Tác giả: Avijit Goswami, Nilanjana Mukherjee, Tayven Taylor, Mimi Wang, Rahul Gidwani, Prateek Kakirwar
Ngày phát hành: 14 JAN 2026
Chuyên mục: Amazon Bedrock, Amazon EMR, Customer Solutions, Intermediate (200)
Tại Slack, nền tảng dữ liệu của chúng tôi xử lý hàng terabyte dữ liệu mỗi ngày bằng cách sử dụng Apache Spark trên Amazon EMR trên Amazon Elastic Compute Cloud (Amazon EC2), cung cấp những thông tin chi tiết thúc đẩy việc ra quyết định chiến lược trên toàn tổ chức.
Khi khối lượng dữ liệu của chúng tôi mở rộng, các thách thức về hiệu suất cũng tăng theo. Với các công cụ giám sát truyền thống, chúng tôi không thể quản lý hệ thống một cách hiệu quả khi các Spark job chậm lại hoặc chi phí tăng vọt ngoài tầm kiểm soát. Chúng tôi bị mắc kẹt trong việc tìm kiếm qua các log khó hiểu, đưa ra những phỏng đoán có cơ sở về phân bổ tài nguyên và chứng kiến các nhóm kỹ sư của chúng tôi dành hàng giờ để tinh chỉnh thủ công mà lẽ ra phải được tự động hóa. Đó là lý do tại sao chúng tôi đã xây dựng một thứ tốt hơn: một framework chỉ số chi tiết được thiết kế đặc biệt cho các thách thức độc đáo của Spark. Đây là một hệ thống hiển thị cung cấp cho chúng tôi những thông tin chi tiết chi tiết về hành vi ứng dụng, việc sử dụng tài nguyên và các mẫu hiệu suất cấp job mà chúng tôi chưa từng có trước đây. Chúng tôi đã đạt được mức giảm chi phí 30–50% và thời gian hoàn thành job nhanh hơn 40–60%. Đây là hiệu quả vận hành thực sự trực tiếp chuyển thành dịch vụ tốt hơn cho người dùng và tiết kiệm đáng kể cho ngân sách cơ sở hạ tầng của chúng tôi. Trong bài đăng này, chúng tôi sẽ hướng dẫn bạn chính xác cách chúng tôi xây dựng framework này, các chỉ số chính tạo nên sự khác biệt và cách nhóm của bạn có thể triển khai giám sát tương tự để biến đổi các hoạt động Spark của riêng bạn.
Tại sao giám sát Spark toàn diện lại quan trọng
Trong môi trường doanh nghiệp, các Spark job được tối ưu hóa kém có thể lãng phí hàng nghìn đô la chi phí tính toán trên đám mây, chặn các pipeline dữ liệu quan trọng ảnh hưởng đến các quy trình kinh doanh hạ nguồn, tạo ra các lỗi dây chuyền trên các quy trình làm việc dữ liệu được kết nối và ảnh hưởng đến việc tuân thủ thỏa thuận mức dịch vụ (SLA) cho các phân tích nhạy cảm về thời gian.
Framework giám sát mà chúng tôi đang xem xét thu thập hơn 40 chỉ số riêng biệt trên năm danh mục chính, cung cấp những thông tin chi tiết chi tiết cần thiết để ngăn chặn các vấn đề này.
Cách chúng tôi thu thập, xử lý và hành động dựa trên các chỉ số Spark
Để giải quyết các thách thức trong việc quản lý Spark ở quy mô lớn, chúng tôi đã phát triển một pipeline giám sát và tối ưu hóa tùy chỉnh—từ việc thu thập chỉ số đến tinh chỉnh được hỗ trợ bởi AI. Nó bắt đầu với framework Spark listener nội bộ của chúng tôi, thu thập hơn 40 chỉ số theo thời gian thực trên các ứng dụng, job, stage và task của Spark trong khi lấy ngữ cảnh vận hành quan trọng từ các công cụ như Apache Airflow và Apache Hadoop YARN.
