Tác giả: Caique de Almeida, Guilherme Rinaldo, Paulo Finardi, Victor Costa Beraldo, Vinicius Caridá
Ngày phát hành: 09 JAN 2026
Chuyên mục: Amazon Bedrock, Amazon Comprehend, Amazon SageMaker AI, Amazon Transcribe, Artificial Intelligence, Customer Solutions, Generative AI
Bài viết này được đồng sáng tác bởi Instituto de Ciência e Tecnologia Itaú (ICTi) và AWS.
Phân tích cảm xúc ngày càng trở nên quan trọng trong các doanh nghiệp hiện đại, cung cấp cái nhìn sâu sắc về ý kiến khách hàng, mức độ hài lòng và những thất vọng tiềm ẩn. Khi các tương tác chủ yếu diễn ra thông qua văn bản (như mạng xã hội, ứng dụng trò chuyện và đánh giá thương mại điện tử) hoặc giọng nói (như trung tâm cuộc gọi và điện thoại), các tổ chức cần những phương pháp mạnh mẽ để diễn giải các tín hiệu này ở quy mô lớn. Bằng cách xác định và phân loại chính xác trạng thái cảm xúc của khách hàng, các công ty có thể mang lại trải nghiệm chủ động, tùy chỉnh hơn, tác động tích cực đến sự hài lòng và lòng trung thành của khách hàng.
Mặc dù có giá trị chiến lược, việc triển khai các giải pháp phân tích cảm xúc toàn diện vẫn đặt ra một số thách thức. Sự mơ hồ của ngôn ngữ, sắc thái văn hóa, phương ngữ vùng miền, cách diễn đạt mỉa mai và khối lượng lớn dữ liệu thời gian thực đều đòi hỏi các kiến trúc có khả năng mở rộng và linh hoạt. Ngoài ra, trong phân tích cảm xúc dựa trên giọng nói, các đặc điểm quan trọng như ngữ điệu và ngữ âm có thể bị mất nếu âm thanh được phiên âm và xử lý thuần túy dưới dạng văn bản. Amazon Web Services (AWS) cung cấp một bộ công cụ để giải quyết những thách thức này. AWS cung cấp các dịch vụ từ thu âm và phiên âm âm thanh (Amazon Transcribe) đến phân loại cảm xúc văn bản (Amazon Comprehend), cũng như các giải pháp trung tâm liên hệ thông minh (Amazon Connect) và truyền dữ liệu thời gian thực (Amazon Kinesis).
Bài viết này, được phát triển thông qua quan hệ đối tác khoa học chiến lược giữa AWS và Instituto de Ciência e Tecnologia Itaú (ICTi), trung tâm R&D do Itaú Unibanco, ngân hàng tư nhân lớn nhất ở Mỹ Latinh duy trì, khám phá các khía cạnh kỹ thuật của phân tích cảm xúc cho cả văn bản và âm thanh. Chúng tôi trình bày các thử nghiệm so sánh nhiều mô hình ML và dịch vụ, thảo luận về các đánh đổi và cạm bẫy của từng phương pháp, đồng thời nêu bật cách các dịch vụ AWS có thể được điều phối để xây dựng các giải pháp mạnh mẽ, đầu cuối. Chúng tôi cũng đưa ra những hiểu biết sâu sắc về các hướng đi tiềm năng trong tương lai, bao gồm kỹ thuật nhắc lệnh (prompt engineering) nâng cao hơn cho các mô hình ngôn ngữ lớn (LLM) và mở rộng phạm vi phân tích dựa trên âm thanh để nắm bắt các tín hiệu cảm xúc mà dữ liệu văn bản một mình có thể bỏ lỡ. Chúng tôi khám phá phân tích cảm xúc dựa trên âm thanh qua hai giai đoạn:
- Giai đoạn 1 – Phiên âm âm thanh thành văn bản và thực hiện phân tích cảm xúc bằng cách sử dụng LLM
- Giai đoạn 2 – Phân tích cảm xúc trực tiếp từ tín hiệu âm thanh bằng cách sử dụng các mô hình âm thanh
Phân tích cảm xúc trong văn bản
Trong phần này, chúng tôi thảo luận về phương pháp phiên âm âm thanh thành văn bản và thực hiện phân tích cảm xúc bằng cách sử dụng LLM.
