Tác giả: Donnie Prakoso
Ngày phát hành: 03/12/2025
Chuyên mục: Amazon Bedrock, Amazon Machine Learning, Announcements, Artificial Intelligence, AWS re:Invent, Events, Launch, News, Serverless
Các tổ chức phải đối mặt với một sự đánh đổi đầy thách thức khi điều chỉnh các mô hình AI cho nhu cầu kinh doanh cụ thể của họ: chấp nhận các mô hình chung chung cho kết quả trung bình, hoặc đối mặt với sự phức tạp và chi phí của việc tùy chỉnh mô hình nâng cao. Các phương pháp truyền thống buộc phải lựa chọn giữa hiệu suất kém với các mô hình nhỏ hơn hoặc chi phí cao khi triển khai các biến thể mô hình lớn hơn và quản lý cơ sở hạ tầng phức tạp. Tinh chỉnh tăng cường là một kỹ thuật nâng cao giúp huấn luyện các mô hình bằng cách sử dụng phản hồi thay vì các bộ dữ liệu được gán nhãn khổng lồ, nhưng việc triển khai nó thường đòi hỏi chuyên môn ML chuyên sâu, cơ sở hạ tầng phức tạp và đầu tư đáng kể—mà không có gì đảm bảo sẽ đạt được độ chính xác cần thiết cho các trường hợp sử dụng cụ thể.
Hôm nay, chúng tôi công bố tính năng tinh chỉnh tăng cường trong Amazon Bedrock, một khả năng tùy chỉnh mô hình mới giúp tạo ra các mô hình thông minh hơn, tiết kiệm chi phí hơn, học hỏi từ phản hồi và cung cấp kết quả đầu ra chất lượng cao hơn cho các nhu cầu kinh doanh cụ thể. Tinh chỉnh tăng cường sử dụng phương pháp tiếp cận dựa trên phản hồi, trong đó các mô hình cải thiện lặp đi lặp lại dựa trên các tín hiệu phần thưởng, mang lại mức tăng độ chính xác trung bình 66% so với các mô hình cơ sở.
Amazon Bedrock tự động hóa quy trình tinh chỉnh tăng cường, giúp các nhà phát triển thông thường có thể tiếp cận kỹ thuật tùy chỉnh mô hình nâng cao này mà không cần chuyên môn sâu về machine learning (ML) hay các bộ dữ liệu được gán nhãn lớn.
Cách hoạt động của tinh chỉnh tăng cường
Tinh chỉnh tăng cường được xây dựng dựa trên các nguyên tắc của học tăng cường (reinforcement learning) để giải quyết một thách thức chung: làm cho các mô hình liên tục tạo ra các kết quả đầu ra phù hợp với yêu cầu kinh doanh và sở thích của người dùng.
Trong khi tinh chỉnh truyền thống đòi hỏi các bộ dữ liệu lớn, được gán nhãn và việc chú thích thủ công tốn kém, thì tinh chỉnh tăng cường lại có một cách tiếp cận khác. Thay vì học từ các ví dụ cố định, nó sử dụng các hàm phần thưởng (reward functions) để đánh giá và phán đoán xem phản hồi nào được coi là tốt cho các trường hợp sử dụng kinh doanh cụ thể. Điều này dạy cho các mô hình cách hiểu điều gì tạo nên một phản hồi chất lượng mà không cần một lượng lớn dữ liệu huấn luyện được gán nhãn trước, giúp việc tùy chỉnh mô hình nâng cao trong Amazon Bedrock trở nên dễ tiếp cận và tiết kiệm chi phí hơn.
Dưới đây là những lợi ích của việc sử dụng tinh chỉnh tăng cường trong Amazon Bedrock:
- Dễ sử dụng – Amazon Bedrock tự động hóa phần lớn sự phức tạp, giúp các nhà phát triển xây dựng ứng dụng AI dễ dàng tiếp cận hơn với tinh chỉnh tăng cường. Các mô hình có thể được huấn luyện bằng cách sử dụng nhật ký API hiện có trong Amazon Bedrock hoặc bằng cách tải lên các bộ dữ liệu làm dữ liệu huấn luyện, loại bỏ nhu cầu về bộ dữ liệu được gán nhãn hoặc thiết lập cơ sở hạ tầng.
- Hiệu suất mô hình tốt hơn – Tinh chỉnh tăng cường cải thiện độ chính xác của mô hình trung bình 66% so với các mô hình cơ sở, cho phép tối ưu hóa về giá cả và hiệu suất bằng cách huấn luyện các biến thể mô hình nhỏ hơn, nhanh hơn và hiệu quả hơn. Tính năng này hoạt động với mô hình Amazon Nova 2 Lite, cải thiện chất lượng và hiệu suất giá cho các nhu cầu kinh doanh cụ thể, và sẽ sớm hỗ trợ thêm các mô hình khác.
- Bảo mật – Dữ liệu vẫn nằm trong môi trường AWS an toàn trong suốt quá trình tùy chỉnh, giảm thiểu các lo ngại về bảo mật và tuân thủ.
