Tác giả: Levent Kent, Aiham Taleb, PhD, Amir Mahdi Namazi, Brian Jensen, Daniel Schleicher, Kim Robins, Liza (Elizaveta) Zinovyeva, Martin Kraus, Nikita Kozodoi, PhD, và Samer Odeh
Ngày phát hành: 15 JAN 2026
Chuyên mục: Amazon API Gateway, Amazon Bedrock, Amazon Q Developer, Amazon SageMaker, Artificial Intelligence, Automotive, AWS Lambda, Generative AI, Industries, Kiro
Trong bài đăng blog này, chúng ta sẽ tìm hiểu về cách AUMOVIO đã sử dụng các dịch vụ và chuyên môn của Amazon Web Services (AWS) để phát triển một trợ lý mã hóa ô tô sáng tạo trong lĩnh vực xe hơi định nghĩa bằng phần mềm (SDV). Giải pháp của AUMOVIO sử dụng nhiều mô hình AI để tăng tốc các bước khác nhau trong vòng đời phát triển, đồng thời giúp đảm bảo tuân thủ các tiêu chuẩn ngành ô tô và các phương pháp mã hóa tốt nhất của AUMOVIO. Bằng cách tối đa hóa việc tái sử dụng mã và do đó giảm thiểu các thay đổi cần thiết, trợ lý này giảm đáng kể nỗ lực của các bước mô hình V khác. Bạn có thể đọc thêm về AUMOVIO và giải pháp SDV được hỗ trợ bởi AWS của họ tại đây.
Thách thức
Khi các phương tiện ngày càng được định nghĩa bằng phần mềm, các nhà sản xuất ô tô phải đối mặt với những thách thức về sự phức tạp của phần mềm ngày càng tăng, chu kỳ đổi mới nhanh hơn và các yêu cầu chất lượng nghiêm ngặt. Các phương pháp phát triển truyền thống, được xây dựng xung quanh phần cứng vật lý, các nhóm cục bộ và quy trình thủ công, đang trở thành những hạn chế. Các nhà sản xuất ô tô hiện phải phối hợp hàng nghìn kỹ sư trên các địa điểm toàn cầu trong khi quản lý các cơ sở mã rộng lớn yêu cầu xác thực trên nhiều khía cạnh. Ngoài ra, các nhóm phát triển phải tuân thủ các tiêu chuẩn phát triển phần mềm dành riêng cho từng lĩnh vực như AUTOSAR, hướng dẫn MISRA-C/C++, được bổ sung bởi các bộ quy tắc nội bộ của riêng họ. Các nhóm phát triển của AUMOVIO phải đối mặt với áp lực ngày càng tăng để điều chỉnh các quy trình hệ thống nhúng của họ cho thực tế mới này.
Nhận thấy nhu cầu về một giải pháp thông minh để tăng năng suất của các nhóm đồng thời duy trì các tiêu chuẩn nghiêm ngặt cho các ứng dụng ô tô, AUMOVIO đã tìm đến AWS.
Phân tích vấn đề
Để phù hợp hơn với các phương pháp hay nhất và quy định của ngành ô tô, AUMOVIO phát triển mã theo quy trình phát triển Mô hình V. Nhờ dữ liệu lịch sử khổng lồ cho thấy những nỗ lực đã bỏ ra trong mỗi bước, AUMOVIO đã có thể chỉ ra các bước có tiềm năng tăng hiệu quả cao nhất. Xem xét điều này và theo hướng dẫn của AWS về sự phức tạp trong việc tự động hóa từng bước, nhóm AUMOVIO đã quyết định tạo ra một trợ lý mã hóa có thể tạo ra:
- Các thân phương thức hướng ô tô từ các thiết kế hệ thống (bản phát hành đầu tiên của trợ lý mã hóa)
- Các bài kiểm thử đơn vị từ các thiết kế hệ thống (bản phát hành thứ hai của trợ lý mã hóa)
Hướng tới giải pháp
Để kiểm tra tính khả thi của một trợ lý mã hóa được hỗ trợ bởi AI, AUMOVIO đã tổ chức một hackathon dưới sự hướng dẫn của AWS. Đầu tiên, nhóm AUMOVIO đã thử các phương pháp tiếp cận dựa trên RAG lưu trữ cơ sở mã của họ trong một kho vector và sử dụng Amazon Bedrock, một dịch vụ được quản lý hoàn toàn giúp dễ dàng sử dụng các mô hình nền tảng từ các nhà cung cấp bên thứ ba và Amazon, để tạo mã dựa trên các đoạn được truy xuất. Tuy nhiên, các thử nghiệm cho thấy tìm kiếm ngữ nghĩa không thể truy xuất mã liên quan cho tác vụ đã cho trong một truy vấn duy nhất. Thay vì cam kết với phương pháp này, nhóm đã chuyển sang các phương pháp agentic, trong đó trợ lý mã hóa (được hỗ trợ bởi các mô hình có khả năng suy luận mạnh mẽ) truy xuất ngữ cảnh mã liên quan từng bước từ cơ sở mã. Nói cách khác, đối với một tác vụ nhất định, agent thực hiện nhiều tìm kiếm, phân tích kết quả từ mỗi tìm kiếm để xác định ngữ cảnh mã bổ sung nào nó cần, và sau đó tìm kiếm lại cho đến khi nó có tất cả thông tin liên quan để hoàn thành tác vụ, chẳng hạn như tạo mã.
