by Elisabetta Castellano, Carmela Gambardella, Federico D’Alessio, and Leonardo Fenu on 16 APR 2025 in Amazon API Gateway, Amazon Bedrock, Amazon Titan, AWS Lambda Permalink Comments Share
Việc duy trì danh mục tài sản (asset inventory) luôn cập nhật, khi thiết bị thật sự được triển khai ngoài hiện trường, có thể là một công việc thách thức và tốn thời gian. Nhiều nhà cung cấp điện sử dụng nhãn của nhà sản xuất như thông tin then chốt để liên kết tài sản vật lý với hệ thống quản lý tài sản. Computer vision có thể là giải pháp khả thi để đẩy nhanh việc kiểm tra của nhân viên vận hành và giảm sai sót do con người bằng cách tự động trích xuất dữ liệu liên quan từ nhãn. Tuy nhiên, việc xây dựng một ứng dụng computer vision tiêu chuẩn có khả năng quản lý hàng trăm loại nhãn khác nhau có thể là một nhiệm vụ phức tạp và tốn thời gian.
Trong bài đăng này, chúng tôi giới thiệu một giải pháp sử dụng generative AI và large language models (LLMs) để giảm bớt những tác vụ tốn thời gian và công sức khi xây dựng ứng dụng computer vision, cho phép bạn ngay lập tức chụp ảnh nhãn tài sản và trích xuất thông tin cần thiết để cập nhật inventory, sử dụng các dịch vụ AWS như AWS Lambda, Amazon Bedrock, Amazon Titan, Anthropic’s Claude 3 on Amazon Bedrock, Amazon API Gateway, AWS Amplify, Amazon S3, và Amazon DynamoDB.
LLMs là các mô hình học sâu (deep learning) lớn đã được pre-trained trên lượng dữ liệu khổng lồ. Chúng có khả năng hiểu và sinh văn bản giống con người, làm cho chúng trở thành công cụ rất linh hoạt với nhiều ứng dụng. Cách tiếp cận này tận dụng khả năng hiểu hình ảnh của mô hình Claude 3 của Anthropic để trích xuất thông tin trực tiếp từ ảnh được chụp tại hiện trường, bằng cách phân tích nhãn tồn tại trong hình ảnh.
Solution overview
Giải pháp labeling inventory tài sản hỗ trợ AI nhằm đơn giản hóa quy trình cập nhật database inventory bằng cách tự động trích xuất thông tin liên quan từ nhãn tài sản thông qua computer vision và khả năng generative AI. Giải pháp sử dụng nhiều dịch vụ AWS để tạo nên hệ thống đầu-cuối (end-to-end) giúp kỹ thuật viên hiện trường chụp ảnh nhãn, trích xuất dữ liệu bằng mô hình AI, xác minh độ chính xác, và cập nhật database inventory một cách liền mạch.
Đồ họa sau mô tả kiến trúc giải pháp:
(ảnh kiến trúc)
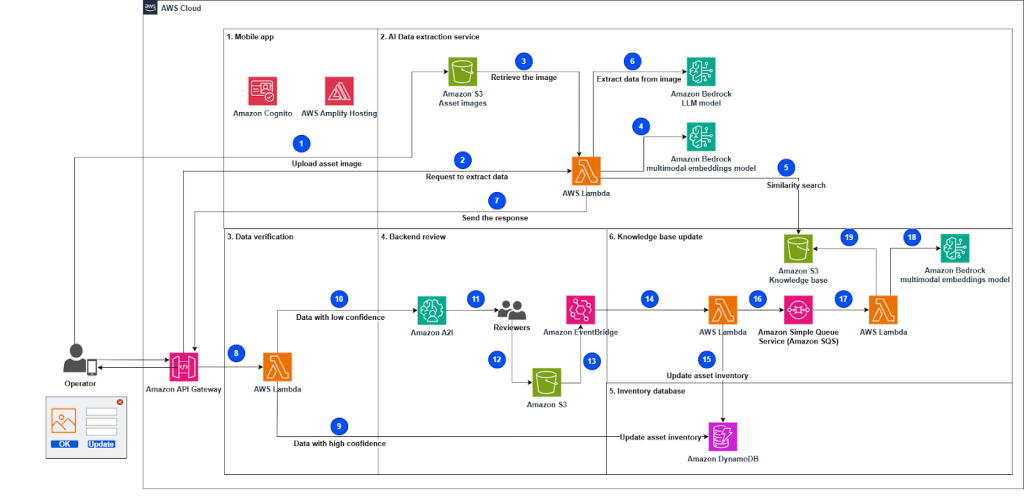
Quy trình làm việc bao gồm các bước sau:
- Người vận hành chụp và upload ảnh của tài sản qua ứng dụng di động.
- Người vận hành gửi yêu cầu để trích xuất dữ liệu từ ảnh tài sản.
- Một hàm Lambda lấy ảnh tài sản đã upload từ datastore ảnh.
- Hàm này tạo embeddings (các biểu diễn vector của dữ liệu) bằng cách gọi (invoke) mô hình Amazon Titan Multimodal Embeddings G1.
- Hàm thực hiện tìm kiếm tương đồng (similarity search) trong cơ sở tri thức (knowledge base) để truy xuất các nhãn tài sản tương tự. Những kết quả gần nhất sẽ bổ sung vào câu lệnh (prompt) như các ví dụ tương đồng để cải thiện độ chính xác của phản hồi, và được gửi cùng các hướng dẫn tới LLM để trích xuất dữ liệu từ ảnh tài sản.
- Hàm invoke Anthropic’s Claude 3 Sonnet trên Amazon Bedrock để trích xuất dữ liệu (serial number, tên nhà cung cấp, v.v.) sử dụng prompt đã được bổ sung.
- Hàm gửi phản hồi về ứng dụng di động kèm dữ liệu trích xuất.
- Ứng dụng di động xác minh dữ liệu trích xuất và gán mức độ confidence. Nó invoke API để xử lý dữ liệu. Các dữ liệu có confidence cao sẽ được nhập trực tiếp vào hệ thống.
- Hàm Lambda được invoke để cập nhật database inventory nếu mức độ confidence được đánh dấu cao bởi ứng dụng di động.
- Hàm gửi dữ liệu có confidence thấp đến Amazon A2I để xử lý thêm.
- Nhân viên xem xét qua Amazon A2I xác minh hoặc chỉnh sửa dữ liệu có confidence thấp.
- Nhân viên (subject matter experts) xác định dữ liệu được trích xuất, đánh dấu và lưu vào bucket S3.
- Một rule trong Amazon EventBridge được định nghĩa để trigger Lambda khi quy trình Amazon A2I hoàn tất.
- Hàm Lambda xử lý đầu ra của quy trình Amazon A2I bằng cách load dữ liệu từ file JSON lưu trữ thông tin đã được xác minh bởi operator hậu cần.
- Hàm cập nhật database inventory với dữ liệu trích xuất mới.
- Hàm gửi dữ liệu mới (do reviewers đánh dấu) tới queue Amazon SQS để xử lý thêm.
- Hàm Lambda khác lấy message từ queue và serialize các cập nhật vào knowledge base database.
- Hàm này tạo embeddings ảnh tài sản bằng cách invoke mô hình Amazon Titan Multimodal Embeddings G1.
- Hàm cập nhật knowledge base với embeddings mới và thông báo cho các hàm khác rằng database đã được cập nhật.
