bởi John Kitaoka, Varun Jasti, and Baladithya Balamurugan vào NGÀY 16 THÁNG 4 2025 trong Amazon EC2, Artificial Intelligence, Generative AI, Technical How-to Permalink
Các doanh nghiệp ngày càng tìm kiếm các mô hình nền tảng (Foundation Models – FMs) được tùy chỉnh theo miền và chuyên biệt để đáp ứng những nhu cầu cụ thể trong các lĩnh vực như tóm tắt tài liệu, tùy chỉnh theo ngành, và tạo cũng như tư vấn mã nguồn kỹ thuật. Việc sử dụng ngày càng phổ biến các mô hình AI tạo sinh đã mang đến những trải nghiệm tùy chỉnh với yêu cầu kỹ thuật tối thiểu, và các tổ chức đang ngày càng tận dụng sức mạnh của các mô hình này để thúc đẩy đổi mới và nâng cao chất lượng dịch vụ trong nhiều lĩnh vực khác nhau, từ xử lý ngôn ngữ tự nhiên (NLP) đến tạo nội dung.
Tuy nhiên, việc sử dụng các mô hình AI tạo sinh trong môi trường doanh nghiệp cũng mang đến những thách thức riêng biệt. Các mô hình “dùng ngay” thường thiếu kiến thức chuyên sâu cần thiết cho một số lĩnh vực hoặc thuật ngữ đặc thù của tổ chức. Để giải quyết vấn đề này, các doanh nghiệp đang chuyển sang sử dụng các mô hình được tinh chỉnh, còn được gọi là mô hình ngôn ngữ lớn theo miền. Những mô hình này được tùy chỉnh để thực hiện các tác vụ chuyên biệt trong một hoặc nhiều miền nhỏ.
Tương tự, các tổ chức cũng đang tinh chỉnh mô hình AI tạo sinh cho nhiều lĩnh vực khác nhau như tài chính, bán hàng, marketing, du lịch, công nghệ thông tin, nhân sự, mua sắm, y tế và khoa học đời sống, cũng như dịch vụ khách hàng. Ngoài ra, các nhà cung cấp phần mềm độc lập cũng đang xây dựng các nền tảng AI tạo sinh có tính bảo mật cao, được quản lý và hỗ trợ đa người dùng.Khi nhu cầu về các giải pháp AI cá nhân hóa và chuyên biệt ngày càng tăng, các doanh nghiệp phải đối mặt với thách thức trong việc quản lý và triển khai hiệu quả hàng loạt mô hình tinh chỉnh cho nhiều trường hợp sử dụng và phân khúc khách hàng khác nhau. Từ phân tích hồ sơ xin việc và ghép kỹ năng công việc, đến tạo email chuyên biệt theo lĩnh vực và hiểu ngôn ngữ tự nhiên, nhiều công ty đang phải xử lý hàng trăm mô hình tinh chỉnh được phát triển cho các nhu cầu cụ thể.Thách thức này càng trở nên phức tạp hơn bởi vấn đề về khả năng mở rộng và hiệu quả chi phí. Các phương pháp phục vụ mô hình truyền thống có thể trở nên cồng kềnh và tốn tài nguyên, dẫn đến chi phí hạ tầng tăng cao, gánh nặng vận hành, và nguy cơ tắc nghẽn hiệu năng, do kích thước lớn và yêu cầu phần cứng cao để duy trì hiệu suất cho các mô hình nền .Sơ đồ dưới đây minh họa cách tiếp cận truyền thống trong việc phục vụ nhiều mô hình ngôn ngữ lớn.

Việc tinh chỉnh các mô hình ngôn ngữ lớn LLMs là cực kỳ tốn kém do yêu cầu phần cứng và chi phí liên quan đến việc lưu trữ các phiên bản riêng biệt cho các tác vụ khác nhau.
Trong bài viết này, chúng ta khám phá cách Low-Rank Adaptation (LoRA) có thể được sử dụng để giải quyết những thách thức đó một cách hiệu quả. Cụ thể, chúng ta thảo luận về việc sử dụng LoRA serving với LoRA eXchange (LoRAX) và các phiên bản GPU của Amazon Elastic Compute Cloud (Amazon EC2), cho phép các tổ chức quản lý và triển khai hiệu quả danh mục các mô hình đã được tinh chỉnh ngày càng tăng, tối ưu chi phí và cung cấp hiệu suất mượt mà cho khách hàng.
LoRA là một kỹ thuật để điều chỉnh hiệu quả các mô hình ngôn ngữ lớn đã được tiền huấn luyện cho các tác vụ hoặc lĩnh vực mới bằng cách chèn các ma trận trọng số nhỏ có thể huấn luyện, gọi là adapter, vào mỗi lớp tuyến tính của mô hình tiền huấn luyện. Cách tiếp cận này cho phép thích ứng hiệu quả với số lượng tham số cần huấn luyện giảm đáng kể so với việc tinh chỉnh toàn bộ mô hình.Mặc dù LoRA cho phép thích ứng hiệu quả, việc lưu trữ các mô hình đã được tinh chỉnh thông thường lại hợp nhất các lớp đã tinh chỉnh với trọng số của mô hình gốc, vì vậy các tổ chức có nhiều biến thể đã được tinh chỉnh thường phải lưu trữ từng biến thể trên các phiên bản riêng biệt. Vì các adapter thu được tương đối nhỏ so với mô hình gốc và chỉ nằm ở vài lớp cuối của quá trình suy luận, cách triển khai phục vụ mô hình tùy chỉnh truyền thống này không hiệu quả cả về tài nguyên lẫn chi phí.