Một Spark SQL pipeline được điều phối bởi Apache Airflow chuyển đổi dữ liệu này thành những thông tin chi tiết có thể hành động, làm nổi bật các nút thắt cổ chai về hiệu suất và các điểm lỗi. Để tích hợp các chỉ số này vào quy trình tinh chỉnh của nhà phát triển, chúng tôi hiển thị một công cụ chỉ số và một prompt tùy chỉnh thông qua máy chủ giao thức ngữ cảnh mô hình phân tích nội bộ (MCP) của chúng tôi. Điều này cho phép tích hợp liền mạch với các công cụ mã hóa được hỗ trợ bởi AI như Cursor hoặc Claude Code.
Sau đây là danh sách các công cụ được sử dụng cho giải pháp giám sát Spark của chúng tôi, bao gồm thu thập chỉ số đến tinh chỉnh được hỗ trợ bởi AI:
- Amazon Bedrock
- Amazon EMR
- Spark SQL
- Apache Airflow
- Apache Kafka
- FastAPI
- FastMCP
- Claude Code
- Apache Iceberg
Kết quả là việc tinh chỉnh Spark nhanh chóng, đáng tin cậy, có tính xác định mà không cần phỏng đoán. Các nhà phát triển nhận được các đề xuất phù hợp với môi trường, cập nhật cấu hình tự động và các pull request sẵn sàng để xem xét.
Tìm hiểu sâu về việc thu thập chỉ số Spark
Trung tâm của giải pháp giám sát thời gian thực của chúng tôi là một framework Spark listener tùy chỉnh thu thập dữ liệu đo từ xa kỹ lưỡng trong suốt vòng đời của Spark. Các chỉ số tích hợp sẵn của Spark thường thô, tồn tại trong thời gian ngắn và nằm rải rác trên giao diện người dùng (UI) và log, điều này để lại bốn khoảng trống quan trọng:
- Hồ sơ lịch sử nhất quán
- Liên kết yếu từ ứng dụng đến job đến stage đến task
- Ngữ cảnh hạn chế (người dùng, cluster, nhóm)
- Khả năng hiển thị kém đối với các mẫu như skew, spill và retries
Framework listener mở rộng của chúng tôi lấp đầy những khoảng trống này bằng cách hợp nhất và làm phong phú dữ liệu đo từ xa bằng các thẻ môi trường và cấu hình, xây dựng một lịch sử bền vững, có thể truy vấn và tương quan các sự kiện trên biểu đồ thực thi. Nó giải thích tại sao các task thất bại, xác định nơi xảy ra áp lực bộ nhớ hoặc CPU, so sánh các cấu hình dự định với việc sử dụng thực tế và đưa ra các đề xuất tinh chỉnh rõ ràng, có thể lặp lại để các nhóm có thể thiết lập hành vi cơ bản, giảm thiểu lãng phí và giải quyết vấn đề nhanh hơn. Sơ đồ kiến trúc sau đây minh họa luồng của pipeline thu thập chỉ số Spark.

