bởi Shiyang Wei | Ngày 20 Tháng 3 Năm 2025 | trong Advanced (300), Amazon EMR, Serverless
Khi hỗ trợ khách hàng của chúng tôi xây dựng hệ thống trên AWS, chúng tôi nhận thấy rằng một số lượng lớn khách hàng doanh nghiệp — những người chú trọng cao đến bảo mật và tuân thủ dữ liệu, chẳng hạn như các doanh nghiệp B2C FinTech — xây dựng các ứng dụng nhạy cảm với dữ liệu trên on-premises và sử dụng các ứng dụng khác trên AWS để tận dụng các dịch vụ được quản lý của AWS. Việc sử dụng các dịch vụ được quản lý của AWS có thể giúp đơn giản hóa đáng kể các hoạt động và bảo trì hàng ngày, cũng như giúp bạn đạt được tối ưu hóa việc sử dụng tài nguyên và hiệu suất.
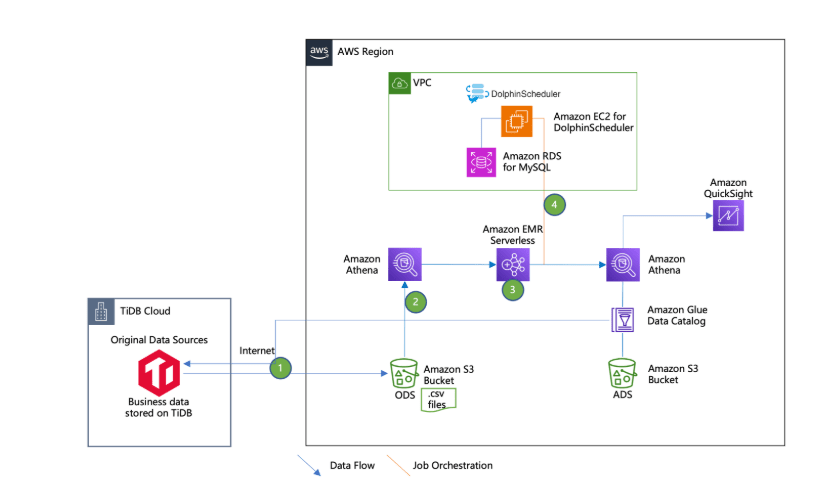
Bài viết này thảo luận về một phương pháp tách rời trong việc xây dựng một serverless data lakehouse bằng cách sử dụng các dịch vụ tập trung vào đám mây của AWS, bao gồm Amazon EMR Serverless, Amazon Athena, Amazon Simple Storage Service (Amazon S3), Apache DolphinScheduler (một open source data job scheduler), cũng như PingCAP TiDB, một sản phẩm data warehouse của bên thứ ba có thể được triển khai trên on-premises hoặc trên đám mây thông qua mô hình phần mềm dưới dạng dịch vụ (SaaS).
Tổng quan giải pháp
Trong trường hợp sử dụng của chúng tôi, một enterprise data warehouse với dữ liệu kinh doanh được lưu trữ trên nền tảng on-premises TiDB — một AWS Global Partner, đồng thời cũng có sẵn trên AWS thông qua AWS Marketplace
Dữ liệu này sau đó được xử lý bởi một Amazon EMR Serverless Job để đạt được phân tầng data lakehouse. Các tầng dữ liệu khác nhau được lưu trữ trong các S3 bucket riêng biệt hoặc các S3 prefix riêng biệt trong cùng một S3 bucket. Thông thường, có bốn tầng trong thiết kế data warehouse:
- Operational data store layer (ODS) – Tầng này lưu trữ dữ liệu thô của data warehouse.
- Data warehouse stage layer (DWS) – Tầng này là một khu vực staging tạm thời trong kiến trúc data warehousing, nơi dữ liệu từ nhiều nguồn được tải, làm sạch, chuyển đổi và chuẩn bị trước khi được đưa vào tầng cơ sở dữ liệu data warehouse.
- Data warehouse database layer (DWD) – Tầng này là kho lưu trữ trung tâm trong môi trường data warehousing, nơi dữ liệu từ nhiều nguồn được tích hợp, chuyển đổi và lưu trữ trong định dạng có cấu trúc để phục vụ mục đích phân tích.
- Analytical data store (ADS) – Tầng này là một tập con của data warehousing, được thiết kế và tối ưu hóa đặc biệt cho một chức năng kinh doanh, bộ phận hoặc mục đích phân tích cụ thể.
Trong bài viết này, chúng tôi chỉ sử dụng hai tầng ODS và ADS để minh họa tính khả thi kỹ thuật.
Lược đồ (schema) của dữ liệu này được quản lý thông qua AWS Glue Data Catalog và có thể được truy vấn bằng Athena. Các EMR Serverless Jobs được điều phối bằng Apache DolphinScheduler, được triển khai ở chế độ cluster trên các instance của Amazon Elastic Compute Cloud (Amazon EC2), với meta data được lưu trữ trong Amazon Relational Database Service (Amazon RDS) cho MySQL.
Việc sử dụng DolphinScheduler làm công cụ điều phối data lakehouse job mang lại các lợi ích sau:
- Kiến trúc phân tán cho phép khả năng mở rộng tốt hơn, và trình thiết kế visual DAG giúp việc tạo workflow trở nên trực quan hơn cho các thành viên có trình độ kỹ thuật khác nhau.
- Cung cấp khả năng kiểm soát tác vụ chi tiết hơn và hỗ trợ nhiều loại tác vụ có sẵn như Spark, Flink, và machine learning (ML) workflows mà không cần cài đặt plugin bổ sung.
- Tính năng multi-tenancy cho phép cô lập tài nguyên tốt hơn và kiểm soát truy cập trên nhiều nhóm khác nhau trong cùng một tổ chức.
Tuy nhiên, DolphinScheduler yêu cầu nhiều nỗ lực thiết lập và bảo trì ban đầu hơn, khiến nó phù hợp hơn cho các tổ chức có khả năng DevOps mạnh và mong muốn có mức độ kiểm soát cao hơn đối với hạ tầng workflow của họ.
Sơ đồ dưới đây minh họa kiến trúc của giải pháp.
Điều kiện tiên quyết
Bạn cần tạo một tài khoản AWS và thiết lập một người dùng AWS Identity and Access Management (IAM) như một điều kiện tiên quyết cho việc triển khai sau. Hoàn tất các bước sau:
Để đăng ký tài khoản AWS, vui lòng thực hiện theo các hướng dẫn trong liên kết được cung cấp.
