Tác giả: Gautam Bhaghavatula, Sucharitha Boinapally, Veera Bhargav Nunna, and Radhakant Sahu
Ngày phát hành: 15 JAN 2026
Chuyên mục: Advanced (300), Amazon Athena, Amazon EMR, Amazon Managed Streaming for Apache Kafka (Amazon MSK), Technical How-to
Trong bài viết này, chúng tôi sẽ chỉ cho bạn cách triển khai thu nạp dữ liệu thời gian thực từ nhiều topic Kafka vào các bảng Apache Hudi bằng cách sử dụng Amazon EMR. Giải pháp này tối ưu hóa quá trình thu nạp dữ liệu bằng cách xử lý song song nhiều topic Amazon Managed Streaming for Apache Kafka (Amazon MSK) đồng thời cung cấp chất lượng dữ liệu và khả năng mở rộng thông qua ghi nhận thay đổi dữ liệu (CDC) và Apache Hudi.
Các tổ chức xử lý thay đổi dữ liệu thời gian thực trên nhiều nguồn thường gặp khó khăn trong việc duy trì tính nhất quán của dữ liệu và quản lý chi phí tài nguyên. Xử lý hàng loạt truyền thống yêu cầu xử lý lại toàn bộ tập dữ liệu, dẫn đến việc sử dụng tài nguyên cao và phân tích bị trì hoãn. Bằng cách triển khai CDC với MultiTable DeltaStreamer của Apache Hudi, bạn có thể đạt được các bản cập nhật thời gian thực; xử lý tăng dần hiệu quả với đảm bảo tính nguyên tử, nhất quán, cô lập, bền vững (ACID); và tiến hóa lược đồ liền mạch trong khi giảm thiểu chi phí lưu trữ và tính toán.
Sử dụng Amazon Simple Storage Service (Amazon S3), Amazon CloudWatch, Amazon EMR, Amazon MSK và AWS Glue Data Catalog, bạn sẽ xây dựng một đường ống dữ liệu sẵn sàng cho sản xuất để xử lý các thay đổi từ nhiều nguồn dữ liệu đồng thời. Thông qua hướng dẫn này, bạn sẽ học cách cấu hình các đường ống CDC, quản lý cấu hình dành riêng cho bảng, triển khai khoảng thời gian đồng bộ 15 phút và duy trì đường ống streaming của mình. Kết quả là một hệ thống mạnh mẽ duy trì tính nhất quán của dữ liệu đồng thời cho phép phân tích thời gian thực và sử dụng tài nguyên hiệu quả.
CDC là gì?
Hãy tưởng tượng một luồng dữ liệu liên tục phát triển, một dòng thông tin nơi các bản cập nhật chảy liên tục. CDC hoạt động như một lưới tinh vi, chỉ ghi nhận các sửa đổi—thêm mới, cập nhật và xóa—xảy ra trong luồng dữ liệu đó. Thông qua phương pháp tiếp cận có mục tiêu này, bạn có thể tập trung vào dữ liệu mới và đã thay đổi, cải thiện đáng kể hiệu quả của các đường ống dữ liệu của mình. Có nhiều lợi thế khi áp dụng CDC:
- Giảm thời gian xử lý – Tại sao phải xử lý lại toàn bộ tập dữ liệu khi bạn chỉ có thể tập trung vào các bản cập nhật? CDC giảm thiểu chi phí xử lý, tiết kiệm thời gian và tài nguyên quý giá.
- Thông tin chi tiết thời gian thực – Với CDC, các đường ống dữ liệu của bạn trở nên phản hồi nhanh hơn. Bạn có thể phản ứng với các thay đổi gần như ngay lập tức, cho phép phân tích và ra quyết định thời gian thực.
- Đường ống dữ liệu đơn giản hóa – Xử lý hàng loạt truyền thống có thể dẫn đến các đường ống phức tạp. CDC tối ưu hóa quy trình, làm cho các đường ống dữ liệu dễ quản lý và bảo trì hơn.
Tại sao lại là Apache Hudi?
