Tác giả: Aashraya Sachdeva và Shibu Jacob
Ngày phát hành: 08 JAN 2026
Chuyên mục: Amazon SageMaker, Amazon SageMaker AI, Intermediate (200)
Bài viết này được đồng tác giả bởi Aashraya Sachdeva từ Observe.ai.
Bạn có thể sử dụng Amazon SageMaker để xây dựng, huấn luyện và triển khai các mô hình Machine Learning (ML), bao gồm các mô hình ngôn ngữ lớn (LLM) và các mô hình nền tảng (FM) khác. Điều này giúp bạn giảm đáng kể thời gian cần thiết cho một loạt các tác vụ phát triển AI tạo sinh và ML. Một chu trình phát triển AI/ML thường bao gồm các giai đoạn tiền xử lý dữ liệu, phát triển mô hình, huấn luyện, kiểm thử và triển khai. Bằng cách sử dụng SageMaker, các nhóm khoa học dữ liệu và kỹ sư ML của bạn có thể giảm bớt nhiều công việc nặng nhọc không phân biệt liên quan đến phát triển mô hình.
Mặc dù SageMaker có thể giúp các nhóm giảm bớt nhiều công việc nặng nhọc, các nhóm kỹ thuật vẫn phải sử dụng các bước thủ công để triển khai và tinh chỉnh các dịch vụ liên quan là một phần của các pipeline suy luận, chẳng hạn như hàng đợi và cơ sở dữ liệu. Ngoài ra, các nhóm phải kiểm thử nhiều loại phiên bản GPU để tìm ra sự cân bằng phù hợp giữa hiệu suất và chi phí.
Observe.ai cung cấp sản phẩm Conversation Intelligence (CI) tích hợp với các giải pháp Contact Center as a Service (CCaaS). Công cụ này phân tích các cuộc gọi theo thời gian thực và sau khi hoàn thành để kích hoạt các tính năng như tóm tắt cuộc gọi, phản hồi của nhân viên và trả lời tự động. Các tính năng Conversation Intelligence (CI) cần mở rộng quy mô từ các khách hàng có ít hơn 100 nhân viên đến các khách hàng có hàng nghìn nhân viên—tăng gấp mười lần về quy mô. Để hỗ trợ điều này, Observe.ai cần một cơ chế để tối ưu hóa cơ sở hạ tầng ML và chi phí phục vụ mô hình của họ. Nếu không có cơ chế như vậy, các nhà phát triển phải viết nhiều script kiểm thử và phát triển các pipeline kiểm thử cũng như hệ thống gỡ lỗi, điều này tiêu tốn rất nhiều thời gian.
Để giải quyết thách thức này, Observe.ai đã phát triển One Load Audit Framework (OLAF), tích hợp với SageMaker để xác định các nút thắt cổ chai và vấn đề hiệu suất trong các dịch vụ ML, cung cấp các phép đo độ trễ và thông lượng dưới cả tải dữ liệu tĩnh và động. Framework này cũng tích hợp liền mạch kiểm thử hiệu suất ML vào vòng đời phát triển phần mềm, tạo điều kiện thuận lợi cho việc cấp phát chính xác và tiết kiệm chi phí. Sử dụng OLAF, nhóm ML của Observe.AI đã có thể giảm thời gian kiểm thử từ một tuần xuống còn vài giờ. Điều này đã giúp Observe.AI tăng tần suất triển khai endpoint và số lượng khách hàng mới lên gấp nhiều lần. Tiện ích OLAF có sẵn trên GitHub và miễn phí sử dụng. Nó là mã nguồn mở và được phân phối theo giấy phép Apache 2.0.
Trong bài đăng trên blog này, bạn sẽ tìm hiểu cách sử dụng tiện ích OLAF để kiểm thử và xác thực endpoint SageMaker của mình.
Tổng quan giải pháp
Sau khi bạn đã triển khai mô hình của mình để suy luận và xác minh rằng nó chính xác về mặt chức năng, bạn sẽ muốn cải thiện hiệu suất của mô hình. Bước đầu tiên để làm điều này là kiểm thử tải endpoint suy luận. Bạn có thể sử dụng các số liệu kiểm thử tải để áp dụng các tối ưu hóa cho mô hình của mình, quyết định loại phiên bản GPU và tinh chỉnh pipeline ML để tăng hiệu suất mà không ảnh hưởng đến độ chính xác. Kiểm thử tải cần được lặp lại nhiều lần để đo lường tác động của bất kỳ tối ưu hóa nào. Để kiểm thử tải, bạn cần cấu hình các script kiểm thử tải để tích hợp với các API SageMaker có liên quan, trích xuất các số liệu như độ trễ, CPU và mức sử dụng bộ nhớ. Bạn cũng cần thiết lập một dashboard để xem kết quả kiểm thử tải và xuất các số liệu kiểm thử tải để phân tích thêm; và bạn cần một framework có thể cấu hình để áp dụng tải đồng thời cho endpoint.
OLAF hỗ trợ như thế nào
OLAF giúp bạn giảm bớt công việc nặng nhọc bằng cách cung cấp các yếu tố trên dưới dạng một package. OLAF được tích hợp với Locust, một framework kiểm thử tải, để cung cấp khả năng tạo tải đồng thời và một dashboard để xem kết quả khi quá trình kiểm thử diễn ra. OLAF tích hợp với API SageMaker để gọi API và trích xuất các số liệu để đo lường hiệu suất.
Trong giải pháp sau, bạn sẽ tìm hiểu cách triển khai OLAF trên máy trạm của mình dưới dạng một Docker container. Sử dụng giao diện người dùng thiết lập kiểm thử tải (như trong hình sau), cấu hình kiểm thử tải được cung cấp và framework OLAF sử dụng Boto3 SDK để đẩy các yêu cầu suy luận đến một endpoint suy luận SageMaker. OLAF giám sát độ trễ và các số liệu hiệu suất có sẵn bằng cách sử dụng dashboard báo cáo hiệu suất do OLAF cung cấp.
