Tác giả: Flora Wang, Anila Joshi, Baishali Chaudhury, Sungmin Hong, Jae Oh Woo và Rahul Ghosh
Ngày đăng: 10/04/2025
Danh mục: Advanced (300), Amazon Bedrock, Amazon Machine Learning, Amazon Nova, Amazon SageMaker, Generative AI, Technical How-to
Khi doanh nghiệp và nhà phát triển ngày càng mong muốn tối ưu hóa các mô hình ngôn ngữ cho những tác vụ cụ thể, việc lựa chọn giữa tùy biến mô hình (model customization) và Retrieval Augmented Generation (RAG) trở nên mang tính quyết định. Trong bài viết này, chúng tôi giải quyết nhu cầu ngày càng tăng đó bằng cách cung cấp các hướng dẫn rõ ràng, có thể áp dụng ngay, cùng những best practice về thời điểm nên sử dụng từng phương pháp, giúp bạn đưa ra quyết định phù hợp với yêu cầu và mục tiêu riêng của mình.
Sự ra đời của các mô hình Amazon Nova đánh dấu một bước tiến quan trọng trong lĩnh vực AI, mở ra nhiều cơ hội mới để tối ưu hóa các large language model (LLM). Trong bài viết này, chúng tôi trình bày cách triển khai hiệu quả cả tùy biến mô hình và RAG với Amazon Nova làm baseline. Chúng tôi đã thực hiện một nghiên cứu so sánh toàn diện giữa tùy biến mô hình và RAG sử dụng các mô hình Amazon Nova mới nhất, đồng thời chia sẻ những insight giá trị thu được.
Tổng quan phương pháp và mô hình nền
Trong phần này, chúng tôi thảo luận sự khác biệt giữa phương pháp fine-tuning và RAG, trình bày các use case phổ biến cho từng phương pháp, và cung cấp tổng quan về mô hình nền được sử dụng trong các thí nghiệm.
Giải mã RAG và tùy biến mô hình
RAG là một kỹ thuật nhằm nâng cao năng lực của các mô hình đã được huấn luyện sẵn bằng cách cho phép mô hình truy cập vào các nguồn dữ liệu bên ngoài, mang tính domain-specific. Phương pháp này kết hợp hai thành phần: truy xuất tri thức bên ngoài và sinh câu trả lời. RAG cho phép các mô hình ngôn ngữ được huấn luyện sẵn động thời tích hợp dữ liệu bên ngoài trong quá trình tạo phản hồi, từ đó tạo ra các kết quả chính xác hơn về mặt ngữ cảnh và cập nhật hơn.
Khác với fine-tuning, trong RAG, mô hình không trải qua quá trình huấn luyện lại và trọng số mô hình không được cập nhật để “học” tri thức domain. Mặc dù fine-tuning ngầm sử dụng thông tin domain-specific bằng cách nhúng trực tiếp kiến thức vào mô hình, RAG sử dụng thông tin domain-specific một cách tường minh thông qua cơ chế truy xuất bên ngoài.
Tùy biến mô hình (model customization) đề cập đến việc điều chỉnh một mô hình ngôn ngữ đã huấn luyện sẵn để phù hợp hơn với các tác vụ, domain hoặc tập dữ liệu cụ thể. Fine-tuning là một trong những kỹ thuật như vậy, giúp đưa kiến thức theo tác vụ hoặc domain cụ thể vào mô hình nhằm cải thiện hiệu năng. Phương pháp này điều chỉnh các tham số của mô hình để phù hợp hơn với đặc thù của tác vụ mục tiêu, đồng thời vẫn tận dụng kiến thức tổng quát vốn có của mô hình.
Các use case phổ biến cho từng phương pháp
RAG phù hợp tối ưu cho các use case yêu cầu dữ liệu động hoặc thường xuyên cập nhật (chẳng hạn như FAQ hỗ trợ khách hàng và catalog ecommerce), insight chuyên biệt theo domain (như hỏi đáp pháp lý hoặc y tế), các giải pháp có khả năng mở rộng cho ứng dụng diện rộng (như nền tảng software as a service (SaaS)), truy xuất dữ liệu đa phương thức (như tóm tắt tài liệu), và các hệ thống yêu cầu tuân thủ nghiêm ngặt về bảo mật hoặc dữ liệu nhạy cảm (như hệ thống tài chính và tuân thủ pháp lý).
Ngược lại, fine-tuning phát huy hiệu quả trong các kịch bản đòi hỏi mức độ tùy biến cao (như chatbot cá nhân hóa hoặc sáng tác nội dung), độ chính xác cao cho các tác vụ hẹp (như sinh code hoặc tóm tắt chuyên biệt), độ trễ cực thấp (như tương tác khách hàng theo thời gian thực), dữ liệu tĩnh ổn định (như glossary theo domain), và khả năng mở rộng chi phí hiệu quả cho các tác vụ khối lượng lớn (như tự động hóa call center).
Mặc dù RAG vượt trội trong việc grounding theo dữ liệu bên ngoài theo thời gian thực, còn fine-tuning mạnh ở các workflow tĩnh, có cấu trúc và cá nhân hóa, việc lựa chọn giữa hai phương pháp thường phụ thuộc vào nhiều yếu tố tinh tế. Bài viết này cung cấp một so sánh toàn diện giữa RAG và fine-tuning, làm rõ điểm mạnh, hạn chế và bối cảnh mà mỗi phương pháp mang lại hiệu quả tốt nhất.
Giới thiệu về các mô hình Amazon Nova
Amazon Nova là thế hệ foundation model (FM) mới, mang lại trí tuệ tiên tiến và tỷ lệ price-performance hàng đầu ngành. Amazon Nova Pro và Amazon Nova Lite là các mô hình đa phương thức, nổi bật về độ chính xác và tốc độ, trong đó Amazon Nova Lite được tối ưu cho chi phí thấp và xử lý nhanh. Amazon Nova Micro tập trung vào các tác vụ văn bản với độ trễ cực thấp.
Các mô hình này cung cấp khả năng inference nhanh, hỗ trợ agentic workflow với Amazon Bedrock Knowledge Bases và RAG, đồng thời cho phép fine-tuning cho cả dữ liệu văn bản và đa phương thức. Chúng được tối ưu cho hiệu năng chi phí và được huấn luyện trên dữ liệu hơn 200 ngôn ngữ.
Tổng quan giải pháp
Để đánh giá hiệu quả của RAG so với tùy biến mô hình, chúng tôi đã thiết kế một framework kiểm thử toàn diện sử dụng tập câu hỏi chuyên biệt về AWS. Nghiên cứu sử dụng Amazon Nova Micro và Amazon Nova Lite làm foundation model nền và kiểm tra hiệu năng trên nhiều cấu hình khác nhau.
