Tác giả: Ramesh Eega, Chirag Dave, and Dave Cramer
Ngày phát hành: 08 JAN 2026
Chuyên mục: Advanced (300), Amazon Aurora, Technical How-to
Các ứng dụng Java hiện đại sử dụng Amazon Aurora thường gặp khó khăn trong việc tận dụng tối đa các khả năng dựa trên đám mây của chúng. Mặc dù Aurora cung cấp các tính năng mạnh mẽ như chuyển đổi dự phòng nhanh, hỗ trợ xác thực AWS Identity and Access Management (IAM) và tích hợp AWS Secrets Manager, các trình điều khiển JDBC tiêu chuẩn không được thiết kế với các tính năng dành riêng cho đám mây. Đây không phải là một hạn chế của các trình điều khiển mã nguồn mở; chúng xuất sắc trong những gì chúng được thiết kế và tập trung vào các tiêu chuẩn cơ sở dữ liệu hơn là các tối ưu hóa dựa trên đám mây.
Khi Aurora chuyển đổi dự phòng trong vài giây, các trình điều khiển JDBC tiêu chuẩn có thể mất tới một phút để kết nối lại do độ trễ lan truyền DNS. Mặc dù Aurora hỗ trợ các tính năng mạnh mẽ như xác thực IAM và tích hợp Secrets Manager, việc triển khai các tính năng này với các trình điều khiển JDBC tiêu chuẩn đòi hỏi mã tùy chỉnh phức tạp và xử lý lỗi—sự phức tạp mà AWS Advanced JDBC Wrapper loại bỏ.
Bài đăng trên blog này chỉ cho các nhà phát triển Java cách nâng cao một ứng dụng hiện có sử dụng trình điều khiển JDBC tiêu chuẩn mã nguồn mở với bộ kết nối HikariCP bằng cách thêm AWS Advanced JDBC Wrapper (JDBC Wrapper), mở khóa các khả năng của Aurora và AWS Cloud với những thay đổi mã tối thiểu. Cách tiếp cận này bảo toàn tất cả các lợi ích của trình điều khiển PostgreSQL hiện có của bạn trong khi thêm các tính năng dựa trên đám mây. Bài đăng cũng trình bày một trong những tính năng mạnh mẽ của JDBC Wrapper: chia tách đọc/ghi.
Tổng quan giải pháp
JDBC Wrapper là một wrapper thông minh giúp nâng cao trình điều khiển JDBC hiện có của bạn với các khả năng của Aurora và AWS Cloud. Wrapper có thể biến trình điều khiển PostgreSQL, MySQL hoặc MariaDB tiêu chuẩn của bạn thành một giải pháp sẵn sàng cho sản xuất, nhận biết đám mây. Các nhà phát triển có thể áp dụng JDBC Wrapper để tận dụng các khả năng sau:
- Chuyển đổi dự phòng nhanh vượt qua giới hạn DNS – JDBC Wrapper duy trì bộ nhớ đệm thời gian thực về cấu trúc liên kết cụm Aurora của bạn và vai trò chính hoặc bản sao của mỗi phiên bản cơ sở dữ liệu thông qua các truy vấn trực tiếp tới Aurora. Điều này bỏ qua hoàn toàn độ trễ DNS, cho phép kết nối ngay lập tức với phiên bản chính mới trong quá trình chuyển đổi dự phòng.
- Xác thực AWS liền mạch – Aurora hỗ trợ xác thực cơ sở dữ liệu IAM, nhưng việc triển khai theo cách truyền thống đòi hỏi mã tùy chỉnh để tạo token, xử lý hết hạn và quản lý gia hạn. JDBC Wrapper tự động xử lý toàn bộ vòng đời xác thực IAM.
- Hỗ trợ Secrets Manager tích hợp sẵn – Tích hợp Secrets Manager tự động truy xuất thông tin đăng nhập cơ sở dữ liệu. Ứng dụng của bạn không cần biết mật khẩu thực tế—trình điều khiển xử lý mọi thứ ở chế độ nền.
- Xác thực liên kết – Cho phép truy cập cơ sở dữ liệu bằng cách sử dụng thông tin đăng nhập của tổ chức thông qua Microsoft Active Directory Federation Services hoặc Okta.
- Chia tách đọc/ghi bằng cách kiểm soát kết nối – Bạn có thể tối đa hóa hiệu suất Aurora bằng cách định tuyến các hoạt động ghi tới phiên bản chính và phân phối các hoạt động đọc trên các bản sao Aurora.
Lưu ý: Tính năng chia tách đọc/ghi yêu cầu các nhà phát triển phải gọi rõ ràngsetReadOnly(true)trên các kết nối cho các hoạt động đọc. Trình điều khiển không tự động phân tích cú pháp các truy vấn để xác định các hoạt động đọc so với ghi. KhisetReadOnly(true)được gọi, tất cả các câu lệnh tiếp theo được thực thi trên kết nối đó sẽ được định tuyến tới các bản sao cho đến khisetReadOnly(false)được gọi. Tính năng này được khám phá chi tiết hơn trong bài đăng này.
