Tác giả: Liza Zinovyeva, Aiham Taleb, Callum Macpherson, Arefeh Ghahvechi, Nikita Kozodoi, Nuno Castro, và Dmitrii Ryzhov
Ngày phát hành: 08 JAN 2026
Chuyên mục: Amazon Bedrock, Amazon Textract, Customer Solutions, Foundation models, Generative AI, Healthcare, Intermediate (200)
Bài viết này dựa trên công việc được đồng phát triển với Flo Health.
Khoa học chăm sóc sức khỏe đang phát triển nhanh chóng. Việc duy trì nội dung y tế chính xác và cập nhật trực tiếp ảnh hưởng đến cuộc sống, quyết định sức khỏe và hạnh phúc của mọi người. Khi ai đó tìm kiếm thông tin sức khỏe, họ thường ở trạng thái dễ bị tổn thương nhất, khiến độ chính xác không chỉ quan trọng mà còn có khả năng cứu sống.
Flo Health tạo ra hàng nghìn bài viết y tế mỗi năm, cung cấp cho hàng triệu người dùng trên toàn thế giới thông tin đáng tin cậy về sức khỏe phụ nữ. Việc xác minh độ chính xác và mức độ liên quan của thư viện nội dung khổng lồ này là một thách thức đáng kể. Kiến thức y tế liên tục phát triển, và việc xem xét thủ công từng bài viết không chỉ tốn thời gian mà còn dễ mắc lỗi của con người. Đây là lý do tại sao nhóm tại Flo Health, công ty đứng sau ứng dụng sức khỏe phụ nữ hàng đầu Flo, đang sử dụng generative AI để tạo điều kiện thuận lợi cho độ chính xác của nội dung y tế ở quy mô lớn. Thông qua quan hệ đối tác với AWS Generative AI Innovation Center, Flo Health đang phát triển một phương pháp tiếp cận đổi mới, được gọi là “Giải pháp Tối ưu hóa Đánh giá và Sửa đổi Nội dung Y tế Tự động” (MACROS) để xác minh và duy trì độ chính xác của thư viện thông tin sức khỏe rộng lớn của mình. Giải pháp được hỗ trợ bởi AI này có khả năng:
- Xử lý hiệu quả khối lượng lớn nội dung y tế dựa trên các nguồn khoa học đáng tin cậy.
- Xác định các thông tin không chính xác hoặc lỗi thời tiềm ẩn dựa trên các nguồn khoa học đáng tin cậy.
- Đề xuất cập nhật dựa trên nghiên cứu và hướng dẫn y tế mới nhất, cũng như kết hợp phản hồi của người dùng.
Hệ thống được hỗ trợ bởi Amazon Bedrock cho phép Flo Health thực hiện đánh giá và sửa đổi nội dung y tế ở quy mô lớn, đảm bảo độ chính xác cập nhật và hỗ trợ đưa ra quyết định chăm sóc sức khỏe sáng suốt hơn. Hệ thống này thực hiện phân tích nội dung chi tiết, cung cấp những hiểu biết toàn diện về các tiêu chuẩn y tế và tuân thủ hướng dẫn để các chuyên gia y tế của Flo xem xét. Nó cũng được thiết kế để tích hợp liền mạch với cơ sở hạ tầng công nghệ hiện có của Flo, tạo điều kiện cập nhật tự động khi thích hợp.
Loạt bài gồm hai phần này khám phá hành trình của Flo Health với generative AI để xác minh nội dung y tế. Phần 1 xem xét bằng chứng khái niệm (PoC) của chúng tôi, bao gồm giải pháp ban đầu, khả năng và kết quả ban đầu. Phần 2 tập trung vào các thách thức về mở rộng quy mô và triển khai thực tế. Mỗi bài viết có thể đứng độc lập trong khi cùng nhau cho thấy cách AI biến đổi quản lý nội dung y tế ở quy mô lớn.
Mục tiêu và tiêu chí thành công của Proof of Concept
Trước khi đi sâu vào giải pháp kỹ thuật, chúng tôi đã thiết lập các mục tiêu rõ ràng cho hệ thống đánh giá nội dung y tế PoC của mình:
Mục tiêu chính:
- Xác thực tính khả thi của việc sử dụng generative AI để xác minh nội dung y tế
- Xác định mức độ chính xác so với đánh giá thủ công
- Đánh giá thời gian xử lý và cải thiện chi phí
Các chỉ số thành công:
- Độ chính xác: Khả năng thu hồi nội dung đạt 90%
- Hiệu quả: Giảm thời gian phát hiện từ hàng giờ xuống còn vài phút cho mỗi hướng dẫn
- Giảm chi phí: Giảm khối lượng công việc đánh giá của chuyên gia
- Chất lượng: Duy trì các tiêu chuẩn biên tập và độ chính xác y tế của Flo
- Tốc độ: Nhanh hơn 10 lần so với quy trình đánh giá thủ công
Để xác minh giải pháp đáp ứng các tiêu chuẩn cao của Flo Health về nội dung y tế, các chuyên gia y tế và nhóm nội dung của Flo Health đã làm việc chặt chẽ với các chuyên gia kỹ thuật của AWS thông qua các buổi đánh giá thường xuyên, cung cấp phản hồi quan trọng và chuyên môn y tế để liên tục nâng cao hiệu suất và độ chính xác của mô hình AI. Kết quả là MACROS, giải pháp tùy chỉnh của chúng tôi để xác minh nội dung y tế được hỗ trợ bởi AI.
