Tác giả: Rizwan Mushtaq, Fan Zhang, Hector Lopez, and Meena Menon
Ngày phát hành: 16 JAN 2026
Chuyên mục: Amazon Aurora, Amazon Bedrock, Amazon Redshift, Amazon Titan, Customer Solutions, Technical How-to
Bài viết này được đồng tác giả bởi Fan Zhang, Kỹ sư/Kiến trúc sư chính cấp cao từ Palo Alto Networks.
Nhóm Bảo mật Thiết bị của Palo Alto Networks muốn phát hiện sớm các dấu hiệu cảnh báo về các vấn đề tiềm ẩn trong sản xuất để cung cấp thêm thời gian cho các SME phản ứng với những vấn đề mới nổi này. Thách thức chính mà họ phải đối mặt là việc xử lý phản ứng hơn 200 triệu mục nhật ký dịch vụ và ứng dụng hàng ngày dẫn đến thời gian phản hồi chậm trễ đối với các vấn đề quan trọng này, khiến họ có nguy cơ bị suy giảm dịch vụ tiềm ẩn.
Để giải quyết thách thức này, họ đã hợp tác với Trung tâm Đổi mới AI Tạo sinh của AWS (GenAIIC) để phát triển một quy trình phân loại nhật ký tự động được hỗ trợ bởi Amazon Bedrock. Giải pháp này đạt được độ chính xác 95% trong việc phát hiện các vấn đề sản xuất đồng thời giảm thời gian phản hồi sự cố xuống 83%.
Trong bài viết này, chúng ta sẽ khám phá cách xây dựng một hệ thống phân tích nhật ký có khả năng mở rộng và hiệu quả về chi phí bằng cách sử dụng Amazon Bedrock để biến việc giám sát nhật ký phản ứng thành phát hiện vấn đề chủ động. Chúng ta sẽ thảo luận về cách Amazon Bedrock, thông qua mô hình Claude Haiku của Anthropic, và Amazon Titan Text Embeddings hoạt động cùng nhau để tự động phân loại và phân tích dữ liệu nhật ký. Chúng ta sẽ khám phá cách quy trình tự động này phát hiện các vấn đề quan trọng, kiểm tra kiến trúc giải pháp và chia sẻ những hiểu biết về triển khai đã mang lại những cải tiến hoạt động có thể đo lường được.
Palo Alto Networks cung cấp Dịch vụ Bảo mật Phân phối qua Đám mây (CDSS) để giải quyết các rủi ro bảo mật thiết bị. Giải pháp của họ sử dụng máy học và khám phá tự động để cung cấp khả năng hiển thị vào các thiết bị được kết nối, thực thi các nguyên tắc Zero Trust. Các nhóm đối mặt với những thách thức phân tích nhật ký tương tự có thể tìm thấy những hiểu biết thực tế trong việc triển khai này.
Tổng quan giải pháp
Hệ thống phân loại nhật ký tự động của Palo Alto Networks giúp nhóm Bảo mật Thiết bị của họ phát hiện và phản ứng với các lỗi dịch vụ tiềm ẩn trước thời hạn. Giải pháp này xử lý hơn 200 triệu nhật ký dịch vụ và ứng dụng hàng ngày, tự động xác định các vấn đề quan trọng trước khi chúng leo thang thành các sự cố ngừng dịch vụ ảnh hưởng đến khách hàng.
Hệ thống sử dụng Amazon Bedrock với mô hình Claude Haiku của Anthropic để hiểu các mẫu nhật ký và phân loại mức độ nghiêm trọng, và Amazon Titan Text Embeddings cho phép khớp tương tự thông minh. Amazon Aurora cung cấp một lớp bộ nhớ đệm giúp việc xử lý khối lượng nhật ký khổng lồ trở nên khả thi trong thời gian thực. Giải pháp tích hợp liền mạch với cơ sở hạ tầng hiện có của Palo Alto Networks, giúp nhóm Bảo mật Thiết bị tập trung vào việc ngăn chặn sự cố ngừng hoạt động thay vì quản lý các quy trình phân tích nhật ký phức tạp.
