Tác giả: Jonathan Wu, Aditya Garg, Darius Atmar và Manoj CS
Ngày đăng: 05/01/2026
Danh mục: Amazon Bedrock, Amazon CloudWatch, Amazon EventBridge, Amazon SageMaker, Amazon SageMaker AI, Amazon Simple Storage Service (S3), AWS Cost Explorer, AWS Glue, AWS Lambda, AWS Step Functions, Industries, Telecommunications
Giới thiệu
Frontier Communications là nhà cung cấp dịch vụ cáp quang thuần túy lớn nhất tại Hoa Kỳ, với 3,2 triệu thuê bao băng thông rộng trên 25 bang và hơn 12.000 nhân viên. Nhóm Retention & Loyalty đảm bảo khách hàng luôn hài lòng bằng cách tối ưu hành trình khách hàng, giảm tỷ lệ rời bỏ và cải thiện Lifetime Value (LTV).
Với vai trò là các nhà khoa học dữ liệu, chúng tôi sử dụng môi trường Amazon Web Services (AWS) để phân tích dữ liệu tương tác khách hàng và cung cấp các insight có thể hành động. Theo định hướng đó, chúng tôi đã phát triển một ứng dụng generative AI trên AWS để phân tích bản ghi (transcript) của các cuộc gọi trung tâm chăm sóc khách hàng, có tên là Giga-T.
Thách thức
Mỗi tháng, các nhân viên trung tâm cuộc gọi của Frontier thuộc nhóm Retention & Loyalty xử lý khoảng 125.000 cuộc gọi, tương đương 25.000 giờ hội thoại và 250 triệu từ được phát ngôn. Đây là một nguồn dữ liệu chưa từng được khai thác đúng mức, có thể truyền tải “tiếng nói thực sự của khách hàng” đến ban lãnh đạo theo cách chưa từng có trước đây.
Xử lý Ngôn ngữ Tự nhiên (NLP) để phân tích văn bản phi cấu trúc không đạt được ngưỡng độ chính xác tối thiểu mà chúng tôi mong muốn. Hơn nữa, việc triển khai NLP truyền thống vừa tốn nhiều công sức, vừa thiếu linh hoạt. Vì vậy, chúng tôi quyết định thử nghiệm công nghệ mới nổi của các mô hình ngôn ngữ lớn (LLMs) để phân tích bản ghi cuộc gọi.
Chúng tôi bắt đầu với một câu hỏi cốt lõi cho mọi transcript: Vì sao khách hàng gọi đến?
Chúng tôi chia mục đích cuộc gọi thành 50 phân loại theo nguyên tắc MECE (Mutually Exclusive, Collectively Exhaustive – loại trừ lẫn nhau và bao quát toàn bộ). Mỗi mục đích cuộc gọi khác nhau ở tổ hợp nguyên nhân gốc rễ, tác động đến KPI và biện pháp xử lý.
Dữ liệu về chủ đề cốt lõi này cho phép chúng tôi trả lời hàng loạt câu hỏi “evergreen” cho doanh nghiệp:
- Tỷ lệ tương đối của các lý do hủy dịch vụ là gì và chúng thay đổi như thế nào theo thời gian?
- Có sự tăng đột biến theo thời gian đối với một số nhóm khách hàng nhất định hay không?
- Có lý do hủy nào khó xử lý hơn cho nhân viên ở các cấp độ kỹ năng khác nhau không?
- Nhân viên nào có tỷ lệ thuyết phục cao nhất và thấp nhất cho từng lý do hủy cụ thể?
- Tổ hợp giữa nhân viên và các mục đích không hủy nào có tỷ lệ giải quyết ngay lần gọi đầu thấp nhất?
- Độ nhọn (kurtosis) của phân phối các cuộc gọi không hủy giữa các nhân viên là bao nhiêu?