Bài đăng này sẽ hướng dẫn bạn qua một quá trình chuyển đổi thực tế của ứng dụng Java bằng JDBC Wrapper. Bạn sẽ thấy một ứng dụng Java hiện có phát triển qua ba giai đoạn tiến bộ:
- Giai đoạn 1: Trình điều khiển JDBC tiêu chuẩn (cơ sở) – Ứng dụng kết nối trực tiếp với điểm cuối ghi của Aurora thông qua trình điều khiển JDBC tiêu chuẩn, với tất cả các hoạt động sử dụng một phiên bản cơ sở dữ liệu duy nhất và dựa vào chuyển đổi dự phòng dựa trên DNS.
- Giai đoạn 2: JDBC Wrapper với chuyển đổi dự phòng nhanh – Ứng dụng sử dụng JDBC Wrapper để duy trì bộ nhớ đệm cấu trúc liên kết nội bộ của cụm Aurora, cho phép chuyển đổi dự phòng nhanh thông qua khám phá phiên bản trực tiếp trong khi vẫn định tuyến tất cả các hoạt động thông qua điểm cuối ghi.
- Giai đoạn 3: Chia tách đọc/ghi – Ứng dụng sử dụng tính năng chia tách đọc/ghi của JDBC Wrapper để gửi các hoạt động ghi tới phiên bản ghi của Aurora và phân phối các hoạt động đọc trên các phiên bản đọc của Aurora, tối ưu hóa hiệu suất thông qua cân bằng tải tự động.
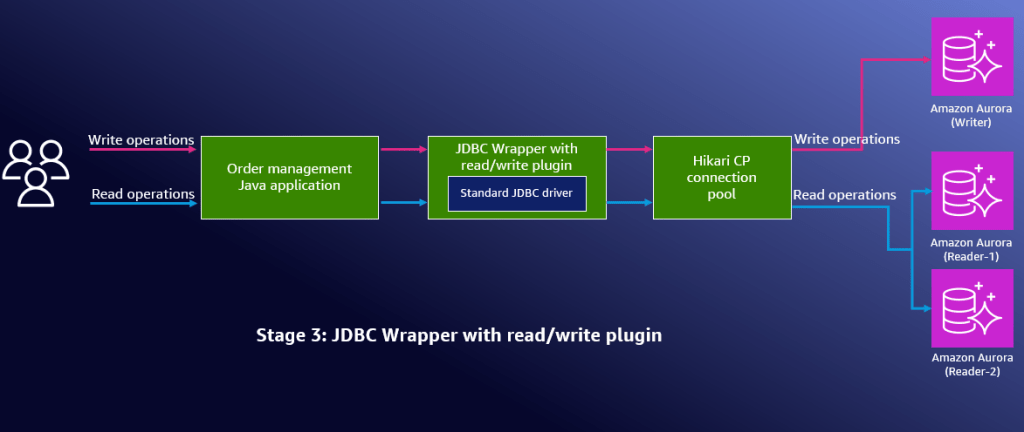
Hình 1: Sơ đồ kiến trúc hiển thị cấu hình Giai đoạn 3 với tính năng chia tách đọc/ghi được bật
Điều kiện tiên quyết
Bạn phải có những điều sau đây để triển khai giải pháp của bài đăng này:
- Một tài khoản AWS có quyền tạo các cụm Aurora
- Một máy dựa trên Linux với phần mềm sau được cài đặt để chạy ứng dụng demo có thể kết nối với cụm Aurora:
- AWS CLI phiên bản 2 được cấu hình với thông tin đăng nhập của bạn
- Java Development Kit 8 trở lên
- Gradle 8.14 trở lên
Các tùy chọn thiết lập hạ tầng
- Tùy chọn A: Hạ tầng dưới dạng mã với AWS Cloud Development Kit (AWS CDK) (được khuyến nghị)
- Yêu cầu bổ sung: Node.js 20 trở lên, Maven 3.6 trở lên
- AWS CDK v2 đã cài đặt và cấu hình:
- Cài đặt:
npm install -g aws-cdk(Hướng dẫn bắt đầu với AWS CDK) - Bootstrap:
cdk bootstrap(Hướng dẫn dành cho nhà phát triển AWS CDK)
- Cài đặt:
- Quyền IAM: Thông tin đăng nhập AWS của bạn cần các quyền được chỉ định trong iam-policy-cdk.json
- Tùy chọn B: Thiết lập thủ công
- Cụm Aurora: Tạo một cụm Aurora với ít nhất một bản sao đọc
- Nhóm bảo mật: Mở cổng 5432 từ máy nơi bạn đã sao chép kho lưu trữ.
