Tác giả: Srini Ponnada, Davide Pagano, Ashish Agrawal, và Niranjan Kulkarni
Ngày phát hành: 15 JAN 2026
Chuyên mục: Amazon Redshift, Announcements, Intermediate (200), Serverless, Technical How-to
Amazon Redshift Serverless loại bỏ việc quản lý cơ sở hạ tầng và các yêu cầu mở rộng thủ công khỏi các hoạt động kho dữ liệu. Quản lý tài nguyên truy vấn dựa trên hàng đợi của Amazon Redshift Serverless giúp bạn bảo vệ các khối lượng công việc quan trọng và kiểm soát chi phí bằng cách cô lập các truy vấn vào các hàng đợi chuyên dụng với các quy tắc tự động ngăn chặn các truy vấn vượt quá giới hạn ảnh hưởng đến những người dùng khác. Bạn có thể tạo các hàng đợi truy vấn chuyên dụng với các quy tắc giám sát tùy chỉnh cho các khối lượng công việc khác nhau, cung cấp khả năng kiểm soát chi tiết việc sử dụng tài nguyên. Các hàng đợi cho phép bạn xác định các vị từ dựa trên số liệu và các phản hồi tự động, chẳng hạn như tự động hủy bỏ các truy vấn vượt quá giới hạn thời gian hoặc tiêu thụ quá nhiều tài nguyên.
Các khối lượng công việc phân tích khác nhau có những yêu cầu riêng biệt. Các bảng điều khiển tiếp thị cần thời gian phản hồi nhanh và nhất quán. Các khối lượng công việc khoa học dữ liệu có thể chạy các truy vấn phức tạp, tốn nhiều tài nguyên. Các quy trình trích xuất, chuyển đổi và tải (ETL) có thể thực hiện các chuyển đổi dài trong giờ thấp điểm.
Khi các tổ chức mở rộng việc sử dụng phân tích cho nhiều người dùng, nhóm và khối lượng công việc hơn, việc đảm bảo hiệu suất nhất quán và kiểm soát chi phí ngày càng trở nên thách thức trong một môi trường chia sẻ. Một truy vấn được tối ưu hóa kém có thể tiêu thụ tài nguyên không cân xứng, làm giảm hiệu suất cho các bảng điều khiển quan trọng trong kinh doanh, các tác vụ ETL và báo cáo điều hành. Với Quy tắc giám sát truy vấn (QMR) dựa trên hàng đợi của Amazon Redshift Serverless, quản trị viên có thể xác định ngưỡng nhận biết khối lượng công việc và các hành động tự động ở cấp độ hàng đợi—một cải tiến đáng kể so với giám sát cấp workgroup trước đây. Bạn có thể tạo các hàng đợi chuyên dụng cho các khối lượng công việc riêng biệt như báo cáo BI, phân tích ad hoc hoặc kỹ thuật dữ liệu, sau đó áp dụng các quy tắc cụ thể cho hàng đợi để tự động hủy bỏ, ghi nhật ký hoặc hạn chế các truy vấn vượt quá giới hạn thời gian thực thi hoặc tiêu thụ tài nguyên. Bằng cách cô lập các khối lượng công việc và thực thi các kiểm soát mục tiêu, phương pháp này bảo vệ các truy vấn quan trọng, cải thiện khả năng dự đoán hiệu suất và ngăn chặn việc độc quyền tài nguyên—tất cả trong khi vẫn duy trì sự linh hoạt của trải nghiệm serverless.
Trong bài viết này, chúng tôi thảo luận về cách bạn có thể triển khai các khối lượng công việc của mình với hàng đợi truy vấn trong Redshift Serverless.
Giám sát dựa trên hàng đợi so với giám sát cấp workgroup
Trước khi có hàng đợi truy vấn, Redshift Serverless chỉ cung cấp các quy tắc giám sát truy vấn (QMR) ở cấp độ workgroup. Điều này có nghĩa là các truy vấn, bất kể mục đích hay người dùng, đều phải tuân theo cùng một quy tắc giám sát.
Giám sát dựa trên hàng đợi thể hiện một bước tiến đáng kể:
- Kiểm soát chi tiết – Bạn có thể tạo các hàng đợi chuyên dụng cho các loại khối lượng công việc khác nhau
- Gán dựa trên vai trò – Bạn có thể định hướng các truy vấn đến các hàng đợi cụ thể dựa trên vai trò người dùng và nhóm truy vấn
- Hoạt động độc lập – Mỗi hàng đợi duy trì các quy tắc giám sát riêng
Tổng quan giải pháp
Trong các phần sau, chúng tôi sẽ xem xét cách một tổ chức điển hình có thể triển khai hàng đợi truy vấn trong Redshift Serverless.