Thách thức và đặc điểm
Phương pháp này trình bày những thách thức sau:
- Đa dạng nguồn dữ liệu – Các tương tác văn bản xuất hiện từ nhiều kênh—mạng xã hội, nền tảng thương mại điện tử, chatbot và phiếu hỗ trợ—mỗi kênh có định dạng và ràng buộc riêng. Ví dụ, văn bản trên mạng xã hội có thể chứa hashtag, biểu tượng cảm xúc hoặc giới hạn ký tự, trong khi tin nhắn trò chuyện có thể bao gồm các từ viết tắt và biệt ngữ chuyên ngành. Do đó, một quy trình xử lý văn bản mạnh mẽ phải bao gồm các bước làm sạch và tiền xử lý dữ liệu thích hợp để chuẩn hóa các biến thể này.
- Sự mơ hồ của ngôn ngữ tự nhiên – Ngôn ngữ con người thường mơ hồ và phụ thuộc vào ngữ cảnh. Sự mỉa mai, châm biếm và các cách diễn đạt ẩn dụ làm phức tạp việc phân loại bằng các kỹ thuật xử lý ngôn ngữ tự nhiên (NLP) bề mặt. Mặc dù các mạng thần kinh sâu—như BERT, RoBERTa và các kiến trúc dựa trên Transformers—đã chứng tỏ khả năng nắm bắt ngữ nghĩa tinh tế hơn, nhưng việc giải thích đầy đủ các cách sử dụng ngôn ngữ sáng tạo hoặc phụ thuộc vào ngữ cảnh vẫn là một thách thức đang diễn ra.
- Các cân nhắc về đa ngôn ngữ và phương ngữ – Các doanh nghiệp toàn cầu như Itaú Unibanco gặp phải nhiều ngôn ngữ và phương ngữ vùng miền, mỗi ngôn ngữ đòi hỏi các mô hình chuyên biệt hoặc dữ liệu đào tạo bổ sung. Một mô hình cảm xúc được đào tạo chủ yếu trên một ngôn ngữ hoặc phương ngữ có thể thất bại khi đối mặt với tiếng lóng, thành ngữ hoặc cấu trúc ngữ pháp đặc trưng từ một ngôn ngữ khác.
Các mô hình đã thử nghiệm và lý do
Trong các thử nghiệm của chúng tôi, chúng tôi đã đánh giá một số LLM tập trung vào phân loại cảm xúc. Trong số đó có các mô hình nền tảng (FM) phổ biến có sẵn thông qua Amazon Bedrock và Amazon SageMaker JumpStart, chẳng hạn như Llama 3 70B của Meta, Claude 3.5 Sonnet của Anthropic, Mixtral 8x7B của Mistral AI và Amazon Nova Pro. Mỗi dịch vụ cung cấp những lợi thế riêng dựa trên nhu cầu cụ thể. Ví dụ, Amazon Bedrock đơn giản hóa việc thử nghiệm quy mô lớn bằng cách cung cấp một giao diện thống nhất, phi máy chủ cho nhiều nhà cung cấp LLM thông qua truy cập dựa trên API. SageMaker AI cung cấp trải nghiệm quản lý máy chủ để truy cập các FM phổ biến với giao diện người dùng thân thiện hoặc triển khai và quản lý dựa trên API. Cả Amazon Bedrock và SageMaker AI đều hợp lý hóa các vấn đề vận hành như lưu trữ mô hình, khả năng mở rộng, bảo mật và tối ưu hóa chi phí—những lợi ích chính cho việc áp dụng AI tạo sinh trong doanh nghiệp.
Chúng tôi đã thử nghiệm từng mô hình trong hai cấu hình:
- Nhắc lệnh zero-shot hoặc few-shot – Sử dụng các nhắc lệnh chung để phân loại cảm xúc trong văn bản
- Tinh chỉnh (Fine-tuning) – Điều chỉnh mô hình trên dữ liệu cảm xúc chuyên biệt theo miền để đánh giá xem liệu việc đào tạo chuyên biệt này có cải thiện hiệu suất hay có nguy cơ quá khớp (overfitting) hay không
Các dịch vụ AWS để phân tích văn bản
Amazon cung cấp một bộ dịch vụ để giúp hợp lý hóa quy trình phân tích văn bản. Đối với bài viết này, chúng tôi đã sử dụng các dịch vụ sau để xây dựng dịch vụ phân tích văn bản:
- Amazon Bedrock – Tạo điều kiện truy cập phi máy chủ vào các FM được đào tạo trước từ các nhà cung cấp khác nhau trong một giao diện an toàn, duy nhất—đặc biệt là truy cập vào các mô hình trọng số đóng như Claude của Anthropic. Điều này cho phép thử nghiệm nhanh chóng nhiều mô hình mà không cần quản lý cơ sở hạ tầng bên dưới.