Triển khai giải pháp
Thiết lập môi trường phát triển
Trong phần này, bạn sẽ sao chép kho lưu trữ mẫu và kiểm tra ứng dụng quản lý đơn hàng Java sử dụng HikariCP connection pooling với trình điều khiển JDBC PostgreSQL tiêu chuẩn.
Sao chép kho lưu trữ GitHub bằng cách sử dụng mã sau:
git clone https://github.com/aws-samples/sample-aws-advanced-jdbc-wrapper-demo.git
cd sample-aws-advanced-jdbc-wrapper-demoỨng dụng demo mô phỏng một hệ thống quản lý đơn hàng thực tế cung cấp năng lượng cho một cửa hàng trực tuyến nơi khách hàng đặt hàng, nhân viên cập nhật trạng thái đơn hàng và quản lý tạo báo cáo bán hàng. Kịch bản này chứng minh thách thức của khối lượng công việc cơ sở dữ liệu hỗn hợp: Một số hoạt động ghi nặng cần tính nhất quán ngay lập tức như xử lý thanh toán, nhưng các hoạt động đọc nặng khác sử dụng bản sao đọc có thể chấp nhận độ trễ nhỏ như khi tạo báo cáo bán hàng.
Kho lưu trữ có cấu trúc sau:

Bây giờ bạn đã có mã ứng dụng demo cục bộ và hiểu cấu trúc của nó như một hệ thống quản lý đơn hàng Java điển hình sử dụng HikariCP và trình điều khiển JDBC PostgreSQL tiêu chuẩn, bước tiếp theo là tạo cơ sở hạ tầng cơ sở dữ liệu Aurora mà ứng dụng sẽ kết nối.
Triển khai hạ tầng cơ sở dữ liệu
Bạn sẽ tạo một cụm Aurora với hai bản sao đọc bằng cách sử dụng một tập lệnh tự động sử dụng hạ tầng dưới dạng mã với AWS CDK. Hai bản sao đọc là cần thiết để chứng minh khả năng chia tách đọc/ghi của AWS Advanced JDBC Wrapper—chúng cung cấp các phiên bản riêng biệt để định tuyến các hoạt động đọc trong khi phiên bản chính xử lý các hoạt động ghi. Nếu bạn chọn không sử dụng tập lệnh được cung cấp, bạn có thể tạo cụm thủ công thông qua AWS Management Console.
Ghi đè các giá trị mặc định bằng .env (Tùy chọn)
Bạn có thể ghi đè các cài đặt mặc định bằng cách tạo tệp .env nếu bạn cần sử dụng các tài nguyên AWS hiện có (như một VPC hoặc nhóm bảo mật cụ thể) hoặc muốn tùy chỉnh tên tài nguyên. Nếu bạn không muốn sử dụng cơ sở hạ tầng AWS hiện có, bạn có thể bỏ qua bước này và sử dụng các giá trị mặc định.
cp .env.example .env
# Edit the .env file with your AWS resource values, if needed
# Aurora cluster name (default: demo-app)
# AURORA_CLUSTER_ID=demo-app
# Database username (default: postgres)
# AURORA_DB_USERNAME=postgres
# Database name (default: postgres)
# AURORA_DB_NAME=postgres
# AWS Region (default: AWS CLI configures the Region)
# AWS_REGION=us-east-1
# Existing VPC ID (default: the CDK creates a new VPC)
# AWS_VPC_ID=vpc-xxxxxxxxx
# Existing security group (default: the CDK creates a new security group with port 5432 open)
# AWS_SECURITY_GROUP_ID=sg-xxxxxxxxx
# Existing subnet group (default: the CDK creates a new subnet group)
# AWS_DB_SUBNET_GROUP_NAME=existing-subnet-groupTạo một cụm Aurora
Chạy tập lệnh thiết lập để tạo một cụm Aurora với hai phiên bản đọc và phiên bản ghi:
# Set up the Aurora cluster with your configuration
./setup-aurora-cdk.shBạn sẽ thấy đầu ra sau khi tạo cụm thành công:
==================================================
📋 Connection details:
==================================================
Writer endpoint: aurora-jdbc-demo.cluster-abc123.us-east-1.rds.amazonaws.com
Reader endpoint: aurora-jdbc-demo.cluster-ro-abc123.us-east-1.rds.amazonaws.com
Username: postgres
Database: postgres
Port: 5432
Region: us-east-1
📝 Next steps:
1. ✅ application.properties has been updated automatically
2. Set up database password environment variable (see next section)
3. Run the demo: ./gradlew clean run
🧹 To clean up resources later:
cd infrastructure/cdk && cdk destroyThiết lập thuộc tính ứng dụng
Tệp thuộc tính ứng dụng chứa các chi tiết kết nối cơ sở dữ liệu mà ứng dụng Java của bạn sử dụng để kết nối với cụm Aurora.
