Tác giả: Efe Karakus
Ngày phát hành: 15 JAN 2026
Chuyên mục: Artificial Intelligence, DevOps, Generative AI, Technical How-to
Tại re:Invent 2025, Matt Garman đã công bố AWS DevOps Agent, một tác nhân tiên phong giúp giải quyết và chủ động ngăn chặn sự cố, liên tục cải thiện độ tin cậy và hiệu suất. Là một thành viên của nhóm DevOps Agent, chúng tôi đã tập trung rất nhiều vào việc đảm bảo khả năng “phản hồi sự cố” của DevOps Agent tạo ra các phát hiện và quan sát hữu ích. Đặc biệt, chúng tôi đã và đang nỗ lực để phân tích nguyên nhân gốc rễ cho các ứng dụng AWS gốc trở nên chính xác và hiệu quả. Về cơ bản, DevOps Agent có kiến trúc đa tác nhân, trong đó một tác nhân chính đóng vai trò chỉ huy sự cố: nó hiểu triệu chứng, tạo kế hoạch điều tra và ủy quyền các tác vụ riêng lẻ cho các tác nhân phụ chuyên biệt khi các tác vụ đó được hưởng lợi từ việc nén ngữ cảnh. Một tác nhân phụ thực hiện tác vụ của mình với một cửa sổ ngữ cảnh nguyên bản và báo cáo kết quả đã nén trở lại tác nhân chính. Ví dụ, khi kiểm tra các bản ghi nhật ký có khối lượng lớn, một tác nhân phụ sẽ lọc bỏ nhiễu để chỉ đưa ra các thông báo liên quan cho tác nhân chính.
Trong bài đăng này, chúng tôi muốn tập trung vào các cơ chế cần thiết để phát triển một sản phẩm tác nhân hoạt động hiệu quả. Xây dựng một nguyên mẫu với các mô hình ngôn ngữ lớn (LLMs) có rào cản gia nhập thấp – bạn có thể trình bày một thứ gì đó hoạt động khá nhanh chóng. Tuy nhiên, biến nguyên mẫu đó thành một sản phẩm hoạt động đáng tin cậy trên nhiều môi trường khách hàng đa dạng là một thách thức hoàn toàn khác, và thường bị đánh giá thấp. Bài đăng này chia sẻ những gì chúng tôi đã học được khi xây dựng AWS DevOps Agent để bạn có thể áp dụng những bài học này vào quá trình phát triển tác nhân của riêng mình.
Theo kinh nghiệm của chúng tôi, có năm cơ chế cần thiết để liên tục cải thiện chất lượng tác nhân và thu hẹp khoảng cách từ nguyên mẫu đến sản xuất. Thứ nhất, bạn cần đánh giá (evals) để xác định nơi tác nhân của bạn thất bại và nơi nó có thể cải thiện, đồng thời thiết lập một tiêu chuẩn chất lượng cho các loại kịch bản mà tác nhân của bạn xử lý tốt. Thứ hai, bạn cần một công cụ trực quan hóa để gỡ lỗi quỹ đạo của tác nhân và hiểu chính xác tác nhân đã sai ở đâu. Thứ ba, bạn cần một vòng lặp phản hồi nhanh với khả năng chạy lại các kịch bản thất bại đó cục bộ để lặp lại. Thứ tư, bạn cần thực hiện những thay đổi có chủ đích: thiết lập tiêu chí thành công trước khi sửa đổi hệ thống của mình để tránh sai lệch xác nhận. Cuối cùng, bạn cần đọc các mẫu sản phẩm thực tế thường xuyên để hiểu trải nghiệm khách hàng thực tế và khám phá các kịch bản mới mà evals của bạn chưa bao gồm.
Đánh giá (Evals)
Evals là tương đương với bộ kiểm thử trong kỹ thuật phần mềm truyền thống. Giống như việc xây dựng bất kỳ sản phẩm phần mềm nào khác, một bộ các trường hợp kiểm thử tốt sẽ xây dựng niềm tin vào chất lượng. Lặp lại chất lượng tác nhân tương tự như phát triển dựa trên kiểm thử (TDD): bạn có một kịch bản eval mà tác nhân thất bại (kiểm thử màu đỏ), bạn thực hiện các thay đổi cho đến khi tác nhân vượt qua (kiểm thử màu xanh). Một eval vượt qua có nghĩa là tác nhân đã đưa ra một đầu ra chính xác, hữu ích thông qua lý luận đúng đắn.