Việc nhân viên hoặc khách hàng tự báo cáo mục đích cuộc gọi thường không đáng tin cậy vì nhiều lý do: nhân viên có thể không ghi nhận một cách nhất quán hoặc chính xác; khách hàng mô tả mục đích với IVR quá chung chung hoặc khó hiểu; hai nhân viên có thể hiểu cùng một mã mục đích theo hai cách khác nhau; hoặc ý nghĩa của mã mục đích thay đổi theo thời gian mà không có tài liệu. Thậm chí, mục đích cuộc gọi có thể thay đổi giữa chừng trong cuộc trò chuyện.
Việc con người rà soát toàn bộ các cuộc gọi là không khả thi. Sẽ mất 10 tháng để một người nghe và xác định mục đích cho 6.000 transcript (khối lượng gọi mỗi ngày của nhóm Retention & Loyalty). Lấy mẫu ngẫu nhiên nhỏ để kiểm tra lại có sai số thống kê quá cao, vừa dễ tạo ra lỗi loại I (phát hiện mẫu hình không tồn tại) vừa dễ bỏ sót mẫu hình thực sự (lỗi loại II). Không có ý nghĩa gì khi đề xuất thay đổi vận hành nếu phân tích không có ý nghĩa thống kê lẫn ý nghĩa thực tiễn. Trong khi đó, lấy mẫu đủ lớn thì vừa tốn thời gian vừa tốn chi phí.
Giải pháp
Thiết lập ban đầu cho Giga-T
Nhóm khoa học dữ liệu của chúng tôi may mắn có sự ủng hộ từ ban lãnh đạo cấp cao với tinh thần intrapreneurial: chấp nhận rủi ro có tính toán, bắt đầu nhỏ, thất bại nhanh và lặp lại nhanh. Hành trình với Giga-T phản ánh rõ triết lý này, từ một proof of concept đơn giản đến một giải pháp tinh vi, có khả năng mở rộng, như minh họa ở Hình 1.
Chúng tôi bắt đầu với kiến trúc rõ ràng:
- Amazon Simple Storage Service (Amazon S3) để lưu trữ file transcript đầu vào và kết quả phân loại dưới dạng CSV.
- Amazon Sagemaker AI instance storage để quản lý các file prompt cho prompt chaining dựa trên đồ thị DAG.