Nếu bạn đã tạo cụm bằng cách sử dụng tập lệnh AWS CDK được cung cấp (tùy chọn A), tập lệnh sẽ tự động tạo và cấu hình src/main/resources/application.properties với các chi tiết kết nối Aurora của bạn. Do đó, bạn không cần tạo hoặc cấu hình tệp thuộc tính ứng dụng vì tập lệnh đã làm điều này cho bạn.
Đối với thiết lập thủ công (tùy chọn B), hãy tạo và cấu hình tệp thuộc tính ứng dụng:
cp src/main/resources/application.properties.example src/main/resources/application.properties
# Edit application.properties with your Aurora connection detailsThiết lập mật khẩu cơ sở dữ liệu
Nếu bạn đã tạo cơ sở hạ tầng bằng cách sử dụng tập lệnh AWS CDK được cung cấp (tùy chọn A): Tập lệnh AWS CDK tự động tạo mật khẩu an toàn và lưu trữ nó trong Secrets Manager. Thiết lập biến môi trường mật khẩu cơ sở dữ liệu bằng cách sử dụng các lệnh sau:
# Get your current AWS Region and the secret ARN from the AWS CDK deployment
AWS_REGION=$(aws configure get region)
SECRET_ARN=$(aws cloudformation describe-stacks --stack-name aws-jdbc-driver-stack --region $AWS_REGION --query "Stacks[0].Outputs[?OutputKey=='SecretArn'].OutputValue" --output text) export DB_PASSWORD=$(aws secretsmanager get-secret-value --secret-id "$SECRET_ARN" --region $AWS_REGION --query SecretString --output text | jq -r .password)Nếu bạn đã sử dụng thiết lập thủ công (tùy chọn B):
Chạy lệnh này để đặt mật khẩu bạn đã chỉ định khi tạo cụm Aurora của mình:
export DB_PASSWORD=<your_database_password>
Bây giờ bạn đã triển khai thành công cụm Aurora của mình với các bản sao đọc và cấu hình các thuộc tính ứng dụng và mật khẩu cơ sở dữ liệu, bước tiếp theo là kiểm tra ứng dụng trong ba giai đoạn tiến bộ chứng minh các khả năng của AWS Advanced JDBC Wrapper.
Cấu hình ứng dụng với JDBC Wrapper
Phần này bao gồm ba giai đoạn tiến bộ của việc cấu hình ứng dụng Java của bạn với JDBC Wrapper:
- Giai đoạn 1: Trình điều khiển JDBC tiêu chuẩn (cơ sở) – Chạy ứng dụng với trình điều khiển JDBC PostgreSQL tiêu chuẩn.
- Giai đoạn 2: JDBC Wrapper với chuyển đổi dự phòng nhanh – Cấu hình JDBC Wrapper với khả năng chuyển đổi dự phòng nhanh.
- Giai đoạn 3: Chia tách đọc/ghi – Bật chia tách đọc/ghi để phân phối các hoạt động đọc trên các bản sao Aurora.
Giai đoạn 1: Trình điều khiển JDBC tiêu chuẩn (cơ sở)
Bạn sẽ chạy ứng dụng bằng cách sử dụng trình điều khiển JDBC PostgreSQL tiêu chuẩn để thiết lập một đường cơ sở trước khi nâng cao nó với các khả năng của JDBC Wrapper. Thực thi ứng dụng để quan sát hành vi JDBC tiêu chuẩn:
./gradlew clean run
Sau đây là đầu ra mẫu:
Task :run
INFO com.zaxxer.hikari.HikariDataSource - StandardPostgresPool - Starting...
INFO com.example.config.DatabaseConfig - Standard JDBC connection pool initialized
=== PERFORMING WRITE OPERATIONS ===
INFO com.example.dao.OrderDAO - WRITE OPERATION: Creating new order for customer: John Doe
INFO com.example.dao.OrderDAO - Connection URL:
→ WRITER: jdbc:postgresql://aurora-jdbc-demo.cluster-xxxxxxx.us-east-1.rds.amazonaws.com:5432/postgres
INFO com.example.dao.OrderDAO - Order created with ID: 1
=== PERFORMING READ OPERATIONS ===
INFO com.example.dao.OrderDAO - READ OPERATION: Getting order history
INFO com.example.dao.OrderDAO - Connection URL:
→ WRITER: jdbc:postgresql://aurora-jdbc-demo.cluster-xxxxxxx.us-east-1.rds.amazonaws.com:5432/postgres
INFO com.example.dao.OrderDAO - Found 4 orders
INFO com.example.Application - Retrieved 4 total orders
BUILD SUCCESSFUL in 2sLưu ý trong đầu ra rằng cả hoạt động ghi (tạo đơn hàng) và hoạt động đọc (lấy lịch sử đơn hàng) đều hiển thị cùng một mẫu URL kết nối: → WRITER jdbc:postgresql://aurora-jdbc-demo.cluster-xxxxxxx. Điều này chứng minh hành vi JDBC tiêu chuẩn trong đó tất cả các hoạt động cơ sở dữ liệu được định tuyến đến điểm cuối ghi của Aurora, nghĩa là cả hoạt động giao dịch và truy vấn phân tích đều cạnh tranh cho cùng một tài nguyên ghi—vấn đề chính xác mà tính năng chia tách đọc/ghi của AWS Advanced JDBC Wrapper sẽ giải quyết trong các bước tiếp theo.
