Tác giả: Jia Li, Xi Wan, Bao Cao, Hanyi Zhang, Xiaowei Zhu, và Zepei Yu
Ngày phát hành: 15 JAN 2026
Chuyên mục: Amazon Bedrock, Amazon Machine Learning, Amazon Nova, Artificial Intelligence, Intermediate (200)
Các công ty game đang đối mặt với một thách thức chưa từng có trong việc quản lý tài sản sáng tạo quảng cáo của họ. Các công ty game hiện đại sản xuất hàng nghìn quảng cáo video cho các chiến dịch thử nghiệm A/B, với một số tổ chức duy trì thư viện với hơn 100.000 tài sản video và con số này tăng thêm hàng nghìn mỗi tháng. Những tài sản này rất quan trọng cho các chiến dịch thu hút người dùng, nơi việc tìm kiếm tài sản sáng tạo phù hợp có thể tạo ra sự khác biệt giữa một lần ra mắt thành công và một thất bại tốn kém.
Trong bài đăng này, chúng tôi mô tả cách bạn có thể sử dụng Amazon Nova Multimodal Embeddings để truy xuất các phân đoạn video cụ thể. Chúng tôi cũng xem xét một trường hợp sử dụng thực tế trong đó Nova Multimodal Embeddings đạt tỷ lệ thành công truy xuất 96,7% và tỷ lệ truy xuất độ chính xác cao 73,3% (trả về nội dung mục tiêu trong hai kết quả hàng đầu) khi được thử nghiệm với thư viện gồm 170 tài sản sáng tạo game. Mô hình cũng thể hiện khả năng đa ngôn ngữ mạnh mẽ với sự suy giảm hiệu suất tối thiểu trên nhiều ngôn ngữ.
Các phương pháp truyền thống để sắp xếp, lưu trữ và tìm kiếm tài sản sáng tạo không thể đáp ứng nhu cầu năng động của các nhóm sáng tạo. Theo truyền thống, các tài sản sáng tạo đã được gắn thẻ thủ công để cho phép tìm kiếm dựa trên từ khóa và sau đó được tổ chức trong các hệ thống phân cấp thư mục, được tìm kiếm thủ công để tìm các tài sản mong muốn. Các hệ thống tìm kiếm dựa trên từ khóa yêu cầu gắn thẻ thủ công vừa tốn công sức vừa không nhất quán. Mặc dù các giải pháp mô hình ngôn ngữ lớn (LLM) như gắn thẻ tự động dựa trên LLM cung cấp khả năng hiểu đa phương thức mạnh mẽ, nhưng chúng không thể mở rộng để đáp ứng nhu cầu của các nhóm sáng tạo để thực hiện các tìm kiếm đa dạng, thời gian thực trên các thư viện tài sản khổng lồ.
Thách thức cốt lõi nằm ở tìm kiếm ngữ nghĩa cho việc khám phá tài sản sáng tạo. Việc tìm kiếm cần hỗ trợ các yêu cầu tìm kiếm không thể đoán trước mà không thể được tổ chức trước bằng các lời nhắc cố định hoặc các thẻ được xác định trước. Khi các chuyên gia sáng tạo tìm kiếm `the character is pinched away by hand`, hoặc `A finger taps a card in the game`, hệ thống phải hiểu không chỉ các từ khóa mà còn cả ý nghĩa ngữ nghĩa trên các loại phương tiện khác nhau.
Đây là nơi Nova Multimodal Embeddings thay đổi cục diện. Nova Multimodal Embeddings là một mô hình embedding đa phương thức tiên tiến cho các ứng dụng Retrieval-Augmented Generation (RAG) và tìm kiếm ngữ nghĩa với kiến trúc không gian vector hợp nhất, có sẵn trong Amazon Bedrock. Quan trọng hơn, mô hình tạo ra các embedding trực tiếp từ tài sản video mà không yêu cầu các bước chuyển đổi trung gian hoặc gắn thẻ thủ công.
Việc tạo embedding video của Nova Multimodal Embeddings cho phép hiểu ngữ nghĩa thực sự của nội dung video. Nova Multimodal Embeddings có thể phân tích các cảnh quay, hành động, đối tượng và ngữ cảnh trong video để tạo ra các biểu diễn ngữ nghĩa phong phú. Khi bạn tìm kiếm `the character is pinched away by hand`, mô hình hiểu hành động cụ thể, các yếu tố hình ảnh và ngữ cảnh được mô tả—không chỉ khớp từ khóa. Khả năng ngữ nghĩa này tránh được những hạn chế cơ bản của các hệ thống tìm kiếm dựa trên từ khóa, để các nhóm sáng tạo có thể tìm thấy nội dung video liên quan bằng cách sử dụng các mô tả ngôn ngữ tự nhiên mà không thể gắn thẻ hoặc tổ chức trước bằng các phương pháp truyền thống.
