng Hierarchical chunking là phương pháp phù hợp nhất cho trường hợp sử dụng của chúng tôi. Khả năng của phương pháp này trong việc giữ các đặc tả kỹ thuật liên quan cùng nhau đồng thời bảo toàn mối quan hệ với các phần rộng hơn tỏ ra đặc biệt giá trị để điều hướng và hiểu các đặc tả DOCSIS 4.0 phức tạp. Một lưu ý là các chunk cha rộng hơn đồng nghĩa với việc nhiều token đầu vào hơn và do đó chi phí cao hơn. Mặc dù khó đưa ra hướng dẫn áp dụng chung cho mọi dữ liệu, chúng tôi khuyến nghị thực hiện xác thực sâu hơn cho dữ liệu của bạn với các công cụ như đánh giá RAG và LLM-as-a-judge, hiện đã có sẵn (dưới dạng preview từ tháng 12/2024) trong Amazon Bedrock.Hình 2 minh họa một biểu diễn đơn giản về các chiến lược chunking trong Amazon Bedrock.
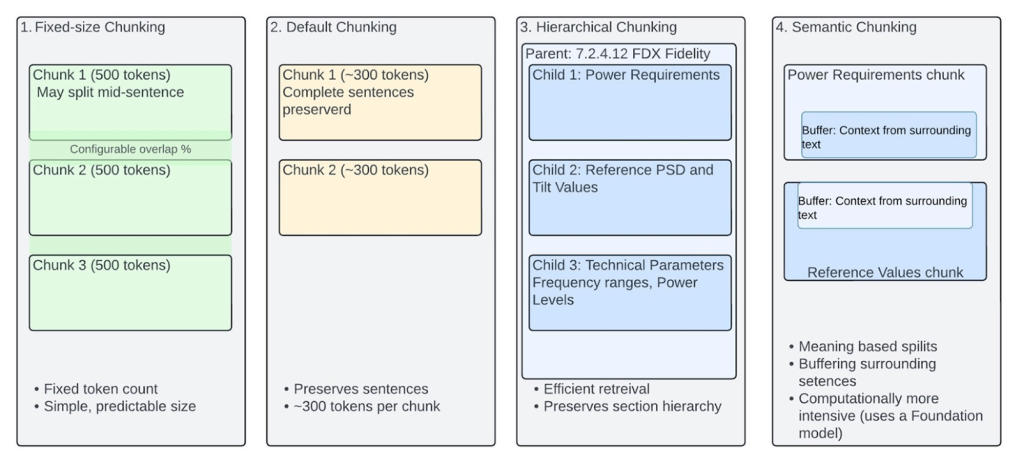
Hình 2: Biểu diễn đơn giản so sánh các phương pháp phân đoạn được áp dụng cho Thông số kỹ thuật DOCSIS 4.0
Trong các bài viết sau, chúng tôi sẽ trình bày thêm các khái niệm RAG nâng cao áp dụng cho giai đoạn Pre-retrieval (viết lại truy vấn, mở rộng truy vấn) và Post-retrieval (sắp xếp lại kết quả). Chúng tôi cũng sẽ giới thiệu các ứng dụng nâng cao với Structured Data Retrieval và Graph RAG, giúp khám phá các mối quan hệ trong dữ liệu telemetry mạng.
AI Agents
Peter Norvig và Stuart Russell trong tài liệu tham khảo uy tín về AI “Artificial Intelligence: A Modern Approach” định nghĩa agent là một thực thể nhân tạo có khả năng nhận biết môi trường xung quanh thông qua các cảm biến, đưa ra quyết định và sau đó thực hiện các hành động phản hồi bằng các bộ truyền động (actuator).
Đối với DOCSIS 4.0 Intelligence framework của chúng tôi, khái niệm AI Agent được điều chỉnh thành một thực thể thông minh tự chủ toàn diện. Khung Agentic có khả năng lập kế hoạch, suy luận và hành động, đồng thời truy cập vào knowledge base DOCSIS được quản lý và các guardrail để đảm bảo việc điều phối thông minh.
Trong phần tiếp theo, chúng tôi sẽ trình bày các bước để xây dựng một agent mẫu giúp các kỹ sư tính toán capacity mạng DOCSIS.
DOCSIS AI Agents: lý do
Chúng tôi nhận thấy rằng việc sử dụng zero-shot chain-of-thought prompting trên một LLM để trả lời các câu hỏi chuyên môn, chẳng hạn như tính toán capacity mạng DOCSIS, dẫn đến kết quả không chính xác. Thú vị là, khi dùng zero-shot prompting trên Mistral Large 24.07, kết quả mặc định theo chuẩn DOCSIS châu Âu (Hình 3.1), trong khi trên Anthropic Sonnet 3.5 v2 lại mặc định theo chuẩn DOCSIS Mỹ (Hình 3.2).