Mobile app
Thành phần mobile app đóng vai trò quan trọng trong giải pháp AI-powered asset inventory labeling này. Nó hoạt động như giao diện chính cho các kỹ thuật viên hiện trường trên máy tính bảng hoặc thiết bị di động để chụp và tải lên hình ảnh của asset labels bằng camera của thiết bị. Việc triển khai mobile app bao gồm một cơ chế xác thực (authentication) cho phép chỉ những người dùng đã được xác thực mới có quyền truy cập. Ứng dụng cũng được xây dựng theo hướng phi máy chủ (serverless approach) nhằm giảm chi phí vận hành định kỳ, đồng thời cung cấp một giải pháp scalable và robust cao.
Mobile app được xây dựng bằng các dịch vụ sau:
- AWS Amplify – Cung cấp framework phát triển và hosting cho nội dung tĩnh của mobile app. Bằng cách sử dụng Amplify, thành phần mobile app được hưởng lợi từ các tính năng như tích hợp liền mạch với các dịch vụ AWS khác, khả năng hoạt động ngoại tuyến, secure authentication, và scalable hosting.
- Amazon Cognito – Xử lý user authentication và authorization cho mobile app.
AI data extraction service
AI data extraction service được thiết kế để trích xuất các thông tin quan trọng như manufacturer name, model number, và serial number từ hình ảnh của asset labels.
Để tăng độ chính xác và hiệu quả của quá trình trích xuất dữ liệu, service này sử dụng một knowledge base bao gồm các hình ảnh nhãn mẫu và dữ liệu tương ứng. Knowledge base này đóng vai trò như một tài liệu tham chiếu cho AI model, giúp mô hình có thể học và khái quát hóa từ các ví dụ đã được gán nhãn sang các định dạng nhãn mới một cách hiệu quả. Knowledge base được lưu trữ dưới dạng vector embeddings trong một high-performance vector database: Meta’s FAISS (Facebook AI Similarity Search), được host trên Amazon S3.
Embeddings là các biểu diễn số dày đặc (dense) thể hiện bản chất của dữ liệu phức tạp như văn bản hoặc hình ảnh trong không gian vector. Mỗi điểm dữ liệu được ánh xạ thành một vector (hoặc danh sách có thứ tự các con số), trong đó các điểm dữ liệu tương tự được đặt gần nhau hơn. Không gian embedding này cho phép tính toán độ tương đồng một cách hiệu quả bằng cách đo khoảng cách giữa các vector. Embeddings giúp các mô hình machine learning (ML) xử lý và hiểu mối quan hệ trong dữ liệu phức tạp, dẫn đến việc cải thiện hiệu suất trong nhiều tác vụ như xử lý ngôn ngữ tự nhiên (NLP) và computer vision.
Hình dưới đây minh họa một ví dụ về workflow:
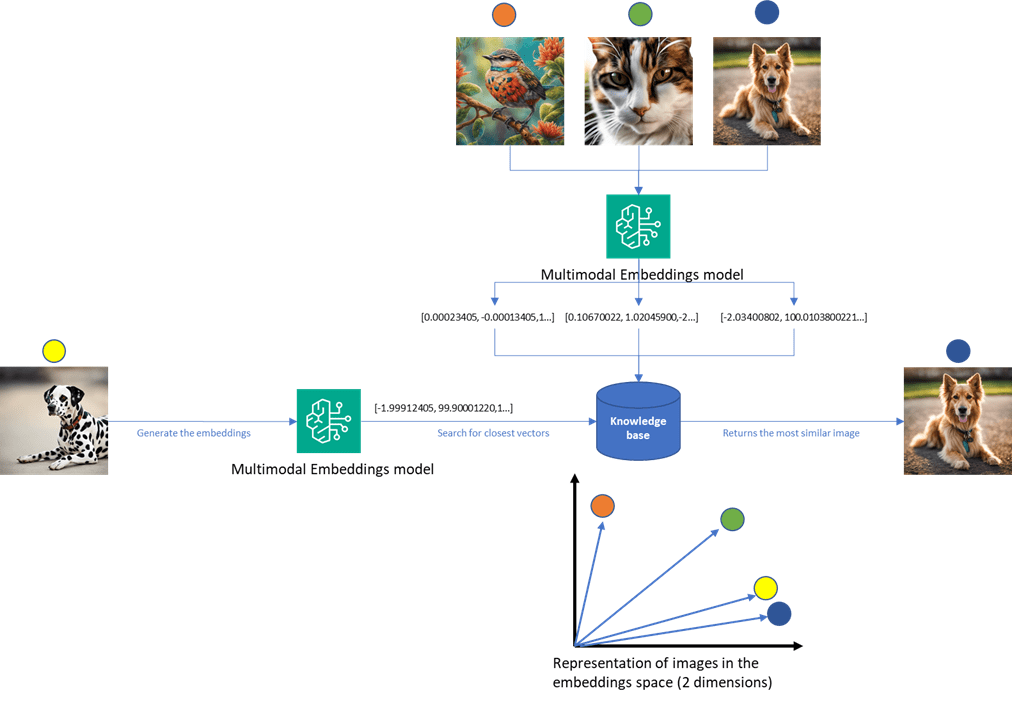
Vector embeddings được tạo ra bằng Amazon Titan, một dịch vụ mạnh mẽ chuyên tạo embeddings, chuyển đổi các ví dụ đã được gán nhãn thành biểu diễn số phù hợp cho việc tìm kiếm tương đồng hiệu quả. Workflow bao gồm các bước sau:
- Khi một hình ảnh asset label mới được gửi để xử lý, AI data extraction service thông qua Lambda function sẽ truy xuất hình ảnh đã upload từ bucket lưu trữ.
- Lambda function thực hiện similarity search bằng Meta’s FAISS vector search engine. Quá trình tìm kiếm này so sánh hình ảnh mới với các vector embeddings trong knowledge base được tạo bởi Amazon Titan Multimodal Embeddings (được invoke thông qua Amazon Bedrock) để xác định các ví dụ gán nhãn có liên quan nhất.
- Sử dụng augmented prompt chứa thông tin ngữ cảnh từ kết quả similarity search, Lambda function invoke Amazon Bedrock, cụ thể là Anthropic’s Claude 3, một state-of-the-art generative AI model, để thực hiện các tác vụ image understanding và optical character recognition (OCR). Bằng cách tận dụng các ví dụ tương tự, mô hình AI có thể trích xuất và diễn giải chính xác hơn các thông tin quan trọng từ hình ảnh asset label mới.
- Kết quả phản hồi được gửi về mobile app để field technician xác nhận.
Trong giai đoạn này, các dịch vụ AWS được sử dụng gồm có:
- Amazon Bedrock – Dịch vụ được quản lý toàn phần, cung cấp nhiều foundation models (FMs) hiệu năng cao từ các công ty AI hàng đầu như AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, và Amazon, thông qua một single API, kèm theo nhiều khả năng mở rộng.
- AWS Lambda – Dịch vụ serverless computing cho phép chạy code mà không cần quản lý physical servers hoặc virtual machines. Một Lambda function thực thi logic trích xuất dữ liệu và điều phối toàn bộ quy trình data extraction.
- Amazon S3 – Dịch vụ lưu trữ cung cấp durability, availability, performance, security hàng đầu ngành, với khả năng mở rộng gần như vô hạn và chi phí thấp. Được sử dụng để lưu trữ hình ảnh tài sản do field technicians tải lên.
Data verification
Data verification đóng vai trò quan trọng trong việc duy trì độ chính xác và độ tin cậy của dữ liệu được trích xuất trước khi cập nhật vào asset inventory database, và được tích hợp trực tiếp trong mobile app.
