Bởi: Avinash Desireddy và Suvojit Dasgupta
Ngày: 01 tháng 5 năm 2025
Chủ đề: Amazon EMR on EKS, Amazon Managed Workflows for Apache Airflow (Amazon MWAA), AWS Big Data, Cấp độ Trung cấp (200), Mã nguồn mở
Các workload Apache Spark chạy trên Amazon EMR on EKS là nền tảng của nhiều nền tảng dữ liệu hiện đại. EMR trên EKS mang lại lợi ích bằng cách cung cấp một môi trường Spark được quản lý, tích hợp liền mạch với các dịch vụ AWS khác và các mẫu triển khai dựa trên Kubernetes hiện có của tổ chức bạn.
Các nền tảng dữ liệu xử lý khối lượng dữ liệu quy mô lớn thường yêu cầu nhiều cụm EMR on EKS. Trong bài viết Sử dụng Batch Processing Gateway để tự động hóa quản lý công việc trong môi trường Amazon EMR on EKS đa cụm, chúng tôi đã giới thiệu Batch Processing Gateway (BPG) như một giải pháp để quản lý các workload Spark trên các cụm này. Mặc dù BPG cung cấp chức năng nền tảng để phân phối workload và hỗ trợ định tuyến cho các công việc Spark trong môi trường đa cụm, các nền tảng dữ liệu doanh nghiệp đòi hỏi các tính năng bổ sung cho một pipeline xử lý dữ liệu toàn diện.
Bài viết này chỉ ra cách nâng cao giải pháp đa cụm bằng cách tích hợp Amazon Managed Workflows for Apache Airflow (Amazon MWAA) với BPG. Bằng cách sử dụng Amazon MWAA, chúng tôi thêm vào khả năng lập lịch và điều phối công việc, cho phép bạn xây dựng một pipeline xử lý dữ liệu dựa trên Spark end-to-end toàn diện.
Tổng quan về giải pháp
Hãy xem xét HealthTech Analytics, một công ty phân tích y tế quản lý hai workload xử lý dữ liệu riêng biệt. Đội ngũ Khoa học Dữ liệu Clinical Insights của họ xử lý dữ liệu nhạy cảm về kết quả bệnh nhân, yêu cầu tuân thủ HIPAA và tài nguyên chuyên dụng. Trong khi đó, đội ngũ Digital Analytics xử lý dữ liệu tương tác website với các yêu cầu linh hoạt hơn. Khi hoạt động của họ phát triển, họ đối mặt với những thách thức ngày càng tăng trong việc quản lý hiệu quả các workload đa dạng này.
Công ty cần duy trì sự tách biệt nghiêm ngặt giữa việc xử lý thông tin sức khỏe được bảo vệ (PHI) và dữ liệu không phải PHI, đồng thời giải quyết các yêu cầu về trung tâm chi phí khác nhau. Đội ngũ Clinical Insights chạy các quy trình batch quan trọng vào cuối ngày cần tài nguyên được đảm bảo, trong khi đội ngũ Digital Analytics có thể sử dụng các spot instance được tối ưu hóa về chi phí cho các workload biến đổi của họ. Ngoài ra, các nhà khoa học dữ liệu từ cả hai đội đều yêu cầu môi trường để thử nghiệm và tạo mẫu khi cần.
Kịch bản này là một trường hợp sử dụng lý tưởng để triển khai pipeline dữ liệu bằng Amazon MWAA, BPG và nhiều cụm EMR on EKS. Giải pháp cần định tuyến các workload Spark khác nhau đến các cụm phù hợp dựa trên yêu cầu bảo mật và hồ sơ chi phí, trong khi vẫn duy trì sự cô lập và các biện pháp kiểm soát tuân thủ cần thiết. Để quản lý hiệu quả một môi trường như vậy, chúng ta cần một giải pháp duy trì sự tách biệt rõ ràng giữa các mối quan tâm về quản lý ứng dụng và cơ sở hạ tầng, và kết nối nhiều thành phần lại với nhau thành một pipeline mạnh mẽ.