- Tạo tài khoản AWS.
- Đăng nhập vào tài khoản bằng root user lần đầu tiên.
- Trên bảng điều khiển IAM, tạo một người dùng IAM với AdministratorAccess Policy.
- Sử dụng người dùng IAM này để đăng nhập vào AWS Management Console thay vì tài khoản root.
- Trên bảng điều khiển IAM, chọn Users trong thanh điều hướng.
- Điều hướng đến người dùng của bạn, và trong tab Security credentials, tạo một access key.
- Lưu access key và secret key ở nơi an toàn và sử dụng chúng cho truy cập API của các tài nguyên trong tài khoản AWS này.
Thiết lập DolphinScheduler, cấu hình IAM, và bảng TiDB Cloud
Trong phần này, chúng ta sẽ thực hiện các bước để cài đặt DolphinScheduler, hoàn tất cấu hình IAM bổ sung để kích hoạt EMR Serverless job, và thiết lập bảng TiDB Cloud.
Cài đặt DolphinScheduler trên một EC2 instance với RDS for MySQL instance dùng để lưu trữ metadata của DolphinScheduler. Chế độ triển khai cho môi trường production của DolphinScheduler là cluster mode. Trong bài viết này, chúng tôi sử dụng pseudo cluster mode có cùng các bước cài đặt như cluster mode, đồng thời giúp tiết kiệm tài nguyên. EC2 instance này được đặt tên là ds-pseudo.
Đảm bảo rằng inbound rule của security group được gắn với EC2 instance cho phép lưu lượng TCP qua cổng 12345 Sau đó, hoàn thành các bước sau:
1. Đăng nhập vào Amazon EC2 với quyền root user và cài đặt jvm.
sudo dnf install java-1.8.0-amazon-corretto
java -version
2. Chuyển sang dir /usr/local/src:
cd /usr/local/src3. Cài đặt Apache Zookeeper:
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz
cd apache-zookeeper-3.8.0-bin/conf
cp zoo_sample.cfg zoo.cfg
cd ..
nohup bin/zkServer.sh start-foreground &> nohup_zk.out &
bin/zkServer.sh status
4. Kiểm tra phiên bản Python:
python3 --versionPhiên bản yêu cầu 3.9 hoặc cao hơn. Khuyến nghị sử dụng Amazon Linux 2023 hoặc mới hơn làm hệ điều hành cho Amazon EC2. phiên bản Python 3.9 đáp ứng yêu cầu. Để biết thông tin chi tiết, hãy tham khảo Python trong AL2023.

5. Cài đặt DolphinScheduler
a. Tải gói cài đặt dolphinscheduler:
cd /usr/local/src
wget https://dlcdn.apache.org/dolphinscheduler/3.1.9/apache-dolphinscheduler-3.1.9-bin.tar.gz
tar -zxvf apache-dolphinscheduler-3.1.9-bin.tar.gz
mv apache-dolphinscheduler-3.1.9-bin apache-dolphinschedulerb. Tải xuống gói trình kết nối mysql:
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.31.tar.gz
tar -zxvf mysql-connector-j-8.0.31.tar.gzc. Sao chép tệp JAR của trình kết nối mysql cụ thể đến các đích sau:
cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler/api-server/libs/
cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler/alert-server/libs/
cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler/master-server/libs/
cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler/worker-server/libs/
cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler/tools/libs/d. Thêm người dùng dolphinscheduler và đảm bảo thư mục apache-dolphinscheduler và các tệp bên dưới nó thuộc sở hữu của người dùng dolphinscheduler
useradd dolphinscheduler
echo "dolphinscheduler" | passwd --stdin dolphinscheduler
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler6. Cài đặt ứng dụng mysql:
sudo dnf update -y
sudo dnf install mariadb1057. Trên bảng điều khiển Amazon RDS, cung cấp phiên bản RDS cho MySQL với các cấu hình sau:
- Đối với Database Creation Method, chọn Standard create.
- Đối với Engine options, hãy chọn MySQL.
- Đối với Edition: chọn MySQL 8.0.35.
- Đối với Templates: chọn Dev/Test.
- Đối với Availability and durability, chọn Single DB instance.
- Đối với Credentials management, hãy chọn Self-managed.
- Đối với Connectivity, chọn Connect to an EC2 compute resource và chọn phiên bản EC2 đã tạo trước đó.
- Đối với Database Authentication: chọn Password Authentication.
8. Điều hướng đến trang chi tiết cơ sở dữ liệu ds- mysql và trong Connectivity & security, sao chép endpoint RDS cho MySQL.
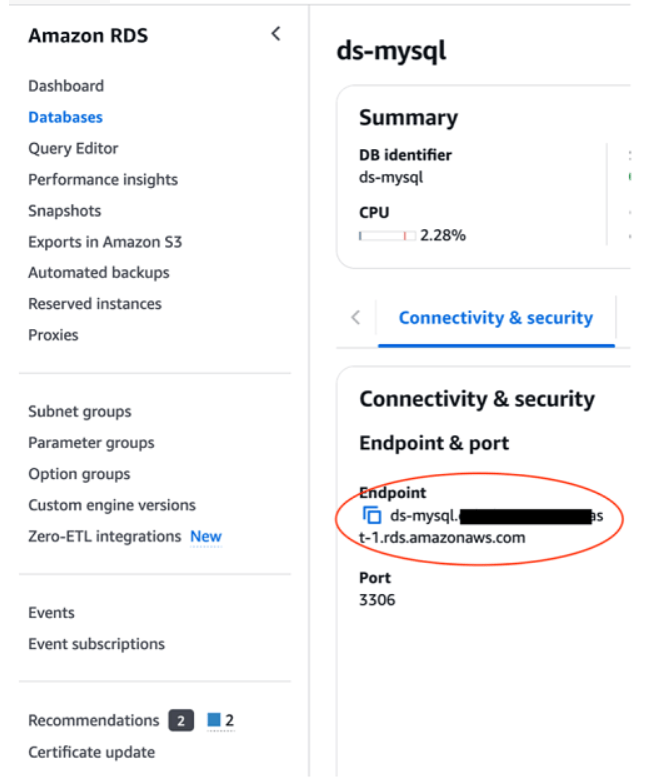
9. Cấu hình intance.
mysql -h <RDS formysql Endpoint> -u admin -p
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
mysql> exit;10. Cấu hình file dolphinscheduler
cd /usr/local/src/apache-dolphinscheduler/11. Cập nhật: dolphinscheduler_env.sh
vim bin/env/dolphinscheduler_env.sh
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://ds-mysql.cq**********.us-east-1.rds.amazonaws.com/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME="admin"
export SPRING_DATASOURCE_PASSWORD="<your password>"12. Trên bảng điều khiển Amazon EC2, điều hướng đến trang chi tiết phiên bản và sao chép địa chỉ IP riêng.