Sơ đồ kiến trúc thu thập chỉ số Spark
Spark listener
Framework listener của chúng tôi thu thập các chỉ số Spark ở bốn cấp độ riêng biệt:
- Application metrics: Tỷ lệ thành công/thất bại tổng thể của ứng dụng, tổng thời gian chạy và phân bổ tài nguyên
- Job-level metrics: Thời lượng job riêng lẻ và theo dõi trạng thái trong một ứng dụng
- Stage-level metrics: Chi tiết thực thi stage, các hoạt động shuffle và việc sử dụng bộ nhớ trên mỗi stage
- Task-level metrics: Hiệu suất task riêng lẻ cho các kịch bản gỡ lỗi sâu
Ví dụ mã Scala sau đây cho thấy SparkTaskListener mở rộng lớp SparkListener để thu thập các chỉ số cấp task chi tiết:
class SparkTaskListener(conf: SparkConf) extends SparkListener { val taskToStageId = new mutable.HashMap[Long, Int]() val stageToJobID = new mutable.HashMap[Int, Int]() private val emitter: Emitter = getEmitter(conf) override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = { taskToStageId += taskStart.taskInfo.taskId -> taskStart.stageId } override def onTaskEnd(taskEnd: SparkListenerTaskEnd): Unit = { val taskInfo = taskEnd.taskInfo val taskMetrics = taskEnd.taskMetrics val jobId = stageToJobID.apply(taskToStageId.apply(taskInfo.taskId)) val metrics = Map[String, Any]( "event_type" -> "task_metric", "job_id" -> jobId, "task_id" -> taskInfo.taskId, "duration" -> taskInfo.duration, "executor_run_time" -> taskMetrics.executorRunTime, "memory_bytes_spilled" -> taskMetrics.memoryBytesSpilled, "bytes_read" -> taskMetrics.inputMetrics.bytesRead, "records_read" -> taskMetrics.inputMetrics.recordsRead // additional metrics..... ) emitter.report(convertToJson(metrics)) }}Truyền dữ liệu thời gian thực đến Kafka
Các chỉ số này được truyền theo thời gian thực đến Kafka dưới dạng dữ liệu đo từ xa định dạng JSON bằng cách sử dụng một hệ thống emitter linh hoạt:
class KafkaEmitter(conf: SparkConf) extends Emitter { private val broker = conf.get("spark.custom.listener.kafkaBroker", "<broker_address>") private val topic = conf.get("spark.custom.listener.kafkaTopic", "<topic_name>") private var producer: Producer[String, Array[Byte]] = _ override def report(str: String): Unit = { val message = str.getBytes(StandardCharsets.UTF_8) producer.send(new ProducerRecord[String, Array[Byte]](topic, message)) }}Từ Kafka, một pipeline hạ nguồn thu thập các bản ghi này vào một bảng Apache Iceberg.
Khả năng quan sát giàu ngữ cảnh
Ngoài các chỉ số Spark tiêu chuẩn, framework của chúng tôi còn thu thập ngữ cảnh vận hành thiết yếu:
- Tích hợp Airflow: Metadata DAG, ID task và dấu thời gian thực thi
- Theo dõi tài nguyên: Các chỉ số executor có thể cấu hình (sử dụng heap, bộ nhớ thực thi)
- Ngữ cảnh môi trường: Nhận dạng cluster, theo dõi người dùng và cấu hình Spark
- Phân tích lỗi: Thông báo lỗi chi tiết và nguyên nhân gốc rễ của lỗi task
Sự kết hợp giữa việc thu thập chỉ số kỹ lưỡng và truyền dữ liệu thời gian thực đã định nghĩa lại việc giám sát Spark ở quy mô lớn, đặt nền móng cho những thông tin chi tiết mạnh mẽ.
Tìm hiểu sâu về xử lý chỉ số Spark
Khi các chỉ số thô—thường chứa hàng triệu bản ghi—được thu thập từ nhiều nguồn khác nhau, một Spark SQL pipeline sẽ chuyển đổi dữ liệu khối lượng lớn này thành những thông tin chi tiết có thể hành động. Nó tổng hợp dữ liệu thành một hàng duy nhất trên mỗi ID ứng dụng, giảm đáng kể độ phức tạp trong khi vẫn giữ được các tín hiệu hiệu suất chính.
Để đảm bảo tính nhất quán trong cách các nhóm diễn giải và hành động dựa trên dữ liệu này, chúng tôi áp dụng Năm Trụ cột Giám sát Spark, một framework có cấu trúc biến dữ liệu đo từ xa thô thành các chẩn đoán rõ ràng và các chiến lược tối ưu hóa có thể lặp lại, như được hiển thị trong bảng sau.