Giải pháp của chúng tôi bao gồm việc tích hợp Amazon MWAA với BPG thông qua một Airflow custom operator cho BPG được gọi là BPGOperator. Operator này đóng gói logic quản lý cơ sở hạ tầng cần thiết để tương tác với BPG. BPGOperator cung cấp một giao diện rõ ràng để gửi công việc thông qua Amazon MWAA. Khi được thực thi, operator giao tiếp với BPG, sau đó BPG sẽ định tuyến các workload Spark đến các cụm EMR on EKS có sẵn dựa trên các quy tắc định tuyến được xác định trước.
Sơ đồ kiến trúc sau đây minh họa các thành phần và sự tương tác của chúng.
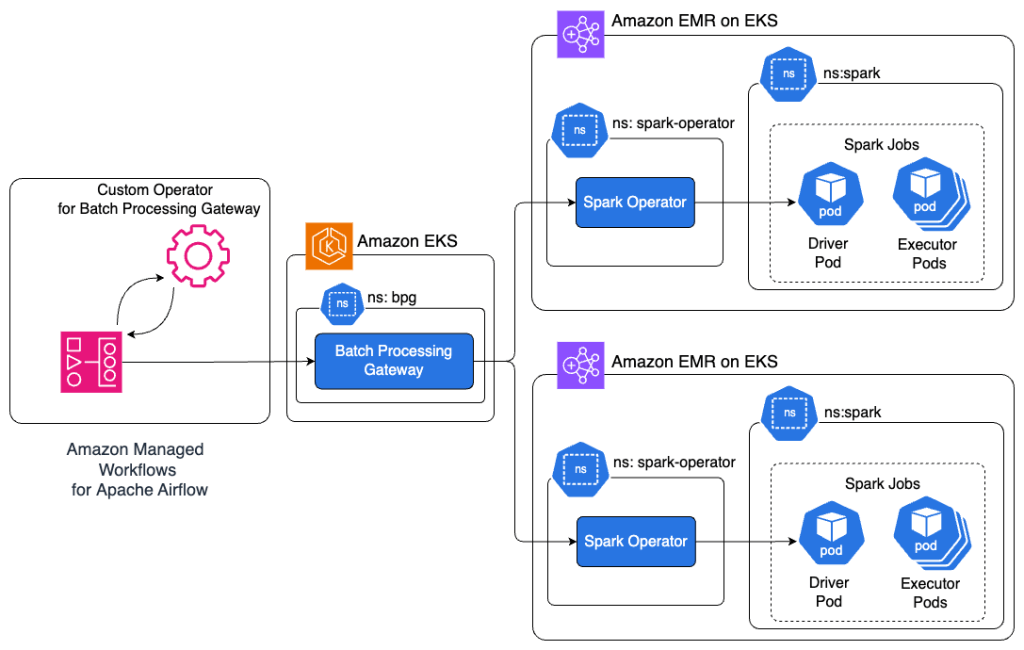
Giải pháp hoạt động qua các bước sau:
- Amazon MWAA thực thi các DAGs đã được lập lịch bằng BPGOperator. Các kỹ sư dữ liệu tạo DAG bằng operator này, chỉ yêu cầu tệp cấu hình ứng dụng Spark và các tham số lập lịch cơ bản.
- BPGOperator xác thực và gửi công việc đến endpoint của BPG POST:/apiv2/spark. Nó xử lý tất cả các chi tiết giao tiếp HTTP, quản lý token xác thực và cung cấp việc truyền tải an toàn các cấu hình công việc.
- BPG định tuyến các công việc đã gửi đến các cụm EMR on EKS dựa trên các quy tắc định tuyến được xác định trước. Các quy tắc này được quản lý tập trung thông qua cấu hình của BPG, cho phép phân phối workload dựa trên quy tắc trên nhiều cụm.
- BPGOperator giám sát trạng thái công việc, ghi lại log và xử lý việc thử lại thực thi. Nó thăm dò endpoint trạng thái công việc của BPG GET:/apiv2/spark/{subID}/status và truyền log đến Airflow bằng cách thăm dò endpoint GET:/apiv2/log mỗi giây. Endpoint log của BPG lấy thông tin log mới nhất trực tiếp từ Spark Driver Pod.