Tổng quan giải pháp
Trong phần này, chúng tôi phác thảo cách giải pháp MACROS sử dụng Amazon Bedrock và các dịch vụ AWS khác để tự động hóa việc đánh giá và sửa đổi nội dung y tế.
Hình 1. Tổng quan giải pháp tối ưu hóa đánh giá và sửa đổi nội dung y tế tự động
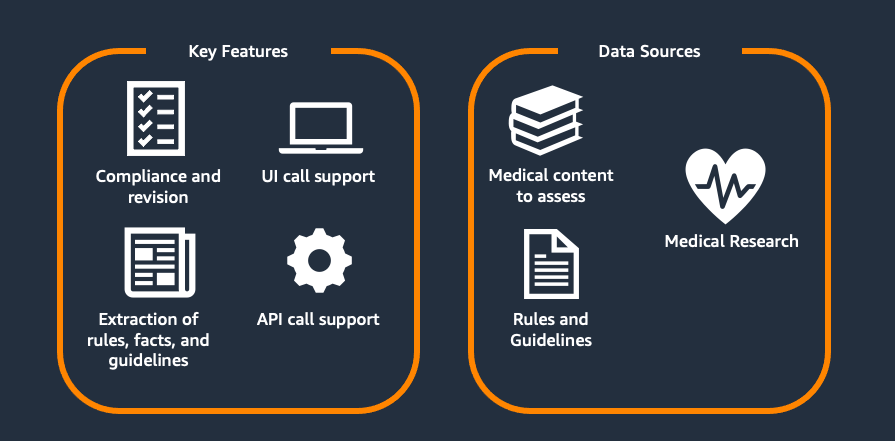
Như được hiển thị trong Hình 1, giải pháp được phát triển hỗ trợ hai quy trình chính:
- Đánh giá và Sửa đổi Nội dung: Cho phép tuân thủ các tiêu chuẩn y tế và phong cách của các bài viết y tế hiện có ở quy mô lớn dựa trên các quy tắc và hướng dẫn tùy chỉnh được chỉ định trước và đề xuất một bản sửa đổi phù hợp với các tiêu chuẩn y tế mới cũng như hướng dẫn về phong cách và giọng điệu của Flo.
- Tối ưu hóa Quy tắc: MACROS đẩy nhanh quá trình trích xuất các hướng dẫn (y tế) mới từ nghiên cứu (y tế), tiền xử lý chúng thành định dạng cần thiết để đánh giá nội dung, cũng như tối ưu hóa chất lượng của chúng.
Cả hai bước có thể được thực hiện thông qua giao diện người dùng (UI) cũng như gọi API trực tiếp. Hỗ trợ UI cho phép các chuyên gia y tế trực tiếp xem số liệu thống kê đánh giá nội dung, tương tác với các thay đổi và thực hiện điều chỉnh thủ công. Hỗ trợ gọi API dành cho việc tích hợp vào quy trình để đánh giá định kỳ.
Kiến trúc
Hình 2 mô tả kiến trúc của MACROS. Nó bao gồm hai phần chính: backend và frontend.