Tổng quan giải pháp
Trong phần này, bạn sẽ tìm hiểu về Nova Multimodal Embeddings và các khả năng, lợi thế chính của nó, cũng như tích hợp với các dịch vụ AWS để tạo ra một kiến trúc tìm kiếm đa phương thức toàn diện. Kiến trúc tìm kiếm đa phương thức được mô tả trong bài đăng này cung cấp:
- Tính linh hoạt đầu vào: Chấp nhận các truy vấn văn bản, hình ảnh được tải lên, video và tệp âm thanh làm đầu vào tìm kiếm
- Truy xuất đa phương thức: Người dùng có thể tìm thấy nội dung video, hình ảnh và âm thanh bằng cách sử dụng mô tả văn bản hoặc sử dụng hình ảnh được tải lên để khám phá nội dung hình ảnh tương tự trên nhiều loại phương tiện
- Độ chính xác đầu ra: Trả về các kết quả được xếp hạng với điểm tương đồng, dấu thời gian chính xác cho các phân đoạn video và siêu dữ liệu chi tiết
- Tìm kiếm và truy xuất đồng bộ: Cung cấp kết quả tìm kiếm ngay lập tức thông qua các embedding được tính toán trước và khớp tương đồng vector hiệu quả
- Kiến trúc bất đồng bộ hợp nhất: Các truy vấn tìm kiếm được xử lý bất đồng bộ để xử lý thời gian xử lý khác nhau và cung cấp trải nghiệm người dùng nhất quán
Amazon Nova Multimodal Embeddings
Nova Multimodal Embeddings là mô hình embedding hợp nhất đầu tiên hỗ trợ văn bản, tài liệu, hình ảnh, video và âm thanh thông qua một mô hình duy nhất để cho phép truy xuất đa phương thức với độ chính xác hàng đầu trong ngành. Nó cung cấp các khả năng và lợi thế chính sau:
- Kiến trúc không gian vector hợp nhất: Không giống như các hệ thống dựa trên thẻ truyền thống hoặc các pipeline chuyển đổi đa phương thức sang văn bản yêu cầu ánh xạ phức tạp giữa các không gian vector khác nhau, Nova Multimodal Embeddings tạo ra các embedding tồn tại trong cùng một không gian ngữ nghĩa bất kể phương thức đầu vào. Điều này có nghĩa là mô tả văn bản về
`racing car`sẽ gần về mặt không gian với hình ảnh và video chứa xe đua, cho phép tìm kiếm đa phương thức trực quan. - Kích thước embedding linh hoạt: Nova Multimodal Embeddings cung cấp bốn tùy chọn kích thước embedding (256, 384, 1024 và 3072), được đào tạo bằng Matryoshka Representation Learning (MRL), cho phép truy xuất độ trễ thấp với mất mát độ chính xác tối thiểu trên các kích thước khác nhau. Tùy chọn 1024 chiều cung cấp sự cân bằng tối ưu cho hầu hết các ứng dụng doanh nghiệp, trong khi 3072 chiều cung cấp độ chính xác tối đa cho các trường hợp sử dụng quan trọng.
- API đồng bộ và bất đồng bộ: Mô hình hỗ trợ cả tạo embedding thời gian thực cho nội dung nhỏ hơn và xử lý bất đồng bộ cho các tệp lớn với phân đoạn tự động. Tính linh hoạt này cho phép các hệ thống xử lý mọi thứ từ truy xuất truy vấn văn bản nhanh chóng đến lập chỉ mục hàng giờ nội dung video.
- Hiểu video nâng cao: Đối với nội dung video, Nova Multimodal Embeddings cung cấp khả năng phân đoạn tinh vi, chia các video dài thành các phân đoạn có ý nghĩa (1–30 giây) và tạo embedding cho mỗi phân đoạn. Đối với quản lý tài sản sáng tạo quảng cáo, cách tiếp cận phân đoạn này hoàn toàn phù hợp với các quy trình sản xuất điển hình, nơi các nhóm sáng tạo cần quản lý và truy xuất các phân đoạn video cụ thể thay vì toàn bộ video.