- Việc thực thi DAG tiến tới các task tiếp theo dựa trên trạng thái hoàn thành của công việc và các phụ thuộc đã xác định. BPGOperator truyền đạt trạng thái công việc thông qua hệ thống giao tiếp task tích hợp của Airflow, cho phép điều phối workflow phức tạp.
Tham khảo tài liệu giao diện REST API của BPG để biết thêm chi tiết.
Kiến trúc này cung cấp một số lợi ích chính:
- Tách biệt trách nhiệm – Các đội Kỹ thuật Dữ liệu và Kỹ thuật Nền tảng trong các tổ chức doanh nghiệp thường duy trì các trách nhiệm riêng biệt. Thiết kế mô-đun trong giải pháp này cho phép các kỹ sư nền tảng cấu hình BPGOperator và quản lý các cụm EMR on EKS, trong khi các kỹ sư dữ liệu duy trì DAGs.
- Quản lý mã nguồn tập trung – BPGOperator đóng gói tất cả các chức năng cốt lõi cần thiết để các DAG của Amazon MWAA gửi công việc Spark thông qua BPG vào một mô-đun Python duy nhất, có thể tái sử dụng. Việc tập trung này giảm thiểu sự trùng lặp mã nguồn giữa các DAG và cải thiện khả năng bảo trì bằng cách cung cấp một giao diện chuẩn hóa để gửi công việc.
Airflow custom operator cho BPG
Một Operator trong Airflow là một mẫu cho một Task được xác định trước mà bạn có thể định nghĩa một cách khai báo bên trong DAG của mình. Airflow cung cấp nhiều operator tích hợp sẵn như BashOperator để thực thi các lệnh bash, PythonOperator để thực thi các hàm Python, và EmrContainerOperator để gửi công việc mới đến một cụm EMR on EKS. Tuy nhiên, không có operator tích hợp nào để thực hiện tất cả các bước cần thiết cho việc tích hợp Amazon MWAA với BPG.
Airflow cho phép bạn tạo các operator mới để phù hợp với yêu cầu cụ thể của mình. Loại operator này được gọi là custom operator. Một custom operator đóng gói logic liên quan đến cơ sở hạ tầng tùy chỉnh vào một thành phần duy nhất, có thể bảo trì. Custom operator được tạo bằng cách mở rộng lớp airflow.models.baseoperator.BaseOperator. Chúng tôi đã phát triển và mã nguồn mở một Airflow custom operator cho BPG có tên là BPGOperator, thực hiện các bước cần thiết để cung cấp sự tích hợp liền mạch của Amazon MWAA với BPG.
Sơ đồ lớp sau đây cung cấp một cái nhìn chi tiết về việc triển khai BPGOperator.

Khi một DAG bao gồm một task BPGOperator, instance của Amazon MWAA sẽ kích hoạt operator để gửi một yêu cầu công việc đến BPG. Operator thường thực hiện các bước sau:
- Khởi tạo công việc – BPGOperator chuẩn bị payload của công việc, bao gồm các tham số đầu vào, cấu hình, chi tiết kết nối và các siêu dữ liệu khác mà BPG yêu cầu.
- Gửi công việc – BPGOperator xử lý các yêu cầu HTTP POST để gửi công việc đến các endpoint của BPG với các cấu hình đã cung cấp.
- Giám sát thực thi công việc – BPGOperator kiểm tra trạng thái công việc, thăm dò BPG cho đến khi công việc hoàn thành thành công hoặc thất bại. Quá trình giám sát bao gồm xử lý các trạng thái công việc khác nhau, quản lý các kịch bản timeout và phản ứng với các lỗi xảy ra trong quá trình thực thi công việc.
- Xử lý hoàn thành công việc – Khi hoàn thành, BPGOperator ghi lại kết quả của công việc, log các chi tiết liên quan và có thể kích hoạt các task sau đó dựa trên kết quả thực thi.
Sơ đồ tuần tự sau đây minh họa luồng tương tác giữa Airflow DAG, BPGOperator và BPG.