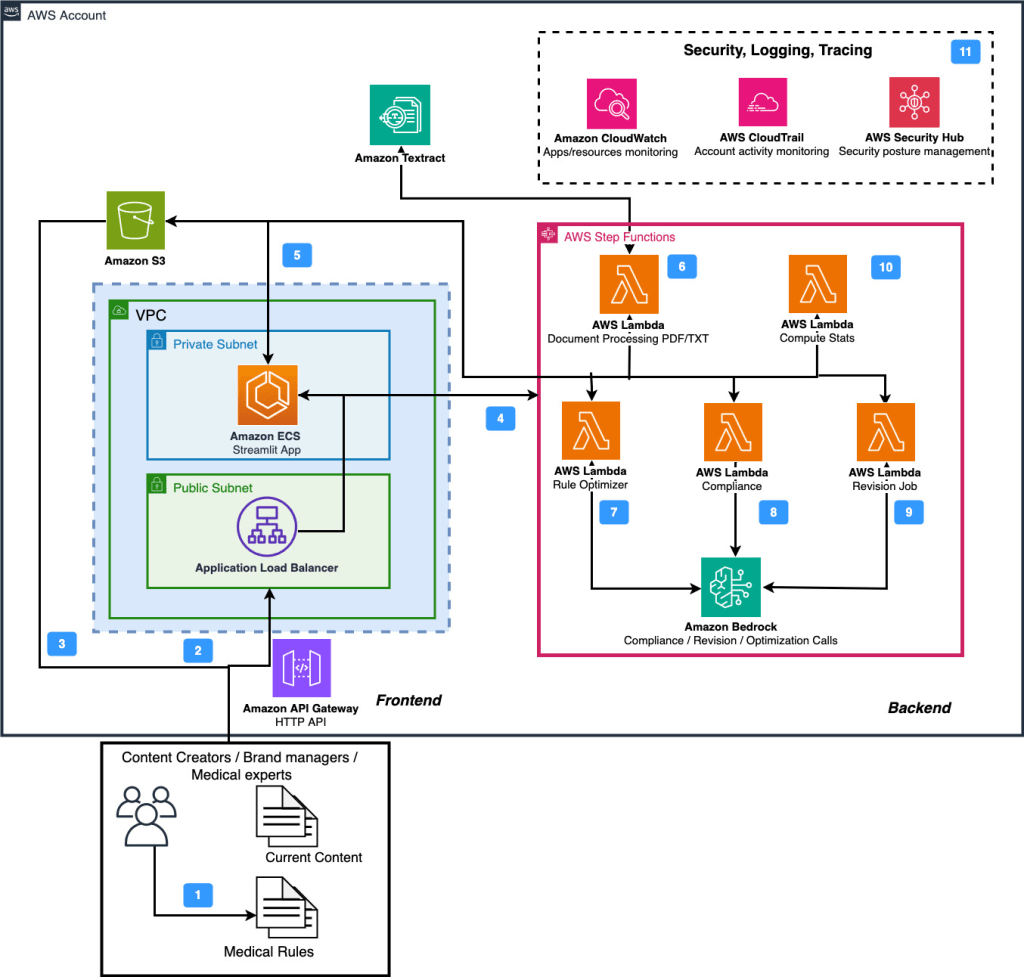
Hình 2. Kiến trúc MACROS
Sau đây, luồng của các thành phần ứng dụng chính được trình bày:
- Người dùng bắt đầu bằng cách thu thập và chuẩn bị nội dung phải đáp ứng các tiêu chuẩn và quy tắc y tế.
- Ở bước thứ hai, dữ liệu được cung cấp dưới dạng tệp PDF, TXT hoặc văn bản thông qua Streamlit UI được lưu trữ trong Amazon Elastic Container Service (ECS). Xác thực để tải tệp lên diễn ra thông qua Amazon API Gateway.
- Ngoài ra, các tệp JSON tùy chỉnh của Flo Health có thể được tải trực tiếp lên Amazon Simple Storage Service (S3) bucket của stack giải pháp.
- Frontend được lưu trữ trên ECS có quyền AWS IAM để điều phối các tác vụ bằng cách sử dụng AWS Step Functions.
- Hơn nữa, container ECS có quyền truy cập vào S3 để liệt kê, tải xuống và tải lên các tệp thông qua URL được ký trước hoặc boto3.
- Tùy chọn, nếu tệp đầu vào được tải lên qua UI, giải pháp sẽ gọi dịch vụ AWS Step Functions bắt đầu chức năng tiền xử lý được lưu trữ bởi một hàm AWS Lambda. Lambda này có quyền truy cập vào Amazon Textract để trích xuất văn bản từ các tệp PDF. Các tệp được lưu trữ trong S3 và cũng được trả về UI.
7-9. Được lưu trữ trên AWS Lambda, các chức năng Rule Optimizer, Content Review và Revision được điều phối thông qua AWS Step Function. Chúng có quyền truy cập vào Amazon Bedrock để sử dụng khả năng generative AI nhằm thực hiện trích xuất quy tắc từ dữ liệu phi cấu trúc, đánh giá và sửa đổi nội dung tương ứng. Hơn nữa, chúng có quyền truy cập vào S3 thông qua boto3 SDK để lưu trữ kết quả. - Hàm AWS Lambda Compute Stats có quyền truy cập vào S3 và có thể đọc và kết hợp kết quả của các lần chạy sửa đổi và đánh giá riêng lẻ.
- Giải pháp tận dụng Amazon CloudWatch để giám sát hệ thống và quản lý nhật ký. Đối với các triển khai sản xuất xử lý nội dung y tế quan trọng, khả năng giám sát có thể được mở rộng với các chỉ số và cảnh báo tùy chỉnh để cung cấp thông tin chi tiết hơn về hiệu suất hệ thống và các mẫu xử lý nội dung.