Khả năng này hỗ trợ hai phương pháp bổ sung cho nhau để cung cấp sự linh hoạt trong việc tối ưu hóa mô hình:
- Reinforcement Learning with Verifiable Rewards (RLVR) sử dụng các bộ phân loại dựa trên quy tắc cho các tác vụ khách quan như tạo mã hoặc suy luận toán học.
- Reinforcement Learning from AI Feedback (RLAIF) sử dụng các bộ đánh giá dựa trên AI cho các tác vụ chủ quan như tuân theo chỉ dẫn hoặc kiểm duyệt nội dung.
Bắt đầu với tinh chỉnh tăng cường trong Amazon Bedrock
Hãy cùng thực hiện các bước để tạo một công việc tinh chỉnh tăng cường.
Đầu tiên, tôi truy cập bảng điều khiển Amazon Bedrock. Sau đó, tôi điều hướng đến trang Custom models. Tôi chọn Create và sau đó chọn Reinforcement fine-tuning job.
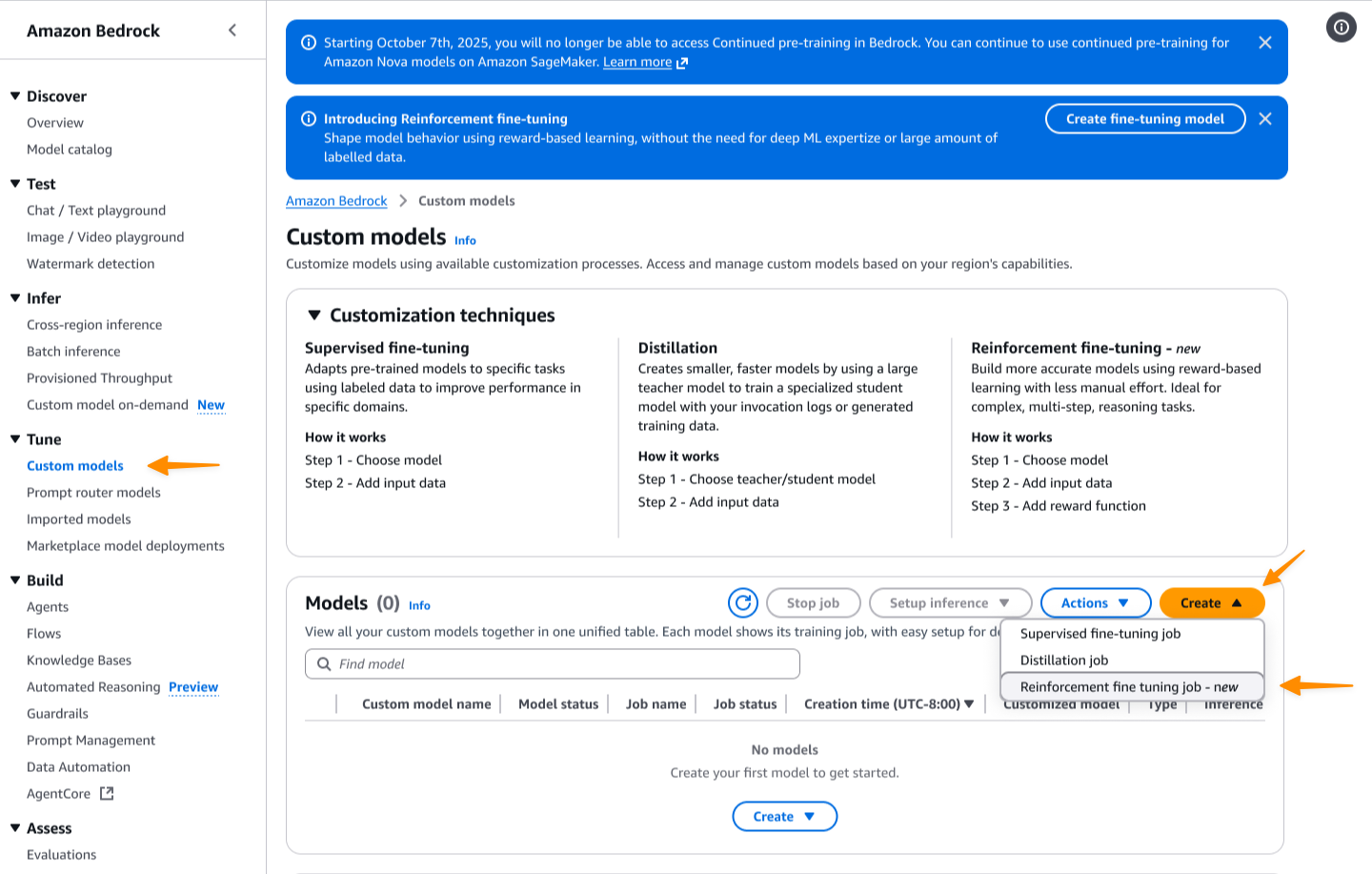
Hình 1: Tạo một công việc tinh chỉnh tăng cường mới.
