by Deepak Dalakoti, Kai Zhu, Melanie Li, Rafa Xu, and Sam Edwards on 21 APR 2025 in Advanced (300), Amazon Bedrock, Amazon Nova, Customer Solutions Permalink Comments Share
Các mô hình ngôn ngữ lớn (Large Language Model – LLM) đã trở thành một phần không thể thiếu trong nhiều ứng dụng thuộc các ngành khác nhau — từ việc nâng cao tương tác với khách hàng cho đến tự động hóa các quy trình kinh doanh. Việc triển khai các mô hình này trong môi trường thực tế đặt ra nhiều thách thức đáng kể, đặc biệt là trong việc đảm bảo độ chính xác, tính công bằng, mức độ liên quan, và giảm thiểu hiện tượng ảo giác (hallucination). Do đó, việc đánh giá toàn diện hiệu năng và đầu ra của các mô hình này là rất quan trọng để duy trì niềm tin và an toàn.
Việc đánh giá (Evaluation) đóng vai trò trung tâm trong vòng đời của ứng dụng generative AI, tương tự như trong machine learning truyền thống. Các phương pháp đánh giá vững chắc giúp đưa ra các quyết định sáng suốt liên quan đến việc lựa chọn mô hình và prompt. Tuy nhiên, việc đánh giá LLM là một quá trình phức tạp và tốn nhiều tài nguyên, do đầu ra của chúng là văn bản tự do (free-form text). Các phương pháp như đánh giá thủ công (human evaluation) mang lại những hiểu biết quý giá nhưng lại tốn kém và khó mở rộng quy mô. Vì vậy, có một nhu cầu rõ ràng về các framework đánh giá tự động, có thể mở rộng linh hoạt và tích hợp trực tiếp vào quy trình phát triển ứng dụng, tương tự như unit test và integration test trong phát triển phần mềm.
Trong bài viết này, nhằm giải quyết những thách thức đã nêu, chúng tôi giới thiệu một framework đánh giá tự động có thể triển khai trên AWS. Giải pháp này có thể tích hợp nhiều LLM khác nhau, sử dụng các thước đo đánh giá tùy chỉnh, và cho phép doanh nghiệp liên tục theo dõi hiệu năng của mô hình. Chúng tôi cũng cung cấp các chỉ số đánh giá sử dụng LLM làm giám khảo (LLM-as-a-judge metrics) bằng cách sử dụng các mô hình Amazon Nova mới được phát hành. Các mô hình này cho phép đánh giá trên quy mô lớn nhờ khả năng mạnh mẽ và độ trễ thấp. Ngoài ra, chúng tôi còn cung cấp giao diện thân thiện với người dùng để tăng tính dễ sử dụng.
Trong các phần tiếp theo, chúng tôi sẽ thảo luận về các phương pháp đánh giá LLM khác nhau, sau đó trình bày quy trình đánh giá điển hình, và cuối cùng là giải pháp dựa trên AWS giúp tự động hóa quy trình này.
Các phương pháp đánh giá
Trước khi triển khai các quy trình đánh giá cho giải pháp generative AI, điều quan trọng là cần xác định rõ các chỉ số (metrics) và tiêu chí đánh giá, đồng thời thu thập bộ dữ liệu đánh giá (evaluation dataset).
Bộ dữ liệu đánh giá cần phản ánh đúng trường hợp sử dụng thực tế. Nó nên bao gồm nhiều mẫu đa dạng và lý tưởng nhất là có giá trị thực tế/dữ liệu chuẩn (ground truth) được tạo bởi các chuyên gia. Quy mô của bộ dữ liệu sẽ phụ thuộc vào ứng dụng cụ thể và chi phí thu thập dữ liệu; tuy nhiên, tối thiểu bộ dữ liệu cần phải bao quát được các trường hợp sử dụng có liên quan và đa dạng.
Việc xây dựng bộ dữ liệu đánh giá có thể là một quá trình lặp lại, được cải thiện dần theo thời gian bằng cách bổ sung các mẫu mới và thêm những mẫu mà mô hình thể hiện chưa tốt.
Sau khi có bộ dữ liệu đánh giá, ta có thể xác định các tiêu chí đánh giá (evaluation criteria).
