Tác giả: Mike Koźmiński, Magdalena Gargas, Luca Perrozzi, and Simone Pomata
Ngày phát hành: 09 JAN 2026
Chuyên mục: Amazon Bedrock, Artificial Intelligence, Customer Solutions
Bài viết này được đồng tác giả bởi Mike Koźmiński từ Beekeeper.
Các Mô hình Ngôn ngữ Lớn (LLM) đang phát triển nhanh chóng, khiến các tổ chức gặp khó khăn trong việc lựa chọn mô hình tốt nhất cho từng trường hợp sử dụng cụ thể, tối ưu hóa lời nhắc (prompt) để đạt chất lượng và chi phí, thích ứng với khả năng mô hình thay đổi, và cá nhân hóa phản hồi cho những người dùng khác nhau.
Việc chọn LLM và lời nhắc “đúng” không phải là một quyết định một lần duy nhất—nó thay đổi khi các mô hình, giá cả và yêu cầu thay đổi. Các lời nhắc hệ thống đang trở nên lớn hơn (ví dụ: lời nhắc hệ thống của Anthropic) và phức tạp hơn. Nhiều công ty cỡ trung không có đủ tài nguyên để nhanh chóng đánh giá và cải thiện chúng. Để giải quyết vấn đề này, Beekeeper đã xây dựng một hệ thống được hỗ trợ bởi Amazon Bedrock liên tục đánh giá các ứng viên mô hình + lời nhắc, xếp hạng chúng trên bảng xếp hạng trực tiếp và định tuyến mỗi yêu cầu đến lựa chọn tốt nhất hiện tại cho trường hợp sử dụng đó.
Beekeeper: Kết nối và trao quyền cho lực lượng lao động tuyến đầu
Beekeeper by LumApps cung cấp một hệ thống nơi làm việc kỹ thuật số toàn diện được thiết kế đặc biệt cho các hoạt động của lực lượng lao động tuyến đầu. Công ty cung cấp giải pháp giao tiếp và năng suất ưu tiên thiết bị di động, kết nối những người lao động không làm việc tại bàn với nhau và với trụ sở chính, cho phép các tổ chức hợp lý hóa hoạt động, tăng cường sự gắn kết của nhân viên và quản lý công việc hiệu quả. Hệ thống của họ có khả năng tích hợp mạnh mẽ với các hệ thống kinh doanh hiện có (nhân sự, lập lịch, bảng lương), đồng thời nhắm mục tiêu đến các ngành có lực lượng lao động không làm việc tại bàn lớn như khách sạn, sản xuất, bán lẻ, chăm sóc sức khỏe và vận tải. Về cốt lõi, Beekeeper giải quyết sự ngắt kết nối truyền thống giữa nhân viên tuyến đầu và tổ chức của họ bằng cách cung cấp các công cụ kỹ thuật số dễ tiếp cận giúp tăng cường giao tiếp, hiệu quả hoạt động và duy trì lực lượng lao động, tất cả đều được cung cấp thông qua hệ thống SaaS dựa trên đám mây với ứng dụng di động, bảng điều khiển quản trị và các tính năng bảo mật cấp doanh nghiệp.
Giải pháp của Beekeeper: Một hệ thống đánh giá động
Beekeeper đã giải quyết thách thức này bằng một hệ thống tự động liên tục kiểm tra các kết hợp mô hình và lời nhắc khác nhau, xếp hạng các tùy chọn dựa trên chất lượng, chi phí và tốc độ, kết hợp phản hồi của người dùng để cá nhân hóa phản hồi và tự động định tuyến các yêu cầu đến tùy chọn tốt nhất hiện tại. Chất lượng được chấm điểm bằng một bộ kiểm tra tổng hợp nhỏ và được xác thực trong sản xuất bằng phản hồi của người dùng (thích/không thích và bình luận). Bằng cách kết hợp biến đổi lời nhắc, Beekeeper đã tạo ra một hệ thống hữu cơ phát triển theo thời gian. Kết quả là một thiết lập liên tục tối ưu hóa, cân bằng chất lượng, độ trễ và chi phí—và tự động thích ứng khi bối cảnh thay đổi.
Ví dụ thực tế: Tóm tắt cuộc trò chuyện
Nền tảng Frontline Success của Beekeeper hợp nhất giao tiếp cho những người lao động không làm việc tại bàn trong các ngành công nghiệp. Một ứng dụng thực tế của hệ thống LLM của họ là tóm tắt cuộc trò chuyện. Khi một người dùng quay lại ca làm việc, họ có thể tìm thấy một cuộc trò chuyện với nhiều tin nhắn chưa đọc – thay vì đọc tất cả, họ có thể yêu cầu một bản tóm tắt. Hệ thống tạo ra một bản tổng quan ngắn gọn với các mục hành động được điều chỉnh theo nhu cầu của người dùng. Người dùng sau đó có thể cung cấp phản hồi để cải thiện các bản tóm tắt trong tương lai. Tính năng tưởng chừng đơn giản này lại dựa trên công nghệ tinh vi đằng sau hậu trường. Hệ thống phải hiểu ngữ cảnh cuộc trò chuyện, xác định các điểm quan trọng, nhận diện các mục hành động và trình bày thông tin một cách ngắn gọn—tất cả trong khi thích ứng với sở thích của người dùng.