Các thành phần kiến trúc
- Cấu hình Workgroup
- Đơn vị nền tảng nơi các hàng đợi truy vấn được định nghĩa
- Chứa các định nghĩa hàng đợi, ánh xạ vai trò người dùng và quy tắc giám sát
- Cấu trúc hàng đợi
- Nhiều hàng đợi độc lập hoạt động trong một workgroup duy nhất
- Mỗi hàng đợi có các tham số phân bổ tài nguyên và quy tắc giám sát riêng
- Ánh xạ Người dùng/Vai trò
- Định hướng các truy vấn đến các hàng đợi thích hợp dựa trên:
- Vai trò người dùng (ví dụ: analyst, etl_role, admin)
- Nhóm truy vấn (ví dụ: reporting, group_etl_inbound)
- Ký tự đại diện nhóm truy vấn để khớp linh hoạt
- Quy tắc giám sát truy vấn (QMR)
- Xác định ngưỡng cho các số liệu như thời gian thực thi và mức sử dụng tài nguyên
- Chỉ định các hành động tự động (hủy bỏ, ghi nhật ký) khi vượt quá ngưỡng
Điều kiện tiên quyết
Để triển khai hàng đợi truy vấn trong Amazon Redshift Serverless, bạn cần có các điều kiện tiên quyết sau:
Môi trường Redshift Serverless:
- Workgroup Amazon Redshift Serverless đang hoạt động
- Namespace liên quan
Yêu cầu truy cập:
- Truy cập AWS Management Console với các quyền Redshift Serverless
- Truy cập AWS CLI (tùy chọn cho triển khai dòng lệnh)
- Thông tin đăng nhập cơ sở dữ liệu quản trị cho workgroup của bạn
Các quyền yêu cầu:
- Quyền IAM cho các hoạt động của Redshift Serverless (CreateWorkgroup, UpdateWorkgroup)
- Khả năng tạo và quản lý người dùng và vai trò cơ sở dữ liệu
Xác định các loại khối lượng công việc
Bắt đầu bằng cách phân loại các khối lượng công việc của bạn. Các mẫu phổ biến bao gồm:
- Phân tích tương tác – Các bảng điều khiển và báo cáo yêu cầu thời gian phản hồi nhanh
- Khoa học dữ liệu – Phân tích khám phá phức tạp, tốn nhiều tài nguyên
- ETL/ELT – Xử lý hàng loạt với thời gian chạy dài hơn
- Quản trị – Các hoạt động bảo trì yêu cầu đặc quyền đặc biệt
Định cấu hình hàng đợi
Đối với mỗi loại khối lượng công việc, hãy xác định các tham số và quy tắc thích hợp. Để có một ví dụ thực tế, hãy giả sử chúng ta muốn triển khai ba hàng đợi:
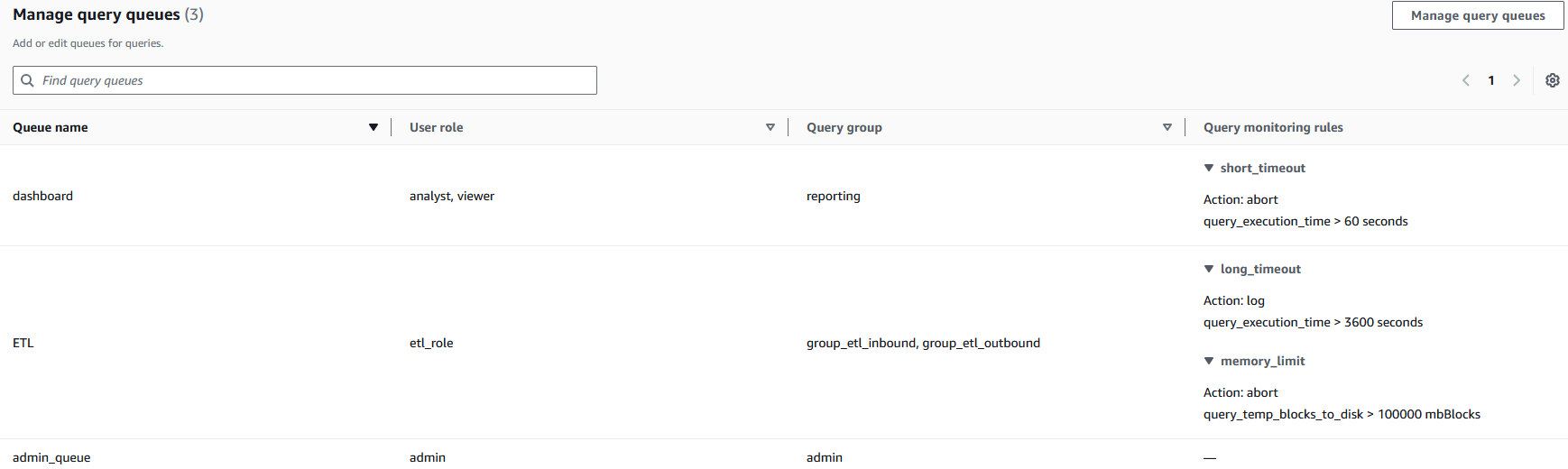
- Hàng đợi Dashboard – Được sử dụng bởi các vai trò người dùng analyst và viewer, với giới hạn thời gian chạy nghiêm ngặt được đặt để dừng các truy vấn dài hơn 60 giây
- Hàng đợi ETL – Được sử dụng bởi các vai trò người dùng etl_role, với giới hạn 100.000 khối trên đĩa tràn (
query_temp_blocks_to_disk) để kiểm soát việc sử dụng tài nguyên trong các hoạt động xử lý dữ liệu - Hàng đợi Admin – Được sử dụng bởi các vai trò người dùng admin, không áp dụng giới hạn giám sát truy vấn
Để triển khai điều này bằng cách sử dụng AWS Management Console, hãy hoàn thành các bước sau:
- Trên console Redshift Serverless, đi tới workgroup của bạn.