Một giải pháp cho vấn đề này được cung cấp bởi một công cụ mã nguồn mở có tên LoRAX, cung cấp cơ chế hoán đổi trọng số trong quá trình suy luận để phục vụ nhiều biến thể của một FM nền tảng. LoRAX loại bỏ việc phải thiết lập thủ công quá trình gắn và tháo adapter với FM đã được tiền huấn luyện khi bạn chuyển đổi giữa việc suy luận các mô hình đã tinh chỉnh cho các miền hoặc trường hợp hướng dẫn khác nhau.
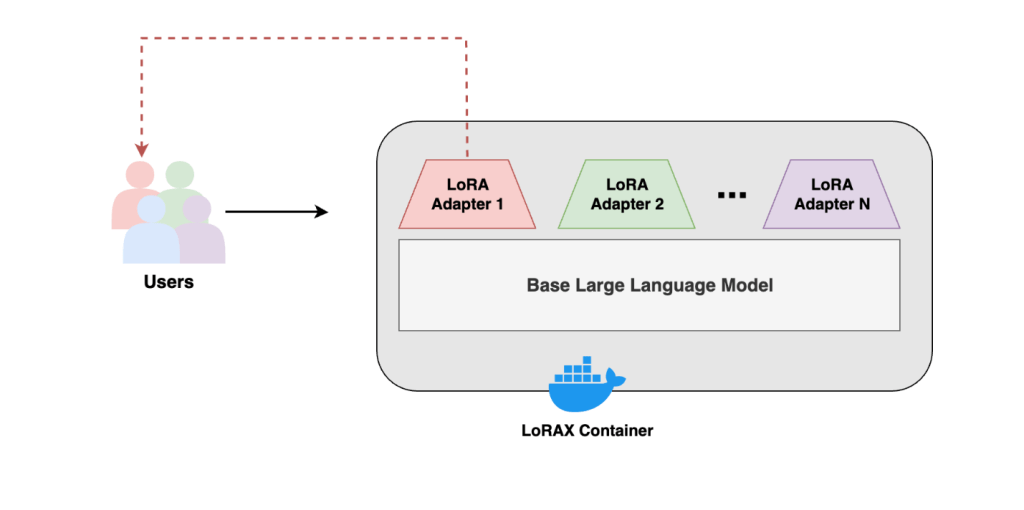
Với LoRAX, bạn có thể tinh chỉnh một FM gốc cho nhiều tác vụ khác nhau, bao gồm tạo truy vấn SQL, điều chỉnh theo lĩnh vực ngành nghề, trích xuất thực thể và phản hồi theo hướng dẫn. Các biến thể khác nhau có thể được lưu trữ trên cùng một phiên bản EC2 thay vì phải sử dụng nhiều điểm cuối mô hình riêng biệt, giúp tiết kiệm chi phí mà không ảnh hưởng đến hiệu suất.
Tại sao chọn LoRAX cho việc triển khai LoRA trên AWS?
Sự gia tăng phổ biến của việc tinh chỉnh LLMs đã dẫn đến sự xuất hiện của nhiều phương pháp container suy luận khác nhau để triển khai các adapter LoRA trên AWS. Hai phương pháp nổi bật nhất được khách hàng của chúng tôi sử dụng là LoRAX và vLLM.
vLLM mang lại tốc độ suy luận nhanh và hiệu suất cao, rất phù hợp cho các ứng dụng yêu cầu khả năng phục vụ lớn với chi phí thấp, đặc biệt lý tưởng khi chạy nhiều mô hình tinh chỉnh có cùng mô hình gốc. Bạn có thể chạy các container suy luận vLLM bằng Amazon SageMaker, như được minh họa trong bài viết Efficient and cost-effective multi-tenant LoRA serving with Amazon SageMaker trên AWS Machine Learning Blog. Tuy nhiên, sự phức tạp của vLLM hiện nay khiến việc triển khai các tích hợp tùy chỉnh cho ứng dụng trở nên khó khăn hơn. vLLM cũng có khả năng hỗ trợ lượng tử hóa còn hạn chế.
Đối với những ai đang tìm kiếm phương pháp xây dựng ứng dụng có sự hỗ trợ mạnh mẽ từ cộng đồng và khả năng tích hợp tùy chỉnh, LoRAX là một lựa chọn thay thế. LoRAX được xây dựng dựa trên container Text Generation Interface (TGI) của Hugging Face, được tối ưu hóa cho hiệu quả bộ nhớ và tài nguyên khi làm việc với các mô hình dựa trên transformer. Ngoài ra, LoRAX hỗ trợ các phương pháp lượng tử hóa như Activation-aware Weight Quantization (AWQ) và Half-Quadratic Quantization (HQQ).