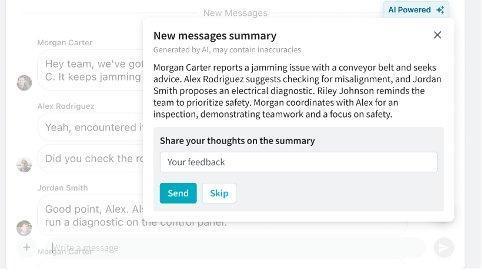
Tổng quan giải pháp
Giải pháp của Beekeeper bao gồm hai giai đoạn chính: xây dựng bảng xếp hạng cơ sở và cá nhân hóa bằng phản hồi của người dùng.
Hệ thống sử dụng một số thành phần AWS, bao gồm Amazon EventBridge để lập lịch, Amazon Elastic Kubernetes Service (EKS) để điều phối, AWS Lambda cho các hàm đánh giá, Amazon Relational Database Service (RDS) để lưu trữ dữ liệu và Amazon Mechanical Turk để xác thực thủ công.
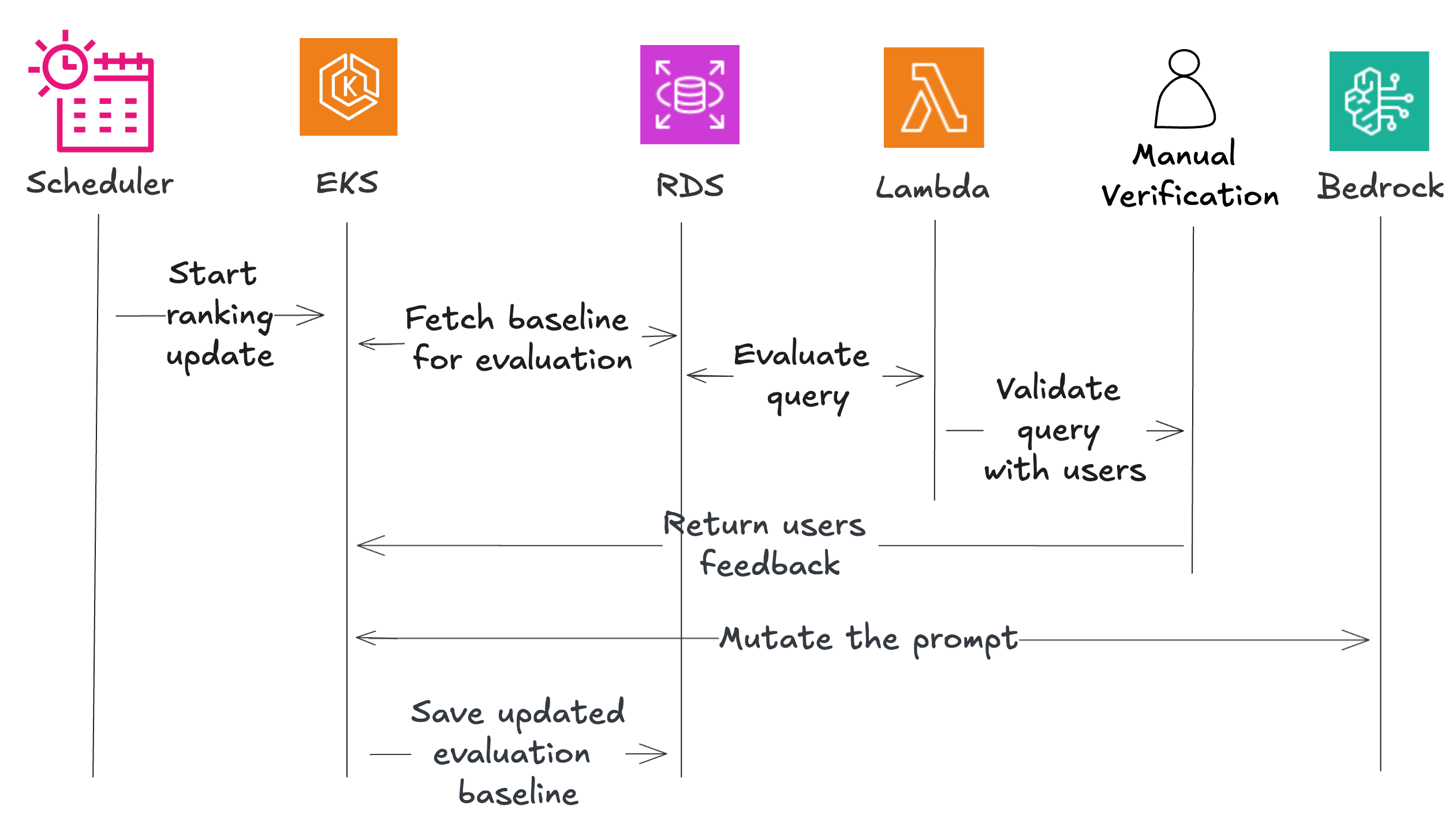
Quy trình làm việc bắt đầu với một trình tạo xếp hạng tổng hợp thiết lập hiệu suất cơ sở. Một bộ lập lịch kích hoạt bộ điều phối, bộ này tìm nạp dữ liệu thử nghiệm và gửi đến các bộ đánh giá. Các bộ đánh giá này kiểm tra từng cặp mô hình/lời nhắc và trả về kết quả, với một phần được gửi để xác thực thủ công. Hệ thống biến đổi các lời nhắc đầy hứa hẹn để tạo ra các biến thể, đánh giá lại chúng và lưu trữ những lời nhắc hoạt động tốt nhất. Khi phản hồi của người dùng đến, hệ thống kết hợp nó thông qua giai đoạn thứ hai. Bộ điều phối tìm nạp các cặp mô hình/lời nhắc đã được xếp hạng và gửi chúng cùng với phản hồi của người dùng đến một bộ biến đổi, bộ này trả về các lời nhắc được cá nhân hóa. Một bộ phát hiện độ lệch đảm bảo rằng các phiên bản được cá nhân hóa này không đi quá xa so với các tiêu chuẩn chất lượng, và các lời nhắc đã được xác thực được lưu trữ cho những người dùng cụ thể.