Hình 3.1: Đầu ra với Mistral Large 24.07

Hình 3.2: Đầu ra với Claude Sonnet 3.5 v2
Để tính toán chính xác năng lực DOCSIS 4.0 với kết quả xác định, chúng tôi trình bày cách xây dựng một tác nhân AI DOCSIS.

Hình 4: Cấu hình thời gian xây dựng cho DOCSIS Agent của chúng tôi
Hình 4 cho thấy các khối xây dựng của thiết kế AI Agent dựa trên Amazon Bedrock Agent. Một Agent được hỗ trợ bởi LLM (các LLM) và bao gồm các Nhóm Hành động, Cơ sở Kiến thức và Hướng dẫn (Prompts). Agent xác định các hành động cần thực hiện dựa trên thông tin đầu vào của người dùng và phản hồi lại bằng câu trả lời phù hợp với câu hỏi được hỏi.
Cấu hình khi xây dựng (Build-time configuration)
- Foundation model: Bước đầu tiên là chọn một FM (foundation model) mà agent sẽ sử dụng để diễn giải đầu vào từ người dùng và các prompt tiếp theo trong quá trình điều phối. Agent cũng sẽ sử dụng FM này để tạo phản hồi và các bước tiếp theo trong quy trình của nó. Chúng tôi đã chọn Amazon Nova Pro 1.0 từ danh sách rộng các FM tiên tiến có sẵn trên Amazon Bedrock.
Ví dụ hướng dẫn cho Agent (Prompt)
Bước tiếp theo là viết các hướng dẫn rõ ràng mô tả agent được thiết kế để làm gì. Các prompt nâng cao cho phép bạn tùy chỉnh hướng dẫn cho agent ở mỗi bước trong quá trình điều phối và có thể bao gồm các hàm AWS Lambda để phân tích đầu ra của từng bước.
Dưới đây là một ví dụ về prompt hướng dẫn cho LLM Agent của chúng tôi, chuyên về DOCSIS 4.0, với một công cụ cụ thể mà agent có thể sử dụng trong thời gian chạy. Các hướng dẫn này định hướng cho agent biết nó nên làm gì và cách tương tác với người dùng.

Hình 5.1: Một hướng dẫn mẫu của AI Agent (Prompt)
Một đoạn trích ngắn để bạn tham khảo (lời nhắc thực tế phức tạp hơn một chút và có thể thay đổi tùy theo FM đã chọn):

Hình 5.2: Đoạn mã nhắc nhở của AI Agent
Action groups
Action groups được tạo thành từ nhiều Actions. Actions là các công cụ thực hiện một logic nghiệp vụ cụ thể. Trong ví dụ của chúng tôi, chúng tôi viết một hàm Lambda xác định (deterministic) nhận một tập hợp các tham số đầu vào từ người dùng cuối và thực hiện phép tính dựa trên một công thức mẫu để tính capacity DOCSIS 4.0.

