Tác giả: Jayashree R, Fahim Surani, và Harsha Pradha
Ngày phát hành: 15 JAN 2026
Chuyên mục: Amazon Bedrock, Amazon Machine Learning, Artificial Intelligence, Best Practices, Customer Solutions, Financial Services, Generative AI*, Industries, Python, Strands Agents, Technical How-to
Tại Amazon.ae, chúng tôi phục vụ khoảng 10 triệu khách hàng mỗi tháng trên năm quốc gia thuộc khu vực Trung Đông và Bắc Phi—Các Tiểu vương quốc Ả Rập Thống nhất (UAE), Ả Rập Xê Út, Ai Cập, Thổ Nhĩ Kỳ và Nam Phi. Nhóm AMET (Châu Phi, Trung Đông và Thổ Nhĩ Kỳ) Payments của chúng tôi quản lý các lựa chọn thanh toán, giao dịch, trải nghiệm và các tính năng khả năng chi trả trên các quốc gia đa dạng này, phát hành trung bình năm tính năng mới mỗi tháng. Mỗi tính năng yêu cầu tạo trường hợp kiểm thử toàn diện, mà theo truyền thống tiêu tốn 1 tuần công sức thủ công cho mỗi dự án. Các kỹ sư đảm bảo chất lượng (QA) của chúng tôi đã dành thời gian này để phân tích các tài liệu yêu cầu nghiệp vụ (BRD), tài liệu thiết kế, bản mô phỏng UI và các chuẩn bị kiểm thử lịch sử—một quy trình yêu cầu một kỹ sư toàn thời gian hàng năm chỉ để tạo trường hợp kiểm thử.
Để cải thiện quy trình thủ công này, chúng tôi đã phát triển SAARAM (QA Lifecycle App), một giải pháp AI đa tác nhân giúp giảm thời gian tạo trường hợp kiểm thử từ 1 tuần xuống còn vài giờ. Sử dụng Amazon Bedrock với Claude Sonnet của Anthropic và Strands Agents SDK, chúng tôi đã giảm thời gian cần thiết để tạo trường hợp kiểm thử từ 1 tuần xuống chỉ còn vài giờ, đồng thời cải thiện chất lượng độ bao phủ kiểm thử. Giải pháp của chúng tôi chứng minh cách nghiên cứu các mô hình nhận thức của con người, thay vì chỉ tối ưu hóa các thuật toán AI, có thể tạo ra các hệ thống sẵn sàng sản xuất giúp nâng cao chứ không thay thế chuyên môn của con người.
Trong bài viết này, chúng tôi giải thích cách chúng tôi đã vượt qua các hạn chế của hệ thống AI đơn tác nhân thông qua một phương pháp tiếp cận lấy con người làm trung tâm, triển khai các đầu ra có cấu trúc để giảm đáng kể hiện tượng “ảo giác” (hallucinations) và xây dựng một giải pháp có khả năng mở rộng hiện đang được định vị để mở rộng trên toàn nhóm QA AMET và sau đó là các nhóm QA khác trong Tổ chức International Emerging Stores and Payments (IESP).
Tổng quan giải pháp
Nhóm QA AMET Payments xác thực các triển khai mã ảnh hưởng đến chức năng thanh toán cho hàng triệu khách hàng trên các môi trường quy định và phương thức thanh toán đa dạng. Quy trình tạo trường hợp kiểm thử thủ công của chúng tôi đã làm tăng thời gian quay vòng (TAT) trong chu kỳ sản phẩm, tiêu tốn các tài nguyên kỹ thuật quý giá vào các tác vụ chuẩn bị và tài liệu kiểm thử lặp đi lặp lại thay vì các sáng kiến kiểm thử chiến lược. Chúng tôi cần một giải pháp tự động có thể duy trì các tiêu chuẩn chất lượng của chúng tôi đồng thời giảm thời gian đầu tư.
Các mục tiêu của chúng tôi bao gồm giảm thời gian tạo trường hợp kiểm thử từ 1 tuần xuống dưới vài giờ, thu thập kiến thức chuyên môn từ các kiểm thử viên có kinh nghiệm, chuẩn hóa các phương pháp kiểm thử trên các nhóm và giảm thiểu các vấn đề “ảo giác” phổ biến trong các hệ thống AI. Giải pháp cần phải xử lý các yêu cầu nghiệp vụ phức tạp trải dài trên nhiều phương thức thanh toán, quy định khu vực và phân khúc khách hàng, đồng thời tạo ra các trường hợp kiểm thử cụ thể, có thể thực hiện được phù hợp với các hệ thống quản lý kiểm thử hiện có của chúng tôi.
Kiến trúc sử dụng một quy trình làm việc đa tác nhân tinh vi. Để đạt được điều này, chúng tôi đã trải qua 3 lần lặp lại khác nhau và tiếp tục cải thiện và nâng cao khi các kỹ thuật mới được phát triển và các mô hình mới được triển khai.
Thách thức với các phương pháp AI truyền thống
Những nỗ lực ban đầu của chúng tôi tuân theo các phương pháp AI truyền thống, cung cấp toàn bộ BRD cho một tác nhân AI duy nhất để tạo trường hợp kiểm thử. Phương pháp này thường tạo ra các đầu ra chung chung như “xác minh thanh toán hoạt động chính xác” thay vì các trường hợp kiểm thử cụ thể, có thể thực hiện được mà nhóm QA của chúng tôi yêu cầu. Ví dụ, chúng tôi cần các trường hợp kiểm thử cụ thể như “xác minh rằng khi khách hàng UAE chọn thanh toán khi nhận hàng (COD) cho một đơn hàng trên 1.000 AED với thẻ tín dụng đã lưu, hệ thống hiển thị phí COD là 11 AED và xử lý thanh toán qua cổng COD với trạng thái đơn hàng chuyển sang ‘đang chờ giao hàng’.”
Phương pháp tiếp cận đơn tác nhân đã đặt ra một số hạn chế quan trọng. Hạn chế về độ dài ngữ cảnh ngăn cản việc xử lý các tài liệu lớn một cách hiệu quả, nhưng việc thiếu các giai đoạn xử lý chuyên biệt có nghĩa là AI không thể hiểu các ưu tiên kiểm thử hoặc các phương pháp tiếp cận dựa trên rủi ro. Ngoài ra, các vấn đề “ảo giác” đã tạo ra các kịch bản kiểm thử không liên quan có thể gây hiểu lầm cho các nỗ lực QA. Nguyên nhân gốc rễ rất rõ ràng: AI đã cố gắng nén logic nghiệp vụ phức tạp mà không có quá trình tư duy lặp đi lặp lại mà các kiểm thử viên có kinh nghiệm sử dụng khi phân tích các yêu cầu.
Sơ đồ luồng sau đây minh họa các vấn đề của chúng tôi khi cố gắng sử dụng một tác nhân duy nhất với một lời nhắc toàn diện.

Bước đột phá lấy con người làm trung tâm
Bước đột phá của chúng tôi đến từ một sự thay đổi cơ bản trong cách tiếp cận. Thay vì hỏi, “AI nên suy nghĩ về kiểm thử như thế nào?”, chúng tôi đã hỏi, “Con người có kinh nghiệm suy nghĩ về kiểm thử như thế nào?” để tập trung vào việc tuân theo một quy trình từng bước cụ thể thay vì dựa vào mô hình ngôn ngữ lớn (LLM) để tự mình nhận ra điều này. Sự thay đổi triết lý này đã dẫn chúng tôi đến việc thực hiện các cuộc phỏng vấn nghiên cứu với các chuyên gia QA cấp cao, nghiên cứu chi tiết quy trình làm việc nhận thức của họ.