| Trụ cột | Chỉ số | Mục đích/thông tin chi tiết chính | Sự kiện thúc đẩy |
|---|---|---|---|
| Metadata ứng dụng và chi tiết điều phối | – YARN metadata (ứng dụng, lần thử, bộ nhớ được cấp phát, cụm tính toán, trạng thái công việc cuối cùng, thời gian chạy) – Airflow metadata (DAG, tác vụ, chủ sở hữu) | Tương quan các mẫu hiệu suất với các nhóm và cơ sở hạ tầng để xác định sự kém hiệu quả và quyền sở hữu. | – Airflow metadata – YARN metadata trên Amazon EMR trên EC2 |
| Cấu hình do người dùng chỉ định | – Bộ nhớ được cấp (driver, executor) – Cấp phát động (số lượng executor tối thiểu/tối đa/ban đầu) – Số core trên mỗi executor – Số phân vùng shuffle | So sánh cấu hình với hiệu suất thực tế để phát hiện việc cấp phát quá mức hoặc thiếu hụt và tối ưu hóa chi phí. Đây là nơi thường ẩn chứa những khoản tiết kiệm chi phí đáng kể. | Spark event: – app_metric |
| Thông tin chi tiết về hiệu suất | – Tỷ lệ độ lệch tối đa (phân vị thứ 75 so với tổng số byte shuffle_total_bytes_read tối đa của các tác vụ Spark trên mỗi stage) – Tổng số spill – Thử lại/thất bại của Spark stage/task | Đây là nơi sức mạnh chẩn đoán thực sự nằm ở đó. Các chỉ số này xác định ba yếu tố chính làm ngừng hiệu suất Spark: skew, spill và failures. | Spark event: – task_metric – stage_metric |
| Thông tin chi tiết về thực thi | – Số lượng Spark job/stage/task – Thời lượng Spark job/stage/task | Hiểu phân phối thời gian chạy, xác định các nút thắt cổ chai và làm nổi bật các ngoại lệ thực thi. | Spark event: – task_metric – stage_metric – job_metric |
| Sử dụng tài nguyên và tình trạng hệ thống | – Bộ nhớ heap JVM cao nhất – Tỷ lệ GC overhead tối đa | Tiết lộ sự kém hiệu quả của bộ nhớ và áp lực liên quan đến JVM để cải thiện chi phí và độ ổn định. So sánh những điều này với các cấu hình đã cho giúp xác định sự lãng phí và tối ưu hóa tài nguyên. | Spark event: – task_metric – stage_metric – executor_metric |
Tinh chỉnh Spark được hỗ trợ bởi AI
Sơ đồ kiến trúc sau đây minh họa việc sử dụng các công cụ AI tác nhân để phân tích các chỉ số Spark tổng hợp.
Sơ đồ tinh chỉnh Spark được hỗ trợ bởi AI
Để tích hợp các chỉ số này vào quy trình tinh chỉnh của nhà phát triển, chúng tôi xây dựng một công cụ chỉ số Spark tùy chỉnh và một prompt tùy chỉnh mà bất kỳ tác nhân nào cũng có thể sử dụng. Chúng tôi sử dụng dịch vụ phân tích hiện có của mình, một ứng dụng web nội bộ mà người dùng có thể truy vấn data warehouse của chúng tôi, xây dựng dashboard và chia sẻ thông tin chi tiết. Backend được viết bằng Python sử dụng FastAPI, và chúng tôi hiển thị một máy chủ MCP từ cùng một dịch vụ bằng cách sử dụng FastMCP. Bằng cách hiển thị công cụ chỉ số Spark và prompt tùy chỉnh thông qua máy chủ MCP, chúng tôi giúp các nhà phát triển có thể kết nối các công cụ mã hóa được hỗ trợ ưa thích của họ (Cursor, Claude Code, v.v.) và sử dụng dữ liệu để hướng dẫn việc tinh chỉnh của họ.
Vì dữ liệu được hiển thị bởi máy chủ MCP phân tích có thể nhạy cảm, chúng tôi sử dụng Amazon Bedrock trong tài khoản Amazon Web Services (AWS) của mình để cung cấp các foundation model cho các client MCP của chúng tôi. Điều này giúp dữ liệu của chúng tôi an toàn hơn và tạo điều kiện thuận lợi cho việc tuân thủ vì nó không bao giờ rời khỏi môi trường AWS của chúng tôi.