- Amazon SageMaker AI – Cung cấp quyền truy cập vào các FM mã nguồn mở mới nhất như Llama, Mistral, DeepSeek, v.v. Với SageMaker AI, bạn có tùy chọn đơn giản hóa việc triển khai FM bằng cách sử dụng Amazon SageMaker JumpStart—một trung tâm quản lý ML và AI tạo sinh cung cấp triển khai hàng trăm FM dựa trên UI hoặc API đơn giản hoặc thay vào đó giúp bạn triển khai FM và kiến trúc ưa thích của mình trên cơ sở hạ tầng GPU NVIDIA được quản lý một cách dễ dàng.
- Amazon Comprehend – Một dịch vụ AI với khả năng phân tích văn bản bao gồm phân tích cảm xúc, nhận dạng thực thể và mô hình hóa chủ đề. Nó có thể đóng vai trò là đường cơ sở hoặc được tích hợp với các quy trình làm việc LLM nâng cao để có một quy trình toàn diện hơn.
- Amazon Kinesis – Xử lý việc nhập và truyền dữ liệu văn bản theo thời gian thực từ các nguồn đa dạng (chẳng hạn như nguồn cấp dữ liệu mạng xã hội, luồng nhật ký hoặc phiên trò chuyện khách hàng thời gian thực).
Một kiến trúc đơn giản hóa có thể bao gồm các thành phần sau:
- Nhập dữ liệu bằng Kinesis để thu thập văn bản từ các nguồn khác nhau
- Tiền xử lý dữ liệu bằng AWS Lambda hoặc Amazon EMR để chuẩn hóa, mã hóa và lọc.
- Suy luận mô hình bằng cách sử dụng LLM được truy cập thông qua Amazon Bedrock hoặc SageMaker AI
- Lưu trữ và phân tích trong Amazon Simple Storage Service (Amazon S3) hoặc Amazon Redshift để phân tích, báo cáo và trực quan hóa dài hạn
Kết quả thử nghiệm cho văn bản
Bảng sau tóm tắt các chỉ số hiệu suất (độ chính xác, độ chính xác, độ thu hồi) trên các mô hình khác nhau đã được thử nghiệm. Mỗi mô hình được đánh giá trên cùng một tập dữ liệu văn bản với mục tiêu phân loại câu là tích cực, tiêu cực hoặc trung tính.
| Mô hình | Độ chính xác (Accuracy) | Độ chính xác (Precision) | Độ thu hồi (Recall) |
|---|---|---|---|
| Amazon SageMaker JumpStart Llama 3 70B Instruct v1 | 0.189 | 0.527 | 0.189 |
| Amazon Bedrock Anthropic Claude 3.5 Sonnet 2024-06-20-v1 | 0.187 | 0.44 | 0.187 |
| Amazon SageMaker Mixtral 8x7B Instruct v0 | 0.164 | 0.545 | 0.164 |
| Amazon Bedrock Amazon Nova Pro v1 | 0.159 | 0.239 | 0.16 |
| LLM tiên tiến nguồn đóng 1 (>50B) | 0.159 | 0.025 | 0.159 |
| LLM tiên tiến nguồn đóng 2 (>50B) | 0.159 | 0.025 | 0.159 |
Phân tích kết quả
Chúng tôi đã quan sát thấy những điều sau từ kết quả của mình:
- Hiệu suất tổng thể thấp – Tất cả các mô hình đều cho thấy độ chính xác tương đối thấp trong việc phát hiện phân cực cảm xúc. Điều này cho thấy các đầu vào chỉ dựa trên văn bản có thể không cung cấp đủ ngữ cảnh hoặc tín hiệu cảm xúc, đặc biệt đối với các cách diễn đạt tinh tế hơn như mỉa mai hoặc châm biếm.
- Tác động của tinh chỉnh – Hai mô hình OpenAI được tinh chỉnh đạt được các chỉ số cao hơn hầu hết các cấu hình khác, mặc dù sự gia tăng hiệu suất có thể cho thấy sự quá khớp. Chúng nhất quán gắn nhãn các câu là không trung tính chỉ khi có một chỉ báo cảm xúc mạnh mẽ.