Các tiêu chí đánh giá này có thể được chia thành ba nhóm chính:
- Latency-based metrics – Bao gồm các phép đo như thời gian tạo phản hồi (response generation time) hoặc thời gian đến token đầu tiên (time to first token). Mức độ quan trọng của từng chỉ số có thể thay đổi tùy theo ứng dụng cụ thể.
- Cost – Liên quan đến chi phí phát sinh trong quá trình tạo phản hồi.
- Performance – Các chỉ số dựa trên hiệu năng thường phụ thuộc mạnh vào từng trường hợp sử dụng. Chúng có thể bao gồm độ chính xác (accuracy), tính nhất quán về mặt thông tin (factual consistency), hoặc khả năng tạo phản hồi có cấu trúc (structured responses).
Thông thường, có một mối quan hệ nghịch đảo giữa latency, cost và performance. Tùy vào use case, một yếu tố có thể quan trọng hơn các yếu tố khác.
Việc xây dựng các metrics cho ba nhóm này trên nhiều mô hình khác nhau giúp bạn ra quyết định dựa trên dữ liệu, nhằm xác định lựa chọn tối ưu cho từng trường hợp cụ thể.
Mặc dù việc đo lường latency và cost tương đối đơn giản, nhưng đánh giá performance lại đòi hỏi hiểu sâu về use case và biết rõ yếu tố nào quyết định thành công.
Tùy vào ứng dụng, bạn có thể muốn đánh giá độ chính xác về mặt dữ kiện (factual accuracy) của đầu ra mô hình (đặc biệt khi phản hồi dựa trên các dữ kiện hoặc tài liệu tham chiếu cụ thể), hoặc đánh giá mức độ lịch sự và hữu ích trong phản hồi của mô hình — hoặc cả hai.
Để hỗ trợ các kịch bản đa dạng này, chúng tôi đã tích hợp một số evaluation metrics trong giải pháp của mình:
- FMEval – Thư viện Foundation Model Evaluation (FMEval) do AWS cung cấp, mang đến các các mô hình đánh giá chuyên dụng (purpose-built) để đo các chỉ số như toxicity trong output của LLM, độ chính xác (accuracy), và độ tương đồng ngữ nghĩa (semantic similarity) giữa văn bản tạo ra và văn bản tham chiếu. Thư viện này có thể được sử dụng để đánh giá LLM trên nhiều nhiệm vụ khác nhau như tạo văn bản mở (open-ended generation), text summarization, question answering, và classification.
- Ragas – Ragas là một framework open source cung cấp các metrics để đánh giá các hệ thống Retrieval Augmented Generation (RAG) (các hệ thống tạo câu trả lời dựa trên một ngữ cảnh đã cho). Ragas có thể dùng để đánh giá hiệu suất của một information retriever (thành phần lấy thông tin liên quan từ cơ sở dữ liệu) thông qua các metrics như ộ chính xác ngữ cảnh (context precision) và độ phủ (recall). Ragas cũng cung cấp các metrics để đánh giá việc LLM generation từ ngữ cảnh đã cho, sử dụng các metrics như Độ trung thực (Faithfulness) với ngữ cảnh cung cấp và answer relevance với câu hỏi gốc.
- LLMeter – LLMeter là giải pháp đơn giản để kiểm tra latency và throughput của LLM, chẳng hạn như các LLM được cung cấp thông qua Amazon Bedrock và OpenAI. Điều này hữu ích trong việc so sánh các mô hình theo các chỉ số cho latency-critical workloads.
- LLM-as-a-judge metrics – Việc định nghĩa các performance metrics cho văn bản tự do (free form text) do LLM tạo ra gặp nhiều thách thức – ví dụ, cùng một thông tin có thể được diễn đạt theo cách khác nhau. Cũng rất khó để định nghĩa rõ ràng các metrics để đo các đặc tính như politeness. Để giải quyết vấn đề này, các LLM-as-a-judge metrics đã trở nên phổ biến. LLM-as-a-judge evaluations sử dụng một LLM đóng vai trò thẩm phán (judge LLM) để chấm điểm output của LLM dựa trên các tiêu chí đã được định nghĩa trước. Chúng tôi sử dụng Amazon Nova model làm judge nhờ vào độ chính xác và hiệu suất tiên tiến của nó.