Tích hợp với các dịch vụ AWS
Nova Multimodal Embeddings tích hợp liền mạch với các dịch vụ AWS khác để tạo ra một kiến trúc tìm kiếm đa phương thức sẵn sàng sản xuất:
- Amazon Bedrock: Cung cấp quyền truy cập mô hình nền tảng với bảo mật và khả năng mở rộng cấp doanh nghiệp
- Amazon OpenSearch Service: Đóng vai trò là cơ sở dữ liệu vector để lưu trữ và tìm kiếm các embedding với thời gian phản hồi truy vấn ở mức mili giây
- AWS Lambda: Xử lý không máy chủ cho việc tạo embedding và các hoạt động tìm kiếm
- Amazon Simple Storage Service (Amazon S3): Lưu trữ các tệp phương tiện gốc và kết quả xử lý với khả năng mở rộng không giới hạn
- Amazon API Gateway: Cung cấp các API RESTful để tích hợp frontend
Triển khai kỹ thuật
Kiến trúc hệ thống
Hệ thống hoạt động thông qua hai luồng công việc chính: nhập nội dung và truy xuất tìm kiếm, được hiển thị trong sơ đồ kiến trúc sau và được mô tả trong các phần sau.
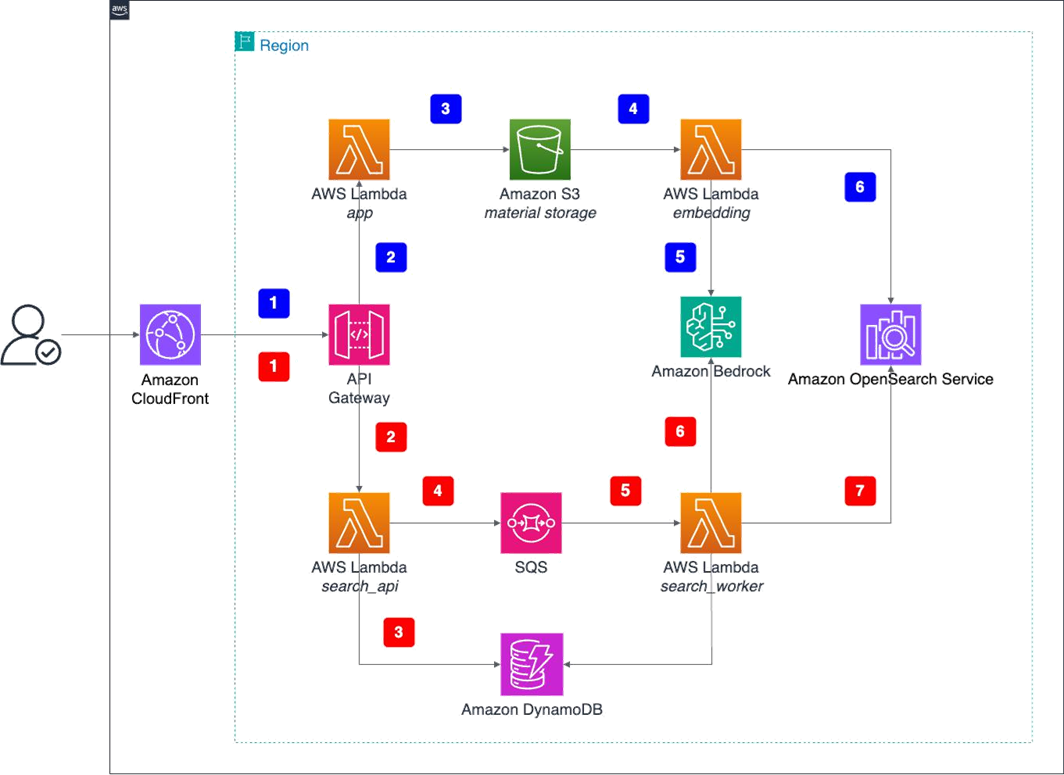
Luồng thực thi hệ thống
Luồng công việc nhập nội dung chuyển đổi các tệp phương tiện thô thành các embedding vector có thể tìm kiếm thông qua một loạt các bước tự động. Quá trình này bắt đầu khi người dùng tải lên nội dung và kết thúc bằng việc lưu trữ các embedding trong cơ sở dữ liệu vector, làm cho nội dung có thể được khám phá thông qua tìm kiếm ngữ nghĩa.
- Tương tác người dùng: Người dùng truy cập giao diện web thông qua Amazon CloudFront, tải lên các tệp phương tiện (hình ảnh, video và âm thanh) bằng cách kéo và thả hoặc chọn tệp.