Palo Alto Networks và AWS GenAIIC đã hợp tác để xây dựng một giải pháp với các khả năng sau:
- Khử trùng lặp và lưu trữ thông minh – Hệ thống mở rộng quy mô bằng cách xác định thông minh các mục nhật ký trùng lặp cho cùng một sự kiện mã. Thay vì sử dụng một mô hình ngôn ngữ lớn (LLM) để phân loại từng nhật ký riêng lẻ, hệ thống trước tiên xác định các bản sao thông qua khớp chính xác, sau đó chuyển sang khớp tương tự chồng chéo, và cuối cùng chỉ sử dụng khớp tương tự ngữ nghĩa nếu không tìm thấy khớp nào trước đó. Cách tiếp cận này giảm chi phí hiệu quả hơn 99% trong số 200 triệu nhật ký hàng ngày, chỉ còn lại các nhật ký đại diện cho các sự kiện duy nhất. Lớp bộ nhớ đệm cho phép xử lý thời gian thực bằng cách giảm nhu cầu gọi LLM dư thừa.
- Truy xuất ngữ cảnh cho các nhật ký duy nhất – Đối với các nhật ký duy nhất, mô hình Claude Haiku của Anthropic sử dụng Amazon Bedrock để phân loại mức độ nghiêm trọng của từng nhật ký. Mô hình xử lý nhật ký đến cùng với các ví dụ lịch sử được gắn nhãn có liên quan. Các ví dụ được truy xuất động tại thời điểm suy luận thông qua tìm kiếm tương tự vector. Theo thời gian, các ví dụ được gắn nhãn được thêm vào để cung cấp ngữ cảnh phong phú cho LLM để phân loại. Cách tiếp cận nhận biết ngữ cảnh này cải thiện độ chính xác cho các nhật ký và hệ thống nội bộ của Palo Alto Networks cũng như các mẫu nhật ký đang phát triển mà các hệ thống dựa trên quy tắc truyền thống gặp khó khăn trong việc xử lý.
- Phân loại với Amazon Bedrock – Giải pháp cung cấp các dự đoán có cấu trúc, bao gồm phân loại mức độ nghiêm trọng (Ưu tiên 1 (P1), Ưu tiên 2 (P2), Ưu tiên 3 (P3)) và lý do chi tiết cho mỗi quyết định. Đầu ra toàn diện này giúp các SME của Palo Alto Networks nhanh chóng ưu tiên phản hồi và thực hiện hành động phòng ngừa trước khi các sự cố ngừng hoạt động tiềm ẩn xảy ra.
- Tích hợp với các quy trình hiện có để hành động – Kết quả tích hợp với quy trình FluentD và Kafka hiện có của họ, với dữ liệu chảy đến Amazon Simple Storage Service (Amazon S3) và Amazon Redshift để phân tích và báo cáo thêm.
Sơ đồ sau (Hình 1) minh họa cách quy trình ba giai đoạn xử lý 200 triệu nhật ký hàng ngày của Palo Alto Networks trong khi cân bằng quy mô, độ chính xác và hiệu quả chi phí. Kiến trúc bao gồm các thành phần chính sau:
- Lớp nhập dữ liệu – Quy trình FluentD và Kafka và nhật ký đến
- Quy trình xử lý – Bao gồm các giai đoạn sau:
- Giai đoạn 1: Lưu trữ thông minh và khử trùng lặp – Aurora để khớp chính xác và Amazon Titan Text Embeddings để khớp ngữ nghĩa
- Giai đoạn 2: Truy xuất ngữ cảnh – Amazon Titan Text Embeddings để kích hoạt các ví dụ được gắn nhãn lịch sử và tìm kiếm tương tự vector
- Giai đoạn 3: Phân loại – Mô hình Claude Haiku của Anthropic để phân loại mức độ nghiêm trọng (P1/P2/P3)
- Lớp đầu ra – Aurora, Amazon S3, Amazon Redshift và giao diện xem xét của SME
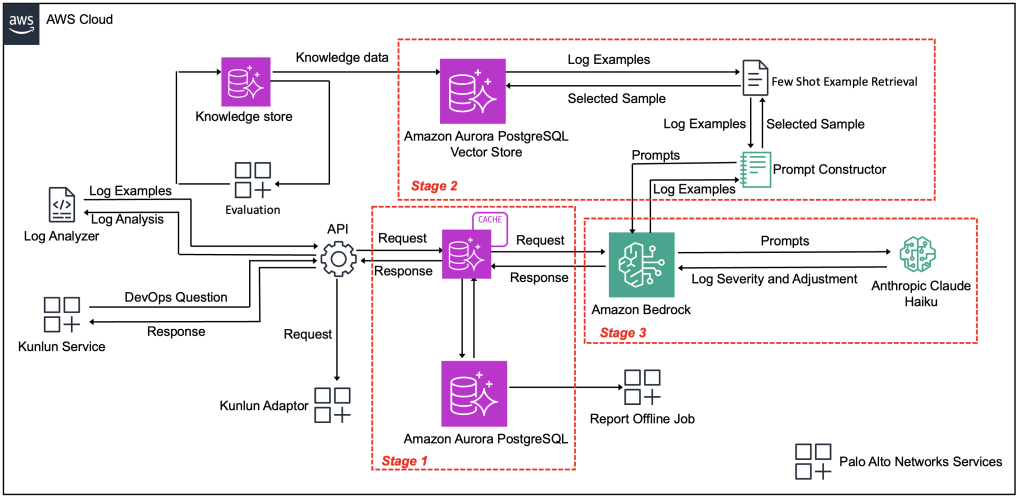
Hình 1: Kiến trúc hệ thống phân loại nhật ký tự động
Quy trình xử lý diễn ra qua các giai đoạn sau:
- Giai đoạn 1: Lưu trữ thông minh và khử trùng lặp – Các nhật ký đến từ quy trình FluentD và Kafka của Palo Alto Networks được xử lý ngay lập tức thông qua một lớp bộ nhớ đệm dựa trên Aurora. Hệ thống trước tiên áp dụng khớp chính xác, sau đó chuyển sang khớp tương tự chồng chéo, và cuối cùng sử dụng khớp tương tự ngữ nghĩa thông qua Amazon Titan Text Embeddings nếu không tìm thấy khớp nào trước đó. Trong quá trình thử nghiệm, cách tiếp cận này đã xác định rằng hơn 99% nhật ký tương ứng với các sự kiện trùng lặp, mặc dù chúng chứa các dấu thời gian, mức độ nhật ký và cách diễn đạt khác nhau. Hệ thống bộ nhớ đệm đã giảm thời gian phản hồi cho các kết quả được lưu trong bộ nhớ đệm và giảm xử lý LLM không cần thiết.
- Giai đoạn 2: Truy xuất ngữ cảnh cho các nhật ký duy nhất – Dưới 1% các nhật ký thực sự duy nhất còn lại yêu cầu phân loại. Đối với các mục này, hệ thống sử dụng Amazon Titan Text Embeddings để xác định các ví dụ lịch sử phù hợp nhất từ tập dữ liệu được gắn nhãn của Palo Alto Networks. Thay vì sử dụng các ví dụ tĩnh, việc truy xuất động này đảm bảo mỗi nhật ký nhận được hướng dẫn phù hợp theo ngữ cảnh để phân loại.
- Giai đoạn 3: Phân loại với Amazon Bedrock – Các nhật ký duy nhất và các ví dụ được chọn của chúng được xử lý bởi Amazon Bedrock sử dụng mô hình Claude Haiku của Anthropic. Mô hình phân tích nội dung nhật ký cùng với các ví dụ lịch sử có liên quan để tạo ra các phân loại mức độ nghiêm trọng (P1, P2, P3) và giải thích chi tiết. Kết quả được lưu trữ trong Aurora và bộ nhớ đệm và được tích hợp vào quy trình dữ liệu hiện có của Palo Alto Networks để SME xem xét và hành động.