Cải tiến trong tương lai
Trong khi kiến trúc hiện tại của chúng tôi sử dụng AWS Step Functions để điều phối quy trình làm việc, chúng tôi đang khám phá tiềm năng của Amazon Bedrock Flows cho các phiên bản tương lai. Bedrock Flows cung cấp các khả năng đầy hứa hẹn để hợp lý hóa các quy trình làm việc dựa trên AI, có khả năng đơn giản hóa kiến trúc của chúng tôi và tăng cường tích hợp với các dịch vụ Bedrock khác. Giải pháp thay thế này có thể cung cấp khả năng quản lý liền mạch hơn các quy trình AI của chúng tôi, đặc biệt khi chúng tôi mở rộng quy mô và phát triển giải pháp của mình.
Đánh giá và sửa đổi nội dung
Cốt lõi của MACROS nằm ở chức năng Đánh giá và Sửa đổi Nội dung với các mô hình nền tảng Amazon Bedrock. Khối Đánh giá và Sửa đổi Nội dung bao gồm năm thành phần chính: 1) Giai đoạn Lọc tùy chọn 2) Phân đoạn 3) Đánh giá 4) Sửa đổi và 5) Hậu xử lý, được mô tả trong Hình 3.
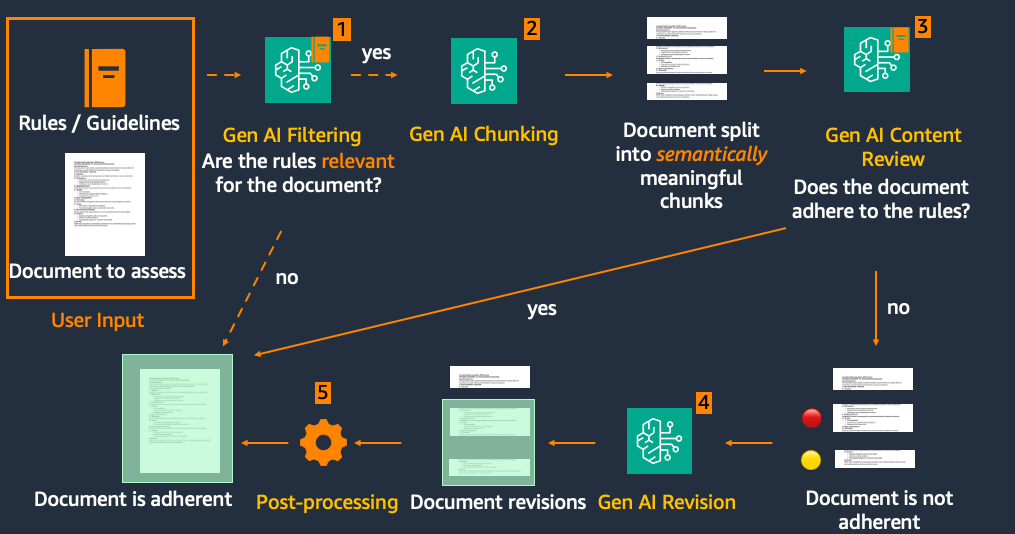
Hình 3. Quy trình đánh giá và sửa đổi nội dung
Đây là cách MACROS xử lý nội dung y tế đã tải lên:
- Lọc (Tùy chọn): Hành trình bắt đầu với một bước lọc tùy chọn. Tính năng thông minh này kiểm tra xem bộ quy tắc có liên quan đến bài viết hay không, có khả năng tiết kiệm thời gian và tài nguyên cho việc xử lý không cần thiết.
- Phân đoạn: Văn bản nguồn sau đó được chia thành các đoạn văn. Bước quan trọng này tạo điều kiện thuận lợi cho việc đánh giá chất lượng tốt và giúp ngăn chặn các sửa đổi không mong muốn đối với văn bản không liên quan. Phân đoạn có thể được thực hiện bằng cách sử dụng các phương pháp heuristic, chẳng hạn như phân tách dựa trên dấu câu hoặc biểu thức chính quy, cũng như sử dụng các mô hình ngôn ngữ lớn (LLM) để xác định các đoạn văn bản hoàn chỉnh về mặt ngữ nghĩa.
- Đánh giá: Mỗi đoạn văn hoặc phần trải qua một quá trình đánh giá kỹ lưỡng dựa trên các quy tắc và hướng dẫn liên quan.
- Sửa đổi: Chỉ các đoạn văn được gắn cờ là không tuân thủ mới được chuyển sang giai đoạn sửa đổi, hợp lý hóa quy trình và duy trì tính toàn vẹn của nội dung tuân thủ. AI đề xuất các bản cập nhật để đưa các đoạn văn không tuân thủ phù hợp với các hướng dẫn mới nhất và yêu cầu về phong cách của Flo.
- Hậu xử lý: Cuối cùng, các đoạn văn đã sửa đổi được tích hợp liền mạch trở lại văn bản gốc, tạo ra một tài liệu được cập nhật, tuân thủ.