Chúng tôi phát hiện ra rằng các kiểm thử viên có kinh nghiệm không xử lý tài liệu một cách toàn diện—họ làm việc thông qua các giai đoạn tư duy chuyên biệt. Đầu tiên, họ phân tích tài liệu bằng cách trích xuất các tiêu chí chấp nhận, xác định hành trình khách hàng, hiểu các yêu cầu UX, ánh xạ các yêu cầu sản phẩm, phân tích dữ liệu người dùng và đánh giá khả năng của luồng công việc. Sau đó, họ phát triển các kiểm thử thông qua một quy trình có hệ thống: phân tích hành trình, xác định kịch bản, ánh xạ luồng dữ liệu, phát triển trường hợp kiểm thử và cuối cùng là tổ chức và ưu tiên.
Sau đó, chúng tôi đã phân tách tác nhân ban đầu của mình thành các hành động tư duy tuần tự đóng vai trò là các bước riêng lẻ. Chúng tôi đã xây dựng và kiểm thử từng bước bằng cách sử dụng Amazon Q Developer for CLI để đảm bảo các ý tưởng cơ bản là hợp lý và kết hợp cả đầu vào chính và phụ.
Insight này đã dẫn chúng tôi đến việc thiết kế SAARAM với các tác nhân chuyên biệt phản ánh các phương pháp kiểm thử chuyên gia này. Mỗi tác nhân tập trung vào một khía cạnh cụ thể của quy trình kiểm thử, chẳng hạn như cách các chuyên gia con người phân chia các giai đoạn phân tích khác nhau trong tâm trí.
Kiến trúc đa tác nhân với Strands Agents
Dựa trên sự hiểu biết của chúng tôi về quy trình làm việc QA của con người, ban đầu chúng tôi đã cố gắng tự xây dựng các tác nhân của riêng mình. Chúng tôi phải tạo ra các vòng lặp, thực thi nối tiếp hoặc song song của riêng mình. Chúng tôi cũng tạo ra các biểu đồ điều phối và quy trình làm việc của riêng mình, điều này đòi hỏi nỗ lực thủ công đáng kể. Để giải quyết những thách thức này, chúng tôi đã chuyển sang Strands Agents SDK. Điều này cung cấp các khả năng điều phối đa tác nhân cần thiết để phối hợp các tác vụ phức tạp, phụ thuộc lẫn nhau trong khi duy trì các đường dẫn thực thi rõ ràng, giúp cải thiện hiệu suất và giảm thời gian phát triển của chúng tôi.
Lặp lại quy trình làm việc 1: Tạo kiểm thử từ đầu đến cuối
Lần lặp lại đầu tiên của SAARAM bao gồm một đầu vào duy nhất và tạo ra các tác nhân chuyên biệt đầu tiên của chúng tôi. Nó liên quan đến việc xử lý một tài liệu công việc thông qua năm tác nhân chuyên biệt để tạo ra độ bao phủ kiểm thử toàn diện.
Tác nhân 1 được gọi là Customer Segment Creator, và nó tập trung vào phân tích phân khúc khách hàng, sử dụng bốn tác nhân phụ:
- Customer Segment Discovery xác định các phân khúc người dùng sản phẩm
- Decision Matrix Generator tạo ma trận dựa trên tham số
- E2E Scenario Creation phát triển các kịch bản từ đầu đến cuối (E2E) cho mỗi phân khúc
- Test Steps Generation phát triển trường hợp kiểm thử chi tiết
Tác nhân 2 được gọi là User Journey Mapper, và nó sử dụng bốn tác nhân phụ để ánh xạ các hành trình sản phẩm một cách toàn diện:
- Flow Diagram và Sequence Diagram là các trình tạo sử dụng cú pháp Mermaid.
- Trình tạo E2E Scenarios được xây dựng dựa trên các sơ đồ này.
- Test Steps Generator được sử dụng để tài liệu kiểm thử chi tiết.
Tác nhân 3 được gọi là Customer Segment x Journey Coverage, và nó kết hợp đầu vào từ tác nhân 1 và 2 để tạo ra các phân tích chi tiết theo phân khúc. Nó sử dụng bốn tác nhân phụ:
- sơ đồ luồng dựa trên Mermaid
- Hành trình người dùng
- Sơ đồ trình tự cho mỗi phân khúc khách hàng
- Các bước kiểm thử tương ứng.
Tác nhân 4 được gọi là State Transition Agent. Nó phân tích các điểm trạng thái sản phẩm khác nhau trong luồng hành trình khách hàng. Các tác nhân phụ của nó tạo ra các sơ đồ trạng thái Mermaid đại diện cho các trạng thái hành trình khác nhau, sơ đồ kịch bản trạng thái cụ thể theo phân khúc và tạo ra các kịch bản và bước kiểm thử liên quan.
Quy trình làm việc, được hiển thị trong sơ đồ sau, kết thúc bằng một quy trình trích xuất, chuyển đổi và tải (ETL) cơ bản để hợp nhất và loại bỏ trùng lặp dữ liệu từ các tác nhân, lưu đầu ra cuối cùng dưới dạng tệp văn bản.
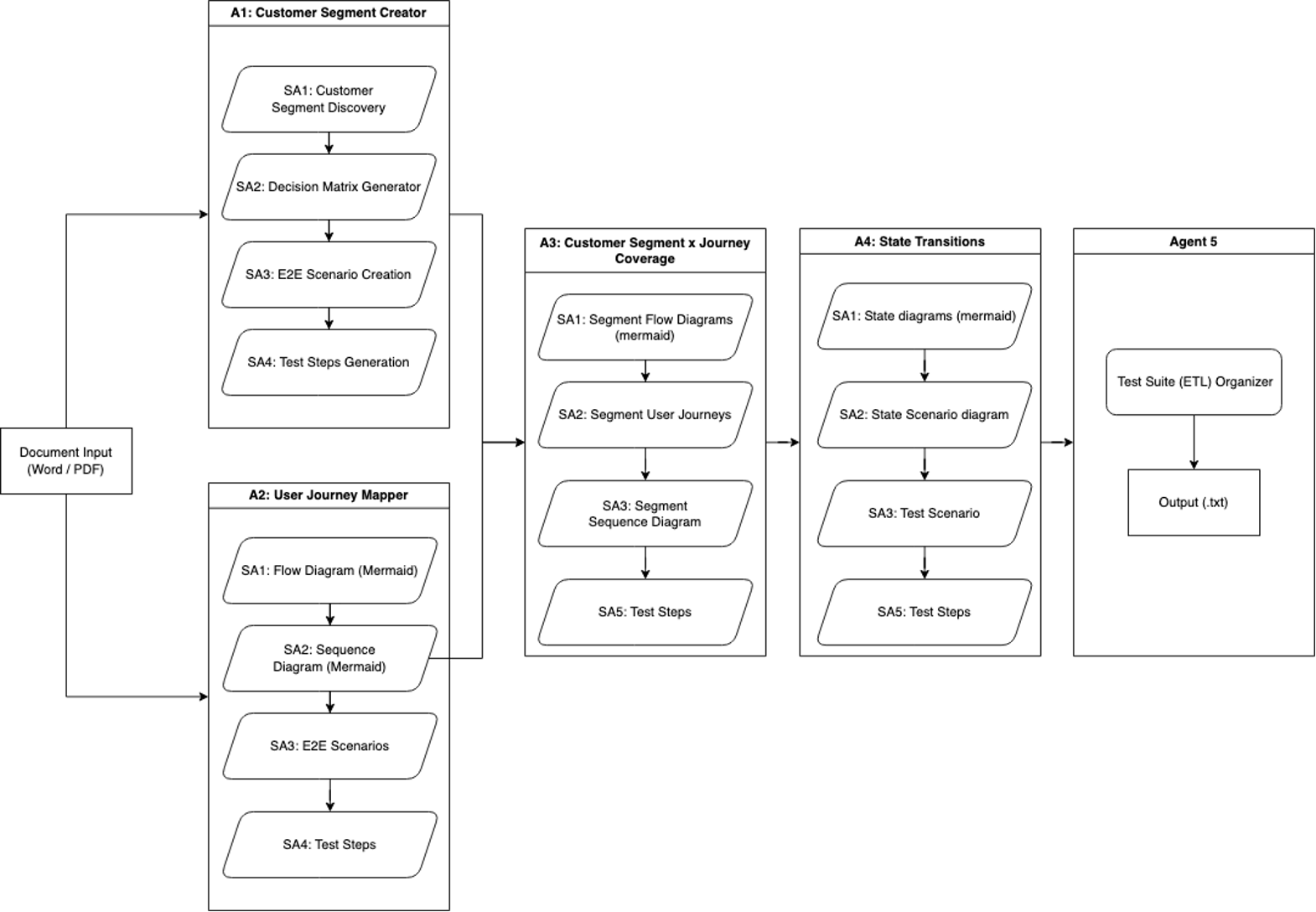
Phương pháp tiếp cận có hệ thống này tạo điều kiện cho việc bao phủ toàn diện các hành trình khách hàng, phân khúc và các loại sơ đồ khác nhau, cho phép tạo độ bao phủ kiểm thử kỹ lưỡng thông qua xử lý lặp đi lặp lại bởi các tác nhân và tác nhân phụ.