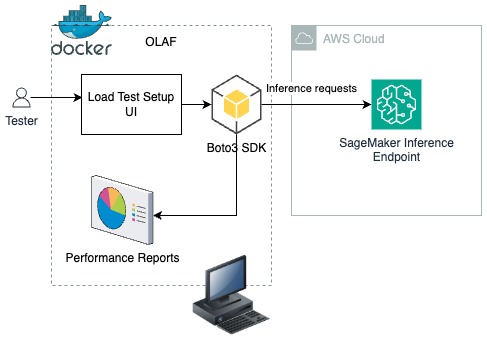
Điều kiện tiên quyết
Để thực hiện giải pháp này, bạn cần những điều sau:
- Một tài khoản AWS
- Docker được cài đặt trên máy trạm của bạn
- AWS Command Line Interface (AWS CLI) được cài đặt và cấu hình. Nếu bạn đang sử dụng thông tin xác thực dài hạn như khóa truy cập, hãy xem quản lý khóa truy cập cho người dùng IAM và bảo mật khóa truy cập để biết các phương pháp hay nhất. Bài đăng này sử dụng thông tin xác thực tạm thời ngắn hạn được tạo bởi AWS Security Token Service (AWS STS).
Tạo thông tin xác thực AWS của bạn bằng AWS STS
Để bắt đầu, hãy sử dụng AWS CLI để tạo thông tin xác thực của bạn.
Lưu ý: Đảm bảo rằng vai trò hoặc người dùng mà từ đó các khóa truy cập được tạo có quyền AmazonSageMakerFullAccess. Vai trò AWS CLI của bạn phải có chính sách tin cậy cần thiết để đảm nhận vai trò mà từ đó các khóa truy cập được tạo.
Lấy role-arn
Trong AWS CLI của bạn, nhập lệnh sau:
aws iam get-role --role-name sagemaker_role
Lệnh sẽ tạo ra đầu ra JSON bên dưới. role arn là giá trị trong thuộc tính arn trong JSON bên dưới.
{
"Role":{
"Path":"/",
"RoleName":"sagemaker_role",
"RoleId":"AROA123456789EXAMPLE",
"Arn":"arn:aws:iam::111122223333:role/sagemaker_role",
"CreateDate":"2025-12-05T13:02:33+00:00",
"AssumeRolePolicyDocument":{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Principal":{
"Service":"ec2.amazonaws.com"
},
"Action":"sts:AssumeRole"
}
]
},
"Description":"Allows EC2 instances to call AWS services on your behalf.",
"MaxSessionDuration":3600,
"RoleLastUsed":{
}
}
}
Chạy lệnh sau trong AWS CLI của bạn:
aws sts assume-role --role-arn <role arn to assume> --role-session-name <session name> --duration-seconds <timeout duration>
Đặt giá trị role arn từ bước trên vào đối số –role-arn.
Cung cấp giá trị olaf_session cho đối số —role-session-name và đặt giá trị tương đương với thời gian bạn mong đợi kiểm thử tải của mình sẽ chạy trong đối số –duration-seconds. Trong blog này, chúng tôi đặt nó ở 1800 giây, cho phép 30 phút kiểm thử tải.
- Lệnh assume-role sẽ tạo thông tin xác thực AWS tạm thời như sau:
{
"Credentials":{
"AccessKeyId":"ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey":"wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"SessionToken":"IQoJb3JpZ2luX2VjEJf//////////wEaCXVzLWVhc3QtMSJFMEMCIFdzSaxLya/E71xi2SeG8KFDF46DkxvsWt6Ih0I5X2I6Ah9FYGmWi3fnQfyPQWuzE0Co44xp+qOAxbfaHJ53OYbBKpkCCF8QARoMNjE1NTE1NDU5MjM5IgyoWu5a5DJX3BMn7LYq9gHiRr2sQvStZT9tvvdS8QFjTntBYFEkDL636Crj4xw5rDieBoYFB9h+ozSqMXOtze79DHQLyCduT+McWOlB9Ic5x/xtzPT9HZsfMaEMUOPgI9LtKWUK367rVdcqBV8HH8wOwUS9RhwIyXg2vsGa+WanaS8o6sO8PVkvqOs4ea3CFguncGgSqIftJvgMg0OswzkAoUKXG6jMwL3Ppu13Dg9NV3YKOsS80vejhEJ8QFiKiTsJKX2QmQz/wUN4DN83y8qeFfYEpuYC92oZzv2gErrsXqFd+7/+2w97mInPlD6g1tyd8FlGdXg821WckmwdPu7TYqsCR9kwiM3LyQY6nwFM3U7f/sCre28o2Js31dig0WHb1iv3nTR6m/bIKqsQL4EtYXPGjHD6Ifsf9nQYtkPQC/PqzXg7anx6Q6OW5CzVvk4xU/G9+HcCej84MutK/hQGp3xnRPuJvUIs/q/QlddURk/MFZW9X3njLCn89FRmJ/tI1Mzy/yctwgLcBetE7RIPgaM/90HNXp62vBMK0tzqR0orm6/7eOGV5DXaprQ=",
"Expiration":"2025-12-05T14:34:56+00:00"
},
"AssumedRoleUser":{
"AssumedRoleId":"AROA123456789EXAMPLE:olaf-session",
"Arn":"arn:aws:sts::111122223333:assumed-role/sm-blog-role/olaf-session"
}
}
- Ghi lại khóa truy cập, khóa bí mật và mã thông báo phiên, bạn sẽ sử dụng chúng để cấu hình kiểm thử trong công cụ OLAF.
Thiết lập endpoint suy luận SageMaker của bạn
Trong bước này, bạn thiết lập một endpoint suy luận SageMaker. Sau đây là một script CloudFormation để thiết lập endpoint. Sao chép nội dung bên dưới và lưu nó dưới dạng một tệp YAML để sử dụng trong các bước sau.