- Sự khác biệt của mô hình – Llama 3 70B của Meta và Claude 3.5 Sonnet của Anthropic hoạt động tốt hơn một số mô hình cơ sở khác nhưng vẫn dưới các giải pháp OpenAI được tinh chỉnh. Điều này có thể phản ánh các mục tiêu tiền đào tạo của chúng và sự khác biệt về miền giữa dữ liệu đào tạo ban đầu của chúng và nhiệm vụ phân loại cảm xúc của chúng tôi.
Các hướng đi tương lai cho phân tích dựa trên văn bản
Bạn có thể xem xét mở rộng phân tích dựa trên văn bản của mình theo những cách sau:
- Kỹ thuật nhắc lệnh nâng cao – Các thử nghiệm hiện tại đã sử dụng các nhắc lệnh chuỗi suy nghĩ (chain-of-thought) đơn giản. Công việc trong tương lai có thể khám phá các thiết kế nhắc lệnh few-shot hoặc zero-shot tinh tế hơn, bao gồm các chiến lược suy luận nâng cao như “buffer of thoughts” hoặc nhắc lệnh chuyên biệt theo miền được nhắm mục tiêu cẩn thận.
- Đầu vào đa phương thức – Kết hợp thông tin cận ngôn ngữ (chẳng hạn như ngữ điệu hoặc sự nhấn mạnh của người nói) có thể thúc đẩy phân loại dựa trên văn bản. Dữ liệu như vậy có thể được mã hóa dưới dạng siêu dữ liệu hoặc được trích xuất bởi các mô hình phụ trợ để làm phong phú ngữ cảnh văn bản.
- Phạm vi ngôn ngữ – Mở rộng sang các ngữ liệu phi tiếng Anh và đào tạo các mô hình đa ngôn ngữ hoặc chuyên biệt theo miền có thể cải thiện khả năng khái quát hóa trong các triển khai thực tế.
Phân tích cảm xúc trong âm thanh
Trong phần này, chúng tôi thảo luận về phương pháp phân tích cảm xúc trực tiếp từ tín hiệu âm thanh bằng cách sử dụng các mô hình âm thanh.
Thách thức và đặc điểm
Phương pháp này trình bày những thách thức sau:
- Ngữ điệu và ngữ âm – Ngôn ngữ nói mang các tín hiệu âm thanh (âm sắc, cao độ, âm lượng, nhịp độ và nhịp điệu) ảnh hưởng lớn đến cảm xúc được cảm nhận. Một lời chào đơn giản như “Chào bạn, bạn khỏe không?” có thể thực sự nhiệt tình hoặc mỉa mai một cách thụ động, tùy thuộc vào ngữ điệu. Các quy trình chuyển lời nói thành văn bản truyền thống bỏ qua các tín hiệu phi ngôn ngữ này, có khả năng làm suy yếu tín hiệu cảm xúc.
- Chuyển lời nói thành văn bản – Nhiều hệ thống phân tích cảm xúc âm thanh dựa vào ASR (Nhận dạng giọng nói tự động) để tạo bản ghi, sau đó được đưa vào các mô hình cảm xúc dựa trên văn bản. Mặc dù có lợi cho việc hiểu nội dung, phân tích thuần túy văn bản bỏ qua các đặc điểm ngữ âm—một lý do khiến việc phân loại cảm xúc trực tiếp dựa trên âm thanh đã thu hút sự quan tâm nghiên cứu.
- Tiếng ồn và chất lượng ghi âm – Âm thanh trong thế giới thực thường chứa tiếng ồn nền, đối thoại chồng chéo hoặc bản ghi chất lượng thấp. Các mô hình phải mạnh mẽ trong các điều kiện như vậy để có thể hoạt động trong các môi trường như trung tâm cuộc gọi hoặc đường dây hỗ trợ khách hàng.
Tập dữ liệu thử nghiệm
Chúng tôi đã sử dụng hai loại tập dữ liệu riêng biệt, mỗi loại tập trung vào các khía cạnh khác nhau của cảm xúc trong lời nói:
- Loại 1 – Một bộ sưu tập được tuyển chọn gồm các câu nói ngắn được ghi lại với các ngữ điệu cảm xúc khác nhau. Ban đầu được gắn nhãn theo mức độ kích thích (chẳng hạn như vui vẻ, tức giận, ghê tởm), dữ liệu sau đó được gắn nhãn lại theo giá trị (tích cực, tiêu cực, trung tính). Các bản ghi được gắn nhãn “ngạc nhiên” đã bị loại bỏ vì nó có thể biểu hiện là tích cực hoặc tiêu cực.