Giải quyết các hạn chế và nâng cao khả năng
Trong hành trình phát triển một công cụ mạnh mẽ và hiệu quả hơn bằng cách sử dụng Strands Agents, chúng tôi đã xác định năm hạn chế quan trọng trong cách tiếp cận ban đầu của mình:
- Thách thức về ngữ cảnh và “ảo giác” – Quy trình làm việc đầu tiên của chúng tôi phải đối mặt với các hạn chế từ các hoạt động tác nhân riêng biệt, nơi các tác nhân riêng lẻ độc lập thu thập dữ liệu và tạo ra các biểu diễn trực quan. Sự cô lập này dẫn đến hiểu biết ngữ cảnh hạn chế, dẫn đến giảm độ chính xác và tăng “ảo giác” trong các đầu ra.
- Hiệu quả tạo dữ liệu kém – Ngữ cảnh hạn chế có sẵn cho các tác nhân đã gây ra một vấn đề quan trọng khác: tạo ra quá nhiều dữ liệu không liên quan. Nếu không có nhận thức ngữ cảnh phù hợp, các tác nhân đã tạo ra các đầu ra ít tập trung hơn, dẫn đến nhiễu làm che khuất những hiểu biết có giá trị.
- Khả năng phân tích cú pháp bị hạn chế – Phạm vi phân tích cú pháp dữ liệu của hệ thống ban đầu tỏ ra quá hẹp, chỉ giới hạn ở các phân khúc khách hàng, ánh xạ hành trình và các yêu cầu cơ bản. Hạn chế này đã ngăn các tác nhân truy cập toàn bộ thông tin cần thiết cho phân tích toàn diện.
- Hạn chế đầu vào một nguồn – Quy trình làm việc chỉ có thể xử lý các tài liệu Word, tạo ra một nút thắt đáng kể. Môi trường phát triển hiện đại yêu cầu dữ liệu từ nhiều nguồn và hạn chế này đã ngăn cản việc thu thập dữ liệu toàn diện.
- Vấn đề kiến trúc cứng nhắc – Quan trọng là, quy trình làm việc đầu tiên đã sử dụng một hệ thống gắn kết chặt chẽ với điều phối cứng nhắc. Kiến trúc này gây khó khăn trong việc sửa đổi, mở rộng hoặc tái sử dụng các thành phần, hạn chế khả năng thích ứng của hệ thống với các yêu cầu thay đổi.
Trong lần lặp lại thứ hai, chúng tôi cần triển khai các giải pháp chiến lược để giải quyết những vấn đề này.
Lặp lại quy trình làm việc 2: Quy trình phân tích toàn diện
Lần lặp lại thứ hai của chúng tôi đại diện cho một sự tái hình dung hoàn chỉnh về kiến trúc quy trình làm việc tác nhân. Thay vì vá lỗi từng vấn đề riêng lẻ, chúng tôi đã xây dựng lại từ đầu với tính mô-đun, nhận thức ngữ cảnh và khả năng mở rộng là các nguyên tắc cốt lõi:
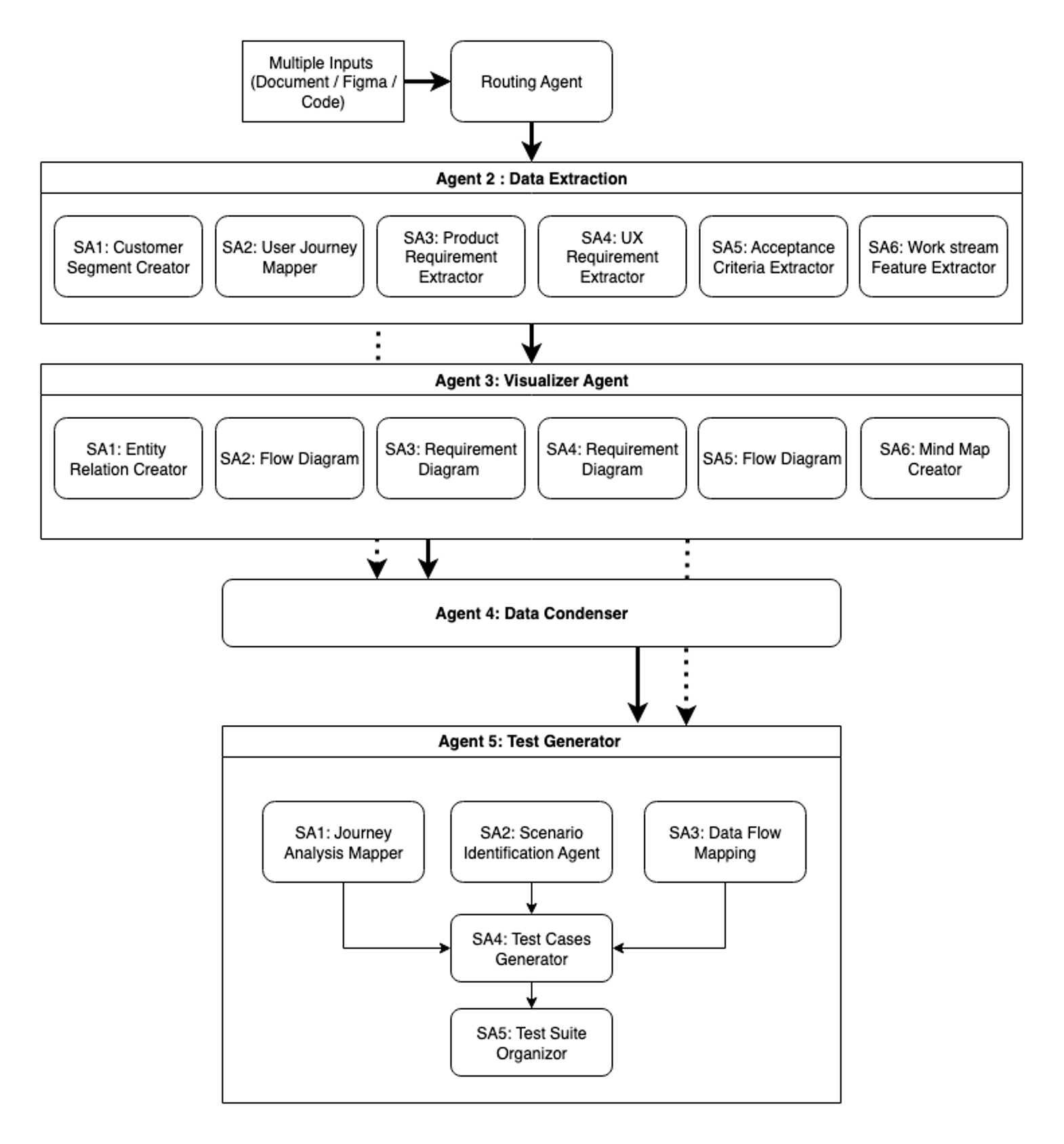
Tác nhân 1 là cổng thông minh. Tác nhân quyết định loại tệp đóng vai trò là điểm vào và bộ định tuyến của hệ thống. Xử lý các tệp tài liệu, thiết kế Figma và kho mã, nó phân loại và định tuyến dữ liệu đến các tác nhân hạ nguồn phù hợp. Việc định tuyến thông minh này là cần thiết để duy trì cả hiệu quả và độ chính xác trong suốt quy trình làm việc.
