Tác giả: Karthik Prabhakar, Matt Tolton, Neil Mukerje và Ravi Kumar Singh
Ngày đăng: 07/01/2026
Danh mục: Amazon EMR, Analytics, Announcements, Intermediate (200), Serverless
Tại AWS re:Invent 2025, Amazon Web Services (AWS) đã công bố serverless storage cho Amazon EMR Serverless, một năng lực mới giúp loại bỏ nhu cầu cấu hình đĩa cục bộ cho các workload Apache Spark. Điều này giúp giảm chi phí xử lý dữ liệu lên đến 20%, đồng thời loại bỏ các lỗi job do giới hạn dung lượng đĩa.
Với serverless storage, Amazon EMR Serverless tự động xử lý các thao tác dữ liệu trung gian, chẳng hạn như shuffle, thay cho bạn. Bạn chỉ trả tiền cho compute và memory — không phát sinh chi phí lưu trữ. Bằng cách tách rời lưu trữ khỏi compute, Spark có thể giải phóng ngay các worker nhàn rỗi, giúp giảm chi phí trong suốt vòng đời của job. Hình ảnh sau đây minh họa thông báo về serverless storage cho EMR Serverless tại keynote AWS re:Invent 2025:

Thách thức: Xác định kích thước lưu trữ đĩa cục bộ
Việc chạy các workload Apache Spark yêu cầu phải xác định dung lượng lưu trữ đĩa cục bộ cho các thao tác shuffle — nơi Spark phân phối lại dữ liệu giữa các executor trong quá trình join, aggregation và sort. Điều này đòi hỏi phải phân tích lịch sử job để ước tính nhu cầu đĩa, dẫn đến hai vấn đề phổ biến: cấp phát dư gây lãng phí chi phí cho dung lượng không sử dụng, và cấp phát thiếu gây lỗi job khi hết không gian đĩa. Phần lớn khách hàng thường cấp phát dư lưu trữ cục bộ để đảm bảo job hoàn thành thành công trong môi trường production.
Hiện tượng lệch dữ liệu (data skew) càng làm vấn đề trầm trọng hơn. Khi một executor phải xử lý một partition lớn bất thường, executor đó sẽ mất nhiều thời gian hơn đáng kể để hoàn thành, trong khi các worker khác thì nhàn rỗi. Nếu bạn không cấp phát đủ dung lượng đĩa cho executor bị lệch này, toàn bộ job sẽ thất bại — khiến data skew trở thành một trong những nguyên nhân hàng đầu gây lỗi job Spark. Tuy nhiên, vấn đề không chỉ dừng lại ở việc lập kế hoạch dung lượng. Do dữ liệu shuffle gắn chặt với đĩa cục bộ, các Spark executor bị “ghim” vào các node worker ngay cả khi yêu cầu compute giảm giữa các stage của job. Điều này ngăn Spark giải phóng worker và scale down, làm tăng chi phí compute trong suốt vòng đời job. Khi một worker node gặp sự cố, Spark phải tính toán lại dữ liệu shuffle được lưu trên node đó, gây ra độ trễ và sử dụng tài nguyên kém hiệu quả.
Cách thức hoạt động
Serverless storage cho Amazon EMR Serverless giải quyết các thách thức này bằng cách offload các thao tác shuffle khỏi từng worker compute sang một tầng lưu trữ đàn hồi, tách biệt. Thay vì lưu trữ dữ liệu quan trọng trên các đĩa cục bộ gắn với Spark executor, serverless storage tự động cấp phát và scale lưu trữ từ xa hiệu năng cao trong suốt quá trình job chạy.
Kiến trúc này mang lại một số lợi ích chính. Thứ nhất, compute và storage có thể scale độc lập — Spark có thể cấp phát và giải phóng worker theo nhu cầu ở từng stage của job mà không phải lo giữ lại dữ liệu được lưu cục bộ. Thứ hai, dữ liệu shuffle được phân phối đồng đều trên tầng serverless storage, loại bỏ các điểm nghẽn do data skew khi một số executor phải xử lý các partition shuffle quá lớn. Thứ ba, nếu một worker node gặp sự cố, job của bạn vẫn tiếp tục xử lý mà không bị gián đoạn hay phải chạy lại, vì dữ liệu được lưu trữ an toàn bên ngoài các worker compute riêng lẻ.
Serverless storage được cung cấp mà không tính thêm phí, đồng thời loại bỏ chi phí liên quan đến lưu trữ cục bộ. Thay vì phải trả tiền cho dung lượng đĩa cố định được cấp phát để đáp ứng tải I/O tối đa — dung lượng mà thường xuyên bị nhàn rỗi trong các workload nhẹ hơn — bạn có thể sử dụng serverless storage mà không phát sinh chi phí lưu trữ. Bạn có thể tập trung ngân sách cho tài nguyên compute trực tiếp xử lý dữ liệu, thay vì quản lý và cấp phát dư dung lượng đĩa.