Tổng quan giải pháp
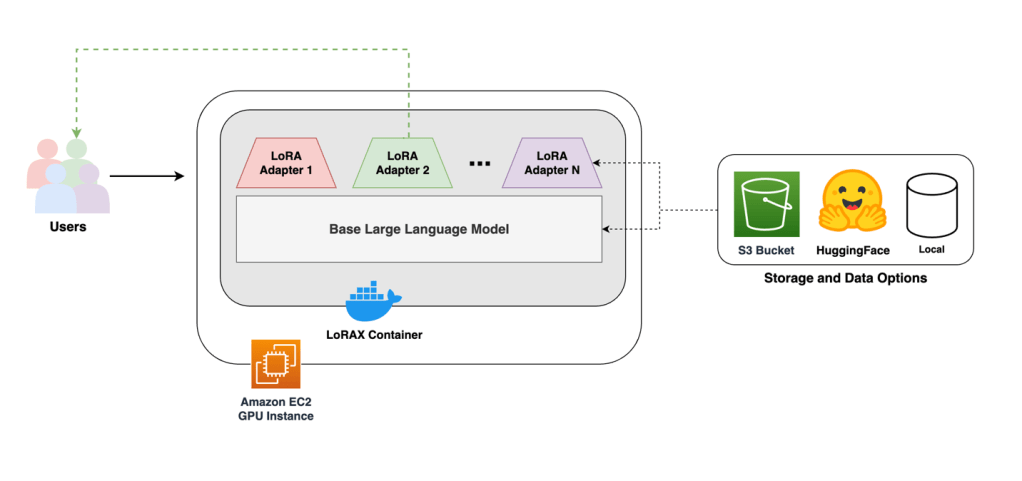
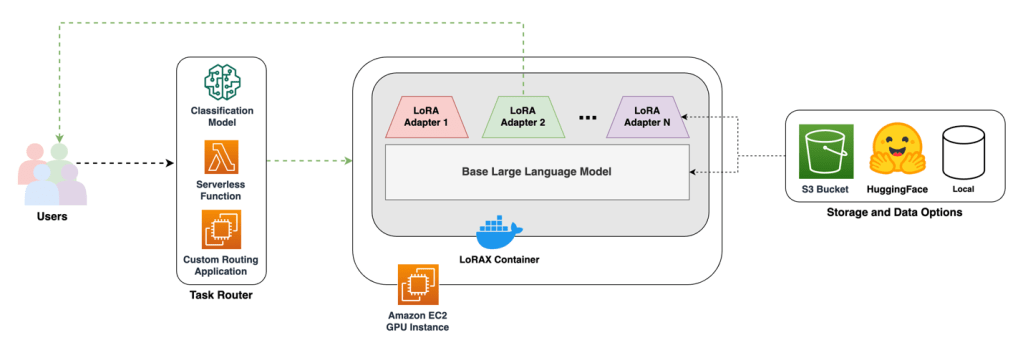
Container suy luận LoRAX có thể được triển khai trên một phiên bản EC2 G6 duy nhất, và các mô hình cùng adapter có thể được tải từ Amazon Simple Storage Service (Amazon S3) hoặc Hugging Face. Sơ đồ sau minh họa kiến trúc của giải pháp này.
Yêu cầu tiên quyết
Để thực hiện hướng dẫn này, bạn cần có quyền truy cập vào các yêu cầu sau:
- Một tài khoản AWS
- Quyền thích hợp để triển khai các phiên bản EC2 G6. LoRAX được xây dựng với mục đích sử dụng công nghệ NVIDIA CUDA, và dòng phiên bản EC2 G6 là loại tiết kiệm chi phí nhất có bộ tăng tốc NVIDIA CUDA mới nhất. Cụ thể, G6.xlarge là lựa chọn tiết kiệm chi phí nhất cho hướng dẫn này tại thời điểm viết bài. Hãy đảm bảo rằng hạn ngạch (quota) đã được tăng trước khi triển khai.
- (Tùy chọn) Một sổ tay Jupyter trong Amazon SageMaker Studio hoặc SageMaker Notebook Instances. Sau khi các hạn ngạch được áp dụng cho tài khoản của bạn, bạn có thể sử dụng hình ảnh mặc định Studio Python 3 (Data Science) với phiên bản ml.t3.medium để chạy các đoạn mã sổ tay tùy chọn. Để xem danh sách đầy đủ các kernel có sẵn, hãy tham khảo danh sách Amazon SageMaker kernels.
Hướng dẫn thực hành
Bài viết này sẽ hướng dẫn bạn tạo một phiên bản EC2, tải xuống và triển khai hình ảnh container, đồng thời lưu trữ một mô hình ngôn ngữ đã được huấn luyện sẵn cùng các adapter tùy chỉnh từ Amazon S3. Hãy làm theo danh sách kiểm tra các yêu cầu tiên quyết để đảm bảo rằng bạn có thể triển khai giải pháp này đúng cách.