- Amazon Bedrock để truy cập họ mô hình nền tảng (FM) Anthropic Claude.
- Amazon SageMaker Jupyter notebooks để:
- Ghép transcript và prompt vào system message và user message
- Thiết lập DAG cho prompt chaining
- Gọi API Amazon Bedrock để phân tích tại từng node trong DAG
- Lưu kết quả vào CSV trong Amazon S3
- Lặp sang transcript tiếp theo
- AWS Cost Explorer để theo dõi chi phí API phát sinh trong quá trình phân tích
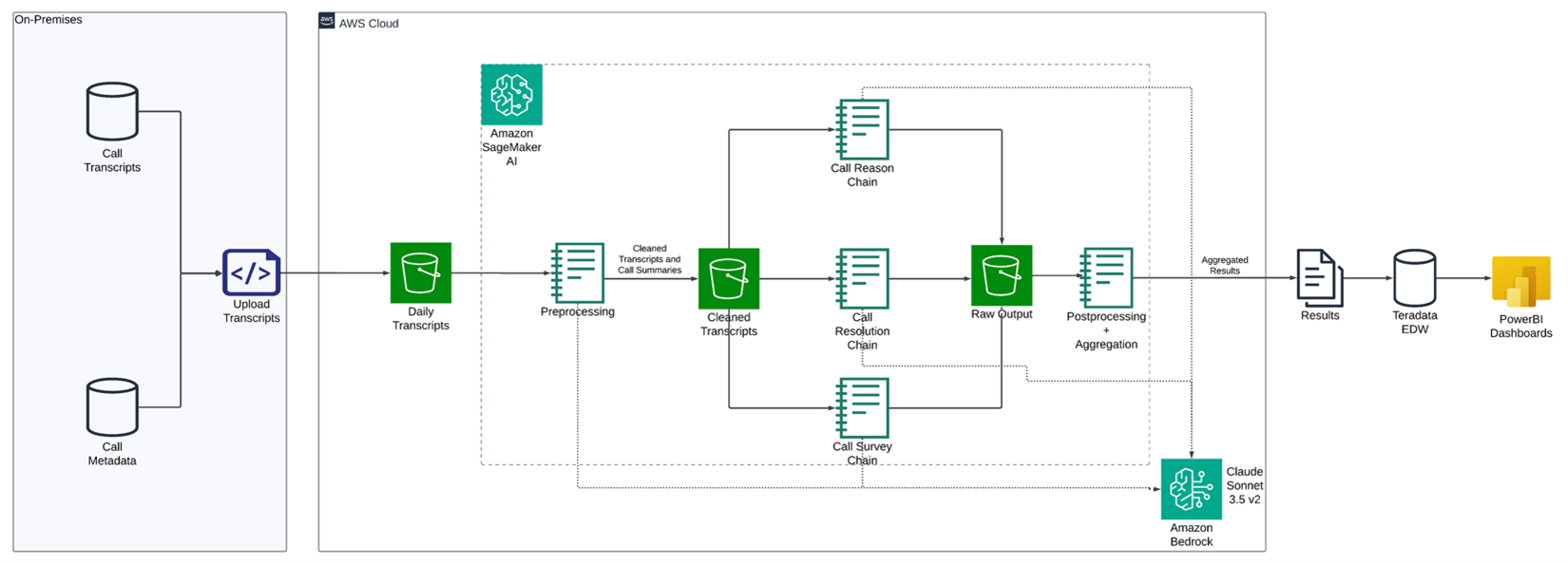
Hình 1: Kiến trúc – Kiến trúc ban đầu của Giga-T
Kiến trúc này cho phép chúng tôi bắt đầu xử lý transcript ngay lập tức và ước tính chi phí khi đưa vào production. Dự án skunkworks đã tạo ra những insight trước đây không thể đạt được, chứng minh giá trị của ý tưởng mà không bị sa lầy vào thiết kế hạ tầng phức tạp.
Triển khai đầy đủ trong năm 2024
Cách tiếp cận theo từng giai đoạn giúp chúng tôi liên tục cải tiến trong suốt 2024 và 2025.
Tháng 1–3/2024: Proof of concept
- Con người kiểm tra 900 transcript cho 50 phân loại MECE
- Đạt trên 70% cho cả precision và recall ở mỗi phân loại trong bài test đánh giá
- Phân loại thành công 20.000 cuộc gọi bằng Giga-T trong AWS
- Tạo các visualization cho các câu hỏi evergreen về cuộc gọi, khách hàng và nhân viên
Tháng 4–6/2024: Sản xuất quy mô nhỏ
- Ứng dụng generative AI đầu tiên trong công ty được phê duyệt chính thức cho production
- Bắt đầu phân tích ngẫu nhiên 1.000 cuộc gọi Retention & Loyalty mỗi ngày
- Thêm prompt đánh giá call resolution với hơn 95% precision và recall
Tháng 7–12/2024: Sản xuất quy mô lớn