Để đạt được điều đó, nhóm đã tích hợp trợ lý mã hóa mã nguồn mở Cline, được hỗ trợ bởi Claude 3.7 Sonnet được lưu trữ trong Amazon Bedrock. Thiết lập agentic đã cho thấy tiềm năng lớn, cung cấp các giai thoại như trợ lý mã hóa có thể:
- Sửa một lỗi trong vài phút mà một nhà phát triển cấp cao phải mất 5 ngày làm việc
- Tái cấu trúc một tệp rất lớn, loại bỏ các dư thừa và giảm kích thước 50%
Thiết lập tương tự cũng hoạt động rất tốt trong việc giải thích mã hiện có. Mặt khác, nhóm nhanh chóng hiểu được giới hạn của các mô hình tiêu chuẩn như vậy trong các lĩnh vực cụ thể của ô tô, vì chúng không được tinh chỉnh trên cơ sở mã của AUMOVIO, bao gồm nhiều API có thể tái sử dụng và các phương pháp hay nhất. Trong nhiều trường hợp, ngay cả khi mã được tạo ra tốt, nó không sử dụng các thư viện hiện có và do đó gây ra các bản sao hoặc các biến thể nhỏ của các triển khai hiện có.
Xem xét các kết quả tích cực và tiêu cực của hội thảo, AUMOVIO và nhóm AWS, bao gồm Trung tâm Đổi mới AI Tạo sinh của AWS, đã cùng nhau đưa ra một kiến trúc agentic như một phần của Proof of Concept (PoC). Mục tiêu của PoC là khám phá tính khả thi của một trợ lý mã hóa chuyên biệt cho việc phát triển phần mềm ô tô. Chương trình tuân theo một phương pháp tiếp cận có cấu trúc với các tiêu chí và số liệu thành công được xác định để đánh giá nhanh tiềm năng đổi mới dựa trên AI. Khung PoC bao gồm định nghĩa phạm vi, phát triển, kiểm thử, đánh giá hiệu suất và xác thực kỹ thuật, được thiết kế để mang lại kết quả có thể đo lường được trong khung thời gian.
Nhóm đã thiết kế một kiến trúc agentic bao gồm:
- Các mô hình hoặc agent được tinh chỉnh được sử dụng để mang lại độ chính xác tiên tiến cho các bước mô hình V cụ thể như tạo mã và tạo kiểm thử đơn vị.
- Các mô hình điều phối, chẳng hạn như Claude Sonnet 3.7/4, được sử dụng trong cửa sổ đối thoại của ứng dụng để:
- Thu thập thông tin về các tác vụ từ người dùng;
- Giao nhiệm vụ cho các mô hình được tinh chỉnh, nếu có thể; và
- Phản hồi các tác vụ không được hỗ trợ bởi các mô hình được tinh chỉnh (ví dụ: giải thích mã).
Để thiết lập các đường cơ sở hiệu suất và hiểu tiềm năng của các phương pháp khác nhau cho các agent, chúng tôi đã đánh giá một số mô hình với các khả năng khác nhau. Chúng bao gồm các mô hình chỉ sử dụng kỹ thuật prompt như Nova Pro được tối ưu hóa cho các phản hồi nhanh, cũng như các mô hình như Qwen3 32B, mà chúng tôi sau đó đã sử dụng làm cơ sở để tinh chỉnh trên mã cụ thể của ô tô.
Giải pháp cuối cùng
Giai đoạn đánh giá này đã cung cấp thông tin cho việc triển khai kiến trúc của chúng tôi, tích hợp các khả năng mô hình khác nhau này thông qua một cơ sở hạ tầng linh hoạt. Các khía cạnh chính của kiến trúc được mô tả trong sơ đồ dưới đây:

Hình 1: Kiến trúc Trợ lý Mã hóa Đa mô hình / Đa tác nhân
AUMOVIO đã áp dụng VS Code làm môi trường phát triển tích hợp (IDE) tiêu chuẩn của họ với nhiều tiện ích mở rộng. Dựa trên thiết lập hiện có này, kiến trúc của chúng tôi sử dụng các tiện ích mở rộng trợ lý mã hóa như Q-Developer hoặc Cline.