Cấu hình chi tiết máy chủ
Trong phần này, chúng tôi sẽ hướng dẫn cách cấu hình và tạo một phiên bản EC2 để lưu trữ LLM. Hướng dẫn này sử dụng lớp phiên bản EC2 G6 và triển khai mô hình Llama2 7B dung lượng 15 GB. Khuyến nghị nên có dung lượng bộ nhớ GPU khoảng gấp 1,5 lần dung lượng của mô hình để chạy suy luận (inference) trơn tru. Thông số bộ nhớ GPU có thể được tìm thấy trong phần Amazon ECS task definitions for GPU workloads.
Bạn có tùy chọn lượng tử hóa mô hình. Lượng tử hóa (quantization) mô hình ngôn ngữ giúp giảm kích thước trọng số mô hình xuống mức bạn chọn. Ví dụ, LLM mà chúng tôi sử dụng là Llama2 7B của Meta, mặc định có kích thước trọng số ở định dạng fp16, tức là số thực dấu chấm động 16-bit. Chúng ta có thể chuyển đổi trọng số mô hình sang int8 hoặc int4 (số nguyên 8-bit hoặc 4-bit) để giảm dung lượng bộ nhớ của mô hình lần lượt 50% và 25%. Trong hướng dẫn này, chúng tôi sử dụng định dạng fp16 mặc định của Llama2 7B từ Meta, vì vậy chúng tôi cần loại phiên bản có ít nhất 22 GB bộ nhớ GPU (VRAM).
Tùy theo thông số của mô hình ngôn ngữ, bạn cần điều chỉnh dung lượng lưu trữ Amazon Elastic Block Store (Amazon EBS) để đủ chỗ lưu mô hình gốc và trọng số adapter.
Để thiết lập máy chủ suy luận của bạn, hãy làm theo các bước sau:
- Trong bảng điều khiển Amazon EC2, chọn Launch instances, như minh họa trong hình bên dưới.
- Đối với tên, nhập LoRAX – Inference Server.
- Để mở AWS CloudShell, ở góc dưới bên trái của AWS Management Console chọn CloudShell, như minh họa trong ảnh chụp màn hình sau.

- Dán lệnh sau vào CloudShell và sao chép đoạn văn bản kết quả, như minh họa trong ảnh tiếp theo. Đây là Amazon Machine Image (AMI) ID mà bạn sẽ sử dụng:
aws ec2 describe-images –filters ‘Name=name,Values=Deep Learning OSS Nvidia Driver AMI GPU PyTorch 2.5*(Ubuntu*’ ‘Name=state,Values=available’ –query ‘sort_by(Images, &CreationDate)[-1].ImageId’ –output text

- Trong thanh tìm kiếm Application and OS Images (Amazon Machine Image), nhập ami-0d2047d61ff42e139 và nhấn Enter trên bàn phím.
- Trong phần Selected AMI, nhập ID AMI mà bạn đã lấy được từ lệnh CloudShell. Trong Community AMIs, tìm kiếm Deep Learning OSS Nvidia Driver AMI GPU PyTorch 2.5.1 (Ubuntu 22.04) AMI.
- Chọn Select, như hiển thị trong ảnh chụp màn hình sau.
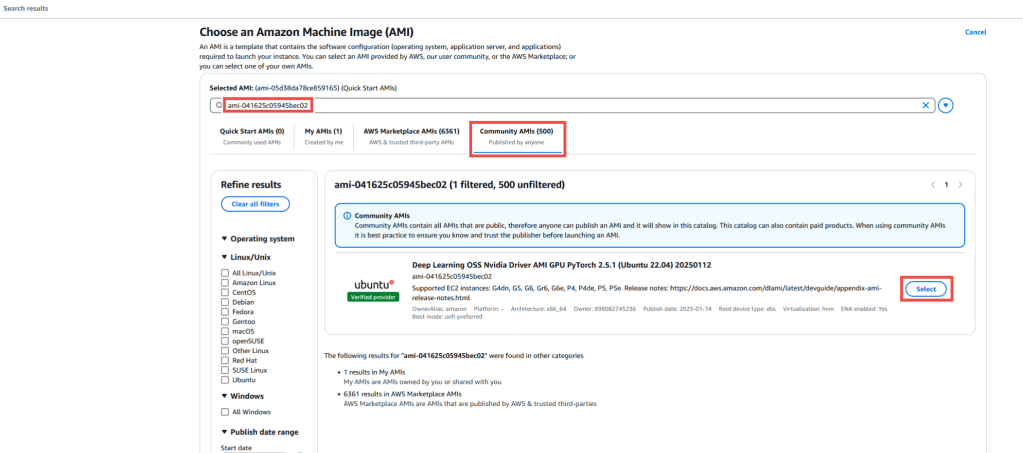
- Chỉ định loại Instance là g6.xlarge. Tùy thuộc vào kích thước của mô hình, bạn có thể tăng kích thước instance để đáp ứng nhu cầu. Để biết thông tin về bộ nhớ GPU theo từng loại instance, hãy truy cập trang Amazon EC2 task definitions for GPU workloads.