- Loại 2 – Chứa nhiều câu đa dạng hơn, mỗi câu được gắn nhãn là tích cực, tiêu cực hoặc trung tính. Sự đa dạng và phức tạp của các câu nói làm cho tập dữ liệu này trở nên thách thức hơn đáng kể.
- Các nguồn bao gồm tập dữ liệu Audio Speech Sentiment và MELD.
Các mô hình đã thử nghiệm và lý do
Chúng tôi đã đánh giá ba mô hình dựa trên giọng nói nổi bật:
- HuBERT (Hidden Unit BERT) – Sử dụng một Transformer tự giám sát học các gán cụm ẩn trong tín hiệu âm thanh. HuBERT vượt trội trong việc nắm bắt các mẫu ngữ âm và âm thanh quan trọng để phát hiện cảm xúc.
- Wav2Vec – Tương tự về triết lý với HuBERT, Wav2Vec học các biểu diễn mạnh mẽ trực tiếp từ âm thanh thô bằng cách sử dụng xương sống bộ mã hóa Transformer. Sơ đồ đào tạo tự giám sát của nó rất hiệu quả với dữ liệu được gắn nhãn hạn chế.
- Whisper – Một bộ mã hóa-giải mã dựa trên Transformer ban đầu được thiết kế để nhận dạng giọng nói mạnh mẽ. Mặc dù trọng tâm của nó là phiên âm và dịch thuật, chúng tôi đã thử nghiệm khả năng của nó trong việc trích xuất các nhúng (embeddings) cho các tác vụ phân loại cảm xúc hạ nguồn.
Các dịch vụ AWS để phân tích âm thanh
Để hợp lý hóa quy trình đào tạo và suy luận, chúng tôi đã sử dụng các dịch vụ AWS sau:
- Amazon SageMaker Studio – Cho phép thiết lập nhanh chóng các công việc đào tạo trên các phiên bản được xây dựng có mục đích (ví dụ: hỗ trợ GPU) mà không cần chi phí cơ sở hạ tầng đáng kể. Mỗi mô hình (HuBERT, Wav2Vec, Whisper) được đào tạo và xác thực trong các phiên SageMaker riêng biệt.
- Amazon Transcribe – Đối với các quy trình làm việc yêu cầu chuyển lời nói thành văn bản, Amazon Transcribe cung cấp ASR có khả năng mở rộng và chính xác. Mặc dù không phải là trọng tâm của các phương pháp cảm xúc trực tiếp dựa trên âm thanh, nó thường được tích hợp vào các kiến trúc trung tâm liên hệ, nơi bản ghi văn bản cũng được sử dụng để phân tích hoặc kiểm tra tuân thủ.
Một kiến trúc đại diện có thể bao gồm Kinesis để nhập âm thanh, Lambda để điều phối tiền xử lý hoặc lựa chọn tuyến đường (chẳng hạn như cảm xúc trực tiếp dựa trên âm thanh so với cảm xúc dựa trên văn bản sau khi phiên âm) và Amazon S3 để lưu trữ kết quả cuối cùng. Sơ đồ sau minh họa kiến trúc ví dụ này.