Bước Lọc có thể được thực hiện bằng cách sử dụng một LLM bổ sung thông qua lệnh gọi Amazon Bedrock đánh giá từng phần riêng biệt với cấu trúc lời nhắc sau:
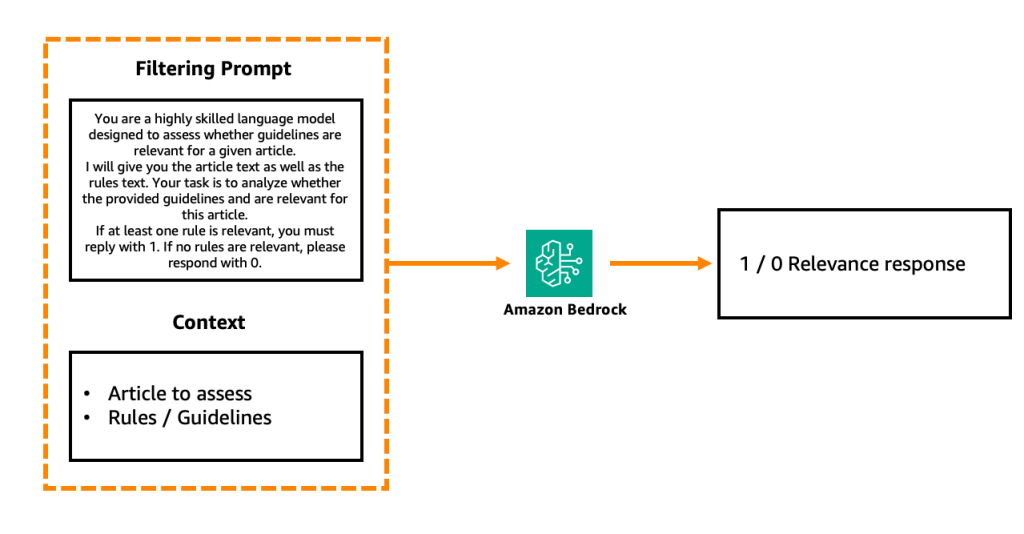
Hình 4. Bước lọc dựa trên LLM đơn giản hóa
Hơn nữa, các phương pháp không phải LLM có thể khả thi để hỗ trợ bước Lọc:
- Mã hóa các quy tắc và bài viết thành các vector nhúng dày đặc và tính toán độ tương đồng giữa chúng. Bằng cách đặt ngưỡng tương đồng, chúng ta có thể xác định bộ quy tắc nào được coi là phù hợp với tài liệu đầu vào.
- Tương tự, sự trùng lặp trực tiếp ở cấp độ từ khóa giữa tài liệu và quy tắc có thể được xác định bằng cách sử dụng các chỉ số BLEU hoặc ROUGE.
Đánh giá nội dung, như đã đề cập, được thực hiện trên cơ sở từng phần văn bản so với nhóm quy tắc và dẫn đến phản hồi ở định dạng XML, chẳng hạn như:
<xml>
<section_text> Section text without any changes </section_text>
<adherence> 0 <adherence>
<rule_name> Text of the non-adherent rule </rule_name>
<reason> Reason why the section is non-adherent to the rule </reason>
<rule_name> Text of the non-adherent rule </rule_name>
<reason> Reason why the section is non-adherent to the rule </reason>
<section_text> Section text without any changes </section_text>
<adherence> 1 <adherence>
<section_text> Section text without any changes </section_text>
<adherence> 1 <adherence>
</xml>
Ở đây, 1 cho biết sự tuân thủ và 0 – không tuân thủ của văn bản đối với các quy tắc đã chỉ định. Sử dụng định dạng XML giúp đạt được việc phân tích đầu ra đáng tin cậy.
Bước Đánh giá này lặp lại các phần trong văn bản để đảm bảo rằng LLM chú ý đến từng phần riêng biệt, điều này dẫn đến kết quả mạnh mẽ hơn trong thử nghiệm của chúng tôi. Để tạo điều kiện cho độ chính xác phát hiện phần không tuân thủ cao hơn, người dùng cũng có thể sử dụng chế độ Multi-call, trong đó thay vì một lệnh gọi Amazon Bedrock đánh giá sự tuân thủ của bài viết đối với tất cả các quy tắc, chúng ta có một lệnh gọi độc lập cho mỗi quy tắc.
Bước Sửa đổi nhận đầu ra của Đánh giá (các phần không tuân thủ và lý do không tuân thủ), cũng như hướng dẫn tạo bản sửa đổi với giọng điệu tương tự. Sau đó, nó đề xuất các sửa đổi của các câu không tuân thủ theo phong cách tương tự như văn bản gốc. Cuối cùng, bước Hậu xử lý kết hợp văn bản gốc với các sửa đổi mới, đảm bảo rằng không có phần nào khác bị thay đổi.
