by Devi Nair, Vishal Karlupia, Nicolas Simard, and Srinivas Ganapathi on 08 APR 2025 in Advanced (300), Amazon Bedrock, Amazon Machine Learning, Artificial Intelligence, Generative AI, Technical How-to Permalink Comments Share
Trong bối cảnh AI đang phát triển nhanh chóng, và ngày càng nhiều tổ chức nhận ra sức mạnh của synthetic data trong việc thúc đẩy đổi mới. Tuy nhiên, các doanh nghiệp muốn sử dụng AI đang đối mặt với một rào cản lớn: làm thế nào để sử dụng dữ liệu nhạy cảm một cách an toàn. Các quy định nghiêm ngặt về quyền riêng tư khiến việc sử dụng dữ liệu này trở nên rủi ro, ngay cả khi đã có các phương pháp anonymization (ẩn danh) mạnh mẽ. Advanced analytics (phân tích nâng cao) có thể tiềm ẩn việc khám phá các mối tương quan ẩn và tiết lộ dữ liệu thực, dẫn đến các vấn đề về tuân thủ và tổn hại uy tín. Thêm vào đó, nhiều ngành công nghiệp gặp khó khăn với việc thiếu các bộ dữ liệu chất lượng cao và đa dạng, cần thiết cho các quy trình quan trọng như kiểm thử phần mềm, phát triển sản phẩm và huấn luyện mô hình AI. Sự thiếu hụt dữ liệu này có thể cản trở đổi mới, làm chậm chu kỳ phát triển trên nhiều hoạt động kinh doanh khác nhau.
Các tổ chức cần các giải pháp sáng tạo để khai thác tiềm năng của các quy trình dựa trên dữ liệu mà không làm ảnh hưởng đến đạo đức hoặc quyền riêng tư dữ liệu. Đây là lúc synthetic data trở nên quan trọng—một giải pháp mô phỏng các thuộc tính thống kê và mẫu của dữ liệu thực nhưng hoàn toàn giả tưởng. Bằng cách sử dụng synthetic data, doanh nghiệp có thể huấn luyện mô hình AI, thực hiện phân tích và phát triển ứng dụng mà không có rủi ro tiết lộ thông tin nhạy cảm. Synthetic data hiệu quả trong việc thu hẹp khoảng cách giữa tính hữu ích của dữ liệu và bảo vệ quyền riêng tư. Tuy nhiên, việc tạo ra synthetic data chất lượng cao đi kèm với nhiều thách thức đáng kể:
- Data quality – Đảm bảo dữ liệu tổng hợp phản ánh chính xác các thuộc tính thống kê và các sắc thái của thế giới thực là điều khó khăn. Dữ liệu có thể không nắm bắt được các trường hợp hiếm gặp hoặc toàn bộ phổ tương tác của con người.
- Bias management – Mặc dù synthetic data có thể giúp giảm thiên lệch, nhưng nó cũng có thể vô tình khuếch đại các thiên lệch hiện có nếu không được quản lý cẩn thận. Chất lượng của synthetic data phụ thuộc nhiều vào mô hình và dữ liệu được sử dụng để tạo ra nó.
- Privacy vs. utility – Cân bằng giữa bảo vệ quyền riêng tư và tính hữu ích của dữ liệu là phức tạp. Có nguy cơ reverse engineering hoặc rò rỉ dữ liệu nếu không triển khai đúng cách.
- Validation challenges – Xác minh chất lượng và sự đại diện của synthetic data thường yêu cầu so sánh với dữ liệu thực, điều này có thể gây khó khăn khi làm việc với thông tin nhạy cảm.
- Reality gap – Synthetic data có thể không hoàn toàn phản ánh tính động của thế giới thực, dẫn đến sự khác biệt giữa hiệu suất mô hình trên dữ liệu tổng hợp và các ứng dụng trong thế giới thực.
Trong bài viết này, chúng ta sẽ khám phá cách sử dụng Amazon Bedrock để tạo synthetic data, xem xét những thách thức này cùng với các lợi ích tiềm năng nhằm phát triển các chiến lược hiệu quả cho nhiều ứng dụng trong nhiều ngành, bao gồm AI và machine learning (ML). Amazon Bedrock cung cấp một tập hợp rộng các khả năng để xây dựng các ứng dụng generative AI với trọng tâm vào bảo mật, quyền riêng tư và AI có trách nhiệm. Được xây dựng trong hệ sinh thái AWS, Amazon Bedrock được thiết kế để giúp duy trì các tiêu chuẩn bảo mật và tuân thủ cần thiết cho doanh nghiệp.
Các thuộc tính của dữ liệu tổng hợp chất lượng cao
Để thực sự hiệu quả, synthetic data phải vừa realistic vừa reliable. Điều này có nghĩa là dữ liệu phải phản ánh chính xác các phức tạp và sắc thái của dữ liệu thực trong thế giới thực trong khi vẫn đảm bảo complete anonymity. Một bộ dữ liệu synthetic chất lượng cao thể hiện một số đặc điểm chính giúp duy trì fidelity với dữ liệu gốc:
- Data structure – Dữ liệu synthetic nên duy trì cùng cấu trúc với dữ liệu thực, bao gồm cùng số lượng cột, data types, và các mối quan hệ giữa các nguồn dữ liệu khác nhau.