- Trên tab Limits, trong phần Query queues, chọn Enable queues.
- Cấu hình mỗi hàng đợi với các tham số thích hợp, như được hiển thị trong ảnh chụp màn hình sau.
Mỗi hàng đợi (dashboard, ETL, admin_queue) được ánh xạ tới các vai trò người dùng và nhóm truy vấn cụ thể, tạo ra ranh giới rõ ràng giữa các quy tắc truy vấn. Các quy tắc giám sát truy vấn triển khai quản trị tài nguyên tự động—ví dụ, hàng đợi dashboard tự động dừng các truy vấn vượt quá 60 giây (short_timeout) trong khi cho phép các quy trình ETL có thời gian chạy dài hơn với các ngưỡng khác nhau. Cấu hình này giúp ngăn chặn việc độc quyền tài nguyên bằng cách thiết lập các làn xử lý riêng biệt với các rào chắn thích hợp, để các quy trình kinh doanh quan trọng có thể duy trì các tài nguyên tính toán cần thiết trong khi hạn chế tác động của các hoạt động tốn nhiều tài nguyên.
Ngoài ra, bạn có thể triển khai giải pháp bằng cách sử dụng AWS Command Line Interface (AWS CLI).
Trong ví dụ sau, chúng ta tạo một workgroup mới có tên test-workgroup trong một namespace hiện có tên là test-namespace. Điều này giúp tạo các hàng đợi và thiết lập các quy tắc giám sát liên quan cho mỗi hàng đợi bằng cách sử dụng lệnh sau:
aws redshift-serverless create-workgroup \ --workgroup-name test-workgroup \ --namespace-name test-namespace \ --config-parameters '[{"parameterKey": "wlm_json_configuration", "parameterValue": "[{\"name\":\"dashboard\",\"user_role\":[\"analyst\",\"viewer\"],\"query_group\":[\"reporting\"],\"query_group_wild_card\":1,\"rules\":[{\"rule_name\":\"short_timeout\",\"predicate\":[{\"metric_name\":\"query_execution_time\",\"operator\":\">\",\"value\":60}],\"action\":\"abort\"}]},{\"name\":\"ETL\",\"user_role\":[\"etl_role\"],\"query_group\":[\"group_etl_inbound\",\"group_etl_outbound\"],\"rules\":[{\"rule_name\":\"long_timeout\",\"predicate\":[{\"metric_name\":\"query_execution_time\",\"operator\":\">\",\"value\":3600}],\"action\":\"log\"},{\"rule_name\":\"memory_limit\",\"predicate\":[{\"metric_name\":\"query_temp_blocks_to_disk\",\"operator\":\">\",\"value\":100000}],\"action\":\"abort\"}]},{\"name\":\"admin_queue\",\"user_role\":[\"admin\"],\"query_group\":[\"admin\"]}]"}]'
Bạn cũng có thể sửa đổi một workgroup hiện có bằng cách sử dụng update-workgroup bằng lệnh sau:
aws redshift-serverless update-workgroup \ --workgroup-name test-workgroup \ --namespace-name test-namespace \ --config-parameters '[{"parameterKey": "wlm_json_configuration", "parameterValue": "[{\"name\":\"dashboard\",\"user_role\":[\"analyst\",\"viewer\"],\"query_group\":[\"reporting\"],\"query_group_wild_card\":1,\"rules\":[{\"rule_name\":\"short_timeout\",\"predicate\":[{\"metric_name\":\"query_execution_time\",\"operator\":\">\",\"value\":60}],\"action\":\"abort\"}]},{\"name\":\"ETL\",\"user_role\":[\"etl_role\"],\"query_group\":[\"group_etl_load\",\"group_etl_replication\"],\"rules\":[{\"rule_name\":\"long_timeout\",\"predicate\":[{\"metric_name\":\"query_execution_time\",\"operator\":\">\",\"value\":3600}],\"action\":\"log\"},{\"rule_name\":\"memory_limit\",\"predicate\":[{\"metric_name\":\"query_temp_blocks_to_disk\",\"operator\":\">\",\"value\":100000}],\"action\":\"abort\"}]},{\"name\":\"admin_queue\",\"user_role\":[\"admin\"],\"query_group\":[\"admin\"]}]"}]'