Tôi bắt đầu bằng cách nhập tên cho công việc tùy chỉnh này và sau đó chọn mô hình cơ sở của mình. Tại thời điểm ra mắt, tinh chỉnh tăng cường hỗ trợ Amazon Nova 2 Lite, và sẽ sớm hỗ trợ thêm các mô hình khác.
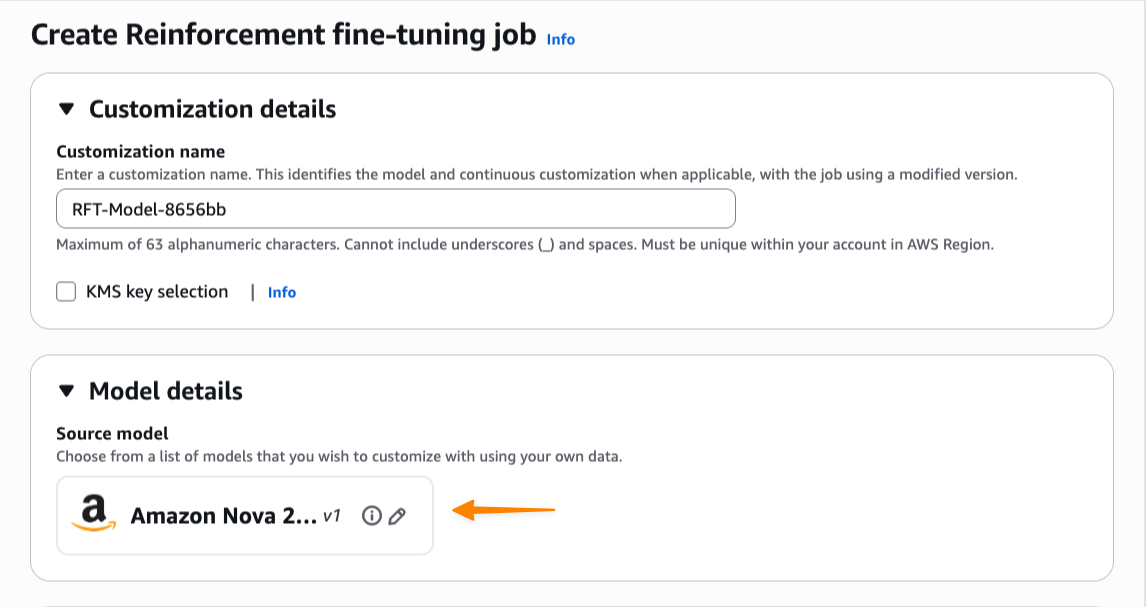
Hình 2: Lựa chọn mô hình cơ sở Amazon Nova 2 Lite.
Tiếp theo, tôi cần cung cấp dữ liệu huấn luyện. Tôi có thể sử dụng trực tiếp nhật ký gọi lệnh (invocation logs) đã lưu trữ của mình, loại bỏ nhu cầu tải lên các bộ dữ liệu riêng biệt. Tôi cũng có thể tải lên các tệp JSONL mới hoặc chọn các bộ dữ liệu hiện có từ Amazon Simple Storage Service (Amazon S3). Tinh chỉnh tăng cường tự động xác thực bộ dữ liệu huấn luyện của tôi và hỗ trợ định dạng dữ liệu OpenAI Chat Completions. Nếu tôi cung cấp nhật ký gọi lệnh ở định dạng invoke hoặc converse của Amazon Bedrock, Amazon Bedrock sẽ tự động chuyển đổi chúng sang định dạng Chat Completions.
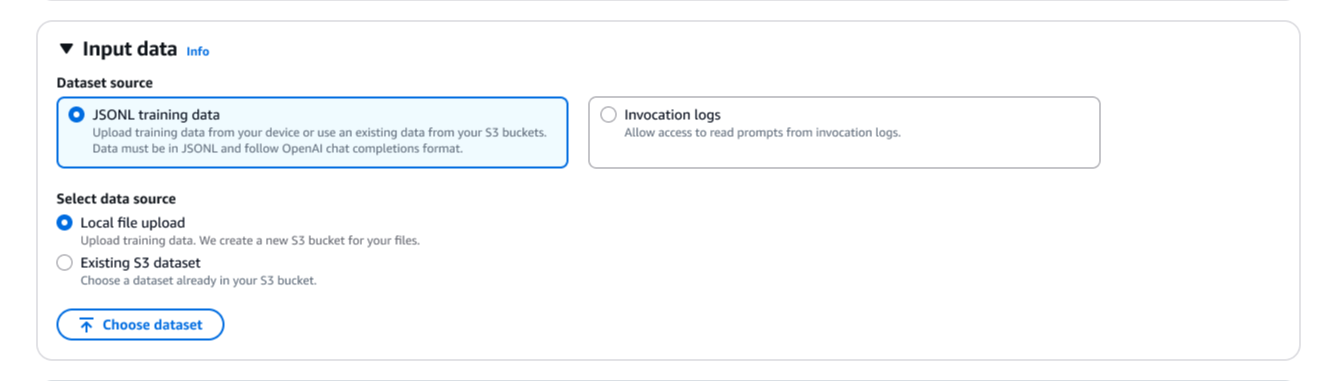
Hình 3: Cấu hình nguồn dữ liệu huấn luyện.