Triển khai giải pháp
Trong phần còn lại của bài viết này, bạn sẽ triển khai pipeline end-to-end để chạy các công việc Spark trên nhiều cụm EMR on EKS. Bạn sẽ bắt đầu bằng cách triển khai các thành phần chung làm nền tảng để xây dựng các pipeline. Tiếp theo, bạn sẽ triển khai và cấu hình BPG trên một cụm EKS, sau đó là triển khai và cấu hình BPGOperator trên Amazon MWAA. Cuối cùng, bạn sẽ thực thi các công việc Spark trên nhiều cụm EMR on EKS từ Amazon MWAA.
Để hợp lý hóa quá trình cài đặt, chúng tôi đã tự động hóa việc triển khai tất cả các thành phần cơ sở hạ tầng cần thiết cho bài viết này, vì vậy bạn có thể tập trung vào các khía cạnh thiết yếu của việc gửi công việc để xây dựng một pipeline end-to-end. Chúng tôi cung cấp thông tin chi tiết để giúp bạn hiểu từng bước, đơn giản hóa việc thiết lập trong khi vẫn giữ được trải nghiệm học hỏi.
Để trình diễn giải pháp, bạn sẽ tạo ba cụm và một môi trường Amazon MWAA:
- Hai cụm EMR on EKS: analytics-cluster và datascience-cluster
- Một cụm EKS: gateway-cluster
- Một môi trường Amazon MWAA: airflow-environment
analytics-cluster và datascience-cluster đóng vai trò là các cụm xử lý dữ liệu chạy các workload Spark, gateway-cluster lưu trữ BPG, và airflow-environment lưu trữ Airflow để điều phối và lập lịch công việc.
Bạn có thể tìm mã nguồn trong kho lưu trữ GitHub.
Điều kiện tiên quyết
Trước khi triển khai giải pháp này, hãy đảm bảo rằng các điều kiện tiên quyết sau đã được đáp ứng:
- Quyền truy cập vào một tài khoản AWS hợp lệ
- AWS Command Line Interface (AWS CLI) được cài đặt trên máy cục bộ của bạn
- Các tiện ích Git, Docker, eksctl, kubectl, Helm, và jq được cài đặt trên máy cục bộ của bạn
- Quyền tạo tài nguyên AWS
- Quen thuộc với Kubernetes, Amazon MWAA, Apache Spark, Amazon Elastic Kubernetes Service (Amazon EKS), và Amazon EMR on EKS
Cài đặt cơ sở hạ tầng chung
Bước này xử lý việc cài đặt cơ sở hạ tầng mạng, bao gồm virtual private cloud (VPC) và subnets, cùng với việc cấu hình các vai trò AWS Identity and Access Management (IAM), lưu trữ Amazon Simple Storage Service (Amazon S3), kho lưu trữ Amazon Elastic Container Registry (Amazon ECR) cho các image BPG, cơ sở dữ liệu Amazon Aurora PostgreSQL-Compatible Edition, môi trường Amazon MWAA, và cả cụm EKS và EMR on EKS với một Spark operator được cấu hình sẵn. Với cơ sở hạ tầng này được cấp phát tự động, bạn có thể tập trung vào các bước tiếp theo mà không bị vướng vào các tác vụ cài đặt cơ bản.
Clone kho lưu trữ về máy cục bộ của bạn và đặt hai biến môi trường. Thay thế <AWS_REGION> bằng Vùng AWS nơi bạn muốn triển khai các tài nguyên này.
git clone [https://github.com/aws-samples/sample-mwaa-bpg-emr-on-eks-spark-pipeline.git](https://github.com/aws-samples/sample-mwaa-bpg-emr-on-eks-spark-pipeline.git)
cd sample-mwaa-bpg-emr-on-eks-spark-pipeline
export REPO_DIR=$(pwd)
export AWS_REGION=<AWS_REGION>Thực thi script sau để tạo cơ sở hạ tầng chung:
cd ${REPO_DIR}/infra
./setup.shĐể xác minh việc triển khai cơ sở hạ tầng thành công, hãy điều hướng đến bảng điều khiển AWS CloudFormation, mở stack của bạn và kiểm tra các tab Events, Resources, và Outputs để xem trạng thái hoàn thành, chi tiết và danh sách các tài nguyên đã tạo.