Chúng tôi cấu trúc quá trình đánh giá như sau:
- Mô hình nền:
- Sử dụng Amazon Nova Micro và Amazon Nova Lite dạng out-of-box
- Sinh câu trả lời cho các câu hỏi AWS mà không cung cấp thêm ngữ cảnh
- Mô hình nền kết hợp RAG:
- Kết nối mô hình nền với Amazon Bedrock Knowledge Bases
- Cung cấp quyền truy cập vào tài liệu và blog AWS liên quan
- Tùy biến mô hình:
- Fine-tune cả hai mô hình Amazon Nova với 1.000 cặp câu hỏi–trả lời chuyên biệt về AWS, được tạo từ cùng một tập bài viết AWS
- Triển khai các mô hình đã tùy biến thông qua provisioned throughput
- Sinh câu trả lời cho các câu hỏi AWS bằng mô hình đã fine-tune
- Kết hợp tùy biến mô hình và RAG:
- Kết nối các mô hình đã fine-tune với Amazon Bedrock Knowledge Bases
- Cung cấp quyền truy cập vào các bài viết AWS liên quan tại thời điểm inference
Trong các phần tiếp theo, chúng tôi sẽ hướng dẫn cách thiết lập hai phương pháp thứ hai và thứ ba (mô hình nền với RAG và tùy biến mô hình với fine-tuning) trong Amazon Bedrock.
Điều kiện tiên quyết
Để thực hiện theo bài viết này, bạn cần đáp ứng các điều kiện sau:
- Một tài khoản AWS và các quyền phù hợp
- Một bucket Amazon Simple Storage Service (Amazon S3) với hai thư mục: một thư mục chứa dữ liệu huấn luyện, và một thư mục dùng cho output mô hình và metric huấn luyện
Triển khai RAG với mô hình Amazon Nova nền
Trong phần này, chúng tôi hướng dẫn các bước triển khai RAG với mô hình nền bằng cách tạo một knowledge base. Thực hiện các bước sau:
- Trên Amazon Bedrock console, chọn Knowledge Bases trong navigation pane.
- Trong mục Knowledge Bases, chọn Create.
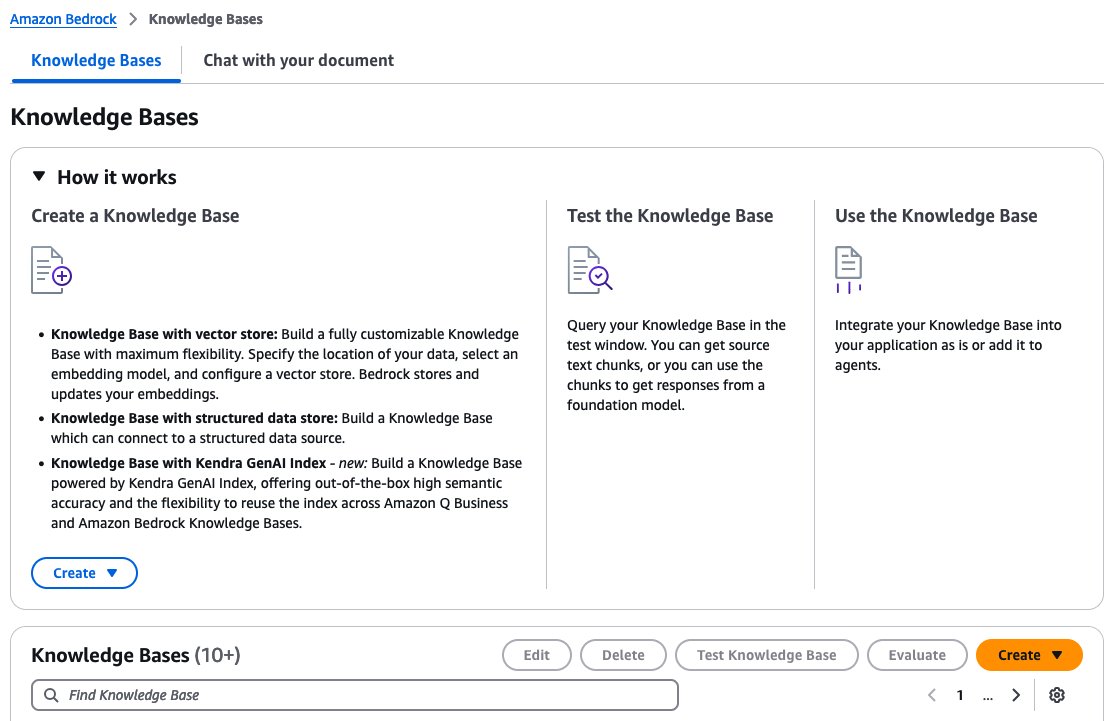
- Trên trang Configure data source, cung cấp các thông tin sau:
- Chỉ định vị trí Amazon S3 của các tài liệu.
- Chỉ định chiến lược chunking.
- Chọn Next.
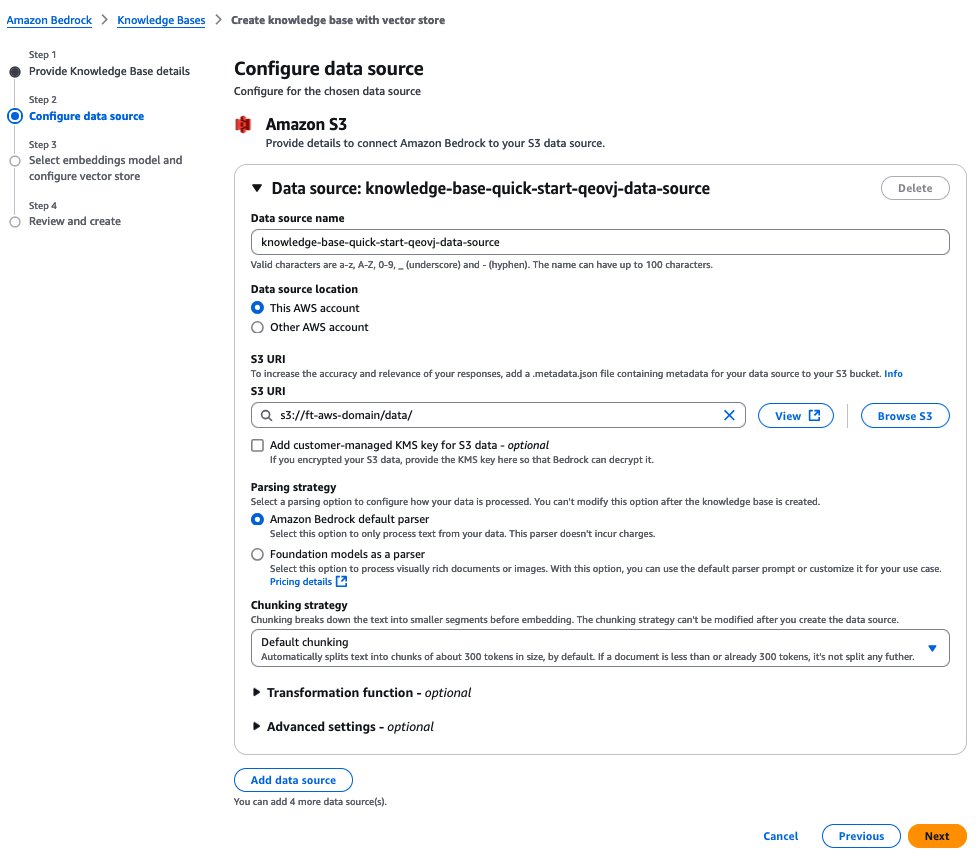
- Trên trang Select embeddings model and configure vector store, cung cấp các thông tin sau:
- Trong mục Embeddings model, chọn mô hình embeddings dùng để nhúng các chunk.
- Trong mục Vector database, tạo mới hoặc sử dụng vector store hiện có để lưu embeddings phục vụ truy xuất.
- Chọn Next.