Thiết lập hàm phần thưởng là nơi tôi xác định điều gì tạo nên một phản hồi tốt. Tôi có hai lựa chọn ở đây. Đối với các tác vụ khách quan, tôi có thể chọn Custom code và viết mã Python tùy chỉnh được thực thi thông qua các hàm AWS Lambda. Đối với các đánh giá chủ quan hơn, tôi có thể chọn Model as judge để sử dụng các foundation models (FMs) làm giám khảo bằng cách cung cấp các hướng dẫn đánh giá.
Ở đây, tôi chọn Custom code, và tôi tạo một hàm Lambda mới hoặc sử dụng một hàm hiện có làm hàm phần thưởng. Tôi có thể bắt đầu với một trong các mẫu được cung cấp và tùy chỉnh nó cho các nhu cầu cụ thể của mình.

Hình 4: Cấu hình hàm phần thưởng với AWS Lambda.
Tôi có thể tùy chọn sửa đổi các siêu tham số (hyperparameters) mặc định như tốc độ học (learning rate), kích thước lô (batch size) và số kỷ nguyên (epochs).

Hình 5: Điều chỉnh các siêu tham số của công việc tinh chỉnh.
Để tăng cường bảo mật, tôi có thể cấu hình cài đặt đám mây riêng ảo (VPC) và mã hóa AWS Key Management Service (AWS KMS) để đáp ứng các yêu cầu tuân thủ của tổ chức tôi. Sau đó, tôi chọn Create để bắt đầu công việc tùy chỉnh mô hình.
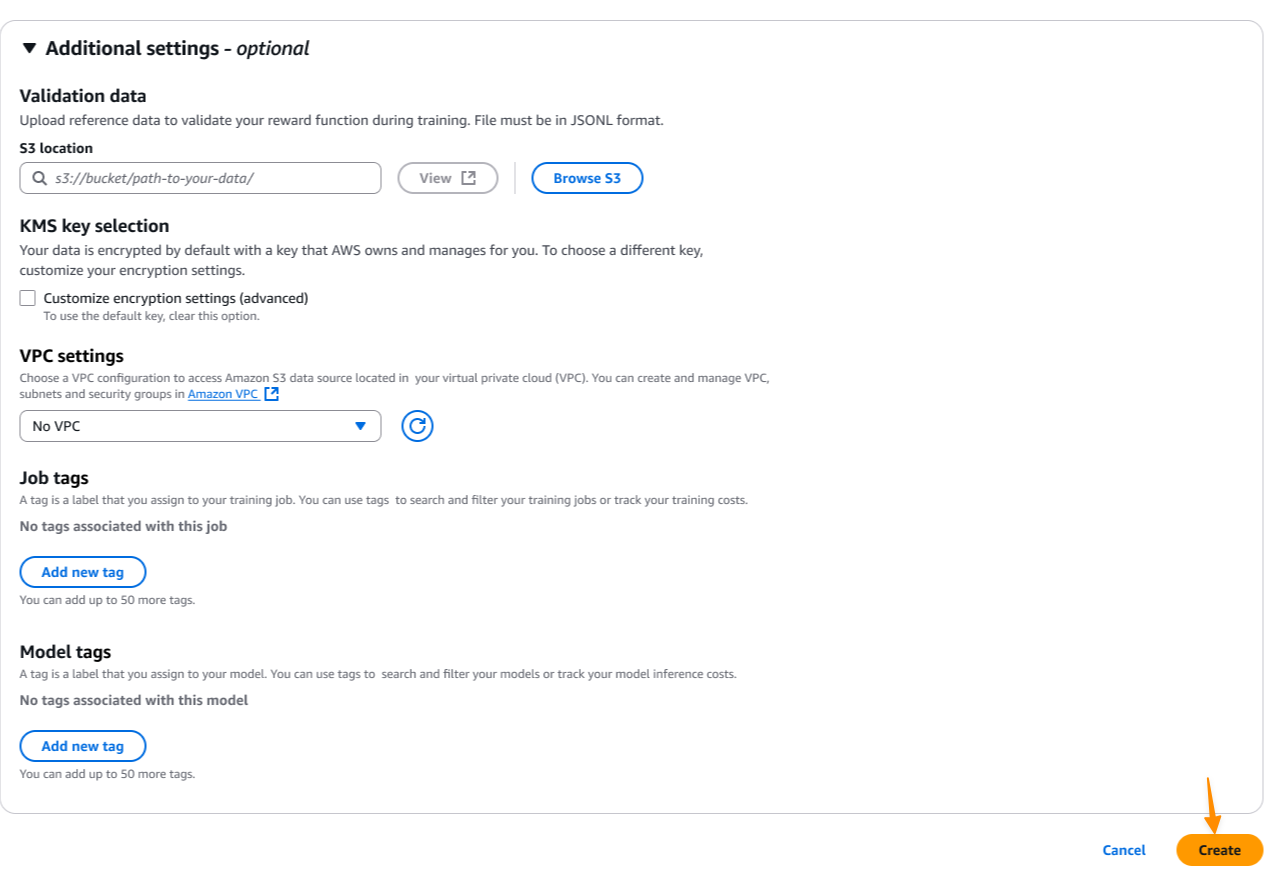
Hình 6: Hoàn tất cấu hình bảo mật và bắt đầu công việc.