Đổi mới kỹ thuật mang lại ba đột phá
Serverless storage giới thiệu ba đổi mới nền tảng giúp giải quyết các điểm nghẽn shuffle của Spark: kiến trúc tổng hợp đa tầng (multi-tier aggregation architecture), mạng được thiết kế chuyên biệt, và sự tách rời thực sự giữa storage và compute. Cơ chế shuffle của Apache Spark có một hạn chế cốt lõi: mỗi mapper ghi output thành nhiều file nhỏ, và mỗi reducer phải lấy dữ liệu từ hàng nghìn worker khác nhau. Trong một job quy mô lớn với 10.000 mapper và 1.000 reducer, điều này tạo ra tới 10 triệu lượt trao đổi dữ liệu riêng lẻ. Serverless storage thực hiện tổng hợp sớm và thông minh — các mapper stream dữ liệu đến một tầng aggregation, nơi dữ liệu shuffle được gom lại trong bộ nhớ trước khi commit xuống storage. Mặc dù từng thao tác ghi và lấy shuffle riêng lẻ có thể có độ trễ cao hơn đôi chút do round-trip qua mạng so với I/O đĩa cục bộ, hiệu năng tổng thể của job lại được cải thiện nhờ chuyển đổi hàng triệu thao tác I/O nhỏ thành một số ít thao tác lớn, tuần tự.
Cơ chế shuffle Spark truyền thống tạo ra một mạng lưới mesh, nơi mỗi worker duy trì kết nối với hàng trăm worker khác, tiêu tốn đáng kể CPU cho việc quản lý kết nối thay vì xử lý dữ liệu. Chúng tôi đã xây dựng một stack mạng tùy chỉnh, trong đó mỗi mapper chỉ mở một kết nối remote procedure call (RPC) bền vững duy nhất tới tầng aggregator, loại bỏ sự phức tạp của mạng mesh. Mặc dù các thao tác shuffle riêng lẻ có thể có độ trễ cao hơn đôi chút do round-trip qua mạng so với I/O đĩa cục bộ, hiệu năng tổng thể của job được cải thiện nhờ sử dụng tài nguyên hiệu quả hơn và khả năng scale đàn hồi. Các worker không còn phải chạy shuffle service — chúng tập trung hoàn toàn vào việc xử lý dữ liệu của bạn.
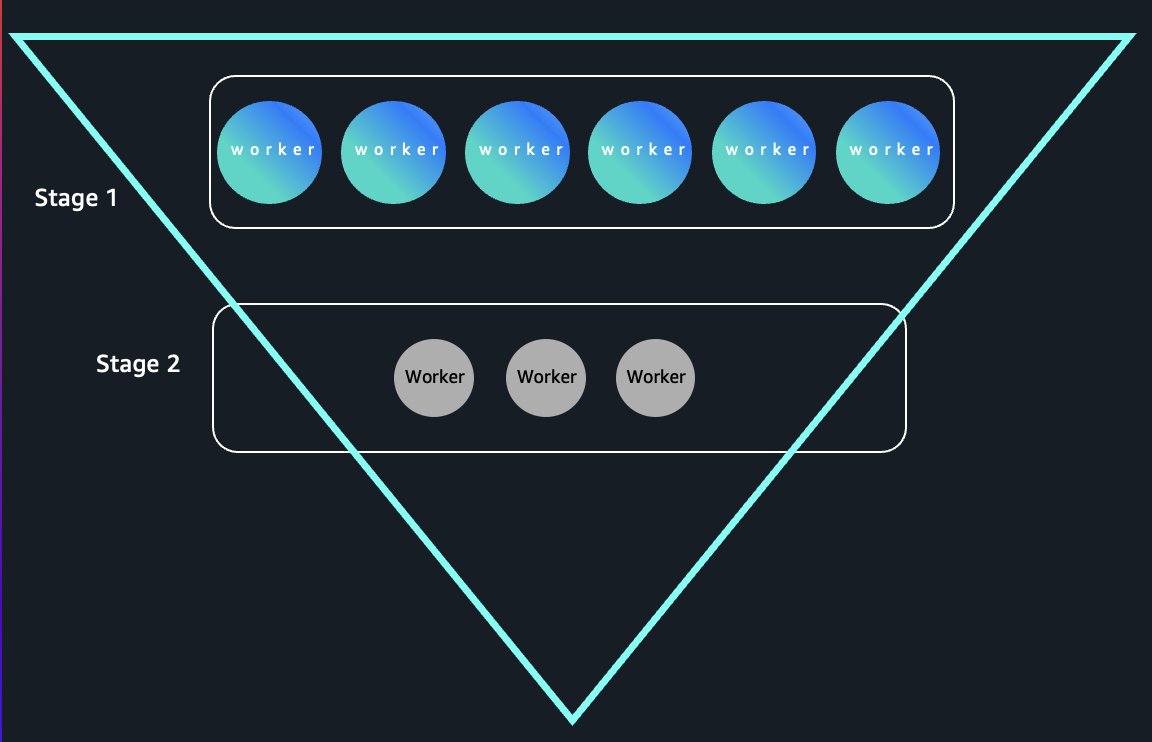
Trong các job Amazon EMR Serverless truyền thống, dữ liệu shuffle được lưu trên đĩa cục bộ, khiến vòng đời dữ liệu gắn chặt với vòng đời worker — các worker nhàn rỗi không thể kết thúc nếu vẫn còn dữ liệu shuffle. Serverless storage tách rời hoàn toàn hai yếu tố này bằng cách lưu trữ dữ liệu shuffle trong storage do AWS quản lý, với các handle ẩn được driver theo dõi. Worker có thể kết thúc ngay sau khi hoàn thành task mà không làm mất dữ liệu, cho phép scale đàn hồi. Trong các truy vấn dạng phễu (funnel-shaped), nơi các stage đầu yêu cầu mức song song rất lớn nhưng thu hẹp dần khi dữ liệu được aggregation, chúng tôi ghi nhận mức giảm chi phí compute lên đến 80% trong các benchmark nhờ giải phóng worker nhàn rỗi ngay lập tức. Sơ đồ sau minh họa việc giải phóng worker tức thì trong các truy vấn dạng phễu.