Evaluation workflow
Bây giờ khi chúng ta đã xác định được các metrics quan trọng, làm thế nào để đánh giá giải pháp của mình? Quá trình phát triển ứng dụng generative AI điển hình (proof of concept) có thể được trừu tượng hóa như sau:
- Các builder sử dụng một vài ví dụ thử nghiệm và thử nhiều prompt khác nhau để xem hiệu suất và có ý tưởng sơ bộ về prompt template và mô hình (model) họ muốn bắt đầu (online evaluation).
- Các builder thử nghiệm phiên bản đầu tiên của prompt template với một LLM đã chọn trên một test dataset có ground truth để đo lường danh sách các evaluation metrics và kiểm tra hiệu suất (offline evaluation). Dựa trên kết quả đánh giá, họ có thể cần chỉnh sửa prompt template, fine-tune mô hình, hoặc triển khai RAG để thêm ngữ cảnh bổ sung nhằm cải thiện hiệu suất.
- Các builder triển khai thay đổi và đánh giá giải pháp đã cập nhật trên dataset để xác nhận cải tiến. Sau đó, họ lặp lại các bước trước cho đến khi hiệu suất của giải pháp phát triển đáp ứng yêu cầu kinh doanh.
Hai giai đoạn chính trong quy trình đánh giá là:
- Online evaluation – Bao gồm đánh giá prompt thủ công dựa trên một vài ví dụ để kiểm tra định tính (qualitative checks).
- Offline evaluation – Bao gồm đánh giá định lượng (quantitative evaluation) tự động trên evaluation dataset.
Quy trình này có thể gây ra nhiều phức tạp và nỗ lực vận hành đáng kể từ đội builder và đội operations. Để thực hiện workflow này, bạn cần:
- Một công cụ so sánh side-by-side cho các LLM khác nhau.
- Một dịch vụ quản lý prompt có thể dùng để lưu và quản lý phiên bản prompt.
- Một dịch vụ batch inference có thể gọi LLM đã chọn trên số lượng lớn ví dụ.
- Một dịch vụ batch evaluation có thể dùng để đánh giá phản hồi LLM được tạo ra ở bước trước.
Trong phần tiếp theo, chúng tôi sẽ mô tả cách tạo workflow này trên AWS.
Solution overview
Trong phần này, chúng tôi trình bày một giải pháp automated generative AI evaluation có thể được sử dụng để đơn giản hóa quy trình đánh giá. Sơ đồ kiến trúc (architecture diagram) của giải pháp được minh họa trong hình dưới đây.
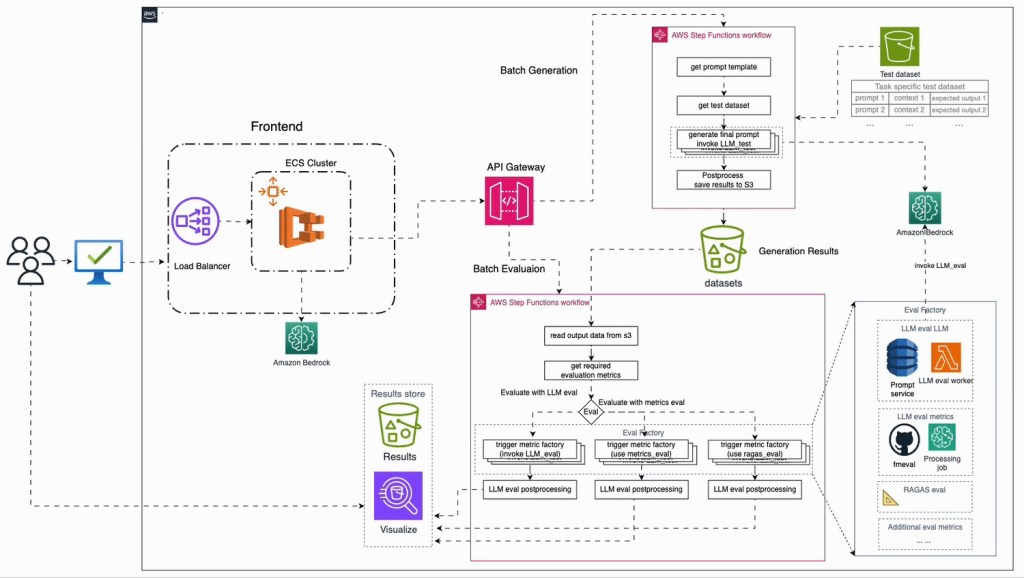
Giải pháp này cung cấp cả hai tùy chọn đánh giá online (so sánh thời gian thực) và offline (đánh giá theo batch), đáp ứng các nhu cầu khác nhau trong vòng đời phát triển giải pháp generative AI. Mỗi thành phần trong hạ tầng đánh giá này có thể được phát triển sử dụng các open source tools hiện có hoặc các dịch vụ AWS native.