- Statistical properties – Dữ liệu synthetic nên mô phỏng các statistical properties của dữ liệu thực, chẳng hạn như mean, median, standard deviation, correlation between variables, và các distribution patterns.
- Temporal patterns – Nếu dữ liệu thực thể hiện các temporal patterns (ví dụ, diurnal hoặc seasonal patterns), dữ liệu synthetic cũng nên phản ánh các mẫu này.
- Anomalies and outliers – Dữ liệu thực thường chứa anomalies and outliers. Dữ liệu synthetic cũng nên bao gồm tỷ lệ và phân bố tương tự của anomalies and outliers để phản ánh chính xác kịch bản thực tế.
- Referential integrity – Nếu dữ liệu thực có các mối quan hệ và phụ thuộc giữa các nguồn dữ liệu khác nhau, dữ liệu synthetic nên duy trì các mối quan hệ này để hỗ trợ referential integrity.
- Consistency – Dữ liệu synthetic nên nhất quán giữa các nguồn dữ liệu khác nhau và duy trì các mối quan hệ và phụ thuộc giữa chúng, tạo nên một biểu diễn thống nhất và có tính coherent.
- Scalability – Quá trình tạo dữ liệu synthetic nên có khả năng scalable để xử lý khối lượng dữ liệu lớn và hỗ trợ việc tạo dữ liệu synthetic cho các scenario và use case khác nhau.
- Diversity – Dữ liệu synthetic nên phản ánh sự đa dạng có trong dữ liệu thực.
Tổng quan giải pháp
Việc generating useful synthetic data đồng thời bảo vệ quyền riêng tư đòi hỏi một thoughtful approach. Hình dưới đây thể hiện high-level architecture của giải pháp được đề xuất. Quá trình này bao gồm ba bước chính:
- Identify validation rules xác định cấu trúc và các statistical properties của dữ liệu thực.
- Sử dụng các quy tắc đó để tạo code bằng Amazon Bedrock nhằm tạo các synthetic data subsets.
- Kết hợp nhiều synthetic subsets thành full datasets.
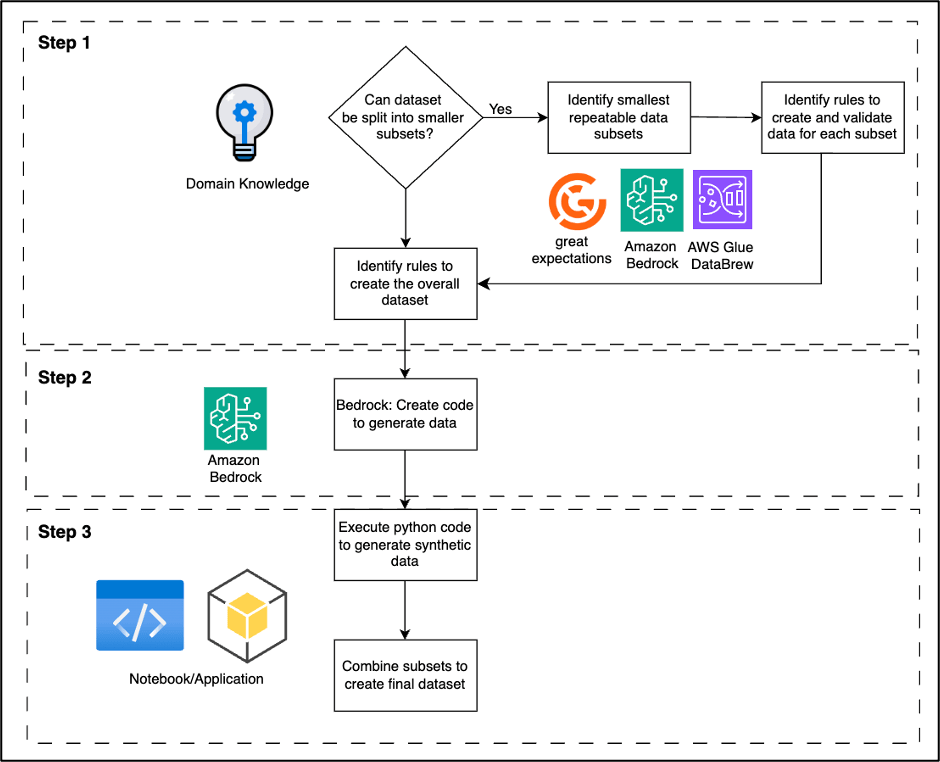
Hãy cùng khám phá chi tiết hơn ba bước chính này để tạo useful synthetic data.
Bước 1: Xác định các quy tắc và đặc điểm của dữ liệu
Để tạo bộ dữ liệu synthetic, hãy bắt đầu bằng việc thiết lập các quy tắc rõ ràng phản ánh bản chất của dữ liệu mục tiêu:
- Sử dụng domain-specific knowledge để xác định các thuộc tính và mối quan hệ chính.
- Nghiên cứu các public datasets, tài liệu học thuật và tài liệu ngành.
- Sử dụng các công cụ như AWS Glue DataBrew, Amazon Bedrock, hoặc các giải pháp mã nguồn mở (như Great Expectations) để phân tích cấu trúc dữ liệu và các mẫu.