- Mở rộng Giga-T để phân tích toàn bộ 6.000 cuộc gọi Retention & Loyalty mỗi ngày làm việc
- Thêm prompt đo lường 15 khía cạnh khác của transcript (ví dụ: mức độ tuân thủ của nhân viên)
- Thiết lập dashboard business intelligence
- Tích hợp vào vòng lặp báo cáo vận hành của trung tâm cuộc gọi để phản hồi hàng tuần về hiệu suất nhân viên
- Tự động hóa thêm các quy trình backend
Kiến trúc nâng cao được xây dựng trên nền tảng ban đầu và bổ sung thêm các thành phần:
- Amazon S3 tiếp tục là nơi lưu trữ chính cho transcript thô
- Amazon EventBridge để điều phối trigger workflow tự động
- AWS Step Functions quản lý orchestration phức tạp của pipeline phân tích
- AWS Lambda functions và AWS Glue Jobs cho xử lý transcript và chuyển đổi dữ liệu
- Amazon Bedrock tiếp tục là lõi cho phân tích LLM với mô hình Claude Sonnet 3.5 v2
- Nền tảng dữ liệu doanh nghiệp hiện có, bao gồm Databricks Unity Catalog và Microsoft Power BI, được tích hợp với kiến trúc AWS
Workflow bắt đầu khi transcript mới được upload lên Amazon S3 và kích hoạt rule EventBridge. Rule này khởi chạy Step Functions workflow để điều phối nhiều Lambda functions thực hiện:
- Tiền xử lý và xác thực transcript
- Chạy phân tích LLM qua Amazon Bedrock với các prompt đã tinh chỉnh
- Lưu kết quả vào Databricks Unity Catalog
- Sinh báo cáo và visualization tự động
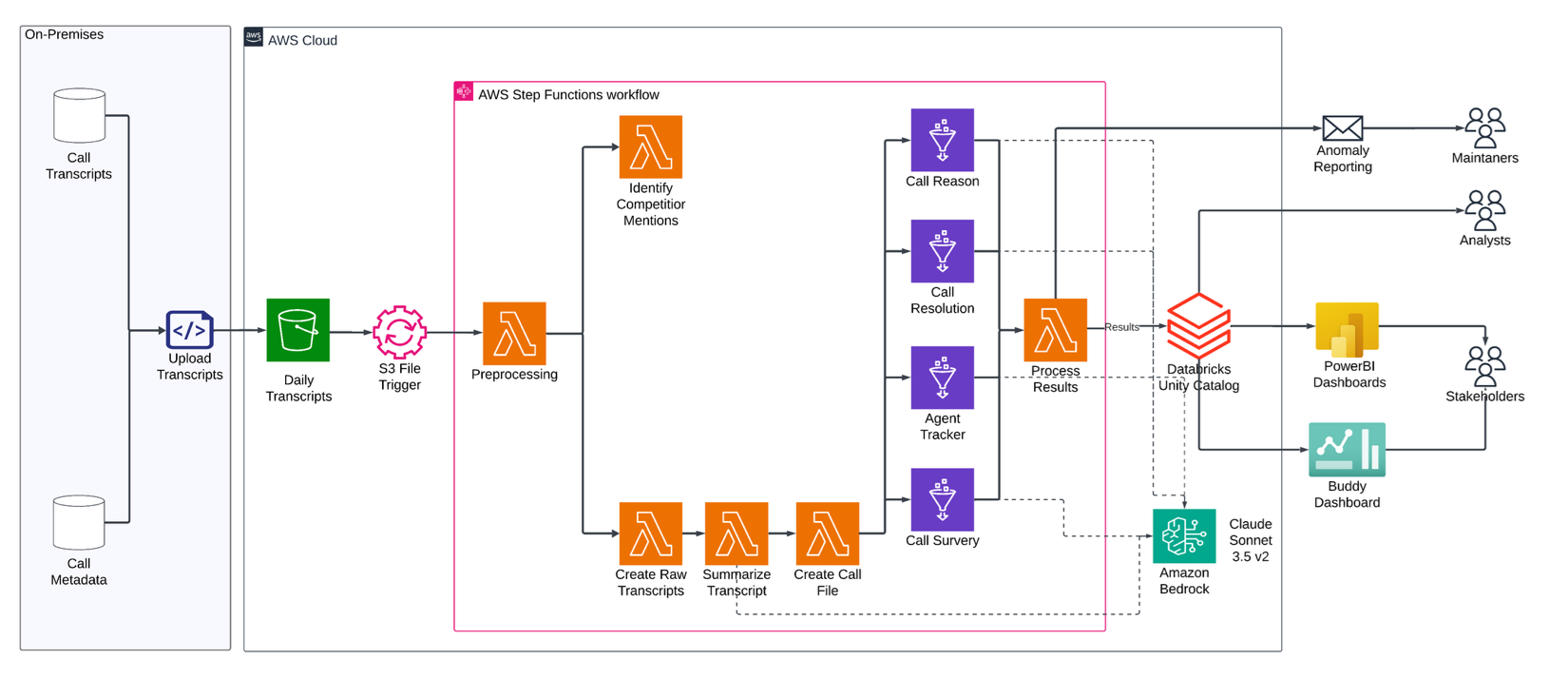
Hình 2: Kiến trúc serverless cho Giga-T
Kiến trúc serverless này cho phép tự động scale theo khối lượng cuộc gọi thay đổi mà vẫn duy trì hiệu năng ổn định. Việc giám sát và logging thông qua Amazon CloudWatch cung cấp khả năng quan sát vận hành và hỗ trợ kiểm soát chất lượng.