Kiến trúc của automated LLM evaluation pipeline tập trung vào modularity, flexibility, và scalability. Triết lý thiết kế đảm bảo rằng các thành phần khác nhau có thể được tái sử dụng hoặc điều chỉnh cho các dự án generative AI khác. Dưới đây là tổng quan về từng thành phần và vai trò của chúng trong giải pháp:
- UI – Giao diện (UI) cung cấp cách tương tác trực quan với framework đánh giá. Người dùng có thể so sánh các LLM khác nhau thông qua side-by-side comparison. UI hiển thị latency, model outputs, và cost cho từng truy vấn (online evaluation). UI cũng giúp lưu trữ và quản lý các prompt templates khác nhau, được hỗ trợ bởi tính năng Amazon Bedrock prompt management. Các prompt này có thể được tham chiếu sau này cho batch generation hoặc sử dụng trong production. Bạn cũng có thể khởi chạy các job batch generation và evaluation thông qua UI. Dịch vụ UI có thể chạy cục bộ trong Docker container hoặc triển khai trên AWS Fargate.
- Prompt management – Giải pháp đánh giá bao gồm một thành phần chính để quản lý prompt. Được hỗ trợ bởi Amazon Bedrock prompt management, bạn có thể lưu và truy xuất các prompt thông qua UI.
- LLM invocation pipeline – Sử dụng AWS Step Functions, workflow này tự động hóa quá trình tạo output từ LLM cho một test dataset. Nó lấy input từ Amazon Simple Storage Service (Amazon S3), xử lý chúng, và lưu phản hồi trở lại Amazon S3. Workflow này hỗ trợ batch processing, phù hợp cho các đánh giá quy mô lớn.
- LLM evaluation pipeline – Workflow này, cũng được quản lý bởi Step Functions, đánh giá các output do LLM tạo ra. Tại thời điểm viết bài, giải pháp hỗ trợ các metrics từ thư viện FMEval, thư viện Ragas, và các custom LLM-as-a-judge metrics. Nó xử lý nhiều phương pháp đánh giá, bao gồm direct metrics computation và LLM-guided evaluation. Kết quả được lưu trong Amazon S3, sẵn sàng cho phân tích.
- Eval factory – Dịch vụ cốt lõi để tiến hành đánh giá, eval factory hỗ trợ nhiều kỹ thuật đánh giá, bao gồm các kỹ thuật sử dụng LLM khác để chấm điểm không cần tham chiếu (reference-free). Nó đảm bảo tính nhất quán (consistency) trong kết quả đánh giá bằng cách chuẩn hóa output thành một metric duy nhất cho mỗi lần đánh giá. Việc tìm một giải pháp “vạn năng” (one-size-fits-all) cho đánh giá là khó, vì vậy giải pháp này cho phép bạn sử dụng script đánh giá riêng. Chúng tôi cũng cung cấp các script và pipeline đã dựng sẵn cho một số tác vụ phổ biến như classification, summarization, translation, và RAG. Đặc biệt với RAG, chúng tôi đã tích hợp các thư viện open source phổ biến như Ragas.
- Postprocessing and results store – Sau khi pipeline tạo ra kết quả, quá trình hậu xử lý (postprocessing) có thể nối (concatenate) các kết quả và hiển thị chúng trong một results store, cung cấp cái nhìn trực quan. Phần này cũng quản lý cập nhật hệ thống quản lý prompt vì mỗi kết hợp giữa prompt template và LLM sẽ có kết quả đánh giá ghi lại, giúp chọn mô hình và prompt template phù hợp cho từng use case. Visualization có thể thực hiện trên UI hoặc thông qua bảng Amazon Athena nếu hệ thống quản lý prompt sử dụng Amazon S3 làm nơi lưu dữ liệu. Phần này có thể được thực hiện bằng AWS Lambda function, được kích hoạt bởi sự kiện gửi sau khi dữ liệu mới được lưu vào vị trí Amazon S3 cho hệ thống quản lý prompt.