Tác nhân 2 dành cho việc trích xuất dữ liệu chuyên biệt. Tác nhân Data Extractor sử dụng sáu tác nhân phụ chuyên biệt, mỗi tác nhân tập trung vào các miền trích xuất cụ thể. Phương pháp xử lý song song này tạo điều kiện cho việc bao phủ kỹ lưỡng trong khi duy trì tốc độ thực tế. Mỗi tác nhân phụ hoạt động với kiến thức chuyên biệt theo miền, trích xuất thông tin sắc thái mà các phương pháp tổng quát có thể bỏ qua.
Tác nhân 3 là tác nhân Visualizer, và nó chuyển đổi dữ liệu đã trích xuất thành sáu loại sơ đồ Mermaid riêng biệt, mỗi loại phục vụ các mục đích phân tích cụ thể. Sơ đồ quan hệ thực thể ánh xạ các mối quan hệ và cấu trúc dữ liệu, và sơ đồ luồng trực quan hóa các quy trình và luồng công việc. Sơ đồ yêu cầu làm rõ các thông số kỹ thuật sản phẩm, và trực quan hóa yêu cầu UX minh họa các luồng trải nghiệm người dùng. Sơ đồ luồng quy trình chi tiết các hoạt động hệ thống, và bản đồ tư duy tiết lộ các mối quan hệ và hệ thống phân cấp tính năng. Các trực quan hóa này cung cấp nhiều góc nhìn về cùng một thông tin, giúp cả người đánh giá và các tác nhân hạ nguồn hiểu các mẫu và kết nối trong các tập dữ liệu phức tạp.
Tác nhân 4 là tác nhân Data Condenser, và nó thực hiện tổng hợp quan trọng thông qua chắt lọc ngữ cảnh thông minh, đảm bảo mỗi tác nhân hạ nguồn nhận được chính xác thông tin cần thiết cho tác vụ chuyên biệt của nó. Tác nhân này, được cung cấp bởi trình tạo thông tin cô đọng của nó, hợp nhất các đầu ra từ cả tác nhân Data Extractor và Visualizer trong khi thực hiện phân tích tinh vi.
Tác nhân trích xuất các yếu tố quan trọng từ ngữ cảnh văn bản đầy đủ—tiêu chí chấp nhận, quy tắc nghiệp vụ, phân khúc khách hàng và các trường hợp biên—tạo ra các bản tóm tắt có cấu trúc bảo toàn các chi tiết thiết yếu trong khi giảm mức sử dụng token. Nó so sánh từng tệp văn bản với sơ đồ Mermaid tương ứng của nó, thu thập thông tin có thể bị bỏ lỡ trong các biểu diễn trực quan. Quá trình xử lý cẩn thận này duy trì tính toàn vẹn thông tin giữa các tác nhân, đảm bảo dữ liệu quan trọng không bị mất khi nó chảy qua hệ thống. Kết quả là một tập hợp các phụ lục cô đọng làm phong phú các sơ đồ Mermaid với ngữ cảnh toàn diện. Sự tổng hợp này đảm bảo rằng khi thông tin chuyển đến việc tạo kiểm thử, nó đến đầy đủ, có cấu trúc và được tối ưu hóa để xử lý.
Tác nhân 5 là tác nhân Test Generator tập hợp thông tin đã thu thập, trực quan hóa và cô đọng để tạo ra các bộ kiểm thử toàn diện. Làm việc với sáu sơ đồ Mermaid cộng với thông tin cô đọng từ Tác nhân 4, tác nhân này sử dụng một pipeline gồm năm tác nhân phụ. Journey Analysis Mapper, Scenario Identification Agent và các tác nhân phụ Data Flow Mapping tạo ra các trường hợp kiểm thử toàn diện dựa trên việc tiếp nhận dữ liệu đầu vào từ Tác nhân 4. Với các trường hợp kiểm thử được tạo ra từ ba góc độ quan trọng, Test Cases Generator đánh giá chúng, định dạng lại theo các hướng dẫn nội bộ để nhất quán. Cuối cùng, Test Suite Organizer thực hiện loại bỏ trùng lặp và tối ưu hóa, cung cấp một bộ kiểm thử cuối cùng cân bằng giữa tính toàn diện và hiệu quả.
Hệ thống hiện xử lý nhiều hơn các yêu cầu cơ bản và ánh xạ hành trình của Quy trình làm việc 1—nó xử lý các yêu cầu sản phẩm, thông số kỹ thuật UX, tiêu chí chấp nhận và trích xuất luồng công việc trong khi chấp nhận đầu vào từ thiết kế Figma, kho mã và nhiều loại tài liệu. Quan trọng nhất, sự chuyển đổi sang kiến trúc mô-đun đã thay đổi cơ bản cách hệ thống hoạt động và phát triển. Không giống như quy trình làm việc đầu tiên cứng nhắc của chúng tôi, thiết kế này cho phép tái sử dụng các đầu ra từ các tác nhân trước đó, tích hợp các tác nhân loại kiểm thử mới và lựa chọn thông minh các trình tạo trường hợp kiểm thử dựa trên yêu cầu của người dùng, định vị hệ thống để thích ứng liên tục.
Hình sau đây cho thấy lần lặp lại thứ hai của SAARAM với năm tác nhân chính và nhiều tác nhân phụ với kỹ thuật ngữ cảnh và nén.
Các tính năng bổ sung của Strands Agents
Strands Agents đã cung cấp nền tảng cho hệ thống đa tác nhân của chúng tôi, cung cấp một phương pháp tiếp cận dựa trên mô hình giúp đơn giản hóa việc phát triển tác nhân phức tạp. Vì SDK có thể kết nối các mô hình với các công cụ thông qua khả năng suy luận nâng cao, chúng tôi đã xây dựng các quy trình làm việc tinh vi chỉ với vài dòng mã. Ngoài chức năng cốt lõi của nó, hai tính năng chính đã chứng tỏ là cần thiết cho việc triển khai sản xuất của chúng tôi: giảm “ảo giác” với đầu ra có cấu trúc và điều phối quy trình làm việc.