Workflow bao gồm các bước sau:
- Dữ liệu đã được trích xuất sẽ hiển thị cho field operator.
- Nếu field operator xác định rằng dữ liệu trích xuất là chính xác và khớp với một asset label có sẵn trong knowledge base, họ có thể xác nhận tính chính xác của kết quả; nếu không, họ có thể chỉnh sửa các giá trị trực tiếp trong ứng dụng.
- Khi field technician xác nhận rằng dữ liệu là đúng, thông tin đó sẽ tự động được chuyển tiếp đến backend review component.
Data verification sử dụng các dịch vụ AWS sau:
- Amazon API Gateway – Một secure và scalable API gateway giúp expose các chức năng của thành phần data verification cho mobile app và các thành phần khác.
- AWS Lambda – Các serverless functions dùng để triển khai verification logic và định tuyến dữ liệu dựa trên confidence levels.
Backend review
Thành phần backend review chịu trách nhiệm đánh giá sự sai lệch giữa dữ liệu được AI data extraction service tự động nhận diện và dữ liệu cuối cùng được field operator phê duyệt, đồng thời tính toán mức độ khác biệt. Nếu sai lệch nhỏ hơn một configured threshold, dữ liệu sẽ được gửi đi để cập nhật inventory database; ngược lại, human review process sẽ được kích hoạt:
- Subject matter experts (SMEs) sẽ xem xét không đồng bộ các mục dữ liệu bị gắn cờ trong Amazon A2I console.
- Những sai lệch đáng kể sẽ được đánh dấu để cập nhật vào generative AI knowledge base.
- Các lỗi nhỏ trong OCR sẽ được chỉnh sửa mà không cần cập nhật AI model’s knowledge base.
Thành phần backend review sử dụng các dịch vụ AWS sau:
- Amazon A2I – Dịch vụ cung cấp giao diện web dành cho human reviewers để kiểm tra và chỉnh sửa dữ liệu trích xuất cũng như hình ảnh asset labels.
- Amazon EventBridge – Dịch vụ serverless sử dụng events để kết nối các thành phần ứng dụng. Khi Amazon A2I human workflow hoàn tất, EventBridge sẽ phát hiện sự kiện này và kích hoạt Lambda function để xử lý dữ liệu đầu ra.
- Amazon S3 – Dịch vụ object storage được sử dụng để lưu trữ thông tin đã được đánh dấu bởi Amazon A2I.
Inventory database
Thành phần inventory database đóng vai trò quan trọng trong việc lưu trữ và quản lý verified asset data theo cách có khả năng mở rộng và hiệu quả Amazon DynamoDB, một dịch vụ cơ sở dữ liệu NoSQL được quản lý toàn diện của AWS, được sử dụng cho mục đích này. DynamoDB là một serverless, scalable, và highly available key-value and document database service. Nó được thiết kế để xử lý massive amounts of data và high traffic workloads, khiến nó trở thành lựa chọn phù hợp cho việc lưu trữ và truy xuất large-scale inventory data.
Dữ liệu đã được xác minh (verified data) từ các quy trình AI extraction và human verification sẽ được nạp vào DynamoDB table. Điều này bao gồm cả dữ liệu có high confidence từ quá trình trích xuất ban đầu, cũng như dữ liệu đã được human reviewers kiểm tra và chỉnh sửa.
Knowledge base update
Thành phần knowledge base update cho phép cải thiện liên tục và thích ứng của các generative AI models được sử dụng trong quy trình asset label data extraction:
- Trong quá trình backend review, các human reviewers từ Amazon A2I xác thực và chỉnh sửa dữ liệu được AI model trích xuất từ asset labels.
- Dữ liệu đã được chỉnh sửa và xác minh, cùng với hình ảnh asset label tương ứng, sẽ được đánh dấu là new label examples nếu chúng chưa tồn tại trong knowledge base.
- Một Lambda function được kích hoạt để cập nhật asset inventory và gửi các new labels vào FIFO (First-In-First-Out) queue.
- Một Lambda function khác xử lý các messages trong queue, cập nhật knowledge base vector store (bucket S3) bằng các ví dụ nhãn mới.
- Quy trình cập nhật này tạo ra vector embeddings bằng cách invoke Amazon Titan Multimodal Embeddings G1 model (được expose qua Amazon Bedrock) và lưu trữ các embeddings trong Meta’s FAISS database trên Amazon S3.
Quy trình knowledge base update đảm bảo rằng giải pháp luôn có khả năng thích ứng và không ngừng cải thiện hiệu suất theo thời gian, giảm khả năng gặp phải các unseen label examples, đồng thời hạn chế sự can thiệp thủ công của subject matter experts trong việc chỉnh sửa dữ liệu trích xuất.
Thành phần này sử dụng các dịch vụ AWS sau:
- Amazon Titan Multimodal Embeddings G1 model– Mô hình này tạo ra embeddings (vector representations) cho các hình ảnh tài sản mới và dữ liệu liên quan của chúng.
- AWS Lambda – Các Lambda functions được sử dụng để cập nhật asset inventory database, gửi và xử lý dữ liệu trích xuất trong FIFO queue, và cập nhật knowledge base khi có new unseen labels.
- Amazon SQS – Cung cấp fully managed message queuing cho microservices, distributed systems, và serverless applications. Dữ liệu trích xuất được human reviewers đánh dấu là mới sẽ được gửi vào SQS FIFO (First-In-First-Out) queue, đảm bảo các messages được xử lý theo đúng thứ tự. FIFO queues duy trì thứ tự gửi và nhận messages, giúp bạn không cần thêm thông tin sắp xếp trong dữ liệu gửi đi.
- Amazon S3 – Knowledge base được lưu trữ trong S3 bucket, chứa các newly generated embeddings, giúp hệ thống AI cải thiện độ chính xác trong các tác vụ asset label recognition trong tương lai.
Navigation flow
Phần này giải thích cách người dùng tương tác với hệ thống và cách dữ liệu luân chuyển giữa các thành phần khác nhau của giải pháp. Chúng ta sẽ xem xét vai trò của từng key component trong quy trình — từ lúc người dùng truy cập ban đầu cho đến giai đoạn xác minh và lưu trữ dữ liệu.
Mobile app
Người dùng cuối (End user) truy cập ứng dụng di động thông qua trình duyệt (browser) có sẵn trên thiết bị cầm tay. Application URL để truy cập mobile app sẽ có sẵn sau khi bạn deploy frontend application. Sử dụng browser trên thiết bị di động hoặc máy tính cá nhân (PC), truy cập vào application URL address, nơi một login window sẽ xuất hiện. Vì đây là demo environment, bạn có thể đăng ký trên ứng dụng bằng cách làm theo quy trình đăng ký tự động được triển khai thông qua Amazon Cognito, và chọn Create Account, như minh họa trong ảnh chụp màn hình sau:
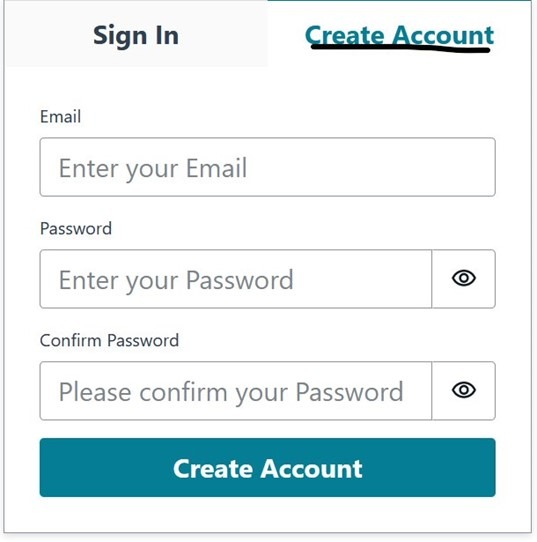
Trong quá trình registration, bạn cần cung cấp một valid email address để xác minh danh tính, đồng thời đặt password. Sau khi hoàn tất đăng ký, bạn có thể log in bằng credentials của mình.