Giải pháp đánh giá này có thể nâng cao đáng kể team productivity trong suốt vòng đời phát triển bằng cách giảm sự can thiệp thủ công và tăng cường các quy trình tự động. Khi các LLM mới xuất hiện, builders có thể so sánh LLM hiện tại trong production với các mô hình mới để xác định xem việc nâng cấp có cải thiện hiệu suất hệ thống hay không. Quy trình đánh giá liên tục này đảm bảo rằng giải pháp generative AI luôn tối ưu và cập nhật.
Prerequisites
Đối với các script để thiết lập giải pháp, hãy tham khảo GitHub repository. Sau khi backend và frontend đã được triển khai và hoạt động, bạn có thể bắt đầu quy trình đánh giá.
Để bắt đầu, mở UI trên trình duyệt của bạn. Giao diện UI cung cấp khả năng thực hiện cả online và offline evaluations.
Online evaluation
Để tinh chỉnh prompt theo từng bước lặp, bạn có thể thực hiện các bước sau:
- Chọn options menu (biểu tượng ba gạch) ở góc trên bên trái của trang để thiết lập AWS Region.
- Sau khi chọn Region, danh sách mô hình (model lists) sẽ được tự động điền sẵn với các Amazon Bedrock models có sẵn trong Region đó.
- Bạn có thể chọn hai mô hình để so sánh side-by-side.
- Bạn có thể chọn một prompt đã được lưu trong Amazon Bedrock prompt management từ menu dropdown. Nếu chọn, các prompt sẽ được điền tự động.
- Bạn cũng có thể tạo một prompt mới bằng cách nhập nội dung vào hộp văn bản. Bạn có thể chọn các generation configurations (như temperature, top P, v.v.) trong mục Generation Configuration. Prompt template cũng có thể sử dụng các dynamic variables bằng cách nhập biến trong {{}} (ví dụ, để thêm ngữ cảnh, thêm biến như {{context}}). Sau đó định nghĩa giá trị của các biến này trong tab Context.
- Chọn Enter để bắt đầu generation.
- Điều này sẽ gọi hai mô hình và hiển thị output trong các hộp văn bản bên dưới mỗi mô hình. Ngoài ra, bạn cũng sẽ thấy latency và cost cho từng mô hình.
- Để lưu prompt vào Amazon Bedrock, chọn Save.

Offline generation and evaluation
Sau khi bạn đã chọn model và prompt, bạn có thể chạy batch generation và evaluation trên một dataset lớn hơn.
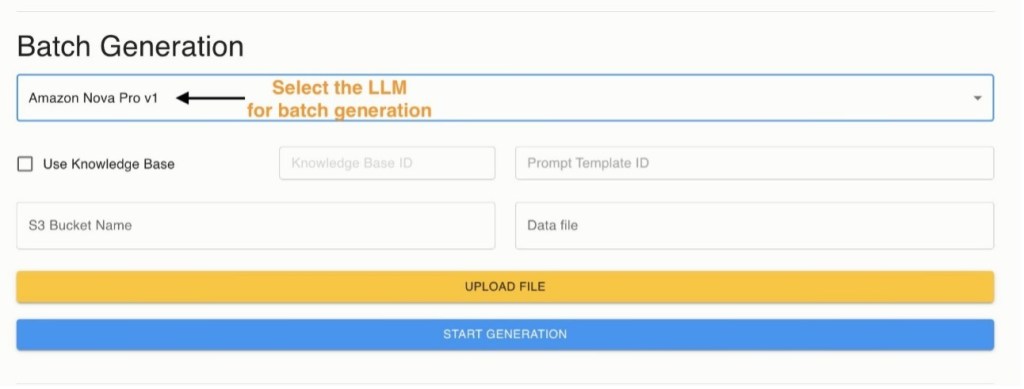
- Để chạy batch generation, chọn mô hình từ menu dropdown list.
- Bạn có thể cung cấp Amazon Bedrock knowledge base ID nếu cần thêm ngữ cảnh cho quá trình generation.
- Bạn cũng có thể cung cấp một prompt template ID. Prompt này sẽ được sử dụng cho generation.
- Tải lên một dataset file. File này sẽ được upload vào S3 bucket đã thiết lập trong thanh bên (sidebar). File này nên là pipe (|) separated CSV file. Để biết chi tiết về định dạng file dữ liệu mong đợi, xem README của dự án trên GitHub.