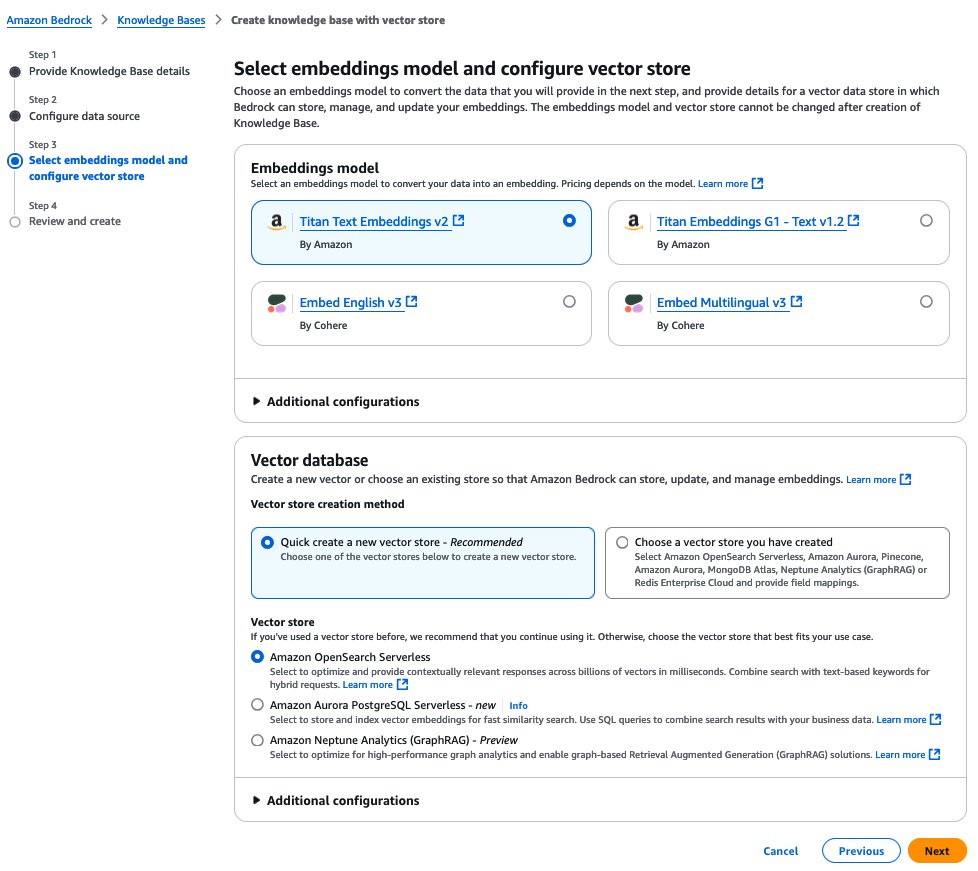
- Trên trang Review and create, rà soát cấu hình và chọn Create Knowledge Base.
Fine-tune mô hình Amazon Nova bằng Amazon Bedrock API
Trong phần này, chúng tôi cung cấp hướng dẫn chi tiết về cách fine-tuning và host các mô hình Amazon Nova đã tùy biến bằng Amazon Bedrock. Sơ đồ sau minh họa kiến trúc giải pháp.

Tạo fine-tuning job
Fine-tuning các mô hình Amazon Nova thông qua Amazon Bedrock API là một quy trình đơn giản:
- Trên Amazon Bedrock console, chọn us-east-1 làm AWS Region.
Tại thời điểm viết bài, fine-tuning cho mô hình Amazon Nova chỉ khả dụng tại us-east-1.
- Trong navigation pane, dưới Foundation models, chọn Custom models.
- Trong mục Customization methods, chọn Create Fine-tuning job.
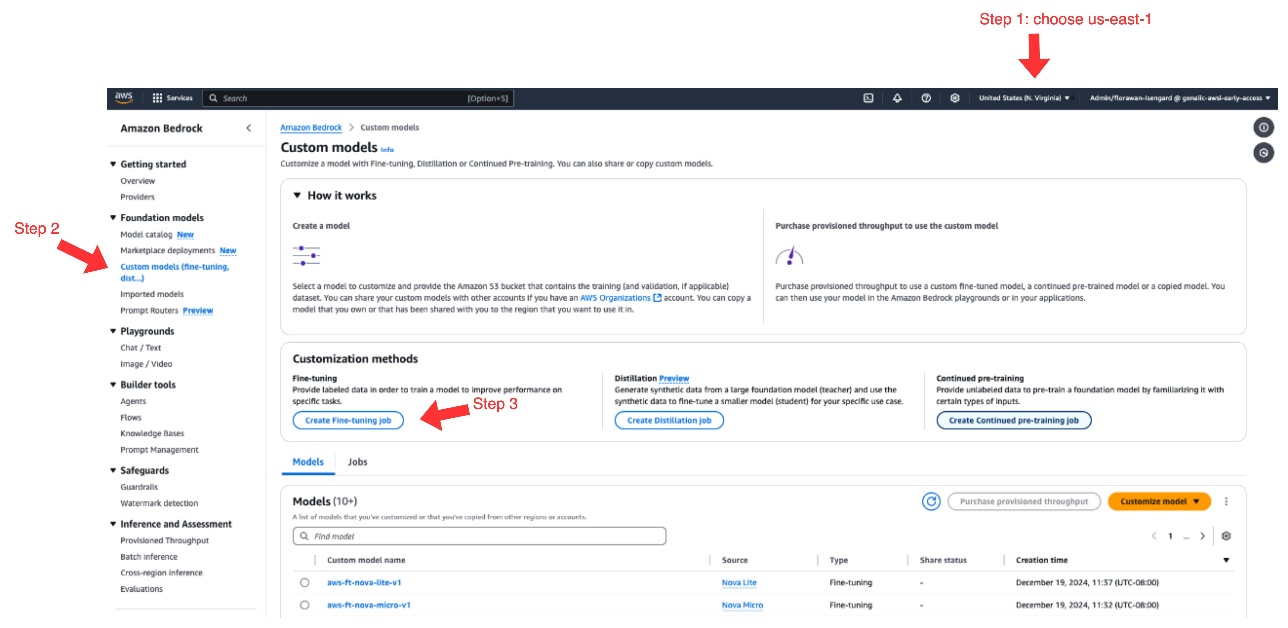
- Với Source model, chọn Select model.
- Chọn Amazon làm provider và mô hình Amazon Nova bạn mong muốn.
- Chọn Apply.