- (Tùy chọn) Trong phần Key pair (login), hãy tạo một key pair mới hoặc chọn một key pair có sẵn nếu bạn muốn dùng để kết nối với instance qua SSH.

- Trong Network settings, chọn Edit như trong ảnh chụp màn hình.

- Giữ nguyên các thiết lập mặc định cho VPC, Subnet và Auto-assign public IP
- Trong phần Firewall (security groups), tại Security group name, nhập Inference Server Security Group.
- FTrong Description, nhập Security Group for Inference Server.
- Trong Inbound Security Group Rules, chỉnh sửa Security group rule 1 để giới hạn truy cập SSH chỉ cho địa chỉ IP của bạn bằng cách thay đổi Source type thành My IP.
- Chọn Add security group rule.
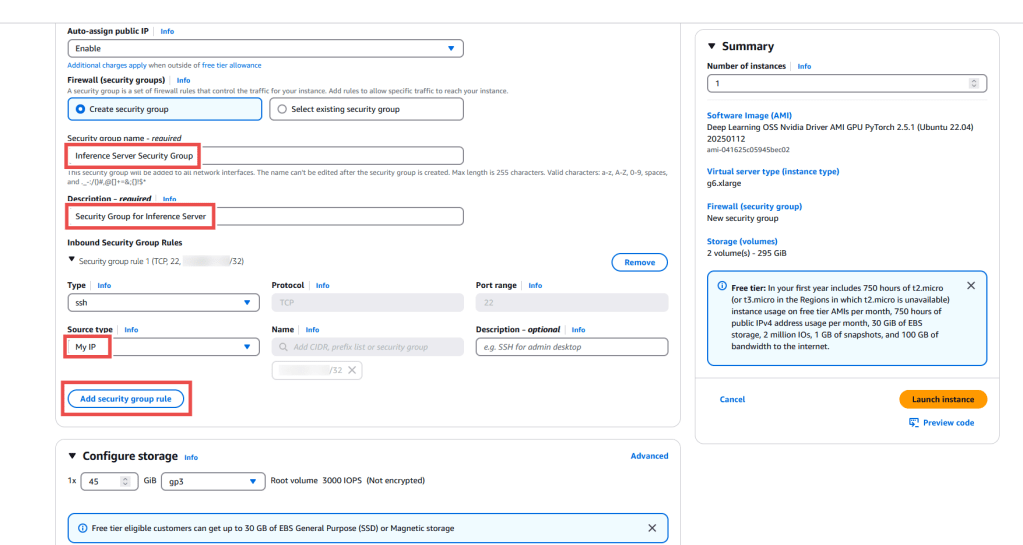
- Cấu hình Security group rule 2 bằng cách thay đổi Type thành All ICMP-IPv4 và Source Type thành My IP. Điều này đảm bảo rằng máy chủ chỉ có thể truy cập được từ địa chỉ IP của bạn, tránh bị truy cập bởi những đối tượng xấu.

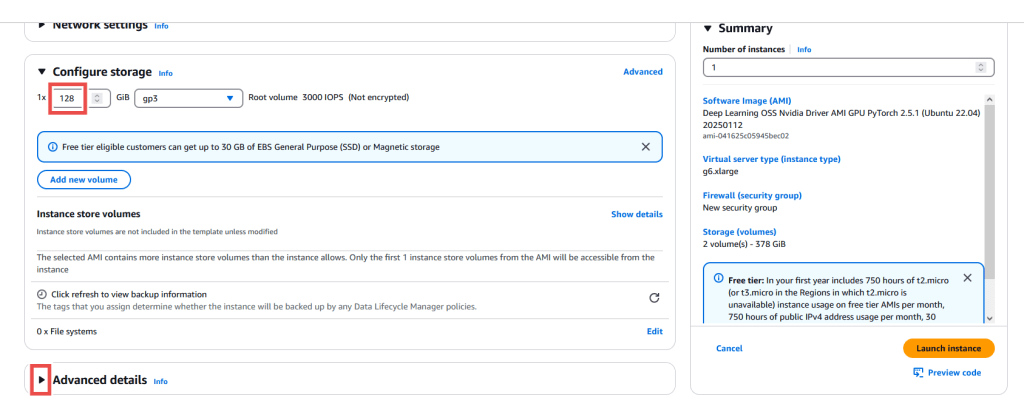
- Trong phần Configure storage, đặt kích thước Root volume size là 128 GiB để đủ dung lượng lưu trữ mô hình cơ sở và trọng số adapter. Đối với các mô hình lớn hơn hoặc nhiều adapter hơn, bạn có thể cần tăng giá trị này. Thẻ mô hình (model card) của hầu hết các mô hình mã nguồn mở đều có thông tin chi tiết về kích thước và cách sử dụng.Chúng tôi gợi ý bắt đầu với 128 GB vì việc tải nhiều adapter cùng với trọng số mô hình có thể chiếm nhiều dung lượng. Khi tính cả không gian cho hệ điều hành, driver, dependencies và tệp dự án, 128 GB là mức an toàn ban đầu trước khi điều chỉnh tăng hoặc giảm.Sau khi thiết lập dung lượng lưu trữ mong muốn, chọn menu thả xuống Advanced details.