Phát triển một bộ quy tắc toàn diện bao gồm:
- Data types và phạm vi giá trị (value ranges)
- Mối quan hệ giữa các trường (inter-field relationships)
- Tiêu chuẩn chất lượng (quality standards)
- Các mẫu và anomalies đặc thù ngành
Bước nền tảng này đảm bảo dữ liệu synthetic của bạn phản ánh chính xác các kịch bản thực tế trong ngành của bạn.
Bước 2: Tạo code với Amazon Bedrock
Chuyển các quy tắc dữ liệu thành functional code sử dụng các Amazon Bedrock language models:
- Chọn mô hình Amazon Bedrock phù hợp dựa trên khả năng tạo code và tính liên quan đến ngành.
- Soạn một detailed prompt mô tả kết quả code mong muốn, bao gồm data structures và các generation rules.
- Sử dụng Amazon Bedrock API để tạo Python code dựa trên các prompt của bạn.
Tinh chỉnh code theo vòng lặp bằng cách:
- Xem xét tính chính xác và hiệu quả (accuracy and efficiency)
- Điều chỉnh prompt khi cần thiết
- Kết hợp ý kiến của nhà phát triển cho các kịch bản phức tạp
Kết quả là một tailored script tạo các synthetic data entries phù hợp với yêu cầu cụ thể của bạn và mô phỏng sát dữ liệu thực trong ngành.
Bước 3: Tập hợp và Mở rộng tập dữ liệu tổng hợp
Chuyển dữ liệu đã tạo thành một bộ dữ liệu tổng thể, đại diện thực tế:
- Sử dụng code từ Step 2 để tạo nhiều synthetic subsets cho các kịch bản khác nhau.
- Hợp nhất các subsets dựa trên domain knowledge, duy trì tỷ lệ và mối quan hệ thực tế.
- Đồng bộ các thành phần temporal hoặc sequential, đồng thời thêm controlled randomness để tạo sự biến thiên tự nhiên.
- Mở rộng bộ dữ liệu đến kích thước cần thiết, phản ánh các khoảng thời gian hoặc dân số khác nhau.
- Bao gồm các rare events và edge cases với tần suất phù hợp.
- Tạo metadata đi kèm mô tả đặc điểm của bộ dữ liệu và quy trình tạo.
Kết quả cuối cùng là một bộ dữ liệu synthetic đa dạng và realistic, phục vụ các mục đích như system testing, ML model training, hoặc data analysis. Metadata cung cấp sự minh bạch về quá trình tạo và đặc điểm dữ liệu.
Tất cả những biện pháp này tạo ra một bộ dữ liệu robust synthetic dataset gần như tương đương với dữ liệu thực nhưng tránh tiết lộ thông tin nhạy cảm trực tiếp. Cách tiếp cận tổng quát này có thể áp dụng cho nhiều loại bộ dữ liệu khác nhau, từ financial transactions đến medical records, tận dụng sức mạnh của Amazon Bedrock cho việc tạo code và kiến thức chuyên môn trong ngành để data validation và cấu trúc dữ liệu.
Tầm quan trọng của Tính riêng tư Vi sai (Differential Privacy)
Mặc dù synthetic data mang lại nhiều lợi ích cho analytics và machine learning, nhưng cần nhận thức rằng các vấn đề về quyền riêng tư vẫn tồn tại ngay cả với các bộ dữ liệu được tạo ra nhân tạo. Khi chúng ta cố gắng tạo high-fidelity synthetic data, cũng cần duy trì các biện pháp bảo vệ quyền riêng tư vững chắc cho dữ liệu gốc. Mặc dù synthetic data mô phỏng các mẫu trong dữ liệu thực, nếu được tạo không đúng cách, nó có nguy cơ tiết lộ chi tiết về thông tin nhạy cảm trong bộ dữ liệu nguồn. Đây chính là lý do differential privacy trở nên quan trọng. Differential privacy là một khung toán học cung cấp cách để quantify và kiểm soát các rủi ro về quyền riêng tư liên quan đến phân tích dữ liệu. Nó hoạt động bằng cách injecting calibrated noise vào quá trình tạo dữ liệu, khiến gần như không thể suy ra bất cứ điều gì về một điểm dữ liệu riêng lẻ hoặc thông tin bảo mật trong bộ dữ liệu nguồn.
Differential privacy bảo vệ chống lại các re-identification exploits từ những kẻ cố gắng khai thác dữ liệu. Lượng noise được cân chỉnh cẩn thận thêm vào dữ liệu synthetic đảm bảo rằng ngay cả khi một kẻ tấn công cố gắng, việc liên kết kết quả với các bản ghi cụ thể trong dữ liệu gốc cũng là computationally infeasible, đồng thời vẫn duy trì các statistical properties tổng thể của bộ dữ liệu. Điều này cho phép dữ liệu synthetic phản ánh gần như chính xác đặc tính thực tế và vẫn hữu ích cho analytics và modeling trong khi bảo vệ quyền riêng tư. Bằng cách tích hợp các kỹ thuật differential privacy vào quá trình tạo dữ liệu synthetic, bạn có thể tạo ra các bộ dữ liệu không chỉ duy trì các statistical properties của dữ liệu gốc mà còn cung cấp các strong privacy guarantees. Nó cho phép các tổ chức chia sẻ dữ liệu tự do hơn, hợp tác trong các dự án nhạy cảm và phát triển các mô hình AI với reduced risk of privacy breaches. Ví dụ, trong lĩnh vực y tế, dữ liệu synthetic patient data với differential privacy có thể thúc đẩy nghiên cứu mà không làm ảnh hưởng đến individual patient confidentiality.