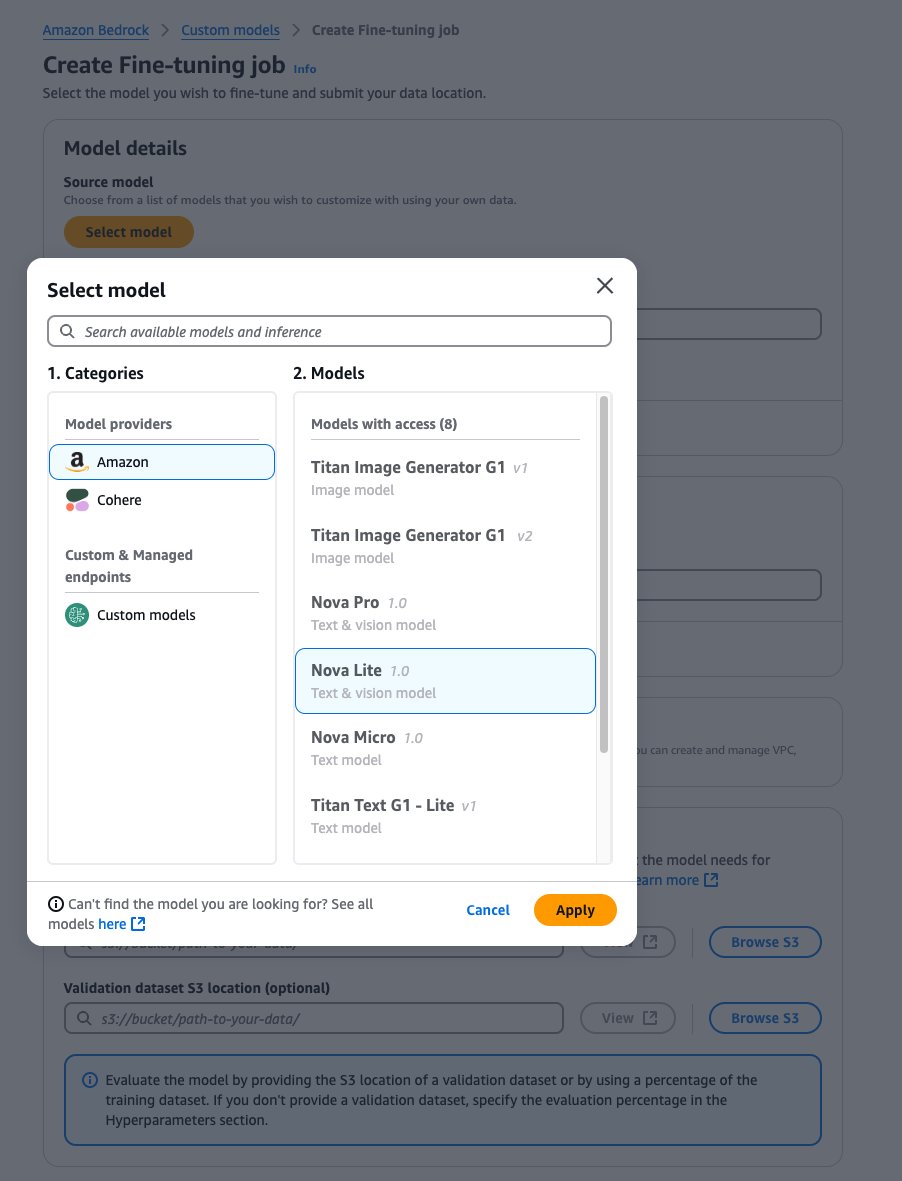
- Với Fine-tuned model name, nhập tên duy nhất cho mô hình đã fine-tune.
- Với Job name, nhập tên cho fine-tuning job.
- Trong mục Input data, nhập vị trí S3 bucket nguồn (dữ liệu huấn luyện) và bucket đích (output mô hình và metric huấn luyện), và tùy chọn thêm vị trí tập validation.
Cấu hình hyperparameters
Với các mô hình Amazon Nova, các hyperparameters sau có thể được tùy chỉnh:
| Tham số | Giới hạn / Ràng buộc |
|---|---|
| Epochs | 1–5 |
| Batch Size | Cố định là 1 |
| Learning Rate | 0.000001–0.0001 |
| Learning Rate Warmup Steps | 0–100 |
Chuẩn bị dataset tương thích với Amazon Nova
Tương tự các LLM khác, Amazon Nova yêu cầu các cặp prompt–completion, còn gọi là cặp câu hỏi–trả lời (Q&A), cho supervised fine-tuning (SFT). Dataset này cần chứa các output lý tưởng mà bạn muốn mô hình tạo ra cho từng tác vụ hoặc prompt cụ thể. Tham khảo Guidelines for preparing your data for Amazon Nova để biết best practice và ví dụ định dạng khi chuẩn bị dataset.