Xây dựng bảng xếp hạng cơ sở
Để khởi động hành trình tối ưu hóa, các kỹ sư của Beekeeper đã chọn nhiều mô hình khác nhau và cung cấp cho chúng các lời nhắc do con người viết, chuyên biệt theo từng lĩnh vực. Nhóm kỹ thuật đã thử nghiệm các lời nhắc này bằng cách sử dụng các ví dụ do LLM tạo ra để đảm bảo chúng không có lỗi. Một nền tảng vững chắc là rất quan trọng ở đây. Nền tảng này giúp họ tinh chỉnh cách tiếp cận khi kết hợp phản hồi từ người dùng thực.
Trong các phần sau, chúng ta sẽ đi sâu vào các chỉ số thành công của họ, những chỉ số này hướng dẫn việc tinh chỉnh lời nhắc và giúp tạo ra trải nghiệm người dùng tối ưu.
Tiêu chí đánh giá cho đường cơ sở
Chất lượng của các bản tóm tắt được tạo bởi các cặp mô hình/lời nhắc được đo lường bằng cả các chỉ số định lượng và định tính, bao gồm:
- Tỷ lệ nén – Đo độ dài tóm tắt so với văn bản gốc, thưởng cho việc tuân thủ độ dài mục tiêu và phạt việc độ dài quá mức.
- Sự hiện diện của các mục hành động – Đảm bảo các mục hành động cụ thể của người dùng được xác định rõ ràng.
- Thiếu ảo giác – Xác thực tính chính xác và nhất quán của thông tin.
- So sánh vector – Đánh giá sự tương đồng ngữ nghĩa với kết quả hoàn hảo do con người tạo ra.
Trong các phần sau, chúng ta sẽ đi qua từng tiêu chí đánh giá và cách chúng được triển khai.
Tỷ lệ nén
Tỷ lệ nén đánh giá độ dài của văn bản tóm tắt so với văn bản gốc và sự tuân thủ độ dài mục tiêu (nó thưởng cho tỷ lệ nén gần với mục tiêu và phạt các văn bản lệch khỏi độ dài mục tiêu). Điểm tương ứng, từ 0 đến 100, được tính toán theo chương trình bằng mã Python sau:
def calculate_compression_score(original_text, compressed_text):
max_length = 650
target_ratio = 1 / 5
margin = 0.05
max_penalty_points = 100 # Maximum penalty if the text is too long
original_length = len(original_text)
compressed_length = len(compressed_text)
# Calculate penalty for exceeding maximum length
excess_length = max(0, original_length - max_length)
penalty = (excess_length / original_length) * max_penalty_points
# Calculate the actual compression ratio
actual_ratio = compressed_length / original_length
lower_bound = target_ratio * (1 - margin)
upper_bound = target_ratio * (1 + margin)
# Calculate the base score based on the compression ratio
if actual_ratio < lower_bound:
base_score = 100 * (actual_ratio / lower_bound)
elif actual_ratio > upper_bound:
base_score = 100 * (upper_bound / actual_ratio)
else:
base_score = 100
# Apply the penalty to the base score
score = base_score - penalty
# Ensure the score does not go below 0
score = max(0, score)
return round(score, 2)
Sự hiện diện của các mục hành động liên quan đến người dùng
Để kiểm tra xem bản tóm tắt có chứa tất cả các mục hành động liên quan đến người dùng hay không, Beekeeper dựa vào việc so sánh với ground truth. Đối với việc so sánh ground truth, định dạng đầu ra mong muốn yêu cầu một phần được gắn nhãn “Action items:” theo sau là các dấu đầu dòng, sử dụng biểu thức chính quy để trích xuất danh sách các mục hành động như trong mã Python sau:
import re
def extract_action_items(text):
action_section = re.search(r'Action items:(.*?)(?=\n\n|\Z)', text, re.DOTALL)
if action_section:
action_content = action_section.group(1).strip()
action_items = re.findall(r'^\s*-\s*(.+)$', action_content, re.MULTILINE)
return action_items
else:
return []
Họ bao gồm bước trích xuất bổ sung này để đảm bảo dữ liệu được định dạng theo cách mà LLM có thể dễ dàng xử lý. Danh sách được trích xuất được gửi đến một LLM với yêu cầu kiểm tra xem nó có đúng hay không. Điểm +1 được gán cho mỗi mục hành động được gán đúng và -1 được sử dụng trong trường hợp dương tính giả. Sau đó, các điểm được chuẩn hóa để không phạt/thưởng các bản tóm tắt có nhiều hoặc ít mục hành động hơn.
