Tác giả: Yunfei Bai, Carrie Song, Elad Dwek, Harsh Asnani, Kristine Pearce, và Sung-Ching Lin
Ngày phát hành: 16 JAN 2026
Chuyên mục: Amazon SageMaker AI, Best Practices, Generative AI, Intermediate (200), Thought Leadership
Công việc của chúng tôi với các khách hàng doanh nghiệp lớn và các nhóm của Amazon đã tiết lộ rằng các trường hợp sử dụng có rủi ro cao tiếp tục hưởng lợi đáng kể từ các kỹ thuật tinh chỉnh mô hình ngôn ngữ lớn (LLM) và hậu huấn luyện nâng cao. Trong bài viết này, chúng tôi sẽ chỉ cho bạn cách tinh chỉnh đã giúp giảm 33% lỗi thuốc nguy hiểm (Amazon Pharmacy), giảm 80% công sức của kỹ sư (Amazon Global Engineering Services), và cải thiện đánh giá chất lượng nội dung từ 77% lên 96% độ chính xác (Amazon A+). Đây không phải là những dự đoán giả định—mà là kết quả sản xuất từ các nhóm của Amazon. Mặc dù nhiều trường hợp sử dụng có thể được giải quyết hiệu quả thông qua prompt engineering, hệ thống Retrieval Augmented Generation (RAG) và triển khai tác nhân sẵn có, công việc của chúng tôi với Amazon và các tài khoản doanh nghiệp lớn cho thấy một mô hình nhất quán: Một trong bốn ứng dụng có rủi ro cao—nơi an toàn bệnh nhân, hiệu quả hoạt động hoặc niềm tin của khách hàng đang bị đe dọa—đòi hỏi các kỹ thuật tinh chỉnh và hậu huấn luyện nâng cao để đạt được hiệu suất cấp độ sản xuất.
Bài viết này trình bày chi tiết các kỹ thuật đằng sau những kết quả này: từ các phương pháp cơ bản như Supervised Fine-Tuning (SFT) (instruction tuning), và Proximal Policy Optimization (PPO), đến Direct Preference Optimization (DPO) để điều chỉnh theo con người, đến các tối ưu hóa suy luận tiên tiến như Grouped-based Reinforcement Learning from Policy Optimization (GRPO), Direct Advantage Policy Optimization (DAPO), và Group Sequence Policy Optimization (GSPO) được xây dựng đặc biệt cho các hệ thống tác nhân. Chúng tôi sẽ đi sâu vào sự phát triển kỹ thuật của từng phương pháp, xem xét các triển khai thực tế tại Amazon, trình bày kiến trúc tham chiếu trên Amazon Web Services (AWS), và cung cấp một khung quyết định để lựa chọn kỹ thuật phù hợp dựa trên yêu cầu trường hợp sử dụng của bạn.
Sự liên quan tiếp tục của tinh chỉnh trong AI tác nhân
Mặc dù khả năng của các foundation model và framework tác nhân ngày càng tăng, khoảng một trong bốn trường hợp sử dụng doanh nghiệp vẫn yêu cầu tinh chỉnh nâng cao để đạt được mức hiệu suất cần thiết. Đây thường là các kịch bản mà rủi ro cao từ góc độ doanh thu hoặc niềm tin của khách hàng, kiến thức chuyên sâu về lĩnh vực là cần thiết, tích hợp doanh nghiệp ở quy mô lớn được yêu cầu, quản trị và kiểm soát là tối quan trọng, tích hợp quy trình kinh doanh phức tạp, hoặc cần hỗ trợ đa phương thức. Các tổ chức theo đuổi các trường hợp sử dụng này đã báo cáo tỷ lệ chuyển đổi sang sản xuất cao hơn, lợi tức đầu tư (ROI) lớn hơn, và tăng trưởng gấp 3 lần theo năm khi tinh chỉnh nâng cao được áp dụng một cách thích hợp.
Sự phát triển của các kỹ thuật tinh chỉnh LLM cho AI tác nhân
Sự phát triển của AI tạo sinh đã chứng kiến một số tiến bộ quan trọng trong các kỹ thuật tùy chỉnh và tối ưu hóa hiệu suất mô hình. Bắt đầu với SFT, sử dụng dữ liệu được gắn nhãn để dạy các mô hình tuân theo các hướng dẫn cụ thể, lĩnh vực này đã thiết lập nền tảng nhưng phải đối mặt với những hạn chế trong việc tối ưu hóa suy luận phức tạp. Để giải quyết những hạn chế này, học tăng cường (RL) tinh chỉnh quy trình SFT bằng một hệ thống dựa trên phần thưởng cung cấp khả năng thích ứng và điều chỉnh tốt hơn với sở thích của con người. Trong số nhiều thuật toán RL, một bước nhảy vọt đáng kể đến với PPO, bao gồm một quy trình làm việc với mạng giá trị (critic) và mạng chính sách. Quy trình làm việc này chứa một chính sách học tăng cường để điều chỉnh trọng số LLM dựa trên hướng dẫn của một mô hình phần thưởng. PPO mở rộng tốt trong các môi trường phức tạp, mặc dù nó có những thách thức về sự ổn định và độ phức tạp cấu hình.