Bạn đã hoàn thành việc thiết lập các thành phần chung làm nền tảng cho phần còn lại của việc triển khai.
Cài đặt Batch Processing Gateway
Phần này xây dựng image Docker cho BPG, triển khai helm chart trên cụm EKS gateway-cluster, và phơi bày endpoint của BPG bằng cách sử dụng service Kubernetes loại LoadBalancer. Hoàn thành các bước sau:
- Triển khai BPG trên cụm EKS gateway-cluster:
cd ${REPO_DIR}/infra/bpg
./configure_bpg.sh- Xác minh việc triển khai bằng cách liệt kê các pod và xem log của pod:
kubectl get pods –namespace bpg
kubectl logs <BPG-PODNAME> --namespace bpgXem lại các log và xác nhận không có lỗi hoặc ngoại lệ.
- Exec vào pod BPG và xác minh health check:
kubectl exec -it <BPG-PODNAME> -n bpg — bash
curl -u admin:admin localhost:8080/skatev2/healthcheck/statusAPI healthcheck sẽ trả về phản hồi thành công là {“status”:”OK”}, xác nhận việc triển khai BPG thành công trên cụm EKS gateway-cluster.
Chúng ta đã cấu hình thành công BPG trên gateway-cluster và thiết lập EMR on EKS cho cả datascience-cluster và analytics-cluster. Đây là điểm chúng ta đã dừng lại trong bài blog trước. Trong các bước tiếp theo, chúng ta sẽ cấu hình Amazon MWAA với BPGOperator, sau đó viết và gửi DAG để minh họa một pipeline dữ liệu dựa trên Spark end-to-end.
Phần này cấu hình plugin BPGOperator trên môi trường Amazon MWAA airflow-environment.
Cấu hình BPGOperator trên Amazon MWAA:
cd ${REPO_DIR}/bpg_operator
./configure_bpg_operator.sh- Trên bảng điều khiển Amazon MWAA, điều hướng đến môi trường airflow-environment.
- Chọn Open Airflow UI, và trong giao diện Airflow, chọn menu thả xuống Admin và chọn Plugins.
- Bạn sẽ thấy plugin BPGOperator được liệt kê trong giao diện Airflow.

Cấu hình Airflow connections cho tích hợp BPG
Phần này hướng dẫn bạn thiết lập các Airflow connection cho phép giao tiếp an toàn giữa môi trường Amazon MWAA và BPG. BPGOperator sử dụng connection đã cấu hình để xác thực và tương tác với các endpoint của BPG.
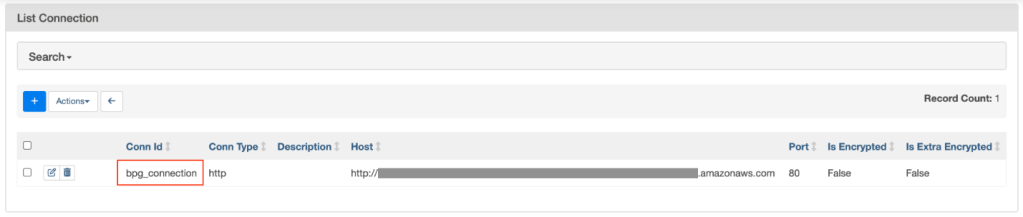
Thực thi script sau để cấu hình Airflow connection bpg_connection:
cd $REPO_DIR/airflow
./configure_connections.shTrong giao diện Airflow, chọn menu thả xuống Admin và chọn Connections. Bạn sẽ thấy bpg_connection được liệt kê.