Thiếu ảo giác
Để đánh giá ảo giác, Beekeeper sử dụng hai phương pháp: đánh giá chéo LLM và xác thực thủ công.

Trong đánh giá chéo LLM, một bản tóm tắt được tạo bởi LLM A (ví dụ: Mistral Large) được chuyển đến thành phần đánh giá, cùng với lời nhắc và đầu vào ban đầu. Bộ đánh giá gửi văn bản này đến LLM B (ví dụ: Claude của Anthropic), hỏi xem các sự kiện từ bản tóm tắt có khớp với ngữ cảnh thô hay không. Một LLM của một họ khác được sử dụng cho việc đánh giá này. Amazon Bedrock làm cho bài tập này đặc biệt đơn giản thông qua Converse API—người dùng có thể chọn các LLM khác nhau bằng cách thay đổi chuỗi định danh mô hình.
Một điểm quan trọng khác là sự hiện diện của xác minh thủ công trên một tập hợp nhỏ các đánh giá tại Beekeeper, để tránh các trường hợp ảo giác kép. Họ gán điểm 1 nếu không phát hiện ảo giác và -1 nếu phát hiện bất kỳ ảo giác nào. Đối với toàn bộ quy trình, họ sử dụng cùng một heuristic là 7% đánh giá thủ công (chi tiết sẽ được thảo luận thêm trong bài viết này).
So sánh vector
Là một phương pháp đánh giá bổ sung, sự tương đồng ngữ nghĩa được sử dụng cho dữ liệu có thông tin ground truth có sẵn. Các mô hình nhúng được chọn trong số MTEB Leaderboard (so sánh đa tác vụ và đa ngôn ngữ của các mô hình nhúng), xem xét kích thước vector lớn để tối đa hóa lượng thông tin được lưu trữ bên trong vector. Beekeeper sử dụng Qwen3 làm đường cơ sở, một mô hình cung cấp kích thước 4096 và hỗ trợ lượng tử hóa 16 bit để tính toán nhanh. Các mô hình nhúng khác cũng được sử dụng trực tiếp từ Amazon Bedrock. Sau khi tính toán các vector nhúng cho cả câu trả lời ground truth và câu trả lời được tạo bởi một cặp mô hình/lời nhắc nhất định, sự tương đồng cosine được sử dụng để tính toán sự tương đồng, như được hiển thị trong mã Python sau:
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(synthetic_summary_embed, generated_summary_embed)
Đường cơ sở đánh giá
Đường cơ sở đánh giá của mỗi cặp mô hình/lời nhắc được thực hiện bằng cách thu thập đầu ra được tạo của một tập hợp các truy vấn cố định, được xác định trước, được chú thích thủ công với các đầu ra ground truth chứa “câu trả lời đúng” (trong trường hợp này, các bản tóm tắt lý tưởng từ bộ dữ liệu nội bộ và công khai). Tập hợp này như đã đề cập trước đây được tạo từ một bộ dữ liệu công khai cũng như các ví dụ được tạo thủ công đại diện tốt hơn cho miền của khách hàng. Các điểm được đánh giá tự động dựa trên các chỉ số được mô tả trước đó: nén, thiếu ảo giác, sự hiện diện của các mục hành động và so sánh vector, để xây dựng phiên bản đường cơ sở của bảng xếp hạng.
Đánh giá thủ công
Để xác thực bổ sung, Beekeeper xem xét thủ công một mẫu đánh giá được xác định khoa học bằng cách sử dụng Amazon Mechanical Turk. Kích thước mẫu này được tính toán bằng công thức của Cochran để hỗ trợ ý nghĩa thống kê.