DPO nổi lên như một bước đột phá vào đầu năm 2024, giải quyết các vấn đề ổn định của PPO bằng cách loại bỏ mô hình phần thưởng rõ ràng và thay vào đó làm việc trực tiếp với dữ liệu ưu tiên bao gồm các phản hồi được ưu tiên và bị từ chối cho các prompt nhất định. DPO tối ưu hóa trọng số LLM bằng cách so sánh các phản hồi được ưu tiên và bị từ chối, cho phép LLM học và điều chỉnh hành vi của nó cho phù hợp. Phương pháp đơn giản hóa này đã được áp dụng rộng rãi, với các mô hình ngôn ngữ lớn tích hợp DPO vào các quy trình huấn luyện của họ để đạt được hiệu suất tốt hơn và đầu ra đáng tin cậy hơn. Các lựa chọn thay thế khác bao gồm Odds Ratio Policy Optimization (ORPO), Relative Preference Optimization (RPO), Identity preference optimization (IPO), Kahneman-Tversky Optimization (KTO), tất cả đều là các phương pháp RL để điều chỉnh sở thích của con người. Bằng cách kết hợp các cấu trúc ưu tiên so sánh và dựa trên danh tính, và đặt nền tảng tối ưu hóa trong kinh tế học hành vi, các phương pháp này hiệu quả về mặt tính toán, dễ hiểu và phù hợp với các quy trình ra quyết định thực tế của con người.
Khi các ứng dụng dựa trên tác nhân trở nên nổi bật vào năm 2025, chúng tôi nhận thấy nhu cầu ngày càng tăng về việc tùy chỉnh mô hình suy luận trong các tác nhân, để mã hóa các ràng buộc cụ thể theo miền, hướng dẫn an toàn và các mô hình suy luận phù hợp với các chức năng dự định của tác nhân (lập kế hoạch tác vụ, sử dụng công cụ hoặc giải quyết vấn đề đa bước). Mục tiêu là cải thiện hiệu suất của tác nhân trong việc duy trì các kế hoạch mạch lạc, tránh mâu thuẫn logic và đưa ra các quyết định phù hợp cho các trường hợp sử dụng cụ thể theo miền. Để đáp ứng những nhu cầu này, GRPO đã được giới thiệu để tăng cường khả năng suy luận và trở nên đặc biệt đáng chú ý với việc triển khai trong DeepSeek-V1.
Đổi mới cốt lõi của GRPO nằm ở phương pháp so sánh dựa trên nhóm của nó: thay vì so sánh các phản hồi riêng lẻ với một tham chiếu cố định, GRPO tạo ra các nhóm phản hồi và đánh giá từng phản hồi so với điểm trung bình của nhóm, thưởng cho những phản hồi hoạt động trên mức trung bình trong khi phạt những phản hồi dưới mức. Cơ chế so sánh tương đối này tạo ra một động lực cạnh tranh khuyến khích mô hình tạo ra suy luận chất lượng cao hơn. GRPO đặc biệt hiệu quả trong việc cải thiện suy luận chain-of-thought (CoT), nền tảng quan trọng cho việc lập kế hoạch tác nhân và phân tách tác vụ phức tạp. Bằng cách tối ưu hóa ở cấp độ nhóm, GRPO nắm bắt sự biến đổi vốn có trong các quy trình suy luận và huấn luyện mô hình để liên tục vượt trội so với hiệu suất trung bình của chính nó.
Một số tác vụ tác nhân phức tạp có thể yêu cầu các chỉnh sửa chi tiết và sắc nét hơn trong các chuỗi suy luận dài, DAPO giải quyết các trường hợp sử dụng này bằng cách xây dựng dựa trên phần thưởng cấp chuỗi của GRPO, sử dụng tỷ lệ cắt cao hơn (khoảng 30% cao hơn GRPO) để khuyến khích các quy trình tư duy đa dạng và khám phá hơn, triển khai lấy mẫu động để loại bỏ các mẫu ít ý nghĩa hơn và cải thiện hiệu quả huấn luyện tổng thể, áp dụng tổn thất gradient chính sách cấp token để cung cấp phản hồi chi tiết hơn về các chuỗi suy luận dài thay vì coi toàn bộ chuỗi là các đơn vị nguyên khối, và kết hợp định hình phần thưởng quá dài để ngăn chặn các phản hồi quá dài dòng làm lãng phí tài nguyên tính toán. Ngoài ra, khi các trường hợp sử dụng tác nhân yêu cầu đầu ra văn bản dài trong huấn luyện mô hình Mixture-of-Experts (MoE), GSPO hỗ trợ các kịch bản này bằng cách chuyển tối ưu hóa từ trọng số quan trọng cấp token của GRPO sang cấp chuỗi. Với những cải tiến này, các phương pháp mới (DAPO và GSPO) cho phép chiến lược suy luận và lập kế hoạch tác nhân hiệu quả và tinh vi hơn, đồng thời duy trì hiệu quả tính toán và độ phân giải phản hồi phù hợp của GRPO.
Các ứng dụng thực tế tại Amazon
Sử dụng các kỹ thuật tinh chỉnh được mô tả trong các phần trước, các LLM được hậu huấn luyện đóng hai vai trò quan trọng trong các hệ thống AI tác nhân. Đầu tiên là trong việc phát triển các thành phần sử dụng công cụ chuyên biệt và các tác nhân phụ trong kiến trúc tác nhân rộng hơn. Các mô hình được tinh chỉnh này hoạt động như các chuyên gia miền, mỗi mô hình được tối ưu hóa cho các chức năng cụ thể. Bằng cách kết hợp kiến thức và ràng buộc cụ thể theo miền trong quá trình tinh chỉnh, các thành phần chuyên biệt này có thể đạt được độ chính xác và độ tin cậy cao hơn đáng kể trong các tác vụ được chỉ định của chúng so với các mô hình đa năng. Ứng dụng quan trọng thứ hai là đóng vai trò là công cụ suy luận cốt lõi, nơi các foundation model được tinh chỉnh đặc biệt để xuất sắc trong việc lập kế hoạch, suy luận logic và ra quyết định, cho các tác nhân trong một miền rất cụ thể. Mục tiêu là cải thiện khả năng của mô hình trong việc duy trì các kế hoạch mạch lạc và đưa ra các quyết định hợp lý—những khả năng thiết yếu cho bất kỳ hệ thống tác nhân nào. Cách tiếp cận kép này, kết hợp một lõi suy luận được tinh chỉnh với các thành phần phụ chuyên biệt, đang nổi lên như một kiến trúc đầy hứa hẹn tại Amazon để phát triển từ các ứng dụng dựa trên LLM sang các hệ thống tác nhân, và xây dựng các ứng dụng AI tạo sinh có khả năng và đáng tin cậy hơn. Bảng sau đây mô tả điều phối AI đa tác nhân với các ví dụ về kỹ thuật tinh chỉnh nâng cao.