Bây giờ bạn đã thiết lập một đường cơ sở với trình điều khiển JDBC tiêu chuẩn và quan sát cách tất cả các hoạt động được định tuyến đến điểm cuối ghi của Aurora, bước tiếp theo là cấu hình ứng dụng để sử dụng JDBC Wrapper trong khi duy trì cùng chức năng nhưng thêm các khả năng đám mây như chuyển đổi dự phòng nhanh.
Giai đoạn 2: JDBC Wrapper với tính năng chuyển đổi dự phòng nhanh
Bây giờ, hãy chuyển đổi ứng dụng này để sử dụng JDBC Wrapper trong khi duy trì cùng chức năng nhưng thêm các khả năng như chuyển đổi dự phòng nhanh. Bạn sẽ sử dụng một tập lệnh để tự động áp dụng các thay đổi cần thiết để nâng cấp ứng dụng JDBC tiêu chuẩn của bạn với các tính năng của Aurora và AWS Cloud. Trước khi chạy tập lệnh, hãy kiểm tra những thay đổi nào là cần thiết để ứng dụng sử dụng JDBC Wrapper:
Tệp build.gradle (Trước khi cấu hình để sử dụng JDBC Wrapper):
dependencies {
implementation 'com.zaxxer:HikariCP:5.0.1'
implementation 'org.postgresql:postgresql:42.6.0'
implementation 'ch.qos.logback:logback-classic:1.4.11'
implementation 'org.slf4j:slf4j-api:2.0.9'
compileOnly 'org.projectlombok:lombok:1.18.30'
annotationProcessor 'org.projectlombok:lombok:1.18.30'
}Cấu hình sau đây hiển thị các thay đổi cần thiết để sử dụng các khả năng của JDBC Wrapper. Tệp build.gradle (Sau khi cấu hình để sử dụng JDBC Wrapper):
Tệp build.gradle (Sau khi cấu hình để sử dụng JDBC Wrapper):
dependencies {
implementation 'com.zaxxer:HikariCP:5.0.1'
implementation 'org.postgresql:postgresql:42.6.0'
implementation 'software.amazon.jdbc:aws-advanced-jdbc-wrapper:2.5.6’ // ← Add this
implementation 'ch.qos.logback:logback-classic:1.4.11'
implementation 'org.slf4j:slf4j-api:2.0.9'
compileOnly 'org.projectlombok:lombok:1.18.30'
annotationProcessor 'org.projectlombok:lombok:1.18.30'
}Thay đổi này thêm thư viện AWS Advanced JDBC Wrapper (software.amazon.jdbc:aws-advanced-jdbc-wrapper:2.5.6) cùng với trình điều khiển PostgreSQL hiện có (org.postgresql:postgresql:42.6.0). Wrapper hoạt động như một lớp trung gian chặn các lệnh gọi cơ sở dữ liệu, thêm các khả năng cụ thể, sau đó ủy quyền các hoạt động SQL thực tế cho trình điều khiển PostgreSQL.
Ngoài các thay đổi mã ở trên, bạn cũng cần cập nhật URL JDBC trong tệp application.properties, chứa các cài đặt kết nối cơ sở dữ liệu. Cấu hình sau đây minh họa cấu hình hiện tại với JDBC tiêu chuẩn:
Trước khi cấu hình để sử dụng JDBC Wrapper:
db.url=jdbc:postgresql://aurora-jdbc-demo.cluster-abc123.us-east-1.rds.amazonaws.com:5432/postgres
Cấu hình sau đây hiển thị thay đổi cần thiết với JDBC Wrapper:
db.url=jdbc:aws-wrapper:postgresql://aurora-jdbc-demo.cluster-abc123.us-east-1.rds.amazonaws.com:5432/postgresTiền tố aws-wrapper: cho trình quản lý trình điều khiển biết rằng sẽ sử dụng các khả năng của JDBC Wrapper.