Khi chúng ta tiếp tục tiến bộ trong lĩnh vực tạo dữ liệu synthetic, việc tích hợp differential privacy đang trở thành không chỉ một best practice, mà còn là một thành phần cần thiết cho responsible data science. Cách tiếp cận này mở ra một tương lai nơi data utility và privacy protection cùng tồn tại hài hòa, thúc đẩy đổi mới trong khi bảo vệ quyền cá nhân. Tuy nhiên, mặc dù differential privacy cung cấp các đảm bảo lý thuyết mạnh mẽ, việc triển khai thực tiễn có thể gặp nhiều thách thức. Các tổ chức phải cân nhắc kỹ lưỡng giữa privacy và utility, bởi vì tăng cường bảo vệ quyền riêng tư thường đi kèm với reduced data utility.
Xây dựng các tập dữ liệu tổng hợp cho các phát hiện của Trusted Advisor bằng Amazon Bedrock
Trong bài viết này, chúng tôi hướng dẫn bạn quy trình tạo synthetic datasets cho các kết quả AWS Trusted Advisor findings sử dụng Amazon Bedrock. Trusted Advisor cung cấp hướng dẫn theo thời gian thực để tối ưu hóa môi trường AWS của bạn, cải thiện hiệu suất, bảo mật và cost-efficiency thông qua hơn 500 checks dựa trên AWS best practices. Chúng tôi minh họa phương pháp tạo dữ liệu synthetic bằng ví dụ “Underutilized Amazon EBS Volumes” check (checkid: DAvU99Dc4C).
Bằng cách theo dõi bài viết này, bạn sẽ có kiến thức thực tiễn về:
- Defining data rules cho các kết quả Trusted Advisor findings
- Sử dụng Amazon Bedrock để tạo data creation code
- Assembling and scaling synthetic datasets
Phương pháp này có thể áp dụng cho hơn 500 Trusted Advisor checks, cho phép bạn xây dựng các bộ dữ liệu toàn diện và privacy-aware để thử nghiệm, huấn luyện và phân tích. Dù bạn muốn nâng cao hiểu biết về các khuyến nghị của Trusted Advisor hay phát triển các chiến lược tối ưu hóa mới, synthetic data đều mang lại những khả năng mạnh mẽ.
Prerequisites
Để triển khai phương pháp này, bạn cần có AWS account với các quyền thích hợp.
- AWS Account Setup:
- IAM permissions cho:
- Amazon Bedrock
- AWS Trusted Advisor
- Amazon EBS
- Amazon Bedrock
- AWS Service Access:
- Bật quyền truy cập Amazon Bedrock trong Region của bạn
- Truy cập Anthropic Claude model trong Amazon Bedrock
- Có Enterprise hoặc Business support plan để truy cập đầy đủ Trusted Advisor
- Development Environment:
- Cài đặt Python 3.8 trở lên
- Các Python packages cần thiết:
- pandas
- numpy
- random
- boto3
- pandas
- Knowledge Requirements:
- Hiểu biết cơ bản về:
- Python programming
- AWS services (đặc biệt là EBS và Trusted Advisor)
- Các khái niệm Data analysis
- JSON/YAML file format
- Python programming
Định nghĩa các quy tắc phát hiện của Trusted Advisor
Bắt đầu bằng cách xem xét các kết quả thực tế của Trusted Advisor findings cho “Underutilized Amazon EBS Volumes” check. Phân tích cấu trúc và nội dung của các kết quả này để xác định các key data elements và mối quan hệ giữa chúng. Chú ý đến các yếu tố sau:
- Standard fields – Check ID, volume ID, volume type, snapshot ID, và snapshot age
- Volume attributes – Size, type, age, và cost
- Usage metrics – Read and write operations, throughput, và IOPS
- Temporal patterns – Sự thay đổi volume type và size
- Metadata – Tags, creation date, và last attached date
Khi nghiên cứu các yếu tố này, hãy ghi chú các typical ranges, patterns, và distributions cho từng thuộc tính. Ví dụ, quan sát cách volume sizes tương quan với volume types, hoặc cách các usage patterns khác nhau giữa môi trường phát triển và sản xuất. Phân tích này sẽ giúp bạn tạo ra một bộ quy tắc phản ánh chính xác các Trusted Advisor findings thực tế.
Sau khi phân tích các kết quả thực tế của Trusted Advisor cho “Underutilized Amazon EBS Volumes” check, chúng tôi xác định các crucial patterns và rules sau:
- Volume type – Xem xét các loại gp2, gp3, io1, io2, và st1. Kiểm tra xem volume sizes có hợp lệ cho các loại volume này không.
- Criteria – Đại diện cho nhiều AWS Regions, với các loại volume phù hợp. Snapshot ages phải tương quan với volume ages.
- Data structure – Mỗi kết quả nên bao gồm cùng số lượng cột.