Các bước khác nhau của luồng yêu cầu các mức độ phức tạp của mô hình LLM khác nhau. Trong khi các tác vụ đơn giản hơn như phân đoạn có thể được thực hiện hiệu quả với một mô hình tương đối nhỏ như họ mô hình Claude Haiku, các tác vụ suy luận phức tạp hơn như đánh giá và sửa đổi nội dung yêu cầu các mô hình lớn hơn như họ mô hình Claude Sonnet hoặc Opus để tạo điều kiện phân tích chính xác và tạo nội dung chất lượng cao. Cách tiếp cận phân cấp này để lựa chọn mô hình tối ưu hóa cả hiệu suất và hiệu quả chi phí của giải pháp.
Chế độ hoạt động
Tính năng Đánh giá và Sửa đổi Nội dung hoạt động ở hai chế độ UI: Xử lý Tài liệu Chi tiết và Xử lý Nhiều Tài liệu, mỗi chế độ phục vụ các quy mô quản lý nội dung khác nhau. Chế độ Xử lý Tài liệu Chi tiết cung cấp một cách tiếp cận chi tiết để đánh giá nội dung và được mô tả trong Hình 5. Người dùng có thể tải lên tài liệu ở nhiều định dạng khác nhau (PDF, TXT, JSON hoặc dán văn bản trực tiếp) và chỉ định các hướng dẫn mà nội dung sẽ được đánh giá.

Hình 5. Ví dụ về Xử lý tài liệu chi tiết
Người dùng có thể chọn từ các bộ quy tắc được xác định trước, ở đây là Vitamin D, Sức khỏe Vú, và Hội chứng Tiền kinh nguyệt và Rối loạn Tiền kinh nguyệt (PMS và PMDD), hoặc nhập các hướng dẫn tùy chỉnh. Các hướng dẫn tùy chỉnh này có thể bao gồm các quy tắc như “Tiêu đề bài viết phải chính xác về mặt y tế” cũng như các ví dụ về nội dung tuân thủ và không tuân thủ quy tắc.
Các bộ quy tắc đảm bảo rằng việc đánh giá phù hợp với các tiêu chuẩn y tế cụ thể và hướng dẫn phong cách độc đáo của Flo. Giao diện cho phép điều chỉnh nhanh chóng, làm cho nó trở nên lý tưởng cho việc xem xét tài liệu cá nhân, kỹ lưỡng. Đối với các hoạt động quy mô lớn hơn, nên sử dụng chế độ Xử lý Nhiều Tài liệu. Chế độ này được thiết kế để xử lý đồng thời nhiều tệp JSON tùy chỉnh, mô phỏng cách Flo sẽ tích hợp MACROS vào hệ thống quản lý nội dung của họ.
Trích xuất quy tắc và hướng dẫn từ dữ liệu phi cấu trúc
Các hướng dẫn có thể hành động và được chuẩn bị tốt không phải lúc nào cũng có sẵn ngay lập tức. Đôi khi chúng được cung cấp trong các tệp phi cấu trúc hoặc cần được tìm thấy. Sử dụng tính năng Rule Optimizer, chúng ta có thể trích xuất và tinh chỉnh các hướng dẫn có thể hành động từ nhiều tài liệu phức tạp.
Rule Optimizer xử lý các tài liệu PDF thô để trích xuất văn bản, sau đó được phân đoạn thành các phần có ý nghĩa dựa trên tiêu đề tài liệu. Nội dung được phân đoạn này được xử lý thông qua Amazon Bedrock bằng cách sử dụng các lời nhắc hệ thống chuyên biệt, với hai chế độ riêng biệt: chế độ Phong cách/giọng điệu và chế độ Y tế.
Chế độ Phong cách/giọng điệu tập trung vào việc trích xuất các hướng dẫn về cách viết văn bản, phong cách của nó, các định dạng và từ ngữ có thể hoặc không thể được sử dụng.
Rule Optimizer gán mức độ ưu tiên cho mỗi quy tắc: cao, trung bình và thấp. Mức độ ưu tiên cho biết tầm quan trọng của quy tắc, hướng dẫn thứ tự đánh giá nội dung và tập trung sự chú ý vào các lĩnh vực quan trọng trước tiên. Rule Optimizer bao gồm giao diện chỉnh sửa thủ công nơi người dùng có thể tinh chỉnh văn bản quy tắc, điều chỉnh phân loại và quản lý mức độ ưu tiên. Do đó, nếu người dùng cần cập nhật một quy tắc nhất định, các thay đổi sẽ được lưu trữ để sử dụng trong tương lai trong Amazon S3.