Amazon Mechanical Turk cho phép các doanh nghiệp khai thác trí tuệ con người cho các tác vụ mà máy tính không thể thực hiện hiệu quả. Thị trường crowdsourcing này kết nối người dùng với lực lượng lao động toàn cầu, theo yêu cầu để hoàn thành các tác vụ nhỏ như gắn nhãn dữ liệu, kiểm duyệt nội dung và xác thực nghiên cứu—giúp mở rộng quy mô hoạt động mà không làm giảm chất lượng hoặc tăng chi phí. Như đã đề cập trước đó, Beekeeper sử dụng phản hồi của con người để xác minh rằng hệ thống xếp hạng tự động dựa trên LLM đang hoạt động chính xác. Dựa trên các giả định trước đó của họ, họ biết tỷ lệ phần trăm phản hồi nào nên được phân loại là có ảo giác. Nếu số lượng được phát hiện bởi xác minh của con người khác biệt hơn hai điểm phần trăm so với ước tính của họ, họ biết rằng quy trình tự động không hoạt động đúng cách và cần được sửa đổi. Giờ đây, Beekeeper đã thiết lập đường cơ sở của mình, họ có thể cung cấp kết quả tốt nhất cho khách hàng của mình. Bằng cách liên tục cập nhật các mô hình của mình, họ có thể mang lại giá trị mới một cách tự động. Bất cứ khi nào các kỹ sư của họ có ý tưởng tối ưu hóa lời nhắc mới, họ có thể để quy trình đánh giá nó so với các lời nhắc trước đó bằng cách sử dụng kết quả đường cơ sở. Beekeeper có thể tiến xa hơn và nhúng phản hồi của người dùng, cho phép kết quả tùy chỉnh hơn. Tuy nhiên, họ không muốn phản hồi của người dùng thay đổi hoàn toàn hành vi của mô hình thông qua việc chèn lời nhắc vào phản hồi. Trong phần sau, chúng ta sẽ xem xét phần hữu cơ của quy trình của Beekeeper nhúng sở thích của người dùng vào các phản hồi mà không ảnh hưởng đến những người dùng khác.
Đánh giá phản hồi của người dùng
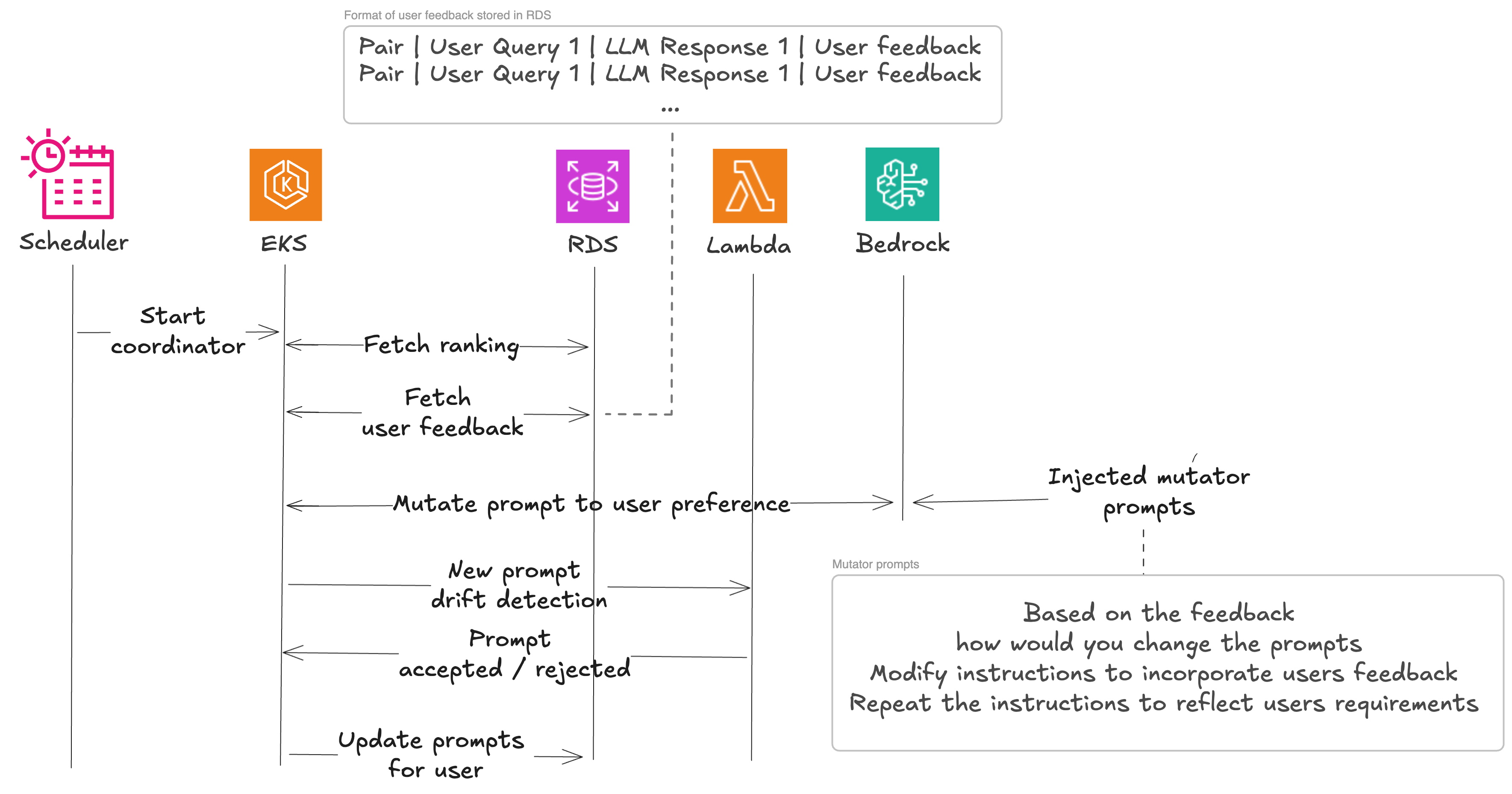
Giờ đây, Beekeeper đã thiết lập đường cơ sở của mình bằng cách sử dụng bộ ground truth, họ có thể bắt đầu kết hợp phản hồi của con người. Điều này hoạt động theo cùng các nguyên tắc như quy trình phát hiện ảo giác đã mô tả trước đó. Phản hồi của người dùng được tổng hợp cùng với đầu vào và phản hồi của LLM. Họ chuyển các câu hỏi đến LLM theo định dạng sau:
You are given a task to identify if the hypothesis is in agreement with the context
below. You will only use the contents of the context and not rely on external knowledge.