Cấu hình Airflow DAG để thực thi các công việc Spark
Bước này cấu hình một Airflow DAG để chạy một ứng dụng mẫu. Cụ thể, chúng tôi sẽ gửi một DAG chứa nhiều công việc Spark mẫu bằng Amazon MWAA đến các cụm EMR on EKS sử dụng BPG. Vui lòng đợi vài phút để DAG xuất hiện trong giao diện Airflow.
cd $REPO_DIR/công việcs
./configure_công việc.shKích hoạt Amazon MWAA DAG
Trong bước này, chúng tôi kích hoạt Airflow DAG và quan sát hành vi thực thi công việc, bao gồm cả việc xem lại log Spark trong giao diện Airflow:
- Trong giao diện Airflow, xem lại DAG MWAASparkPipelineDemocông việc và chọn biểu tượng play để kích hoạt DAG.

- Đợi DAG hoàn thành thành công.
- Khi DAG hoàn thành thành công, bạn sẽ thấy Success:1 dưới cột Runs.
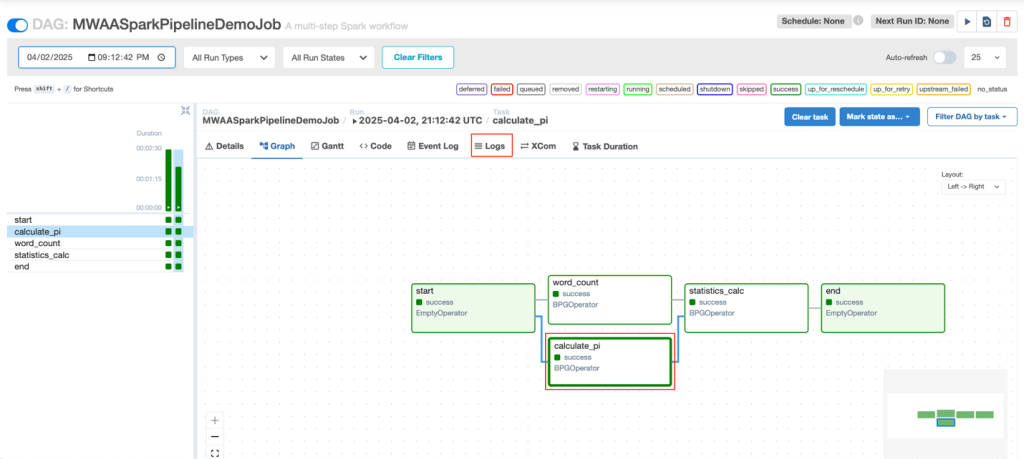
- Trong giao diện Airflow, tìm và chọn DAG MWAASparkPipelineDemocông việc.
- Trên tab Graph, chọn bất kỳ task nào (ví dụ, chúng tôi chọn task calculate_pi) và sau đó chọn Logs.
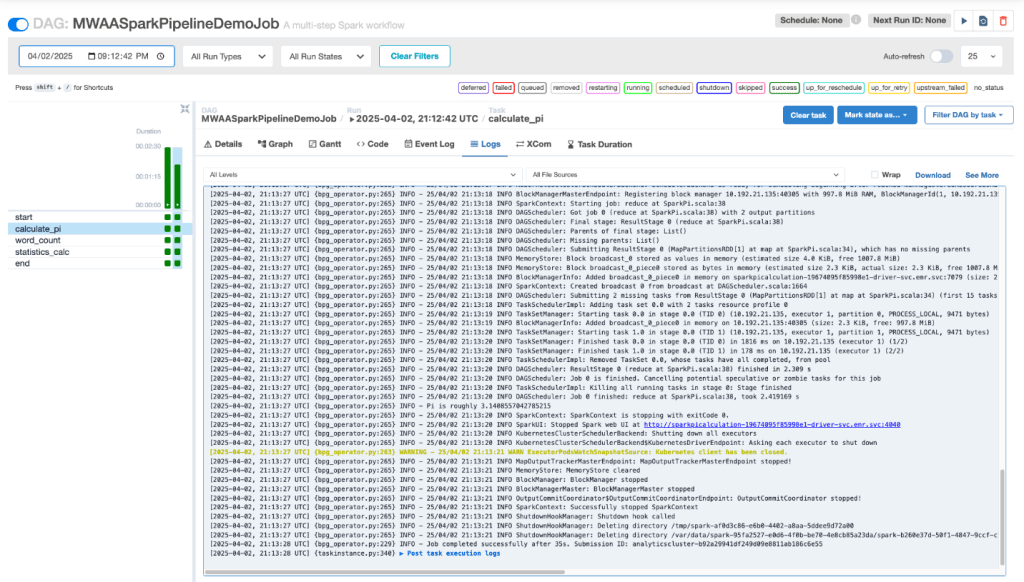
- Xem log Spark trong giao diện Airflow.