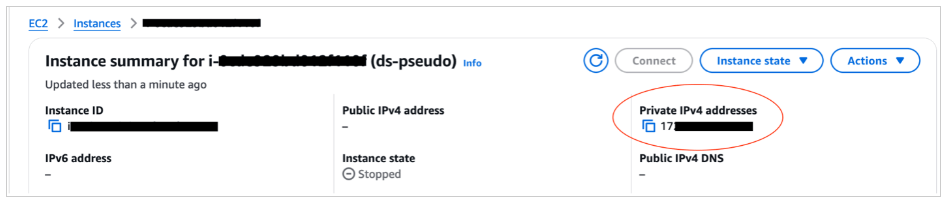
13. Cập nhật: install_env.sh
vim bin/env/install_env.sh
ips=${ips:-"<private ip address of ds-pseudo EC2 instance>"}
masters=${masters:-"<private ip address of ds-pseudo EC2 instance>"}
workers=${workers:-" private ip address of ds-pseudo EC2 instance:default"}
alertServer=${alertServer:-" private ip address of ds-pseudo EC2 instance "}
apiServers=${apiServers:-" private ip address of ds-pseudo EC2 instance "}
installPath=${installPath:-"~/dolphinscheduler"}
export JAVA_HOME=${JAVA_HOME:-/usr/lib/jvm/jre-1.8.0-openjdk}
export PYTHON_HOME=${PYTHON_HOME:-/bin/python3}14. Áp dụng cấu hình file: dolphinscheduler
cd /usr/local/src/apache-dolphinscheduler/
bash tools/bin/upgrade-schema.sh15. Cài đặt DolphinScheduler:
cd /usr/local/src/apache-dolphinscheduler/
su dolphinscheduler
bash ./bin/install.sh16. Khởi động DolphinScheduler sau khi cài đặt:
cd /usr/local/src/apache-dolphinscheduler/
su dolphinscheduler
bash ./bin/start-all.sh17. Mở bảng điều khiển DolphinScheduler:
http://<ec2 ipaddress>:12345/dolphinscheduler/ui/login
Sau khi nhập tên người dùng và mật khẩu ban đầu, nhấn nút Đăng nhập để vào bảng điều khiển được hiển thị như bên dưới.
initial user/password admin/dolphinscheduler123
Cấu hình IAM role để bật các EMR serverless job
EMR serverless job role cần có quyền truy cập vào một vùng lưu trữ S3 cụ thể để đọc các lệnh thực thi job và có khả năng ghi kết quả, đồng thời có quyền truy cập AWS Glue để đọc Data Catalog lưu trữ metadata của bảng. Để được hướng dẫn chi tiết, vui lòng tham khảo Grant permission to use EMR Serverless hoặc EMR Serverless Samples.
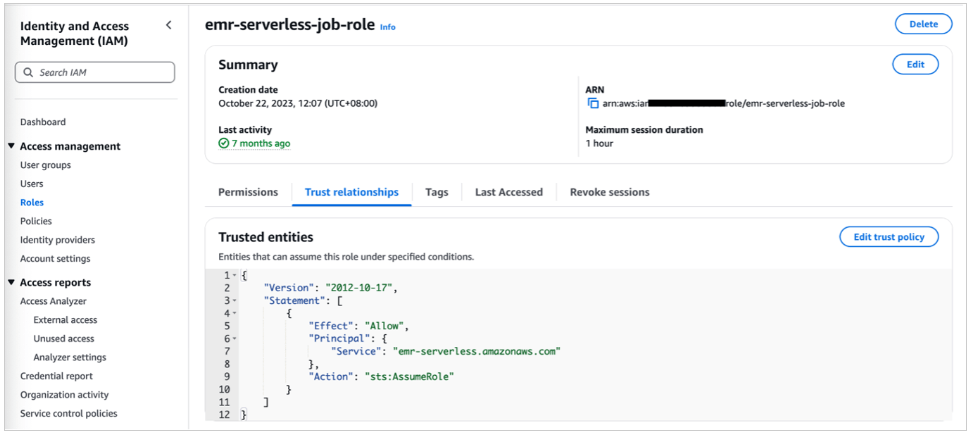
Ảnh chụp màn hình sau đây cho thấy IAM role được đặt cấu hình với trust policy được đính kèm.
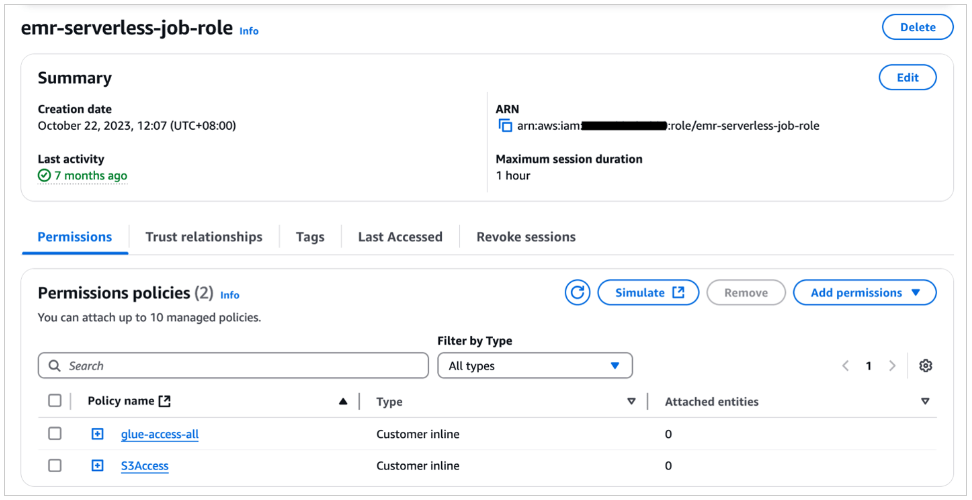
IAM role phải có các permissions policy sau được đính kèm, như minh họa trong ảnh chụp màn hình sau.
Cung cấp bảng TiDB Cloud
- Để cung cấp bảng TiDB Cloud, hãy hoàn thành các bước sau:
- Đăng ký TiDB Cloud.