| Amazon Pharmacy | Amazon Global Engineering Services | Amazon A+ Content | |
|---|---|---|---|
| Miền | Chăm sóc sức khỏe | Xây dựng và cơ sở vật chất | Thương mại điện tử |
| Yếu tố rủi ro cao | An toàn bệnh nhân | Hiệu quả hoạt động | Niềm tin của khách hàng |
| Thách thức | Chi phí hàng năm 3,5 tỷ USD từ lỗi thuốc | Đánh giá kiểm tra hơn 3 giờ | Đánh giá chất lượng ở quy mô hơn 100 triệu |
| Kỹ thuật | SFT, PPO, RLHF, RL nâng cao | SFT, PPO, RLHF, RL nâng cao | Tinh chỉnh dựa trên tính năng |
| Kết quả chính | Giảm 33% lỗi thuốc | Giảm 80% công sức của con người | Độ chính xác 77%–96% |
Amazon Healthcare Services (AHS) bắt đầu hành trình với AI tạo sinh với một thách thức đáng kể hai năm trước, khi nhóm giải quyết hiệu quả dịch vụ khách hàng thông qua một hệ thống Q&A dựa trên RAG. Các nỗ lực ban đầu sử dụng RAG truyền thống với các foundation model đã mang lại kết quả đáng thất vọng, với độ chính xác dao động từ 60 đến 70%. Bước đột phá đến khi họ tinh chỉnh mô hình nhúng đặc biệt cho kiến thức miền dược phẩm, dẫn đến cải thiện đáng kể lên 90% độ chính xác và giảm 11% liên hệ hỗ trợ khách hàng. Trong an toàn thuốc, lỗi hướng dẫn thuốc có thể gây ra rủi ro an toàn nghiêm trọng và tốn tới 3,5 tỷ USD hàng năm để khắc phục. Bằng cách tinh chỉnh một mô hình với hàng nghìn ví dụ được chuyên gia chú thích, Amazon Pharmacy đã tạo ra một thành phần tác nhân xác thực hướng dẫn thuốc bằng cách sử dụng logic dược phẩm và hướng dẫn an toàn. Điều này đã giảm các sự kiện suýt xảy ra 33%, như được chỉ ra trong ấn phẩm Nature Medicine của họ. Năm 2025, AHS đang mở rộng khả năng AI của họ và chuyển đổi các ứng dụng dựa trên LLM riêng biệt này thành một hệ thống đa tác nhân toàn diện để nâng cao trải nghiệm bệnh nhân. Các ứng dụng riêng lẻ này được điều khiển bởi các mô hình được tinh chỉnh đóng vai trò quan trọng trong kiến trúc tác nhân tổng thể, phục vụ như các công cụ chuyên gia miền để giải quyết các chức năng quan trọng cụ thể trong dịch vụ dược phẩm.
Nhóm Amazon Global Engineering Services (GES), chịu trách nhiệm giám sát hàng trăm trung tâm hoàn thiện đơn hàng của Amazon trên toàn thế giới, đã bắt tay vào một hành trình đầy tham vọng để sử dụng AI tạo sinh trong hoạt động của họ. Nỗ lực ban đầu của họ vào công nghệ này tập trung vào việc tạo ra một hệ thống Q&A tinh vi được thiết kế để hỗ trợ các kỹ sư truy cập hiệu quả thông tin thiết kế liên quan từ các kho kiến thức rộng lớn. Cách tiếp cận của nhóm là tinh chỉnh một foundation model bằng SFT, dẫn đến cải thiện đáng kể về độ chính xác (được đo bằng điểm tương đồng ngữ nghĩa) từ 0,64 lên 0,81. Để phù hợp hơn với phản hồi từ các chuyên gia chủ đề (SME), nhóm tiếp tục tinh chỉnh mô hình bằng PPO kết hợp dữ liệu phản hồi của con người, giúp tăng điểm đánh giá LLM từ 3,9 lên 4,2 trên 5, một thành tựu đáng chú ý đã chuyển thành giảm đáng kể 80% công sức cần thiết từ các chuyên gia miền. Tương tự như trường hợp Amazon Pharmacy, các mô hình chuyên biệt được tinh chỉnh này sẽ tiếp tục hoạt động như các công cụ chuyên gia miền trong hệ thống AI tác nhân rộng hơn.
Năm 2025, nhóm GES đã mạo hiểm vào một lĩnh vực chưa được khám phá bằng cách áp dụng các hệ thống AI tác nhân để tối ưu hóa quy trình kinh doanh của họ. Các phương pháp tinh chỉnh LLM tạo thành một cơ chế quan trọng để tăng cường khả năng suy luận trong các tác nhân AI, cho phép phân tách hiệu quả các mục tiêu phức tạp thành các chuỗi hành động có thể thực thi phù hợp với các ràng buộc hành vi được xác định trước và các kết quả định hướng mục tiêu. Nó cũng đóng vai trò là thành phần kiến trúc quan trọng trong việc tạo điều kiện thực hiện tác vụ chuyên biệt và tối ưu hóa cho các chỉ số hiệu suất cụ thể theo tác vụ.