Answer with yes/no."context": {{input}} "summary": {{output}} "hypothesis": {{ statement }} "agreement":
Họ sử dụng điều này để kiểm tra xem phản hồi được cung cấp có còn áp dụng được sau khi cặp lời nhắc-mô hình được cập nhật hay không. Điều này hoạt động như một đường cơ sở để kết hợp phản hồi của người dùng. Giờ đây, họ đã sẵn sàng bắt đầu biến đổi lời nhắc. Điều này được thực hiện để tránh phản hồi được áp dụng nhiều lần. Nếu thay đổi mô hình hoặc biến đổi đã giải quyết vấn đề, thì không cần áp dụng lại.
Quá trình biến đổi bao gồm việc đánh giá lại bộ dữ liệu do người dùng tạo sau khi biến đổi lời nhắc cho đến khi đầu ra kết hợp phản hồi của người dùng, sau đó chúng tôi sử dụng đường cơ sở để hiểu sự khác biệt và loại bỏ các thay đổi trong trường hợp chúng làm suy yếu hoạt động của mô hình.
Bốn cặp mô hình/lời nhắc hoạt động tốt nhất được chọn trong đánh giá đường cơ sở (đối với các lời nhắc đã biến đổi) được xử lý thêm thông qua quy trình biến đổi lời nhắc, để kiểm tra sự cải thiện còn lại của kết quả. Điều này rất cần thiết trong một môi trường mà ngay cả những sửa đổi nhỏ đối với một lời nhắc cũng có thể dẫn đến kết quả khác biệt đáng kể khi được sử dụng cùng với phản hồi của người dùng.
Lời nhắc ban đầu được làm giàu với một biến đổi lời nhắc, phản hồi của người dùng nhận được, một phong cách tư duy (một cách tiếp cận nhận thức cụ thể như “Hãy sáng tạo” hoặc “Suy nghĩ theo từng bước” hướng dẫn cách LLM tiếp cận tác vụ biến đổi), ngữ cảnh người dùng và được gửi đến LLM để tạo ra một lời nhắc đã biến đổi. Các lời nhắc đã biến đổi được thêm vào danh sách, được đánh giá và các điểm tương ứng được đưa vào bảng xếp hạng. Các lời nhắc biến đổi cũng có thể bao gồm phản hồi của người dùng khi có.
Ví dụ về các lời nhắc biến đổi được tạo ra bao gồm:
“Add hints which would help LLM solve this problem:”
“Modify Instructions to be simpler:”
“Repeat that instruction in another way:”
“What additional instructions would you give someone to include this feedback {feedback}
into that instructions:”
Ví dụ giải pháp
Quá trình đánh giá đường cơ sở bắt đầu với tám cặp lời nhắc và các mô hình liên quan (Amazon Nova, Anthropic Claude 4 Sonnet, Meta Llama 3 và Mistral 8x7B). Beekeeper thường sử dụng bốn lời nhắc cơ sở và hai mô hình để bắt đầu. Các lời nhắc này được sử dụng trên tất cả các mô hình, nhưng kết quả được xem xét theo cặp lời nhắc-mô hình. Các mô hình được tự động cập nhật khi các phiên bản mới hơn có sẵn thông qua Amazon Bedrock.
Beekeeper bắt đầu bằng cách đánh giá tám cặp hiện có:
- Mỗi đánh giá yêu cầu tạo 20 bản tóm tắt cho mỗi cặp (8 x 20 = 160)
- Mỗi bản tóm tắt được kiểm tra bởi ba kiểm tra tĩnh và hai kiểm tra LLM (160 x 2 = 320)
Tổng cộng, điều này tạo ra 480 cuộc gọi LLM. Các điểm được so sánh, tạo ra một bảng xếp hạng, và hai cặp lời nhắc-mô hình được chọn. Hai lời nhắc này được biến đổi bằng cách sử dụng phản hồi của người dùng, tạo ra 10 lời nhắc mới, sau đó lại được đánh giá, tạo ra 600 cuộc gọi đến LLM (10 x 20 + 10 x 20 x 2 = 600).