Amazon Q Developer là một trợ lý được hỗ trợ bởi AI tạo sinh (genAI) giúp các nhà phát triển hiểu, xây dựng, mở rộng và vận hành các ứng dụng. Khi được sử dụng trong một IDE như VS Code, Amazon Q có thể trò chuyện về mã, cung cấp các gợi ý mã nội tuyến, tạo mã mới, quét mã để tìm lỗ hổng bảo mật và thực hiện nâng cấp và cải tiến mã, chẳng hạn như cập nhật ngôn ngữ, gỡ lỗi và tối ưu hóa. Khả năng suy luận và agentic của Q-Developer được hỗ trợ bởi các mô hình cao cấp. Tại thời điểm viết bài, nó có thể được cấu hình để sử dụng với Claude Sonnet 3.7 hoặc Claude Sonnet 4.
Tương tự, plugin mã nguồn mở Cline hỗ trợ nhiều điểm cuối khác nhau để cung cấp năng lượng cho các trường hợp sử dụng trợ lý mã hóa agentic trong IDE. Cline có thể dễ dàng cấu hình với một mô hình được lưu trữ trên Amazon Bedrock như Claude Sonnet 3.7 hoặc Claude Sonnet 4.
Hơn nữa, kiến trúc sử dụng Giao thức Ngữ cảnh Mô hình (MCP), một tiêu chuẩn mở cho phép các trợ lý AI tương tác với các công cụ và dịch vụ bên ngoài. Tương tự như Cline, Amazon Q Developer hỗ trợ MCP, cho phép người dùng mở rộng khả năng của Q bằng cách kết nối nó với các công cụ và dịch vụ tùy chỉnh. Trong trường hợp của chúng tôi, chúng tôi hiển thị các mô hình được tinh chỉnh dưới dạng các điểm cuối MCP cho mô hình điều phối. Bằng cách này, mô hình điều phối có thể thực hiện lập kế hoạch ban đầu cho tác vụ do người dùng đưa ra, thu thập thêm thông tin nếu cần và cuối cùng gọi các mô hình được tinh chỉnh thông qua giao thức MCP.
Dưới đây là ví dụ về luồng điều hướng sử dụng Q Developer, được căn chỉnh theo số thứ tự của sơ đồ:
1) Nhà phát triển đặt câu hỏi cho VS Code với tích hợp Q-Developer.
2) Sử dụng mô hình điều phối cơ bản, Q Developer hiểu rằng tác vụ là về tạo phương thức. Tiếp theo, mô hình điều phối xác định rằng một số đầu vào bị thiếu để tạo mã liên quan. Q Developer sau đó yêu cầu thêm đầu vào (chẳng hạn như tài liệu yêu cầu bị thiếu).
3) Sau một số trao đổi tin nhắn giữa nhà phát triển và mô hình, Q Developer đã thu thập tất cả các đầu vào. Q Developer sau đó sử dụng “MCP-Client for Method Generator” để chuyển tiếp yêu cầu đến Amazon API Gateway, một dịch vụ AWS để tạo, xuất bản, duy trì, giám sát và bảo mật các API REST, HTTP và WebSocket ở mọi quy mô.
4) Amazon API Gateway sử dụng Amazon Cognito, một dịch vụ xác thực gốc đám mây, để xác thực người dùng.
5) Amazon API Gateway ủy quyền cho “Method Generator” AWS Lambda Function, là một công cụ tính toán phi máy chủ gốc đám mây để chạy mã.
6a) Khởi động một MCP Server từ xa, Hàm Lambda “Method Generator” thực hiện yêu cầu suy luận đến Amazon Bedrock, nơi lưu trữ mô hình được tinh chỉnh dành riêng cho việc tạo phương thức. Tương tự, “Test Generator” sẽ được gọi nếu tác vụ là về tạo kiểm thử đơn vị (6b).
7) Phản hồi từ mô hình được trả về thông qua đường dẫn AWS Lambda → API-Gateway → MCP Client đến Q Developer, sau đó thay đổi mã trong IDE cục bộ và yêu cầu người dùng xác nhận (số thứ tự được bỏ qua trong sơ đồ để cải thiện khả năng đọc).
Trong một luồng điều hướng khác, người dùng có thể yêu cầu giải thích mã hiện có. Trong trường hợp này, mô hình điều phối sẽ kết luận rằng nó không có bất kỳ mô hình được tinh chỉnh nào để xử lý tác vụ và do đó nó sẽ sử dụng khả năng suy luận của riêng mình để cung cấp câu trả lời.
Lưu ý rằng các điểm cuối MCP của giải pháp hiện tại được hỗ trợ bởi các điểm cuối mô hình, xử lý các tác vụ đơn lẻ. Do đó, phiên bản hiện tại là đa mô hình nhưng không nhất thiết là đa tác nhân, vì tác nhân duy nhất thực hiện suy luận và sử dụng công cụ là mô hình điều phối. Đồng thời, kiến trúc này hỗ trợ triển khai các tác nhân bổ sung (với khả năng suy luận và điều phối) đằng sau các điểm cuối MCP, điều này sẽ dẫn đến một trợ lý mã hóa đa tác nhân.