- Trong phần IAM instance profile, hãy chọn hoặc tạo một IAM instance profile có quyền đọc S3.

- Chọn Launch instance.

- Khi instance đã khởi chạy xong, chọn SSH hoặc Instance connect để kết nối đến instance và nhập các lệnh sau:
sudo apt update
sudo systemctl start docker
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerCài đặt container và khởi chạy máy chủ
Máy chủ hiện đã được cấu hình đúng để tải và chạy phần mềm phục vụ.
Nhập các lệnh sau để tải xuống và triển khai image Docker của LoRAX. Để biết thêm thông tin, hãy tham khảo phần chạy container với LLM gốc. Chỉ định một mô hình từ Hugging Face hoặc từ thư mục lưu trữ cục bộ và tải mô hình đó để thực hiện suy luận. Thay thế các tham số trong lệnh cho phù hợp với nhu cầu của bạn (ví dụ: <huggingface-access-token>).
Thêm thẻ -d như trong ví dụ sẽ giúp quá trình tải và cài đặt chạy ở chế độ nền. Quá trình này có thể mất đến 30 phút để hoàn tất việc cấu hình. Sử dụng các lệnh Docker docker ps và docker logs <container-name>, để xem tiến trình của container Docker và quan sát khi nào container hoàn tất cài đặt. Lệnh docker logs <container-name> –follow sẽ tiếp tục hiển thị luồng log mới từ container để bạn có thể theo dõi liên tục.
model=meta-llama/Llama-2-7b-hf
volume=$PWD/data
token=<huggingface-access-token>
docker run -d --gpus all --shm-size 1g -p 8080:80 -v $volume:/data -e HUGGING_FACE_HUB_TOKEN=$token ghcr.io/predibase/lorax:main --model-id $modelKiểm tra máy chủ và adapter
Khi chạy container ở chế độ nền bằng thẻ -d , bạn có thể gửi yêu cầu đến máy chủ (server) để kiểm tra phản hồi.Khi bạn chỉ định model-id là một ID mô hình trên Hugging Face, LoRAX sẽ tải mô hình đó trực tiếp vào bộ nhớ từ Hugging Face.
Tuy nhiên, cách này không được khuyến nghị cho môi trường production vì việc phụ thuộc vào Hugging Face có thể dẫn đến lỗi nếu mô hình hoặc adapter không khả dụng.Khuyến nghị nên lưu trữ mô hình cục bộ trên Amazon S3, Amazon EBS, hoặc Amazon Elastic File System (Amazon EFS) để đảm bảo khả năng triển khai ổn định.Phần sau của bài viết sẽ hướng dẫn cách tải mô hình và adapter từ S3 khi cần.
LoRAX cũng có thể tải tệp adapter trực tiếp từ Hugging Face trong thời gian chạy. Bạn có thể sử dụng tính năng này bằng cách thêm adapter_id và adapter_source vào phần nội dung (body) của yêu cầu. Lần đầu tiên một adapter mới được yêu cầu, quá trình tải có thể mất một khoảng thời gian, nhưng các yêu cầu sau đó sẽ nhanh hơn vì adapter đã được lưu trong bộ nhớ.
- Nhập lệnh sau để gửi yêu cầu đến mô hình gốc:
curl 127.0.0.1:8080/generate \
-X POST \
d '{
"inputs": "why is the sky blue",
"parameters": {
"max_new_tokens": 6
}
}' \
H 'Content-Type: application/json'- Enter the following command to prompt the base model with the specified adapter:
curl 127.0.0.1:8080/generate \
-X POST \
-d '{
"inputs": "why is the sky blue",
"parameters": {
"max_new_tokens": 64,
"adapter_id": "vineetsharma/qlora-adapter-Llama-2-7b-hf-databricks-dolly-15k",
"adapter_source": "hub"
}
}' \ -H 'Content-Type: application/json'[Tùy chọn] Tạo adapter tùy chỉnh bằng SageMaker training và PEFT
Các tác vụ tinh chỉnh (fine-tuning) thông thường cho LLM thường hợp nhất trọng số của adapter với mô hình gốc. Tuy nhiên, sử dụng phần mềm như thư viện PEFT của Hugging Face cho phép tinh chỉnh mà vẫn tách biệt các adapter.
Làm theo các bước được trình bày trong bài viết in this AWS Machine Learning blog post để tinh chỉnh mô hình Llama 2 của Meta và lấy adapter LoRA được tách riêng trong Amazon S3.