Amazon A+ Content cung cấp các trang sản phẩm phong phú với hàng trăm triệu lượt gửi hàng năm. Nhóm A+ cần đánh giá chất lượng nội dung ở quy mô lớn—đánh giá tính gắn kết, nhất quán và mức độ liên quan, không chỉ các lỗi bề mặt. Chất lượng nội dung ảnh hưởng trực tiếp đến tỷ lệ chuyển đổi và niềm tin thương hiệu, khiến đây trở thành một ứng dụng có rủi ro cao.
Theo mô hình kiến trúc được thấy trong Amazon Pharmacy và Global Engineering Services, nhóm đã xây dựng một tác nhân đánh giá chuyên biệt được hỗ trợ bởi một mô hình được tinh chỉnh. Họ đã áp dụng tinh chỉnh dựa trên tính năng cho Nova Lite trên Amazon SageMaker—huấn luyện một bộ phân loại nhẹ trên các tính năng được trích xuất từ mô hình ngôn ngữ thị giác (VLM) thay vì cập nhật toàn bộ tham số mô hình. Cách tiếp cận này, được tăng cường bởi các prompt quy tắc do chuyên gia tạo ra, đã cải thiện độ chính xác phân loại từ 77% lên 96%. Kết quả: một tác nhân AI đánh giá hàng triệu lượt gửi nội dung và đưa ra các khuyến nghị có thể hành động. Điều này chứng minh một nguyên tắc chính từ khung trưởng thành của chúng tôi—độ phức tạp kỹ thuật phải phù hợp với yêu cầu tác vụ. Trường hợp sử dụng A+, mặc dù có rủi ro cao và hoạt động ở quy mô lớn, về cơ bản là một tác vụ phân loại rất phù hợp với các phương pháp này. Không phải mọi thành phần tác nhân đều yêu cầu GRPO hoặc DAPO; việc lựa chọn kỹ thuật phù hợp cho từng vấn đề là điều mang lại các hệ thống hiệu quả, cấp độ sản xuất.
Kiến trúc tham chiếu cho điều phối AI nâng cao bằng cách sử dụng tinh chỉnh
Mặc dù các mô hình được tinh chỉnh phục vụ các mục đích đa dạng trên các miền và trường hợp sử dụng khác nhau trong một hệ thống AI tác nhân, cấu trúc của một tác nhân vẫn phần lớn nhất quán và có thể được bao gồm trong các nhóm thành phần, như được hiển thị trong sơ đồ kiến trúc sau.
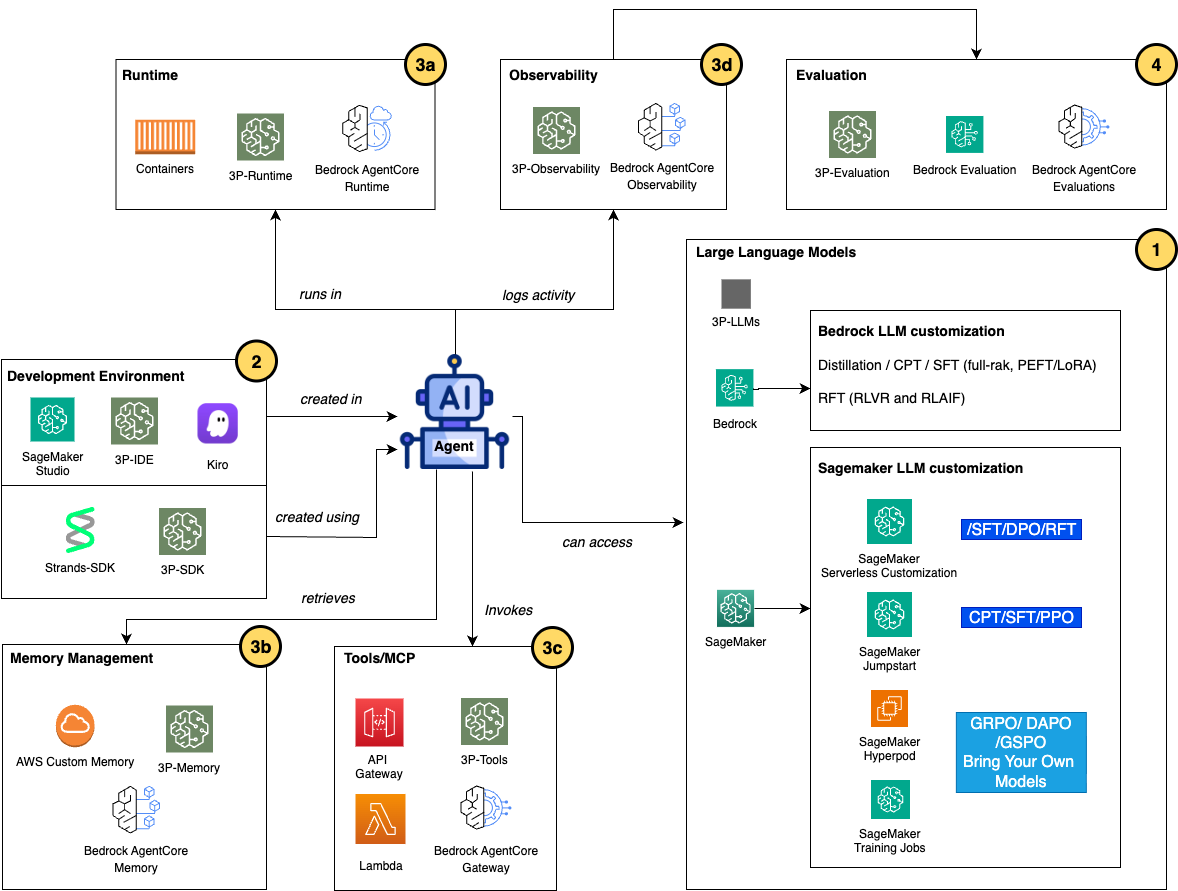
Cách tiếp cận mô-đun này áp dụng một số dịch vụ AI tạo sinh của AWS, bao gồm Amazon Bedrock AgentCore, Amazon SageMaker, và Amazon Bedrock, duy trì cấu trúc của các nhóm chính tạo nên một tác nhân trong khi cung cấp các tùy chọn khác nhau trong mỗi nhóm để cải thiện một tác nhân AI.