Đối với AWS DevOps Agent, kích thước của một kịch bản eval riêng lẻ tương tự như một kiểm thử end-to-end trong kim tự tháp kiểm thử kỹ thuật phần mềm truyền thống. Nhìn qua lăng kính của các kiểm thử kiểu “Given-When-Then”:
- Given – Phần thiết lập kiểm thử có xu hướng tốn thời gian nhất để viết. Đối với AWS DevOps Agent, một kịch bản eval ví dụ bao gồm một ứng dụng chạy trên Amazon Elastic Kubernetes Service bao gồm nhiều microservice được đặt phía trước bởi Application Load Balancers, đọc và ghi từ các kho dữ liệu như cơ sở dữ liệu Amazon Relational Database Service và các bucket Amazon Simple Storage Service, với các hàm AWS Lambda thực hiện chuyển đổi dữ liệu. Chúng tôi đưa vào một lỗi bằng cách triển khai một thay đổi mã vô tình loại bỏ một quyền AWS Identity and Access Management (IAM) quan trọng để ghi vào S3 sâu trong chuỗi phụ thuộc.
- When – Khi lỗi được đưa vào, một cảnh báo sẽ kích hoạt, và điều này kích hoạt AWS DevOps Agent bắt đầu điều tra. Khung eval thăm dò các bản ghi mà Agent tạo ra, giống như cách ứng dụng web DevOps Agent hiển thị chúng. Phần này không khác biệt cơ bản so với việc định nghĩa hành động trong một kiểm thử tích hợp hoặc end-to-end.
- Then – Phần này khẳng định và báo cáo về nhiều số liệu. Về cơ bản, có một số liệu “PASS” (1) hoặc “FAIL” (0) duy nhất cho chất lượng. Đối với khả năng phản hồi sự cố của DevOps Agent, “PASS” có nghĩa là nguyên nhân gốc rễ đúng đã được đưa ra cho khách hàng – trong ví dụ của chúng tôi, điều này có nghĩa là xác định việc triển khai lỗi là nguyên nhân gốc rễ và theo dõi chuỗi phụ thuộc để đưa ra các tài nguyên bị ảnh hưởng và các quan sát tiết lộ quyền ghi S3 bị thiếu; nếu không thì “FAIL”. Chúng tôi định nghĩa đây là một rubric: không chỉ “tác nhân có tìm thấy nguyên nhân gốc rễ không?” mà còn “tác nhân có tìm thấy nguyên nhân gốc rễ thông qua lý luận đúng đắn với bằng chứng hỗ trợ phù hợp không?” Sự thật cơ bản (cái “mong đợi” hoặc “mong muốn” trong thuật ngữ kiểm thử phần mềm) được so sánh với phản hồi của hệ thống (cái “thực tế”) thông qua một LLM Judge – một LLM nhận cả sự thật cơ bản và đầu ra thực tế của tác nhân, sau đó đưa ra lý luận và phán quyết về việc chúng có khớp nhau không. Chúng tôi sử dụng một LLM để so sánh vì đầu ra của tác nhân là không xác định: tác nhân tuân theo một định dạng đầu ra tổng thể nhưng tạo ra văn bản thực tế một cách tự do, vì vậy mỗi lần chạy có thể sử dụng các từ hoặc cấu trúc câu khác nhau trong khi truyền tải cùng một ý nghĩa ngữ nghĩa. Chúng tôi không muốn tìm kiếm nghiêm ngặt các từ khóa trong báo cáo phân tích nguyên nhân gốc rễ cuối cùng mà thay vào đó đánh giá xem bản chất của rubric có được đáp ứng hay không.
Báo cáo đánh giá được cấu trúc với các kịch bản là hàng và các số liệu là cột. Các số liệu chính mà chúng tôi theo dõi là khả năng (pass@k – liệu tác nhân có vượt qua ít nhất một lần trong k lần thử), độ tin cậy (pass^k – số lần tác nhân vượt qua trong k lần thử, ví dụ, 0.33 có nghĩa là vượt qua 1 trong 3 lần đối với k=3), độ trễ và mức sử dụng token.