Hình 6.1: Nhóm hành động của Amazon Bedrock Agent
Chúng tôi khuyên bạn nên sử dụng tùy chọn Tạo nhanh hàm Lambda mới để tạo các đối tượng phản hồi yêu cầu mẫu trong mã Lambda và các quyền AWS Identity and Access Management (IAM) cần thiết cho dịch vụ Amazon Bedrock để gọi hàm Lambda.
Chi tiết hàm hoặc sơ đồ API (Function details or API schema)
Tiếp theo, chúng tôi xác định Function Details (hoặc sử dụng sơ đồ API tương thích Open API 3.0). Trong ví dụ của chúng tôi, frequency_plan được đánh dấu là tham số bắt buộc, trong khi downstream và upstream được chỉ định là các tham số tùy chọn. Nếu các tham số tùy chọn downstream và upstream không được cung cấp, thì mã Lambda sẽ tính toán capacity cho cả hai trường hợp.
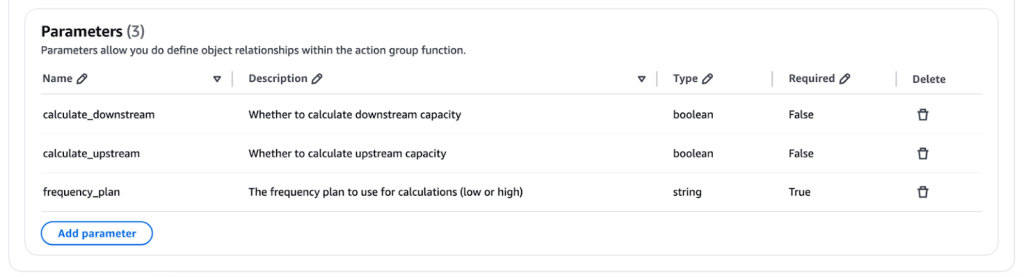
Hình 6.2: Sơ đồ API
Lambda function
Dưới đây là một đoạn mã Lambda mẫu thực hiện logic để tính capacity DOCSIS 4.0 dựa trên các tham số đầu vào.

Hình 6.3: Đoạn mã Lambda – calc-docsis-capacity-nova
Runtime process
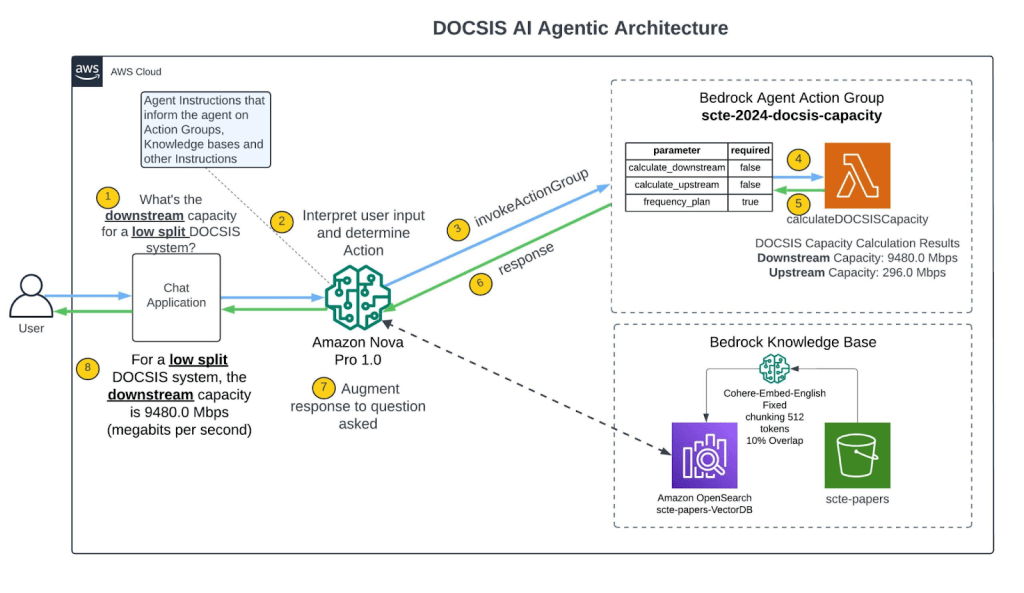
Hình 7: Kiến trúc tham chiếu DOCSIS AI Agentic
Runtime của AI Agent được quản lý bởi Invoke Agent API operation. Hoạt động này khởi động chuỗi tác vụ của agent, bao gồm ba bước chính: 1/ Pre-processing, 2/ Orchestration, và 3/ Post-processing. Để ngắn gọn, trong phần sau chúng tôi chỉ trình bày các bước Orchestration (được chú thích bằng số trong Hình 7).
Bước orchestration thực hiện các chức năng sau: thu thập đầu vào từ người dùng (bước 1), diễn giải và suy luận (bước 2), gọi các action group (bước 3), xử lý các kết quả trung gian (bước 4, 5, 6), và trả kết quả cho người dùng (bước 7 và 8). Mỗi bước được mô tả chi tiết như sau:
- Người dùng được ủy quyền khởi động AI Assistant thông qua chat hoặc giao diện khác.
- AI Agent diễn giải đầu vào với một FM (Amazon Nova Pro 1.0) và tạo ra rationale mô tả logic cho bước tiếp theo mà agent cần thực hiện.
- Agent xác định Action Group phù hợp dựa trên rationale hoặc knowledge base truy vấn.
- Nếu agent dự đoán rằng cần thực hiện một action, agent sẽ gửi các tham số, được xác định từ prompt của người dùng, đến Lambda function được cấu hình cho action group, hoặc trả quyền điều khiển bằng cách gửi các tham số trong phản hồi của InvokeAgent. Hình 7.1 minh họa rationale có sẵn dưới dạng trace trong Amazon Bedrock console.