Quá trình này có thể được chạy n lần để thực hiện các biến đổi sáng tạo hơn; Beekeeper thường thực hiện hai chu kỳ.
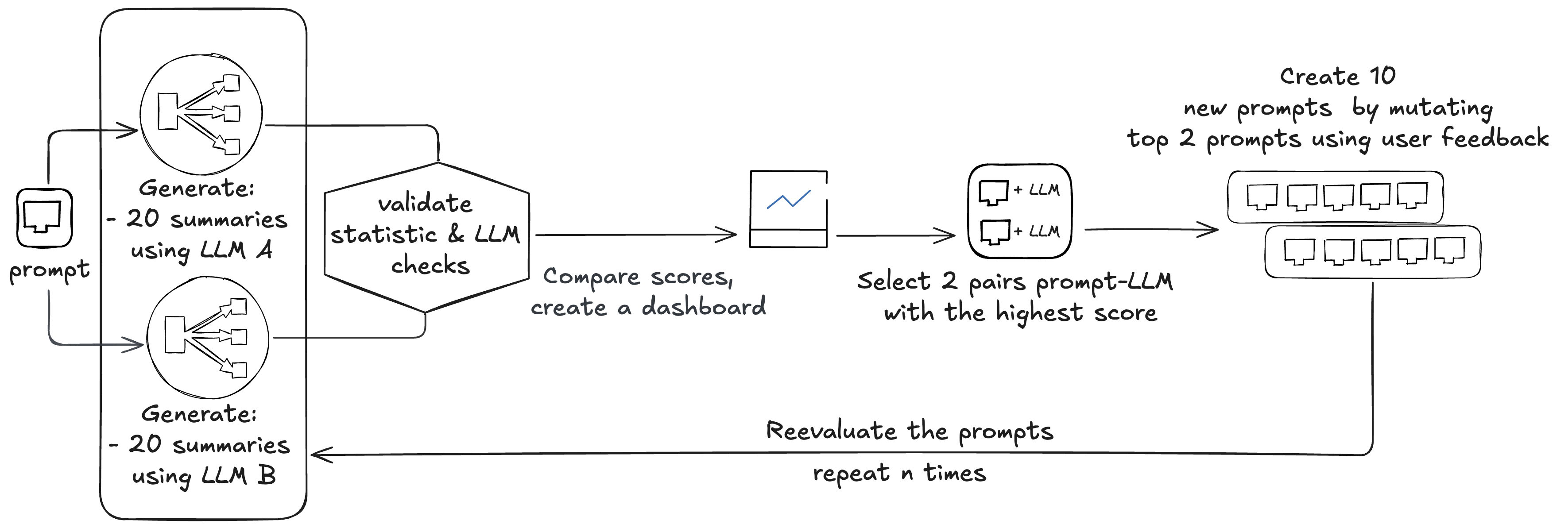
Tổng cộng, bài tập này thực hiện các thử nghiệm trên (8 + 10 + 10) x 2 cặp mô hình/lời nhắc. Toàn bộ quá trình trung bình yêu cầu khoảng 8.352.000 token đầu vào và khoảng 1.620.000 token đầu ra, với chi phí khoảng 48 đô la. Các cặp mô hình/lời nhắc mới được chọn được sử dụng trong sản xuất với tỷ lệ 1st: 50%, 2nd: 30% và 3rd: 20%. Sau khi triển khai các cặp mô hình/lời nhắc mới, Beekeeper thu thập phản hồi từ người dùng. Phản hồi này được sử dụng để cung cấp cho bộ biến đổi để tạo ra ba lời nhắc mới. Các lời nhắc này được gửi để phát hiện độ lệch, so sánh chúng với đường cơ sở. Tổng cộng, chúng tạo ra bốn cuộc gọi LLM, với chi phí khoảng 4.800 token đầu vào và 500 token đầu ra.