- Chọn Start Generation để bắt đầu job. Điều này sẽ kích hoạt một workflow của Step Functions, mà bạn có thể theo dõi bằng cách chọn liên kết trong pop-up.
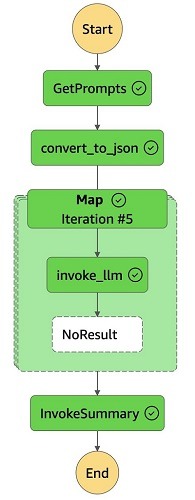
Việc invoking batch generation sẽ kích hoạt một workflow của Step Functions, được minh họa trong hình dưới đây. Logic của workflow thực hiện theo các bước sau:
- GetPrompts – Bước này lấy một file CSV chứa các prompt từ S3 bucket. Nội dung của file này sẽ trở thành payload cho workflow của Step Functions.
- convert_to_json – Bước này phân tích (parse) output CSV và chuyển đổi nó sang định dạng JSON. Quá trình chuyển đổi này cho phép Step Function sử dụng Map state để xử lý invoke_llm flow đồng thời (concurrently).
- Map step – Đây là bước lặp (iterative step) xử lý payload JSON bằng cách gọi hàm invoke_llm Lambda đồng thời cho từng mục trong payload. Một giới hạn concurrency được đặt, với giá trị mặc định là 3. Bạn có thể điều chỉnh giới hạn này dựa trên khả năng của backend LLM service. Trong mỗi lần lặp của Map, hàm invoke_llm Lambda gọi dịch vụ LLM backend để tạo phản hồi cho một câu hỏi cùng ngữ cảnh liên quan.
- InvokeSummary – Bước này kết hợp output từ mỗi lần lặp của Map step. Nó tạo ra một file JSON Lines chứa kết quả, sau đó được lưu vào S3 bucket để phục vụ cho mục đích đánh giá.
Khi batch generation hoàn tất, bạn có thể kích hoạt batch evaluation pipeline với các metrics đã chọn từ danh sách predefined metric list. Bạn cũng có thể chỉ định vị trí của một file trên S3 chứa các output LLM đã được tạo sẵn để thực hiện batch evaluation.
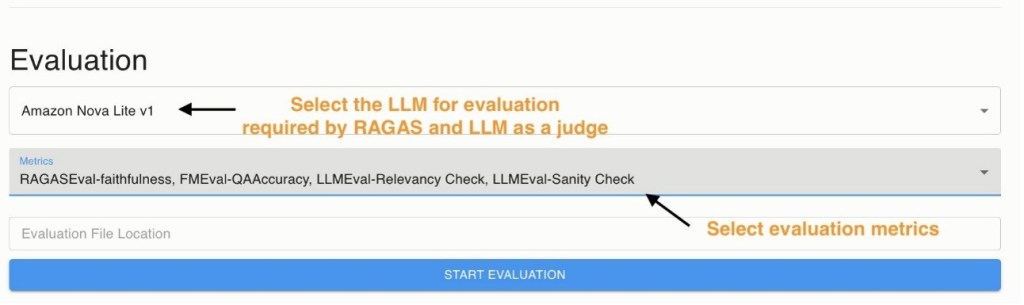
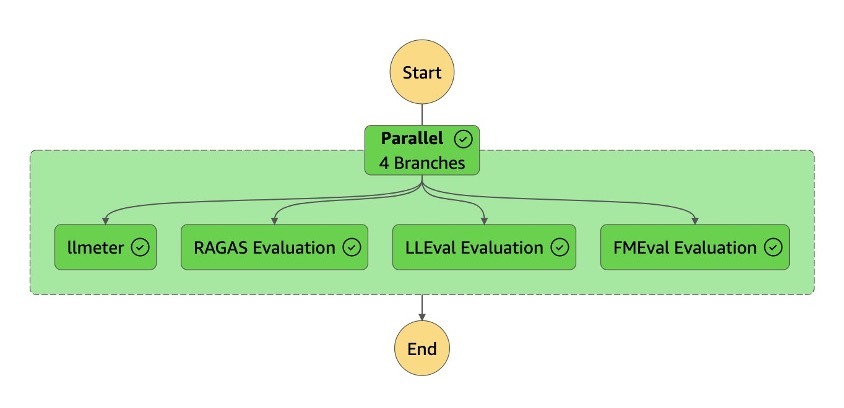
Việc invoking batch evaluation sẽ kích hoạt một workflow Evaluate-LLM Step Functions, được minh họa trong hình dưới đây. Workflow Evaluate-LLM Step Functions được thiết kế để đánh giá toàn diện hiệu suất của LLM bằng cách sử dụng nhiều evaluation frameworks:
- LLMeter evaluation – Sử dụng framework AWS Labs LLMeter, tập trung vào các endpoint performance metrics và benchmarking.