Hudi đơn giản hóa việc xử lý dữ liệu tăng dần và phát triển đường ống dữ liệu. Framework này quản lý hiệu quả các yêu cầu kinh doanh như vòng đời dữ liệu và cải thiện chất lượng dữ liệu. Bạn có thể sử dụng Hudi để quản lý dữ liệu ở cấp độ bản ghi trong các hồ dữ liệu Amazon S3 để đơn giản hóa CDC và thu nạp dữ liệu streaming, đồng thời xử lý các trường hợp sử dụng quyền riêng tư dữ liệu yêu cầu cập nhật và xóa ở cấp độ bản ghi. Các tập dữ liệu được quản lý bởi Hudi được lưu trữ trong Amazon S3 bằng các định dạng lưu trữ mở, trong khi tích hợp với Presto, Apache Hive, Apache Spark và Data Catalog cung cấp cho bạn quyền truy cập gần thời gian thực vào dữ liệu đã cập nhật. Apache Hudi tạo điều kiện thuận lợi cho việc xử lý dữ liệu tăng dần cho Amazon S3 bằng cách:
- Quản lý thay đổi cấp độ bản ghi – Lý tưởng cho các trường hợp sử dụng cập nhật và xóa
- Định dạng mở – Tích hợp với Presto, Hive, Spark và Data Catalog
- Tiến hóa lược đồ – Hỗ trợ thay đổi lược đồ động
- HoodieMultiTableDeltaStreamer – Đơn giản hóa việc thu nạp vào nhiều bảng bằng cách sử dụng cấu hình tập trung
Hudi MultiTable Delta Streamer
HoodieMultiTableStreamer cung cấp một phương pháp tiếp cận hợp lý để thu nạp dữ liệu từ nhiều nguồn vào các bảng Hudi. Bằng cách xử lý nhiều nguồn đồng thời thông qua một công việc DeltaStreamer duy nhất, nó loại bỏ nhu cầu về các đường ống riêng biệt trong khi giảm độ phức tạp vận hành. Framework cung cấp các tùy chọn cấu hình linh hoạt và bạn có thể điều chỉnh cài đặt cho các định dạng và lược đồ đa dạng trên các nguồn dữ liệu khác nhau.
Một trong những điểm mạnh chính của nó nằm ở việc phân phối dữ liệu thống nhất, tổ chức thông tin trong các bảng Hudi tương ứng để truy cập liền mạch. Khả năng upsert thông minh của hệ thống xử lý hiệu quả cả thêm mới và cập nhật, duy trì tính nhất quán của dữ liệu trên đường ống của bạn. Ngoài ra, hỗ trợ tiến hóa lược đồ mạnh mẽ của nó cho phép đường ống dữ liệu của bạn thích ứng với các yêu cầu kinh doanh thay đổi mà không bị gián đoạn, làm cho nó trở thành một giải pháp lý tưởng cho các môi trường dữ liệu động.
Tổng quan giải pháp
Trong phần này, chúng tôi sẽ chỉ cho bạn cách truyền dữ liệu đến Bảng Apache Hudi bằng Amazon MSK. Đối với kịch bản ví dụ này, có các luồng dữ liệu từ ba nguồn riêng biệt nằm trong các topic Kafka riêng biệt. Chúng tôi đặt mục tiêu triển khai một đường ống streaming sử dụng Hudi DeltaStreamer với hỗ trợ đa bảng để thu nạp và xử lý dữ liệu này theo khoảng thời gian 15 phút.
Cơ chế
Sử dụng MSK Connect, dữ liệu từ nhiều nguồn chảy vào các topic MSK. Các topic này sau đó được thu nạp vào các bảng Hudi bằng Hudi MultiTable DeltaStreamer. Trong triển khai mẫu này, chúng tôi tạo ba topic Amazon MSK và cấu hình đường ống để xử lý dữ liệu ở định dạng JSON bằng JsonKafkaSource, với sự linh hoạt để xử lý định dạng Avro khi cần thông qua cấu hình bộ giải tuần tự thích hợp.