Đi sâu vào Fine-Tuning
Để tạo mã ô tô dành riêng cho từng lĩnh vực, có tính đến các tiêu chuẩn ngành, chúng tôi tinh chỉnh các mô hình ngôn ngữ trên mã chất lượng cao do con người viết từ môi trường ô tô. Phần này cung cấp chi tiết về quy trình tinh chỉnh.
Chuẩn bị dữ liệu
Nền tảng của việc tinh chỉnh mô hình hiệu quả nằm ở dữ liệu huấn luyện chất lượng cao, dành riêng cho từng lĩnh vực. Chúng tôi đã xây dựng một pipeline tiền xử lý chuyển đổi các kho lưu trữ phần mềm ô tô thô thành các ví dụ huấn luyện có cấu trúc, bảo toàn ngữ cảnh phong phú cần thiết để tạo mã C/C++.
Pipeline tiền xử lý bắt đầu bằng cách duyệt qua các kho lưu trữ C/C++ của AUMOVIO để trích xuất các hàm riêng lẻ cùng với ngữ cảnh toàn diện của chúng. Ngữ cảnh này bao gồm:
- Tài liệu hàm: Cả các bình luận kiểu Doxygen và tài liệu nội tuyến đều được trích xuất và liên kết với các triển khai hàm tương ứng của chúng.
- Yêu cầu hệ thống: Pipeline phân tích các tệp XML xuất DOORS để ánh xạ các định danh yêu cầu được đề cập trong tài liệu hàm với toàn bộ văn bản yêu cầu của chúng.
- Ngữ cảnh kiến trúc: Các sơ đồ PlantUML được tham chiếu trong tài liệu được trích xuất và bao gồm để cung cấp các đặc tả hành vi.
- Ngữ cảnh API: Các tệp tiêu đề liên quan và chữ ký hàm của chúng được thu thập để cung cấp thông tin về các API và cấu trúc dữ liệu có sẵn.
Một đổi mới quan trọng trong phương pháp tiền xử lý là việc liên kết thông minh các tệp tiêu đề với các tệp triển khai. Hệ thống xác định tệp tiêu đề chính tương ứng với mỗi tệp nguồn C/C++ và trích xuất ngữ cảnh bổ sung từ các phụ thuộc được bao gồm. Điều này đảm bảo rằng mã được tạo có thể sử dụng các API hiện có.
# Example of context aggregation from the preprocessing pipelinedef create_training_example(function_info): user_message = f"Implement the function: {function_info['signature']}\n\n" if function_info["documentation"]: user_message += f"with following specifications:\n{function_info['documentation']}" if function_info["requirements"]: user_message += f"\n\nRequirements tests:\n{function_info['requirements']}" if function_info["uml_diagram"]: user_message += f"\n\nThe behavior follows this UML diagram:\n{function_info['uml_diagram']}" return { "messages": [ {"role": "user", "content": user_message}, {"role": "assistant", "content": function_info["implementation"]},
Hình 2: Mã minh họa việc tổng hợp ngữ cảnh
Pipeline tiền xử lý cũng triển khai một số cơ chế đảm bảo chất lượng:
- Xác thực chữ ký hàm: Tự động sửa chữ ký hàm trong các tệp triển khai bằng cách khớp chúng với các khai báo tệp tiêu đề.
- Tính đầy đủ của tài liệu: Chỉ các hàm có tài liệu toàn diện mới được đưa vào tập huấn luyện.
- Tuân thủ mã: Các hàm được xác thực theo các bộ quy tắc tùy chỉnh với các mẫu kiến trúc và an toàn ô tô.
Để đảm bảo biểu diễn cân bằng trên các mức độ phức tạp mã khác nhau, pipeline tiền xử lý triển khai lấy mẫu phân tầng dựa trên độ dài và độ phức tạp của hàm. Phương pháp này tạo ra các tập huấn luyện và kiểm thử duy trì các đặc điểm phân phối nhất quán:
# Stratified sampling ensures balanced complexity distributionstats = stratified_sample_jsonl( input_file="dataset-7037-funcs.jsonl", sampled_file="test-set-funcs.jsonl", remaining_file="train-set-funcs.jsonl", sample_size=1000, num_strata=5,)
Hình 3: Tạo mẫu huấn luyện phân tầng
Tập dữ liệu kết quả chứa khoảng bảy nghìn triển khai hàm chất lượng cao với thông tin ngữ cảnh đầy đủ của chúng, được chia thành các tập huấn luyện và đánh giá trong khi vẫn duy trì sự cân bằng phân phối độ phức tạp.
Fine-Tuning
Phương pháp tinh chỉnh sử dụng các kỹ thuật tiên tiến được tối ưu hóa cho các ràng buộc tính toán và yêu cầu độ chính xác của việc phát triển phần mềm ô tô.