Tại sao Evals lại quan trọng?
Có một số lợi ích khi có evals:
- Các kịch bản màu đỏ cung cấp các điểm điều tra rõ ràng cho nhóm phát triển tác nhân để tăng chất lượng sản phẩm.
- Theo thời gian, các kịch bản màu xanh đóng vai trò là kiểm thử hồi quy, thông báo cho chúng tôi khi các thay đổi đối với hệ thống làm giảm trải nghiệm khách hàng hiện có.
- Khi tỷ lệ vượt qua là màu xanh, chúng tôi có thể cải thiện trải nghiệm khách hàng theo các số liệu bổ sung. Ví dụ, giảm độ trễ end-to-end và/hoặc tối ưu hóa chi phí (được đại diện bởi mức sử dụng token) trong khi vẫn duy trì tiêu chuẩn chất lượng.
Điều gì khiến Evals trở nên thách thức?
Vòng lặp phản hồi nhanh giúp các nhà phát triển biết liệu mã có hoạt động không (có đúng, hiệu quả, an toàn không) và liệu các ý tưởng có tốt không (có cải thiện các chỉ số kinh doanh chính không). Điều này có vẻ hiển nhiên, nhưng quá thường xuyên, các nhóm và tổ chức chấp nhận các vòng lặp phản hồi chậm […] — Nicole Forsgren và Abi Noda, Frictionless: 7 Steps to Remove Barriers, Unlock Value, and Outpace Your Competition in the AI Era
Có một số thách thức với evals. Theo thứ tự giảm dần độ khó:
- Các kịch bản thực tế và đa dạng rất khó để viết. Việc đưa ra các ứng dụng và kịch bản lỗi thực tế là khó khăn. Việc viết các ứng dụng microservice và lỗi có độ trung thực cao là một công việc đáng kể đòi hỏi kinh nghiệm trong ngành trước đó. Những gì chúng tôi thấy hiệu quả: chúng tôi viết một vài “môi trường” (dựa trên kiến trúc ứng dụng thực tế) nhưng tạo nhiều kịch bản lỗi trên đó. Môi trường là phần tốn kém của thiết lập đánh giá, vì vậy chúng tôi tối đa hóa việc tái sử dụng trên nhiều kịch bản.
- Vòng lặp phản hồi chậm. Nếu phần “Given” mất 20 phút để triển khai cho một kịch bản eval và sau đó phần “When” mất thêm 10-20 phút để hoàn thành các cuộc điều tra phức tạp, các nhà phát triển tác nhân sẽ không kiểm thử kỹ lưỡng các thay đổi của họ. Thay vào đó, họ sẽ hài lòng với một eval vượt qua duy nhất, sau đó phát hành ra sản phẩm, có khả năng gây ra các hồi quy cho đến khi báo cáo eval toàn diện được tạo ra. Ngoài ra, các vòng lặp phản hồi chậm khuyến khích việc gộp nhiều thay đổi lại với nhau thay vì các thử nghiệm gia tăng nhỏ, khiến việc hiểu thay đổi nào thực sự tạo ra sự khác biệt trở nên khó khăn hơn. Chúng tôi đã tìm thấy ba cơ chế hiệu quả để tăng tốc vòng lặp phản hồi:
- Môi trường chạy dài cho các kịch bản eval. Ứng dụng và trạng thái lành mạnh của nó được tạo một lần và giữ cho chạy. Việc đưa lỗi xảy ra định kỳ (ví dụ, vào cuối tuần), và các nhà phát triển trỏ thông tin xác thực tác nhân của họ vào môi trường lỗi, hoàn toàn bỏ qua phần “Given” của kiểm thử.
- Kiểm thử cô lập chỉ phần diện tích bề mặt tác nhân quan trọng. Trong hệ thống đa tác nhân của chúng tôi, các nhà phát triển có thể kích hoạt trực tiếp một tác nhân phụ cụ thể bằng một lời nhắc từ một lần chạy eval trước đó thay vì chạy toàn bộ luồng end-to-end. Ngoài ra, chúng tôi đã xây dựng một tính năng “fork”: các nhà phát triển có thể khởi tạo bất kỳ tác nhân nào với lịch sử cuộc trò chuyện từ một lần chạy thất bại cho đến một thông báo điểm kiểm tra cụ thể, sau đó chỉ lặp lại trên quỹ đạo còn lại. Cả hai phương pháp này đều giảm đáng kể thời gian chờ của phần “When”.