Resources:
SageMakerExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: sagemaker.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonSageMakerFullAccess
- arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess
SageMakerModel:
Type: AWS::SageMaker::Model
Properties:
ModelName: !Sub '${AWS::StackName}-flan-t5-model'
ExecutionRoleArn: !GetAtt SageMakerExecutionRole.Arn
EnableNetworkIsolation: true
PrimaryContainer:
Image: !Sub '763104351884.dkr.ecr.${AWS::Region}.amazonaws.com/huggingface-pytorch-inference:1.13.1-transformers4.26.0-gpu-py39-cu117-ubuntu20.04'
Environment:
HF_MODEL_ID: !Sub 'google/flan-t5-${ModelSize}'
SageMakerEndpointConfig:
Type: AWS::SageMaker::EndpointConfig
Properties:
EndpointConfigName: !Sub '${EndpointName}-config'
ProductionVariants:
- VariantName: AllTraffic
ModelName: !GetAtt SageMakerModel.ModelName
InstanceType: !Ref InstanceType
InitialInstanceCount: 1
SageMakerEndpoint:
Type: AWS::SageMaker::Endpoint
Properties:
EndpointName: !Ref EndpointName
EndpointConfigName: !GetAtt SageMakerEndpointConfig.EndpointConfigName
Parameters:
ModelName:
Type: String
Default: flan-t5-model
Description: Name of the SageMaker model
EndpointName:
Type: String
Default: flan-t5-endpoint-blog
Description: Name of the SageMaker endpoint
InstanceType:
Type: String
Default: ml.g5.xlarge
Description: Instance type for the SageMaker endpoint
AllowedValues:
- ml.g4dn.xlarge
- ml.g4dn.2xlarge
- ml.g5.xlarge
- ml.g5.2xlarge
- ml.p3.2xlarge
ModelSize:
Type: String
Default: base
Description: Size of the FLAN-T5 model
AllowedValues:
- small
- base
- large
- xl
- xxl
Outputs:
SageMakerEndpointId:
Description: ID of the SageMaker Endpoint
Value: !Ref SageMakerEndpoint
SageMakerEndpointName:
Description: Name of the SageMaker Endpoint
Value: !Ref EndpointName
ModelName:
Description: Name of the deployed model
Value: !Ref ModelName
AWSTemplateFormatVersion: '2010-09-09'
Description: 'CloudFormation template for deploying FLAN-T5 model on Amazon SageMaker'
- Mở một cửa sổ AWS CloudShell bằng cách chọn biểu tượng CloudShell ở đầu AWS Management Console trong AWS Region nơi bạn muốn tạo endpoint.
- Trong cửa sổ CloudShell của bạn, chọn Actions và chọn Upload file. Chọn và tải lên tệp YAML CloudFormation được chia sẻ ở đầu phần này.
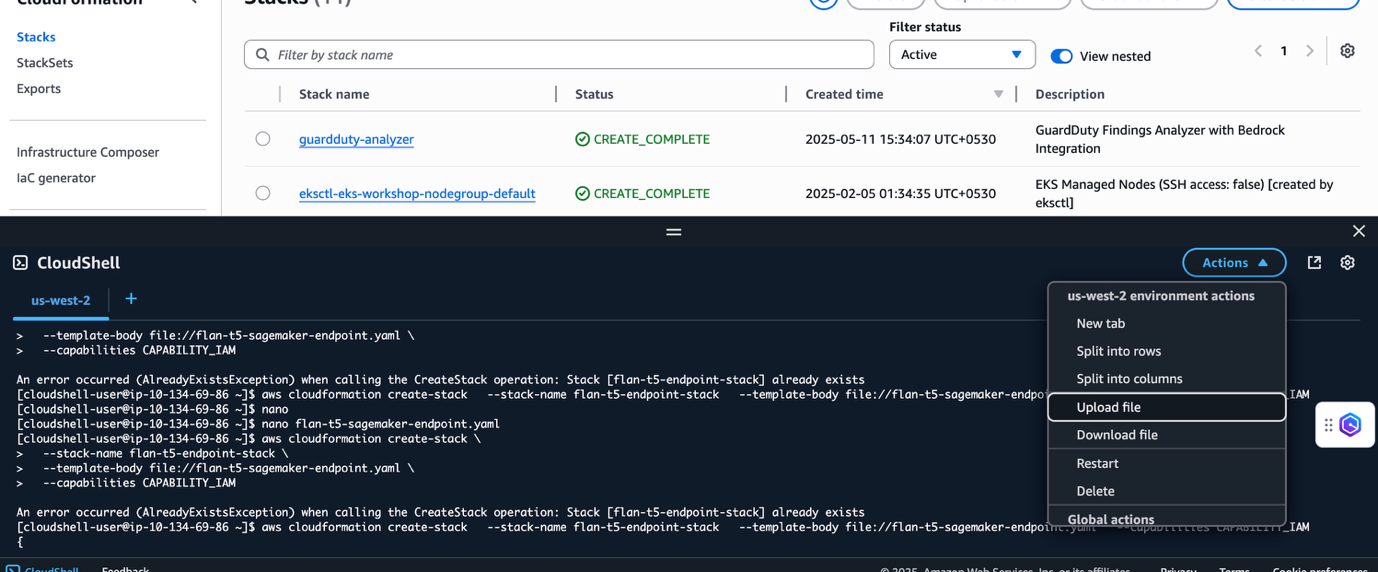
- Chạy lệnh sau tại dấu nhắc CloudShell:
aws cloudformation create-stack \
--stack-name flan-t5-endpoint-stack \
--template-body file://<YAML_FILE_NAME> \
--capabilities CAPABILITY_IAM
- Điều hướng đến console Amazon SageMaker AI Studio. Bạn có thể cần thay đổi Region để khớp với nơi bạn đã triển khai endpoint SageMaker của mình. Chọn Inference và sau đó Endpoints trong ngăn điều hướng để xem endpoint đã triển khai. Endpoint SageMaker sẽ mất vài phút để hoàn tất việc cấp phát. Khi sẵn sàng, giá trị của trường Status sẽ là InService. Ghi lại endpoint name.