Kiểm tra trạng thái fine-tuning job và artifact huấn luyện
Sau khi tạo fine-tuning job, trong navigation pane dưới Foundation models, chọn Custom models. Bạn sẽ thấy fine-tuning job hiện tại trong mục Jobs, nơi bạn có thể theo dõi trạng thái job.
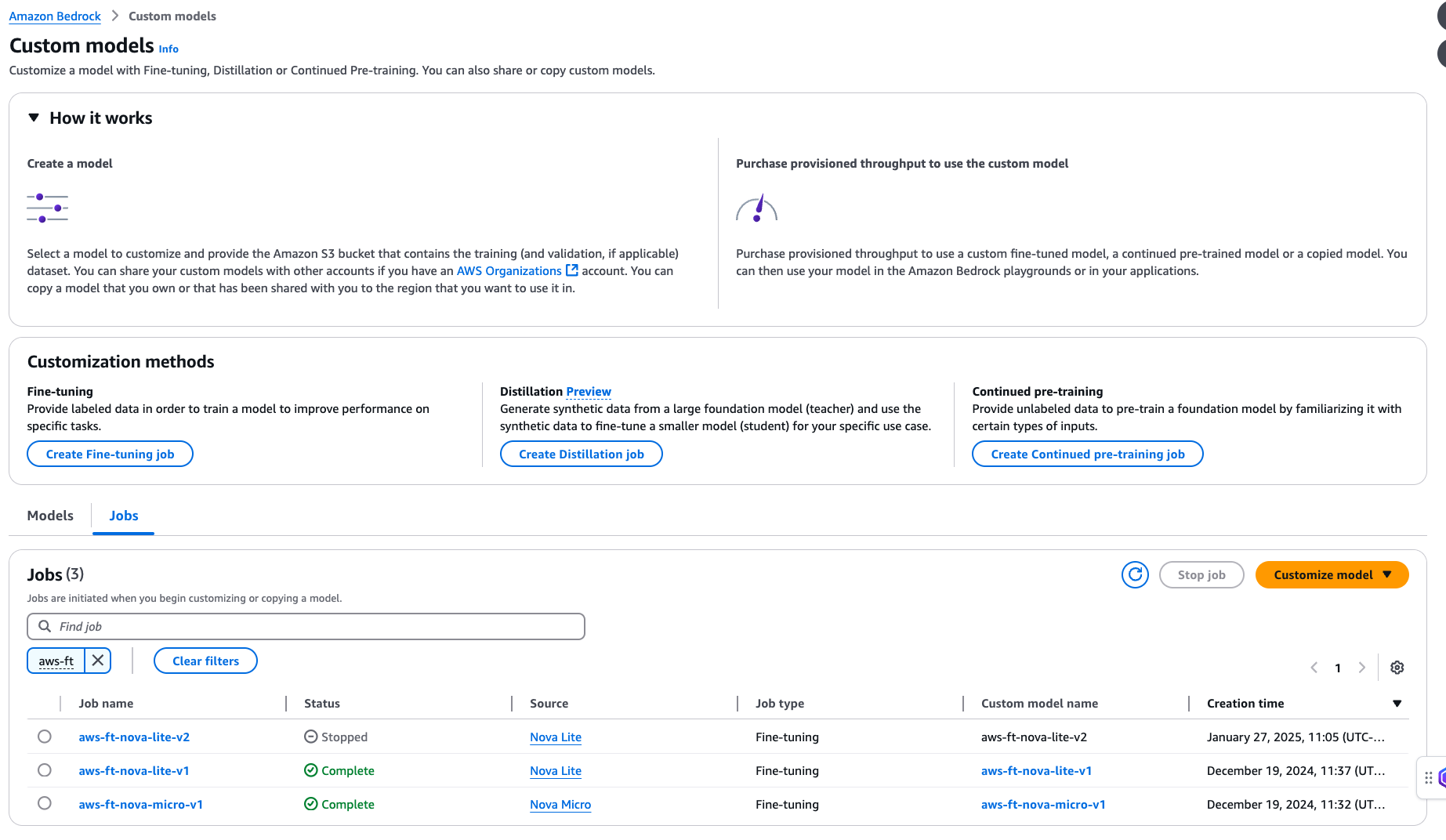
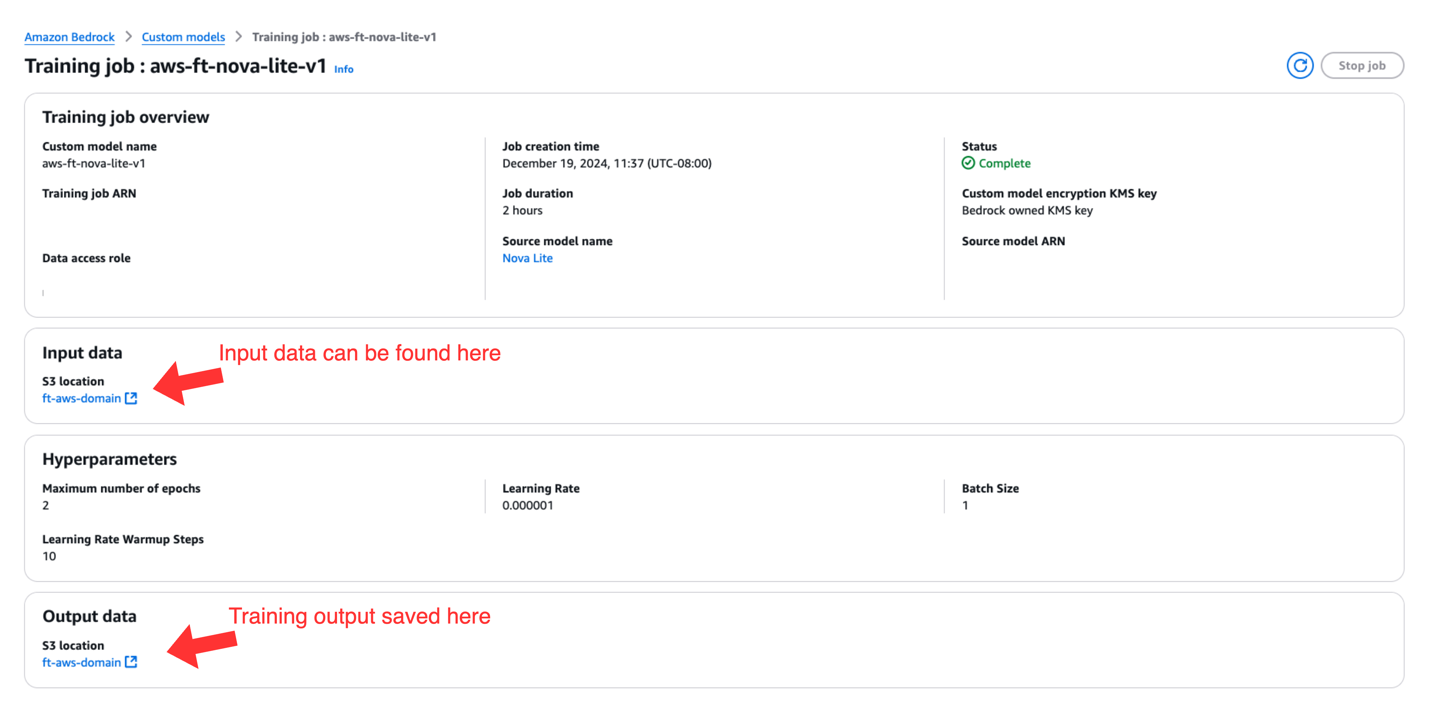
Khi trạng thái job chuyển sang Complete, bạn có thể chọn tên job và truy cập trang Training job overview, nơi hiển thị các thông tin sau:
- Thông số kỹ thuật của training job
- Vị trí Amazon S3 của dữ liệu input dùng cho fine-tuning
- Các hyperparameters đã sử dụng trong quá trình fine-tuning
- Vị trí Amazon S3 của output huấn luyện
Host mô hình đã fine-tune bằng provisioned throughput
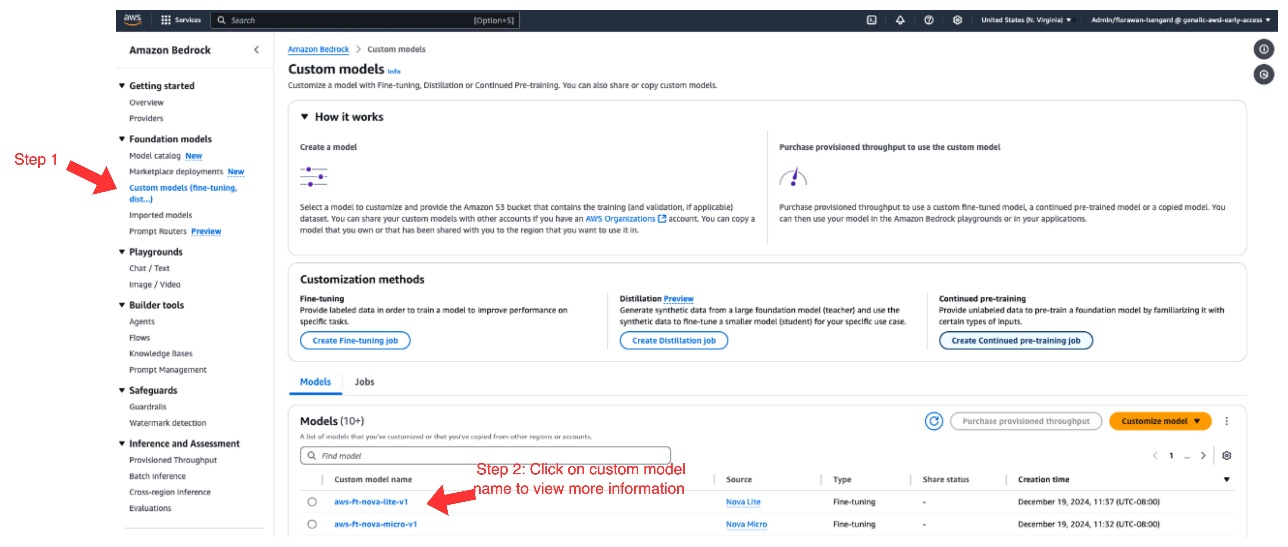
Sau khi fine-tuning job hoàn tất thành công, bạn có thể truy cập mô hình đã tùy biến theo các bước sau:
- Trên Amazon Bedrock console, trong navigation pane dưới Foundation models, chọn Custom models.
- Trong mục Models, chọn mô hình custom của bạn.