Prompt tùy chỉnh
Để tạo prompt tùy chỉnh cho việc tinh chỉnh Spark dựa trên AI, chúng tôi thiết kế một định dạng có cấu trúc, dựa trên quy tắc nhằm khuyến khích đầu ra có tính xác định và tiêu chuẩn hóa hơn. Prompt định nghĩa các phần bắt buộc (tổng quan ứng dụng, cấu hình Spark hiện tại, tóm tắt tình trạng job, đề xuất tài nguyên và tóm tắt) để đảm bảo tính nhất quán giữa các phân tích. Chúng tôi bao gồm các quy tắc định dạng chi tiết, chẳng hạn như gói các giá trị trong dấu backtick, tránh ngắt dòng và thực thi cấu trúc bảng nghiêm ngặt để duy trì sự rõ ràng và khả năng đọc của máy. Prompt cũng nhúng hướng dẫn rõ ràng để diễn giải các chỉ số Spark và ánh xạ chúng tới các hành động tinh chỉnh được đề xuất dựa trên các phương pháp hay nhất, với các tiêu chí rõ ràng cho các cờ trạng thái và giải thích tác động. Prompt có nghĩa là các đề xuất của AI có thể được theo dõi, tái tạo và thực hiện dựa trên dữ liệu được cung cấp bằng cách kiểm soát chặt chẽ luồng đầu vào-đầu ra và cố gắng ngăn chặn các ảo giác.
Kết quả cuối cùng
Các ảnh chụp màn hình trong phần này cho thấy cách công cụ của chúng tôi thực hiện phân tích và đưa ra các đề xuất. Sau đây là phân tích hiệu suất cho một ứng dụng hiện có.
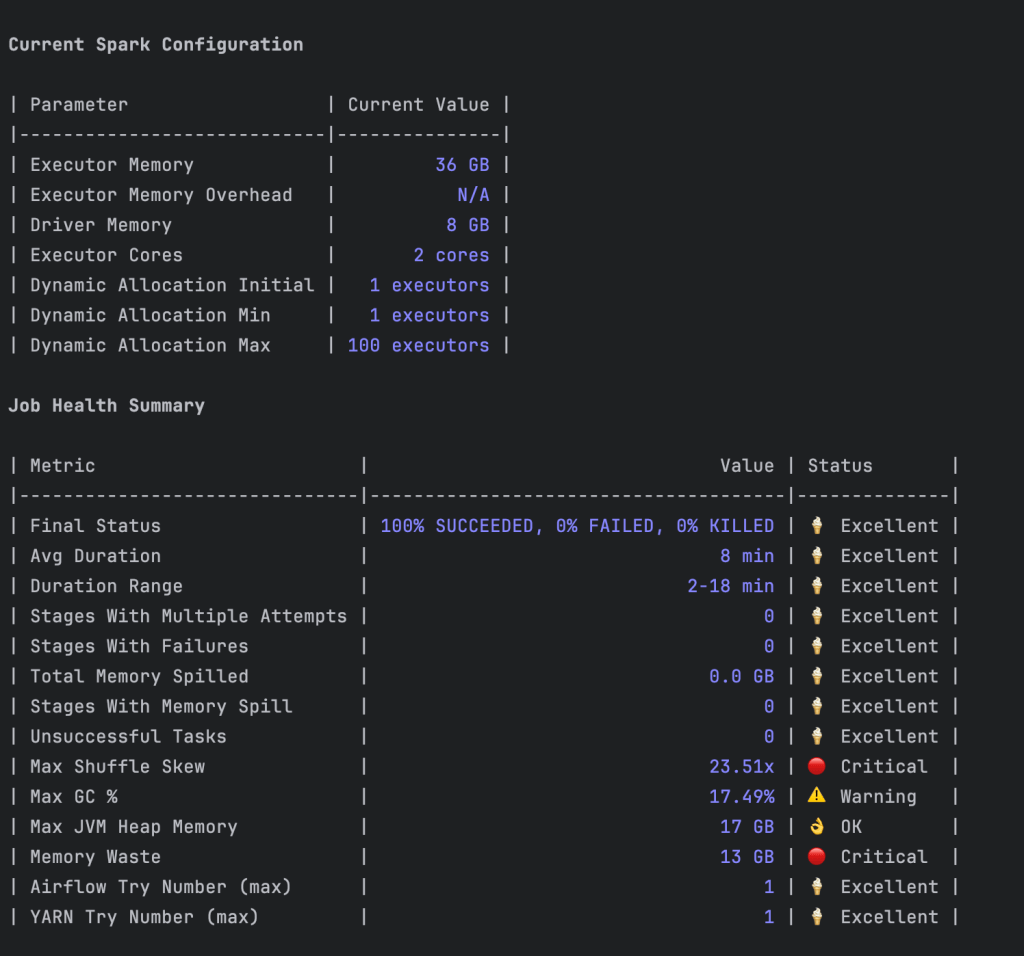
Sau đây là một đề xuất để giảm lãng phí tài nguyên.