- Xử lý API: Các tệp được chuyển đổi sang định dạng base64 và gửi qua API Gateway đến hàm Lambda chính để xác thực loại tệp và giới hạn kích thước (kích thước tệp tối đa là 10 MB).
- Lưu trữ Amazon S3: Lambda giải mã dữ liệu base64 và tải các tệp thô lên Amazon S3 để lưu trữ liên tục.
- Kích hoạt sự kiện Amazon S3: Amazon S3 tự động kích hoạt một hàm Lambda embedding chuyên dụng khi các tệp mới được tải lên, bắt đầu quá trình tạo embedding.
- Gọi Amazon Bedrock: Hàm Lambda embedding gọi bất đồng bộ mô hình Amazon Bedrock Nova Multimodal Embeddings để tạo các vector embedding hợp nhất cho nhiều loại phương tiện.
- Lưu trữ vector: Hàm Lambda embedding lưu trữ các vector embedding được tạo cùng với siêu dữ liệu trong OpenSearch Service, tạo ra một cơ sở dữ liệu vector có thể tìm kiếm.
Luồng công việc tìm kiếm và truy xuất
Thông qua luồng công việc tìm kiếm và truy xuất, người dùng có thể tìm thấy nội dung liên quan bằng cách sử dụng các truy vấn đa phương thức. Quá trình này chuyển đổi các truy vấn của người dùng thành các embedding và thực hiện tìm kiếm tương đồng đối với cơ sở dữ liệu vector được xây dựng trước, trả về các kết quả được xếp hạng dựa trên sự tương đồng ngữ nghĩa trên các loại phương tiện khác nhau.
- Yêu cầu tìm kiếm: Người dùng bắt đầu tìm kiếm thông qua giao diện web bằng cách sử dụng các tệp được tải lên hoặc truy vấn văn bản, với các tùy chọn để chọn các chế độ tìm kiếm khác nhau (hình ảnh, ngữ nghĩa hoặc âm thanh).
- Xử lý API: Các yêu cầu tìm kiếm được gửi qua API Gateway đến hàm Lambda API tìm kiếm để xử lý ban đầu.
- Tạo tác vụ: Hàm Lambda API tìm kiếm tạo các bản ghi tác vụ tìm kiếm trong Amazon DynamoDB và gửi tin nhắn đến hàng đợi Amazon Simple Queue Service (Amazon SQS) để xử lý bất đồng bộ.
- Xử lý hàng đợi: Hàm Lambda API tìm kiếm gửi tin nhắn đến hàng đợi Amazon SQS để xử lý bất đồng bộ. Kiến trúc bất đồng bộ hợp nhất này xử lý các yêu cầu API của Nova Multimodal Embeddings (gọi bất đồng bộ để phân đoạn video), ngăn chặn thời gian chờ của API Gateway và giúp đảm bảo xử lý có thể mở rộng cho nhiều loại truy vấn.
- Kích hoạt worker: Hàm Lambda worker tìm kiếm được kích hoạt bởi các tin nhắn Amazon SQS, trích xuất các tham số tìm kiếm và chuẩn bị cho việc tạo embedding.
- Embedding truy vấn: Hàm Lambda worker gọi mô hình Amazon Bedrock Nova Multimodal Embeddings để tạo các vector embedding cho các truy vấn tìm kiếm (văn bản hoặc tệp được tải lên).
- Tìm kiếm vector: Hàm Lambda worker thực hiện tìm kiếm tương đồng bằng cách sử dụng độ tương đồng cosine trong OpenSearch Service, sau đó cập nhật kết quả trong DynamoDB để frontend thăm dò.
Tích hợp luồng công việc
Hai luồng công việc được mô tả trong phần trước chia sẻ các thành phần cơ sở hạ tầng chung nhưng phục vụ các mục đích khác nhau:
- Luồng công việc tải lên (1–6): Tập trung vào việc nhập và xử lý các tệp phương tiện để xây dựng cơ sở dữ liệu vector có thể tìm kiếm
- Luồng công việc tìm kiếm (A–G): Xử lý các truy vấn của người dùng và truy xuất các kết quả liên quan từ cơ sở dữ liệu vector được xây dựng trước
- Các thành phần được chia sẻ: Cả hai luồng công việc đều sử dụng cùng một mô hình Amazon Bedrock, các chỉ mục OpenSearch Service và các dịch vụ AWS cốt lõi
Các tính năng kỹ thuật chính
- Không gian vector hợp nhất: Tất cả các loại phương tiện (hình ảnh, video, âm thanh và văn bản) được nhúng vào cùng một không gian chiều, cho phép tìm kiếm đa phương thức thực sự.