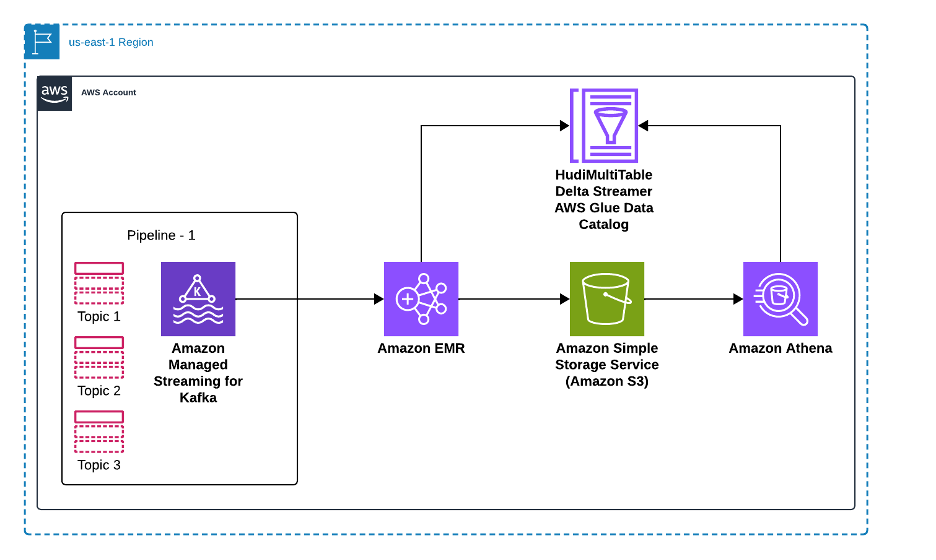
Sơ đồ sau minh họa cách giải pháp của chúng tôi xử lý dữ liệu từ nhiều cơ sở dữ liệu nguồn thông qua Amazon MSK và Apache Hudi để cho phép phân tích trong Amazon Athena. Các cơ sở dữ liệu nguồn gửi các thay đổi dữ liệu của chúng—bao gồm thêm mới, cập nhật và xóa—đến các topic chuyên dụng trong Amazon MSK, nơi mỗi nguồn dữ liệu duy trì topic Kafka riêng cho các sự kiện thay đổi. Một cụm Amazon EMR chạy Apache Hudi MultiTable DeltaStreamer, xử lý song song nhiều topic Kafka này, chuyển đổi dữ liệu và ghi vào các bảng Apache Hudi được lưu trữ trong Amazon S3. Data Catalog duy trì siêu dữ liệu cho các bảng này, cho phép tích hợp liền mạch với các công cụ phân tích. Cuối cùng, Amazon Athena cung cấp khả năng truy vấn SQL trên các bảng Hudi, cho phép các nhà phân tích chạy cả truy vấn snapshot và tăng dần trên dữ liệu mới nhất. Kiến trúc này mở rộng theo chiều ngang khi các nguồn dữ liệu mới được thêm vào, với mỗi nguồn nhận topic Kafka chuyên dụng và cấu hình bảng Hudi, đồng thời duy trì tính nhất quán dữ liệu và đảm bảo ACID trên toàn bộ đường ống.
Để thiết lập giải pháp, bạn cần hoàn thành các bước cấp cao sau:
- Thiết lập Amazon MSK và tạo các topic Kafka
- Tạo các topic Kafka
- Tạo cấu hình dành riêng cho bảng
- Khởi chạy cụm Amazon EMR
- Gọi Hudi MultiTable DeltaStreamer
- Xác minh và truy vấn dữ liệu
Điều kiện tiên quyết
Để thực hiện giải pháp, bạn cần có các điều kiện tiên quyết sau. Đối với các dịch vụ và quyền của AWS, bạn cần:
- Tài khoản AWS:
- Amazon MSK. Tham khảo Bắt đầu với Amazon MSK.
- Amazon EMR (phiên bản 6.15.0 trở lên được khuyến nghị).
- Amazon S3.
- Data Catalog.
- Các vai trò và chính sách IAM.