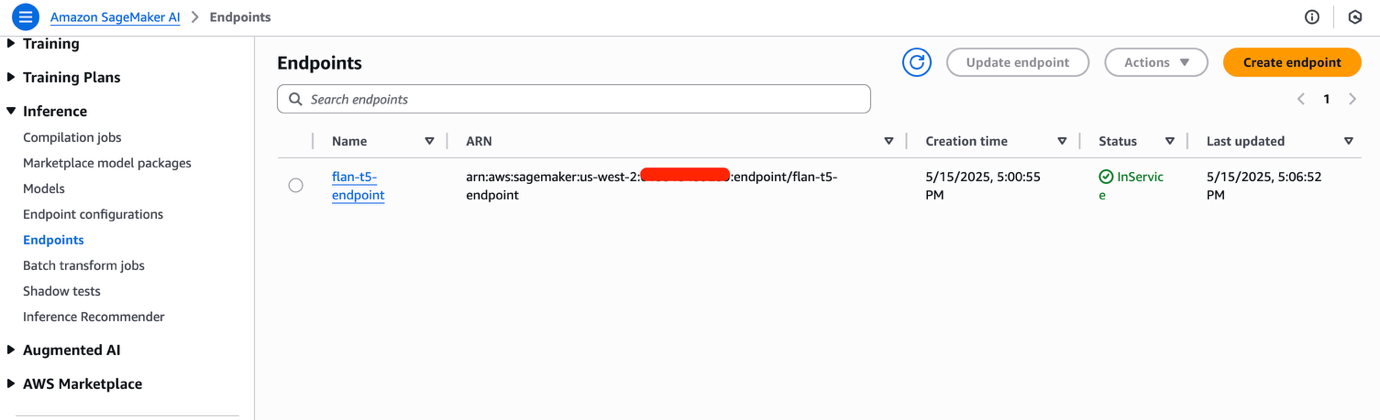
Cài đặt OLAF
Bạn đã sẵn sàng cài đặt và cấu hình OLAF để giúp bạn kiểm thử tải endpoint suy luận SageMaker AI của mình.
- Clone repository OLAF từ OLAF GitHub repo:
git clone https://github.com/Observeai-Research/olaf.git
- Điều hướng đến thư mục
olafvà xây dựng Docker image cho OLAF:
cd olaf
docker build -t olaf .
- Chạy OLAF:
docker run -p 80:8000 olaf
- Mở một cửa sổ trình duyệt và nhập URL sau để hiển thị giao diện người dùng OLAF.
http://localhost
- Nhập
olaflàm tên người dùng và mật khẩu để đăng nhập vào dashboard OLAF. Ở bên trái là một loạt các nút radio để chọn tài nguyên cần kiểm thử, bao gồm SageMaker, S3, v.v. Ở bên phải là màn hình thiết lập thay đổi dựa trên tài nguyên được chọn.
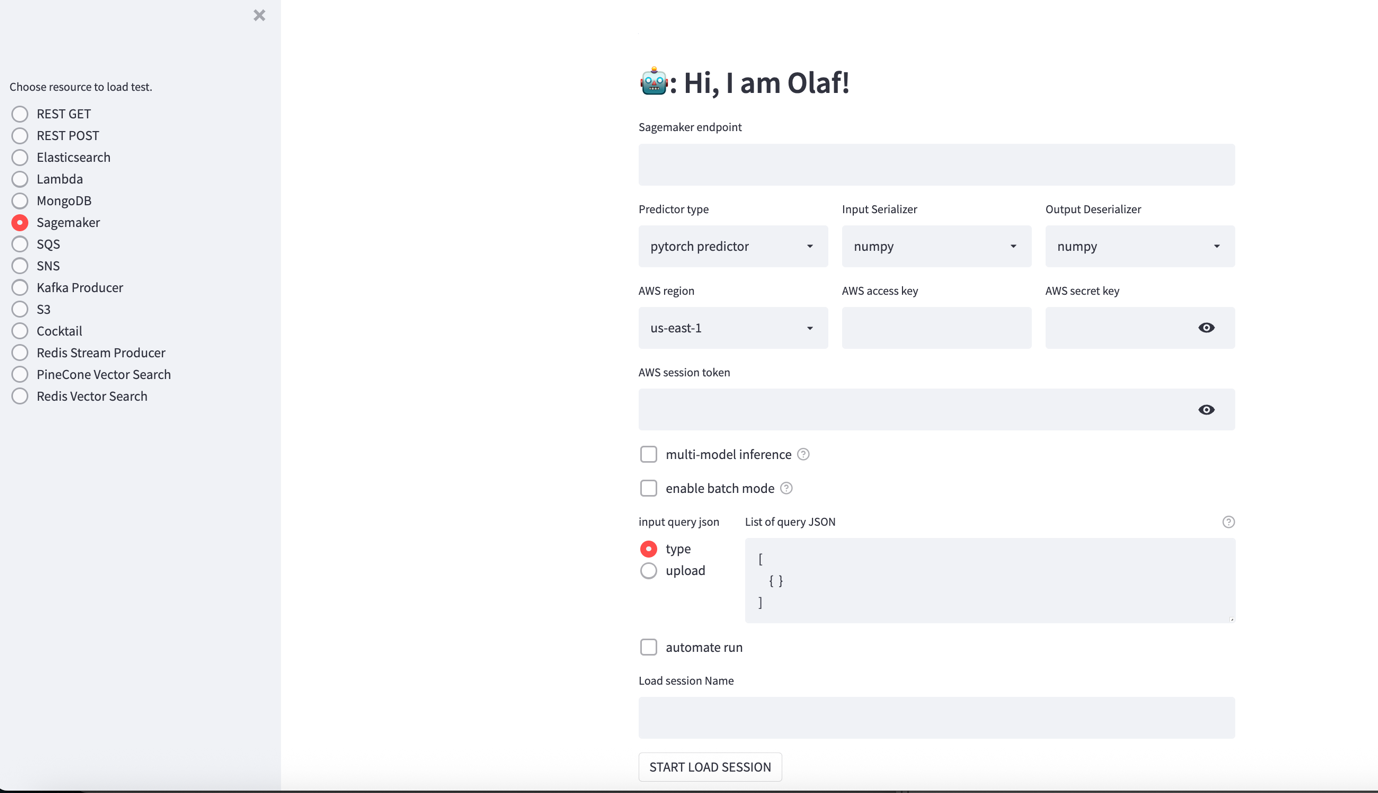
OLAF hỗ trợ các tùy chọn bổ sung, bao gồm:
- Multi-model
- Enable batch mode
Kiểm thử endpoint SageMaker
- Mở giao diện người dùng OLAF tại http://localhost:80/.