Hình 7.1: Cơ sở lý luận của tác nhân từ dấu vết
Agent cũng có thể truy vấn một knowledge base. Tuy nhiên, trong trường hợp của chúng tôi, agent sử dụng công cụ calc-docsis-capacity-nova (hàm Lambda) để trả lời câu hỏi của người dùng.
- Lambda function trả về phản hồi cho Agent API gọi hàm.
- Agent tạo ra một output, được gọi là observation, từ việc gọi action và/hoặc tóm tắt kết quả từ knowledge base.

Hình 7.2: Hành động của tác nhân quan sát đầu ra từ dấu vết
- Agent sử dụng observation để bổ sung vào base prompt, sau đó một lần nữa được diễn giải bằng FM (Amazon Nova Pro 1.0). Sau đó, agent xác định xem có cần lặp lại quá trình orchestration hay không. Vòng lặp này tiếp tục cho đến khi agent trả về phản hồi cho người dùng hoặc cần yêu cầu thêm thông tin từ người dùng.
- Trong quá trình orchestration, base prompt template được bổ sung với các agent instructions, action groups, và knowledge bases mà bạn đã thêm vào agent. Sau đó, augmented base prompt được sử dụng để gọi FM. FM dự đoán các bước và lộ trình tối ưu để thực hiện đầu vào của người dùng. Ở mỗi vòng lặp orchestration, FM dự đoán API operation cần gọi hoặc knowledge base cần truy vấn.

Hình 7.3: Cơ sở lý luận của tác nhân và phản hồi cuối cùng từ dấu vết
Kết quả
Việc triển khai các bước nêu trên đã cho phép chúng tôi có DOCSIS AI Agent đầu tiên, được hỗ trợ bởi Amazon Nova Pro 1.0, có khả năng gọi công cụ để tính toán DOCSIS capacity dựa trên công thức đã định nghĩa. Trong thực tế, có nhiều agent cùng hoạt động phối hợp trên các nhiệm vụ phức tạp nhiều bước và các Knowledge Bases. Chúng tôi sẽ đề cập đến Amazon Bedrock Multi-agent collaboration (phiên bản xem trước từ tháng 12/2024) trong một bài viết sau.