- Tùy chỉnh LLM cho các tác nhân AI Các nhà phát triển có thể sử dụng nhiều dịch vụ AWS khác nhau để tinh chỉnh và hậu huấn luyện các LLM cho một tác nhân AI bằng cách sử dụng các kỹ thuật đã thảo luận trong phần trước. Nếu bạn sử dụng LLM trên Amazon Bedrock cho các tác nhân của mình, bạn có thể sử dụng nhiều phương pháp tùy chỉnh mô hình để tinh chỉnh các mô hình của mình. Distillation và SFT thông qua tinh chỉnh hiệu quả tham số (PEFT) với low-rank adaptation (LoRA) có thể được sử dụng để giải quyết các tác vụ tùy chỉnh đơn giản. Đối với tinh chỉnh nâng cao, Continued Pre-training (CPT) mở rộng kiến thức của một foundation model bằng cách huấn luyện trên các tập dữ liệu chuyên biệt theo miền (tài liệu y tế, tài liệu pháp lý hoặc nội dung kỹ thuật độc quyền), nhúng trực tiếp từ vựng chuyên biệt và các mô hình suy luận miền vào trọng số mô hình. Reinforcement fine-tuning (RFT), ra mắt tại re:Invent 2025, dạy các mô hình hiểu điều gì tạo nên một phản hồi chất lượng mà không cần lượng lớn dữ liệu huấn luyện được gắn nhãn trước. Có hai cách tiếp cận được hỗ trợ cho RFT: Reinforcement Learning with Verifiable Rewards (RLVR) sử dụng các bộ chấm điểm dựa trên quy tắc cho các tác vụ khách quan như tạo mã hoặc suy luận toán học, trong khi Reinforcement Learning from AI Feedback (RLAIF) sử dụng các bộ đánh giá dựa trên AI cho các tác vụ chủ quan như tuân thủ hướng dẫn hoặc kiểm duyệt nội dung. Nếu bạn yêu cầu kiểm soát sâu hơn đối với cơ sở hạ tầng tùy chỉnh mô hình cho các tác nhân AI của mình, Amazon SageMaker AI cung cấp một nền tảng toàn diện để phát triển và tinh chỉnh mô hình tùy chỉnh. Amazon SageMaker JumpStart tăng tốc hành trình tùy chỉnh bằng cách cung cấp các giải pháp dựng sẵn với triển khai một cú nhấp chuột các foundation model phổ biến (Llama, Mistral, Falcon, và các mô hình khác) và các sổ ghi chép tinh chỉnh end-to-end xử lý chuẩn bị dữ liệu, cấu hình huấn luyện và quy trình triển khai. Amazon SageMaker Training jobs cung cấp cơ sở hạ tầng được quản lý để thực hiện các quy trình tinh chỉnh tùy chỉnh, tự động cấp phát các phiên bản GPU, quản lý thực thi huấn luyện và xử lý dọn dẹp sau khi hoàn thành. Cách tiếp cận này phù hợp với hầu hết các kịch bản tinh chỉnh nơi cấu hình phiên bản tiêu chuẩn cung cấp đủ sức mạnh tính toán và huấn luyện hoàn thành đáng tin cậy trong giới hạn thời gian của job. Bạn có thể sử dụng SageMaker Training jobs với custom Docker containers và code dependencies chứa bất kỳ framework học máy (ML), thư viện huấn luyện hoặc kỹ thuật tối ưu hóa nào, cho phép thử nghiệm các phương pháp mới nổi ngoài các dịch vụ được quản lý. Tại re:Invent 2025, Amazon SageMaker HyperPod đã giới thiệu hai khả năng để tùy chỉnh mô hình quy mô lớn: Checkpointless training giảm chu kỳ checkpoint-restart, rút ngắn thời gian phục hồi từ hàng giờ xuống còn vài phút. Elastic training tự động mở rộng khối lượng công việc để sử dụng dung lượng nhàn rỗi và giải phóng tài nguyên khi khối lượng công việc ưu tiên cao hơn đạt đỉnh. Các tính năng này xây dựng trên các thế mạnh cốt lõi của HyperPod—các cụm huấn luyện phân tán linh hoạt với khả năng phục hồi lỗi tự động cho các job kéo dài nhiều tuần trên hàng nghìn GPU. HyperPod hỗ trợ các framework NVIDIA NeMo và AWS Neuronx, và lý tưởng khi quy mô huấn luyện, thời lượng hoặc yêu cầu độ tin cậy vượt quá những gì cơ sở hạ tầng dựa trên job có thể cung cấp một cách kinh tế. Trong SageMaker AI, đối với các nhà phát triển muốn tùy chỉnh mô hình mà không cần quản lý cơ sở hạ tầng, tùy chỉnh không máy chủ của Amazon SageMaker AI, ra mắt tại re:Invent 2025, cung cấp trải nghiệm hoàn toàn được quản lý, dựa trên UI và SDK để tinh chỉnh mô hình. Khả năng này cung cấp quản lý cơ sở hạ tầng—SageMaker tự động chọn và cấp phát tài nguyên tính toán phù hợp (các phiên bản P5, P4de, P4d và G5) dựa trên kích thước mô hình và yêu cầu huấn luyện. Thông qua giao diện người dùng SageMaker Studio, bạn có thể tùy chỉnh các mô hình phổ biến (Amazon Nova, Llama, DeepSeek, GPT-OSS và Qwen) bằng cách sử dụng các kỹ thuật nâng cao bao gồm SFT, DPO, RLVR và RLAIF. Bạn cũng có thể chạy tùy chỉnh không máy chủ tương tự bằng cách sử