Trang chi tiết mô hình hiển thị các thông tin sau:
- Thông tin mô hình đã fine-tune
- Vị trí Amazon S3 của dữ liệu input dùng cho fine-tuning
- Các hyperparameters đã sử dụng
- Vị trí Amazon S3 của output huấn luyện
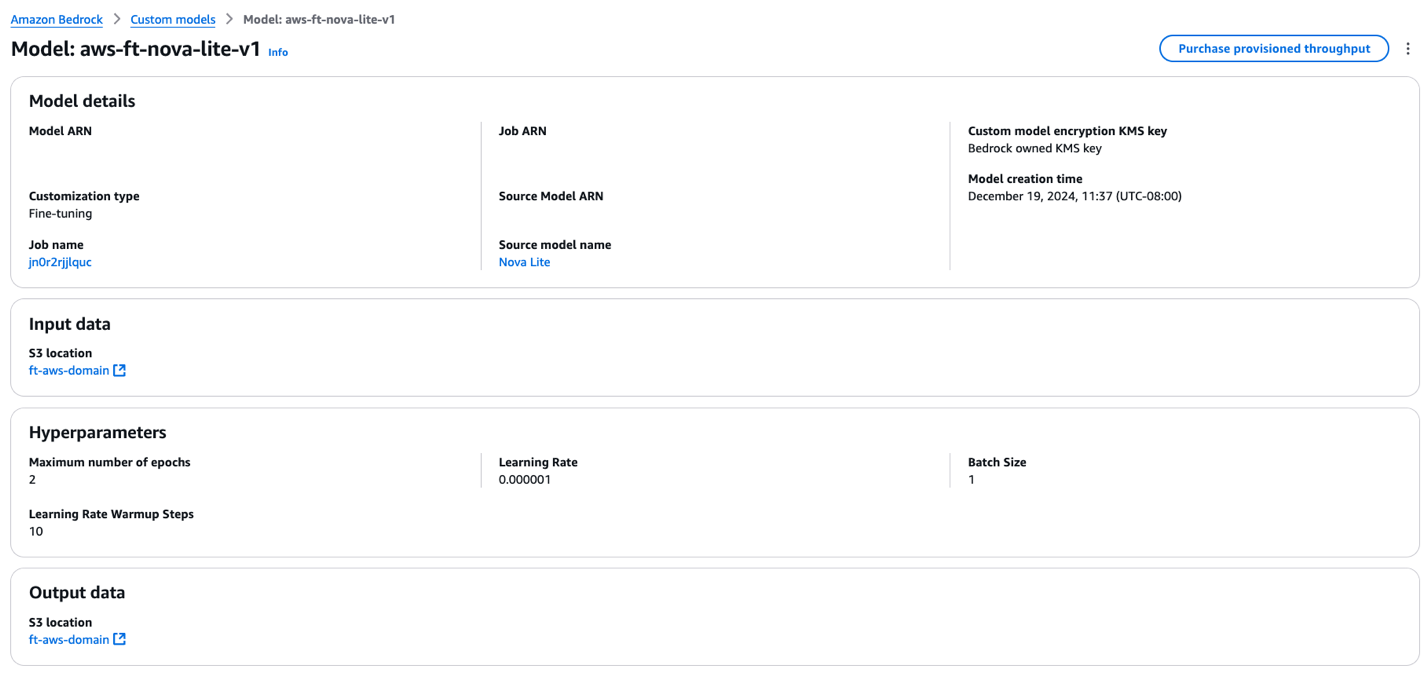
- Để đưa mô hình đã fine-tune vào inference, chọn Purchase provisioned throughput.
- Chọn thời hạn cam kết (không cam kết, 1 tháng hoặc 6 tháng) và xem chi phí liên quan đến việc host mô hình.
Sau khi mô hình được host thông qua provisioned throughput, một model ID sẽ được gán và có thể dùng cho inference.
Các bước fine-tuning và inference nêu trên cũng có thể được thực hiện bằng code. Tham khảo GitHub repo chứa code mẫu để biết thêm chi tiết.
Framework đánh giá và kết quả
Trong phần này, trước tiên chúng tôi giới thiệu framework đánh giá multi-LLM-judge, được thiết kế nhằm giảm thiểu bias của từng LLM judge riêng lẻ. Sau đó, chúng tôi so sánh kết quả RAG và fine-tuning về chất lượng phản hồi, cũng như độ trễ và tác động đến token.
Sử dụng nhiều LLM làm giám khảo để giảm bias
Sơ đồ sau minh họa workflow sử dụng nhiều LLM làm giám khảo.
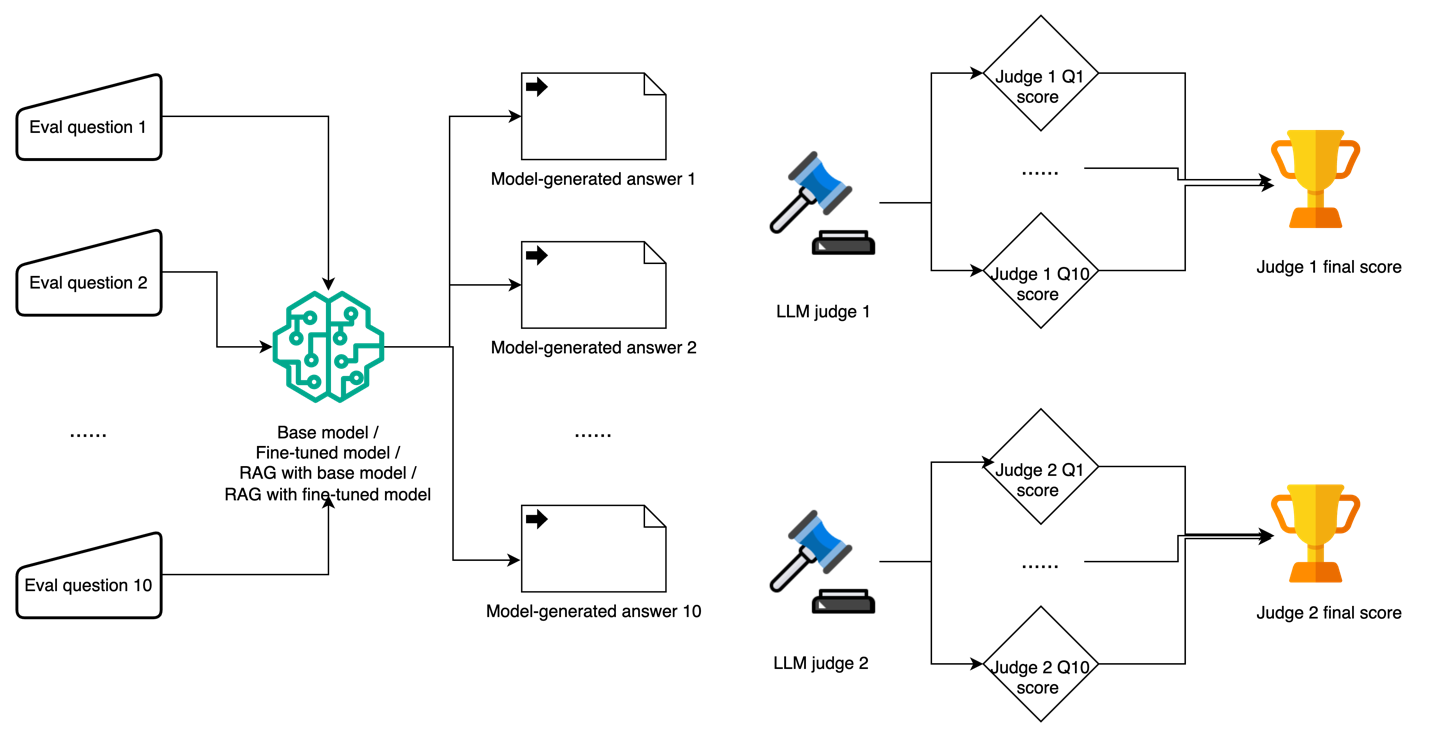
Việc sử dụng LLM làm giám khảo ngày càng trở nên phổ biến trong việc đánh giá các tác vụ khó đo lường bằng phương pháp truyền thống hoặc đánh giá thủ công. Với framework này, chúng tôi xây dựng 10 câu hỏi domain-specific về AWS nhằm kiểm tra cả độ chính xác về mặt sự kiện và độ sâu hiểu biết. Mỗi phản hồi do mô hình sinh ra được chấm điểm theo thang 0–10, trong đó 0–3 là sai hoặc gây hiểu nhầm, 4–6 là đúng một phần nhưng chưa đầy đủ, 7–8 là hầu hết đúng với một vài sai sót nhỏ, và 9–10 là hoàn toàn chính xác với giải thích toàn diện.