Khi authentication hoàn tất, mobile app sẽ xuất hiện, như hình dưới đây:
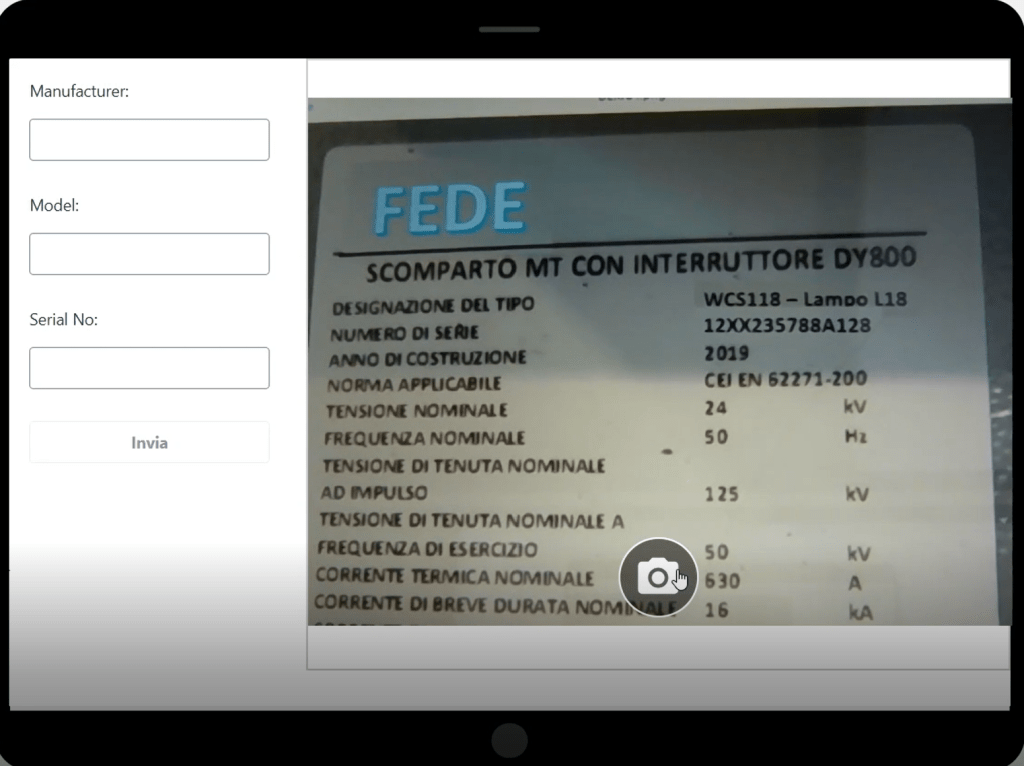
Quy trình sử dụng ứng dụng như sau:
- Sử dụng camera button để chụp hình ảnh label.
- Ứng dụng hỗ trợ upload hình ảnh đã chụp lên private S3 bucket được chỉ định riêng cho việc lưu trữ asset images. S3 Transfer Acceleration là một AWS service riêng biệt có thể tích hợp với Amazon S3 để cải thiện tốc độ upload và download dữ liệu. Dịch vụ này hoạt động bằng cách sử dụng các AWS edge locations, vốn được phân bố toàn cầu và gần với client applications, đóng vai trò trung gian trong quá trình truyền dữ liệu. Điều này giúp giảm latency và cải thiện tốc độ truyền tải tổng thể, đặc biệt hữu ích cho các clients ở xa AWS Region chứa S3 bucket.
- Sau khi hình ảnh được upload, ứng dụng gửi một request đến AI data extraction service, kích hoạt quá trình data extraction và analysis tiếp theo. Extracted data được trả về bởi service sẽ hiển thị và có thể chỉnh sửa trực tiếp trong form, như mô tả ở phần sau của bài viết. Điều này cho phép thực hiện data verification.
AI data extraction service
Module này sử dụng Anthropic’s Claude 3 FM, một multimodal system có khả năng xử lý cả images và text. Để extract relevant data, chúng tôi sử dụng prompt technique kết hợp samples nhằm định hướng model’s output. Prompt của chúng tôi bao gồm hai sample images cùng với corresponding extracted text của chúng. Model sẽ xác định sample image nào giống nhất với image mà chúng ta cần phân tích, sau đó sử dụng extracted text của sample đó làm reference để xác định relevant information trong target image.
Chúng tôi sử dụng prompt sau đây để đạt được kết quả này:
{
"role": "user",
"content": [
{
"type": "text",
"text": "first_sample_image:",
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": first_sample_encoded_image,
},
},
{
"type": "text",
"text": "target_image:",
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": encoded_image,
},
},
{"type": "text",
"text": f"""
answer the question using the following example as reference.
match exactly the same set of fields and information as in the provided example.
<example>
analyze first_sample_image and answer with a json file with the following information: Model, SerialN, ZOD.
answer only with json.
Answer:
{first_sample_answer}
</example>
<question>
analyze target_image and answer with a json file with the following information: Model, SerialN, ZOD.
answer only with json.
Answer:
</question>
"""},
],
}Trong đoạn code phía trên, first_sample_encoded_image và first_sample_answer lần lượt là reference image và expected output, còn encoded_image chứa new image cần được phân tích.
Data verification
Sau khi hình ảnh được xử lý bởi AI data extraction service, control sẽ quay trở lại mobile app:
- Mobile app nhận dữ liệu đã được trích xuất từ AI data extraction service, dịch vụ này đã xử lý uploaded asset label image và trích xuất các thông tin liên quan bằng computer vision và ML models.
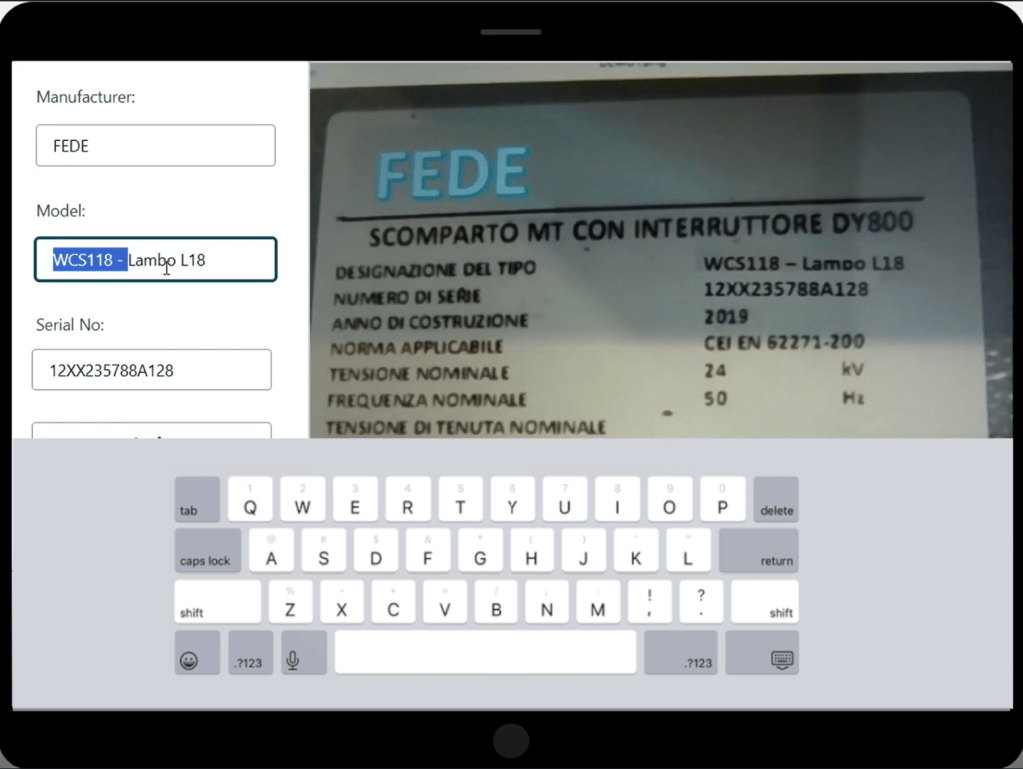
- Khi nhận được dữ liệu trích xuất, mobile app hiển thị cho field operator, cho phép họ review và confirm độ chính xác của thông tin (xem ảnh chụp màn hình minh họa). Nếu dữ liệu trích xuất là chính xác và khớp với physical asset label, technician có thể gửi confirmation qua ứng dụng, xác nhận rằng dữ liệu valid và sẵn sàng được insert vào asset inventory database.