dụng SageMaker Python SDK trong sổ ghi chép Jupyter của mình. Cách tiếp cận không máy chủ cung cấp giá trả theo token, tự động dọn dẹp tài nguyên, theo dõi thử nghiệm MLflow tích hợp và triển khai liền mạch đến cả Amazon Bedrock và các endpoint của SageMaker. Nếu bạn cần tùy chỉnh các mô hình Amazon Nova cho quy trình làm việc tác nhân của mình, bạn có thể thực hiện thông qua recipes và huấn luyện chúng trên SageMaker AI. Nó cung cấp quy trình tùy chỉnh end-to-end bao gồm huấn luyện, đánh giá và triển khai mô hình để suy luận, với sự linh hoạt và kiểm soát cao hơn để tinh chỉnh các mô hình Nova, tối ưu hóa siêu tham số với độ chính xác, và triển khai các kỹ thuật như LoRA PEFT, full-rank SFT, DPO, RFT, CPT, PPO, v.v. Đối với các mô hình Nova trên Amazon Bedrock, bạn cũng có thể huấn luyện các mô hình Nova của mình bằng SFT và RFT với nội dung suy luận để nắm bắt các bước tư duy trung gian hoặc sử dụng tối ưu hóa dựa trên phần thưởng khi khó xác định câu trả lời chính xác. Nếu bạn có các trường hợp sử dụng tác nhân nâng cao hơn yêu cầu tùy chỉnh mô hình sâu hơn, bạn có thể sử dụng Amazon Nova Forge—ra mắt tại re:Invent 2025—để xây dựng các mô hình tiên phong của riêng bạn từ các checkpoint mô hình ban đầu, kết hợp các tập dữ liệu của bạn với dữ liệu huấn luyện được Amazon Nova tuyển chọn, và lưu trữ các mô hình tùy chỉnh của bạn một cách an toàn trên AWS.
- Môi trường phát triển tác nhân AI và SDK Môi trường phát triển là nơi các nhà phát triển tạo, kiểm tra và lặp lại logic tác nhân trước khi triển khai. Các nhà phát triển sử dụng các môi trường phát triển tích hợp (IDE) như SageMaker AI Studio (Jupyter Notebooks so với trình chỉnh sửa mã), Amazon Kiro hoặc các IDE trên máy cục bộ như PyCharm. Logic tác nhân được triển khai bằng cách sử dụng các SDK và framework chuyên biệt trừu tượng hóa độ phức tạp của điều phối—Strands cung cấp một framework Python được xây dựng đặc biệt cho các hệ thống đa tác nhân, cung cấp các định nghĩa tác nhân khai báo, quản lý trạng thái tích hợp và tích hợp dịch vụ AWS gốc xử lý các chi tiết cấp thấp của các lệnh gọi API LLM, giao thức gọi công cụ, phục hồi lỗi và quản lý hội thoại. Với các công cụ phát triển này xử lý các chi tiết cấp thấp của các lệnh gọi API LLM, các nhà phát triển có thể tập trung vào logic kinh doanh thay vì thiết kế và bảo trì cơ sở hạ tầng.
- Triển khai và vận hành tác nhân AI Sau khi phát triển tác nhân AI của bạn hoàn tất và sẵn sàng triển khai vào sản xuất, bạn có thể sử dụng Amazon Bedrock AgentCore để xử lý việc thực thi tác nhân, bộ nhớ, bảo mật và tích hợp công cụ mà không yêu cầu quản lý cơ sở hạ tầng. Bedrock AgentCore cung cấp một bộ dịch vụ tích hợp, bao gồm: a. AgentCore Runtime cung cấp các môi trường được xây dựng đặc biệt để trừu tượng hóa việc quản lý cơ sở hạ tầng, trong khi các lựa chọn thay thế dựa trên container (SageMaker AI jobs, AWS Lambda, Amazon Elastic Kubernetes Service (Amazon EKS), và Amazon Elastic Container Service (Amazon ECS)) cung cấp nhiều quyền kiểm soát hơn cho các yêu cầu tùy chỉnh. Về cơ bản, runtime là nơi mã tác nhân được tạo ra cẩn thận của bạn gặp gỡ người dùng thực và mang lại giá trị kinh doanh ở quy mô lớn.
b. AgentCore Memory cung cấp cho các tác nhân AI của bạn khả năng ghi nhớ các tương tác trong quá khứ, cho phép chúng cung cấp các cuộc trò chuyện thông minh hơn, nhận biết ngữ cảnh và cá nhân hóa hơn. Nó cung cấp một cách đơn giản và mạnh mẽ để xử lý cả ngữ cảnh ngắn hạn và lưu giữ kiến thức dài hạn mà không cần xây dựng hoặc quản lý cơ sở hạ tầng phức tạp.
c. Với AgentCore Gateway, các nhà phát triển có thể xây dựng, triển khai, khám phá và kết nối với các công cụ ở quy mô lớn, cung cấp khả năng quan sát các mẫu sử dụng công cụ, xử lý lỗi cho các lệnh gọi không thành công và tích hợp với các hệ thống danh tính để truy cập các công cụ thay mặt người dùng (sử dụng OAuth hoặc khóa API). Các nhóm có thể cập nhật các backend công cụ, thêm các khả năng mới hoặc sửa đổi các yêu cầu xác thực mà không cần triển khai lại tác nhân vì kiến trúc gateway tách rời việc triển khai công cụ khỏi logic tác nhân—duy trì sự linh hoạt khi các yêu cầu kinh doanh phát triển.