Giảm hiện tượng “ảo giác” với đầu ra có cấu trúc
Tính năng đầu ra có cấu trúc của Strands Agents sử dụng các mô hình Pydantic để biến đổi các đầu ra LLM thường không thể đoán trước thành các phản hồi đáng tin cậy, an toàn về kiểu. Phương pháp này giải quyết một thách thức cơ bản trong AI tạo sinh: mặc dù LLM xuất sắc trong việc tạo ra văn bản giống con người, chúng có thể gặp khó khăn với các đầu ra được định dạng nhất quán cần thiết cho các hệ thống sản xuất. Bằng cách thực thi các lược đồ thông qua xác thực Pydantic, chúng tôi đảm bảo rằng các phản hồi tuân thủ các cấu trúc được xác định trước, cho phép tích hợp liền mạch với các hệ thống quản lý kiểm thử hiện có.
Việc triển khai mẫu sau đây minh họa cách các đầu ra có cấu trúc hoạt động trong thực tế:
from pydantic import BaseModel, Fieldfrom typing import Listimport json# Define structured output schemaclass TestCaseItem(BaseModel): name: str = Field(description="Test case name") priority: str = Field(description="Priority: P0, P1, or P2") category: str = Field(description="Test category")class TestOutput(BaseModel): test_cases: List[TestCaseItem] = Field(description="Generated test cases")# Agent tool with validation@tooldef save_results(self, results: str) -> str: try: # Parse and validate Claude's JSON output data = json.loads(results) validated = TestOutput(**data) # Save only if validation passes with open("results.json", 'w') as f: json.dump(validated.dict(), f, indent=) return "Validated results saved" except ValidationError as e: return f"Invalid output format: e"
Pydantic tự động xác thực các phản hồi LLM dựa trên các lược đồ đã xác định để tạo điều kiện cho tính đúng kiểu và sự hiện diện của các trường bắt buộc. Khi các phản hồi không khớp với cấu trúc mong đợi, lỗi xác thực cung cấp phản hồi rõ ràng về những gì cần sửa, giúp ngăn chặn dữ liệu bị định dạng sai lan truyền qua hệ thống. Trong môi trường của chúng tôi, phương pháp này đã cung cấp các đầu ra nhất quán, có thể dự đoán được trên các tác nhân bất kể các biến thể lời nhắc hoặc cập nhật mô hình, giảm thiểu toàn bộ loại lỗi định dạng dữ liệu. Kết quả là, nhóm phát triển của chúng tôi làm việc hiệu quả hơn với sự hỗ trợ đầy đủ của IDE.
Lợi ích của điều phối quy trình làm việc
Kiến trúc quy trình làm việc của Strands Agents đã cung cấp các khả năng phối hợp tinh vi mà hệ thống đa tác nhân của chúng tôi yêu cầu. Khung này cho phép phối hợp có cấu trúc với các định nghĩa tác vụ rõ ràng, thực thi song song tự động cho các tác vụ độc lập và xử lý tuần tự cho các hoạt vụ phụ thuộc. Điều này có nghĩa là chúng tôi có thể xây dựng các mẫu giao tiếp phức tạp giữa các tác nhân mà sẽ rất khó để triển khai thủ công.
Đoạn mã mẫu sau đây cho thấy cách tạo một quy trình làm việc trong Strands Agents SDK:
from strands import Agentfrom strands_tools import workflow# Create agent with workflow capabilitymain_agent_3 = create_main_agent_3()# Create workflow with structured output tasksworkflow_result = main_agent_3.tool.workflow( action="create", workflow_id="comprehensive_e2e_test_generation", tasks=[ # Phase 1: Parallel execution (no dependencies) { "task_id": "journey_analysis", "description": "Generate journey scenario names with brief descriptions using structured output", "dependencies": [], "model_provider": "bedrock", "model_settings": { "model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0", "params": {"temperature": } }, "system_prompt": load_prompt("journey_analysis"), "structured_output_model": "JourneyAnalysisOutput", "priority": , "timeout": }, { "task_id": "scenario_identification", "description": "Generate scenario variations using structured output for different path types", "dependencies": [], "model_provider": "bedrock", "model_settings": { "model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0", "params": {"temperature": } }, "system_prompt": load_prompt("scenario_identification"), "structured_output_model": "ScenarioIdentificationOutput", "priority": , "timeout": }, { "task_id": "data_flow_mapping", "description": "Generate data flow scenarios using structured output covering information journey", "dependencies": [], "model_provider": "bedrock", "model_settings": { "model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0", "params": {"temperature": } }, "system_prompt": load_prompt("data_flow_mapping"), "structured_output_model": "DataFlowMappingOutput", "priority": , "timeout": }, # Phase 2: Waits for first 3 tasks to complete { "task_id": "test_case_development", "description": "Generate test cases from all scenario outputs using structured output", "dependencies": ["journey_analysis", "scenario_identification", "data_flow_mapping"], "model_provider": "bedrock", "model_settings": { "model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0", "params": {"temperature": } }, "system_prompt": load_prompt("test_case_development"), "structured_output_model": "TestCaseDevelopmentOutput", "priority": , "timeout": }, # Phase 3: Waits for test case development to complete { "task_id": "test_suite_organization", "description": "Organize all test cases into final comprehensive test suite using structured output", "dependencies": ["test_case_development"], "model_provider": "bedrock", "model_settings": { "model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0", "params": {"temperature": } }, "system_prompt": load_prompt("test_suite_organization"), "structured_output_model": "TestSuiteOrganizationOutput", "priority": , "timeout": } ]
Hệ thống quy trình làm việc đã cung cấp ba khả năng quan trọng cho trường hợp sử dụng của chúng tôi. Thứ nhất, tối ưu hóa xử lý song song cho phép phân tích hành trình, xác định kịch bản và phân tích độ bao phủ chạy đồng thời, với các tác nhân độc lập xử lý các khía cạnh khác nhau mà không chặn lẫn nhau. Hệ thống tự động phân bổ tài nguyên dựa trên khả dụng, tối đa hóa thông lượng.
Thứ hai, quản lý phụ thuộc thông minh đảm bảo rằng việc phát triển kiểm thử chờ xác định kịch bản hoàn thành, và các tác vụ tổ chức phụ thuộc vào các trường hợp kiểm thử được tạo. Ngữ cảnh được bảo toàn và truyền hiệu quả giữa các giai đoạn phụ thuộc, duy trì tính toàn vẹn thông tin trong suốt quy trình làm việc.
Cuối cùng, các tính năng độ tin cậy tích hợp đã cung cấp khả năng phục hồi mà hệ thống của chúng tôi yêu cầu. Các cơ chế thử lại tự động xử lý các lỗi tạm thời một cách linh hoạt, khả năng duy trì trạng thái cho phép tạm dừng và tiếp tục các quy trình làm việc dài hạn, và ghi nhật ký kiểm toán toàn diện hỗ trợ cả việc gỡ lỗi và tối ưu hóa hiệu suất.