Dưới đây là một ví dụ về ruleset:
Analysis of the AWS Trusted Advisor finding for "Underutilized Amazon EBS Volumes":
1. Columns in the Trusted Advisor Finding:
- Region
- Volume ID
- Volume Name
- Volume Type
- Volume Size
- Monthly Storage Cost
- Snapshot ID
- Snapshot Name
- Snapshot Age
2. Key Columns and Their Significance:
- Region: AWS region where the EBS volume is located
- Volume ID: Unique identifier for the EBS volume
- Volume Type: Type of EBS volume (e.g., gp2, io1, st1)
- Volume Size: Size of the volume in GB
- Monthly Storage Cost: Estimated cost for storing the volume
- Snapshot ID: Identifier of the most recent snapshot (if any)
- Snapshot Age: Age of the most recent snapshot
3. Relationships and Patterns:
- Volume ID and Snapshot ID relationship: Each volume may have zero or more snapshots
- Region and cost correlation: Storage costs may vary by region
- Volume Type and Size correlation: Certain volume types have size limitations
- Volume Size and Cost correlation: Larger volumes generally cost more
- Snapshot Age and utilization: Older snapshots might indicate less active volumes
4. Data Types and Formats:
- Region: String (e.g., "us-east-1")
- Volume ID: String starting with "vol-"
- Volume Name: String (can be null)
- Volume Type: String (gp2, gp3, io1, io2, st1, sc1, standard)
- Volume Size: Integer (in GB)
- Monthly Storage Cost: Decimal number
- Snapshot ID: String starting with "snap-" (can be null)
- Snapshot Name: String (can be null)Tạo code với Amazon Bedrock
Khi bạn đã xác định xong các rules, bây giờ bạn có thể sử dụng Amazon Bedrock để tạo Python code cho việc tạo các synthetic Trusted Advisor findings.
Dưới đây là một ví dụ về prompt cho Amazon Bedrock:
Give me python code to create a 100 row pandas df with the following data:
<<Copy paste the ruleset from the above step>>Bạn có thể gửi prompt này lên Amazon Bedrock chat playground sử dụng Anthropic’s Claude 3.5 Sonnet trên Amazon Bedrock, và nhận về Python code được tạo ra. Xem xét kỹ lưỡng code này, xác minh rằng nó đáp ứng tất cả các specifications và tạo ra dữ liệu realistic. Nếu cần, hãy lặp lại prompt hoặc thực hiện các manual adjustments trên code để xử lý các missing logic hoặc edge cases.
Code kết quả sẽ là nền tảng để tạo ra các synthetic Trusted Advisor findings đa dạng và realistic, tuân theo các defined parameters. Bằng cách sử dụng Amazon Bedrock theo phương pháp này, bạn có thể nhanh chóng phát triển sophisticated data generation code, vốn nếu làm thủ công sẽ đòi hỏi nhiều công sức và domain expertise.
Tạo tập dữ liệu con
Với code được tạo ra bởi Amazon Bedrock và đã được tinh chỉnh bằng các custom functions của bạn, bây giờ bạn có thể tạo ra các diverse subsets của synthetic Trusted Advisor findings cho “Underutilized Amazon EBS Volumes” check. Phương pháp này cho phép bạn mô phỏng nhiều real-world scenarios khác nhau. Trong sample code dưới đây, chúng tôi đã tùy chỉnh volume_id và snapshot_id để bắt đầu lần lượt với vol-9999 và snap-9999:
import pandas as pd
import numpy as np
import random
def generate_volume_id():
return f"vol-9999{''.join(random.choices('0123456789abcdef', k=17))}"
def generate_snapshot_id():
return f"snap-9999{''.join(random.choices('0123456789abcdef', k=17))}"
def generate_volume_name():
prefixes = ['app', 'db', 'web', 'cache', 'log']
suffixes = ['prod', 'dev', 'test', 'staging']
return f"{random.choice(prefixes)}-{random.choice(suffixes)}-{random.randint(1, 100)}"
def step3_generate_base_data():
# Generate synthetic data
num_records = 1000
regions = ['us-east-1', 'us-west-2', 'eu-west-1', 'ap-southeast-1']
volume_types = ['gp2', 'gp3', 'io1', 'io2', 'st1', 'sc1', 'standard']
data = {
'Region': np.random.choice(regions, num_records),
'Volume ID': [generate_volume_id() for _ in range(num_records)],
'Volume Name': [generate_volume_name() if random.random() > 0.3 else None for _ in range(num_records)],
'Volume Type': np.random.choice(volume_types, num_records, p=[0.4, 0.2, 0.1, 0.1, 0.1, 0.05, 0.05]),
'Volume Size': np.random.choice(range(1, 1001), num_records),
'Monthly Storage Cost': np.random.uniform(0.1, 100, num_records).round(2),
'Snapshot ID': [generate_snapshot_id() if random.random() > 0.4 else None for _ in range(num_records)],
'Snapshot Name': [f"snapshot-{i}" if random.random() > 0.6 else None for i in range(num_records)],