Trong quá trình huấn luyện, tôi có thể theo dõi các chỉ số thời gian thực để hiểu mô hình đang học như thế nào. Bảng điều khiển chỉ số huấn luyện hiển thị các chỉ số hiệu suất chính bao gồm điểm phần thưởng, đường cong mất mát (loss curves) và các cải thiện về độ chính xác theo thời gian. Những chỉ số này giúp tôi hiểu liệu mô hình có đang hội tụ đúng cách hay không và liệu hàm phần thưởng có đang hướng dẫn quá trình học một cách hiệu quả hay không.

Hình 7: Theo dõi tiến trình và hiệu suất của công việc huấn luyện.
Khi công việc tinh chỉnh tăng cường hoàn tất, tôi có thể xem trạng thái cuối cùng của công việc trên trang Model details.
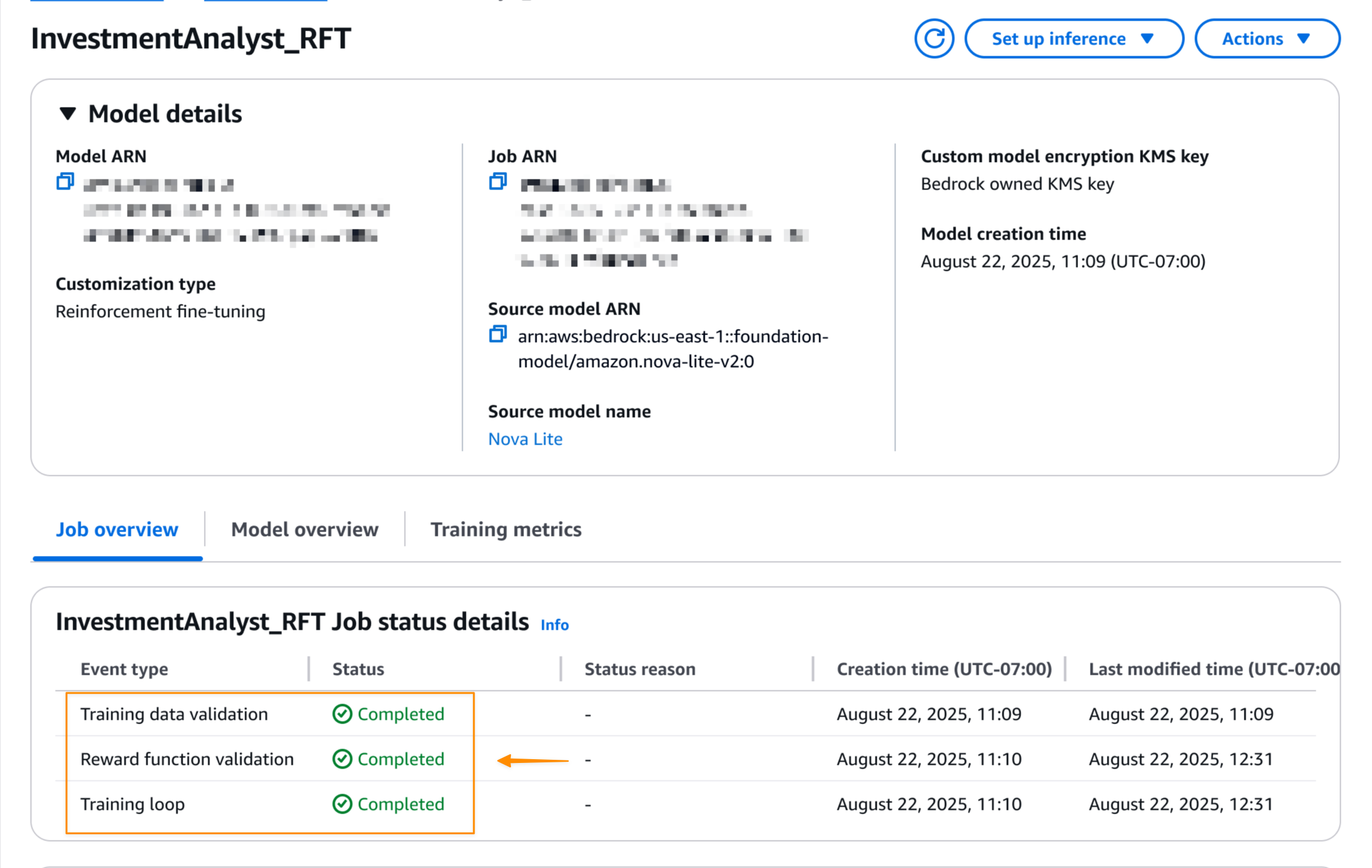
Hình 8: Xem lại chi tiết công việc đã hoàn thành.