- Các vai trò IAM:
- Vai trò dịch vụ Amazon EMR (EMR_DefaultRole) với các quyền cho Amazon S3, AWS Glue và CloudWatch.
- Hồ sơ phiên bản Amazon EC2 (EMR_EC2_DefaultRole) với quyền đọc/ghi S3.
- Vai trò truy cập Amazon MSK với các quyền thích hợp.
- Các bucket S3:
- Bucket cấu hình để lưu trữ các tệp thuộc tính và lược đồ.
- Bucket đầu ra cho các bảng Hudi.
- Bucket ghi nhật ký (tùy chọn nhưng được khuyến nghị).
- Cấu hình mạng:
- Amazon Virtual Private Cloud (Amazon VPC) với các subnet thích hợp.
- Nhóm bảo mật cho phép lưu lượng truy cập giữa Amazon EMR và Amazon MSK.
- NAT gateway hoặc VPC endpoints để truy cập Amazon S3.
- Công cụ phát triển:
- AWS CLI đã cấu hình.
- Truy cập vào bảng điều khiển Amazon EMR hoặc AWS CLI.
- Công cụ client Kafka để kiểm tra.
Thiết lập Amazon MSK và tạo các topic Kafka
Trong bước này, bạn sẽ tạo một cụm MSK và cấu hình các topic Kafka cần thiết cho các luồng dữ liệu của mình.
- Để tạo một cụm MSK:
aws kafka create-cluster \ --cluster-name hudi-msk-cluster \ --broker-node-group-info file://broker-nodes.json \ --kafka-version "2.8.1" \ --number-of-broker-nodes 3 \ --encryption-info file://encryption-info.json \ --client-authentication file://client-authentication.json
- Xác minh trạng thái cụm:
aws kafka describe-cluster --cluster-arn $CLUSTER_ARN | jq '.ClusterInfo.State'
Lệnh sẽ trả về ACTIVE khi cụm sẵn sàng.
Thiết lập lược đồ
Để thiết lập lược đồ, hãy hoàn thành các bước sau:
- Tạo các tệp lược đồ của bạn.
a.input_schema.avsc:
{ "type": "record", "name": "CustomerSales", "fields": [ {"name": "Id", "type": "string"}, {"name": "ts", "type": "long"}, {"name": "amount", "type": "double"}, {"name": "customer_id", "type": "string"}, {"name": "transaction_date", "type": "string"} ]}
b. `output_schema.avsc`:
{ "type": "record", "name": "CustomerSalesProcessed", "fields": [ {"name": "Id", "type": "string"}, {"name": "ts", "type": "long"}, {"name": "amount", "type": "double"}, {"name": "customer_id", "type": "string"}, {"name": "transaction_date", "type": "string"}, {"name": "processing_timestamp", "type": "string"} ]}
- Tạo và tải lược đồ lên bucket S3 của bạn:
# Create the schema directoryaws s3 mb s3://hudi-config-bucket-$AWS_ACCOUNT_IDaws s3api put-object --bucket hudi-config-bucket-$AWS_ACCOUNT_ID --key HudiProperties/# Upload schema filesaws s3 cp input_schema.avsc s3://hudi-config-bucket-$AWS_ACCOUNT_ID/HudiProperties/aws s3 cp output_schema.avsc s3://hudi-config-bucket-$AWS_ACCOUNT_ID/HudiProperties/
Tạo các topic Kafka
Để tạo các topic Kafka, hãy hoàn thành các bước sau:
- Lấy chuỗi bootstrap broker:
# Get bootstrap brokersBOOTSTRAP_BROKERS=$(aws kafka get-bootstrap-brokers --cluster-arn $CLUSTER_ARN --query 'BootstrapBrokerString' --output text)
- Tạo các topic cần thiết:
kafka-topics.sh --create \ --bootstrap-server $BOOTSTRAP_BROKERS \ --replication-factor 3 \ --partitions 3 \ --topic cust_sales_detailskafka-topics.sh --create \ --bootstrap-server $BOOTSTRAP_BROKERS \ --replication-factor 3 \ --partitions 3 \ --topic cust_sales_appointmentkafka-topics.sh --create \ --bootstrap-server $BOOTSTRAP_BROKERS \ --replication-factor 3 \ --partitions 3 \ --topic cust_info
Cấu hình Apache Hudi
Cấu hình Hudi MultiTable DeltaStreamer được chia thành hai thành phần chính để hợp lý hóa và chuẩn hóa việc thu nạp dữ liệu:
- Cấu hình chung – Các cài đặt này áp dụng cho tất cả các bảng và định nghĩa các thuộc tính chung cho việc thu nạp. Chúng bao gồm các chi tiết như song song hóa shuffle, Kafka brokers và cấu hình thu nạp chung cho tất cả các topic.