Tiến triển trong năm 2025
Trong năm 2025, Giga-T tiếp tục được cải thiện với nhiều tự động hóa backend hơn, nhiều dữ liệu hơn, nhiều insight hơn, nhiều báo cáo hơn và tác động lớn hơn đến KPI của trung tâm cuộc gọi. Môi trường AWS chứng minh khả năng mở rộng dễ dàng, đồng thời đáp ứng SLA và các yêu cầu cấp doanh nghiệp.
Chúng tôi đã đào tạo thêm 14 prompt engineer trong công ty về cách sử dụng Amazon S3, Amazon Bedrock và Sagemaker để mở rộng Giga-T sang các bộ phận khác như Sales, B2B, Tech Support và Customer Service. Tổng cộng, các trung tâm cuộc gọi của Frontier xử lý 500.000 cuộc gọi và khoảng 1 tỷ từ được phát ngôn mỗi tháng.
Bên cạnh khả năng mở rộng, độ ổn định và tính linh hoạt của hạ tầng, đội ngũ AWS đã thực sự đồng hành và đóng vai trò then chốt trong việc trao quyền cho các nhà khoa học dữ liệu của chúng tôi phát triển Giga-T một cách tự chủ. Hai workshop thuộc chương trình Experience-Based Accelerator (EBA) đã giúp chúng tôi vượt qua rào cản ban đầu khi xây dựng ứng dụng generative AI trên AWS. Một workshop tập trung vào việc sử dụng Amazon Bedrock lần đầu để phân tích transcript; workshop còn lại giúp tự động hóa thành công quy trình backend đầu tiên của Giga-T bằng Step Functions và Lambda.
Ngoài ra, các buổi trao đổi định kỳ với client executive và solutions architect đã nhiều lần giúp chúng tôi “gỡ bế tắc” và học thêm các kỹ thuật mới như yêu cầu tăng backend rate limits, inference cross-Region, batch inference, prompt caching và application inference profiles.
Kết quả
Giga-T giúp chúng tôi hiểu sâu và nhanh hơn những gì đang diễn ra. Nếu con người cần 10 tháng để nghe và phân tích 6.000 cuộc gọi, thì Giga-T có thể xử lý số đó chỉ trong 6 giờ — nhanh hơn 416 lần và giảm 98% chi phí trên mỗi transcript. Những insight và điều chỉnh vận hành từ luồng dữ liệu mới này đã giúp nhóm Retention & Loyalty đạt tỷ lệ giữ chân kỷ lục 83% trong năm 2024.
Thông qua vòng lặp báo cáo giữa Giga-T và vận hành trung tâm cuộc gọi, chúng tôi quan sát thấy trong một trường hợp, tỷ lệ tuân thủ chính sách mới tăng tuyến tính từ 20% lên 80% chỉ trong vài tuần trên toàn bộ các trung tâm.