- Phát triển cục bộ của hệ thống tác nhân. Nếu các nhà phát triển phải hợp nhất các thay đổi và phát hành ra môi trường đám mây trước khi kiểm thử, vòng lặp quá chậm. Chạy cục bộ cho phép lặp lại nhanh chóng.
Trực quan hóa quỹ đạo
Khi một tác nhân thất bại trong một eval hoặc một lần chạy sản phẩm, bạn bắt đầu điều tra từ đâu? Phương pháp hiệu quả nhất là phân tích lỗi. Trực quan hóa quỹ đạo hoàn chỉnh của tác nhân, mọi trao đổi tin nhắn người dùng-trợ lý bao gồm quỹ đạo của tác nhân phụ, và chú thích từng bước là “PASS” hoặc “FAIL” với các ghi chú về những gì đã sai. Quá trình này tẻ nhạt nhưng hiệu quả.
Đối với AWS DevOps Agent, quỹ đạo tác nhân ánh xạ tới các trace OpenTelemetry và bạn có thể sử dụng các công cụ như Jaeger để trực quan hóa chúng. Các bộ công cụ phát triển phần mềm như Strands cung cấp tích hợp tracing với thiết lập tối thiểu.
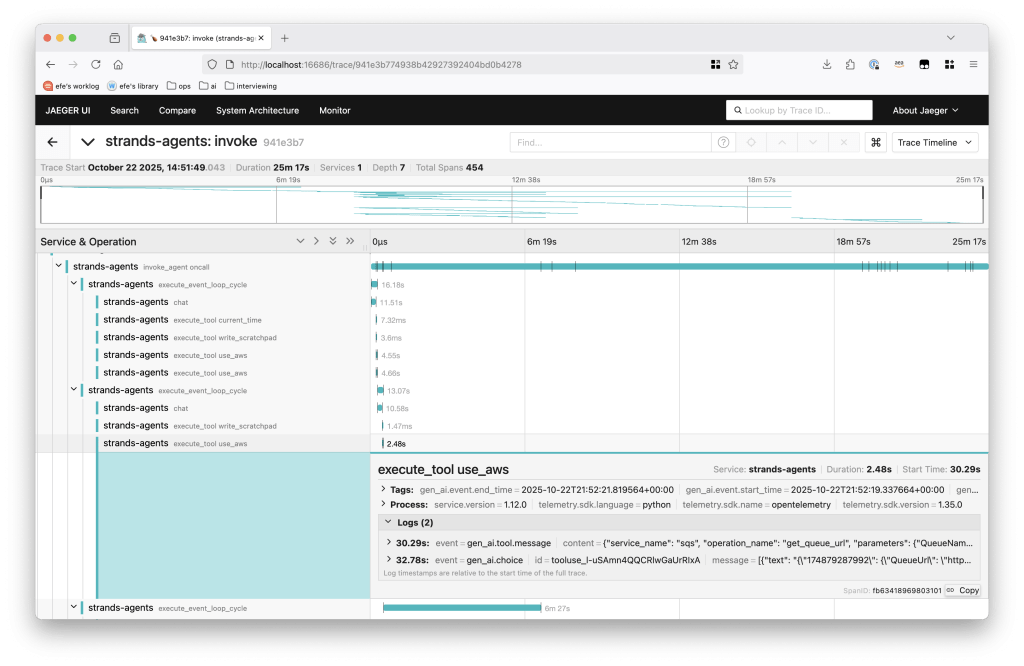
Hình 1 – Một trace mẫu từ AWS DevOps Agent.
Mỗi span chứa các cặp tin nhắn người dùng-trợ lý. Chúng tôi chú thích chất lượng của mỗi span trong một bảng như sau:

Phân tích cấp thấp này liên tục đưa ra nhiều cải tiến, không chỉ một. Đối với một eval thất bại duy nhất, người ta thường xác định nhiều thay đổi cụ thể bao gồm độ chính xác, hiệu suất và chi phí.