- Chọn Sagemaker từ ngăn điều hướng và cấu hình kiểm thử:
- SageMaker endpoint – Nhập tên của endpoint SageMaker từ console SageMaker Unified Studio tại đây.
- Predictor type – OLAF hỗ trợ các predictor pytorch, sklearn và tensorflow. Giữ nguyên các giá trị mặc định.
- Input Serializer – Các tùy chọn serialization là numpy và json. Giữ nguyên các giá trị mặc định.
- Output Serializer – Các tùy chọn serialization là numpy và json. Giữ nguyên các giá trị mặc định.
- AWS Region – Chọn Region nơi endpoint SageMaker được triển khai.
- AWS access key – Nhập khóa truy cập AWS được tạo từ AWS STS trong phần “Tạo thông tin xác thực AWS của bạn bằng AWS STS” ở trên.
- AWS secret key – Nhập khóa bí mật AWS được tạo từ AWS STS trong phần “Tạo thông tin xác thực AWS của bạn bằng AWS STS” ở trên.
- AWS session token – Nhập mã thông báo phiên được tạo từ AWS STS trong phần “Tạo thông tin xác thực AWS của bạn bằng AWS STS” ở trên.
- Input query json – Đối với kiểm thử này, hãy nhập lời nhắc sau để dịch một cụm từ từ tiếng Anh sang tiếng Pháp.
[
{
"inputs": "translate the following phrase in English to French : Hello, how are you"
}
]
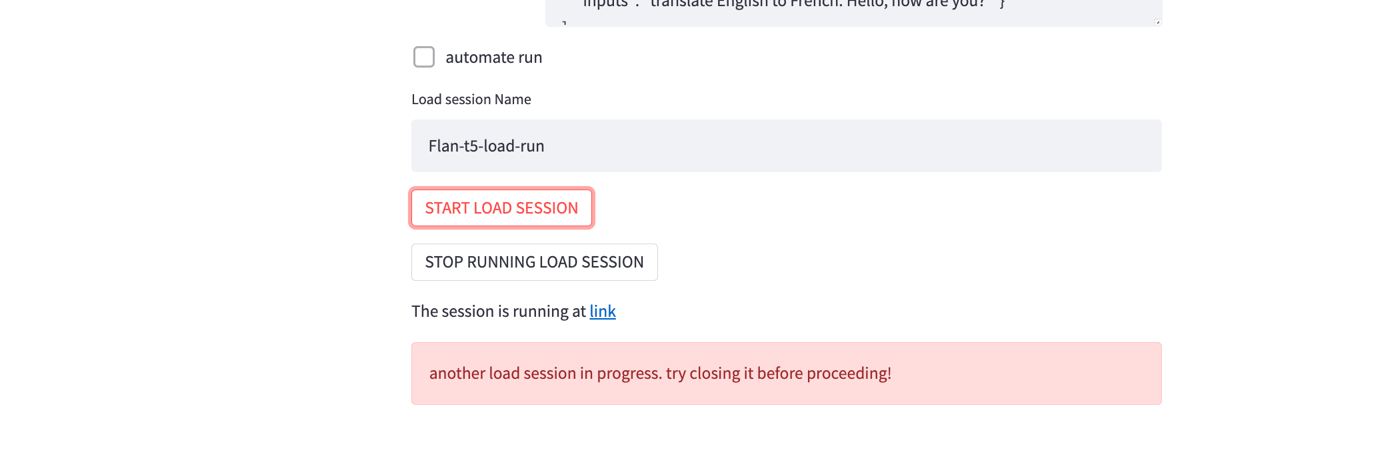
- Chọn START LOAD SESSION để bắt đầu một phiên kiểm thử tải. Phiên được bắt đầu và một liên kết đến phiên được cung cấp ở cuối trang. Nếu liên kết không xuất hiện trong vài giây, hãy chọn START LOAD SESSION để tạo liên kết đến phiên.

- Chọn liên kết sẽ đưa bạn đến một dashboard LOCUST. Nhập số lượng người dùng đồng thời mà bạn muốn kiểm thử mô phỏng vào trường Number of users và khoảng thời gian (tính bằng giây) mà người dùng phải được bắt đầu vào spawn rate. Chọn Start swarming để bắt đầu kiểm thử tải.