- Nếu field operator thấy bất kỳ discrepancies hoặc lỗi nào trong dữ liệu trích xuất so với actual asset label, họ có thể chỉnh sửa các giá trị đó.
- Các giá trị được trả về bởi AI data extraction service cùng với các giá trị cuối cùng được field operators xác nhận sẽ được gửi đến backend review service.
Backend review
Quy trình này được triển khai bằng Amazon A2I:
- Một distance metric được tính toán để đánh giá sự khác biệt giữa dữ liệu mà data extraction service nhận diện và các chỉnh sửa do on-site operator thực hiện.
- Nếu sự khác biệt lớn hơn predefined threshold, hình ảnh và dữ liệu đã được operator modified sẽ được gửi đến Amazon A2I workflow, tạo ra một yêu cầu có con người tham gia (human-in-the-loop request).
- Khi có backend operator sẵn sàng, new request sẽ được phân công.
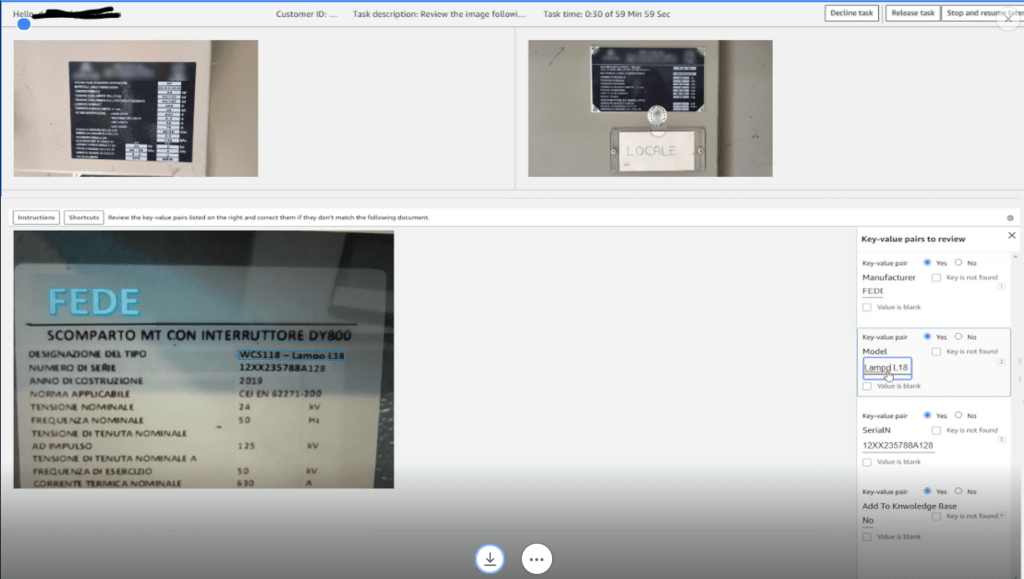
- Operator sử dụng Amazon A2I provided web interface, như minh họa trong ảnh chụp màn hình, để kiểm tra những gì on-site operator đã làm. Nếu phát hiện label type này chưa có trong knowledge base, operator có thể quyết định thêm nó bằng cách nhập Yes vào trường Add to Knowledge Base.
- Khi A2I process hoàn tất, một Lambda function sẽ được kích hoạt.
- Lambda function này lưu trữ thông tin vào inventory database và kiểm tra xem hình ảnh này có cần được sử dụng để cập nhật knowledge base hay không.
- Nếu cần, Lambda function sẽ gửi request kèm dữ liệu liên quan vào SQS FIFO queue.
Inventory database
Để giữ cho giải pháp này đơn giản nhất có thể trong khi vẫn đáp ứng được khả năng cần thiết, chúng tôi đã chọn DynamoDB làm inventory database. Đây là một NoSQL database, và chúng tôi sẽ lưu trữ dữ liệu trong một table với các thông tin sau:
- Manufacturers, model ID, và serial number sẽ là key của table.
- Link đến hình ảnh chứa label được sử dụng trong quá trình on-site inspection.
DynamoDB cung cấp on-demand pricing model, cho phép chi phí phụ thuộc trực tiếp vào actual database usage.
Knowledge base database
Knowledge base database được lưu trữ dưới dạng hai file trong một S3 bucket:
- File đầu tiên là một JSON array chứa metadata (manufacturer, serial number, model ID, và link đến reference image) cho từng mục trong knowledge base.
- File thứ hai là một FAISS database chứa index với embedding cho từng hình ảnh được bao gồm trong file đầu tiên.
Để minimize race conditions khi cập nhật database, một single Lambda function được cấu hình làm consumer của SQS queue. Lambda function sẽ trích xuất thông tin về link đến reference image và metadata, đã được xác nhận bởi back-office operator, cập nhật cả hai file, lưu phiên bản mới vào S3 bucket.
Trong các phần tiếp theo, chúng ta sẽ tạo một seamless workflow cho việc field data collection, AI-powered extraction, human validation, và inventory updates.
Prerequisites
Bạn cần có các điều kiện tiên quyết (prerequisites) sau trước khi có thể tiếp tục triển khai giải pháp. Trong bài viết này, chúng tôi sử dụng us-east-1 Region.
Bạn cũng cần một AWS Identity and Access Management (IAM) user với quyền quản trị để triển khai các thành phần cần thiết, cùng với một môi trường phát triển đã được cấu hình để truy cập các AWS resources.
Đối với môi trường phát triển, bạn có thể sử dụng một Amazon Elastic Compute Cloud (Amazon EC2) instance (chọn ít nhất loại t3.small instance để có thể build web application) hoặc sử dụng môi trường phát triển mà bạn chọn.
Cài đặt Python 3.9 và cài đặt, cấu hình AWS Command Line Interface (AWS CLI).
Bạn cũng cần cài đặt Amplify CLI. Tham khảo Set up Amplify CLI để biết thêm thông tin.
Bước tiếp theo là enable các models được sử dụng trong workshop này trên Amazon Bedrock. Để làm điều này, hoàn thành các bước sau:
- Trên Amazon Bedrock console, chọn Model access trong navigation pane.