Thay đổi có chủ đích
Tôi đã học được từ cha mình tầm quan trọng của sự chủ đích — biết mình đang cố gắng làm gì, và đảm bảo mọi việc mình làm đều phục vụ mục tiêu đó. — Will Guidara, Unreasonable Hospitality: The Remarkable Power of Giving People More Than They Expect
Bạn đã xác định các kịch bản thất bại và chẩn đoán các vấn đề thông qua phân tích quỹ đạo. Bây giờ là lúc sửa đổi hệ thống.
Sai lầm lớn nhất mà chúng tôi đã quan sát ở giai đoạn này: sai lệch xác nhận dẫn đến quá khớp. Với những thách thức về evals đã đề cập trước đó (vòng lặp phản hồi chậm và tính không thực tế của các bộ kiểm thử toàn diện), các nhà phát triển thường chỉ kiểm thử một vài kịch bản thất bại cụ thể cục bộ cho đến khi chúng vượt qua. Người ta sửa đổi ngữ cảnh (lời nhắc hệ thống, thông số công cụ, triển khai công cụ, v.v.) cho đến khi một hoặc hai kịch bản vượt qua, mà không xem xét tác động rộng hơn. Khi các thay đổi không tuân theo các thực hành tốt nhất về kỹ thuật ngữ cảnh, chúng có thể có những tác động tiêu cực mà chúng ta không thể nắm bắt thông qua các evals hạn chế.
Bạn cần cả sự siêng năng và phán đoán: thiết lập tiêu chí thành công thông qua các evals có sẵn và các kịch bản sản phẩm thực tế có thể tái sử dụng, nhưng cũng tự trang bị kiến thức về các thực hành tốt nhất về kỹ thuật ngữ cảnh để hướng dẫn các thay đổi của bạn. Chúng tôi đã thấy các thực hành tốt nhất về nhắc nhở và blog kỹ thuật của Anthropic, bài viết how long contexts fail của Drew Breunig, và các bài học từ việc xây dựng Manus là những tài nguyên đặc biệt hữu ích.
Thiết lập tiêu chí thành công trước tiên
Trước khi thực hiện bất kỳ thay đổi nào, hãy xác định thành công trông như thế nào:
- Đường cơ sở. Sửa các ID commit git cụ thể cho hệ thống hiện tại. Suy nghĩ kỹ lưỡng về những số liệu nào sẽ cải thiện cả trải nghiệm của tác nhân và trải nghiệm của khách hàng, sau đó thu thập các số liệu đó cho đường cơ sở.
- Các kịch bản kiểm thử. Evals nào sẽ đo lường tác động của thay đổi của bạn? Bạn sẽ chạy lại các evals này bao nhiêu lần? Hãy tự thuyết phục mình rằng bộ này đại diện cho các mẫu khách hàng rộng hơn, không chỉ một lỗi bạn đang điều tra.
- So sánh. Đo lường các thay đổi của bạn so với đường cơ sở bằng cách sử dụng cùng các số liệu.
Khung chủ đích này bảo vệ chống lại sai lệch xác nhận (diễn giải kết quả một cách thuận lợi) và ngụy biện chi phí chìm (chấp nhận các thay đổi đơn giản vì bạn đã đầu tư thời gian). Nếu các sửa đổi của bạn không làm thay đổi các số liệu như mong đợi, hãy từ chối chúng.
Ví dụ, khi tối ưu hóa một tác nhân phụ trong AWS DevOps Agent, chúng tôi thiết lập một đường cơ sở bằng cách sửa các ID commit git và chạy cùng một kịch bản bảy lần. Điều này tiết lộ cả hiệu suất điển hình và sự biến động.

Mỗi số liệu đo lường một khía cạnh khác nhau:
- Quan sát đúng – Có bao nhiêu tín hiệu liên quan (bản ghi nhật ký, dữ liệu số liệu, đoạn mã, v.v.) liên quan trực tiếp đến sự cố mà tác nhân phụ đã đưa ra?
- Quan sát không liên quan – Tác nhân phụ đã đưa bao nhiêu nhiễu vào tác nhân chính? Điều này đếm các tín hiệu không liên quan đến sự cố và có thể làm xao nhãng cuộc điều tra của tác nhân.