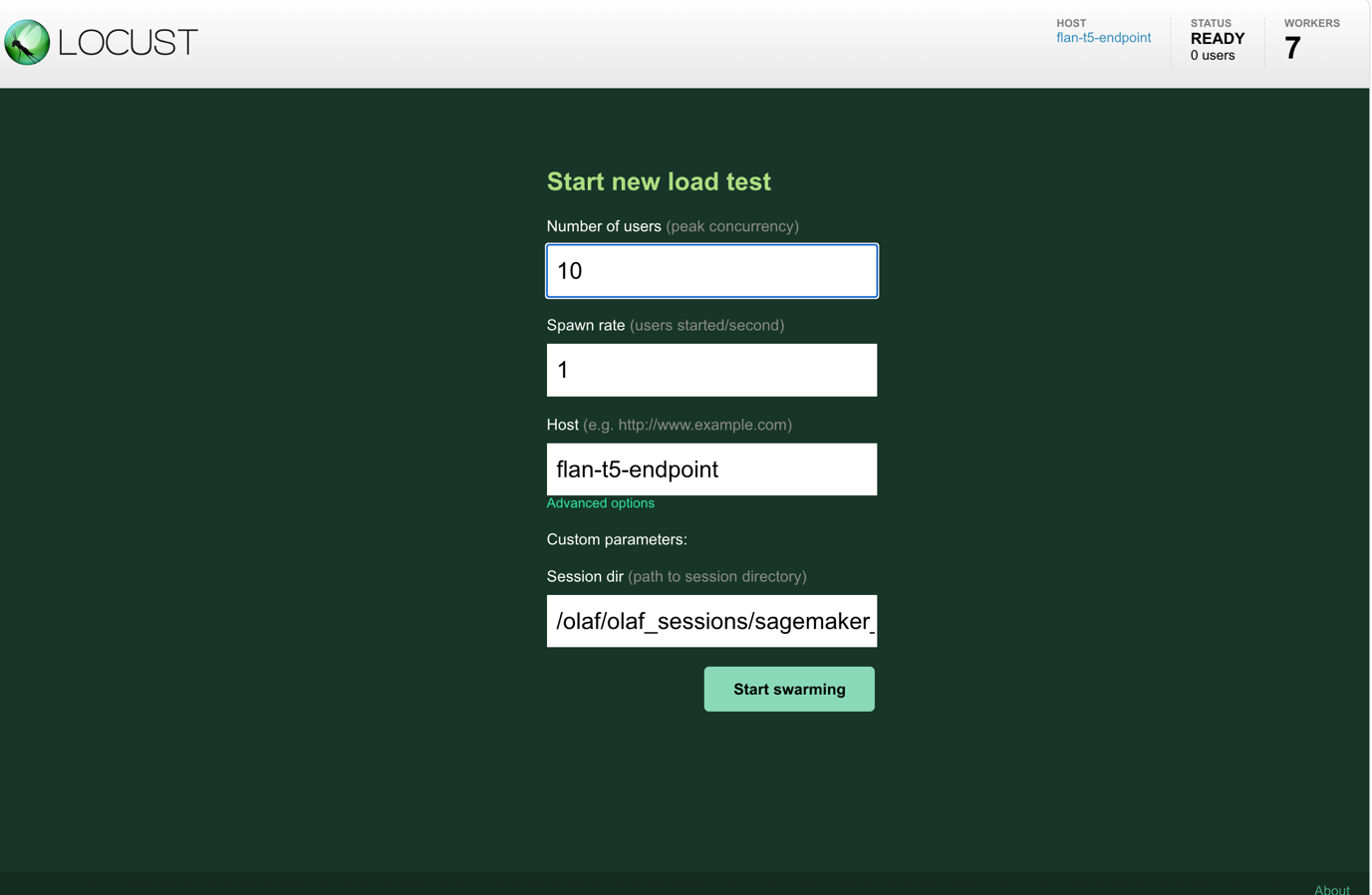
- Khi bắt đầu kiểm thử, một trang báo cáo, hiển thị trong hình sau, được trình bày mà bạn có thể sử dụng để giám sát các tham số hiệu suất khác nhau khi kiểm thử diễn ra. Thông tin trên trang này cung cấp tóm tắt các số liệu thống kê, giá trị độ trễ p50 và p95, và mức sử dụng CPU và bộ nhớ của các worker SageMaker.
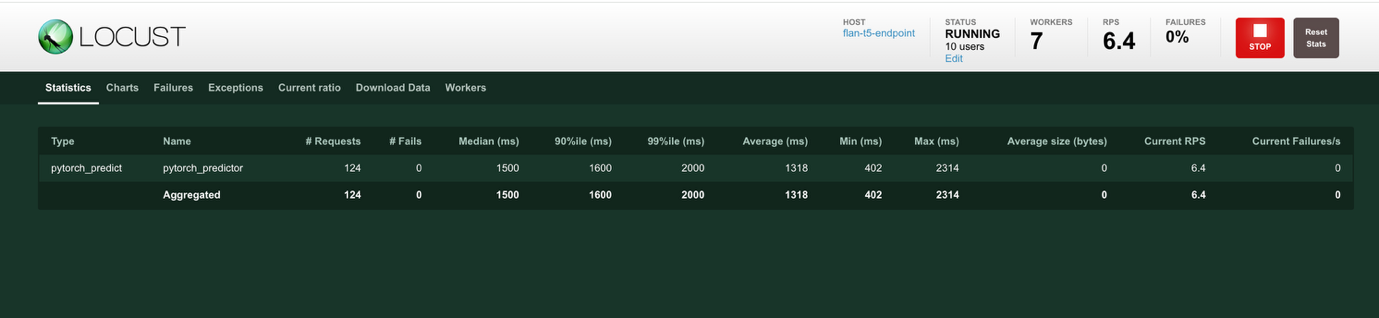
- Chọn Charts ở đầu màn hình để xem các biểu đồ hiển thị Total Requests per Second và Response Times tính bằng mili giây. Biểu đồ Total Requests per Second hiển thị các yêu cầu thành công bằng màu xanh lá cây và các yêu cầu thất bại bằng màu đỏ. Biểu đồ Response Times hiển thị thời gian phản hồi ở phân vị thứ năm mươi bằng màu xanh lá cây và thời gian phản hồi ở phân vị thứ chín mươi lăm bằng màu vàng.