- Tạo cụm phi máy chủ, như trong ảnh chụp màn hình sau. Đối với bài đăng này, chúng tôi đặt tên cho cụm. Cluster0
- Chọn Cluster0, sau đó chọn SQL Editor để tạo cơ sở dữ liệu có tên test;
create table testtable (id varchar(255));
insert into testtable values (1);
insert into testtable values (2);
insert into testtable values (3);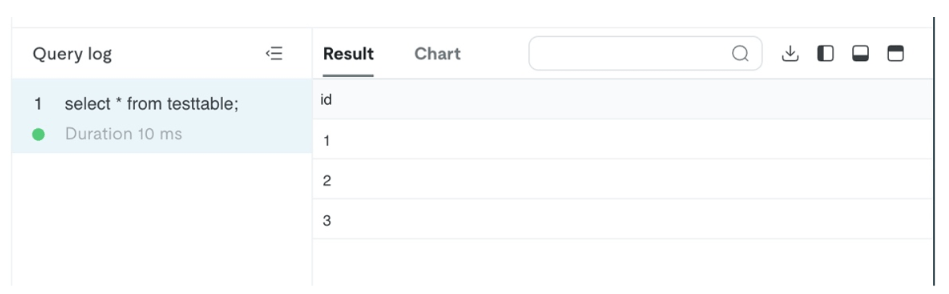
Đồng bộ hóa dữ liệu giữa TiDB và AWS
Trong phần này, chúng tôi thảo luận về cách đồng bộ hóa dữ liệu lịch sử cũng như dữ liệu gia tăng giữa TiDB và AWS.
Sử dụng TiDB Dumpling để đồng bộ hóa dữ liệu lịch sử từ TiDB sang Amazon S3
Sử dụng các lệnh trong phần này để kết xuất dữ liệu được lưu trữ trong TiDB dưới dạng tệp CSV vào vùng lưu trữ S3. Để biết chi tiết đầy đủ về cách đồng bộ hóa dữ liệu từ TiDB on-premises sang Amazon S3, hãy xem Xuất dữ liệu sang lưu trữ đám mây Amazon S3. Đối với bài đăng này, chúng tôi sử dụng công cụ TiDB tool Dumpling. Hoàn thành các bước sau:
- Đăng nhập vào phiên bản EC2 đã tạo trước đó với tư cách root.
- Chạy lệnh sau để cài đặt TiUP:
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
cd /root
source .bash_profile
tiup --version
- Chạy lệnh sau để cài đặt Dumpling:
tiup install dumpling- Chạy lệnh sau để đạt được kết xuất bảng cơ sở dữ liệu mục tiêu vào vùng lưu trữ S3 cụ thể.
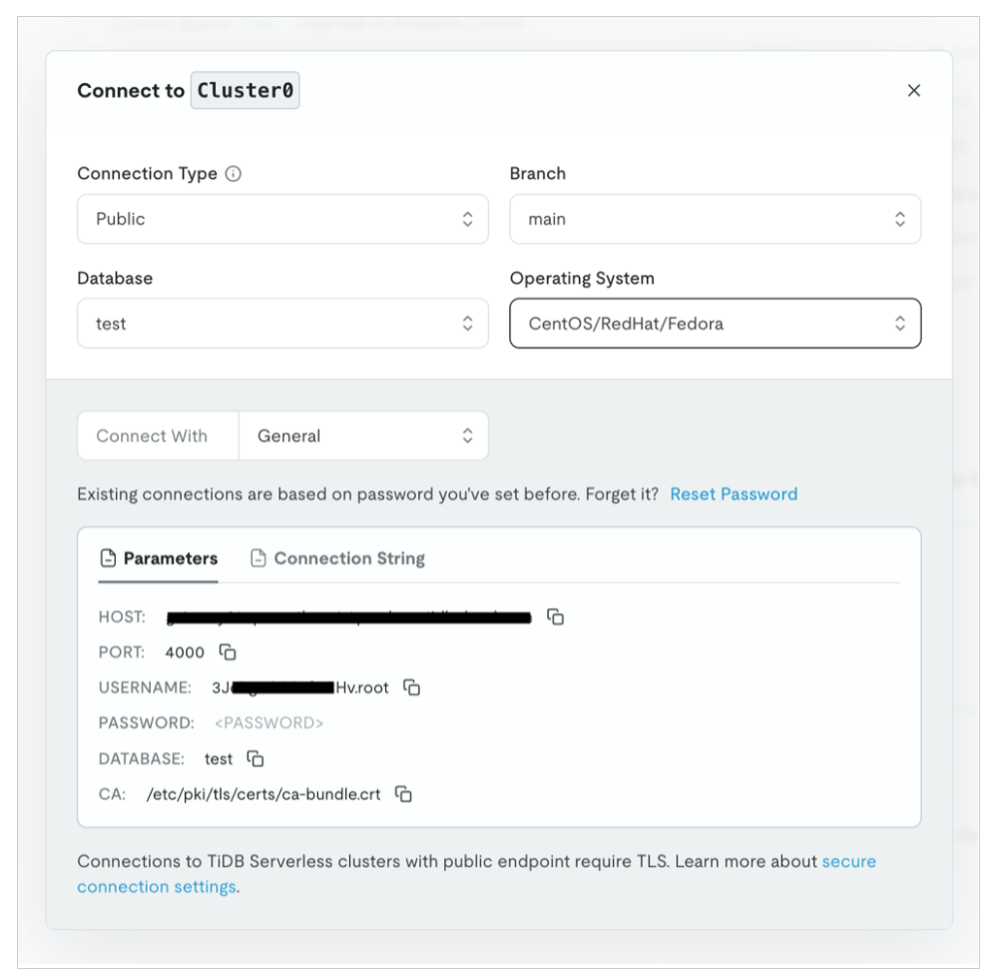
tiup dumpling -u <prefix.root> -P 4000 -h <tidb serverless endpoint/host> -r 200000 -o "s3://<specific s3 bucket>" --sql "select * from <target database>.<target table>" --ca "/etc/pki/tls/certs/ca-bundle.crt" --password <tidb serverless password>- Để lấy thông tin kết nối TiDB serverless, hãy điều hướng đến bảng điều khiển TiDB Cloud và chọn “Connect”.

Bạn có thể thu thập thông tin kết nối cụ thể của cơ sở dữ liệu thử nghiệm từ ảnh chụp màn hình sau.