Kiến trúc này cho phép xử lý hiệu quả về chi phí khối lượng nhật ký khổng lồ trong khi duy trì độ chính xác 95% cho việc phát hiện mức độ nghiêm trọng P1 quan trọng. Hệ thống sử dụng các lời nhắc được tạo ra cẩn thận kết hợp chuyên môn miền với các ví dụ được chọn động:
system_prompt = """<Task>You are an expert log analysis system responsible for classifying production system logs based on severity. Your analysis helps engineering teams prioritize their response to system issues and maintain service reliability.</Task><Severity_Definitions>P1 (Critical): Requires immediate action - system-wide outages, repeated application crashesP2 (High): Warrants attention during business hours - performance issues, partial service disruption P3 (Low): Can be addressed when resources available - minor bugs, authorization failures, intermittent network issues</Severity_Definitions><Examples><log_snippet>2024-08-17 01:15:00.00 [warn] failed (104: Connection reset by peer) while reading response header from upstream</log_snippet>severity: P3category: Category A<log_snippet>2024-08-18 17:40:00.00 <warn> Error: Request failed with status code 500 at settle</log_snippet>severity: P2category: Category B</Examples><Target_Log>Log: {incoming_log_snippet}Location: {system_location}</Target_Log>"""Provide severity classification (P1/P2/P3) and detailed reasoning.Những hiểu biết về triển khai
Giá trị cốt lõi của giải pháp Palo Alto Networks nằm ở việc biến một thách thức không thể vượt qua thành có thể quản lý được: AI giúp nhóm của họ phân tích hiệu quả 200 triệu khối lượng nhật ký hàng ngày, trong khi khả năng thích ứng động của hệ thống giúp mở rộng giải pháp trong tương lai bằng cách thêm nhiều ví dụ được gắn nhãn hơn. Việc triển khai thành công hệ thống phân loại nhật ký tự động của Palo Alto Networks đã mang lại những hiểu biết quan trọng có thể giúp các tổ chức xây dựng các giải pháp AI quy mô sản xuất:
- Hệ thống học liên tục mang lại giá trị tích lũy – Palo Alto Networks đã thiết kế hệ thống của họ để tự động cải thiện khi các SME xác thực các phân loại và gắn nhãn các ví dụ mới. Mỗi phân loại được xác thực trở thành một phần của tập dữ liệu truy xuất ít mẫu động, cải thiện độ chính xác cho các nhật ký tương lai tương tự đồng thời tăng tỷ lệ truy cập bộ nhớ đệm. Cách tiếp cận này tạo ra một chu kỳ trong đó việc sử dụng hoạt động nâng cao hiệu suất hệ thống và giảm chi phí.
- Bộ nhớ đệm thông minh cho phép AI ở quy mô sản xuất – Kiến trúc bộ nhớ đệm đa lớp xử lý hơn 99% nhật ký thông qua các truy cập bộ nhớ đệm, biến các hoạt động LLM tốn kém trên mỗi nhật ký thành một hệ thống hiệu quả về chi phí có khả năng xử lý 200 triệu khối lượng hàng ngày. Nền tảng này làm cho việc xử lý AI khả thi về mặt kinh tế ở quy mô doanh nghiệp trong khi vẫn duy trì thời gian phản hồi.
- Hệ thống thích ứng xử lý các yêu cầu thay đổi mà không cần thay đổi mã – Giải pháp đáp ứng các danh mục và mẫu nhật ký mới mà không yêu cầu sửa đổi hệ thống. Khi hiệu suất cần cải thiện cho các loại nhật ký mới, các SME có thể gắn nhãn các ví dụ bổ sung, và việc truy xuất ít mẫu động sẽ tự động tích hợp kiến thức này vào các phân loại trong tương lai. Khả năng thích ứng này cho phép hệ thống mở rộng theo nhu cầu kinh doanh.
- Phân loại có thể giải thích thúc đẩy sự tự tin trong vận hành – Các SME phản ứng với các cảnh báo quan trọng yêu cầu sự tự tin vào các khuyến nghị của AI, đặc biệt đối với các phân loại mức độ nghiêm trọng P1. Bằng cách cung cấp lý do chi tiết cùng với mỗi phân loại, Palo Alto Networks cho phép các SME nhanh chóng xác thực các quyết định và thực hiện hành động thích hợp. Các giải thích rõ ràng biến đầu ra AI từ các dự đoán thành thông tin tình báo có thể hành động.
Những hiểu biết này chứng minh cách các hệ thống AI được thiết kế để học liên tục và có thể giải thích trở thành tài sản hoạt động ngày càng có giá trị.
Kết luận
Hệ thống phân loại nhật ký tự động của Palo Alto Networks chứng minh cách AI tạo sinh được hỗ trợ bởi AWS giúp các nhóm vận hành quản lý khối lượng lớn dữ liệu trong thời gian thực. Trong bài viết này, chúng ta đã khám phá cách một kiến trúc kết hợp Amazon Bedrock, Amazon Titan Text Embeddings và Aurora xử lý 200 triệu nhật ký hàng ngày thông qua bộ nhớ đệm thông minh và học tập ít mẫu động, cho phép phát hiện chủ động các vấn đề quan trọng với độ chính xác 95%. Hệ thống phân loại nhật ký tự động của Palo Alto Networks đã mang lại những cải tiến hoạt động cụ thể:
- Độ chính xác 95%, độ thu hồi 90% cho nhật ký mức độ nghiêm trọng P1 – Các cảnh báo quan trọng chính xác và có thể hành động, giảm thiểu báo động sai trong khi phát hiện 9 trên 10 vấn đề khẩn cấp, để lại các cảnh báo còn lại được các hệ thống giám sát hiện có thu thập.