Nhóm đã chọn Qwen3-32B làm mô hình cơ sở do hiệu suất mạnh mẽ của nó trong các tác vụ tạo mã và yêu cầu tính toán hợp lý. Quá trình tinh chỉnh sử dụng Low-Rank Adaptation (LoRA) để làm cho việc huấn luyện hiệu quả trong khi vẫn giữ được khả năng chung của mô hình:
- Cấu hình LoRA: Bộ điều hợp Rank-8 với alpha=16 được áp dụng cho các lớp attention và feed-forward.
- Lượng tử hóa: Lượng tử hóa 4-bit sử dụng BitsAndBytes để giảm dung lượng bộ nhớ.
- Các mô-đun mục tiêu: Bộ điều hợp LoRA được áp dụng cho các lớp chiếu query, key, value và output cộng với tất cả các thành phần mạng feed-forward.
Việc tinh chỉnh tận dụng khả năng huấn luyện phân tán của Amazon SageMaker với tích hợp PyTorch DeepSpeed, được thiết kế đặc biệt để xử lý các yêu cầu tính toán của việc huấn luyện các mô hình lớn trên các cơ sở mã ô tô. Chúng tôi sử dụng remote decorator của SageMaker để điều phối việc huấn luyện phân tán trên nhiều GPU trong một phiên bản duy nhất, với hỗ trợ tích hợp để mở rộng quy mô sang cấu hình đa nút.
@remote( instance_type="ml.p4d.24xlarge", volume_size=100, use_torchrun=True, pre_execution_commands=[ "pip install torch==2.5.1 transformers==4.51.3", "pip install peft==0.15.2 deepspeed bitsandbytes", ])def train_model(train_dataset, test_dataset, config): # Adaptive DeepSpeed configuration based on quantization settings stage = 2 if use_quantization else 3 deepspeed_config = { "zero_optimization": { "stage": stage, "overlap_comm": True, "contiguous_gradients": True, "offload_optimizer": {"device": "cpu", "pin_memory": True} } } if stage == 3: deepspeed_config["zero_optimization"].update({ "offload_param": {"device": "cpu", "pin_memory": True}, "stage3_prefetch_bucket_size": 1e6, "stage3_param_persistence_threshold": 1e4, }) # Training implementation...
Hình 4: Huấn luyện LLM thông qua SageMaker remote decorator
Cơ sở hạ tầng huấn luyện triển khai một số tối ưu hóa chính:
- Chiến lược quản lý bộ nhớ thích ứng: Hệ thống sử dụng cả giai đoạn tối ưu hóa DeepSpeed ZeRO-2 và ZeRO-3 dựa trên cấu hình huấn luyện. Khi sử dụng lượng tử hóa, ZeRO-2 được ưu tiên vì khả năng tương thích tốt hơn với các mô hình lượng tử hóa 4-bit, phân vùng trạng thái bộ tối ưu hóa trên các GPU trong khi vẫn giữ các tham số mô hình được sao chép. Đối với các kịch bản huấn luyện độ chính xác đầy đủ, hệ thống tự động chuyển sang ZeRO-3, ngoài ra còn phân vùng các tham số mô hình trên các thiết bị và chuyển chúng sang bộ nhớ CPU khi không cần thiết. Phương pháp thích ứng này cho phép huấn luyện mô hình tham số 32B đầy đủ ngay cả với bộ nhớ GPU hạn chế, đồng thời duy trì hiệu suất tối ưu cho mỗi cấu hình.
- Quản lý tham số nâng cao: Phân vùng tham số của ZeRO-3 cho phép xử lý các cửa sổ ngữ cảnh lớn cần thiết cho tài liệu hàm toàn diện và khả năng truy xuất nguồn gốc yêu cầu. Kích thước bucket và ngưỡng duy trì tham số được điều chỉnh để đảm bảo truyền tham số hiệu quả mà không gây ra chi phí giao tiếp quá mức.
- Tối ưu hóa giao tiếp: Thiết lập phân tán sử dụng Thư viện Giao tiếp Tập thể NVIDIA với cài đặt thời gian chờ được tối ưu hóa và chồng chéo giao tiếp để xử lý các gradient lớn điển hình của các mô hình tạo mã. Cấu hình bao gồm các chiến lược nén và phân nhóm gradient giúp giảm chi phí giao tiếp trong quá trình truyền ngược.
- Khả năng chịu lỗi và độ tin cậy: Với thời gian huấn luyện kéo dài, cơ sở hạ tầng tích hợp khả năng xử lý lỗi mạnh mẽ với backoff theo cấp số nhân cho việc tải xuống mô hình và cơ chế thử lại tự động cho các lỗi phần cứng tạm thời. Hệ thống cũng triển khai khôi phục checkpoint để tiếp tục huấn luyện từ trạng thái đã lưu cuối cùng trong trường hợp bị gián đoạn, với phân vùng tham số của ZeRO-3 cho phép các chiến lược checkpoint chi tiết hơn.
- Phân bổ tài nguyên động: Tích hợp Amazon SageMaker cho phép mở rộng quy mô động dựa trên tải huấn luyện, với khả năng tự động cung cấp thêm tài nguyên tính toán trong các giai đoạn huấn luyện cao điểm.