[Tùy chọn] Sử dụng adapter từ Amazon S3
LoRAX có thể tải tệp adapter từ Amazon S3 trong thời gian chạy. Bạn có thể sử dụng khả năng này bằng cách thêm adapter_id vả adapter_source trong phần nội dung của yêu cầu. Lần đầu tiên một adapter mới được yêu cầu, việc tải có thể mất một khoảng thời gian, nhưng các yêu cầu sau đó sẽ được tải nhanh từ bộ nhớ máy chủ.Đây là phương pháp tối ưu khi chạy LoRAX trong môi trường production so với việc nhập từ Hugging Face vì nó không phụ thuộc vào các thành phần runtime bên ngoài.
curl 127.0.0.1:8080/generate \
-X POST \
-d '{
"inputs": "What is process mining?",
"parameters": {
"max_new_tokens": 64,
"adapter_id": "<your-adapter-s3-bucket-path>",
"adapter_source": "s3"
}
}' \
-H 'Content-Type: application/json'[Tùy chọn] Sử dụng mô hình tùy chỉnh từ Amazon S3
LoRAX cũng có thể tải các mô hình ngôn ngữ tùy chỉnh từ Amazon S3. Nếu kiến trúc mô hình được hỗ trợ trong tài liệu của LoRAX, bạn có thể chỉ định tên bucket để lấy trọng số, như trong ví dụ mã dưới đây. Tham khảo phần tùy chọn trước về việc tách trọng số adapter khỏi trọng số mô hình gốc để tùy chỉnh mô hình ngôn ngữ của riêng bạn.
volume=$PWD/data
bucket_name=<s3-bucket-name>
model=<model-directory-name>
docker run --gpus all --shm-size 1g -e PREDIBASE_MODEL_BUCKET=$bucket_name -p 8080:80 -v $volume:/data ghcr.io/predibase/lorax:latest --model-id $modelTriển khai ổn định bằng Amazon S3 cho việc lưu trữ mô hình và adapter
Lưu trữ mô hình và adapter trong Amazon S3 mang lại giải pháp đáng tin cậy hơn cho việc triển khai nhất quán so với phụ thuộc vào các dịch vụ bên thứ ba như Hugging Face. Bằng cách tự quản lý kho lưu trữ, bạn có thể thiết lập các giao thức mạnh mẽ để đảm bảo mô hình và adapter luôn sẵn sàng khi cần thiết. Ngoài ra, cách tiếp cận này cho phép bạn duy trì kiểm soát phiên bản và tách biệt tài sản của mình khỏi nguồn bên ngoài, điều này rất quan trọng cho việc tuân thủ quy định và quản lý.
Để có thêm sự linh hoạt, bạn có thể sử dụng hệ thống tệp ảo như Amazon EFS hoặc Amazon FSx for Lustre. Bạn có thể sử dụng các dịch vụ này để gắn kết cùng một mô hình và adapter trên nhiều phiên bản, giúp truy cập liền mạch trong môi trường có auto scaling. Điều này có nghĩa là tất cả các phiên bản, dù mở rộng hay thu hẹp, đều có quyền truy cập không gián đoạn vào tài nguyên cần thiết, giúp tăng độ tin cậy và khả năng mở rộng của hệ thống.
So sánh chi phí và tư vấn về khả năng mở rộng
Sử dụng container suy luận LoRAX trên các phiên bản EC2 giúp giảm đáng kể chi phí lưu trữ nhiều phiên bản tinh chỉnh của mô hình ngôn ngữ bằng cách lưu tất cả adapter trong bộ nhớ và hoán đổi linh hoạt trong thời gian chạy. Vì adapter LLM thường chỉ chiếm một phần nhỏ so với mô hình gốc, bạn có thể mở rộng hạ tầng hiệu quả dựa trên mức sử dụng máy chủ thay vì từng biến thể riêng lẻ. Adapter LoRA thường có kích thước bằng khoảng 1/10 đến 1/4 mô hình gốc, tuy nhiên điều này còn phụ thuộc vào cách triển khai và độ phức tạp của tác vụ mà adapter được huấn luyện.
Trong ví dụ trước, các adapter thu được từ quá trình huấn luyện có dung lượng khoảng 5 MB.
Mặc dù dung lượng này phụ thuộc vào kiến trúc mô hình, bạn vẫn có thể hoán đổi hàng nghìn biến thể tinh chỉnh trên cùng một phiên bản mà gần như không ảnh hưởng đến tốc độ suy luận. Khuyến nghị sử dụng các phiên bản có dung lượng bộ nhớ GPU khoảng 150% so với tổng kích thước mô hình và adapter để chứa mô hình, adapter, và vùng lưu trữ KV cache (hoặc attention cache) trong VRAM. Để xem thông số bộ nhớ GPU, hãy tham khảo Amazon ECS task definitions for GPU workloads.
Tùy thuộc vào mô hình gốc và số lượng adapter tinh chỉnh, bạn có thể huấn luyện và triển khai hàng trăm hoặc hàng nghìn mô hình ngôn ngữ tùy chỉnh chia sẻ cùng một mô hình gốc, bằng cách sử dụng LoRAX để hoán đổi adapter linh hoạt. Với cơ chế hoán đổi adapter, nếu bạn có năm biến thể tinh chỉnh, bạn có thể tiết kiệm đến 80% chi phí lưu trữ vì tất cả adapter tùy chỉnh có thể dùng chung trong cùng một phiên bản.