Chúng tôi kết hợp generative AI và các kỹ thuật thống kê truyền thống để xác định những gì các nhân viên giỏi nhất nói và hỏi mà các nhân viên kém nhất thì không. Cụ thể, chúng tôi dùng Giga-T trong Amazon Bedrock để phân tích transcript theo lý thuyết hành vi ngôn ngữ, sau đó xử lý kết quả bằng k-modes clustering và logistic regression trong SageMaker.
Việc nhìn rõ toàn bộ ngữ cảnh ngữ nghĩa của cuộc gọi cho phép đo lường hiệu suất nhân viên công bằng hơn và phù hợp hơn về mặt tài chính cho doanh nghiệp. Ví dụ, không phải mọi cuộc gọi đến của nhân viên Inside Sales đều là cơ hội bán hàng khả thi; một tỷ lệ đáng kể thậm chí không liên quan đến bán hàng. Vì vậy, tỷ lệ chuyển đổi nên lấy cuộc gọi có khả năng bán làm mẫu số, chứ không phải tất cả cuộc gọi. Để làm được điều đó, cần có năng lực generative AI như Giga-T để xác định chính xác cuộc gọi nào là cơ hội bán và cuộc gọi nào không.
Trong một phân tích ngẫu hứng, chúng tôi thực hiện voice of the customer analysis để xác định các khiếu nại và câu hỏi phổ biến nhất sau cơn bão Helene, từ đó điều chỉnh chính sách trung tâm cuộc gọi theo thời gian thực nhằm đáp ứng tốt hơn nhu cầu khách hàng trong giai đoạn khủng hoảng.
Bài học chính
Chúng tôi có ba lời khuyên dành cho các nhà khoa học dữ liệu trên hành trình generative AI:
Tư duy start-up: Generative AI là công nghệ mới nổi, phát triển rất nhanh và chưa ai biết chính xác khi nào nó sẽ chậm lại hay đi đến đâu. Không có giáo trình chuẩn về best practices. Không thể tuyển một người có hàng chục năm kinh nghiệm triển khai generative AI trong môi trường doanh nghiệp vì họ chưa tồn tại. Cách duy nhất để học là thử và quan sát kết quả. Đừng ngại bắt đầu nhỏ, thất bại nhanh, lặp nhanh và xoay chuyển kịp thời. Sự ủng hộ của lãnh đạo mang tinh thần intrapreneurial là vô giá.
Cách tiếp cận human-in-the-loop: Thành công của dự án generative AI cần sự tham gia của con người nhiều hơn bạn nghĩ trong việc xây dựng input và đánh giá output. Ngữ cảnh là yếu tố then chốt, vì vậy hãy trực tiếp tham gia vào prompt engineering. LLMs không có ngữ cảnh offline về cách kết quả được thảo luận hay sử dụng downstream. Prompt engineer lý tưởng là người giao tiếp bằng văn bản xuất sắc và có chuyên môn domain vững. LLMs rất “nhạy cảm”; những thay đổi tưởng chừng nhỏ trong cách diễn đạt có thể làm thay đổi lớn độ chính xác. Khi hệ quả downstream ảnh hưởng trực tiếp đến con người, việc đánh giá dựa trên ground truth do con người xác định cùng các thước đo thống kê (precision, recall, Cohen’s Kappa) càng trở nên quan trọng.
Hợp tác với chuyên gia domain của AWS: Môi trường AWS rất rộng lớn, vừa đầy tiềm năng vừa phức tạp. Solutions architect của AWS nhìn thấy toàn bộ các vấn đề phát sinh trên nhiều khách hàng khác nhau, nắm rõ các giải pháp tốt nhất, cũng như điểm mạnh, hạn chế và cải tiến sắp tới của AWS. Hợp tác với họ thông qua workshop EBA và các buổi trao đổi định kỳ sẽ mang lại lợi ích to lớn trong việc đưa ứng dụng generative AI trên AWS tạo ra tác động thực sự cho doanh nghiệp.