- Ragas framework evaluation – Sử dụng framework Ragas để đo bốn critical quality metrics:
- Context precision – Metric này đánh giá xem các mục liên quan theo ground truth trong ngữ cảnh (các đoạn văn bản được truy xuất (retrieved chunks) từ vector database) có được xếp hạng cao hơn hay không. Giá trị dao động từ 0–1, giá trị cao hơn biểu thị hiệu suất tốt hơn. Hệ thống RAG thường lấy nhiều hơn 1 chunk cho một truy vấn, và các chunk được xếp theo thứ tự. Điểm thấp hơn được gán khi các chunk xếp cao chứa nhiều thông tin không liên quan, cho thấy khả năng khả năng truy xuất thông tin (information retrieval) kém.
- Context recall – Metric đo mức độ mà ngữ cảnh được truy xuất phù hợp với ground truth. Giá trị dao động từ 0–1, giá trị cao hơn biểu thị hiệu suất tốt hơn. Ground truth có thể chứa nhiều khẳng định ngắn và rõ ràng. Ví dụ, ground truth: “Canberra is the capital city of Australia, and the city is located at the northern end of the Australian Capital Territory” có hai khẳng định: “Canberra is the capital city of Australia” và “Canberra city is located at the northern end of the Australian Capital Territory.” Mỗi khẳng định được phân tích xem có thể được suy ra từ ngữ cảnh truy xuất hay không. Giá trị cao hơn được gán khi nhiều khẳng định trong ground truth có thể liên kết với ngữ cảnh truy xuất.
- Faithfulness – Metric đo độ factual consistency của câu trả lời được tạo ra so với ngữ cảnh đã cho. Giá trị từ 0–1, giá trị cao hơn biểu thị hiệu suất tốt hơn. Câu trả lời có thể chứa nhiều khẳng định; điểm thấp hơn được gán cho các câu trả lời có ít khẳng định được suy ra từ ngữ cảnh.
- Mức độ liên quan của câu trả lời (Answer relevancy) – Metric đánh giá mức độ phù hợp của câu trả lời với prompt đã cho. Giá trị được chuẩn hóa trong khoảng (0, 1), giá trị cao hơn tốt hơn. Điểm thấp được gán cho các câu trả lời không đầy đủ hoặc chứa thông tin thừa, điểm cao biểu thị relevancy tốt hơn.
- Context precision – Metric này đánh giá xem các mục liên quan theo ground truth trong ngữ cảnh (các đoạn văn bản được truy xuất (retrieved chunks) từ vector database) có được xếp hạng cao hơn hay không. Giá trị dao động từ 0–1, giá trị cao hơn biểu thị hiệu suất tốt hơn. Hệ thống RAG thường lấy nhiều hơn 1 chunk cho một truy vấn, và các chunk được xếp theo thứ tự. Điểm thấp hơn được gán khi các chunk xếp cao chứa nhiều thông tin không liên quan, cho thấy khả năng khả năng truy xuất thông tin (information retrieval) kém.
- LLM-as-a-judge evaluation – Sử dụng khả năng của LLM để so sánh và chấm điểm output so với câu trả lời kỳ vọng, cung cấp đánh giá qualitative về độ chính xác. Các prompt dùng cho LLM-as-a-judge chỉ mang tính minh họa; để phục vụ use case cụ thể, bạn nên cung cấp các prompt đánh giá riêng để đảm bảo LLM-as-a-judge đáp ứng yêu cầu đánh giá chính xác.
- FM evaluation – Sử dụng thư viện AWS open source FMEval để phân tích các metrics chính, bao gồm đo lường toxicity.
Kiến trúc này triển khai các đánh giá trên dưới dạng nested Step Functions workflows chạy đồng thời (concurrently), cho phép đánh giá mô hình một cách hiệu quả và toàn diện. Thiết kế này cũng giúp dễ dàng thêm các framework mới vào workflow đánh giá.