Chúng tôi sử dụng prompt đánh giá của LLM judge như sau:
{
"system_prompt": "You are a helpful assistant.",
"prompt_template": "[Instruction] Please act as an impartial judge and evaluate the quality of the response provided by an AI assistant to the user question displayed below. Your evaluation should consider factors such as the helpfulness, relevance, accuracy, depth, creativity, and level of detail of the response. Begin your evaluation by providing a short explanation. Be as objective as possible. After providing your explanation, you must rate the response on a scale of 1 to 10 by strictly following this format: \"[[rating]]\", for example: \"Rating: [[5]]\".\n\n[Question]\n{question}\n\n[The Start of Assistant's Answer]\n{answer}\n[The End of Assistant's Answer]",
"description": "Prompt for general questions",
"category": "general",
"output_format": "[[rating]]"
}Chúng tôi sử dụng câu hỏi đánh giá mẫu và ground truth như sau:
{
"question_id": 9161,
"category": "AWS",
"turns": [
" \"What specific details are collected and sent to AWS when anonymous operational metrics are enabled for an Amazon EFS file system?",
"What's required for a successful AWS CloudFormation launch?"
],
"reference": [
"When anonymous operational metrics are enabled for an Amazon EFS file system, the following specific details are collected and sent to AWS: Solution ID, Unique ID, Timestamp, Backup ID, Backup Start Time, Backup Stop Time, Backup Window, Source EFS Size, Destination EFS Size, Instance Type, Retain, S3 Bucket Size, Source Burst Credit Balance, Source Burst Credit Balance Post Backup, Source Performance Mode, Destination Performance Mode, Number of Files, Number of Files Transferred, Total File Size, Total Transferred File Size, Region, Create Hard Links Start Time, Create Hard Links Stop Time, Remove Snapshot Start Time, Remove Snapshot Stop Time, Rsync Delete Start Time, Rsync Delete Stop Time.",
"For a successful AWS CloudFormation launch, you need to sign in to the AWS Management Console, choose the correct AWS Region, use the button to launch the template, verify the correct template URL, assign a name to your solution stack, review and modify the parameters as necessary, review and confirm the settings, check the boxes acknowledging that the template creates AWS Identity and Access Management resources and may require an AWS CloudFormation capability, and choose Create stack to deploy the stack. You should receive a CREATE_COMPLETE status in approximately 15 minutes."
]
}So sánh chất lượng phản hồi
Cả fine-tuning và RAG đều cải thiện đáng kể chất lượng phản hồi được sinh ra cho các câu hỏi chuyên biệt về AWS so với mô hình nền. Khi sử dụng Amazon Nova Lite làm mô hình nền, chúng tôi quan sát thấy cả fine-tuning và RAG đều giúp tăng điểm đánh giá trung bình của LLM judge về chất lượng phản hồi lên khoảng 30%. Đáng chú ý, việc kết hợp fine-tuning với RAG giúp cải thiện tổng thể chất lượng phản hồi lên tới 83%, như minh họa trong hình sau.
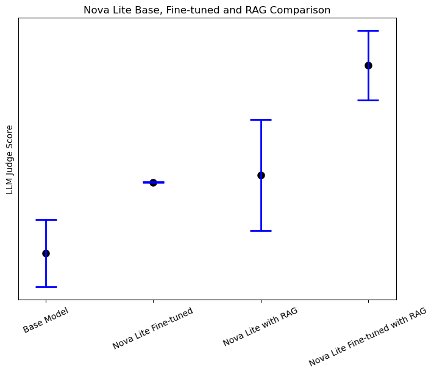
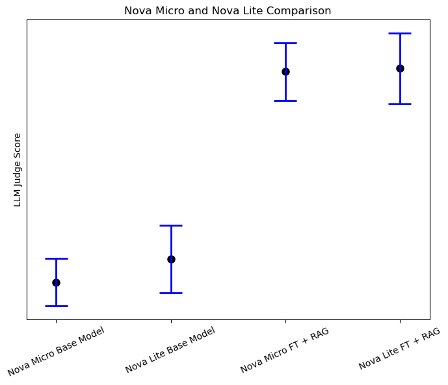
Một phát hiện đáng chú ý từ quá trình đánh giá (như thể hiện trong hình sau) là khi kết hợp fine-tuning và RAG, các mô hình nhỏ hơn như Amazon Nova Micro thể hiện sự cải thiện hiệu năng rất rõ rệt trong các tác vụ domain-specific, gần tiệm cận với hiệu năng của các mô hình lớn hơn. Điều này cho thấy rằng đối với các use case chuyên biệt, có phạm vi xác định rõ ràng, việc sử dụng các mô hình nhỏ kết hợp cả fine-tuning và RAG có thể là một giải pháp hiệu quả hơn về chi phí so với việc triển khai các mô hình lớn.
Độ trễ và tác động đến token
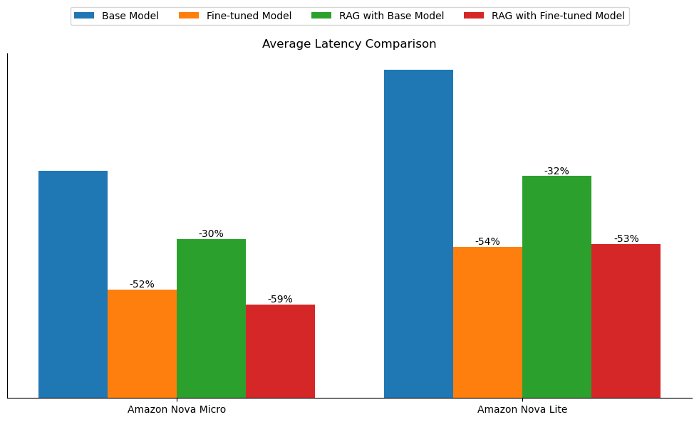
Bên cạnh việc nâng cao chất lượng phản hồi, cả fine-tuning và RAG đều giúp giảm độ trễ khi sinh phản hồi so với mô hình nền. Đối với cả Amazon Nova Micro và Amazon Nova Lite, fine-tuning giúp giảm độ trễ của mô hình nền khoảng 50%, trong khi RAG giúp giảm khoảng 30%, như minh họa trong hình sau.