- Xử lý bất đồng bộ: Kiến trúc bất đồng bộ hợp nhất xử lý các yêu cầu API của Amazon Nova Multimodal Embedding và giúp đảm bảo xử lý có thể mở rộng thông qua hàng đợi Amazon SQS và các hàm Lambda worker.
- Tìm kiếm đa phương thức: Hỗ trợ tìm kiếm tương đồng văn bản sang hình ảnh, văn bản sang video, văn bản sang âm thanh và tệp sang tệp.
- Kiến trúc có thể mở rộng: Thiết kế không máy chủ tự động mở rộng dựa trên nhu cầu.
- Theo dõi trạng thái: Cơ chế thăm dò cung cấp các cập nhật về trạng thái xử lý bất đồng bộ và kết quả tìm kiếm.
Tạo embedding cốt lõi bằng Amazon Nova Multimodal Embeddings
request_body = {
"schemaVersion": "amazon.nova-embedding-v1:0",
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": self.dimension,
"video": {
"format": self._get_video_format(s3_uri),
"source": {
"s3Location": {
"uri": s3_uri
}
},
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"segmentationConfig": {
"durationSeconds": 5 # Default 5 second segmentation
}
}
}
}
output_config = {
"s3OutputDataConfig": {
"s3Uri": output_s3_uri
}
}
print(f"Nova async embedding request: {json.dumps(request_body, indent=2)}")
# Start an asynchronous call
response = self.bedrock_client.start_async_invoke(
modelId=self.model_id,
modelInput=request_body,
outputDataConfig=output_config
)
invocation_arn = response['invocationArn']
print(f"Started Nova async embedding job: {invocation_arn}")Triển khai tìm kiếm đa phương thức
Cốt lõi của hệ thống nằm ở khả năng tìm kiếm đa phương thức thông minh bằng cách sử dụng tìm kiếm k-nearest neighbor (KNN) của OpenSearch, như được hiển thị trong đoạn mã sau:
def search_similar(self, query_vector: List[float], embedding_field: str, top_k: int = 20, filters: Dict[str, Any] = None) -> List[Dict[str, Any]]: """Search for similar vectors using OpenSearch KNN""" query = { "size": top_k, "query": { "knn": { embedding_field: { "vector": query_vector, "k": top_k } } }, "_source": [ "s3_uri", "file_type", "timestamp", "media_type", "segment_index", "start_time", "end_time", "duration" ] } # Add filters for media type or other criteria if filters: query["query"] = { "bool": { "must": [query["query"]], "filter": [{"terms": {k: v}} for k, v in filters.items()] } } response = self.client.search(index=self.index, body=query) # Process and return results with metadata results = [] for hit in response['hits']['hits']: source = hit['_source'] results.append({ 'score': hit['_score'], 's3_uri': source['s3_uri'], 'file_type': source['file_type'], 'media_type': source.get('media_type', 'unknown'), 'segment_info': { 'segment_index': source.get('segment_index'), 'start_time': source.get('start_time'), 'end_time': source.get('end_time') } }) return results
Lưu trữ và truy xuất vector
Hệ thống sử dụng OpenSearch Service làm cơ sở dữ liệu vector, tối ưu hóa việc lập chỉ mục cho các loại embedding khác nhau, như được hiển thị trong đoạn mã sau:
def create_index_if_not_exists(self): """Create OpenSearch index with optimized schema""" if not self.client.indices.exists(self.index): index_body = { 'settings': { 'index': { 'knn': True, "mapping.total_fields.limit": 5000 } }, 'mappings': { 'properties': { # Vector fields for different modalities with HNSW configuration 'visual_embedding': { 'type': 'knn_vector', 'dimension': VECTOR_DIMENSION, 'method': { 'name': 'hnsw', 'space_type': 'cosinesimil', 'engine': 'faiss' } }, 'text_embedding': { 'type': 'knn_vector', 'dimension': VECTOR_DIMENSION, 'method': { 'name': 'hnsw', 'space_type': 'cosinesimil', 'engine': 'faiss' } }, 'audio_embedding': { 'type': 'knn_vector', 'dimension': VECTOR_DIMENSION, 'method': { 'name': 'hnsw', 'space_type': 'cosinesimil', 'engine': 'faiss' } }, # Metadata fields 's3_uri': {'type': 'keyword'}, 'media_type': {'type': 'keyword'}, 'file_type': {'type': 'keyword'}, 'timestamp': {'type': 'date'}, 'segment_index': {'type': 'integer'}, 'start_time': {'type': 'float'}, 'end_time': {'type': 'float'}, 'duration': {'type': 'float'}, # Amazon Nova Multimodal Embeddings support audio_video_combined fields 'audio_video_combined_embedding': { 'type': 'knn_vector', 'dimension': VECTOR_DIMENSION, 'method': { 'name': 'hnsw', 'space_type': 'cosinesimil', 'engine': 'faiss' } }, # model fields 'model_type': {'type': 'keyword'}, 'model_version': {'type': 'keyword'}, 'vector_dimension': {'type': 'integer'}, # document fields 'document_type': {'type': 'keyword'}, 'source_file': {'type': 'keyword'}, 'page_number': {'type': 'integer'}, 'total_pages': {'type': 'integer'} } } } self.client.indices.create(self.index, body=index_body) print(f"Created index: {self.index}")
Lược đồ này hỗ trợ nhiều phương thức (hình ảnh, văn bản và âm thanh) với tính năng lập chỉ mục KNN được bật, cho phép tìm kiếm đa phương thức linh hoạt trong khi vẫn giữ lại siêu dữ liệu chi tiết về các phân đoạn video và nguồn gốc mô hình.