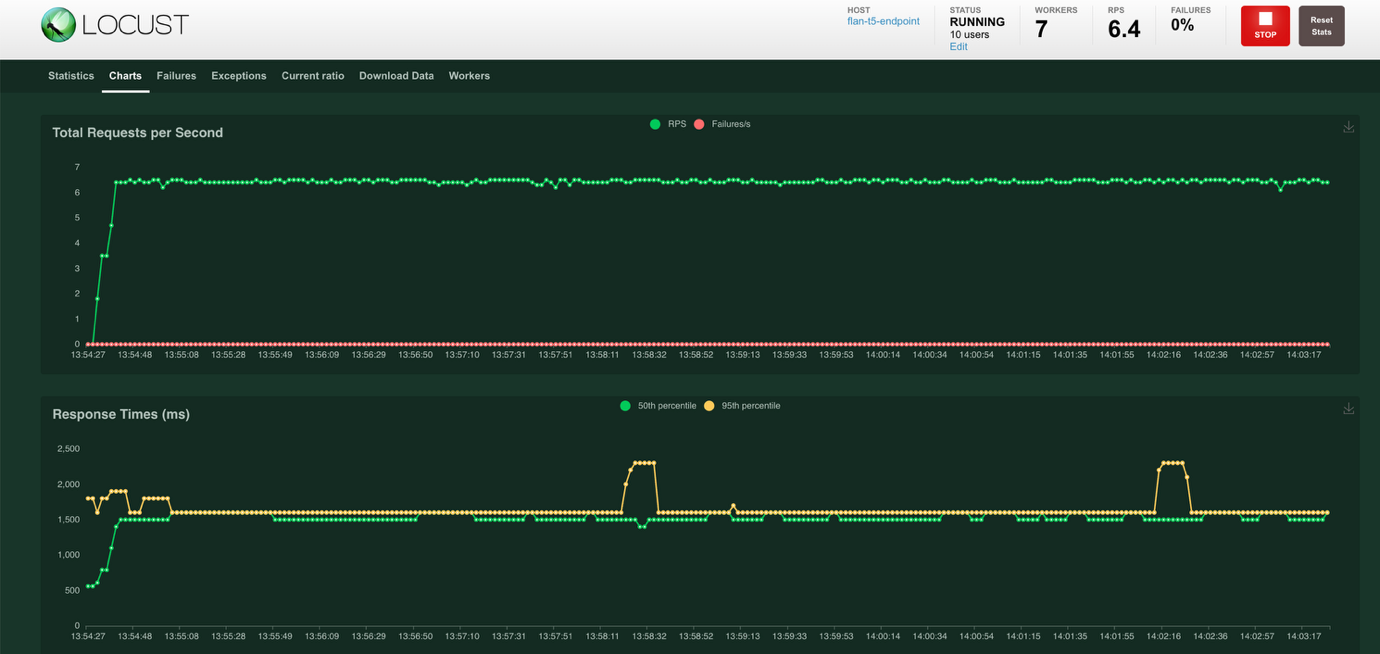
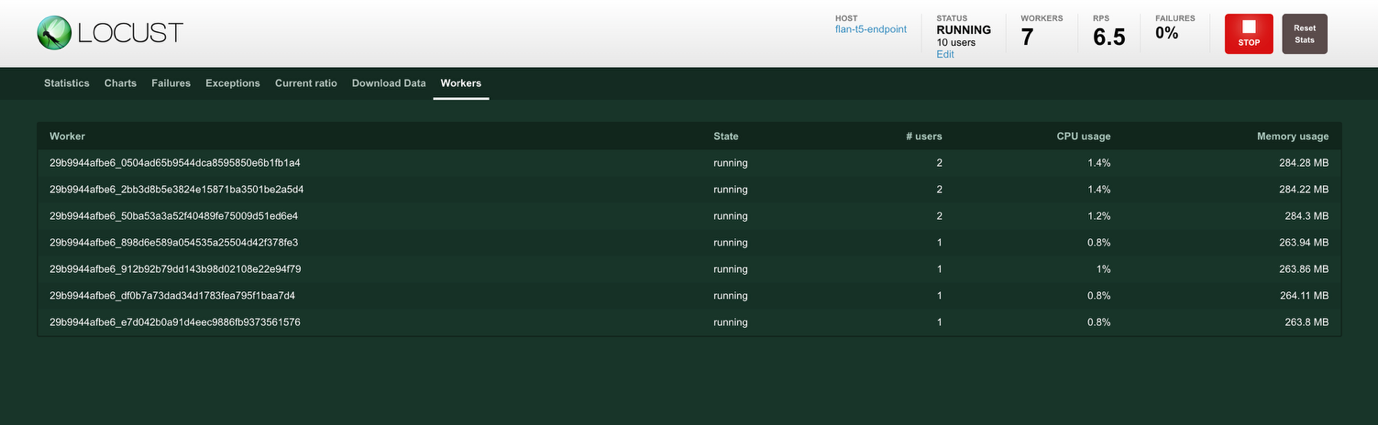
- Chọn Workers ở đầu màn hình để xem số liệu thống kê của worker. Các worker được tạo để tạo ra tải mong muốn. # users hiển thị số lượng người dùng được tạo bởi worker, CPU usage và Memory Usage hiển thị mức sử dụng tài nguyên của worker.
- Bạn có thể xem và tải xuống các số liệu thống kê cuối cùng để phân tích. Chọn Download Data ở đầu màn hình để xem các tùy chọn tải xuống dữ liệu. Bạn có thể tải xuống dữ liệu dưới dạng tệp CSV từ các trang báo cáo Statistics, Failures, Exceptions và Charts.

- Bạn phải dừng phiên tải hiện tại trước khi có thể thực hiện một phiên mới. Chọn STOP RUNNING LOAD SESSION để dừng phiên. Nếu được cấu hình, dữ liệu có thể được tải lên một Amazon Simple Storage Service (Amazon S3) bucket được chỉ định. Làm theo hướng dẫn trong Advanced OLAF Usage mục 3, Automated Backup of Load Test Report, để cấu hình việc tải lên kết quả kiểm thử lên Amazon S3.