- Giảm 83% thời gian gỡ lỗi – Các SME dành ít thời gian hơn cho việc phân tích nhật ký thường xuyên và nhiều thời gian hơn cho các cải tiến chiến lược.
- Tỷ lệ truy cập bộ nhớ đệm trên 99% – Lớp bộ nhớ đệm thông minh xử lý 20 triệu khối lượng hàng ngày một cách hiệu quả về chi phí thông qua các phản hồi dưới một giây.
- Phát hiện vấn đề chủ động – Hệ thống xác định các vấn đề tiềm ẩn trước khi chúng ảnh hưởng đến khách hàng, ngăn chặn các sự cố ngừng hoạt động kéo dài nhiều tuần đã làm gián đoạn dịch vụ trước đây.
- Cải tiến liên tục – Mỗi xác thực của SME tự động cải thiện các phân loại trong tương lai và tăng hiệu quả bộ nhớ đệm, dẫn đến giảm chi phí.
Đối với các tổ chức đang đánh giá các sáng kiến AI để phân tích nhật ký và giám sát hoạt động, việc triển khai của Palo Alto Networks cung cấp một bản thiết kế để xây dựng các hệ thống quy mô sản xuất mang lại những cải tiến có thể đo lường được về hiệu quả hoạt động và giảm chi phí. Để xây dựng các giải pháp AI tạo sinh của riêng bạn, hãy khám phá Amazon Bedrock để truy cập được quản lý vào các mô hình nền tảng. Để được hướng dẫn thêm, hãy xem các tài nguyên AWS Machine Learning và duyệt qua các ví dụ triển khai trong Blog AWS Artificial Intelligence.
Sự hợp tác giữa Palo Alto Networks và AWS GenAIIC chứng minh cách triển khai AI chu đáo có thể biến các hoạt động phản ứng thành các hệ thống chủ động, có khả năng mở rộng, mang lại giá trị kinh doanh bền vững.
Để bắt đầu với Amazon Bedrock, hãy xem Xây dựng giải pháp AI tạo sinh với Amazon Bedrock.
Về tác giả

Rizwan Mushtaq
Rizwan là Kiến trúc sư Giải pháp chính tại AWS. Anh ấy giúp khách hàng thiết kế các giải pháp sáng tạo, linh hoạt và hiệu quả về chi phí bằng cách sử dụng các dịch vụ AWS. Anh ấy có bằng Thạc sĩ Kỹ thuật Điện từ Đại học Wichita State.

Hector Lopez
Hector Lopez, Tiến sĩ là một Nhà khoa học Ứng dụng tại Trung tâm Đổi mới AI Tạo sinh của AWS, nơi anh chuyên cung cấp các giải pháp AI tạo sinh sẵn sàng sản xuất và các bằng chứng khái niệm trên nhiều ứng dụng công nghiệp đa dạng. Chuyên môn của anh bao gồm máy học truyền thống và khoa học dữ liệu trong khoa học đời sống và vật lý. Hector áp dụng phương pháp tiếp cận từ các nguyên tắc cơ bản cho các giải pháp của khách hàng, làm việc ngược lại từ các nhu cầu kinh doanh cốt lõi để giúp các tổ chức hiểu và tận dụng các công cụ AI tạo sinh cho sự chuyển đổi kinh doanh có ý nghĩa.

Meena Menon
Meena Menon là Giám đốc Thành công Khách hàng cấp cao tại AWS với hơn 20 năm kinh nghiệm mang lại kết quả cho khách hàng doanh nghiệp và chuyển đổi kỹ thuật số. Tại AWS, cô hợp tác với các ISV chiến lược bao gồm Palo Alto Networks, Proofpoint, New Relic và Splunk để đẩy nhanh quá trình hiện đại hóa và di chuyển lên đám mây.

Fan Zhang
Fan là Kỹ sư/Kiến trúc sư chính cấp cao tại Palo Alto Networks, dẫn dắt hạ tầng và quy trình dữ liệu của nhóm Bảo mật IoT, cũng như hạ tầng AI tạo sinh của họ.