Tệp DatabaseConfig.java cập nhật cấu hình kết nối. Mã sau đây minh họa cấu hình hiện tại với JDBC tiêu chuẩn:
Trước khi cấu hình để sử dụng JDBC Wrapper:
// Standard JDBC configuration
configuredJdbcUrl = props.getProperty("db.url");
config.setJdbcUrl(configuredJdbcUrl);
config.setUsername(props.getProperty("db.username"));
config.setPassword(props.getProperty("db.password"));
config.setPoolName("StandardPostgresPool");
log.info("Standard JDBC connection pool initialized");Mã sau đây hiển thị thay đổi cần thiết với JDBC Wrapper:
// JDBC Wrapper configuration
configuredJdbcUrl = props.getProperty("db.url");
config.setDataSourceClassName("software.amazon.jdbc.ds.AwsWrapperDataSource"); config.addDataSourceProperty("jdbcUrl", configuredJdbcUrl); config.addDataSourceProperty("targetDataSourceClassName", "org.postgresql.ds.PGSimpleDataSource");
Properties targetProps = new Properties();
targetProps.setProperty("user", props.getProperty("db.username"));
targetProps.setProperty("password", props.getProperty("db.password"));
targetProps.setProperty("wrapperPlugins", "failover"); // ← Enables fast failover
config.addDataSourceProperty("targetDataSourceProperties", targetProps);
config.setPoolName("AWSJDBCPool");
log.info("JDBC Wrapper connection pool initialized");Mã trước đó chuyển từ cấu hình URL JDBC trực tiếp sang sử dụng JDBC Wrapper. Điều này cho phép các khả năng chuyển đổi dự phòng nhanh và hỗ trợ các tính năng nâng cao như chia tách đọc/ghi và xác thực IAM. Trong khi thêm các khả năng đám mây này, wrapper vẫn ủy quyền tất cả các hoạt động cơ sở dữ liệu thực tế cho trình điều khiển PostgreSQL cơ bản. Điều này mang lại cho bạn các tính năng đám mây của Aurora mà không cần thay đổi logic nghiệp vụ của ứng dụng.
Chạy tập lệnh sau để áp dụng tất cả các thay đổi trên và sau đó thực thi ứng dụng:
./demo.sh aws-jdbc-wrapper
Tập lệnh trước đó thực hiện các thay đổi của JDBC Wrapper và chạy ứng dụng Java. Bạn sẽ thấy cùng một đầu ra như trước, nhưng bây giờ nó bao gồm các khả năng của JDBC Wrapper:
Running application...
> Task :run
16:22:18.954 [main] INFO com.zaxxer.hikari.HikariDataSource - AWSJDBCPool - Starting...
16:22:19.632 [main] INFO com.zaxxer.hikari.pool.HikariPool - AWSJDBCPool - Added connection software.amazon.jdbc.wrapper.ConnectionWrapper@770d3326 - org.postgresql.jdbc.PgConnection@4cc8eb05
16:22:19.634 [main] INFO com.zaxxer.hikari.HikariDataSource - AWSJDBCPool - Start completed.
16:22:19.634 [main] INFO com.example.config.DatabaseConfig - AWS JDBC Wrapper connection pool initialized
=== WRITE OPERATIONS ===
16:22:19.661 [main] INFO com.example.dao.OrderDAO - WRITE OPERATION: Creating new order for customer: John Doe
16:22:19.665 [main] INFO com.example.dao.OrderDAO - Connection URL:
→ WRITER: jdbc:postgresql://aurora-jdbc-demo4.cluster-curzkcvul3uv.us-east-1.rds.amazonaws.com:5432/postgres
16:22:19.684 [main] INFO com.example.dao.OrderDAO - Order created with ID: 13
=== READ OPERATIONS ===
16:22:19.706 [main] INFO com.example.dao.OrderDAO - READ OPERATION: Getting order history
16:22:19.708 [main] INFO com.example.dao.OrderDAO - Connection URL:
→ WRITER: jdbc:postgresql://aurora-jdbc-demo4.cluster-curzkcvul3uv.us-east-1.rds.amazonaws.com:5432/postgres
16:22:19.714 [main] INFO com.example.dao.OrderDAO - Found 16 ordersLưu ý rằng tên connection pool đã thay đổi từ StandardPostgresPool thành AWSJDBCPool, và log hiển thị “AWS JDBC Wrapper connection pool initialized”, xác nhận rằng ứng dụng hiện đang sử dụng JDBC Wrapper. Loại kết nối hiển thị software.amazon.jdbc.wrapper.ConnectionWrapper bao bọc org.postgresql.jdbc.PgConnection bên dưới, chứng minh rằng wrapper đang chặn các lệnh gọi cơ sở dữ liệu trong khi ủy quyền cho trình điều khiển PostgreSQL.
Các hoạt động vẫn sử dụng điểm cuối ghi của Aurora, nhưng bây giờ ứng dụng của bạn có khả năng chuyển đổi dự phòng nhanh mà không cần bạn thực hiện bất kỳ thay đổi logic nghiệp vụ nào.
Bây giờ bạn đã cấu hình thành công ứng dụng để sử dụng JDBC Wrapper với khả năng chuyển đổi dự phòng nhanh trong khi duy trì tất cả các hoạt động trên điểm cuối ghi của Aurora, bước tiếp theo là cấu hình chia tách đọc/ghi để phân phối các hoạt động đọc trên các bản sao Aurora và tối ưu hóa hiệu suất.