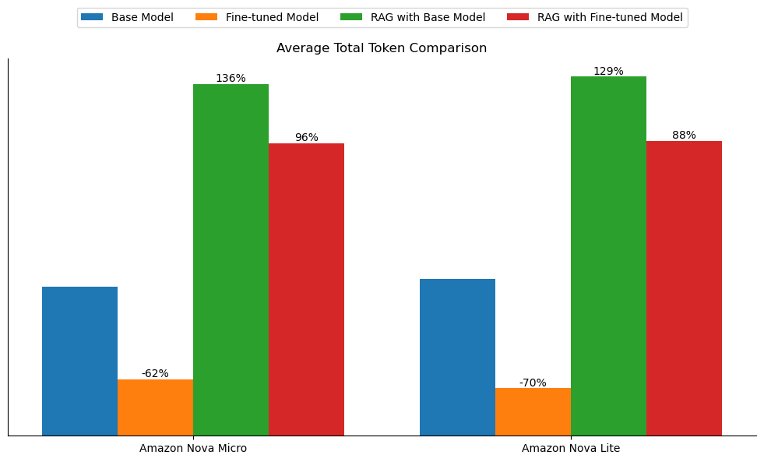
Fine-tuning cũng mang lại một lợi thế riêng biệt trong việc cải thiện tone và style của các câu trả lời, giúp chúng phù hợp hơn với dữ liệu huấn luyện. Trong các thí nghiệm của chúng tôi, tổng số token trung bình (bao gồm input token và output token) đã giảm hơn 60% đối với cả hai mô hình đã fine-tune. Ngược lại, tổng số token trung bình tăng hơn gấp đôi khi sử dụng phương pháp RAG, do cần truyền thêm context vào mô hình, như minh họa trong hình sau.
Kết quả này cho thấy rằng đối với các use case nhạy cảm về độ trễ hoặc khi mục tiêu là căn chỉnh phản hồi của mô hình theo tone, style hoặc brand voice cụ thể, tùy biến mô hình có thể mang lại giá trị kinh doanh cao hơn.
Kết luận
Trong bài viết này, chúng tôi đã so sánh tùy biến mô hình (fine-tuning) và RAG cho các tác vụ domain-specific với Amazon Nova. Đầu tiên, chúng tôi cung cấp hướng dẫn chi tiết về cách fine-tune, host và thực hiện inference với các mô hình Amazon Nova đã được tùy biến thông qua Amazon Bedrock API. Sau đó, chúng tôi áp dụng phương pháp LLM-as-a-judge để đánh giá chất lượng phản hồi của các cách tiếp cận khác nhau. Ngoài ra, chúng tôi cũng phân tích độ trễ và tác động đến token của từng cấu hình.
Cả fine-tuning và RAG đều giúp cải thiện hiệu năng mô hình. Tùy theo tác vụ và tiêu chí đánh giá, tùy biến mô hình có thể mang lại hiệu năng tương đương hoặc thậm chí tốt hơn so với RAG. Tùy biến mô hình cũng đặc biệt hữu ích trong việc cải thiện tone và phong cách của câu trả lời. Trong thí nghiệm này, phản hồi của mô hình đã fine-tune tuân theo phong cách trả lời ngắn gọn của dữ liệu huấn luyện, từ đó giúp giảm độ trễ so với mô hình nền.
Ngoài ra, tùy biến mô hình còn phù hợp với nhiều use case mà RAG không dễ áp dụng, chẳng hạn như tool calling, sentiment analysis, entity extraction, và nhiều kịch bản khác. Nhìn chung, chúng tôi khuyến nghị kết hợp cả tùy biến mô hình và RAG cho các bài toán hỏi–đáp hoặc các tác vụ tương tự để đạt được hiệu năng tối đa.
Để tìm hiểu thêm về Amazon Bedrock và các mô hình Amazon Nova mới nhất, vui lòng tham khảo Amazon Bedrock User Guide và Amazon Nova User Guide. AWS Generative AI Innovation Center quy tụ đội ngũ chuyên gia về khoa học và chiến lược AI của AWS, với kinh nghiệm toàn diện xuyên suốt hành trình triển khai generative AI, hỗ trợ khách hàng xác định use case ưu tiên, xây dựng roadmap và đưa giải pháp vào production. Tham khảo thêm tại Generative AI Innovation Center để xem các dự án mới nhất và câu chuyện thành công của khách hàng.
Tác giả

Mengdie (Flora) Wang
Là Data Scientist tại AWS Generative AI Innovation Center, nơi cô làm việc cùng khách hàng để thiết kế kiến trúc và triển khai các giải pháp Generative AI có khả năng mở rộng, giải quyết các bài toán kinh doanh đặc thù. Flora chuyên sâu về các kỹ thuật tùy biến mô hình và hệ thống AI dựa trên agent, giúp tổ chức khai thác tối đa tiềm năng của công nghệ generative AI. Trước khi gia nhập AWS, Flora nhận bằng Thạc sĩ Khoa học Máy tính tại University of Minnesota, nơi cô phát triển nền tảng chuyên môn về machine learning và trí tuệ nhân tạo.

Sungmin Hong
Là Senior Applied Scientist tại Amazon Generative AI Innovation Center, nơi anh hỗ trợ đẩy nhanh việc triển khai đa dạng các use case cho khách hàng AWS. Trước khi gia nhập Amazon, Sungmin là nghiên cứu sinh sau tiến sĩ tại Harvard Medical School. Anh sở hữu bằng Tiến sĩ Khoa học Máy tính từ New York University. Ngoài công việc, Sungmin tự hào vì đã giữ cho các chậu cây trong nhà của mình sống khỏe mạnh hơn 3 năm.

Jae Oh Woo
Là Senior Applied Scientist tại AWS Generative AI Innovation Center, chuyên phát triển các giải pháp tùy chỉnh và tùy biến mô hình cho nhiều use case khác nhau. Anh có niềm đam mê mạnh mẽ với nghiên cứu liên ngành, kết nối nền tảng lý thuyết với các ứng dụng thực tiễn trong lĩnh vực generative AI đang phát triển nhanh chóng. Trước khi gia nhập Amazon, Jae Oh là Simons Postdoctoral Fellow tại University of Texas at Austin, nơi anh nghiên cứu tại các khoa Toán học và Electrical and Computer Engineering. Anh nhận bằng Tiến sĩ Toán học Ứng dụng tại Yale University.

Rahul Ghosh
Là Applied Scientist tại AWS Generative AI Innovation Center, nơi anh làm việc cùng khách hàng AWS ở nhiều lĩnh vực khác nhau nhằm đẩy nhanh quá trình ứng dụng Generative AI. Rahul nhận bằng Tiến sĩ Khoa học Máy tính tại University of Minnesota.

Baishali Chaudhury
Là Applied Scientist tại Generative AI Innovation Center của AWS, nơi cô tập trung phát triển các giải pháp Generative AI cho các bài toán thực tế. Cô có nền tảng chuyên môn vững chắc về computer vision, machine learning và AI trong lĩnh vực y tế. Baishali sở hữu bằng Tiến sĩ Khoa học Máy tính từ University of South Florida và bằng PostDoc từ Moffitt Cancer Centre.

Anila Joshi
Có hơn một thập kỷ kinh nghiệm xây dựng các giải pháp AI. Với vai trò AWSI Geo Leader tại AWS Generative AI Innovation Center, Anila tiên phong trong việc ứng dụng AI sáng tạo, mở rộng giới hạn khả thi và thúc đẩy việc áp dụng các dịch vụ AWS bằng cách hỗ trợ khách hàng hình thành ý tưởng, xác định và triển khai các giải pháp generative AI an toàn.