'Snapshot Age': [random.randint(1, 365) if random.random() > 0.4 else None for _ in range(num_records)]
}
df = pd.DataFrame(data)
# Apply some logic and constraints
df.loc[df['Volume Type'] == 'gp2', 'Volume Size'] = df.loc[df['Volume Type'] == 'gp2', 'Volume Size'].clip(1, 16384)
df.loc[df['Volume Type'] == 'io1', 'Volume Size'] = df.loc[df['Volume Type'] == 'io1', 'Volume Size'].clip(4, 16384)
df.loc[df['Volume Type'] == 'st1', 'Volume Size'] = df.loc[df['Volume Type'] == 'st1', 'Volume Size'].clip(500, 16384)
df.loc[df['Volume Type'] == 'sc1', 'Volume Size'] = df.loc[df['Volume Type'] == 'sc1', 'Volume Size'].clip(500, 16384)
# Adjust Monthly Storage Cost based on Volume Size and Type
df['Monthly Storage Cost'] = df.apply(lambda row: row['Volume Size'] * random.uniform(0.05, 0.15) * (1.5 if row['Volume Type'] in ['io1', 'io2'] else 1), axis=1).round(2)
# Ensure Snapshot ID, Name, and Age are consistent
df.loc[df['Snapshot ID'].isnull(), 'Snapshot Name'] = None
df.loc[df['Snapshot ID'].isnull(), 'Snapshot Age'] = None
# Add some underutilized volumes
df['Underutilized'] = np.random.choice([True, False], num_records, p=[0.7, 0.3])
df.loc[df['Underutilized'], 'Monthly Storage Cost'] *= random.uniform(1.2, 2.0)
return dfCode này tạo ra các subsets bao gồm:
- Nhiều volume types và instance types khác nhau
- Các mức độ utilization khác nhau
- Một số misconfigurations thỉnh thoảng xảy ra (ví dụ: underutilized volumes)
- Phân bố regional đa dạng
Tổng hợp và mở rộng tập dữ liệu
Quá trình combining and scaling synthetic data bao gồm việc hợp nhất nhiều bộ dữ liệu được tạo ra đồng thời thêm vào các realistic anomalies để tạo thành một bộ dữ liệu toàn diện và đại diện. Bước này rất quan trọng để đảm bảo rằng dữ liệu synthetic phản ánh đúng complexity và variability tồn tại trong các real-world scenarios. Các tổ chức thường thêm các controlled anomalies với một tỷ lệ cụ thể (thường là 5–10% của bộ dữ liệu) để mô phỏng các edge cases và các mẫu bất thường có thể xảy ra trong môi trường sản xuất. Những anomalies này giúp kiểm tra phản ứng của hệ thống, phát triển các giải pháp giám sát và huấn luyện các ML models để nhận diện các vấn đề tiềm ẩn.
Khi tạo dữ liệu synthetic cho các underutilized EBS volumes, bạn có thể thêm các anomalies như Oversized volumes (lớn hơn nhu cầu thực tế 5–10 lần), Volumes với old snapshots (cũ hơn 365 ngày), High-cost volumes với mức utilization thấp. Ví dụ, một bộ dữ liệu synthetic có thể bao gồm một 1 TB gp2 volume chỉ sử dụng 100 GB dung lượng, mô phỏng kịch bản thực tế về tài nguyên được overprovisioned. Xem code dưới đây:
import pandas as pd
import numpy as np
import random
def introduce_anomalies(df, anomaly_rate=0.1):
"""
Introduce various volume-related anomalies into the dataset.
:param df: The input DataFrame
:param anomaly_rate: The rate at which to introduce anomalies (default 10%)
:return: DataFrame with anomalies introduced
"""
num_anomalies = int(len(df) * anomaly_rate)
anomaly_indices = np.random.choice(df.index, num_anomalies, replace=False)
df['Anomaly'] = pd.NA # Initialize Anomaly column with pandas NA
for idx in anomaly_indices:
anomaly_type = random.choice([
'oversized_volume',
'old_snapshot',
'high_cost_low_size',
'mismatched_type',
'very_old_volume'
])
if anomaly_type == 'oversized_volume':
df.at[idx, 'Volume Size'] = int(df.at[idx, 'Volume Size'] * random.uniform(5, 10))
df.at[idx, 'Monthly Storage Cost'] *= random.uniform(5, 10)
elif anomaly_type == 'old_snapshot':
df.at[idx, 'Snapshot Age'] = random.randint(365, 1000)
elif anomaly_type == 'high_cost_low_size':
df.at[idx, 'Volume Size'] = random.randint(1, 10)
df.at[idx, 'Monthly Storage Cost'] *= random.uniform(10, 20)
elif anomaly_type == 'mismatched_type':
if df.at[idx, 'Volume Type'] in ['gp2', 'gp3']:
df.at[idx, 'Volume Type'] = random.choice(['io1', 'io2'])
else:
df.at[idx, 'Volume Type'] = random.choice(['gp2', 'gp3'])
elif anomaly_type == 'very_old_volume':
df.at[idx, 'Volume Name'] = f"old-volume-{random.randint(1, 100)}"
if pd.notna(df.at[idx, 'Snapshot Age']):
df.at[idx, 'Snapshot Age'] = random.randint(1000, 2000)
df.at[idx, 'Anomaly'] = anomaly_type
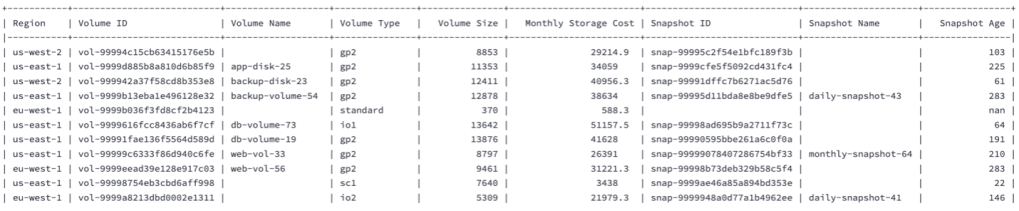
return dfHình chụp màn hình dưới đây minh họa ví dụ về các sample rows được tạo ra.