Chế độ Y tế được thiết kế để xử lý các tài liệu y tế và được điều chỉnh theo ngôn ngữ khoa học hơn. Nó cho phép nhóm các quy tắc được trích xuất thành ba loại:
- Hướng dẫn về tình trạng y tế
- Hướng dẫn cụ thể về điều trị
- Thay đổi về lời khuyên và xu hướng sức khỏe
Hình 6. Lời nhắc tối ưu hóa quy tắc y tế đơn giản hóa
Hình 6 cung cấp một ví dụ về lời nhắc tối ưu hóa quy tắc y tế, bao gồm ba thành phần chính: thiết lập vai trò – chuyên gia AI y tế, mô tả những gì tạo nên một quy tắc tốt và cuối cùng là đầu ra mong đợi. Chúng tôi xác định chất lượng đủ tốt cho một quy tắc nếu nó:
- Rõ ràng, không mơ hồ và có thể hành động
- Liên quan, nhất quán và súc tích (tối đa hai câu)
- Được viết bằng giọng văn chủ động
- Tránh các thuật ngữ không cần thiết
Các cân nhắc và thách thức trong triển khai
Trong quá trình phát triển PoC của chúng tôi, chúng tôi đã xác định một số cân nhắc quan trọng có lợi cho những người khác triển khai các giải pháp tương tự:
- Chuẩn bị dữ liệu: Đây nổi lên như một thách thức cơ bản. Chúng tôi đã học được tầm quan trọng của việc chuẩn hóa các định dạng đầu vào cho cả nội dung y tế và hướng dẫn trong khi duy trì cấu trúc tài liệu nhất quán. Việc tạo ra các bộ thử nghiệm đa dạng trên các chủ đề y tế khác nhau đã chứng tỏ là cần thiết để xác thực toàn diện.
- Quản lý chi phí: Giám sát và tối ưu hóa chi phí nhanh chóng trở thành ưu tiên hàng đầu. Chúng tôi đã triển khai theo dõi việc sử dụng token và tối ưu hóa thiết kế lời nhắc và xử lý hàng loạt để cân bằng hiệu suất và hiệu quả.
- Tuân thủ quy định và đạo đức: Với tính chất nhạy cảm của nội dung y tế, các biện pháp bảo vệ quy định và đạo đức nghiêm ngặt là rất quan trọng. Chúng tôi đã thiết lập các thực hành tài liệu mạnh mẽ cho các quyết định của AI, triển khai kiểm soát phiên bản nghiêm ngặt cho các hướng dẫn y tế và giám sát liên tục của chuyên gia y tế đối với các đề xuất do AI tạo ra. Các quy định chăm sóc sức khỏe khu vực đã được xem xét cẩn thận trong suốt quá trình triển khai.
- Tích hợp và mở rộng quy mô: Chúng tôi khuyên bạn nên bắt đầu với một môi trường thử nghiệm độc lập trong khi lập kế hoạch tích hợp hệ thống quản lý nội dung (CMS) trong tương lai thông qua các điểm cuối API được thiết kế tốt. Xây dựng với tính mô đun đã chứng tỏ giá trị cho các cải tiến trong tương lai. Trong suốt quá trình, chúng tôi đã phải đối mặt với những thách thức chung như duy trì ngữ cảnh trong các bài viết y tế dài, cân bằng tốc độ xử lý với độ chính xác và tạo điều kiện cho giọng điệu nhất quán trong các sửa đổi do AI đề xuất.
- Tối ưu hóa mô hình: Khả năng lựa chọn mô hình đa dạng của Amazon Bedrock đã chứng tỏ giá trị đặc biệt. Thông qua nền tảng của nó, chúng tôi có thể chọn các mô hình tối ưu cho các tác vụ cụ thể, đạt được hiệu quả chi phí mà không phải hy sinh độ chính xác và nâng cấp suôn sẻ lên các mô hình mới hơn – tất cả trong khi duy trì kiến trúc hiện có của chúng tôi.
Kết quả sơ bộ
Bằng chứng khái niệm của chúng tôi đã mang lại kết quả mạnh mẽ trên các chỉ số thành công quan trọng, chứng minh tiềm năng của việc đánh giá nội dung y tế được hỗ trợ bởi AI. Giải pháp đã vượt quá mục tiêu cải thiện tốc độ xử lý trong khi duy trì độ chính xác 80% và khả năng thu hồi hơn 90% trong việc xác định nội dung cần cập nhật. Đáng chú ý nhất, hệ thống được hỗ trợ bởi AI đã áp dụng các hướng dẫn y tế nhất quán hơn so với các đánh giá thủ công và giảm đáng kể gánh nặng thời gian cho các chuyên gia y tế.
Những điểm chính
Trong quá trình triển khai, chúng tôi đã khám phá ra một số hiểu biết quan trọng để tối ưu hóa hiệu suất AI trong phân tích nội dung y tế. Phân đoạn nội dung là điều cần thiết để đánh giá chính xác trên các tài liệu dài, và việc xác thực các quy tắc phân tích của chuyên gia đã giúp các chuyên gia y tế duy trì độ chính xác lâm sàng. Quan trọng nhất, dự án đã xác nhận rằng sự hợp tác giữa con người và AI – chứ không phải tự động hóa hoàn toàn – là chìa khóa để triển khai thành công. Phản hồi thường xuyên của chuyên gia và các chỉ số hiệu suất rõ ràng đã hướng dẫn việc tinh chỉnh hệ thống và cải tiến gia tăng. Mặc dù hệ thống hợp lý hóa đáng kể quy trình đánh giá, nhưng nó hoạt động tốt nhất như một công cụ tăng cường, với các chuyên gia y tế vẫn đóng vai trò thiết yếu trong việc xác thực cuối cùng, tạo ra một cách tiếp cận kết hợp hiệu quả hơn để quản lý nội dung y tế.