Bảng sau đây cho thấy các ví dụ về đầu vào vào quy trình làm việc và các đầu ra tiềm năng.
| Đầu vào: Tài liệu yêu cầu nghiệp vụ | Đầu ra: Các trường hợp kiểm thử được tạo |
|---|---|
| Yêu cầu chức năng: 1. Xử lý thẻ tín dụng. Hệ thống phải: * Hỗ trợ xử lý thanh toán thẻ tín dụng * Xác thực chi tiết thẻ tín dụng trước khi xử lý * Hiển thị biểu mẫu thanh toán và nhập thẻ * Lưu thông tin vận chuyển * Cung cấp xác nhận đơn hàng sau khi thanh toán thành công 2. Xử lý lỗi. Hệ thống phải: * Xử lý lỗi thanh toán một cách linh hoạt * Hiển thị thông báo từ chối thanh toán rõ ràng * Cung cấp tùy chọn thử lại thanh toán * Hỗ trợ chuyển đổi giữa các phương thức thanh toán * Xử lý thời gian chờ của cổng thanh toán bằng cơ chế thử lại 3. Xử lý hoàn tiền. Hệ thống phải: * Hỗ trợ khởi tạo hoàn tiền từ bảng điều khiển quản trị * Xử lý hoàn tiền về phương thức thanh toán ban đầu * Theo dõi và cập nhật trạng thái hoàn tiền * Duy trì hồ sơ giao dịch hoàn tiền 4. Nhiều phương thức thanh toán. Hệ thống phải: * Hỗ trợ thanh toán chia nhỏ qua các phương thức * Xử lý thanh toán một phần bằng thẻ quà tặng * Tính toán số dư còn lại chính xác * Đối chiếu tổng số tiền thanh toán kết hợp * Xác minh tổng số tiền đơn hàng khớp với các khoản thanh toán | TC006: Thanh toán thẻ tín dụng thành công Kịch bản: Khách hàng hoàn tất mua hàng bằng thẻ tín dụng hợp lệ Các bước: 1. Thêm mặt hàng vào giỏ hàng và tiến hành thanh toán. Kết quả mong đợi: Biểu mẫu thanh toán được hiển thị. 2. Nhập thông tin vận chuyển. Kết quả mong đợi: Chi tiết vận chuyển đã được lưu. 3. Chọn phương thức thanh toán thẻ tín dụng. Kết quả mong đợi: Biểu mẫu thẻ được hiển thị. 4. Nhập chi tiết thẻ hợp lệ. Kết quả mong đợi: Thẻ được xác thực. 5. Gửi thanh toán. Kết quả mong đợi: Thanh toán được xử lý, đơn hàng được xác nhận. TC008: Xử lý lỗi thanh toán Kịch bản: Thanh toán thất bại do không đủ tiền hoặc thẻ bị từ chối Các bước: 1. Nhập thẻ không đủ tiền. Kết quả mong đợi: Thông báo thanh toán bị từ chối. 2. Hệ thống cung cấp tùy chọn thử lại. Kết quả mong đợi: Biểu mẫu thanh toán được hiển thị lại. 3. Thử phương thức thanh toán thay thế. Kết quả mong đợi: Thanh toán thay thế thành công. TC009: Thời gian chờ của cổng thanh toán Kịch bản: Cổng thanh toán hết thời gian chờ trong quá trình xử lý giao dịch Các bước: 1. Gửi thanh toán trong thời gian bảo trì cổng. Kết quả mong đợi: Lỗi thời gian chờ được hiển thị. 2. Hệ thống cung cấp cơ chế thử lại. Kết quả mong đợi: Nút thử lại có sẵn. 3. Thử lại thanh toán sau thời gian chờ. Kết quả mong đợi: Thanh toán được xử lý thành công. TC010: Xử lý hoàn tiền Kịch bản: Hoàn tiền cho khách hàng được xử lý về phương thức thanh toán ban đầu Các bước: 1. Khởi tạo hoàn tiền từ bảng điều khiển quản trị. Kết quả mong đợi: Yêu cầu hoàn tiền được tạo. 2. Xử lý hoàn tiền về thẻ ban đầu. Kết quả mong đợi: Giao dịch hoàn tiền được khởi tạo. 3. Xác minh trạng thái hoàn tiền. Kết quả mong đợi: Hoàn tiền được đánh dấu là đã hoàn tất. |
Tích hợp với Amazon Bedrock
Amazon Bedrock đóng vai trò là nền tảng cho các khả năng AI của chúng tôi, cung cấp quyền truy cập liền mạch vào Claude Sonnet của Anthropic thông qua tích hợp dịch vụ AWS tích hợp sẵn của Strands Agents. Chúng tôi đã chọn Claude Sonnet của Anthropic vì khả năng suy luận đặc biệt và khả năng hiểu các yêu cầu miền thanh toán phức tạp. Tích hợp API LLM linh hoạt của Strands Agents đã làm cho việc triển khai này trở nên đơn giản. Đoạn mã sau đây cho thấy cách dễ dàng tạo một tác nhân trong Strands Agents:
import boto3from strands import Agentfrom strands.models import BedrockModelbedrock_model = BedrockModel( model_id="anthropic.claude-sonnet-4-20250514-v1:0", region_name="us-west-2", temperature=0.3,)agent = Agent(model=bedrock_model)
Kiến trúc dịch vụ được quản lý của Amazon Bedrock đã giảm độ phức tạp cơ sở hạ tầng từ việc triển khai của chúng tôi. Dịch vụ này cung cấp khả năng tự động mở rộng quy mô điều chỉnh theo nhu cầu khối lượng công việc của chúng tôi, tạo điều kiện cho hiệu suất nhất quán trên các tác nhân bất kể các mẫu lưu lượng truy cập. Logic thử lại và xử lý lỗi tích hợp đã cải thiện đáng kể độ tin cậy của hệ thống, giảm chi phí vận hành thường liên quan đến việc quản lý cơ sở hạ tầng AI ở quy mô lớn. Sự kết hợp giữa khả năng điều phối tinh vi của Strands Agents và cơ sở hạ tầng mạnh mẽ của Amazon Bedrock đã tạo ra một hệ thống sẵn sàng sản xuất có thể xử lý các quy trình làm việc tạo kiểm thử phức tạp trong khi duy trì các tiêu chuẩn độ tin cậy và hiệu suất cao.
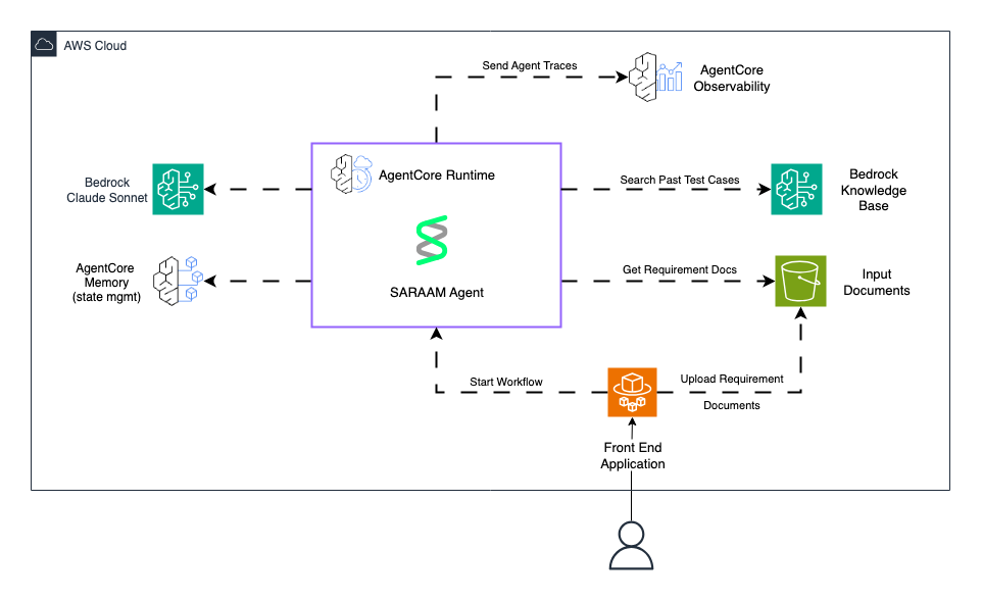
Sơ đồ sau đây cho thấy việc triển khai tác nhân SARAAM với Amazon Bedrock AgentCore và Amazon Bedrock.