Sau khi công việc hoàn tất, tôi có thể triển khai mô hình chỉ bằng một cú nhấp chuột. Tôi chọn Set up inference, sau đó chọn Deploy for on-demand.

Hình 9: Bắt đầu quá trình triển khai mô hình.
Tại đây, tôi cung cấp một vài chi tiết cho mô hình của mình.
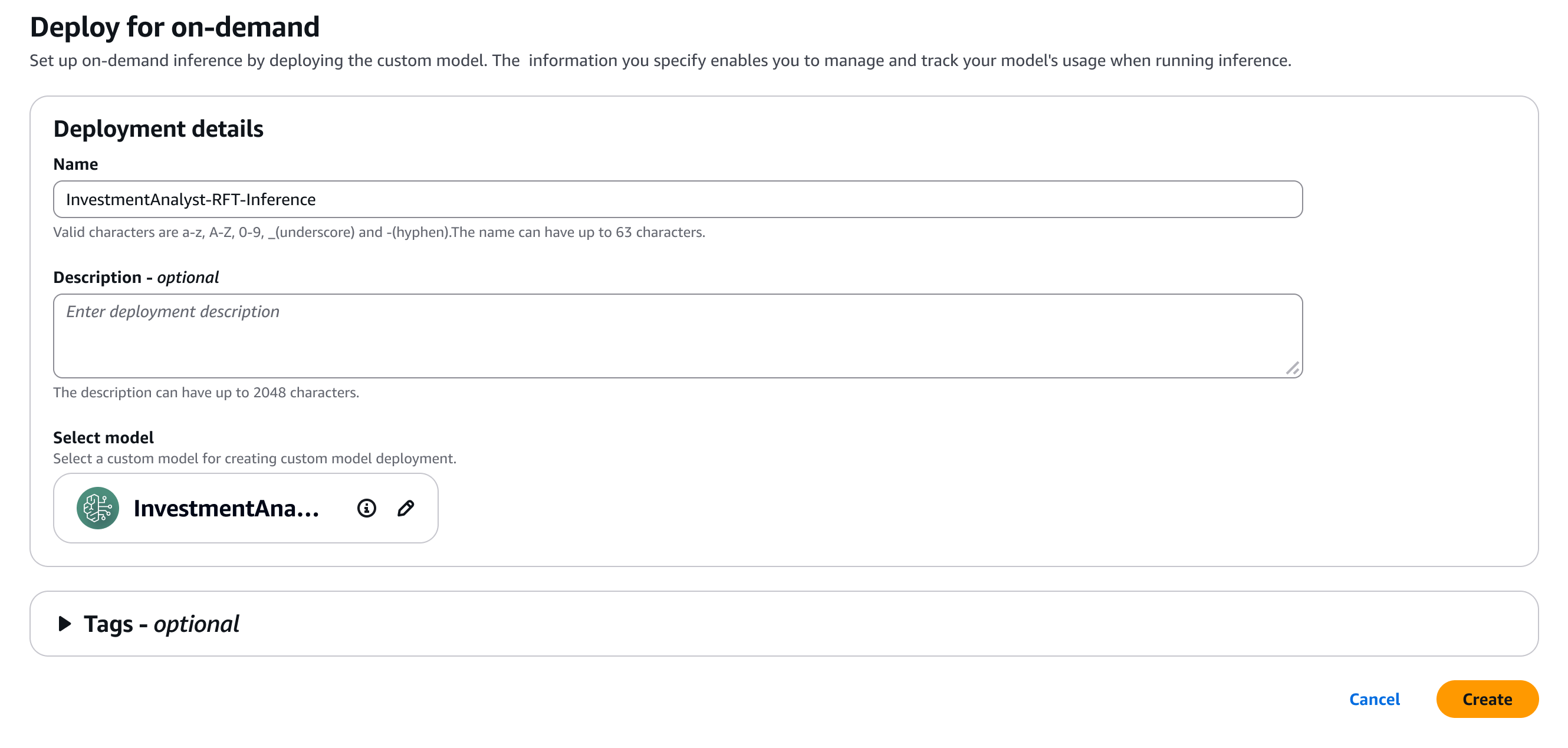
Hình 10: Cấu hình các thông số triển khai.
Sau khi triển khai, tôi có thể nhanh chóng đánh giá hiệu suất của mô hình bằng cách sử dụng playground của Amazon Bedrock. Điều này giúp tôi kiểm tra mô hình đã được tinh chỉnh với các câu lệnh mẫu và so sánh phản hồi của nó với mô hình cơ sở để xác thực các cải tiến. Tôi chọn Test in playground.