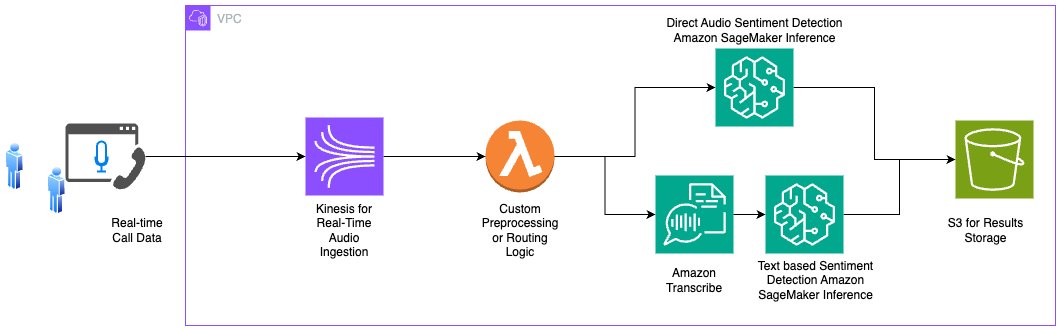
Kết quả thử nghiệm cho âm thanh
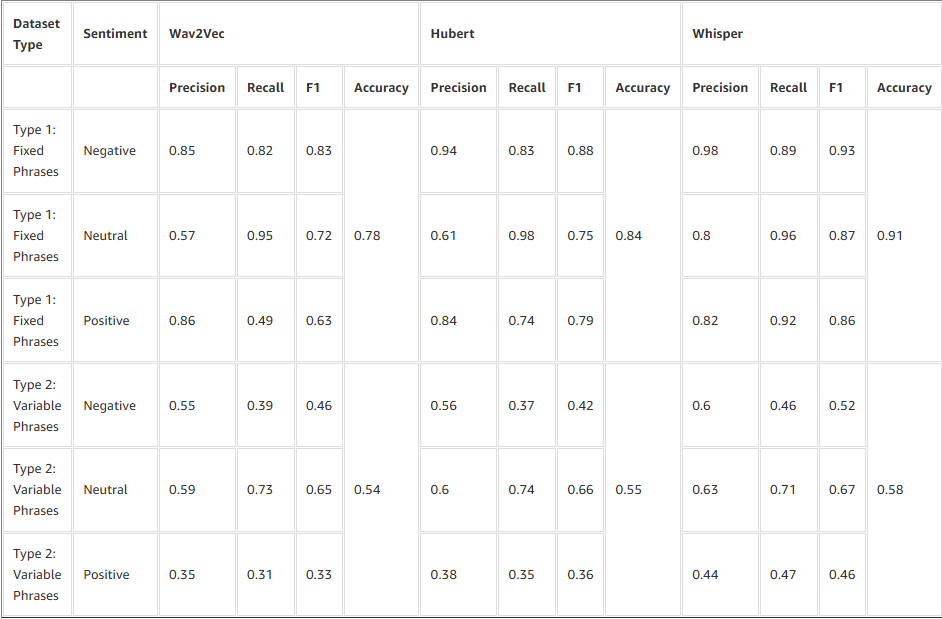
Đánh giá của chúng tôi đã xem xét độ chính xác phân loại trên các phân tách thử nghiệm riêng biệt cho tập dữ liệu Loại 1 và Loại 2. Nói chung, cả ba mô hình đều đạt được hiệu suất cao hơn trên Loại 1 so với Loại 2. Bảng sau tóm tắt các kết quả này.
Phân tích kết quả
Chúng tôi đã quan sát thấy những điều sau từ kết quả của mình:
- Loại 1 – Vì các cụm từ giống nhau được lặp lại với các ngữ điệu cảm xúc khác nhau, các mô hình tập trung nhiều hơn vào các tín hiệu âm thanh hơn là nội dung. Điều này dẫn đến độ chính xác cao hơn—đặc biệt trong việc phân biệt các trạng thái kích thích cao (tức giận, phấn khích) với các trạng thái kích thích thấp (buồn bã, bình tĩnh).
- Loại 2 – Hiệu suất giảm đáng kể khi đối mặt với các câu đa dạng hơn. Ở đây, sự khác biệt về nội dung từ vựng và ngữ cảnh đã làm lu mờ các đặc điểm thuần túy ngữ âm. Các mô hình gặp khó khăn trong việc khái quát hóa trên các cấu trúc câu đa dạng, phong cách người nói và biểu cảm cảm xúc.
Các hướng đi tương lai cho phân tích dựa trên âm thanh
Bạn có thể xem xét mở rộng phân tích dựa trên văn bản của mình theo những cách sau:
- Đa dạng dữ liệu – Mở rộng các tập dữ liệu để bao gồm nhiều ngôn ngữ, giọng địa phương và điều kiện môi trường có thể cải thiện khả năng khái quát hóa của các mô hình này.
- Kết hợp đa phương thức – Kết hợp các nhúng âm thanh trực tiếp (ngữ âm, ngữ điệu) với phân tích văn bản (nội dung từ vựng) có thể mang lại các biểu diễn cảm xúc phong phú hơn. Điều này đặc biệt phù hợp trong các kịch bản dịch vụ khách hàng, nơi cả nội dung ngữ nghĩa và giọng điệu cảm xúc đều quan trọng.