Hình 7.4: Phản hồi cuối cùng của Agent gửi lại cho người dùng
Guardrails cho quản trị và Trí tuệ nhân tạo có trách nhiệm
Là một phần trong chiến lược AI có trách nhiệm (Responsible AI), chúng tôi khuyến khích mạnh mẽ việc triển khai các biện pháp bảo vệ ngay từ đầu. Để mang lại trải nghiệm phù hợp và an toàn cho người dùng, đồng thời tuân thủ các chính sách và nguyên tắc của tổ chức MSO, bạn có thể sử dụng Amazon Bedrock Guardrails.
Bedrock Guardrails cho phép bạn:
- Xác định các chính sách để đánh giá đầu vào từ người dùng
- Thực hiện đánh giá độc lập với mô hình bằng các kiểm tra contextual grounding
- Chặn các chủ đề bị từ chối bằng bộ lọc nội dung phù hợp
- Chặn hoặc ẩn thông tin nhạy cảm (PII)
- Đảm bảo các phản hồi tuân thủ chính sách đã cấu hình
Ví dụ: bạn muốn ngăn một nhân viên tổng đài tuyến đầu sử dụng ứng dụng RAG để tìm kiếm quy trình có thể thao túng cấu hình mạng nhạy cảm. Hãy xem xét một tình huống giả định: một kỹ sư hỗ trợ mới vào muốn tắt lọc MAC trên modem của thuê bao để xử lý sự cố internet. Một prompt zero-shot gửi tới LLM có thể như sau:

Hình 8.1: Prompt zero-shot tới LLM tạo ra phản hồi có thể làm lộ rủi ro bảo mật của thuê bao băng rộng
Việc tắt tính năng lọc địa chỉ MAC có thể gây ra truy cập mạng trái phép, làm ảnh hưởng đến bảo mật. Ví dụ sau minh họa một Guardrail trong Amazon Bedrock được cấu hình để từ chối các thay đổi nhạy cảm như thao túng địa chỉ MAC và trả lại thông điệp cảnh báo đã cấu hình cho người dùng.

Hình 8.2: Bộ lọc chủ đề bị từ chối của Amazon Bedrock Guardrails
Một ví dụ khác mô tả bộ lọc thông tin nhạy cảm trong Guardrails. Giả sử người dùng vô tình nhập địa chỉ MAC (PII) vào cửa sổ chat và không có Guardrails nào được cấu hình. Khi đó, LLM có thể phản hồi như sau:

Hình 8.3: Prompt zero-shot chứa PII (địa chỉ MAC)
Mặc dù LLM nhận ra đây là thông tin nhạy cảm, nhưng prompt cần phải bị chặn trước khi đến được LLM. Dựa trên use case, bạn có thể chọn:
- Từ chối đầu vào chứa thông tin nhạy cảm
- Hoặc tự động ẩn (redact) thông tin này trong phản hồi
Ví dụ sau cho thấy Bedrock Guardrail đã nhận diện mẫu dữ liệu là địa chỉ MAC, và theo hành vi đã cấu hình, prompt bị chặn và hệ thống trả về thông báo tùy chỉnh. Bạn cũng có thể dùng Regular Expression để định nghĩa mẫu dữ liệu mà Guardrail nhận diện và xử lý.
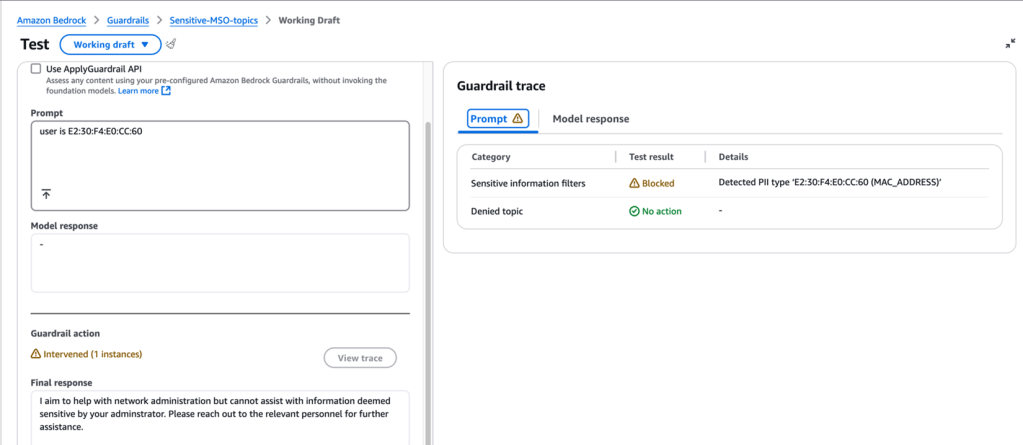
Hình 8.4: Guardrail của Amazon Bedrock phát hiện và chặn PII (địa chỉ MAC)
Với cách tiếp cận thống nhất trên các mô hình nền tảng (FM), Bedrock Guardrails mang đến khả năng bảo vệ an toàn hàng đầu trong ngành. Hai ví dụ trên mới chỉ là ứng dụng cơ bản — Guardrails còn có các tính năng nâng cao như:
- Kiểm tra contextual grounding
- Kiểm tra bằng lý luận tự động (Symbolic AI)
Những tính năng này giúp đảm bảo đầu ra phù hợp với dữ liệu đã biết, không bị bịa đặt hoặc sai lệch. Chúng tôi sẽ giới thiệu thêm về khả năng quản trị nâng cao dành cho ứng dụng generative AI trong DOCSIS 4.0 ở bài viết sau.
Kêu gọi hành động: đón nhận AI trong giai đoạn chuyển đổi DOCSIS 4.0
Sự chuyển dịch sang DOCSIS 4.0 là một bước ngoặt quan trọng đối với các nhà khai thác cáp, và AI có thể thúc đẩy mạnh mẽ quá trình này. Kinh nghiệm của chúng tôi cho thấy việc triển khai AI hiệu quả không cần các framework phức tạp hay thư viện chuyên biệt, hoàn toàn phù hợp với nguyên tắc Invent and Simplify của Amazon.
Thay vào đó, thành công đến từ cách tiếp cận trực tiếp và tiến bộ từng bước:
1. Bắt đầu đơn giản: Tăng cường các hệ thống RAG nền tảng để nâng cao năng suất nhân viên dựa trên các use case ngành và lĩnh vực.
2. Tiến xa dần: Chuyển sang mô hình Agentic, hỗ trợ ra quyết định tự động và xử lý tác vụ phức tạp.
Kết hợp knowledge base, AI agents và guardrails mạnh mẽ giúp MSO xây dựng ứng dụng AI an toàn, hiệu quả, sẵn sàng cho tương lai khi DOCSIS 4.0 và công nghệ cáp ngày càng phát triển. Ở bài viết sau, chúng tôi sẽ đề cập đến các chủ đề nâng cao như fine-tuning, continued pretraining và ứng dụng của chúng trong ngành cáp.
Kết luận
Chuyển đổi số trong ngành cáp không chỉ đang diễn ra — mà còn đang tăng tốc. Trong bối cảnh đó, việc tích hợp AI đã từ một lợi thế trở thành một yêu cầu cạnh tranh bắt buộc. Những nhà khai thác áp dụng các công nghệ này sớm sẽ có vị thế tốt hơn để:
- cung cấp chất lượng dịch vụ vượt trội
- tối ưu hiệu năng mạng
- cải thiện hiệu quả vận hành
- dẫn dắt sự phát triển của các công nghệ tương lai
Hãy cùng chúng tôi định hình tương lai của mạng băng rộng cáp — nơi AI và chuyên môn con người kết hợp để tạo nên hệ thống mạng mạnh mẽ, hiệu quả và thông minh hơn.
Tác giả
Nameet Dutia

Senior Solutions Architect – AWS Telecom Industry Business Unit
Chuyên gia về AI/ML, có 16 năm kinh nghiệm trong kỹ thuật phần mềm, hệ thống phân tán và đổi mới AI. Thạc sĩ tại Southern Methodist University – Cox School of Business Cử nhân Kỹ thuật Máy tính – University of Mumbai
Dr. Jennifer Andreoli-Fang

Lãnh đạo công nghệ với hơn 20 năm kinh nghiệm trong phát triển mạng, cloud và AI/ML. Gia nhập AWS từ 2021, hiện dẫn dắt mảng fixed networks. Nhà phát minh nữ hàng đầu ngành cáp với hơn 110 bằng sáng chế. Tiến sĩ về Machine Learning và Wireless Networks – UC San Diego.