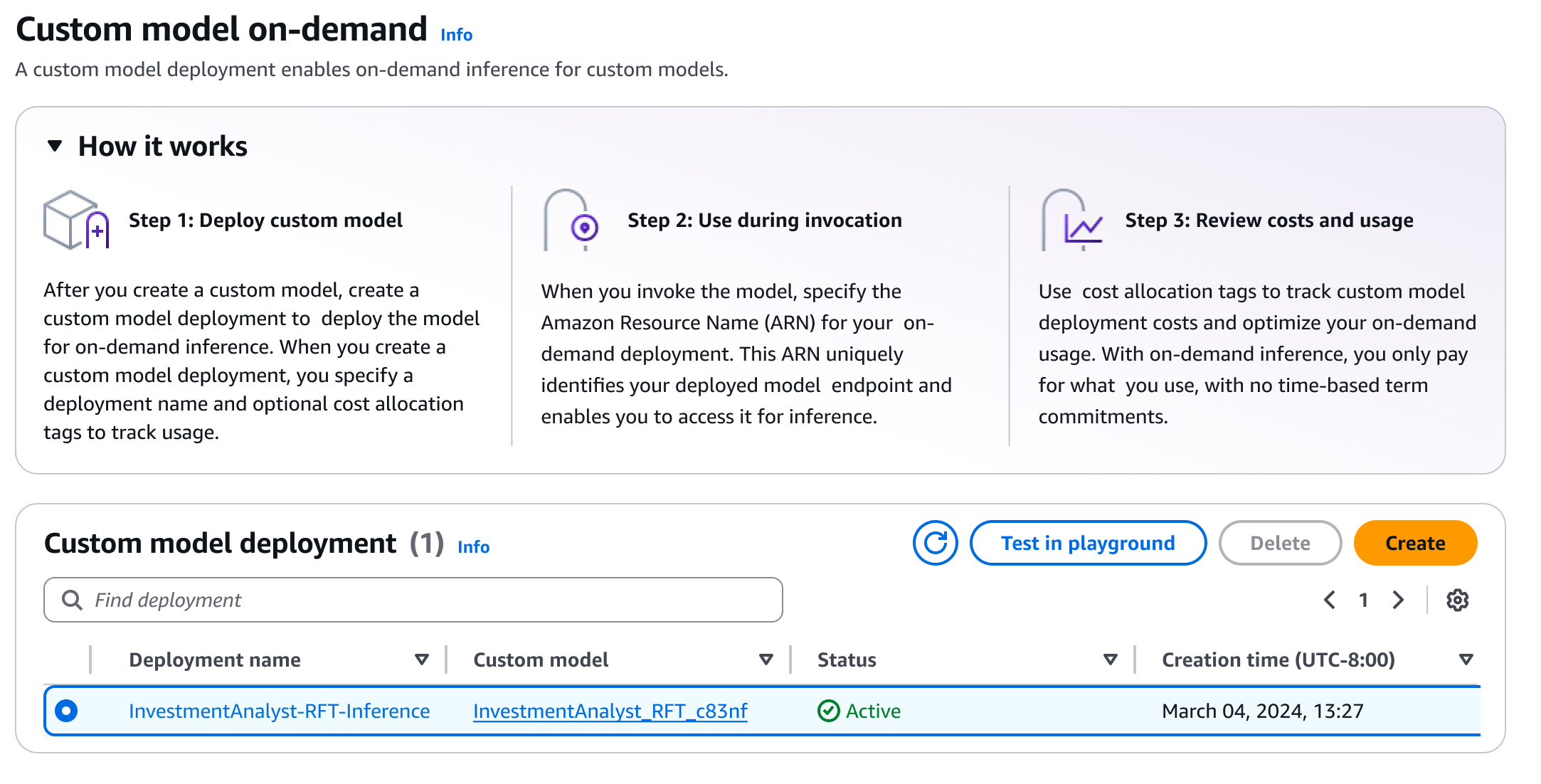
Hình 11: Chuyển đến playground để thử nghiệm.
Playground cung cấp một giao diện trực quan để kiểm tra và lặp lại nhanh chóng, giúp tôi xác nhận rằng mô hình đáp ứng các yêu cầu chất lượng của mình trước khi tích hợp nó vào các ứng dụng sản xuất.