Kết quả và tác động kinh doanh
Việc triển khai SAARAM đã cải thiện các quy trình QA của chúng tôi với những cải tiến có thể đo lường được trên nhiều khía cạnh. Trước SAARAM, các kỹ sư QA của chúng tôi đã dành 3–5 ngày để phân tích thủ công các tài liệu BRD và bản mô phỏng UI để tạo ra các trường hợp kiểm thử toàn diện. Quy trình thủ công này hiện được rút ngắn xuống còn vài giờ, với hệ thống đạt được:
- Thời gian tạo trường hợp kiểm thử: Tiềm năng giảm từ 1 tuần xuống còn vài giờ
- Tối ưu hóa tài nguyên: Nỗ lực QA giảm từ 1.0 nhân viên toàn thời gian (FTE) xuống 0.2 FTE cho việc xác thực
- Cải thiện độ bao phủ: Xác định thêm 40% các trường hợp biên so với quy trình thủ công
- Tính nhất quán: Tuân thủ 100% các tiêu chuẩn và định dạng trường hợp kiểm thử
Việc tạo trường hợp kiểm thử được tăng tốc đã thúc đẩy những cải tiến trong các chỉ số kinh doanh cốt lõi của chúng tôi:
- Tỷ lệ thanh toán thành công: Tăng thông qua kiểm thử trường hợp biên toàn diện và ưu tiên kiểm thử dựa trên rủi ro
- Trải nghiệm thanh toán: Nâng cao sự hài lòng của khách hàng vì các nhóm hiện có thể lặp lại độ bao phủ kiểm thử trong giai đoạn thiết kế
- Tốc độ phát triển: Các nhóm sản phẩm và phát triển tạo ra các trường hợp kiểm thử sơ bộ trong giai đoạn thiết kế, cho phép phản hồi chất lượng sớm
SARAAM thu thập và bảo tồn kiến thức chuyên môn trước đây phụ thuộc vào từng kỹ sư QA:
- Các mẫu kiểm thử từ các chuyên gia có kinh nghiệm hiện được mã hóa
- Các bài học về trường hợp kiểm thử lịch sử được tự động áp dụng cho các tính năng mới
- Các phương pháp kiểm thử nhất quán trên các phương thức thanh toán và ngành khác nhau
- Giảm thời gian đào tạo cho các thành viên nhóm QA mới
Sự cải tiến lặp đi lặp lại này có nghĩa là hệ thống trở nên có giá trị hơn theo thời gian.
Bài học kinh nghiệm
Hành trình phát triển SAARAM của chúng tôi đã cung cấp những hiểu biết quan trọng để xây dựng các hệ thống AI sẵn sàng sản xuất. Bước đột phá của chúng tôi đến từ việc nghiên cứu cách các chuyên gia miền suy nghĩ thay vì tối ưu hóa cách AI xử lý thông tin. Hiểu các mô hình nhận thức của các kiểm thử viên và chuyên gia QA đã dẫn đến một kiến trúc phù hợp tự nhiên với lý luận của con người. Phương pháp này đã tạo ra kết quả tốt hơn so với các tối ưu hóa thuần túy kỹ thuật. Các tổ chức xây dựng các hệ thống tương tự nên dành thời gian quan sát và phỏng vấn các chuyên gia miền trước khi thiết kế kiến trúc AI của họ—những hiểu biết thu được trực tiếp chuyển thành thiết kế tác nhân hiệu quả hơn.
Việc chia nhỏ các tác vụ phức tạp thành các tác nhân chuyên biệt đã cải thiện đáng kể cả độ chính xác và độ tin cậy. Kiến trúc đa tác nhân của chúng tôi, được kích hoạt bởi khả năng điều phối của Strands Agents, xử lý các sắc thái mà các phương pháp đơn khối thường bỏ lỡ. Trách nhiệm tập trung của mỗi tác nhân cho phép chuyên môn miền sâu hơn đồng thời cung cấp khả năng cách ly lỗi và gỡ lỗi tốt hơn.
Một khám phá quan trọng là quy trình làm việc của Strands Agents và các mẫu điều phối dựa trên biểu đồ đã vượt trội đáng kể so với các phương pháp tác nhân giám sát truyền thống. Mặc dù các tác nhân giám sát đưa ra các quyết định định tuyến động có thể gây ra sự biến đổi, các quy trình làm việc cung cấp “các tác nhân trên đường ray”—một đường dẫn có cấu trúc tạo điều kiện cho kết quả nhất quán, có thể tái tạo. Strands Agents cung cấp nhiều mẫu, bao gồm định tuyến dựa trên giám sát, điều phối quy trình làm việc cho xử lý tuần tự với các phụ thuộc và phối hợp dựa trên biểu đồ cho các kịch bản phức tạp. Đối với việc tạo kiểm thử nơi tính nhất quán là tối quan trọng, mẫu quy trình làm việc với các phụ thuộc tác vụ rõ ràng và khả năng thực thi song song đã mang lại sự cân bằng tối ưu giữa tính linh hoạt và kiểm soát. Phương pháp có cấu trúc này hoàn toàn phù hợp với môi trường sản xuất nơi độ tin cậy quan trọng hơn tính linh hoạt lý thuyết.
Việc triển khai các mô hình Pydantic thông qua tính năng đầu ra có cấu trúc của Strands Agents đã giảm hiệu quả các “ảo giác” liên quan đến kiểu trong hệ thống của chúng tôi. Bằng cách buộc các phản hồi AI phải tuân thủ các lược đồ nghiêm ngặt, chúng tôi tạo điều kiện cho các đầu ra đáng tin cậy, có thể sử dụng được bằng chương trình. Phương pháp này đã chứng tỏ là cần thiết khi tính nhất quán và độ tin cậy là không thể thương lượng. Các phản hồi an toàn về kiểu và xác thực tự động đã trở thành nền tảng cho độ tin cậy của hệ thống của chúng tôi.
Mẫu trình tạo thông tin cô đọng của chúng tôi chứng minh cách quản lý ngữ cảnh thông minh duy trì chất lượng trong suốt quá trình xử lý đa giai đoạn. Phương pháp này về việc biết những gì cần bảo tồn, cô đọng và truyền giữa các tác nhân giúp ngăn chặn sự suy giảm ngữ cảnh thường xảy ra trong môi trường giới hạn token. Mẫu này có thể áp dụng rộng rãi cho các hệ thống AI đa giai đoạn đối mặt với các hạn chế tương tự.
Bước tiếp theo
Kiến trúc mô-đun mà chúng tôi đã xây dựng với Strands Agents cho phép thích ứng đơn giản với các miền khác trong Amazon. Các mẫu tương tự tạo ra các trường hợp kiểm thử thanh toán có thể được áp dụng cho kiểm thử hệ thống bán lẻ, tạo kịch bản dịch vụ khách hàng cho các quy trình làm việc hỗ trợ và tạo trường hợp kiểm thử UI và UX ứng dụng di động. Mỗi sự thích ứng chỉ yêu cầu các lời nhắc và lược đồ cụ thể theo miền trong khi tái sử dụng logic điều phối cốt lõi. Trong suốt quá trình phát triển SAARAM, nhóm đã giải quyết thành công nhiều thách thức trong việc tạo trường hợp kiểm thử—từ giảm “ảo giác” thông qua các đầu ra có cấu trúc đến triển khai các quy trình làm việc đa tác nhân tinh vi. Tuy nhiên, một khoảng trống quan trọng vẫn còn: hệ thống vẫn chưa được cung cấp các ví dụ về các trường hợp kiểm thử chất lượng cao thực sự trông như thế nào trong thực tế.