Lưu trữ client
Đối với giải pháp được mô tả trong bài đăng này, bạn đã sử dụng một máy tính để bàn để lưu trữ container OLAF và thiết lập các kiểm thử tải. Việc lựa chọn sử dụng máy tính để bàn của bạn hoặc một phiên bản Amazon Elastic Compute Cloud (Amazon EC2) có thể ảnh hưởng đến độ trễ vì thời gian khứ hồi sẽ bị ảnh hưởng. Băng thông mạng cũng có thể ảnh hưởng đến độ trễ. Điều quan trọng là phải chuẩn hóa môi trường mà bạn sử dụng để chạy các kiểm thử dựa trên cách khách hàng của bạn sử dụng các endpoint.
Dọn dẹp tài nguyên
Khi bạn hoàn thành bản demo này, hãy xóa bất kỳ tài nguyên nào bạn không còn cần để tránh phát sinh chi phí trong tương lai.
- Trong terminal CloudShell, chạy lệnh sau để xóa endpoint SageMaker:
aws cloudformation delete-stack --stack-name flan-t5-endpoint-stack
- Chạy lệnh sau để liệt kê các Docker image đang chạy:
docker ps
- Ghi lại
container_idvà sau đó chạy lệnh sau để dừng các Docker image.
docker stop <container_id>
Kết luận
Trong bài đăng này, bạn đã tìm hiểu cách thiết lập OLAF và sử dụng nó để kiểm thử tải một endpoint SageMaker với một vài bước cơ bản. OLAF đại diện cho một bước tiến đáng kể trong việc hợp lý hóa việc tối ưu hóa cơ sở hạ tầng ML và chi phí phục vụ mô hình. Thông qua bản demo này, bạn đã thấy cách OLAF tích hợp liền mạch với SageMaker để cung cấp những hiểu biết có giá trị về hiệu suất endpoint trong các điều kiện tải khác nhau. Các lợi ích chính của OLAF bao gồm:
- Thiết lập và tích hợp đơn giản với các endpoint SageMaker hiện có
- Giám sát thời gian thực các số liệu hiệu suất bao gồm độ trễ và thông lượng
- Số liệu thống kê chi tiết và báo cáo có thể tải xuống để phân tích
- Khả năng kiểm thử các mẫu tải và mức độ đồng thời khác nhau
- Hỗ trợ nhiều loại mô hình và tùy chọn serialization
Đối với các tổ chức như Observe.ai cần mở rộng quy mô hoạt động ML của họ một cách hiệu quả, OLAF loại bỏ nhu cầu phát triển cơ sở hạ tầng kiểm thử và hệ thống gỡ lỗi tùy chỉnh. Điều này có nghĩa là các nhóm phát triển có thể tập trung vào các tính năng sản phẩm cốt lõi của họ trong khi vẫn đảm bảo hiệu suất tối ưu và hiệu quả chi phí của cơ sở hạ tầng ML của họ. Khi việc áp dụng ML tiếp tục phát triển, các công cụ như OLAF ngày càng trở nên có giá trị trong việc giúp các tổ chức tối ưu hóa hoạt động ML của họ. Cho dù bạn đang chạy một vài mô hình hay quản lý một cơ sở hạ tầng ML quy mô lớn, OLAF cung cấp những hiểu biết cần thiết để đưa ra các quyết định sáng suốt về loại phiên bản, mở rộng quy mô và phân bổ tài nguyên.
Trong giải pháp mẫu này, bạn đã sử dụng thông tin xác thực ngắn hạn được tạo bởi dịch vụ AWS STS để kết nối với SageMaker từ OLAF. Đảm bảo rằng các bước cần thiết được thực hiện để bảo mật khóa truy cập và thông tin xác thực của bạn trong môi trường sản xuất.
Để bắt đầu với OLAF, hãy truy cập kho lưu trữ GitHub và làm theo các bước cài đặt được nêu trong bài đăng này. Giao diện trực quan và khả năng giám sát toàn diện của framework làm cho nó trở thành một công cụ thiết yếu cho các tổ chức muốn tối ưu hóa việc triển khai SageMaker của họ.
Về tác giả

Aashraya Sachdeva là một nhà lãnh đạo công nghệ với chuyên môn sâu về genAI, phát triển sản phẩm và kỹ thuật nền tảng. Với tư cách là Giám đốc Kỹ thuật tại Observe, anh giám sát các nhóm xây dựng các giải pháp có khả năng mở rộng, tác nhân nhằm nâng cao cả trải nghiệm khách hàng và hiệu quả hoạt động. Với kinh nghiệm sâu rộng trong việc hướng dẫn các sáng kiến ML từ giai đoạn khám phá dữ liệu ban đầu đến triển khai và vận hành quy mô lớn, anh mang đến một cách tiếp cận thực dụng, tập trung vào độ tin cậy để cung cấp các nền tảng hiệu suất cao. Trong suốt sự nghiệp của mình, anh đã đóng vai trò quan trọng trong việc ra mắt nhiều sản phẩm, tận dụng nền tảng ML của mình để tạo ra các giải pháp sáng tạo nhưng thực tế, đồng thời liên tục thúc đẩy sự hợp tác, cố vấn và xuất sắc về kỹ thuật trong các nhóm kỹ thuật.

Shibu Jacob là Kiến trúc sư Giải pháp Cấp cao tại Amazon Web Services (AWS), nơi anh giúp khách hàng thiết kế và triển khai các giải pháp gốc đám mây. Với hơn hai thập kỷ kinh nghiệm trong phát triển phần mềm và kiến trúc, Shibu chuyên về containerization, microservices và kiến trúc hướng sự kiện. Anh đặc biệt đam mê tiềm năng biến đổi của AI trong phát triển phần mềm và thiết kế kiến trúc. Trước khi gia nhập AWS, anh đã dành 20 năm làm việc với các doanh nghiệp và công ty khởi nghiệp, mang lại nhiều kinh nghiệm thực tế cho vai trò hiện tại của mình. Ngoài công việc, Shibu thích theo dõi các cuộc đua Công thức 1, thực hiện các dự án ô tô DIY, đi những chuyến đi đường dài và dành thời gian cho gia đình.