- Suy luận thời gian thực – Đối với các ứng dụng như hỗ trợ trung tâm liên hệ trực tiếp bằng Amazon Connect, các quy trình suy luận thời gian thực là rất quan trọng. Các nhà nghiên cứu có thể điều tra các phương pháp như suy luận mô hình dựa trên luồng (ví dụ: xử lý từng đoạn hoặc từng khung) để nhận phản hồi ngay lập tức về cảm xúc của khách hàng và điều chỉnh phản hồi cho phù hợp.
Kết luận
Phân tích cảm xúc—dù được thực hiện trên văn bản hay âm thanh—cung cấp những hiểu biết sâu sắc mạnh mẽ về nhận thức của khách hàng, cho phép các chiến lược tương tác chủ động và đồng cảm hơn. Tuy nhiên, các trở ngại kỹ thuật không hề nhỏ:
- Văn bản – Sự mơ hồ, mỉa mai và ngữ cảnh hạn chế có thể cản trở việc phân loại thuần túy dựa trên văn bản. LLM, ngay cả những LLM được tinh chỉnh, có thể hoạt động kém hiệu quả nếu không có sự quản lý dữ liệu cẩn thận, kỹ thuật nhắc lệnh nâng cao hoặc siêu dữ liệu bổ sung.
- Âm thanh – Phân tích trực tiếp âm thanh nắm bắt các tín hiệu ngữ âm và âm thanh thường bị mất trong quá trình phiên âm. Tuy nhiên, tiếng ồn môi trường, lời nói chồng chéo và sự đa dạng của người nói làm phức tạp việc đào tạo các mô hình mạnh mẽ.
AWS cung cấp một bộ dịch vụ mở rộng bao gồm toàn bộ quy trình phân tích cảm xúc đầu cuối:
- Nhập dữ liệu – Kinesis để truyền dữ liệu văn bản và âm thanh theo thời gian thực
- Tiền xử lý – Lambda và Amazon EMR để làm sạch dữ liệu, trích xuất đặc trưng và chuyển đổi
- Phiên âm (Tùy chọn) – Amazon Transcribe để chuyển đổi âm thanh thành văn bản nếu cần một phương pháp kết hợp văn bản và âm thanh
- Phân loại cảm xúc – AWS cung cấp những điều sau:
- Văn bản – Amazon Comprehend hoặc FM được truy cập thông qua Amazon Bedrock và SageMaker AI
- Âm thanh – Các mô hình tùy chỉnh (chẳng hạn như HuBERT, Wav2Vec, Whisper) được đào tạo trong SageMaker AI
- Tương tác với khách hàng – Amazon Connect cho các trung tâm liên hệ thông minh với tiềm năng cho các vòng phản hồi cảm xúc thời gian thực
Cuối cùng, việc lựa chọn giữa các phương pháp dựa trên âm thanh, dựa trên văn bản hoặc kết hợp phụ thuộc vào trường hợp sử dụng và dữ liệu có sẵn. Các phương pháp trực tiếp dựa trên âm thanh có thể nắm bắt các sắc thái cảm xúc quan trọng trong các tương tác của trung tâm cuộc gọi—đặc biệt trong các lời chào hoặc các cuộc trò chuyện có tính cảm xúc cao—trong khi các phương pháp dựa trên văn bản thường đơn giản hơn để triển khai ở quy mô lớn cho các cuộc trò chuyện, mạng xã hội và phân tích dựa trên đánh giá. Bằng cách sử dụng các khả năng dựa trên AWS Cloud cùng với các phương pháp ML nghiêm ngặt, các doanh nghiệp có thể điều chỉnh các giải pháp phân tích cảm xúc cân bằng giữa độ chính xác, khả năng mở rộng và hiệu quả chi phí. Các khám phá trong tương lai có thể tích hợp thêm các luồng đa phương thức, kỹ thuật nhắc lệnh nâng cao và tinh chỉnh chuyên biệt theo miền, liên tục tinh chỉnh khả năng của chúng ta để diễn giải và hành động theo “tiếng nói của khách hàng.”
Về tác giả

Caique de Almeida là Nhà khoa học dữ liệu cấp cao tại Viện Khoa học và Công nghệ Itaú (ICTI). Anh tập trung vào Xử lý ngôn ngữ tự nhiên, Học sâu và Kiến trúc đám mây, kết nối nghiên cứu ứng dụng với các hệ thống AI cấp sản xuất. Anh sở hữu 11 chứng chỉ AWS và áp dụng chuyên môn đám mây đó để xây dựng các giải pháp AI có khả năng mở rộng, đáng tin cậy. Công việc hiện tại của anh tập trung vào việc xây dựng các tác nhân hướng tới khách hàng cho các dịch vụ tài chính, áp dụng AI trong tài chính và điều tra tính xác thực và khả năng suy luận trong AI tạo sinh. Ngoài công việc, anh thích đạp xe.