Di chuyển các DAG Airflow hiện có để sử dụng BPG
Trong các nền tảng dữ liệu doanh nghiệp, một pipeline dữ liệu điển hình bao gồm Amazon MWAA gửi các công việc Spark đến nhiều cụm EMR on EKS bằng cách sử dụng SparkKubernetesOperator và một Airflow Connection loại Kubernetes. Một Airflow Connection là một tập hợp các tham số và thông tin xác thực được sử dụng để thiết lập giao tiếp giữa Amazon MWAA và các hệ thống hoặc dịch vụ bên ngoài. Một DAG tham chiếu đến tên connection và kết nối đến hệ thống bên ngoài.
Sơ đồ sau đây cho thấy kiến trúc điển hình.
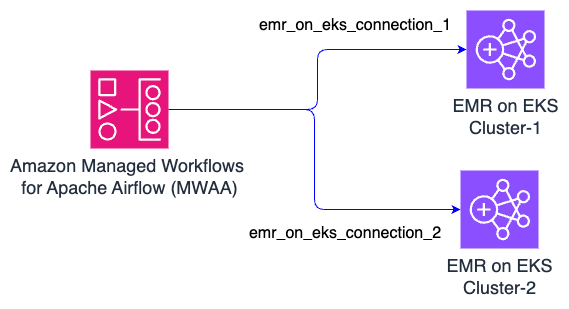
Trong thiết lập này, các DAG Airflow thường sử dụng SparkKubernetesOperator và SparkKubernetesSensor để gửi công việc Spark đến một cụm EMR on EKS từ xa bằng cách sử dụng kubernetes_conn_id=<connection_name>.
# Gửi công việc Spark-Pi bằng Kubernetes connection
submit_spark_pi = SparkKubernetesOperator(
task_id='submit_spark_pi',
namespace='default',
application_file=spark_pi_yaml,
kubernetes_conn_id='emr_on_eks_connection_[1|2]', # Connection ID được định nghĩa trong Airflow
dag=dag)Để di chuyển cơ sở hạ tầng sang cơ sở hạ tầng dựa trên BPG mà không ảnh hưởng đến tính liên tục của môi trường, chúng ta có thể triển khai một cơ sở hạ tầng song song sử dụng BPG, tạo một Airflow Connection mới cho BPG, và di chuyển dần các DAG để sử dụng connection mới. Bằng cách làm như vậy, chúng ta sẽ không làm gián đoạn cơ sở hạ tầng hiện có cho đến khi cơ sở hạ tầng dựa trên BPG hoàn toàn hoạt động, bao gồm cả việc di chuyển tất cả các DAG hiện có.
Sơ đồ sau đây giới thiệu trạng thái tạm thời nơi cả kết nối Kubernetes và kết nối BPG đều hoạt động. Mũi tên màu xanh chỉ ra các đường dẫn workflow hiện có, và mũi tên màu đỏ đại diện cho các đường dẫn di chuyển mới dựa trên BPG.
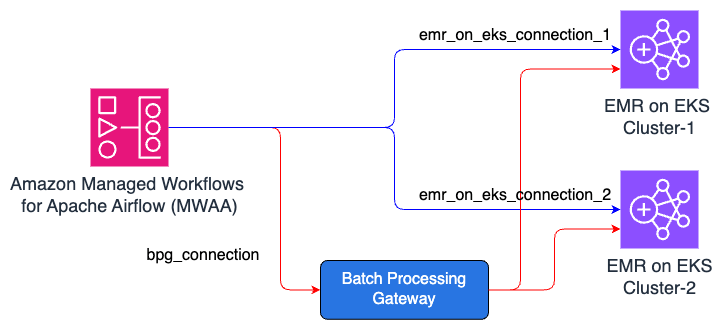
Đoạn mã được sửa đổi cho DAG như sau:
# Gửi công việc Spark-Pi bằng BPG connection
submit_spark_pi = BPGOperator(
task_id='submit_spark_pi',
application_file=spark_pi_yaml,
application_file_type='yaml',
connection_id='bpg_connection', # Connection ID được định nghĩa trong Airflow
dag=dag)Cuối cùng, khi tất cả các DAG đã được sửa đổi để sử dụng BPGOperator thay vì SparkKubernetesOperator, bạn có thể ngừng hoạt động bất kỳ tàn dư nào của workflow cũ. Trạng thái cuối cùng của cơ sở hạ tầng sẽ trông giống như sơ đồ sau.