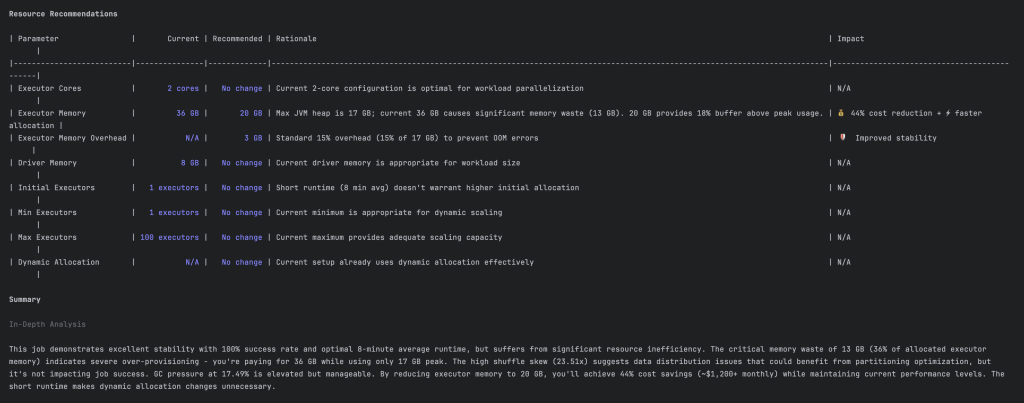
Tác động
Framework được hỗ trợ bởi AI của chúng tôi đã thay đổi cơ bản cách Spark được giám sát và quản lý tại Slack. Chúng tôi đã biến việc tinh chỉnh Spark từ một quy trình đòi hỏi chuyên môn cao, thử và sai thành một tiêu chuẩn tự động, dựa trên dữ liệu bằng cách vượt ra ngoài việc đào sâu log truyền thống và áp dụng một phương pháp có cấu trúc, dựa trên AI. Kết quả tự nói lên tất cả, như được hiển thị trong bảng sau.
| Chỉ số | Trước đây | Sau này | Cải thiện |
|---|---|---|---|
| Chi phí tính toán | Không xác định | Sử dụng tài nguyên tối ưu | Giảm tới 50% |
| Thời gian hoàn thành công việc | Không xác định | Tối ưu hóa | Nhanh hơn hơn 40% |
| Thời gian nhà phát triển dành cho việc tinh chỉnh | Hàng giờ mỗi tuần | Hàng phút mỗi tuần | Giảm >90% |
| Lãng phí cấu hình | Thường xuyên cấp phát quá mức | Cấp phát tài nguyên chính xác | Lãng phí gần như bằng không |
Kết luận
Tại Slack, kinh nghiệm của chúng tôi với việc giám sát Spark cho thấy bạn không cần phải là một chuyên gia hiệu suất để đạt được kết quả đặc biệt. Chúng tôi đã chuyển từ việc phản ứng với các vấn đề hiệu suất sang ngăn chặn chúng bằng cách áp dụng một cách có hệ thống năm danh mục chỉ số chính.
Các con số tự nói lên tất cả: giảm chi phí 30–50% và thời gian hoàn thành job nhanh hơn 40–60% thể hiện hiệu quả vận hành trực tiếp tác động đến khả năng phục vụ hàng triệu người dùng trên toàn thế giới của chúng tôi. Những cải tiến này tích lũy theo thời gian khi các nhóm xây dựng niềm tin vào cơ sở hạ tầng dữ liệu của họ và có thể tập trung vào đổi mới thay vì khắc phục sự cố.