Thiết lập huấn luyện phân tán đạt được khoảng 85% mức sử dụng GPU trên tất cả các thiết bị trong khi vẫn duy trì sự hội tụ ổn định, cho phép AUMOVIO hoàn thành các chu kỳ tinh chỉnh đầy đủ trong khung thời gian phát triển của họ đồng thời tối ưu hóa chi phí điện toán đám mây thông qua việc sử dụng tài nguyên hiệu quả.
Mô hình cuối cùng được đóng gói để triển khai thông qua chức năng nhập mô hình tùy chỉnh của Amazon Bedrock, cho phép tích hợp liền mạch với kiến trúc đa mô hình đã mô tả trước đó. Mô hình được tinh chỉnh đạt được những cải thiện đáng kể về độ chính xác dành riêng cho từng lĩnh vực trong khi vẫn duy trì khả năng đàm thoại cần thiết cho việc tích hợp IDE.
Kết quả kiểm thử
Để đánh giá hiệu quả của các mô hình tạo mã khác nhau được triển khai dưới dạng điểm cuối MCP, chúng tôi tiến hành các đánh giá toàn diện tập trung vào việc tạo mã C và C++. Phần này trình bày chi tiết phương pháp đánh giá và các phát hiện chính của chúng tôi.
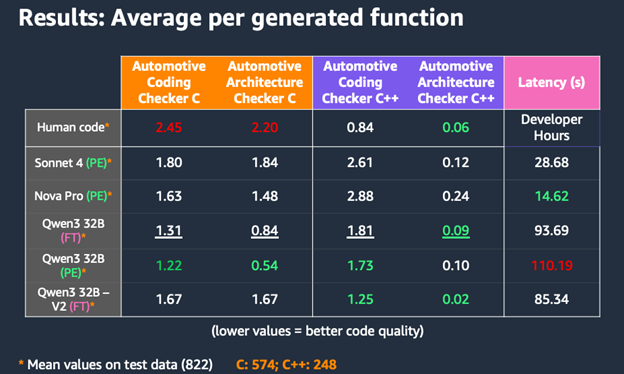
Hình 5: Đánh giá các mô hình khác nhau về tuân thủ và độ trễ
Bảng so sánh các mô hình cơ sở khác nhau, bao gồm các biến thể được tinh chỉnh và chung cũng như điểm chuẩn mã của con người. Chúng tôi tập trung vào các chiến lược kỹ thuật prompt (PE) và tinh chỉnh (FT) và sử dụng nhiều số liệu đánh giá:
- Tuân thủ mã với các bộ quy tắc Mã hóa Ô tô tùy chỉnh, được xác minh bằng các trình phân tích tĩnh tùy chỉnh dựa trên REGEX (được đo bằng số lỗi trung bình trên mỗi hàm).
- Tuân thủ mã với các bộ quy tắc Kiến trúc Ô tô tùy chỉnh, được xác minh bằng các trình phân tích tĩnh tùy chỉnh dựa trên REGEX (được đo bằng số lỗi trung bình trên mỗi hàm).
- Độ trễ tạo mã (số giây trung bình trên mỗi hàm).
Kết quả cho thấy các mẫu thú vị: trong khi các mô hình tập trung vào PE như Qwen3 32B (PE) đạt được điểm chất lượng mã C mạnh mẽ với trung bình 1.22 vi phạm trong Kiến trúc Ô tô và 0.54 trong tuân thủ bộ quy tắc Kiểm tra Mã hóa Ô tô, các phiên bản được tăng cường FT cho thấy kết quả cạnh tranh trong việc tạo C++. Đáng chú ý, Qwen3 32B – V2 (FT) đạt được sự tuân thủ bộ quy tắc Kiểm tra Kiến trúc Ô tô C++ xuất sắc (0.02) và điểm số C++ bộ quy tắc Kiểm tra Mã hóa Ô tô vững chắc (1.25), chứng minh lợi thế của việc kết hợp tinh chỉnh với kỹ thuật prompt.
Những phát hiện này chứng minh lợi thế chiến lược của việc có quyền truy cập linh hoạt vào nhiều mô hình tạo mã thông qua MCP. Các mô hình khác nhau xuất sắc trong các kịch bản khác nhau: Nova Pro cung cấp khả năng tạo nhanh với độ trễ 14.62 giây và tuân thủ mã C tốt, làm cho nó lý tưởng cho việc tạo mẫu nhanh và phát triển tập trung vào C. Trong khi đó, các biến thể Qwen3 32B cho thấy điểm tuân thủ C++ vượt trội. Khả năng chuyển đổi liền mạch giữa các phương pháp PE và FT cung cấp các cơ hội tối ưu hóa bổ sung. Các nhà phát triển có thể sử dụng các mô hình PE cho các triển khai API đơn giản, nơi tùy chỉnh prompt là chìa khóa. Đối với việc tạo mã C++ phức tạp hơn, họ có thể chuyển sang các mô hình FT vì các mẫu đã học chứng tỏ có lợi hơn. Sự linh hoạt này, kết hợp với các đánh đổi chi phí-hiệu suất của mỗi mô hình, cho phép các nhóm phát triển điều chỉnh việc tạo mã dựa trên các yêu cầu cụ thể của dự án.