Bạn có thể xem dữ liệu được lưu trữ trong vùng lưu trữ S3 trên bảng điều khiển Amazon S3.
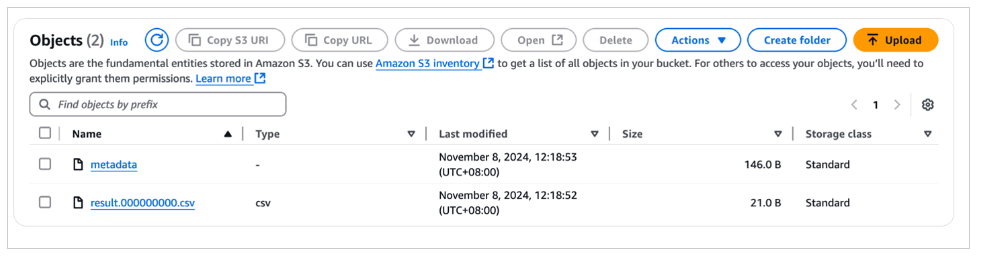
Bạn có thể sử dụng Amazon S3 Select để truy vấn dữ liệu và nhận kết quả tương tự như ảnh chụp màn hình sau, xác nhận rằng dữ liệu đã được nhập vào testtable.

Sử dụng TiDB Dumpling với self-managed checkpoint để đồng bộ hóa dữ liệu gia tăng từ TiDB sang Amazon S3
Để đạt được đồng bộ hóa dữ liệu gia tăng bằng cách sử dụng TiDB Dumpling, điều cần thiết là phải tự quản lý checkpoint của dữ liệu mục tiêu được đồng bộ hóa. Một cách được đề xuất là lưu trữ ID của bản ghi được nhập cuối cùng vào một phương tiện nhất định (chẳng hạn như Amazon ElastiCache for Redis, Amazon DynamoDB) để đạt được checkpoint tự quản lý khi chạy tác vụ shell/Python để kích hoạt TiDB Dumpling. Điều kiện tiên quyết để triển khai điều này là bảng đích có trường id monotonically increasing (tăng tuyến tính) làm khóa chính.
Bạn có thể sử dụng lệnh TiDB Dumpling sau để lọc dữ liệu đã xuất:
tiup dumpling -u <prefix.root> -P 4000 -h <tidb serverless endpoint/host> -r 200000 -o "s3://<specific s3 bucket>" --sql "select * from <target database>.<target table> where id > 2" --ca "/etc/pki/tls/certs/ca-bundle.crt" --password <tidb serverless password>Sử dụng trình kết nối TiDB CDC để đồng bộ hóa dữ liệu gia tăng từ TiDB sang Amazon S3
Ưu điểm của việc sử dụng trình kết nối TiDB CDC để đạt được đồng bộ hóa dữ liệu gia tăng từ TiDB sang Amazon S3 là có cơ chế thu thập dữ liệu thay đổi (CDC) tích hợp và vì công cụ phụ trợ là Flink nên hiệu suất nhanh. Tuy nhiên, có một sự đánh đổi: bạn cần tạo một số bảng Flink để ánh xạ các bảng ODS trên AWS.
Để biết hướng dẫn triển khai trình kết nối TiDB CDC, hãy tham khảo TiDB CDC.
Sử dụng EMR serverless job để đồng bộ hóa dữ liệu lịch sử và gia tăng từ bảng Data Catalog sang bảng TiDB
Dữ liệu thường được truyền từ on-premises đến Đám mây AWS. Tuy nhiên, trong một số trường hợp, dữ liệu có thể truyền từ Đám mây AWS đến cơ sở dữ liệu on-premises của bạn.
Sau khi truy cập vào AWS, dữ liệu sẽ được gói gọn và quản lý bởi Data Catalog bằng cách tạo các bảng Athena với lược đồ của các bảng cụ thể. Lệnh DDL tạo bảng như sau:
CREATE EXTERNAL TABLE IF NOT EXISTS `testtable`(
`id` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
LOCATION 's3://<bucket_name>/<prefix_name>/';Ảnh chụp màn hình bên dưới hiển thị kết quả chạy DDL bằng bảng điều khiển Athena.
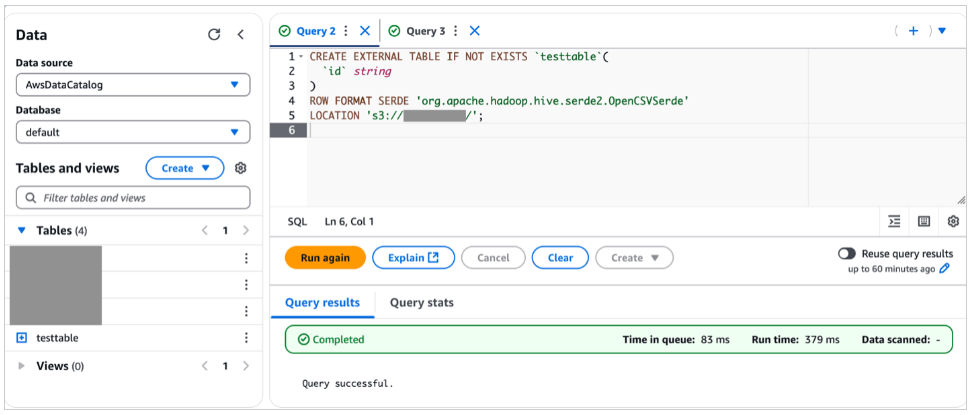
Dữ liệu được lưu trữ trong testtable được truy vấn bằng câu lênh SQL select * from testable . Kết quả truy vấn được hiển thị như sau:

Trong trường hợp này, EMR serverless spark job có thể thực hiện công việc đồng bộ hóa dữ liệu từ bảng AWS Glue với bảng on-premises của bạn.
Nếu Spark job được viết bằng Scala, mã mẫu như sau:
package com.example
import org.apache.spark.sql.{DataFrame, SparkSession}
object Main {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("<specific app name>")
.enableHiveSupport()
.getOrCreate()
spark.sql("show databases").show()
spark.sql("use default")
var df=spark.sql("select * from testtable")
df.write
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://<tidbcloud_endpoint>:4000/namespace")
.option("dbtable", "<table_name>")
.option("user", "<user_name>")
.option("password", "<password_string>")
.save()
spark.close()
}
}Bạn có thể lấy thông tin kết nối của TiDB serverless endpoint trên bảng điều khiển TiDB bằng cách chọn Connect, như được hiển thị trước đó trong bài đăng này.