Giai đoạn 3: Bật chia tách đọc/ghi
Bây giờ hãy triển khai khả năng đọc/ghi của JDBC Wrapper bằng cách bật định tuyến kết nối. Với định tuyến kết nối, các hoạt động ghi sẽ đi đến phiên bản chính và các hoạt động đọc được phân phối trên các bản sao Aurora dựa trên các chiến lược lựa chọn trình đọc như roundRobin và fastestResponse. Để biết thông tin cấu hình chi tiết, hãy xem Reader Selection Strategies.
Cân nhắc về hiệu suất với HikariCP khi sử dụng JDBC Wrapper
Ứng dụng demo sử dụng HikariCP connection pooling bên ngoài để minh họa nhiều trường hợp sử dụng. Tuy nhiên, đối với các ứng dụng sản xuất với các hoạt động đọc/ghi thường xuyên, nên sử dụng internal connection pooling của JDBC Wrapper. JDBC wrapper hiện đang sử dụng HikariCP để tạo và duy trì các connection pool nội bộ của nó.
Để có một ví dụ toàn diện với kiểm tra hiệu suất sử dụng các pool nội bộ và bên ngoài và so sánh với không chia tách đọc/ghi, hãy xem ví dụ ReadWriteSplittingSample.java, minh họa ba cách tiếp cận.
Cân nhắc về Spring Boot/Framework
Nếu bạn đang sử dụng Spring Boot/Framework, hãy lưu ý đến các tác động về hiệu suất khi sử dụng tính năng chia tách đọc/ghi. Ví dụ, chú thích @Transactional(readOnly = true) có thể gây suy giảm hiệu suất đáng kể do việc chuyển đổi liên tục giữa các kết nối đọc và ghi. Để biết thông tin chi tiết về những cân nhắc này và các giải pháp được khuyến nghị, hãy xem Limitations when using Spring Boot/Framework.
Các thay đổi cần thiết để sử dụng chia tách đọc/ghi
Hãy xem xét các thay đổi cần thiết để sử dụng chia tách đọc/ghi. Tệp DatabaseConfig.java thêm plugin readWriteSplitting.
Mã sau đây hiển thị cấu hình JDBC Wrapper hiện có với chuyển đổi dự phòng:
targetProps.setProperty("wrapperPlugins", "failover");Mã được cập nhật để cho phép sử dụng chia tách đọc/ghi là:
targetProps.setProperty("wrapperPlugins", "readWriteSplitting,failover");Tệp OrderDAO.java đánh dấu các kết nối là chỉ đọc để cho phép định tuyến đến các phiên bản đọc:
conn.setReadOnly(true); // Enable read/write splitting for this connection
Note: When `setReadOnly(true) is called, the connection allows read-only operations ONLY. Write operations (INSERT, UPDATE, DELETE) will fail on this connection. To perform write operations through this connection, you must call setReadOnly(false)” Now, run the read/write splitting configuration: `./demo.sh read-write-splittingBây giờ, hãy chạy cấu hình chia tách đọc/ghi:
./demo.sh read-write-splittingSau đây là đầu ra mẫu sau khi chạy cấu hình:
Running application...
> Task :run
16:51:18.705 [main] INFO com.zaxxer.hikari.HikariDataSource - AWSJDBCReadWritePool - Starting...