Bắt đầu như thế nào
Nếu bạn quan tâm đến việc xây dựng giải pháp tương tự cho tổ chức của mình, hãy tham khảo các tài nguyên sau:
Tìm hiểu thêm về Amazon Bedrock và các FM hiện có:
Khám phá các dịch vụ AWS đã sử dụng:
- Amazon Bedrock
- AWS Step Functions
- AWS Lambda
- Amazon S3
- AWS Glue
- Amazon EventBridge
- Amazon CloudWatch
- Amazon Sagemaker
Kết nối với chuyên gia AWS:
- Tìm hiểu về chương trình AWS Experience-Based Accelerator (EBA)
- Liên hệ AWS account team để thảo luận use case
- Tham gia AWS Builder Community
Truy cập tài nguyên mẫu:
Về Frontier Communications
Frontier Communications (NASDAQ: FYBR) là nhà cung cấp dịch vụ viễn thông thuộc Fortune 500, cung cấp dịch vụ internet, TV và điện thoại trên khắp Hoa Kỳ. Tìm hiểu thêm tại Frontier.com.
Tác giả

Jonathan Wu
Jonathan Wu là Giám đốc Data Science & AI tại Frontier Communications, người dẫn dắt ứng dụng GenAI đầu tiên của công ty được phê duyệt cho production. Ông được CEO trao giải “Changemaker of the Year” năm 2025, quản lý đội ngũ data scientist và đã đào tạo 14 prompt engineer trên toàn doanh nghiệp để mở rộng việc áp dụng GenAI. Trước đó, ông có 12 năm kinh nghiệm trong M&A và tư vấn, mang đến góc nhìn chiến lược kinh doanh cho tác động thực tiễn của mô hình thống kê và GenAI. Ông tốt nghiệp Harvard chuyên ngành Kinh tế và hoàn thành các khóa học sau đại học về thống kê tại Harvard và Georgetown.

Aditya Garg
Aditya Garg là Senior Data Scientist tại Frontier Communications, chuyên xây dựng các ứng dụng GenAI cho nhiều bài toán kinh doanh liên quan đến lòng trung thành của khách hàng và vận hành trung tâm cuộc gọi. Anh tập trung vào việc tạo ra các giao diện và workflow dễ tiếp cận để cả kỹ sư lẫn người dùng nghiệp vụ đều có thể khai thác GenAI hiệu quả. Với hơn 4 năm kinh nghiệm chuyên môn sau khi tốt nghiệp Cử nhân Toán tính toán tại UC Riverside, anh có nền tảng vững chắc về pipeline machine learning, mô hình data science và data engineering.

Darius Atmar
Darius Atmar là Senior Data Scientist tại Frontier Communications, nơi anh kiến trúc các giải pháp GenAI cho phân tích hỗ trợ khách hàng quy mô lớn. Với chuyên môn về machine learning và AI ứng dụng, anh dẫn dắt việc tự động hóa và mở rộng Giga-T, biến dữ liệu cuộc gọi phi cấu trúc thành insight có thể hành động. Darius chuyên xây dựng các workflow AI tin cậy và hiệu năng cao. Anh có bằng Cử nhân Vật lý tại University of Pennsylvania và Thạc sĩ Data Science tại Brown University.

Manoj CS
Manoj CS là Senior Solutions Architect tại AWS, làm việc tại Atlanta, Georgia. Anh chuyên hỗ trợ khách hàng trong lĩnh vực viễn thông xây dựng các giải pháp đổi mới trên AWS và có hơn 16 năm kinh nghiệm phát triển ứng dụng, với thế mạnh trong thiết kế kiến trúc bảo mật và có khả năng mở rộng trên hạ tầng cloud. Anh là thành viên cộng đồng AI/ML nội bộ của AWS và đóng vai trò chuyên gia về generative AI. Ngoài công việc, Manoj thích dành thời gian cho gia đình, làm vườn và du lịch.