Kiểm định các phát hiện Trusted Advisor tổng hợp
Data validation là một bước quan trọng để xác minh quality, reliability, và representativeness (tính đại diện) của dữ liệu synthetic. Quá trình này bao gồm thực hiện các phân tích thống kê nghiêm ngặt để xác minh rằng dữ liệu được tạo duy trì các distributions, relationships, và patterns phù hợp với các real-world scenarios (kịch bản thực tế). Việc validation nên bao gồm cả các quantitative metrics (các statistical measures) và các qualitative assessments (phân tích pattern). Các tổ chức nên triển khai các comprehensive validation frameworks bao gồm distribution analysis, correlation checks, pattern verification, và anomaly detection. Việc visualization dữ liệu thường xuyên giúp nhận diện các inconsistencies hoặc các unexpected patterns.
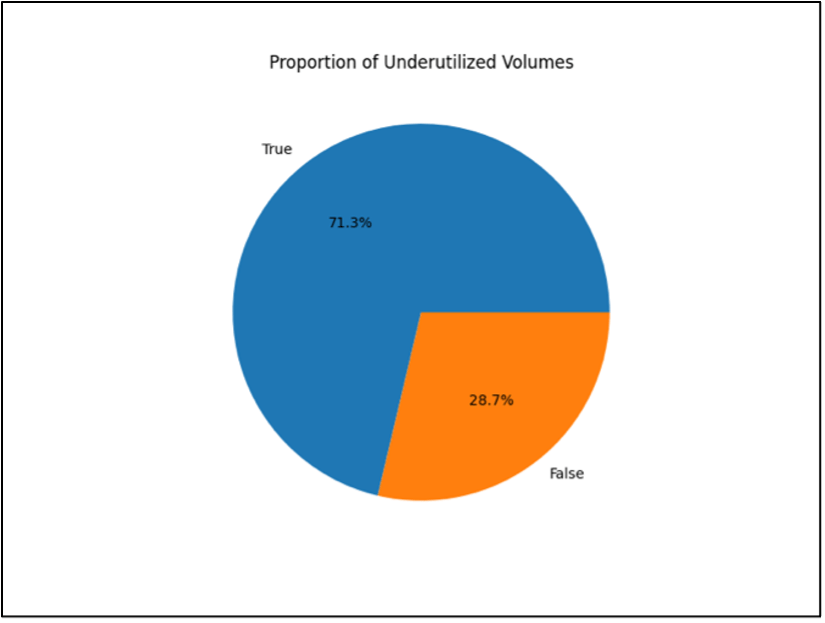
Đối với dữ liệu EBS volume, việc validation có thể bao gồm phân tích distribution of volume sizes trên các loại khác nhau (gp2, gp3, io1), xác minh rằng các cost correlations phù hợp với các expected patterns, và đảm bảo rằng các introduced anomalies (như underutilized volumes) duy trì tỷ lệ realistic. Ví dụ, xác minh rằng tỷ lệ underutilized volumes phù hợp với môi trường doanh nghiệp điển hình (khoảng 15–20% tổng số volumes) và rằng các mối quan hệ cost-to-size vẫn thực tế giữa các loại volume.
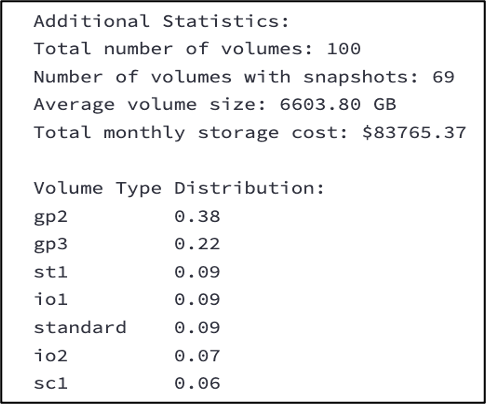
Các hình dưới đây minh họa ví dụ về các validation checks của chúng tôi.
- Hình chụp màn hình dưới đây hiển thị statistics của các synthetic datasets được tạo ra.
- Hình dưới đây minh họa proportion of underutilized volumes trong các synthetic datasets được tạo ra
- Hình dưới đây minh họa distribution of volume sizes trong các synthetic datasets được tạo ra.

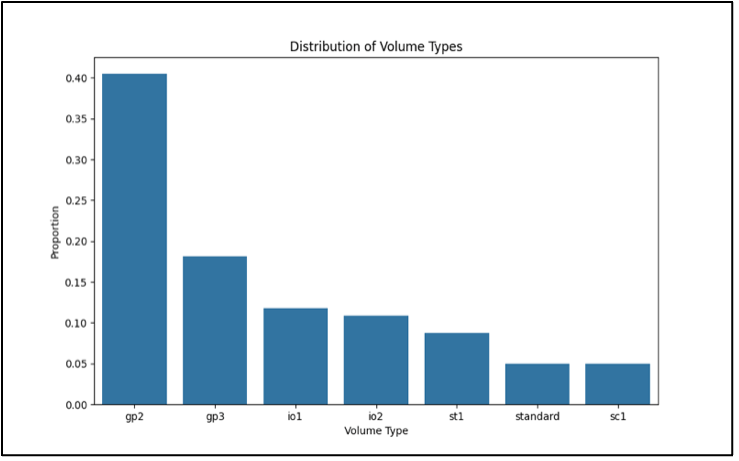
- Hình dưới đây minh họa distribution of volume types trong các synthetic datasets được tạo ra.