Tổ chức của bạn có thể đạt được những kết quả tương tự. Bắt đầu với những điều cơ bản: triển khai giám sát toàn diện, thiết lập các chỉ số cơ bản và cam kết tối ưu hóa liên tục. Hiệu suất Spark không đòi hỏi chuyên môn về mọi tham số, nhưng nó đòi hỏi một nền tảng giám sát vững chắc và một cách tiếp cận phân tích có kỷ luật.
Lời cảm ơn
Chúng tôi muốn gửi lời cảm ơn đến tất cả những người đã đóng góp vào hành trình đáng kinh ngạc này: Johnny Cao, Nav Shergill, Yi Chen, Lakshmi Mohan, Apun Hiran và Ricardo Bion.
Về tác giả

Nilanjana Mukherjee
Nilanjana là kỹ sư phần mềm cấp cao tại Slack, mang đến chuyên môn kỹ thuật sâu rộng và khả năng lãnh đạo kỹ thuật cho các thách thức phần mềm phức tạp. Cô chuyên xây dựng các hệ thống dữ liệu hiệu suất cao, tập trung vào kiến trúc pipeline dữ liệu, tối ưu hóa truy vấn và các giải pháp xử lý dữ liệu có khả năng mở rộng.

Tayven Taylor
Tayven là kỹ sư phần mềm I trong nhóm Data Foundations của Slack, nơi anh giúp duy trì và tối ưu hóa các hệ thống dữ liệu quy mô lớn. Công việc của anh tập trung vào hiệu suất Spark và Amazon EMR, tối ưu hóa chi phí và cải thiện độ tin cậy để giữ cho nền tảng dữ liệu của Slack hiệu quả và có khả năng mở rộng. Anh đam mê tạo ra các công cụ và hệ thống giúp làm việc với dữ liệu nhanh hơn, thông minh hơn và tiết kiệm chi phí hơn.

Mimi Wang
Mimi là kỹ sư phần mềm cấp cao trong nhóm Data Platform của Slack, nơi cô xây dựng các công cụ để tạo điều kiện cho việc ra quyết định dựa trên dữ liệu tại Slack. Gần đây, cô tập trung vào việc sử dụng AI để giảm rào cản cho người dùng không chuyên về kỹ thuật trong việc khai thác giá trị từ dữ liệu. Trước đây, cô làm việc trong nhóm Slack Security, tập trung vào một pipeline phát hiện bất thường theo thời gian thực hướng tới khách hàng.

Rahul Gidwani
Rahul là kỹ sư phần mềm cấp cao tại Salesforce chuyên về cơ sở hạ tầng tìm kiếm. Anh làm việc trong việc phát triển data lake và các pipeline xử lý của Slack, đồng thời đóng góp vào các dự án mã nguồn mở như Apache HBase và Druid. Ngoài công việc, Rahul thích leo núi.

Prateek Kakirwar
Prateek là giám đốc kỹ thuật cấp cao tại Slack, dẫn dắt quá trình chuyển đổi kỹ thuật dữ liệu và phân tích ưu tiên AI. Với hơn 20 năm kinh nghiệm xây dựng các nền tảng dữ liệu quy mô lớn, hệ thống AI và framework chỉ số, anh tập trung vào các kiến trúc có khả năng mở rộng, cho phép phân tích tự phục vụ đáng tin cậy trên toàn tổ chức. Anh có bằng thạc sĩ từ Đại học California, Berkeley.

Avijit Goswami
Avijit là kiến trúc sư giải pháp chuyên gia chính tại AWS, chuyên về dữ liệu và phân tích. Anh giúp khách hàng thiết kế và triển khai các giải pháp data lake mạnh mẽ. Ngoài giờ làm việc, bạn có thể thấy Avijit khám phá những con đường mòn mới, khám phá những điểm đến mới, cổ vũ cho các đội yêu thích của mình, thưởng thức âm nhạc hoặc thử nghiệm các công thức nấu ăn mới trong bếp.