Sử dụng phương pháp này, chúng ta có thể tích hợp BPG một cách liền mạch vào một môi trường hiện chỉ sử dụng Amazon MWAA và các cụm EMR on EKS.
Dọn dẹp
Để tránh phát sinh các khoản phí trong tương lai từ các tài nguyên được tạo trong hướng dẫn này, hãy dọn dẹp môi trường của bạn sau khi đã hoàn thành các bước. Bạn có thể làm điều này bằng cách chạy script cleanup.sh, script này sẽ xóa an toàn tất cả các tài nguyên đã được cấp phát trong quá trình thiết lập:
cd ${REPO_DIR}/setup
./cleanup.shKết luận
Trong bài viết Sử dụng Batch Processing Gateway để tự động hóa quản lý công việc trong môi trường Amazon EMR on EKS đa cụm, chúng tôi đã giới thiệu Batch Processing Gateway như một giải pháp để định tuyến các workload Spark trên nhiều cụm EMR on EKS. Trong bài viết này, chúng tôi đã chứng minh cách nâng cao nền tảng này bằng cách tích hợp BPG với Amazon MWAA. Thông qua BPGOperator tùy chỉnh của chúng tôi, chúng tôi đã chỉ ra cách xây dựng các pipeline xử lý dữ liệu dựa trên Spark end-to-end mạnh mẽ trong khi vẫn duy trì sự tách biệt rõ ràng về trách nhiệm và quản lý mã nguồn tập trung. Cuối cùng, chúng tôi đã chứng minh cách tích hợp liền mạch giải pháp vào nền tảng dữ liệu Amazon MWAA và EMR on EKS hiện có của bạn mà không ảnh hưởng đến tính liên tục hoạt động.
Chúng tôi khuyến khích bạn thử nghiệm kiến trúc này trong môi trường của riêng mình, điều chỉnh nó để phù hợp với các workload và yêu cầu hoạt động độc đáo của bạn. Bằng cách triển khai giải pháp này, bạn có thể xây dựng các pipeline xử lý dữ liệu hiệu quả và có khả năng mở rộng, tận dụng toàn bộ tiềm năng của EMR on EKS và Amazon MWAA. Hãy khám phá thêm bằng cách triển khai giải pháp trong tài khoản AWS của bạn trong khi tuân thủ các phương pháp bảo mật tốt nhất của tổ chức và chia sẻ kinh nghiệm của bạn với cộng đồng Dữ liệu lớn của AWS.
Về các tác giả

Suvojit Dasgupta là một Kiến trúc sư Dữ liệu Chính tại AWS. Anh dẫn dắt một đội ngũ kỹ sư lành nghề trong việc thiết kế và xây dựng các giải pháp dữ liệu có khả năng mở rộng cho khách hàng của AWS. Anh chuyên phát triển và triển khai các kiến trúc dữ liệu sáng tạo để giải quyết các thách thức kinh doanh phức tạp.

Avinash Desireddy là một Kiến trúc sư Cơ sở hạ tầng Đám mây tại AWS, đam mê xây dựng các ứng dụng và nền tảng dữ liệu an toàn. Anh có kinh nghiệm sâu rộng về Kubernetes, DevOps và kiến trúc doanh nghiệp, giúp khách hàng container hóa ứng dụng, hợp lý hóa việc triển khai và tối ưu hóa môi trường cloud-native.