Tầng aggregator của chúng tôi tích hợp trực tiếp với AWS Identity and Access Management (IAM), AWS Lake Formation và các hệ thống kiểm soát truy cập chi tiết, cung cấp khả năng cô lập dữ liệu ở mức job với các quyền truy cập phù hợp với quyền của dữ liệu nguồn.
Bắt đầu sử dụng
Serverless storage hiện khả dụng tại nhiều AWS Regions. Để biết danh sách Region được hỗ trợ hiện tại, hãy tham khảo Amazon EMR User Guide.
Ứng dụng mới
Serverless storage có thể được bật cho các ứng dụng mới, bắt đầu từ Amazon EMR release 7.12. Thực hiện các bước sau:
- Tạo một ứng dụng Amazon EMR Serverless với Amazon EMR 7.12 hoặc mới hơn:
aws emr-serverless create-application \
--type "SPARK" \
--name my-application \
--release-label emr-7.12.0 \
--runtime-configuration '[{
"classification": "spark-defaults",
"properties": {
"spark.aws.serverlessStorage.enabled": "true"
}
}]' \
--region us-east-1
- Gửi Spark job của bạn:
aws emr-serverless start-job-run \
--application-id <application-id> \
--execution-role-arn <execution-role-arn> \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://<bucket>/<your_script.py>",
"sparkSubmitParameters": "--conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=10"
}
}'
Ứng dụng hiện có
Bạn có thể bật serverless storage cho các ứng dụng hiện có trên Amazon EMR 7.12 hoặc mới hơn bằng cách cập nhật cấu hình ứng dụng.
Để bật serverless storage bằng AWS Command Line Interface (AWS CLI), hãy nhập lệnh sau:
aws emr-serverless update-application \
--application-id <application-id> \
--runtime-configuration '[{
"classification": "spark-defaults",
"properties": {
"spark.aws.serverlessStorage.enabled": "true"
}
}]'
Để bật serverless storage bằng giao diện Amazon EMR Studio, hãy truy cập ứng dụng của bạn trong Amazon EMR Studio, vào Configuration, và thêm thuộc tính Spark spark.aws.serverlessStorage.enabled=true trong classification spark-defaults.
Cấu hình ở mức job
Bạn cũng có thể bật serverless storage cho từng job cụ thể, ngay cả khi nó chưa được bật ở mức ứng dụng:
aws emr-serverless start-job-run \
--application-id <application-id> \
--execution-role-arn <execution-role-arn> \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://<bucket>/<your_script.py>",
"sparkSubmitParameters": "--conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.aws.serverlessStorage.enabled=true"
}
}'
(Tùy chọn) Tắt serverless storage
Nếu bạn muốn tiếp tục sử dụng đĩa cục bộ, bạn có thể tắt serverless storage bằng cách bỏ qua cấu hình spark.aws.serverlessStorage.enabled hoặc đặt giá trị là false ở mức ứng dụng hoặc job:
spark.aws.serverlessStorage.enabled=false
Để sử dụng cơ chế cấp phát đĩa cục bộ truyền thống, hãy cấu hình loại đĩa và dung lượng phù hợp cho các worker của ứng dụng.