Mẫu triển khai trong Amazon EC2 có thể được sử dụng để triển khai nhiều phiên bản, với các tùy chọn cân bằng tải hoặc tự động mở rộng. Ngoài ra, bạn có thể sử dụng AWS Systems Manager để triển khai các bản vá hoặc thay đổi. Như đã đề cập trước đó, một hệ thống tệp chia sẻ có thể được sử dụng giữa tất cả các tài nguyên EC2 được triển khai để lưu trọng số LLM cho nhiều adapter, giúp truyền dữ liệu đến các phiên bản nhanh hơn so với Amazon S3. Sự khác biệt giữa việc sử dụng hệ thống tệp chia sẻ như Amazon EFS so với truy cập trực tiếp S3 là số bước cần thiết để tải trọng số và adapter vào bộ nhớ. Với S3, adapter và trọng số phải được chuyển vào hệ thống tệp cục bộ trước khi tải. Trong khi đó, hệ thống tệp chia sẻ không cần chuyển tệp cục bộ và có thể tải trực tiếp. Tuy nhiên, vẫn có những điểm đánh đổi cần xem xét khi triển khai. Bạn cũng có thể sử dụng Amazon API Gateway làm điểm cuối API cho các ứng dụng REST.
Lưu trữ máy chủ LoRAX cho nhiều mô hình trong môi trường production
Nếu bạn dự định sử dụng nhiều mô hình FM tùy chỉnh cho các tác vụ cụ thể với LoRAX, hãy làm theo hướng dẫn này để lưu trữ nhiều biến thể mô hình. Tham khảo bài viết AWS blog on hosting text classification with BERT để thực hiện định tuyến tác vụ giữa các mô hình chuyên biệt. Để xem ví dụ triển khai về lưu trữ mô hình hiệu quả bằng cơ chế hoán đổi adapter, hãy tham khảo LoRA Land, được phát hành bởi Predibase, tổ chức đứng sau LoRAX. LoRA Land là tập hợp gồm 25 biến thể tinh chỉnh của mô hình Mistral-7b từ Mistral.ai, hoạt động hiệu quả hơn so với nhiều mô hình LLM hàng đầu khác khi được lưu trữ sau một endpoint duy nhất. Sơ đồ sau đây minh họa kiến trúc của hệ thống.
Dọn dẹp
Trong hướng dẫn này, chúng ta đã tạo các nhóm bảo mật (security groups), một S3 bucket, một phiên bản sổ tay SageMaker (tùy chọn), và một máy chủ suy luận EC2. Việc quan trọng là phải chấm dứt các tài nguyên được tạo trong quá trình thực hiện để tránh phát sinh thêm chi phí:
- Xóa S3 bucket
- Chấm dứt máy chủ suy luận EC2
- Chấm dứt phiên bản sổ tay SageMaker
Kết luận
Sau khi làm theo hướng dẫn này, bạn có thể thiết lập một phiên bản EC2 với LoRAX để lưu trữ và phục vụ các mô hình ngôn ngữ, lưu trữ và truy cập trọng số mô hình tùy chỉnh cùng các bộ điều hợp trong Amazon S3, và quản lý các mô hình được huấn luyện sẵn cũng như mô hình tùy chỉnh và các biến thể của chúng bằng SageMaker. LoRAX cung cấp một phương pháp tiết kiệm chi phí cho những ai muốn lưu trữ nhiều mô hình ngôn ngữ ở quy mô lớn. Để biết thêm thông tin về cách làm việc với trí tuệ nhân tạo sinh trên AWS, hãy tham khảo bài viết Announcing New Tools for Building with Generative AI on AWS.
Tác giả

John Kitaoka là Kiến trúc sư Giải pháp (Solutions Architect) tại Amazon Web Services, làm việc với các cơ quan chính phủ, trường đại học, tổ chức phi lợi nhuận và các tổ chức khu vực công khác để thiết kế và mở rộng quy mô các giải pháp trí tuệ nhân tạo. Với nền tảng về toán học và khoa học máy tính, công việc của John bao gồm nhiều trường hợp sử dụng ML, với mối quan tâm chính là inference (suy luận), trách nhiệm AI và bảo mật. Trong thời gian rảnh, anh thích làm mộc và trượt tuyết.

Varun Jasti là Kiến trúc sư Giải pháp tại Amazon Web Services, làm việc với các AWS Partner để thiết kế và mở rộng quy mô các giải pháp trí tuệ nhân tạo cho các trường hợp sử dụng trong khu vực công nhằm đáp ứng các tiêu chuẩn tuân thủ. Với nền tảng về Khoa học Máy tính, công việc của anh bao gồm nhiều trường hợp sử dụng ML, chủ yếu tập trung vào việc huấn luyện/inference cho LLM và thị giác máy tính. Trong thời gian rảnh, anh thích chơi quần vợt và bơi lội.

Baladithya Balamurugan là Kiến trúc sư Giải pháp tại AWS, tập trung vào việc triển khai ML cho inference và sử dụng AWS Neuron để tăng tốc quá trình huấn luyện và inference. Anh làm việc với khách hàng để kích hoạt và tăng tốc việc triển khai ML của họ trên các dịch vụ như AWS Sagemaker và AWS EC2. Hiện đang sinh sống tại San Francisco, Baladithya thích mày mò kỹ thuật, phát triển ứng dụng và chăm chút cho homelab của mình trong thời gian rảnh.