- Độ trễ – Tác nhân phụ mất bao lâu (được đo bằng phút và giây)?
- Token tác nhân phụ – Tác nhân phụ đã sử dụng bao nhiêu token để hoàn thành tác vụ của nó? Điều này đóng vai trò là một proxy cho chi phí chạy tác nhân phụ.
- Token tác nhân chính – Bao nhiêu cửa sổ ngữ cảnh của tác nhân chính đang được đầu vào và đầu ra của tác nhân phụ tiêu thụ? Điều này cung cấp cho chúng ta một cách hữu hình để xác định các cơ hội tối ưu hóa cho công cụ tác nhân phụ: chúng ta có thể nén các hướng dẫn cho tác nhân phụ hoặc kết quả mà nó trả về không?
Sau khi thiết lập đường cơ sở, chúng tôi so sánh các số liệu này với các phép đo tương tự với các thay đổi được đề xuất của chúng tôi. Điều này làm rõ liệu thay đổi có phải là một cải tiến thực sự hay không.
Đọc mẫu sản phẩm thực tế
Chúng tôi đã may mắn có một số nhóm Amazon áp dụng AWS DevOps Agent sớm. Một thành viên nhóm DevOps Agent luân phiên thường xuyên lấy mẫu các lần chạy sản phẩm thực tế bằng công cụ trực quan hóa quỹ đạo của chúng tôi (tương tự như trực quan hóa dựa trên OpenTelemetry đã thảo luận trước đó, nhưng được tùy chỉnh để hiển thị các tạo phẩm cụ thể của DevOps Agent như báo cáo phân tích nguyên nhân gốc rễ và các quan sát), đánh dấu xem đầu ra của tác nhân có chính xác hay không và xác định các điểm thất bại. Các mẫu sản phẩm là không thể thay thế; chúng tiết lộ trải nghiệm khách hàng thực tế. Ngoài ra, việc xem xét các mẫu liên tục tinh chỉnh trực giác của bạn về những gì tác nhân làm tốt và làm không tốt. Khi các lần chạy sản phẩm không đạt yêu cầu, bạn có các kịch bản thực tế để lặp lại: sửa đổi tác nhân của bạn cục bộ, sau đó chạy lại nó trên cùng môi trường sản phẩm cho đến khi đạt được kết quả mong muốn. Thiết lập mối quan hệ với một vài nhóm áp dụng sớm quan trọng sẵn sàng hợp tác theo cách này là vô giá. Họ cung cấp sự thật cơ bản cho việc lặp lại nhanh chóng và tạo cơ hội để xác định các kịch bản eval mới. Vòng lặp phản hồi chặt chẽ này với dữ liệu sản phẩm hoạt động cùng với phát triển dựa trên eval để tạo thành một bộ kiểm thử toàn diện.
Lời kết
Xây dựng một nguyên mẫu tác nhân chứng minh tính khả thi của việc giải quyết một vấn đề kinh doanh thực sự là một bước khởi đầu thú vị. Công việc khó khăn hơn là biến nguyên mẫu đó thành một sản phẩm hoạt động đáng tin cậy trên nhiều môi trường và tác vụ khách hàng đa dạng. Trong bài đăng này, chúng tôi đã chia sẻ năm cơ chế tạo thành nền tảng để cải thiện chất lượng tác nhân một cách có hệ thống: evals với các kịch bản thực tế và đa dạng, vòng lặp phản hồi nhanh, trực quan hóa quỹ đạo, các thay đổi có chủ đích và lấy mẫu sản phẩm.
Nếu bạn đang xây dựng một ứng dụng tác nhân, hãy bắt đầu xây dựng bộ eval của bạn ngay hôm nay. Ngay cả khi bắt đầu với một vài kịch bản quan trọng cũng sẽ thiết lập đường cơ sở chất lượng cần thiết để đo lường và cải thiện một cách có hệ thống. Để xem AWS DevOps Agent áp dụng các nguyên tắc này vào phản hồi sự cố như thế nào, hãy xem hướng dẫn bắt đầu của chúng tôi.
Về tác giả

Efe Karakus
Efe Karakus là Kỹ sư Phần mềm Cấp cao trong nhóm AWS DevOps Agent, chủ yếu tập trung vào phát triển tác nhân.
TAGS: DevOps