Clean up
Để xóa triển khai cục bộ (local deployment) cho frontend, chạy lệnh run.sh delete_local Nếu bạn cần xóa triển khai trên cloud, chạy: run.sh delete_cloud Đối với backend, bạn có thể xóa AWS CloudFormation stack có tên: Llm-evaluation-stack Đối với các resources không thể xóa tự động, bạn cần xóa thủ công trên AWS Management Console.
Conclusion
Trong bài viết này, chúng tôi đã khám phá tầm quan trọng của việc đánh giá LLM trong bối cảnh các ứng dụng generative AI, đồng thời nhấn mạnh những thách thức do các vấn đề như hallucinations và biases gây ra. Chúng tôi đã giới thiệu một giải pháp toàn diện sử dụng các dịch vụ AWS để tự động hóa quy trình đánh giá, cho phép giám sát và đánh giá liên tục hiệu suất của LLM. Bằng cách sử dụng các công cụ như FMeval Library, Ragas, LLMeter, và Step Functions, giải pháp mang lại flexibility và scalability, đáp ứng nhu cầu ngày càng phát triển của người dùng LLM.
Với giải pháp này, doanh nghiệp có thể triển khai LLM một cách tự tin, biết rằng chúng tuân thủ các tiêu chuẩn cần thiết về accuracy, fairness, và relevance. Chúng tôi khuyến khích bạn tham khảo GitHub repository và bắt đầu xây dựng automated LLM evaluation pipeline của riêng bạn trên AWS ngay hôm nay. Cấu hình này không chỉ tối ưu hóa workflow AI mà còn đảm bảo rằng các mô hình của bạn cung cấp output chất lượng cao nhất cho các ứng dụng cụ thể của bạn.
About the Authors

Deepak Dalakoti, PhD, là một Deep Learning Architect tại Generative AI Innovation Centre ở Sydney, Australia. Với chuyên môn về artificial intelligence, ông hợp tác với khách hàng để tăng tốc việc áp dụng GenAI thông qua các giải pháp tùy chỉnh và sáng tạo. Ngoài công việc về AI, ông thích khám phá các hoạt động và trải nghiệm mới, hiện đang tập trung vào strength training.

Rafa XU là một senior cloud architect đầy nhiệt huyết tại Amazon Web Services (AWS), tập trung hỗ trợ các khách hàng Public Sector trong việc thiết kế, xây dựng và vận hành hạ tầng, ứng dụng và dịch vụ trên AWS. Với hơn 10 năm kinh nghiệm làm việc trong nhiều lĩnh vực công nghệ thông tin, Rafa đã dành 5 năm gần đây tập trung vào AWS Cloud infrastructure, serverless applications, và automation. Gần đây, Rafa đã mở rộng kỹ năng của mình để bao gồm Generative AI, Machine Learning, Big Data, và Internet of Things (IoT).

Dr. Melanie Li, PhD, là Senior Generative AI Specialist Solutions Architect tại AWS, làm việc tại Sydney, Australia. Bà tập trung hợp tác với khách hàng để xây dựng các giải pháp tận dụng các công cụ AI và machine learning tiên tiến. Bà đã tham gia tích cực vào nhiều sáng kiến Generative AI trên khu vực APJ, khai thác sức mạnh của Large Language Models (LLMs). Trước khi gia nhập AWS, Dr. Li đảm nhiệm các vị trí về data science trong ngành tài chính và bán lẻ.

Sam Edwards là Solutions Architect tại AWS, làm việc tại Sydney và tập trung vào lĩnh vực Media & Entertainment. Anh là Subject Matter Expert cho các dịch vụ Amazon Bedrock và Amazon SageMaker AI. Anh đam mê giúp khách hàng giải quyết các vấn đề liên quan đến machine learning workflows và tạo ra các giải pháp mới cho họ. Trong thời gian rảnh, anh thích du lịch và tận hưởng thời gian bên gia đình.

Dr. Kai Zhu hiện là Cloud Support Engineer tại AWS, hỗ trợ khách hàng với các vấn đề liên quan đến dịch vụ AI/ML như SageMaker, Bedrock, v.v. Ông là Subject Matter Expert về SageMaker và Bedrock. Với kinh nghiệm trong data science và data engineering, ông quan tâm đến việc xây dựng các dự án Generative AI.