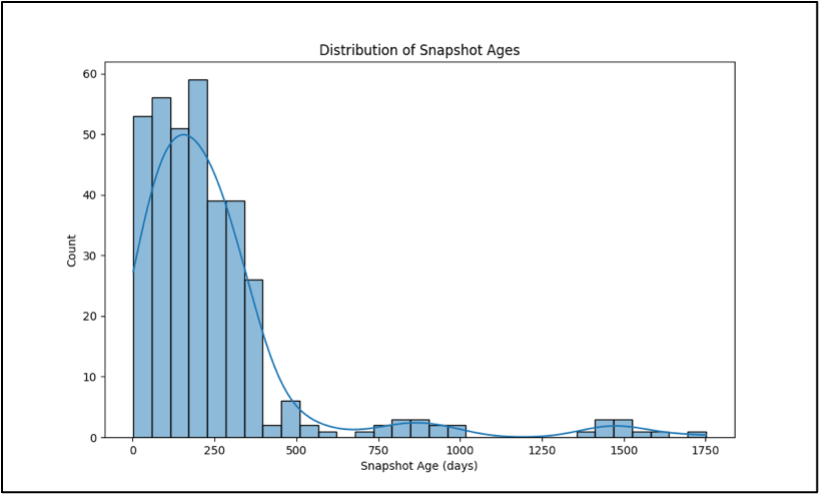
- Hình dưới đây minh họa distribution of snapshot ages trong các synthetic datasets được tạo ra.
Tăng cường dữ liệu tổng hợp bằng Tính riêng tư Vi sai
Sau khi khám phá các bước tạo synthetic datasets cho Trusted Advisor “Underutilized Amazon EBS Volumes” check, đáng giá xem lại cách differential privacy tăng cường phương pháp này. Khi một công ty tư vấn điện toán đám mây phân tích dữ liệu Trusted Advisor được aggregated từ nhiều khách hàng, differential privacy thông qua OpenDP cung cấp sự cân bằng quan trọng giữa privacy và utility. Bằng cách áp dụng carefully calibrated noise vào các phép tính thống kê về underutilized volumes, các tư vấn viên có thể tạo ra các synthetic datasets vừa bảo tồn các mẫu quan trọng giữa các Regions và volume types, vừa đảm bảo về mặt toán học individual client confidentiality. Phương pháp này đảm bảo rằng dữ liệu synthetic vẫn duy trì sufficient accuracy cho các phân tích xu hướng (trend analysis) và đưa ra khuyến nghị có ý nghĩa, đồng thời loại bỏ nguy cơ tiết lộ các chi tiết hạ tầng hoặc usage patterns nhạy cảm của từng khách hàng—làm cho đây trở thành một bổ sung lý tưởng cho synthetic data generation pipeline của chúng ta.
Tổng kết
Trong bài viết này, chúng tôi đã trình bày cách sử dụng Amazon Bedrock để tạo synthetic data cho nhu cầu doanh nghiệp. Bằng cách kết hợp các language models có sẵn trong Amazon Bedrock với kiến thức ngành, bạn có thể xây dựng một phương pháp flexible và secure để tạo dữ liệu thử nghiệm. Phương pháp này giúp tạo các bộ dữ liệu realistic mà không sử dụng thông tin nhạy cảm, tiết kiệm thời gian và chi phí. Nó cũng tạo điều kiện cho việc kiểm thử nhất quán (consistent testing) giữa các dự án và tránh các vấn đề đạo đức khi sử dụng dữ liệu thực của người dùng. Nhìn chung, chiến lược này cung cấp một giải pháp vững chắc cho các thách thức về dữ liệu, hỗ trợ các testing và development practices tốt hơn.
Trong phần 2 của loạt bài này, chúng tôi sẽ trình bày cách sử dụng pattern recognition cho các bộ dữ liệu khác nhau nhằm automate rule-set generation cần thiết cho các Amazon Bedrock prompts để tạo ra dữ liệu synthetic tương ứng.
Về tác giả

Devi Nair là Technical Account Manager tại Amazon Web Services, cung cấp hướng dẫn chiến lược cho các khách hàng doanh nghiệp khi họ xây dựng, vận hành và tối ưu hóa các workloads trên AWS. Cô tập trung vào việc aligning cloud solutions với các business objectives nhằm thúc đẩy long-term success và innovation.

Vishal Karlupia là Senior Technical Account Manager/Lead tại Amazon Web Services, Toronto. Anh chuyên về các ứng dụng generative AI và hỗ trợ khách hàng xây dựng cũng như mở rộng các AI/ML workloads trên AWS. Ngoài công việc, anh thích hoạt động ngoài trời và duy trì các bonfires.

Srinivas Ganapathi là Principal Technical Account Manager tại Amazon Web Services. Anh làm việc tại Toronto, Canada và hỗ trợ các khách hàng trong lĩnh vực games để vận hành các workloads hiệu quả trên AWS.

Nicolas Simard là Technical Account Manager làm việc tại Montreal. Anh hỗ trợ các tổ chức tăng tốc hành trình AI adoption thông qua technical expertise, các architectural best practices, và giúp họ tối đa hóa business value từ các khả năng Generative AI của AWS.