Sau khi nén code Scala dưới dạng tệp JAR bằng SBT, bạn có thể gửi job đến EMR Serverless bằng lệnh Giao diện dòng lệnh AWS (AWS CLI) sau:
export applicationId=00fev6mdk***
export job_role_arn=arn:aws:iam::<aws account id>:role/emr-serverless-job-role
aws emr-serverless start-job-run \
--application-id $applicationId \
--execution-role-arn $job_role_arn \
--job-driver '{
"sparkSubmit": {
"entryPoint": "<s3 object url for the wrapped jar file>",
"sparkSubmitParameters": "--conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.driver.cores=1 --conf spark.driver.memory=3g --conf spark.executor.cores=4 --conf spark.executor.memory=3g --jars s3://spark-sql-test-nov23rd/mysql-connector-j-8.2.0.jar"
}
}'Nếu Spark job được viết bằng PySpark, mã mẫu như sau:
import os
import sys
import pyspark.sql.functions as F
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("app1")\
.enableHiveSupport()\
.getOrCreate()
df=spark.sql(f"select * from {str(sys.argv[1])}")
df.write.format("jdbc").options(
driver="com.mysql.cj.jdbc.Driver",
url="jdbc:mysql://tidbcloud_endpoint:4000/namespace ",
dbtable="table_name",
user="use_name",
password="password_string").save()
spark.stop()Bạn có thể gửi job đến EMR Serverless bằng lệnh AWS CLI sau:
export applicationId=00fev6mdk***
export job_role_arn=arn:aws:iam::<aws account id>:role/emr-serverless-job-role
aws emr-serverless start-job-run \
--application-id $applicationId \
--execution-role-arn $job_role_arn \
--job-driver '{
"sparkSubmit": {
"entryPoint": "<s3 object url for the python script file>",
"entryPointArguments": ["testspark"],
"sparkSubmitParameters": "--conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.driver.cores=1 --conf spark.driver.memory=3g --conf spark.executor.cores=4 --conf spark.executor.memory=3g --jars s3://spark-sql-test-nov23rd/mysql-connector-j-8.2.0.jar"
}
}'Đoạn mã PySpark và lệnh AWS CLI ở trên cũng xử lý đầu vào tham số theo hướng outbound: tên bảng (cụ thể là testspark) được đưa vào câu lệnh SQL khi gửi job.
Các yếu tố cần thiết về việc vận hành EMR Serverless job
Ứng dụng EMR Serverless là một khái niệm nhóm tài nguyên. Một ứng dụng có một dung lượng tài nguyên điện toán, bộ nhớ và lưu trữ nhất định để các job chạy trên ứng dụng sử dụng. Bạn có thể cấu hình dung lượng tài nguyên bằng AWS CLI hoặc bảng điều khiển. Vì là một nhóm tài nguyên nên việc tạo ứng dụng EMR Serverless thường là hành động một lần với dung lượng ban đầu và dung lượng tối đa được định cấu hình.
EMR Serverless job là một đơn vị làm việc thực sự xử lý tác vụ điện toán. Để một tác vụ hoạt động, bạn cần đặt ID ứng dụng EMR Serverless, IAM role thực thi (đã thảo luận trước đó) và cấu hình ứng dụng cụ thể (tài nguyên mà tác vụ dự định sử dụng). Mặc dù bạn có thể tạo tác vụ EMR Serverless trên bảng điều khiển, nhưng bạn nên tạo tác vụ EMR Serverless bằng AWS CLI để tích hợp thêm với bộ lập lịch và tập lệnh.
Để biết thêm chi tiết về cách tạo ứng dụng EMR Serverless và cung cấp tác vụ EMR Serverless, hãy tham khảo truy vấn EMR Serverless Hive hoặc tác vụ EMR Serverless PySpark
Tích hợp DolphinScheduler và điều phối job
DolphinScheduler là một nền tảng điều phối dữ liệu hiện đại. Thật linh hoạt để tạo workflow hiệu suất cao với low-code. Nó cũng cung cấp một giao diện người dùng mạnh mẽ, dành riêng để giải quyết các phần phụ thuộc tác vụ phức tạp trong quy trình dữ liệu và cung cấp nhiều loại công việc khác nhau ngay lập tức.
DolphinScheduler được phát triển và duy trì bởi WhaleOps, đồng thời có sẵn trên AWS Marketplace với tên gọi WhaleStudio.
DolphinScheduler đã được tích hợp nguyên bản với Hadoop: Chế độ cụm DolphinScheduler theo mặc định được khuyến nghị triển khai trên cụm Hadoop (thường là trên các nút dữ liệu HDFS) và các tập lệnh HQL được tải lên DolphinScheduler Resource Manager được lưu trữ theo mặc định trên HDFS và có thể được điều phối bằng lệnh Hive shell sau:
Hive -f example.sql
Hơn nữa, đối với trường hợp cụ thể mà DAG điều phối khá phức tạp, mỗi DAG bao gồm một số công việc (ví dụ: hơn 300) và hầu hết tất cả các công việc là tập lệnh HQL được lưu trữ trong DolphinScheduler Resource Manager.
Hoàn thành các bước được liệt kê trong phần này để tích hợp liền mạch giữa DolphinScheduler và EMR Serverless.
Chuyển storage layer của DolphinScheduler Resource Center từ HDFS sang Amazon S3
Chỉnh sửa các tệp common.properties trong thư mục /usr/local/src/apache-dolphinscheduler/api-server/ và thư mục /usr/local/src/apache-dolphinscheduler/worker-server/conf. Đoạn mã sau đây cho thấy phần của tệp cần được sửa đổi:
# resource storage type: HDFS, S3, OSS, NONE
#resource.storage.type=NONE
resource.storage.type=S3
# resource store on HDFS/S3 path, resource file will store to this base path, self configuration, please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resource.storage.upload.base.path=/dolphinscheduler
# The AWS access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.access.key.id=AKIA************
# The AWS secret access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.secret.access.key=lAm8R2TQzt*************
# The AWS Region to use. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.region=us-east-1
# The name of the bucket. You need to create them by yourself. Otherwise, the system cannot start. All buckets in Amazon S3 share a single namespace; ensure the bucket is given a unique name.
resource.aws.s3.bucket.name=dolphinscheduler-shiyang
# You need to set this parameter when private cloud s3. If S3 uses public cloud, you only need to set resource.aws.region or set to the endpoint of a public cloud such as S3.cn-north-1.amazonaws.com.cn
resource.aws.s3.endpoint=s3.us-east-1.amazonaws.com
Sau khi chỉnh sửa và lưu hai tệp, hãy khởi động lại api-server và worker-server bằng cách chạy các lệnh sau, trong đường dẫn thư mục /usr/local/src/apache-dolphinscheduler/
bash ./bin/stop-all.sh
bash ./bin/start-all.sh
bash ./bin/status-all.sh
Bạn có thể xác thực xem việc chuyển lớp lưu trữ sang Amazon S3 có thành công hay không bằng cách tải lên tập lệnh bằng Bảng điều khiển Trung tâm tài nguyên DolphinScheduler, kiểm tra xem tệp có xuất hiện trong thư mục vùng lưu trữ S3 có liên quan hay không.