- Cấu hình dành riêng cho bảng – Mỗi bảng có các yêu cầu riêng, chẳng hạn như khóa bản ghi, đường dẫn tệp lược đồ và tên topic. Các cấu hình này điều chỉnh quy trình thu nạp của mỗi bảng theo lược đồ và cấu trúc dữ liệu của nó.
Tạo tệp cấu hình chung
Cấu hình chung: tệp cấu hình kafka-hudi nơi chúng tôi chỉ định kafka broker và cấu hình chung cho tất cả các topic như sau
Tạo tệp kafka-hudi-deltastreamer.properties với các thuộc tính sau:
# Common parallelism settingshoodie.upsert.shuffle.parallelism=2hoodie.insert.shuffle.parallelism=2hoodie.delete.shuffle.parallelism=2hoodie.bulkinsert.shuffle.parallelism=2# Table ingestion configurationhoodie.deltastreamer.ingestion.tablesToBeIngested=hudi_sales_tables.cust_sales_details,hudi_sales_tables.cust_sales_appointment,hudi_sales_tables.cust_info# Table-specific config fileshoodie.deltastreamer.ingestion.hudi_sales_tables.cust_sales_details.configFile=s3://hudi-config-bucket-$AWS_ACCOUNT_ID/HudiProperties/tableProperties/cust_sales_details.propertieshoodie.deltastreamer.ingestion.hudi_sales_tables.cust_sales_appointment.configFile=s3://hudi-config-bucket-$AWS_ACCOUNT_ID/HudiProperties/tableProperties/cust_sales_appointment.propertieshoodie.deltastreamer.ingestion.hudi_sales_tables.cust_info.configFile=s3://hudi-config-bucket-$AWS_ACCOUNT_ID/HudiProperties/tableProperties/cust_info.properties# Source configurationhoodie.deltastreamer.source.dfs.root=s3://hudi-config-bucket-$AWS_ACCOUNT_ID/HudiProperties/# MSK configurationbootstrap.servers=BOOTSTRAP_BROKERS_PLACEHOLDERauto.offset.reset=earliestgroup.id=hudi_delta_streamer# Security configurationhoodie.sensitive.config.keys=ssl,tls,sasl,auth,credentialssasl.mechanism=PLAINsecurity.protocol=SASL_SSLssl.endpoint.identification.algorithm=# Deserializerhoodie.deltastreamer.source.kafka.value.deserializer.class=io.confluent.kafka.serializers.KafkaAvroDeserializer
Tạo cấu hình dành riêng cho bảng
Đối với mỗi topic, hãy tạo cấu hình riêng với tên topic và chi tiết khóa chính. Hoàn thành các bước sau:
cust_sales_details.properties:
# Table: cust saleshoodie.datasource.write.recordkey.field=Idhoodie.deltastreamer.source.kafka.topic=cust_sales_detailshoodie.deltastreamer.keygen.timebased.timestamp.type=UNIX_TIMESTAMPhoodie.deltastreamer.keygen.timebased.input.dateformat=yyyy-MM-dd HH:mm:ss.Shoodie.streamer.schemaprovider.registry.schemaconverter=hoodie.datasource.write.precombine.field=ts
cust_sales_appointment.properties:
# Table: cust sales appointmenthoodie.datasource.write.recordkey.field=Idhoodie.deltastreamer.source.kafka.topic=cust_sales_appointmenthoodie.deltastreamer.keygen.timebased.timestamp.type=UNIX_TIMESTAMPhoodie.deltastreamer.keygen.timebased.input.dateformat=yyyy-MM-dd HH:mm:ss.S hoodie.streamer.schemaprovider.registry.schemaconverter=hoodie.datasource.write.precombine.field=ts
cust_info.properties:
# Table: cust infohoodie.datasource.write.recordkey.field=Idhoodie.deltastreamer.source.kafka.topic=cust_infohoodie.deltastreamer.keygen.timebased.timestamp.type=UNIX_TIMESTAMPhoodie.deltastreamer.keygen.timebased.input.dateformat= yyyy-MM-dd HH:mm:ss.Shoodie.streamer.schemaprovider.registry.schemaconverter=hoodie.datasource.write.precombine.field=tshoodie.deltastreamer.schemaprovider.source.schema.file=-$AWS_ACCOUNT_ID/HudiProperties/input_schema.avschoodie.deltastreamer.schemaprovider.target.schema.file=-$AWS_ACCOUNT_ID/HudiProperties/output_schema.avsc
Các cấu hình này tạo thành xương sống của đường ống thu nạp của Hudi, cho phép xử lý dữ liệu hiệu quả và duy trì tính nhất quán thời gian thực. Cấu hình lược đồ định nghĩa cấu trúc của cả dữ liệu nguồn và đích, duy trì chuyển đổi và thu nạp dữ liệu liền mạch. Cài đặt vận hành kiểm soát cách dữ liệu được nhận dạng duy nhất, cập nhật và xử lý tăng dần.
Sau đây là các chi tiết quan trọng để thiết lập đường ống thu nạp Hudi:
hoodie.deltastreamer.schemaprovider.source.schema.file– Lược đồ của bản ghi nguồnhoodie.deltastreamer.schemaprovider.target.schema.file– Lược đồ cho bản ghi đíchhoodie.deltastreamer.source.kafka.topic– Tên topic MSK nguồnbootstap.servers– Điểm cuối riêng tư của máy chủ bootstrap Amazon MSKauto.offset.reset– Hành vi của consumer khi không có vị trí đã commit hoặc khi một offset nằm ngoài phạm vi
Các trường vận hành chính để đạt được cập nhật tại chỗ cho lược đồ được tạo bao gồm:
hoodie.datasource.write.recordkey.field– Trường khóa bản ghi. Đây là định danh duy nhất của một bản ghi trong Hudi.hoodie.datasource.write.precombine.field– Khi hai bản ghi có cùng giá trị khóa bản ghi, Apache Hudi chọn bản ghi có giá trị lớn nhất cho trường pre-combined.hoodie.datasource.write.operation– Thao tác trên tập dữ liệu Hudi. Các giá trị có thể bao gồmUPSERT,INSERTvàBULK_INSERT.