Kết luận và các bước tiếp theo
Phần đầu tiên của loạt bài này của chúng tôi chứng minh cách generative AI có thể làm cho quy trình đánh giá nội dung y tế nhanh hơn, hiệu quả hơn và có thể mở rộng trong khi vẫn duy trì độ chính xác cao. Hãy theo dõi Phần 2 của loạt bài này, nơi chúng tôi sẽ đề cập đến hành trình sản xuất, đi sâu vào các thách thức và chiến lược mở rộng quy mô. Bạn đã sẵn sàng đưa các sáng kiến AI của mình vào sản xuất chưa?
- Tìm hiểu thêm về AWS Generative AI Innovation Center và liên hệ với Quản lý tài khoản AWS của bạn để được kết nối với hướng dẫn và hỗ trợ chuyên môn của chúng tôi.
- Truy cập tài liệu Amazon Bedrock để tìm hiểu thêm về các mô hình nền tảng có sẵn và khả năng của chúng.
- Tham gia cộng đồng AWS Builder của chúng tôi để kết nối với những người khác trên hành trình AI tương tự.
Về tác giả

Liza (Elizaveta) Zinovyeva, Ph.D., là một Nhà khoa học ứng dụng tại AWS Generative AI Innovation Center và làm việc tại Berlin. Cô giúp khách hàng trong các ngành khác nhau tích hợp Generative AI vào các ứng dụng và quy trình làm việc hiện có của họ. Cô đam mê các chủ đề AI/ML, tài chính và bảo mật phần mềm. Trong thời gian rảnh rỗi, cô thích dành thời gian cho gia đình, thể thao, học hỏi các công nghệ mới và các câu đố trên bàn.

Callum Macpherson là một Nhà khoa học dữ liệu tại AWS Generative AI Innovation Center, nơi AI tiên tiến gặp gỡ sự chuyển đổi kinh doanh trong thế giới thực. Callum hợp tác trực tiếp với khách hàng AWS để thiết kế, xây dựng và mở rộng các giải pháp generative AI nhằm mở khóa các cơ hội mới, tăng tốc đổi mới và mang lại tác động có thể đo lường được trên các ngành.

Arefeh Ghahvechi là một Chiến lược gia AI cấp cao tại AWS GenAI Innovation Center, chuyên giúp khách hàng nhận ra giá trị nhanh chóng từ các công nghệ generative AI bằng cách kết nối đổi mới và triển khai. Cô xác định các cơ hội AI có tác động cao trong khi xây dựng các khả năng tổ chức cần thiết để áp dụng quy mô lớn trên các doanh nghiệp và sáng kiến quốc gia.

Nuno Castro là Giám đốc Khoa học Ứng dụng cấp cao. Ông có 19 năm kinh nghiệm trong lĩnh vực này ở các ngành như tài chính, sản xuất và du lịch, lãnh đạo các nhóm ML trong 11 năm.

Dmitrii Ryzhov là Giám đốc tài khoản cấp cao tại Amazon Web Services (AWS), giúp các công ty kỹ thuật số bản địa khai thác tiềm năng kinh doanh thông qua AI, generative AI và các công nghệ đám mây. Ông làm việc chặt chẽ với khách hàng để xác định các sáng kiến kinh doanh có tác động cao và đẩy nhanh việc thực hiện bằng cách điều phối hỗ trợ chiến lược của AWS, bao gồm quyền truy cập vào chuyên môn, tài nguyên và các chương trình đổi mới phù hợp.

Nikita Kozodoi, PhD, là một Nhà khoa học ứng dụng cấp cao tại AWS Generative AI Innovation Center, làm việc ở biên giới nghiên cứu AI và kinh doanh. Nikita xây dựng và triển khai các giải pháp generative AI và ML giải quyết các vấn đề trong thế giới thực và thúc đẩy tác động kinh doanh cho khách hàng AWS trên các ngành.

Aiham Taleb, PhD, là một Nhà khoa học ứng dụng cấp cao tại Generative AI Innovation Center, làm việc trực tiếp với các khách hàng doanh nghiệp của AWS để tận dụng Gen AI trên một số trường hợp sử dụng có tác động cao. Aiham có bằng tiến sĩ về học biểu diễn không giám sát, và có kinh nghiệm trong ngành trải rộng trên nhiều ứng dụng học máy khác nhau, bao gồm thị giác máy tính, xử lý ngôn ngữ tự nhiên và hình ảnh y tế.