- Chọn Enable specific models.
- Chọn tất cả các Anthropic và Amazon models, sau đó chọn Next.
Một cửa sổ mới sẽ liệt kê các requested models.
- Xác nhận rằng các Amazon Titan models và Anthropic Claude models có trong danh sách này, sau đó chọn Submit.
Bước tiếp theo là tạo một Amazon SageMaker Ground Truth private labeling workforce để thực hiện các hoạt động back-office.
Nếu bạn chưa có private labeling workforce trong tài khoản, bạn có thể tạo theo các bước sau:
- Trên SageMaker console, dưới Ground Truth trong navigation pane, chọn Labeling workforce.
- Trong tab Private, chọn Create private team.
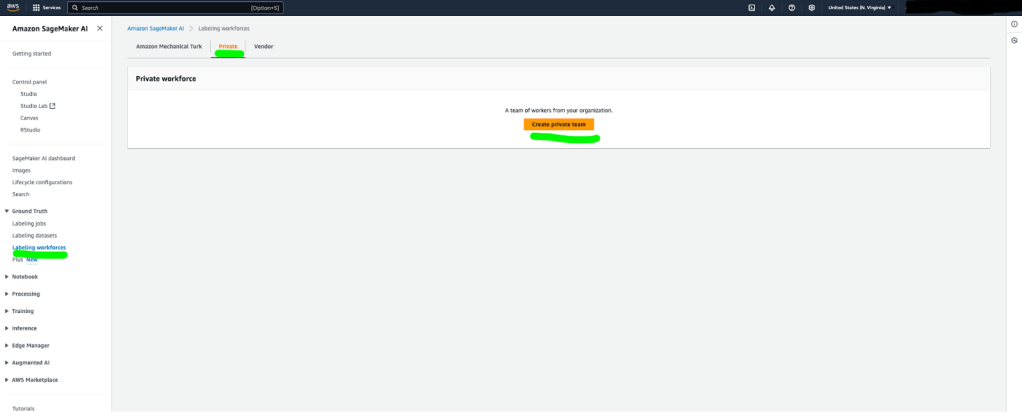
- Cung cấp tên cho team và organization, đồng thời nhập địa chỉ email (phải hợp lệ) cho cả Email addresses và Contact email.
- Giữ tất cả các tùy chọn khác ở default.
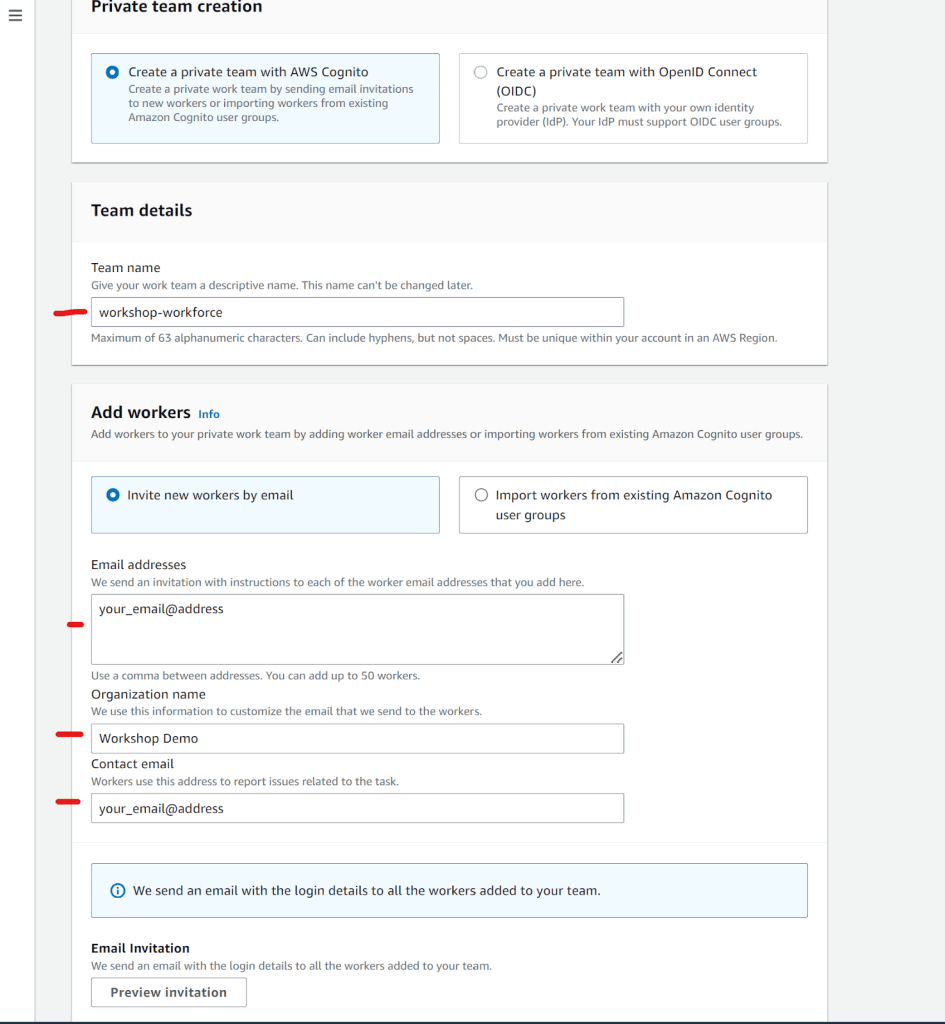
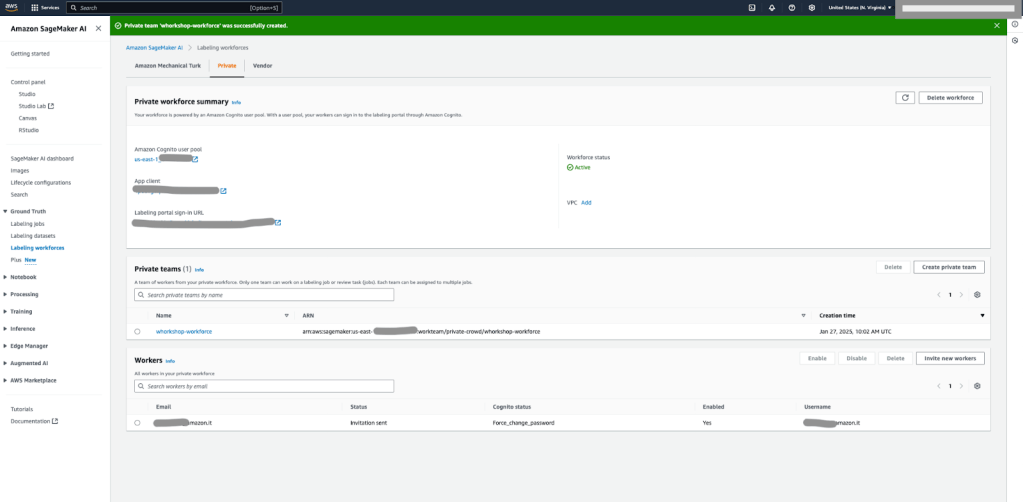
- Chọn Create private team.
- Sau khi workforce được tạo, sao chép Amazon Resource Name (ARN) của workforce trên tab Private và lưu lại để sử dụng sau.
Cuối cùng, xây dựng một Lambda layer bao gồm hai Python libraries.