Ứng dụng thực tế và hiệu suất
Sử dụng một trường hợp sử dụng trong ngành game, hãy xem xét một kịch bản mà một chuyên gia sáng tạo cần tìm các phân đoạn video hiển thị `characters celebrating victory with bright visual effects` cho một chiến dịch mới.
Các phương pháp truyền thống sẽ yêu cầu:
- Gắn thẻ thủ công hàng nghìn video, tốn nhiều công sức và có thể không nhất quán
- Tìm kiếm dựa trên từ khóa bỏ lỡ các sắc thái ngữ nghĩa
- Phân tích dựa trên LLM quá chậm và tốn kém cho các truy vấn thời gian thực
Với Nova Multimodal Embeddings, cùng một truy vấn trở thành một tìm kiếm văn bản đơn giản mà:
- Tạo ra một embedding ngữ nghĩa của truy vấn
- Tìm kiếm trên tất cả các phân đoạn video trong không gian vector hợp nhất
- Trả về các kết quả được xếp hạng dựa trên sự tương đồng ngữ nghĩa
- Cung cấp dấu thời gian chính xác cho các phân đoạn video liên quan
Các chỉ số hiệu suất và xác thực
Dựa trên thử nghiệm toàn diện với các đối tác trong ngành game sử dụng thư viện gồm 170 tài sản (130 video và 40 hình ảnh), Nova Multimodal Embeddings đã thể hiện hiệu suất vượt trội trên 30 trường hợp thử nghiệm:
- Tỷ lệ thành công truy xuất: 96,7% các trường hợp thử nghiệm đã truy xuất thành công nội dung mục tiêu
- Truy xuất độ chính xác cao: 73,3% các trường hợp thử nghiệm đã trả về nội dung mục tiêu trong hai kết quả hàng đầu
- Độ chính xác đa phương thức: Độ chính xác vượt trội trong truy xuất văn bản sang video so với các phương pháp truyền thống
Các phát hiện chính
Dưới đây là những gì chúng tôi đã học được từ kết quả thử nghiệm của mình:
- Chiến lược phân đoạn: Đối với các luồng công việc sáng tạo quảng cáo, chúng tôi khuyên bạn nên sử dụng
SEGMENTED_EMBEDDINGvới các phân đoạn video 5 giây vì nó phù hợp với các yêu cầu sản xuất điển hình. Các nhóm sáng tạo thường cần phân đoạn tài liệu quảng cáo gốc để quản lý và truy xuất các clip cụ thể trong các luồng công việc sản xuất, làm cho chức năng phân đoạn của Nova Multimodal Embeddings đặc biệt có giá trị cho các trường hợp sử dụng này. - Khung đánh giá: Để đánh giá hiệu quả của Nova Multimodal Embeddings cho trường hợp sử dụng của bạn, hãy tập trung vào việc kiểm tra các khả năng cốt lõi sau:
- Phát hiện đối tượng và thực thể: Kiểm tra các truy vấn như
`red sports car`hoặc`character with sword`để đánh giá nhận dạng đối tượng trên các phương thức - Hiểu cảnh và ngữ cảnh: Đánh giá các tìm kiếm theo ngữ cảnh như
`outdoor celebration scene`hoặc`indoor meeting environment` - Hoạt động và hành động: Xác thực các truy vấn dựa trên hành động như
`running character`hoặc`clicking interface elements` - Thuộc tính hình ảnh: Kiểm tra các tìm kiếm cụ thể theo thuộc tính bao gồm màu sắc, kiểu dáng và đặc điểm hình ảnh
- Ngữ nghĩa trừu tượng: Đánh giá hiểu biết khái niệm với các truy vấn như
`victory celebration`hoặc`tense atmosphere`
- Phát hiện đối tượng và thực thể: Kiểm tra các truy vấn như
- Phương pháp thử nghiệm: Xây dựng một tập dữ liệu thử nghiệm đại diện từ thư viện nội dung của bạn, tạo các loại truy vấn đa dạng phù hợp với nhu cầu thực tế của người dùng và đo lường cả tỷ lệ thành công truy xuất (tìm thấy nội dung liên quan) và độ chính xác (chất lượng xếp hạng). Tập trung vào các truy vấn phản ánh các mẫu tìm kiếm thực tế của nhóm bạn thay vì các trường hợp thử nghiệm chung chung.