Khởi chạy cụm Amazon EMR
Bước này tạo một cụm EMR với Apache Hudi đã được cài đặt. Cụm sẽ chạy MultiTable DeltaStreamer để xử lý dữ liệu từ các topic Kafka của bạn. Để tạo cụm EMR, hãy nhập như sau:
# Create EMR cluster with Hudi installedaws emr create-cluster \ --name "Hudi-CDC-Cluster" \ --release-label emr-6.15.0 \ --applications Name=Hadoop Name=Spark Name=Hive Name=Livy \ --ec2-attributes KeyName=myKey,SubnetId=$SUBNET_ID,InstanceProfile=EMR_EC2_InstanceProfile \ --service-role EMR_ServiceRole \ --instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=m5.xlarge InstanceGroupType=CORE,InstanceCount=2,InstanceType=m5.xlarge \ --configurations file://emr-configurations.json \ --bootstrap-actions Name="Install Hudi",Path="s3://hudi-config-bucket-$AWS_ACCOUNT_ID/bootstrap-hudi.sh"
Gọi Hudi MultiTable DeltaStreamer
Bước này cấu hình và khởi động công việc DeltaStreamer sẽ liên tục xử lý dữ liệu từ các topic Kafka của bạn vào các bảng Hudi. Hoàn thành các bước sau:
- Kết nối với nút master Amazon EMR:
# Get master node public DNSMASTER_DNS=$(aws emr describe-cluster --cluster-id $CLUSTER_ID --query 'Cluster.MasterPublicDnsName' --output text)# SSH to master nodessh -i myKey.pem hadoop@$MASTER_DNS
- Thực thi công việc DeltaStreamer:
# spark-submit --deploy-mode client \ --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \ --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog" \ --conf "spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension" \ --jars "/usr/lib/hudi/hudi-utilities-bundle_2.12-0.14.0-amzn-0.jar,/usr/lib/hudi/hudi-spark-bundle.jar" \ --class "org.apache.hudi.utilities.deltastreamer.HoodieMultiTableDeltaStreamer" \ /usr/lib/hudi/hudi-utilities-bundle_2.12-0.14.0-amzn-0.jar \ --props s3://hudi-config-bucket-$AWS_ACCOUNT_ID/HudiProperties/kafka-hudi-deltastreamer.properties \ --config-folder s3://hudi-config-bucket-$AWS_ACCOUNT_ID/HudiProperties/tableProperties/ \ --table-type MERGE_ON_READ \ --base-path-prefix s3://hudi-data-bucket-$AWS_ACCOUNT_ID/hudi/ \ --source-class org.apache.hudi.utilities.sources.JsonKafkaSource \ --schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \ --op UPSERT
Để ở chế độ liên tục, bạn cần thêm thuộc tính sau:
--continuous \--min-sync-interval-seconds 900
Với công việc đã được cấu hình và chạy trên Amazon EMR, Hudi MultiTable DeltaStreamer quản lý hiệu quả việc thu nạp dữ liệu thời gian thực vào hồ dữ liệu Amazon S3 của bạn.
Xác minh và truy vấn dữ liệu
Để xác minh và truy vấn dữ liệu, hãy hoàn thành các bước sau:
- Đăng ký bảng trong Data Catalog:
# Start Spark shellspark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \ --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog" \ --conf "spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension" \ --jars "/usr/lib/hudi/hudi-spark-bundle.jar"# In Spark shellspark.sql("CREATE DATABASE IF NOT EXISTS hudi_sales_tables")spark.sql("""CREATE TABLE hudi_sales_tables.cust_sales_detailsUSING hudiLOCATION 's3://hudi-data-bucket-$AWS_ACCOUNT_ID/hudi/hudi_sales_tables.cust_sales_details'""")# Repeat for other tables
- Truy vấn bằng Athena:
-- Sample querySELECT * FROM hudi_sales_tables.cust_sales_details LIMIT 10;
Bạn có thể sử dụng báo động Amazon CloudWatch để cảnh báo bạn về các vấn đề với công việc EMR hoặc xử lý dữ liệu. Để tạo báo động CloudWatch để giám sát lỗi công việc EMR, hãy nhập như sau:
aws cloudwatch put-metric-alarm \ --alarm-name EMR-Hudi-Job-Failure \ --metric-name JobsFailed \ --namespace AWS/ElasticMapReduce \ --statistic Sum \ --period 300 \ --threshold 1 \ --comparison-operator GreaterThanOrEqualToThreshold \ --dimensions Name=JobFlowId,Value=$CLUSTER_ID \ --evaluation-periods 1 \ --alarm-actions $SNS_TOPIC_ARN
Tác động thực tế của các đường ống Hudi CDC
Với đường ống đã được cấu hình và chạy, bạn có thể đạt được các bản cập nhật thời gian thực cho hồ dữ liệu của mình, cho phép phân tích và ra quyết định nhanh hơn. Ví dụ:
- Phân tích – Dữ liệu tồn kho cập nhật duy trì các bảng điều khiển chính xác cho các nền tảng thương mại điện tử.