Để tạo layer này, kết nối với môi trường phát triển và thực hiện các lệnh sau:
git clone https://github.com/aws-samples/Build_a_computer_vision_based_asset_inventory_app_with_low_no_training
cd Build_a_computer_vision_based_asset_inventory_app_with_low_no_training
bash build_lambda_layer.shBạn sẽ nhận được kết quả tương tự như screenshot sau:
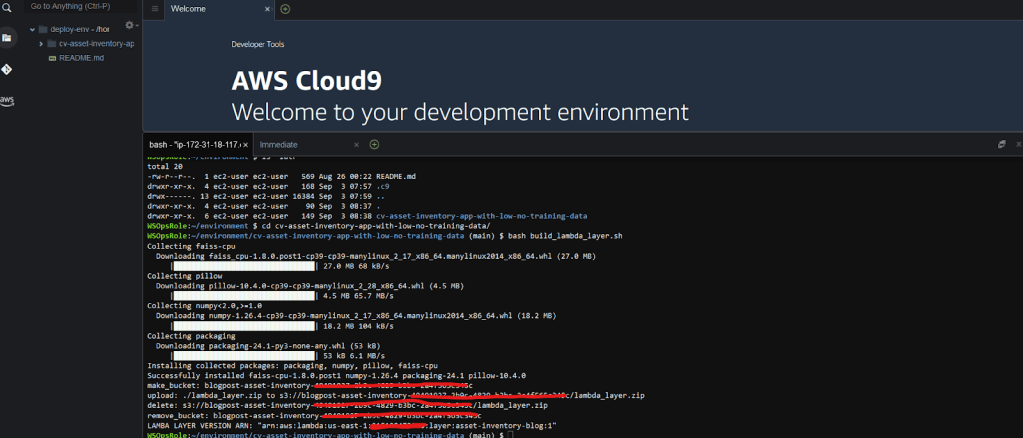
Lưu lại LAMBDA_LAYER_VERSION_ARN để sử dụng sau.
Bây giờ bạn đã sẵn sàng để deploy backend infrastructure và frontend application.
Deploy the backend infrastructure
Backend được triển khai bằng AWS CloudFormation để xây dựng các thành phần sau:
- API Gateway để làm integration layer giữa frontend application và backend.
- S3 bucket để lưu trữ uploaded images và knowledge base.
- Amazon Cognito để cho phép end-user authentication.
- Một tập hợp Lambda functions để triển khai các backend services.
- Amazon A2I workflow để hỗ trợ các hoạt động back-office.
- SQS queue để lưu trữ các knowledge base update requests.
- EventBridge rule để kích hoạt Lambda function ngay khi Amazon A2I workflow hoàn tất.
- DynamoDB table để lưu trữ inventory data.
- IAM roles and policies để cho phép các thành phần truy cập lẫn nhau và truy cập Amazon Bedrock cho các tác vụ liên quan đến generative AI.
Tải xuống CloudFormation template, sau đó thực hiện các bước sau:
- Trên AWS CloudFormation console, chọn Create stack.
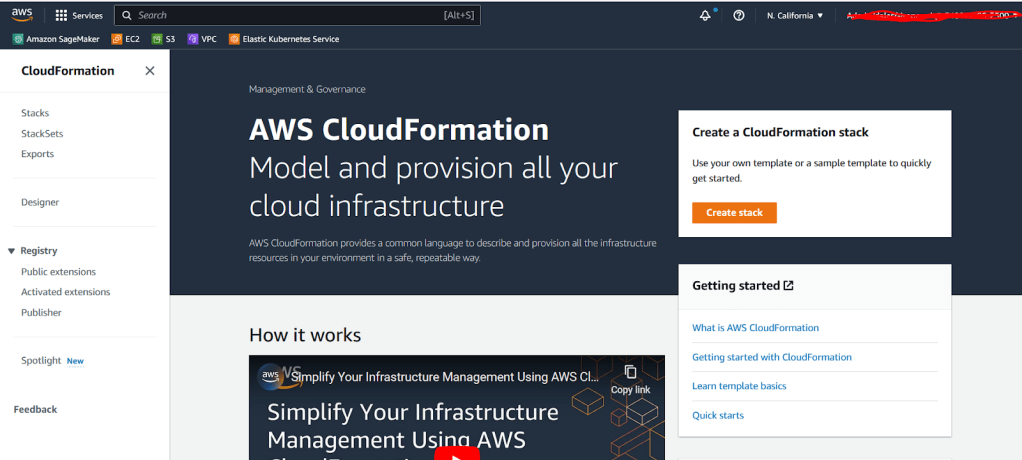
- Chọn Upload a template file và nhấn Choose file để tải lên template đã tải xuống.
- Chọn Next.
- Trong Stack name, nhập tên (ví dụ: asset-inventory).
- Trong A2IWorkforceARN, nhập ARN của labeling workforce bạn đã xác định.
- Trong LambdaLayerARN, nhập ARN của Lambda layer version bạn đã upload.
- Chọn Next và Next lần nữa.
- Xác nhận rằng AWS CloudFormation sẽ tạo các IAM resources và chọn Submit.
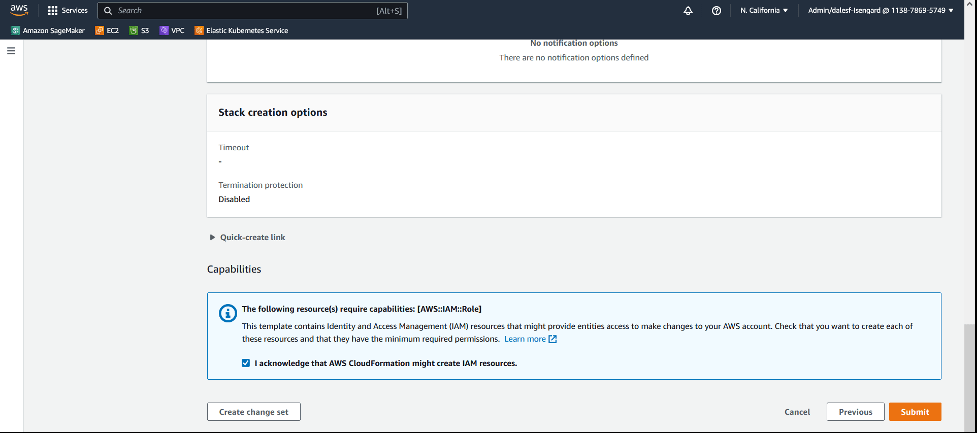
Chờ đến khi quá trình tạo CloudFormation stack hoàn tất; mất khoảng 15–20 phút. Sau đó, bạn có thể xem chi tiết stack.
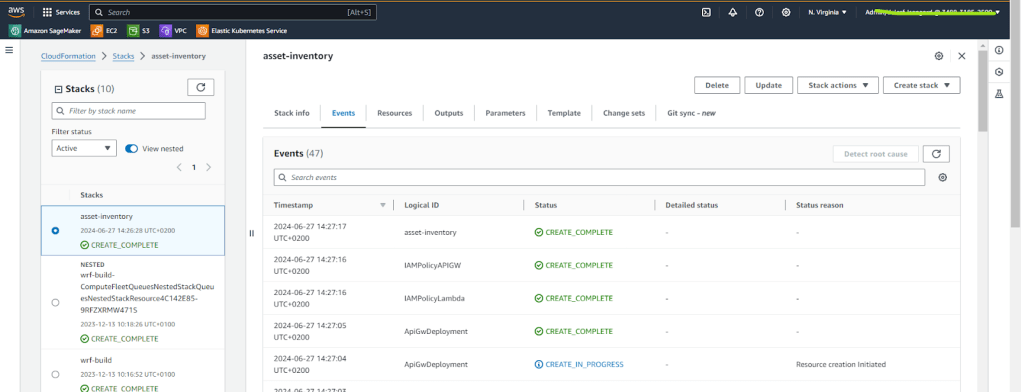
Ghi chú các giá trị trên tab Outputs. Bạn sẽ sử dụng dữ liệu này sau để hoàn tất cấu hình của frontend application.