Lợi ích
Lợi ích chính của giải pháp Beekeeper là khả năng phát triển nhanh chóng và thích ứng với nhu cầu của người dùng. Với cách tiếp cận này, họ có thể đưa ra các ước tính ban đầu về cặp mô hình/lời nhắc nào sẽ là ứng cử viên tối ưu cho mỗi tác vụ, đồng thời kiểm soát cả chi phí và chất lượng kết quả. Bằng cách kết hợp lợi ích của dữ liệu tổng hợp với phản hồi của người dùng, giải pháp này phù hợp ngay cả với các nhóm kỹ thuật nhỏ hơn. Thay vì tập trung vào các lời nhắc chung chung, Beekeeper ưu tiên điều chỉnh quy trình cải thiện lời nhắc để đáp ứng nhu cầu riêng của từng khách hàng. Bằng cách đó, họ có thể tinh chỉnh lời nhắc để trở nên cực kỳ phù hợp và thân thiện với người dùng. Cách tiếp cận này cho phép người dùng phát triển phong cách riêng của họ, từ đó nâng cao trải nghiệm của họ khi họ cung cấp phản hồi và thấy được tác động của nó. Một trong những tác dụng phụ mà họ quan sát được là một số nhóm người thích các phong cách giao tiếp khác nhau. Bằng cách ánh xạ các kết quả này với các tương tác của khách hàng, họ đặt mục tiêu mang đến trải nghiệm phù hợp hơn. Điều này đảm bảo rằng phản hồi của một người dùng không ảnh hưởng đến người khác. Kết quả sơ bộ của họ cho thấy xếp hạng phản hồi tốt hơn 13–24% khi tổng hợp theo từng khách hàng. Tóm lại, giải pháp được đề xuất mang lại một số lợi ích đáng chú ý. Nó giảm thiểu công việc thủ công bằng cách tự động hóa quy trình lựa chọn LLM và lời nhắc, rút ngắn chu kỳ phản hồi, cho phép tạo ra các cải tiến dành riêng cho người dùng hoặc khách hàng, và cung cấp khả năng tích hợp và ước tính hiệu suất của các mô hình mới một cách liền mạch theo cùng một cách như các mô hình trước đó.
Kết luận
Cách tiếp cận bảng xếp hạng tự động của Beekeeper và hệ thống vòng lặp phản hồi của con người để lựa chọn cặp LLM và lời nhắc động giải quyết các thách thức chính mà các tổ chức phải đối mặt trong việc điều hướng bối cảnh mô hình ngôn ngữ đang phát triển nhanh chóng. Bằng cách liên tục đánh giá và tối ưu hóa chất lượng, kích thước, tốc độ và chi phí, giải pháp giúp khách hàng sử dụng các kết hợp mô hình/lời nhắc hoạt động tốt nhất cho các trường hợp sử dụng cụ thể của họ. Trong tương lai, Beekeeper có kế hoạch tinh chỉnh và mở rộng hơn nữa khả năng của hệ thống này, kết hợp các kỹ thuật nâng cao hơn cho kỹ thuật và đánh giá lời nhắc. Ngoài ra, nhóm đang khám phá các cách để trao quyền cho người dùng phát triển các lời nhắc tùy chỉnh của riêng họ, thúc đẩy trải nghiệm cá nhân hóa và hấp dẫn hơn. Nếu tổ chức của bạn đang tìm cách tối ưu hóa lựa chọn LLM và kỹ thuật lời nhắc, không cần phải bắt đầu lại từ đầu. Sử dụng các dịch vụ AWS như Amazon Bedrock để truy cập mô hình, AWS Lambda để đánh giá nhẹ, Amazon EKS để điều phối và Amazon Mechanical Turk để xác thực của con người, một quy trình có thể được xây dựng để tự động đánh giá, xếp hạng và phát triển các lời nhắc của bạn. Thay vì cập nhật lời nhắc thủ công hoặc đánh giá lại các mô hình, hãy tập trung vào việc tạo ra một hệ thống dựa trên phản hồi liên tục cải thiện kết quả cho người dùng của bạn. Bắt đầu với một tập hợp nhỏ các mô hình và lời nhắc, xác định các chỉ số đánh giá của bạn và để hệ thống mở rộng khi các mô hình và trường hợp sử dụng mới xuất hiện.
Về tác giả

Mike (Michał) Koźmiński là Kỹ sư Chính tại Beekeeper by LumApps có trụ sở tại Zürich, nơi anh xây dựng nền tảng biến AI thành một phần hạng nhất của sản phẩm. Với hơn 10 năm kinh nghiệm trải dài từ các công ty khởi nghiệp đến doanh nghiệp, anh tập trung vào việc chuyển đổi công nghệ mới thành các hệ thống đáng tin cậy và tác động thực sự đến khách hàng.

Magdalena Gargas là Kiến trúc sư Giải pháp đam mê công nghệ và giải quyết các thách thức của khách hàng. Tại AWS, cô chủ yếu làm việc với các công ty phần mềm, giúp họ đổi mới trên đám mây.

Luca Perrozzi là Kiến trúc sư Giải pháp tại Amazon Web Services (AWS), có trụ sở tại Thụy Sĩ. Anh tập trung vào các chủ đề đổi mới tại AWS, đặc biệt trong lĩnh vực Trí tuệ Nhân tạo. Luca có bằng Tiến sĩ vật lý hạt và có 15 năm kinh nghiệm thực tế với tư cách là nhà khoa học nghiên cứu và kỹ sư phần mềm.

Simone Pomata là Kiến trúc sư Giải pháp Chính tại AWS. Anh đã làm việc nhiệt tình trong ngành công nghệ hơn 10 năm. Tại AWS, anh giúp khách hàng thành công trong việc xây dựng các công nghệ mới mỗi ngày.