16:51:19.405 [main] INFO com.example.config.DatabaseConfig - AWS JDBC Wrapper with Read/Write Splitting initialized
=== PERFORMING WRITE OPERATIONS ===
16:51:19.434 [main] INFO com.example.dao.OrderDAO - WRITE OPERATION: Creating new order for customer: John Doe
16:51:19.437 [main] INFO com.example.dao.OrderDAO - Connection URL:
→ WRITER: jdbc:postgresql://aurora-jdbc-demo4.cluster-curzkcvul3uv.us-east-1.rds.amazonaws.com:5432/postgres
16:51:19.456 [main] INFO com.example.dao.OrderDAO - Order created with ID: 17
16:51:19.469 [main] INFO com.example.dao.OrderDAO - WRITE OPERATION: Updating order 1 status to SHIPPED
16:51:19.469 [main] INFO com.example.dao.OrderDAO - Connection URL:
→ WRITER: jdbc:postgresql://aurora-jdbc-demo4.cluster-curzkcvul3uv.us-east-1.rds.amazonaws.com:5432/postgres
16:51:19.474 [main] INFO com.example.dao.OrderDAO - Updated 1 order(s)
=== PERFORMING READ OPERATIONS ===
16:51:19.477 [main] INFO com.example.dao.OrderDAO - READ OPERATION: Getting order history
16:51:20.044 [main] INFO com.example.dao.OrderDAO - Connection URL:
→ READER: jdbc:postgresql://aurora-jdbc-reader-2.curzkcvul3uv.us-east-1.rds.amazonaws.com:5432/postgres
16:51:20.051 [main] INFO com.example.dao.OrderDAO - Found 20 orders
16:51:20.052 [main] INFO com.example.dao.OrderDAO - READ OPERATION: Generating sales report
16:51:20.285 [main] INFO com.example.dao.OrderDAO - Connection URL:
→ READER: jdbc:postgresql://aurora-jdbc-reader-2.curzkcvul3uv.us-east-1.rds.amazonaws.com:5432/postgres
16:51:20.285 [main] INFO com.example.dao.OrderDAO - Sales report generated: {totalOrders=20, totalRevenue=8150.0}
16:51:20.286 [main] INFO com.example.dao.OrderDAO - READ OPERATION: Searching orders for customer: John
16:51:20.287 [main] INFO com.example.dao.OrderDAO - Connection URL:
→ READER: jdbc:postgresql://aurora-jdbc-reader-2.curzkcvul3uv.us-east-1.rds.amazonaws.com:5432/postgres
16:51:20.353 [main] INFO com.example.dao.OrderDAO - Found 10 orders for customer: John
BUILD SUCCESSFUL in 3sJDBC Wrapper hiện định tuyến các hoạt động ghi tới điểm cuối ghi của Aurora (phiên bản chính) và các hoạt động đọc tới các điểm cuối đọc của Aurora (các phiên bản bản sao). Plugin chia tách đọc/ghi mang lại các lợi ích sau:
- Quản lý kết nối đơn giản hóa – Bạn không cần quản lý các connection pool riêng biệt cho các kết nối đọc và ghi trong ứng dụng của mình. Chỉ bằng cách đặt phương thức
Connection#setReadOnly()trong ứng dụng, JDBC Wrapper sẽ tự động quản lý các kết nối. - Các chiến lược lựa chọn trình đọc linh hoạt – Chọn từ nhiều chiến lược lựa chọn trình đọc như
roundRobin,fastestResponsehoặcleast connectionsđể tối ưu hóa hiệu suất dựa trên các yêu cầu ứng dụng và mẫu khối lượng công việc cụ thể của bạn. - Giảm tải cho trình ghi – Các truy vấn phân tích không còn cạnh tranh với các giao dịch.
- Sử dụng tài nguyên tốt hơn – Lưu lượng đọc được phân phối trên nhiều bản sao, cho phép mỗi phiên bản Aurora phục vụ khối lượng công việc tối ưu của nó mà không yêu cầu thay đổi logic ứng dụng.
Dọn dẹp
Để tránh phát sinh chi phí trong tương lai, hãy xóa các tài nguyên đã tạo trong quá trình hướng dẫn này.
Nếu bạn đã sử dụng tập lệnh AWS CDK (Tùy chọn A):
Chạy các lệnh sau để xóa tất cả các tài nguyên AWS:
# Navigate to the CDK directory
cd infrastructure/cdk
# Destroy the stack and all resources
cdk destroyNếu bạn đã tạo tài nguyên thủ công (Tùy chọn B): Xóa cụm Aurora và bất kỳ tài nguyên liên quan nào (nhóm bảo mật, nhóm mạng con DB) bằng phương pháp bạn đã sử dụng để tạo chúng—thông qua AWS Management Console hoặc AWS CLI.
Kết luận
Bài đăng này đã chỉ ra cách bạn có thể nâng cao ứng dụng Java của mình với các khả năng dựa trên đám mây của Aurora bằng cách sử dụng JDBC Wrapper. Các thay đổi mã đơn giản được chia sẻ trong bài đăng này có thể biến một ứng dụng JDBC tiêu chuẩn để sử dụng chuyển đổi dự phòng nhanh, chia tách đọc/ghi, xác thực IAM, tích hợp Secrets Manager và xác thực liên kết.
Về tác giả

Ramesh Eega
Ramesh là Kiến trúc sư Giải pháp Tài khoản Toàn cầu có trụ sở tại Atlanta, GA. Anh ấy đam mê giúp đỡ khách hàng trong suốt hành trình đám mây của họ.

Chirag Dave
Chirag là Kiến trúc sư Giải pháp Chính tại Amazon Web Services, tập trung vào PostgreSQL được quản lý. Anh ấy duy trì mối quan hệ kỹ thuật với khách hàng, đưa ra các khuyến nghị về bảo mật, chi phí, hiệu suất, độ tin cậy, hiệu quả hoạt động và kiến trúc thực hành tốt nhất.

Dave Cramer
Dave là Kỹ sư Phần mềm Cấp cao tại Amazon Web Services. Anh ấy cũng là một người đóng góp chính cho PostgreSQL với tư cách là người duy trì trình điều khiển PostgreSQL JDBC. Niềm đam mê của anh ấy là giao diện máy khách và làm việc với máy khách.