Guilherme Rinaldo là Kỹ sư và Nhà nghiên cứu AI cấp cao tại Instituto de Ciência e Tecnologia Itaú (ICTI), nơi anh xây dựng và đánh giá các hệ thống AI tạo sinh cho văn bản và giọng nói, bao gồm các tác nhân dựa trên LLM và các mô hình học sâu. Với 8 năm kinh nghiệm, anh đã dẫn dắt công việc từ các nguyên mẫu nghiên cứu đến các quy trình sản xuất, với sự nhấn mạnh vào độ tin cậy, bảo mật và đánh giá nghiêm ngặt. Sở thích của anh bao gồm học liên tục, các tác nhân tự tiến hóa và giám sát mô hình ở quy mô lớn. Ngoài công việc, Guilherme thích viết lách, du lịch và chơi các trò chơi chiến lược. Bạn có thể tìm thấy Guilherme trên LinkedIn.

Paulo Finardi là Nhà khoa học dữ liệu chính tại Viện Khoa học và Công nghệ Itaú (ICTI). Anh có hơn 10 năm kinh nghiệm trong Học sâu và Xử lý ngôn ngữ tự nhiên, tập trung vào AI ứng dụng trong tài chính, mô phỏng và bản sao kỹ thuật số. Công việc của anh bao gồm nghiên cứu ứng dụng quy mô lớn, cũng như chiến lược và đổi mới AI. Ngoài công việc, anh thích đạp xe. Bạn có thể tìm thấy Finardi trên LinkedIn.

Victor Costa Beraldo là Nhà khoa học dữ liệu trưởng tại Viện Khoa học và Công nghệ Itaú (ICTi), làm việc tại giao điểm của giọng nói và AI. Với nền tảng vững chắc về xử lý tín hiệu và học sâu, anh tập trung vào các giải pháp dựa trên giọng nói, bao gồm ASR, ASV, nhận dạng cảm xúc và xử lý âm thanh thời gian thực, kết nối nghiên cứu ứng dụng và hệ thống sản xuất trong các dịch vụ tài chính. Ngoài công việc, anh thích xem các trận bóng đá. Bạn có thể tìm thấy Victor trên LinkedIn.

Vinicius Caridá là Nhà khoa học dữ liệu xuất sắc tại Itaú Unibanco và là thành viên của ủy ban khoa học và kỹ thuật tại Viện Khoa học và Công nghệ Itaú (ICTI). Anh làm việc trong các lĩnh vực AI tạo sinh, xử lý ngôn ngữ tự nhiên, trợ lý ảo, hệ thống khuyến nghị, hệ thống điều khiển và vòng đời MLOps đầu cuối. Vinicius vinh dự được công nhận là AWS AI Hero, tự hào đại diện cho Mỹ Latinh trong chương trình. Công việc hiện tại của anh tập trung vào việc xây dựng các tác nhân AI hướng tới khách hàng cho các dịch vụ tài chính và thúc đẩy tính xác thực và khả năng suy luận trong các mô hình tạo sinh. Ngoài công việc, anh thích dạy và học hỏi cùng cộng đồng công nghệ và dành thời gian cho vợ Jerusa và con gái Olivia. Bạn có thể tìm thấy Vinicius trên LinkedIn.

Pranav Murthy là Nhà khoa học dữ liệu AI tạo sinh cấp cao tại AWS, chuyên giúp các tổ chức đổi mới với AI tạo sinh, Học sâu và Học máy trên Amazon SageMaker AI. Trong hơn 10 năm qua, anh đã phát triển và mở rộng các mô hình thị giác máy tính (CV) và xử lý ngôn ngữ tự nhiên (NLP) tiên tiến để giải quyết các vấn đề có tác động lớn—từ tối ưu hóa chuỗi cung ứng toàn cầu đến kích hoạt phân tích video thời gian thực và tìm kiếm đa ngôn ngữ. Bạn có thể tìm thấy Pranav trên LinkedIn.
TAGS: AI/ML, Fine Tuning, Generative AI