Trước khi xác minh rằng Amazon S3 hiện là vị trí lưu trữ của DolphinScheduler, bạn cần tạo một tenant trên bảng điều khiển DolphinScheduler và liên kết người dùng quản trị với tenant đó, như minh họa trong ảnh chụp màn hình sau:
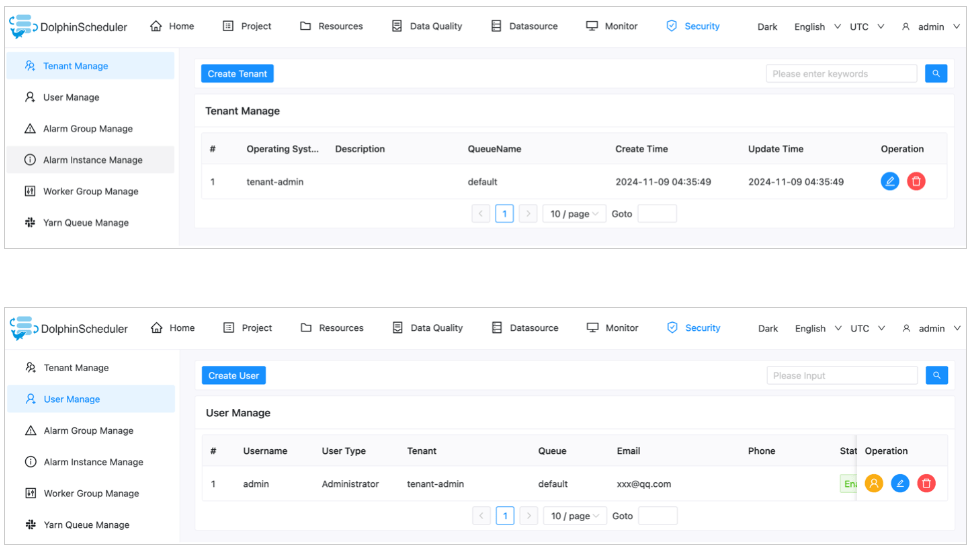
Sau đó, bạn có thể tạo một thư mục trên bảng điều khiển DolphinScheduler và kiểm tra xem thư mục có hiển thị trên bảng điều khiển Amazon S3 hay không.
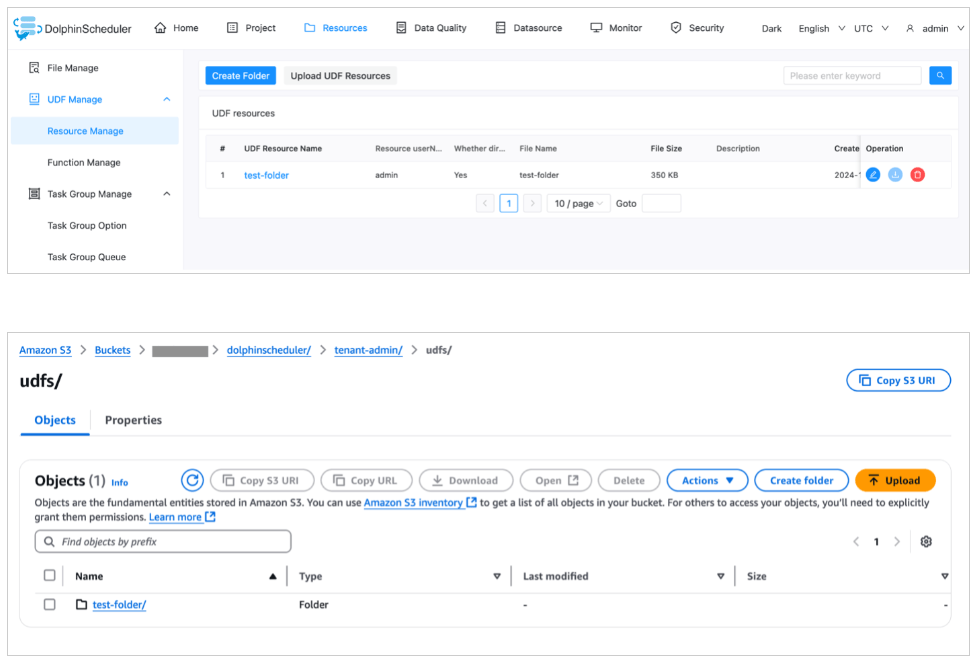
Đảm bảo các job script được tải lên từ Amazon S3 có sẵn trong DolphinScheduler Resource Center
Sau khi hoàn thành tác vụ đầu tiên, bạn có thể tải lên các script từ bảng điều khiển DolphinScheduler Resource Center và xác nhận rằng các tập lệnh được lưu trữ trong Amazon S3. Tuy nhiên, trên thực tế, bạn cần di chuyển tất cả các tập lệnh trực tiếp sang Amazon S3. Bạn có thể tìm và sửa đổi các tập lệnh được lưu trữ trong Amazon S3 bằng bảng điều khiển DolphinScheduler Resource Center. Để làm như vậy, bạn có thể sửa đổi metadata table bằng cách chèn tất cả metadata của script. Lược đồ bảng của bảng t_ds_resourcest_ds_resources được hiển thị trong ảnh sau.

Lệnh insert như sau:
insert into t_ds_resources values(6, 'count.java', ' count.java','',1,1,0,'2024-11-09 04:46:44', '2024-11-09 04:46:44', -1, 'count.java',0);Bây giờ có hai bản ghi trong bảng t_ds_resoruces .

Bạn có thể truy cập các bản ghi có liên quan trên bảng điều khiển DolphinScheduler.