Để thu hẹp khoảng cách này, việc tích hợp Amazon Bedrock Knowledge Bases với một kho lưu trữ được tuyển chọn các trường hợp kiểm thử lịch sử sẽ cung cấp cho SAARAM các ví dụ cụ thể, thực tế trong quá trình tạo. Bằng cách sử dụng khả năng tích hợp của Strands Agents với Amazon Bedrock Knowledge Bases, hệ thống có thể tìm kiếm các trường hợp kiểm thử thành công trong quá khứ để tìm các kịch bản tương tự trước khi tạo các kịch bản mới. Khi xử lý một BRD cho một tính năng thanh toán mới, SAARAM sẽ truy vấn cơ sở kiến thức để tìm các trường hợp kiểm thử tương đương—cho dù là cho các phương thức thanh toán, phân khúc khách hàng hoặc luồng giao dịch tương tự—và sử dụng chúng làm ví dụ ngữ cảnh để hướng dẫn đầu ra của nó.
Việc triển khai trong tương lai sẽ sử dụng Amazon Bedrock AgentCore để quản lý vòng đời tác nhân toàn diện. Amazon Bedrock AgentCore Runtime cung cấp môi trường thực thi sản xuất với quản lý trạng thái tạm thời, dành riêng cho phiên duy trì ngữ cảnh hội thoại trong các phiên hoạt động trong khi tạo điều kiện cách ly giữa các tương tác người dùng khác nhau. Khả năng quan sát của Bedrock AgentCore giúp cung cấp các trực quan hóa chi tiết về từng bước trong quy trình làm việc đa tác nhân của SAARAM, mà nhóm có thể sử dụng để theo dõi các đường dẫn thực thi qua năm tác nhân, kiểm toán các đầu ra trung gian từ các tác nhân Data Condenser và Test Generator, và xác định các nút thắt cổ chai hiệu suất thông qua các bảng điều khiển thời gian thực được cung cấp bởi Amazon CloudWatch với đo lường từ xa tương thích OpenTelemetry được chuẩn hóa.
Dịch vụ này cho phép một số khả năng nâng cao cần thiết cho việc triển khai sản xuất: quản lý tác nhân tập trung và quản lý phiên bản thông qua mặt phẳng điều khiển Amazon Bedrock AgentCore, kiểm thử A/B các chiến lược quy trình làm việc khác nhau và các biến thể lời nhắc trên năm tác nhân phụ trong Test Generator, giám sát hiệu suất với các chỉ số theo dõi mức sử dụng token và độ trễ trên các giai đoạn thực thi song song, cập nhật tác nhân tự động mà không làm gián đoạn các quy trình làm việc tạo kiểm thử đang hoạt động, và duy trì phiên để duy trì ngữ cảnh khi các kỹ sư QA tinh chỉnh lặp đi lặp lại các đầu ra bộ kiểm thử. Sự tích hợp này định vị SAARAM cho việc triển khai ở quy mô doanh nghiệp trong khi cung cấp khả năng hiển thị hoạt động và kiểm soát độ tin cậy biến nó từ một bằng chứng khái niệm thành một hệ thống sản xuất có khả năng xử lý mục tiêu đầy tham vọng của nhóm AMET là mở rộng ra ngoài QA Payments để phục vụ toàn bộ tổ chức.
Kết luận
SAARAM chứng minh cách AI có thể thay đổi các quy trình QA truyền thống khi được thiết kế với chuyên môn của con người làm cốt lõi. Bằng cách giảm thời gian tạo trường hợp kiểm thử từ 1 tuần xuống còn vài giờ đồng thời cải thiện chất lượng và độ bao phủ, chúng tôi đã cho phép triển khai tính năng nhanh hơn và nâng cao trải nghiệm thanh toán cho hàng triệu khách hàng trên khắp khu vực MENA. Chìa khóa thành công của chúng tôi không chỉ là công nghệ AI tiên tiến—mà là sự kết hợp giữa chuyên môn của con người, thiết kế kiến trúc chu đáo và các thực hành kỹ thuật mạnh mẽ. Thông qua nghiên cứu cẩn thận về cách các chuyên gia QA có kinh nghiệm suy nghĩ, triển khai các hệ thống đa tác nhân phản ánh các mô hình nhận thức này và giảm thiểu các hạn chế của AI thông qua các đầu ra có cấu trúc và kỹ thuật ngữ cảnh, chúng tôi đã tạo ra một hệ thống nâng cao chứ không thay thế chuyên môn của con người.
Đối với các nhóm đang xem xét các sáng kiến tương tự, kinh nghiệm của chúng tôi nhấn mạnh ba yếu tố thành công quan trọng: đầu tư thời gian để hiểu các quy trình nhận thức của các chuyên gia miền, triển khai các đầu ra có cấu trúc để giảm thiểu “ảo giác” và thiết kế kiến trúc đa tác nhân phản ánh các phương pháp giải quyết vấn đề của con người. Các công cụ QA này không nhằm mục đích thay thế các kiểm thử viên con người, chúng khuếch đại chuyên môn của họ thông qua tự động hóa thông minh. Nếu bạn quan tâm đến việc bắt đầu hành trình của mình về các tác nhân với AWS, hãy xem kho lưu trữ các triển khai mẫu Strands Agents hoặc bản phát hành mới nhất của chúng tôi, Amazon Bedrock AgentCore, và các ví dụ từ đầu đến cuối với việc triển khai trên kho lưu trữ mẫu Amazon Bedrock AgentCore.
Về tác giả

Jayashree R là Kỹ sư Đảm bảo Chất lượng tại Amazon Music Tech, nơi cô kết hợp chuyên môn kiểm thử thủ công nghiêm ngặt với niềm đam mê mới nổi về tự động hóa được hỗ trợ bởi GenAI. Công việc của cô tập trung vào việc duy trì các tiêu chuẩn chất lượng hệ thống cao trong khi khám phá các phương pháp tiếp cận đổi mới để làm cho việc kiểm thử trở nên thông minh và hiệu quả hơn. Với cam kết giảm sự đơn điệu trong kiểm thử và nâng cao chất lượng sản phẩm trên toàn hệ sinh thái của Amazon, Jayashree đang đi đầu trong việc tích hợp trí tuệ nhân tạo vào các thực hành đảm bảo chất lượng.

Harsha Pradha G là Kỹ sư Đảm bảo Chất lượng cấp cao thuộc bộ phận MENA Payments tại Amazon. Với nền tảng vững chắc trong việc xây dựng các chiến lược chất lượng toàn diện, cô mang đến một góc nhìn độc đáo về sự giao thoa giữa QA và AI với tư cách là một nhà tích hợp QA-AI mới nổi. Công việc của cô tập trung vào việc thu hẹp khoảng cách giữa các phương pháp kiểm thử truyền thống và các đổi mới AI tiên tiến, đồng thời đóng vai trò là chiến lược gia nội dung AI và Tác giả AI.

Fahim Surani là Kiến trúc sư Giải pháp cấp cao tại AWS, giúp khách hàng trong các lĩnh vực Dịch vụ Tài chính, Năng lượng và Viễn thông thiết kế và xây dựng các giải pháp đám mây và AI tạo sinh. Trọng tâm của anh kể từ năm 2022 là thúc đẩy việc áp dụng đám mây trong doanh nghiệp, bao gồm di chuyển lên đám mây, tối ưu hóa chi phí, kiến trúc hướng sự kiện, bao gồm cả việc dẫn đầu các triển khai được công nhận là những người sớm áp dụng các khả năng AI mới nhất của Amazon. Công việc của Fahim bao gồm nhiều trường hợp sử dụng, với mối quan tâm chính là AI tạo sinh, kiến trúc tác nhân. Anh thường xuyên là diễn giả tại các hội nghị thượng đỉnh của AWS và các sự kiện ngành trong khu vực.
TAGS: AI/ML, Amazon Machine Learning, Generative AI, Technical How-to