- Hiệu suất đa ngôn ngữ: Nova Multimodal Embeddings thể hiện khả năng đa ngôn ngữ mạnh mẽ, đặc biệt xuất sắc trong các truy vấn tiếng Trung với điểm số 78,2 so với các truy vấn tiếng Anh ở mức 89,3 (3072 chiều). Điều này thể hiện khoảng cách ngôn ngữ chỉ 11,1, tốt hơn đáng kể so với một mô hình đa phương thức hàng đầu khác cho thấy sự suy giảm hiệu suất đáng kể trên các ngôn ngữ khác nhau.
Khả năng mở rộng và lợi ích chi phí
Kiến trúc không máy chủ cung cấp khả năng tự động mở rộng trong khi tối ưu hóa chi phí. Hãy ghi nhớ các chi tiết hiệu suất kích thước và chiến lược tối ưu hóa chi phí sau khi thiết kế hệ thống khám phá tài sản đa phương thức của bạn.
Hiệu suất kích thước:
- 3072 chiều: Độ chính xác cao nhất (89,3 cho tiếng Anh và 78,2 cho tiếng Trung) và chi phí lưu trữ cao hơn
- 1024 chiều: Hiệu suất cân bằng (85,7 cho tiếng Anh và 68,3 cho tiếng Trung); được khuyến nghị cho hầu hết các trường hợp sử dụng
- 384/256 chiều: Các tùy chọn tối ưu hóa chi phí cho các triển khai quy mô lớn
Chiến lược tối ưu hóa chi phí:
- Chọn kích thước dựa trên yêu cầu độ chính xác so với chi phí lưu trữ
- Sử dụng xử lý bất đồng bộ cho các tệp lớn để tránh chi phí thời gian chờ
- Sử dụng các embedding được tính toán trước để giảm chi phí suy luận LLM định kỳ
- Sử dụng kiến trúc không máy chủ với giá theo yêu cầu trả tiền theo mức sử dụng để giảm chi phí trong thời gian sử dụng thấp
Bắt đầu
Phần này cung cấp các yêu cầu và bước thiết yếu để triển khai và chạy hệ thống tìm kiếm đa phương thức Nova Multimodal Embeddings.
- Một tài khoản AWS có quyền truy cập Amazon Bedrock và khả năng sử dụng mô hình Nova Multimodal Embeddings
- AWS Command Line Interface (AWS CLI) v2 được cấu hình với các quyền thích hợp để tạo tài nguyên
- Node.js 18+ và AWS CDK v2 đã được cài đặt
- Python 3.11 để triển khai cơ sở hạ tầng
- Git để clone kho lưu trữ demo
Triển khai nhanh
Hệ thống hoàn chỉnh có thể được triển khai bằng cách sử dụng các tập lệnh tự động hóa sau:
# Clone the demonstration repositorygit clone https://github.com/aws-samples/sample-multimodal-embedding-modelscd sample-multimodal-embedding-models# Configure service prefix (optional)# Edit config/settings.py to customize SERVICE_PREFIX# Deploy Amazon Nova Multimodal Embeddings system./deploy_model.sh nova-segmented
Tập lệnh triển khai tự động:
- Cài đặt các phụ thuộc cần thiết
- Cung cấp tài nguyên AWS (Lambda, OpenSearch, Amazon S3 và API Gateway)
- Xây dựng và triển khai giao diện frontend
- Cấu hình các điểm cuối API và phân phối CloudFront
Truy cập hệ thống
Sau khi triển khai thành công, hệ thống cung cấp các giao diện web để thử nghiệm:
- Giao diện tải lên: Để thêm các tệp phương tiện vào hệ thống
- Giao diện tìm kiếm: Để thực hiện các truy vấn đa phương thức
- Giao diện quản lý: Để giám sát trạng thái xử lý
Hỗ trợ đầu vào đa phương thức (tùy chọn)
Phần tùy chọn này cho phép hệ thống chấp nhận đầu vào hình ảnh và video ngoài các truy vấn văn bản để có khả năng tìm kiếm đa phương thức toàn diện.