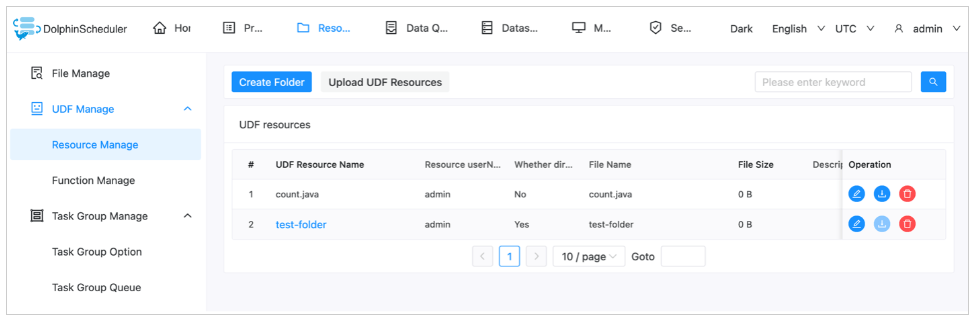
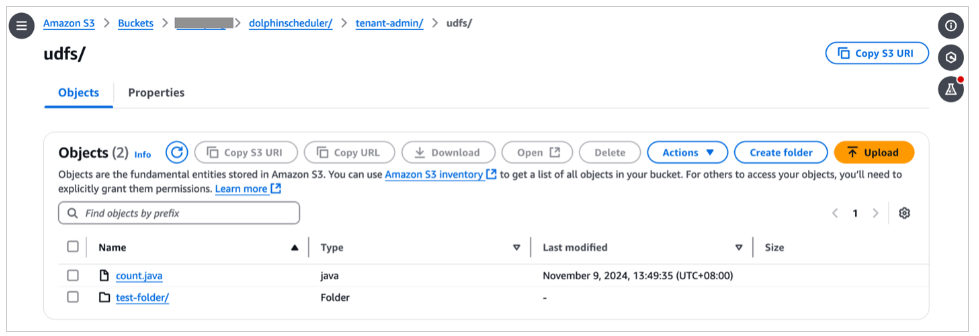
Ảnh chụp màn hình sau đây hiển thị các tệp trên bảng điều khiển Amazon S3.
Làm cho DolphinScheduler DAG orchestrator biết về trạng thái của job để DAG có thể tiếp tục hoặc thực hiện các hành động có liên quan
Như đã đề cập trước đó, DolphinScheduler được tích hợp nguyên bản với hệ sinh thái Hadoop và các tập lệnh HQL có thể được điều phối bởi bộ điều phối DAG của DolphinScheduler thông qua lệnh Hive -f xxx.sql. Do đó, khi các tập lệnh thay đổi thành shell script hoặc Python script (EMR Severless job cần được điều phối thông qua shell script hoặc Python script thay vì lệnh Hive đơn giản), trình điều phối DAG có thể bắt đầu các job, nhưng không thể nhận được trạng thái thời gian thực của job và do đó không thể tiếp tục workflow sang các bước tiếp theo. Bởi vì DAG trong trường hợp này rất phức tạp, nên không khả thi để sửa đổi DAG; thay vào đó, chúng tôi tuân theo chiến lược nâng và thay đổi.
Chúng tôi sử dụng các tập lệnh sau để nắm bắt trạng thái công việc và thực hiện các hành động thích hợp.
Duy trì danh sách ID ứng dụng bằng mã sau:
var=$(cat applicationlist.txt|grep appid1)
applicationId=${var#* }
echo $applicationIdBật tính năng tự động kiểm tra trạng thái các step DolphinScheduler bằng cách sử dụng Linux shell:
app_state
{
response2=$(aws emr-serverless get-application --application-id $applicationId)
application=$(echo $response1 | jq -r '.application')
state=$(echo $application | jq -r '.state')
echo $state
}
job_state
{
response4=$(aws emr-serverless get-job-run --application-id $applicationId --job-run-id $JOB_RUN_ID)
jobRun=$(echo $response4 | jq -r '.jobRun')
JOB_RUN_ID=$(echo $jobRun | jq -r '.jobRunId')
JOB_STATE=$(echo $jobRun | jq -r '.state')
echo $JOB_STATE
}
state=$(job_state)
while [ $state != "SUCCESS" ]; do
case $state in
RUNNING)
state=$(job_state)
;;
SCHEDULED)
state=$(job_state)
;;
PENDING)
state=$(job_state)
;;
FAILED)
break
;;
esac
done
if [ $state == "FAILED" ]
then
false
else
true
fiThu dọn tài nguyên
Để dọn dẹp tài nguyên của bạn, bạn nên sử dụng API thông qua các bước sau:
- Xóa EC2 instance:
- Tìm instance EC2 bằng lệnh sau:
aws ec2 describe-instances- Xóa instance EC2 bằng lệnh sau:
aws ec2 terminate-instances –instance-ids <specific instance id>- Xóa instance RDS:
- Tìm instance bằng lệnh sau:
aws rds describe-db-instances- Xóa instance bằng lệnh sau:
aws rds delete-db-instances –db-instance-identifier <speficic rds instance id>- Xóa ứng dụng EMR Serverless
- Tìm ứng dụng EMR Serverless bằng lệnh sau:
aws emr-serverless list-applications- Xóa ứng dụng EMR Serverless bằng lệnh sau:
aws emr-serverless delete-application –application-id <specific application id>Kết thúc
Trong bài đăng này, chúng tôi đã thảo luận về cách EMR Serverless, với tư cách là công cụ điện toán dữ liệu lớn phi máy chủ do AWS quản lý, tích hợp với các sản phẩm OSS phổ biến như TiDB và DolphinScheduler. Chúng tôi đã thảo luận về cách đạt được đồng bộ hóa dữ liệu giữa TiDB và Đám mây AWS cũng như cách sử dụng DolphineScheduler để điều phối các tác vụ EMR Serverless.
Hãy thử giải pháp với trường hợp sử dụng của riêng bạn và chia sẻ phản hồi của bạn trong phần bình luận.
Giới thiệu về tác giả

Shiyang Wei là Kiến trúc sư giải pháp cấp cao tại Amazon Web Services. Ông chuyên về kiến trúc hệ thống đám mây và thiết kế giải pháp cho ngành tài chính. Đặc biệt, ông tập trung vào các ứng dụng dữ liệu lớn và máy học trong tài chính, cũng như tác động của việc tuân thủ quy định đối với thiết kế kiến trúc đám mây trong lĩnh vực tài chính. Ông có hơn 10 năm kinh nghiệm trong lĩnh vực phát triển lĩnh vực dữ liệu và thiết kế kiến trúc.