Giám sát và theo dõi chi phí
Bạn có thể giám sát mức sử dụng elastic shuffle thông qua các metric tiêu chuẩn trong Spark UI và theo dõi chi phí ở mức ứng dụng trong AWS Cost Explorer và AWS Cost and Usage Reports. Dịch vụ tự động xử lý việc tối ưu hiệu năng và scale, vì vậy bạn không cần tinh chỉnh thêm các tham số cấu hình.
Khi nào nên sử dụng serverless storage
Serverless storage mang lại giá trị lớn nhất cho các workload có khối lượng shuffle đáng kể — thường là các job shuffle hơn 10 GB dữ liệu (và ít hơn 200 GB mỗi job, theo giới hạn tại thời điểm viết bài). Các trường hợp này bao gồm:
- Xử lý dữ liệu quy mô lớn với nhiều thao tác aggregation và join
- Workload phân tích nặng về sort
- Thuật toán lặp cần truy cập lặp đi lặp lại cùng một tập dữ liệu
Các job có kích thước shuffle khó dự đoán đặc biệt hưởng lợi, vì serverless storage tự động scale dung lượng lên và xuống dựa trên nhu cầu theo thời gian thực. Đối với các workload có rất ít shuffle hoặc thời gian chạy rất ngắn (dưới 2–3 phút), lợi ích có thể bị hạn chế. Trong những trường hợp này, overhead của việc truy cập storage từ xa có thể lớn hơn lợi ích từ việc scale đàn hồi.
Bảo mật và vòng đời dữ liệu
Dữ liệu của bạn chỉ được lưu trong serverless storage trong thời gian job đang chạy và sẽ tự động bị xóa khi job hoàn thành. Do các batch job Amazon EMR Serverless có thể chạy tối đa 24 giờ, dữ liệu của bạn sẽ không được lưu trữ lâu hơn khoảng thời gian tối đa này. Serverless storage mã hóa dữ liệu cả khi truyền giữa ứng dụng Amazon EMR Serverless của bạn và tầng serverless storage, lẫn khi dữ liệu được lưu tạm thời ở trạng thái at rest, sử dụng các khóa mã hóa do AWS quản lý. Dịch vụ sử dụng mô hình bảo mật dựa trên IAM với khả năng cô lập dữ liệu ở mức job, nghĩa là một job không thể truy cập dữ liệu shuffle của job khác. Serverless storage duy trì các tiêu chuẩn bảo mật tương đương với Amazon EMR Serverless, với các kiểm soát bảo mật cấp doanh nghiệp xuyên suốt vòng đời xử lý.
Kết luận
Serverless storage đại diện cho một sự thay đổi mang tính nền tảng trong cách chúng ta tiếp cận hạ tầng xử lý dữ liệu, loại bỏ cấu hình thủ công, gắn chi phí với mức sử dụng thực tế và cải thiện độ tin cậy cho các workload I/O intensive. Bằng cách offload các thao tác shuffle sang một dịch vụ được quản lý, các kỹ sư dữ liệu có thể tập trung xây dựng phân tích thay vì quản lý hạ tầng lưu trữ.
Để tìm hiểu thêm về serverless storage và bắt đầu sử dụng, hãy truy cập tài liệu Amazon EMR Serverless.
Tác giả

Karthik Prabhakar
Karthik là Kiến trúc sư Data Processing Engines cho Amazon EMR tại AWS. Anh chuyên về kiến trúc hệ thống phân tán và tối ưu hóa truy vấn, làm việc cùng khách hàng để giải quyết các thách thức hiệu năng phức tạp trong các workload xử lý dữ liệu quy mô lớn. Trọng tâm của anh bao gồm phần lõi của engine, chiến lược tối ưu chi phí và các mô hình kiến trúc giúp khách hàng chạy phân tích ở quy mô petabyte một cách hiệu quả.

Ravi Kumar
Ravi là Senior Product Manager Technical tại Amazon Web Services, chuyên về hạ tầng dữ liệu và nền tảng phân tích ở quy mô exabyte. Anh hỗ trợ khách hàng khai thác insight từ dữ liệu có cấu trúc và phi cấu trúc bằng các công nghệ mã nguồn mở và điện toán đám mây. Ngoài công việc, Ravi yêu thích khám phá các xu hướng mới nổi trong data science và machine learning.

Matt Tolton
Matt là Senior Principal Engineer tại Amazon Web Services.

Neil Mukerje
Neil là Principal Product Manager tại Amazon Web Services.