Những cải tiến về chất lượng mã và tuân thủ các tiêu chuẩn tốt hơn trực tiếp giải quyết thách thức ban đầu của chúng tôi là duy trì chất lượng mã trong khi theo kịp sự phức tạp ngày càng tăng của các phương tiện định nghĩa bằng phần mềm.
“Trợ lý Kỹ thuật của AUMOVIO đã giúp chúng tôi theo kịp sự phức tạp ngày càng tăng của các phương tiện định nghĩa bằng phần mềm đồng thời mang lại chu kỳ phát triển nhanh hơn đáng kể và chất lượng mã tăng lên. Trợ lý đảm bảo chúng tôi duy trì sự tuân thủ các tiêu chuẩn ô tô mà không ảnh hưởng đến tốc độ – chính xác là những gì chúng tôi cần cho thị trường ô tô cạnh tranh ngày nay.”
– Amir Namazi, Giám đốc Giải pháp Ảo hóa Đám mây và AI của AUMOVIO
Kết luận
Trong lần lặp đầu tiên này, AUMOVIO đã tạo ra một trợ lý mã hóa chuyên biệt cao được hỗ trợ bởi một mô hình được tinh chỉnh để tạo mã. Nhìn về phía trước, AUMOVIO sẽ tiếp tục lặp lại trên trợ lý mã hóa, mở rộng khả năng của nó để phục vụ tốt hơn các giai đoạn khác nhau của quy trình phát triển mô hình V. Để thúc đẩy ý tưởng này hơn nữa, AUMOVIO đang dần di chuyển các dự án của mình sang Kiro vì nó hỗ trợ phát triển theo đặc tả, bao gồm nhiều bước của vòng đời mô hình V, cùng với khả năng trợ lý mã hóa agentic của thiết lập hiện tại của họ. Trong khi việc tạo kiểm thử đơn vị vẫn là một lĩnh vực quan tâm chính, tham vọng rộng lớn hơn của AUMOVIO là phát triển công cụ này thành một sản phẩm tích hợp, cấp độ sản phẩm mang lại lợi ích cho cả các nhóm nội bộ của AUMOVIO và các đối tác bên ngoài. Tầm nhìn dài hạn là chuyển đổi sang một khung đa tác nhân, nơi các mô hình chuyên biệt và các bộ điều phối cộng tác liền mạch trong suốt vòng đời phát triển.
Để được hướng dẫn thêm, hãy truy cập các trang AWS cho ô tô và Sản xuất, hoặc liên hệ với nhóm AWS của bạn ngay hôm nay.
Về tác giả

Levent Kent
Levent Kent là kiến trúc sư giải pháp AI tạo sinh cấp cao tại Amazon Web Services (AWS). Anh có hơn 14 năm kinh nghiệm về triển khai và kiến trúc trong nhiều lĩnh vực từ ngân hàng, giáo dục và chăm sóc sức khỏe đến ô tô và sản xuất. Hiện tại, anh đang cộng tác với các khách hàng trong ngành ô tô và sản xuất, giúp họ thiết kế và xây dựng các giải pháp AI tạo sinh có khả năng mở rộng và đổi mới. Trong thời gian rảnh rỗi, anh thích nhảy hoặc hát với bạn bè.

Aiham Taleb, PhD
Aiham Taleb, Tiến sĩ, là Nhà khoa học Ứng dụng cấp cao tại Trung tâm Đổi mới AI Tạo sinh, làm việc trực tiếp với các khách hàng doanh nghiệp của AWS để tận dụng Gen AI trong một số trường hợp sử dụng có tác động cao. Aiham có bằng Tiến sĩ về học biểu diễn không giám sát, và có kinh nghiệm trong ngành trải rộng trên nhiều ứng dụng học máy khác nhau, bao gồm thị giác máy tính, xử lý ngôn ngữ tự nhiên và hình ảnh y tế.

Amir Mahdi Namazi
Amir là Giám đốc Giải pháp và Trưởng dự án về Ảo hóa, Đám mây và AI cho Máy tính Hiệu năng Cao (HPC) tại AUMOVIO. Anh có bằng cử nhân Kỹ thuật và Khoa học Máy tính, và Kỹ thuật Công nghiệp từ TH Köln, cũng như bằng Kỹ thuật Cơ khí từ OTH Regensburg. Amir gia nhập Continental vào năm 2017 với tư cách là Nhà phân tích Dữ liệu, làm việc với các cảm biến NOx trong bộ phận Powertrain trước đây. Năm 2019, Amir trở thành Kỹ sư Phần mềm, tập trung vào AUTOSAR Classic và Bộ điều khiển Động cơ. Từ năm 2020, Amir giữ vị trí Kiến trúc sư Phần mềm cho HPC trong ANS PL1, và từ năm 2023, anh đảm nhiệm vai trò hiện tại của mình.