d. AgentCore Observability giúp bạn theo dõi, gỡ lỗi và giám sát hiệu suất tác nhân trong môi trường sản xuất. Nó cung cấp khả năng hiển thị theo thời gian thực về hiệu suất hoạt động của tác nhân thông qua quyền truy cập vào các bảng điều khiển được hỗ trợ bởi Amazon CloudWatch và đo từ xa cho các chỉ số chính như số lượng phiên, độ trễ, thời lượng, mức sử dụng token và tỷ lệ lỗi, sử dụng tiêu chuẩn giao thức OpenTelemetry (OTEL). - Đánh giá LLM và tác nhân AI Khi các tác nhân AI được điều khiển bởi LLM đã được tinh chỉnh của bạn đang chạy trong sản xuất, điều quan trọng là phải liên tục đánh giá và giám sát các mô hình và tác nhân của bạn để đảm bảo chất lượng và hiệu suất cao. Nhiều trường hợp sử dụng doanh nghiệp yêu cầu các tiêu chí đánh giá tùy chỉnh mã hóa chuyên môn miền và các quy tắc kinh doanh. Đối với quy trình xác thực hướng dẫn thuốc của Amazon Pharmacy, các tiêu chí đánh giá bao gồm: độ chính xác phát hiện tương tác thuốc-thuốc (tỷ lệ phần trăm các chống chỉ định đã biết được xác định chính xác), độ chính xác tính toán liều lượng (điều chỉnh liều lượng chính xác cho tuổi, cân nặng và chức năng thận), tỷ lệ ngăn ngừa suýt xảy ra (giảm lỗi thuốc có thể gây hại cho bệnh nhân), tuân thủ nhãn FDA (tuân thủ việc sử dụng, cảnh báo và chống chỉ định đã được phê duyệt), và tỷ lệ dược sĩ ghi đè (tỷ lệ phần trăm các khuyến nghị của tác nhân được dược sĩ được cấp phép chấp nhận mà không sửa đổi). Đối với các mô hình của bạn trên Amazon Bedrock, bạn có thể sử dụng đánh giá Amazon Bedrock để tạo các chỉ số được xác định trước và quy trình xem xét của con người. Đối với các kịch bản nâng cao, bạn có thể sử dụng SageMaker Training jobs để tinh chỉnh các mô hình đánh giá chuyên biệt trên các tập dữ liệu đánh giá cụ thể theo miền. Để đánh giá tác nhân AI toàn diện, AgentCore Evaluations, ra mắt tại re:Invent 2025, cung cấp các công cụ đánh giá tự động để đo lường hiệu suất của tác nhân hoặc công cụ của bạn trong việc hoàn thành các tác vụ cụ thể, xử lý các trường hợp biên và duy trì tính nhất quán trên các đầu vào và ngữ cảnh khác nhau.
Hướng dẫn quyết định và cách tiếp cận theo giai đoạn được khuyến nghị
Bây giờ bạn đã hiểu sự phát triển kỹ thuật của các kỹ thuật tinh chỉnh nâng cao—từ SFT đến PPO, DPO, GRPO, DAPO và GSPO—câu hỏi quan trọng trở thành khi nào và tại sao bạn nên sử dụng chúng. Kinh nghiệm của chúng tôi cho thấy rằng các tổ chức sử dụng cách tiếp cận trưởng thành theo giai đoạn đạt được tỷ lệ chuyển đổi sản xuất 70–85% (so với mức trung bình ngành 30–40%) và tăng trưởng ROI gấp 3 lần theo năm. Hành trình 12–18 tháng từ triển khai tác nhân ban đầu đến khả năng suy luận nâng cao mang lại giá trị kinh doanh gia tăng ở mỗi giai đoạn. Điều quan trọng là để các yêu cầu trường hợp sử dụng, dữ liệu có sẵn và hiệu suất đo lường hướng dẫn sự tiến bộ—chứ không phải sự tinh vi kỹ thuật vì lợi ích của chính nó.
Con đường trưởng thành tiến triển qua bốn giai đoạn (được hiển thị trong bảng sau). Sự kiên nhẫn chiến lược trong quá trình này xây dựng cơ sở hạ tầng có thể tái sử dụng, thu thập dữ liệu huấn luyện chất lượng và xác thực ROI trước khi đầu tư lớn. Như các ví dụ của chúng tôi đã chứng minh, việc điều chỉnh sự tinh vi kỹ thuật với nhu cầu của con người và doanh nghiệp mang lại kết quả biến đổi và lợi thế cạnh tranh bền vững trong các ứng dụng AI quan trọng nhất của bạn.
| Giai đoạn | Thời gian | Khi nào nên sử dụng | Kết quả chính | Dữ liệu cần thiết | Đầu tư |
|---|---|---|---|---|---|
| Giai đoạn 1: Prompt engineering | 6–8 tuần | Bắt đầu hành trình tác nhân, Xác thực giá trị kinh doanh, Quy trình làm việc đơn giản | Độ chính xác 60–75%), Các mẫu lỗi được xác định | Prompt, ví dụ tối thiểu | 50K–80K USD (2–3 nhân viên toàn thời gian (FTE)) |
| Giai đoạn 2: Supervised Fine-Tuning (SFT) | 12 tuần | Khoảng trống kiến thức miền, Vấn đề thuật ngữ ngành, Cần độ chính xác 80-85% | Độ chính xác 80–85% giảm 60–80% công sức SME | 500–5.000 ví dụ được gắn nhãn | 120K–180K USD (3–4 FTE và tính toán) |
| Giai đoạn 3: Direct Preference Optimization (DPO) | 16 tuần | Điều chỉnh chất lượng/kiểu dáng, An toàn/tuân thủ quan trọng, Cần tính nhất quán thương hiệu | Độ chính xác 85–92%, CSAT trên 20% | 1.000–10.000 cặp ưu tiên | 180K–280K USD (4–5 FTE và tính toán) |
| Giai đoạn 4: GRPO và DAPO | 24 tuần | Yêu cầu suy luận phức tạp, Quyết định có rủi ro cao, Điều phối đa bước, Giải thích là cần thiết | Độ chính xác 95–98%, Triển khai nhiệm vụ quan trọng | Hơn 10.000 quỹ đạo suy luận | 400K-800K USD (6–8 FTE và HyperPod) |
Kết luận
Mặc dù các tác nhân đã thay đổi cách chúng ta xây dựng hệ thống AI, tinh chỉnh nâng cao vẫn là một thành phần quan trọng đối với các doanh nghiệp tìm kiếm lợi thế cạnh tranh trong các lĩnh vực có rủi ro cao. Bằng cách hiểu sự phát triển của các kỹ thuật như PPO, DPO, GRPO, DAPO và GSPO, và áp dụng chúng một cách chiến lược trong kiến trúc tác nhân, các tổ chức có thể đạt được những cải thiện đáng kể về độ chính xác, hiệu quả và an toàn. Các ví dụ thực tế từ Amazon chứng minh rằng sự kết hợp giữa quy trình làm việc tác nhân với các mô hình được tinh chỉnh cẩn thận mang lại kết quả kinh doanh ấn tượng.