Deploy the frontend application
Trong phần này, bạn sẽ xây dựng web application được on-site operator sử dụng để, chụp hình labels, gửi hình đến backend services để extract relevant information, validate hoặc chỉnh sửa thông tin trả về, gửi thông tin đã validated hoặc corrected để lưu trữ trong asset inventory.
Web application sử dụng React và Amplify JavaScript Library.
Amplify cung cấp nhiều sản phẩm để xây dựng full stack applications:
- Amplify CLI – Giao diện dòng lệnh đơn giản để thiết lập các dịch vụ cần thiết.
- Amplify Libraries – Các client libraries theo use-case để tích hợp frontend code với backend.
- Amplify UI Components – Thư viện UI cho React, React Native, Angular, Vue, Flutter.
Trong ví dụ này, bạn đã tạo sẵn các dịch vụ cần thiết bằng CloudFormation template, vì vậy Amplify CLI sẽ triển khai ứng dụng trên Amplify provided hosting service.
Các bước triển khai:
- Đăng nhập vào môi trường phát triển và tải mã nguồn từ GitHub:
git clone https://github.com/aws-samples/Build_a_computer_vision_based_asset_inventory_app_with_low_no_training
cd Build_a_computer_vision_based_asset_inventory_app_with_low_no_training
cd webapp- Nếu sử dụng AWS Cloud9 làm môi trường phát triển, chạy lệnh sau để Amplify CLI sử dụng AWS Cloud9 managed credentials:
ln -s $HOME/.aws/credentials $HOME/.aws/config- Khởi tạo ứng dụng Amplify bằng CLI:
amplify initSau khi xử lý lệnh đó, Amplify CLI sẽ yêu cầu nhập một số thông số.
- Chọn default values bằng cách nhấn Enter cho mỗi câu hỏi.
- Bước tiếp theo sửa file amplifyconfiguration.js.template (trong webapp/src) với thông tin từ CloudFormation stack Outputs, lưu lại dưới tên amplifyconfiguration.js File này hướng dẫn Amplify biết endpoint chính xác để tương tác với backend resources đã tạo. Thông tin cần điền:
- aws_project_region và aws_cognito_region – Region nơi bạn chạy CloudFormation template (ví dụ: us-east-1).
- aws_cognito_identity_pool_id, aws_user_pools_id, aws_user_pools_web_client_id – Lấy từ Outputs tab của CloudFormation stack.
- Endpoint – Trong phần API, cập nhật endpoint với API Gateway URL từ Outputs tab.
- Bây giờ bạn cần thêm một hosting option cho single-page application.Bạn có thể sử dụng Amplify để configure và host ứng dụng web bằng cách chạy lệnh sau:
amplify hosting addAmplify CLI sẽ hỏi loại hosting service và kiểu triển khai.
- Trả lời cả hai câu hỏi bằng cách chọn default option và nhấn Enter.
- Bây giờ bạn cần cài đặt các JavaScript libraries được sử dụng bởi ứng dụng này bằng npm:
npm install- Triển khai ứng dụng:
amplify publish- Xác nhận bằng cách nhập Y.
Sau khi triển khai xong, Amplify sẽ trả về public URL của ứng dụng web, ví dụ:
...
Find out more about deployment here:
https://cra.link/deployment
Zipping artifacts completed.
Deployment complete!
https://dev.xxx.amplifyapp.comBây giờ bạn có thể mở browser và truy cập ứng dụng thông qua URL được cung cấp.
Clean up
Để xóa các resources đã sử dụng để xây dựng giải pháp này, thực hiện các bước sau:
- Xóa ứng dụng Amplify
- Thực hiện lệnh sau.
amplify delete- Xác nhận rằng bạn muốn xóa ứng dụng.
- Xóa các backend resources
- Trên AWS CloudFormation console, chọn Stacks trong navigation pane.
- Chọn stack và nhấn Delete.
- Chọn Delete để xác nhận.
Cuối quá trình xóa, bạn sẽ không thấy mục liên quan đến asset-inventory trong danh sách stacks nữa.
- Xóa Lambda layer bằng cách chạy lệnh sau trong môi trường phát triển:
aws lambda delete-layer-version —layer-name asset-inventory-blog —version-number 1- Nếu bạn đã tạo một new labeling workforce, hãy xóa nó bằng cách sử dụng lệnh sau:
aws delete-workteam —workteam-name <the name you defined when you created the workteam>Conclusion
Trong bài viết này, chúng tôi đã giới thiệu một giải pháp kết hợp nhiều AWS services để xử lý image storage (Amazon S3), mobile app development (Amplify), AI model hosting (Amazon Bedrock sử dụng Anthropic’s Claude), data verification (Amazon A2I), database (DynamoDB), và vector embeddings (Amazon Bedrock sử dụng Amazon Titan Multimodal Embeddings). Giải pháp này tạo ra một seamless workflow cho field data collection, AI-powered extraction, human validation, và inventory updates.
Bằng cách tận dụng sự phong phú của các AWS services và tích hợp khả năng generative AI, giải pháp này cải thiện đáng kể efficiency và accuracy trong quy trình quản lý asset inventory. Nó giảm bớt lao động thủ công, tăng tốc data entry, và duy trì high-quality inventory records, giúp các tổ chức tối ưu hóa việc asset tracking và maintenance operations.
Bạn có thể triển khai giải pháp này và ngay lập tức bắt đầu thu thập hình ảnh assets để xây dựng hoặc cập nhật asset inventory.
Về tác giả

Federico D’Alessio là một AWS Solutions Architect và đã gia nhập AWS vào năm 2018. Hiện tại, anh đang làm việc trong lĩnh vực Năng lượng & Tiện ích và Vận tải. Federico là một người “nghiện cloud”, và khi không làm việc, anh thường cố gắng “chạm đến những đám mây” bằng chiếc hang glider của mình.

Leonardo Fenu là một Solutions Architect, người đã hỗ trợ các khách hàng của AWS điều chỉnh công nghệ của họ phù hợp với mục tiêu kinh doanh kể từ năm 2018. Khi không leo núi hoặc dành thời gian cho gia đình, anh thích nghiên cứu phần cứng và phần mềm, khám phá các công nghệ cloud mới nhất và tìm ra những cách sáng tạo để giải quyết các vấn đề phức tạp.

Elisabetta Castellano là một AWS Solutions Architect, tập trung vào việc hỗ trợ khách hàng phát huy tối đa tiềm năng cloud computing, với chuyên môn về machine learning và generative AI. Cô yêu thích đắm mình trong điện ảnh, các buổi biểu diễn âm nhạc trực tiếp, và sách.

Carmela Gambardella là một AWS Solutions Architect từ tháng 4 năm 2018. Trước khi gia nhập AWS, Carmela từng đảm nhiệm nhiều vai trò khác nhau tại các công ty CNTT lớn, như software engineer, security consultant và solutions architect. Cô đã vận dụng kinh nghiệm của mình trong lĩnh vực security, compliance và cloud operations để hỗ trợ các tổ chức thuộc khu vực công trong hành trình chuyển đổi lên cloud. Trong thời gian rảnh, cô là một người đam mê đọc sách, thích leo núi, du lịch, và tập yoga.