Brian Jensen
Brian Jensen là Giám đốc Khoa học Ứng dụng tại Trung tâm Đổi mới AI Tạo sinh của AWS với 15 năm kinh nghiệm trong lĩnh vực này. Anh dẫn dắt việc triển khai các dự án khách hàng AI Tạo sinh mới lạ từ ý tưởng đến nguyên mẫu và sản xuất, thúc đẩy các kết quả có giá trị cao trên nhiều lĩnh vực khác nhau bao gồm sản xuất, du lịch và vận tải, dịch vụ tài chính và ngành ô tô. Brian mang đến chuyên môn sâu rộng trong các ứng dụng học máy đa dạng, bao gồm thị giác máy tính, robot, dự báo chuỗi thời gian và xử lý hình ảnh y tế.

Daniel Schleicher
Daniel Schleicher là Kiến trúc sư Giải pháp cấp cao tại AWS cho Continental, tập trung vào xe hơi định nghĩa bằng phần mềm. Trong lĩnh vực này, anh quan tâm đến việc áp dụng các nguyên tắc điện toán đám mây cho các ứng dụng ô tô, và thúc đẩy quá trình phát triển phần mềm của các ứng dụng ô tô sử dụng phần cứng ảo hóa. Trong các vai trò trước đây, Daniel đã dẫn dắt việc di chuyển một nền tảng tích hợp doanh nghiệp sang AWS tại Volkswagen và, với tư cách là quản lý sản phẩm, đã đóng góp vào việc tạo ra một dịch vụ trung tâm cho Mercedes Intelligent Cloud.

Kim Robins
Kim Robins là Chiến lược gia AI cấp cao tại Trung tâm Đổi mới AI Tạo sinh của AWS. Anh tận dụng chuyên môn sâu rộng về trí tuệ nhân tạo và học máy để giúp các tổ chức phát triển các sản phẩm đổi mới và tinh chỉnh các chiến lược AI của họ, thúc đẩy giá trị kinh doanh hữu hình.

Liza (Elizaveta) Zinovyeva
Liza (Elizaveta) Zinovyeva là Nhà khoa học Ứng dụng tại Trung tâm Đổi mới AI Tạo sinh của AWS và làm việc tại Berlin. Cô giúp khách hàng trong các ngành khác nhau tích hợp AI Tạo sinh vào các ứng dụng và quy trình làm việc hiện có của họ. Cô đam mê các chủ đề AI/ML, tài chính và bảo mật phần mềm. Trong thời gian rảnh rỗi, cô thích dành thời gian cho gia đình, thể thao, học hỏi các công nghệ mới và các câu đố trên bàn.

Martin Kraus
Martin Kraus đang lãnh đạo tổ chức DevOps tại AUMOVIO cho Máy tính Hiệu năng Cao (HPC) bao gồm các chủ đề CI/CD/CT, AI và Ảo hóa. Anh chịu trách nhiệm thiết lập phát triển hiệu quả cho tất cả các dự án HPC trên toàn thế giới. Anh có hơn 15 năm kinh nghiệm trong việc lãnh đạo các dự án phần mềm ô tô và niềm đam mê của anh là thúc đẩy sự chuyển đổi của AUMOVIO sang phát triển nhanh hơn và hiệu quả hơn.

Nikita Kozodoi, PhD
Nikita Kozodoi, Tiến sĩ, là Nhà khoa học Ứng dụng cấp cao tại Trung tâm Đổi mới AI Tạo sinh của AWS, làm việc ở biên giới nghiên cứu AI và kinh doanh. Nikita xây dựng các giải pháp AI tạo sinh để giải quyết các vấn đề kinh doanh thực tế cho khách hàng AWS trên các ngành và có bằng Tiến sĩ về Học máy.

Samer Odeh
Samer Odeh là Giám đốc Tài khoản Kỹ thuật tại AWS, chuyên hỗ trợ khách hàng trong ngành ô tô. Với hơn 15 năm kinh nghiệm trong lĩnh vực CNTT và công nghệ đám mây, Samer tập trung vào việc giúp các doanh nghiệp ô tô tối ưu hóa cơ sở hạ tầng AWS của họ và sử dụng các dịch vụ đám mây để thúc đẩy đổi mới trong các phương tiện định nghĩa bằng phần mềm (SDV). Chuyên môn của Samer bao gồm kiến trúc đám mây, các phương pháp DevOps và lập kế hoạch CNTT chiến lược cho các giải pháp xe hơi kết nối. Samer đam mê trao quyền cho các tổ chức ô tô đạt được sự xuất sắc trong vận hành và tăng tốc hành trình chuyển đổi kỹ thuật số của họ bằng cách sử dụng các dịch vụ AWS, đặc biệt trong lĩnh vực phát triển và triển khai SDV.