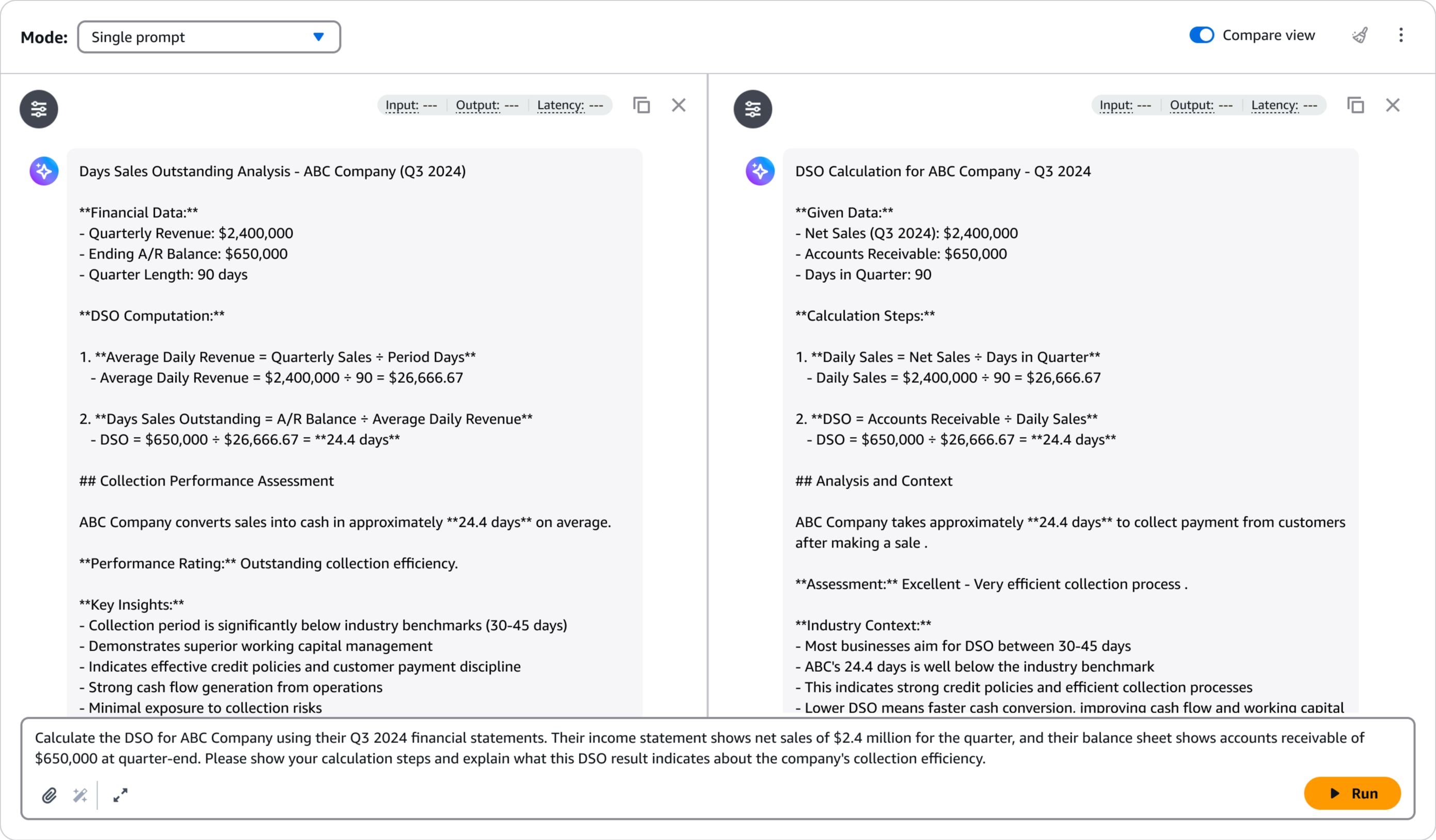
Hình 12: So sánh và đánh giá hiệu suất mô hình trong playground.
Demo tương tác
Tìm hiểu thêm bằng cách điều hướng qua một bản demo tương tác về tinh chỉnh tăng cường của Amazon Bedrock đang hoạt động.

Hình 13: Khám phá bản demo tương tác.
Những điều cần biết thêm
Dưới đây là những điểm chính cần lưu ý:
- Mẫu (Templates) — Có bảy mẫu hàm phần thưởng sẵn sàng sử dụng bao gồm các trường hợp sử dụng phổ biến cho cả tác vụ khách quan và chủ quan.
- Giá cả — Để tìm hiểu thêm về giá cả, hãy tham khảo trang giá của Amazon Bedrock.
- Bảo mật — Dữ liệu huấn luyện và các mô hình tùy chỉnh vẫn được giữ riêng tư và không được sử dụng để cải thiện các FM cho mục đích công cộng. Nó hỗ trợ mã hóa VPC và AWS KMS để tăng cường bảo mật.
Hãy bắt đầu với tinh chỉnh tăng cường bằng cách truy cập tài liệu về tinh chỉnh tăng cường và truy cập bảng điều khiển Amazon Bedrock.
Chúc bạn xây dựng thành công!
— Donnie
Về tác giả

Donnie Prakoso
Donnie Prakoso là một kỹ sư phần mềm, một barista tự phong và là Principal Developer Advocate tại AWS. Với hơn 17 năm kinh nghiệm trong ngành công nghệ, từ viễn thông, ngân hàng đến các startup. Hiện tại, anh đang tập trung vào việc giúp các nhà phát triển hiểu rõ các loại công nghệ khác nhau để biến ý tưởng của họ thành hiện thực. Anh yêu thích cà phê và mọi cuộc thảo luận về bất kỳ chủ đề nào từ microservices đến AI/ML.