def search_by_image(self, image_s3_uri: str) -> Dict: """Find similar content using image as query""" query_embedding = self.nova_service.get_image_embedding(image_s3_uri) # Search across all media types using visual similarity return self.opensearch_manager.search_similar( query_embedding=query_embedding, embedding_field='visual_embedding', size=10 )
Dọn dẹp
Để tránh các khoản phí liên tục, hãy sử dụng lệnh sau để xóa các tài nguyên AWS đã tạo trong quá trình triển khai:
# Remove all system resources./destroy_model.sh nova-segmented
Kết luận
Amazon Nova Multimodal Embeddings đại diện cho một sự thay đổi cơ bản trong cách các tổ chức có thể quản lý và khám phá nội dung đa phương thức ở quy mô lớn. Bằng cách cung cấp một không gian vector hợp nhất tích hợp liền mạch văn bản, hình ảnh và nội dung video, Nova Multimodal Embeddings loại bỏ các rào cản truyền thống đã hạn chế khả năng tìm kiếm đa phương thức. Mã nguồn hoàn chỉnh và các tập lệnh triển khai có sẵn trong kho lưu trữ demo.
Về tác giả

Jia Li là Kiến trúc sư Giải pháp Công nghiệp tại Amazon Web Services, tập trung vào việc thúc đẩy đổi mới kỹ thuật và tăng trưởng kinh doanh trong ngành game. Với 20 năm kinh nghiệm phát triển game full-stack, trước đây đã làm việc tại các công ty như Lianzhong, Renren và Hungry Studio, giữ vai trò nhà sản xuất game và giám đốc trung tâm R&D quy mô lớn. Sở hữu cái nhìn sâu sắc về động lực ngành và mô hình kinh doanh.

Xiaowei Zhu là Nhà xây dựng Giải pháp Công nghiệp tại Amazon Web Services (AWS). Với hơn 10 năm kinh nghiệm phát triển ứng dụng di động, anh cũng có chuyên môn sâu về tìm kiếm embedding, kiểm thử tự động và Vibe Coding. Hiện tại, anh chịu trách nhiệm xây dựng Tài sản ngành Game của AWS và dẫn đầu việc phát triển ứng dụng mã nguồn mở SwiftChat.

Hanyi Zhang là Kiến trúc sư Giải pháp tại AWS, tập trung vào thiết kế kiến trúc đám mây cho ngành game. Với kinh nghiệm sâu rộng về phân tích dữ liệu lớn, AI tạo sinh và khả năng quan sát đám mây, Hanyi đã triển khai thành công nhiều dự án quy mô lớn với các dịch vụ AWS tiên tiến.

Zepei Yu là Kiến trúc sư Giải pháp tại AWS, chịu trách nhiệm tư vấn và thiết kế các giải pháp điện toán đám mây, và có kinh nghiệm sâu rộng về AI/ML, DevOps, Ngành Game, v.v.

Bao Cao là Kiến trúc sư Giải pháp AWS, chịu trách nhiệm thiết kế kiến trúc dựa trên các giải pháp điện toán đám mây của AWS, giúp khách hàng xây dựng các ứng dụng sáng tạo hơn bằng cách sử dụng các công nghệ dịch vụ đám mây hàng đầu. Trước khi gia nhập AWS, đã làm việc tại các công ty như ByteDance, với hơn 10 năm kinh nghiệm sâu rộng trong phát triển game và thiết kế kiến trúc.

Xi Wan là Kiến trúc sư Giải pháp tại Amazon Web Services, chịu trách nhiệm tư vấn và thiết kế các giải pháp điện toán đám mây dựa trên AWS. Một người ủng hộ mạnh mẽ văn hóa AWS Builder. Với hơn 12 năm kinh nghiệm phát triển game, đã tham gia quản lý và phát triển nhiều dự án game và sở hữu sự hiểu biết sâu sắc về ngành game.