- Giám sát – Số liệu CloudWatch xác nhận tình trạng và hiệu quả của đường ống.
- Tính linh hoạt – Việc xử lý tiến hóa lược đồ liền mạch giảm thiểu thời gian ngừng hoạt động và sự không nhất quán dữ liệu.
Dọn dẹp
Để tránh phát sinh chi phí trong tương lai, hãy làm theo các bước sau để dọn dẹp tài nguyên:
Kết luận
Trong bài viết này, chúng tôi đã chỉ ra cách bạn có thể xây dựng một đường ống thu nạp dữ liệu có khả năng mở rộng bằng cách sử dụng MultiTable DeltaStreamer của Apache Hudi trên Amazon EMR để xử lý dữ liệu từ nhiều topic Amazon MSK. Bạn đã học cách cấu hình CDC với Apache Hudi, thiết lập xử lý dữ liệu thời gian thực với khoảng thời gian đồng bộ 15 phút và duy trì tính nhất quán dữ liệu trên nhiều nguồn trong hồ dữ liệu Amazon S3 của bạn.
Để tìm hiểu thêm, hãy khám phá các tài nguyên này:
- Tài liệu Apache Hudi
- Amazon EMR với Apache Hudi
- Hướng dẫn dành cho nhà phát triển Amazon MSK
- Tích hợp AWS Glue Data Catalog
Bằng cách kết hợp CDC với Apache Hudi, bạn có thể xây dựng các đường ống dữ liệu thời gian thực hiệu quả. Các quy trình thu nạp hợp lý hóa đơn giản hóa việc quản lý, nâng cao khả năng mở rộng và duy trì chất lượng dữ liệu, biến phương pháp này thành nền tảng của kiến trúc dữ liệu hiện đại.
Về tác giả

Radhakant Sahu
Radhakant là Kỹ sư dữ liệu cấp cao và chuyên gia về Amazon EMR tại Amazon Web Services (AWS) với hơn một thập kỷ kinh nghiệm trong lĩnh vực dữ liệu. Anh chuyên về dữ liệu lớn, cơ sở dữ liệu đồ thị, AI và DevOps, xây dựng các giải pháp phân tích và dữ liệu mạnh mẽ, có khả năng mở rộng giúp khách hàng toàn cầu thu thập thông tin chi tiết có thể hành động và thúc đẩy kết quả kinh doanh.

Gautam Bhaghavatula
Gautam là Kiến trúc sư giải pháp đối tác cấp cao của AWS với hơn 10 năm kinh nghiệm trong kiến trúc hạ tầng đám mây. Anh chuyên thiết kế các giải pháp có khả năng mở rộng, tập trung vào hệ thống tính toán, mạng, microservices, DevOps, quản trị đám mây và hoạt động AI. Gautam cung cấp hướng dẫn chiến lược và lãnh đạo kỹ thuật cho các đối tác AWS, thúc đẩy các sáng kiến di chuyển và hiện đại hóa đám mây thành công.

Sucharitha Boinapally
Sucharitha là Giám đốc Kỹ thuật Dữ liệu với hơn 15 năm kinh nghiệm trong ngành. Cô chuyên về AI tác nhân, kỹ thuật dữ liệu và biểu đồ tri thức, cung cấp các giải pháp kiến trúc dữ liệu tinh vi. Sucharitha xuất sắc trong việc thiết kế và triển khai các hệ thống ánh xạ tri thức tiên tiến.

Veera “Bhargav” Nunna
Veera là Kỹ sư dữ liệu cấp cao và Trưởng nhóm kỹ thuật tại AWS, tiên phong trong lĩnh vực Biểu đồ tri thức cho các Mô hình ngôn ngữ lớn và các giải pháp dữ liệu quy mô doanh nghiệp. Với hơn một thập kỷ kinh nghiệm, anh chuyên biến AI doanh nghiệp từ ý tưởng thành sản phẩm bằng cách cung cấp các MVP chứng minh ROI rõ ràng đồng thời giải quyết các thách thức thực tế như tối ưu hóa hiệu suất và kiểm soát chi phí.