Các phương pháp hay nhất để quản lý hàng đợi
Hãy xem xét các phương pháp hay nhất sau:
- Bắt đầu đơn giản – Bắt đầu với một tập hợp tối thiểu các hàng đợi và quy tắc
- Phù hợp với ưu tiên kinh doanh – Cấu hình hàng đợi để phản ánh các quy trình kinh doanh quan trọng
- Giám sát và điều chỉnh – Thường xuyên xem xét hiệu suất hàng đợi và điều chỉnh ngưỡng
- Kiểm tra trước khi sản xuất – Xác thực hành vi số liệu truy vấn trong môi trường thử nghiệm trước khi áp dụng vào sản xuất
Dọn dẹp tài nguyên
Để dọn dẹp tài nguyên của bạn, hãy xóa các workgroup và namespace của Amazon Redshift Serverless. Để biết hướng dẫn, hãy xem Xóa một workgroup.
Kết luận
Hàng đợi truy vấn trong Amazon Redshift Serverless thu hẹp khoảng cách giữa sự đơn giản của serverless và khả năng kiểm soát khối lượng công việc chi tiết bằng cách cho phép các Quy tắc giám sát truy vấn (QMR) dành riêng cho hàng đợi được điều chỉnh cho các khối lượng công việc phân tích khác nhau. Bằng cách cô lập các khối lượng công việc và thực thi các ngưỡng tài nguyên mục tiêu, bạn có thể bảo vệ các truy vấn quan trọng trong kinh doanh, cải thiện khả năng dự đoán hiệu suất và hạn chế các truy vấn vượt quá giới hạn, giúp giảm thiểu việc tiêu thụ tài nguyên không mong muốn và kiểm soát chi phí tốt hơn, đồng thời vẫn hưởng lợi từ khả năng tự động mở rộng và sự đơn giản trong vận hành của Redshift Serverless.
Bắt đầu với Amazon Redshift Serverless ngay hôm nay.
Về tác giả

Srini Ponnada
Srini là Kiến trúc sư Dữ liệu cấp cao tại Amazon Web Services (AWS). Ông đã giúp khách hàng xây dựng các giải pháp kho dữ liệu và dữ liệu lớn có khả năng mở rộng trong hơn 20 năm. Ông yêu thích việc thiết kế và xây dựng các giải pháp đầu cuối hiệu quả trên AWS.

Niranjan Kulkarni
Niranjan là Kỹ sư Phát triển Phần mềm cho Amazon Redshift. Ông tập trung vào việc áp dụng Amazon Redshift Serverless và các tính năng liên quan đến bảo mật của Amazon Redshift. Ngoài công việc, ông dành thời gian cho gia đình và thích xem các bộ phim truyền hình chất lượng cao.

Ashish Agrawal
Ashish hiện là Quản lý Sản phẩm Kỹ thuật Chính tại Amazon Redshift, xây dựng các giải pháp kho dữ liệu dựa trên đám mây và dịch vụ đám mây phân tích. Ashish có hơn 24 năm kinh nghiệm trong lĩnh vực CNTT. Ashish có chuyên môn về kho dữ liệu, hồ dữ liệu và nền tảng dưới dạng dịch vụ. Ashish là diễn giả tại các hội nghị kỹ thuật trên toàn thế giới.

Davide Pagano
Davide là Quản lý Phát triển Phần mềm tại Amazon Redshift, chuyên về xây dựng các giải pháp kho dữ liệu thông minh dựa trên đám mây và dịch vụ đám mây phân tích như quản lý khối lượng công việc tự động, bố cục dữ liệu đa chiều, và mở rộng quy mô và tối ưu hóa dựa trên AI cho Amazon Redshift Serverless. Ông có hơn 10 năm kinh nghiệm với cơ sở dữ liệu, bao gồm 8 năm kinh nghiệm chuyên sâu về Amazon Redshift.