AWS tiếp tục đẩy nhanh các khả năng này với một số lần ra mắt quan trọng tại re:Invent 2025. Reinforcement fine-tuning (RFT) trên Amazon Bedrock hiện cho phép các mô hình học các phản hồi chất lượng thông qua RLVR cho các tác vụ khách quan và RLAIF cho các đánh giá chủ quan—mà không yêu cầu lượng lớn dữ liệu được gắn nhãn trước. Amazon SageMaker AI Serverless Customization loại bỏ việc quản lý cơ sở hạ tầng để tinh chỉnh, hỗ trợ các kỹ thuật SFT, DPO và RLVR với giá trả theo token. Đối với huấn luyện quy mô lớn, Amazon SageMaker HyperPod đã giới thiệu checkpointless training và elastic scaling để giảm thời gian phục hồi và tối ưu hóa việc sử dụng tài nguyên. Amazon Nova Forge trao quyền cho các doanh nghiệp xây dựng các mô hình tiên phong tùy chỉnh từ các checkpoint ban đầu, kết hợp các tập dữ liệu độc quyền với dữ liệu huấn luyện được Amazon tuyển chọn. Cuối cùng, AgentCore Evaluation cung cấp các công cụ đánh giá tự động để đo lường hiệu suất tác nhân trong việc hoàn thành tác vụ, các trường hợp biên và tính nhất quán—hoàn thiện vòng lặp trên các hệ thống AI tác nhân cấp độ sản xuất.
Khi bạn đánh giá chiến lược AI tạo sinh của mình, hãy sử dụng hướng dẫn quyết định và cách tiếp cận trưởng thành theo giai đoạn được nêu trong bài viết này để xác định nơi tinh chỉnh nâng cao có thể thay đổi cán cân từ đủ tốt thành mang tính biến đổi. Sử dụng kiến trúc tham chiếu làm cơ sở để cấu trúc các hệ thống AI tác nhân của bạn, và sử dụng các khả năng được giới thiệu tại re:Invent 2025 để tăng tốc hành trình của bạn từ triển khai tác nhân ban đầu đến các kết quả cấp độ sản xuất.
Về tác giả

Yunfei Bai là Kiến trúc sư Giải pháp Chính tại AWS. Với nền tảng về AI/ML, khoa học dữ liệu và phân tích, Yunfei giúp khách hàng áp dụng các dịch vụ AWS để mang lại kết quả kinh doanh. Anh thiết kế các giải pháp AI/ML và phân tích dữ liệu vượt qua các thách thức kỹ thuật phức tạp và thúc đẩy các mục tiêu chiến lược. Yunfei có bằng Tiến sĩ Kỹ thuật Điện tử và Điện. Ngoài công việc, Yunfei thích đọc sách và âm nhạc.

Kristine Pearce là Chuyên gia GTM AI tạo sinh Toàn cầu Chính tại AWS, tập trung vào tùy chỉnh, tối ưu hóa và suy luận mô hình SageMaker AI ở quy mô lớn. Cô kết hợp bằng MBA, nền tảng Kỹ thuật Công nghiệp và chuyên môn thiết kế lấy con người làm trung tâm để mang lại chiều sâu chiến lược và khoa học hành vi cho chuyển đổi được hỗ trợ bởi AI. Ngoài công việc, cô thể hiện sự sáng tạo của mình thông qua nghệ thuật.

Harsh Asnani là Kiến trúc sư Giải pháp Chuyên gia AI tạo sinh Toàn cầu tại AWS chuyên về lý thuyết ML, MLOPs và các framework AI tạo sinh sản xuất. Nền tảng của anh là khoa học dữ liệu ứng dụng với trọng tâm là vận hành khối lượng công việc AI trên đám mây ở quy mô lớn.

Sung-Ching Lin là Kỹ sư Chính tại Amazon Pharmacy, nơi anh dẫn đầu việc thiết kế và áp dụng các hệ thống AI/ML để cải thiện trải nghiệm khách hàng và hiệu quả hoạt động. Anh tập trung vào việc xây dựng các kiến trúc dựa trên tác nhân có khả năng mở rộng, các framework đánh giá ML và các giải pháp AI sẵn sàng sản xuất trong các lĩnh vực chăm sóc sức khỏe được quản lý.

Elad Dwek là Nhà phát triển Kinh doanh AI cấp cao tại Amazon, làm việc trong Global Engineering, Maintenance, and Sustainability. Anh hợp tác với các bên liên quan từ phía kinh doanh và công nghệ để xác định các cơ hội mà AI có thể tăng cường các thách thức kinh doanh hoặc chuyển đổi hoàn toàn các quy trình, thúc đẩy đổi mới từ tạo mẫu đến sản xuất. Với nền tảng về xây dựng và kỹ thuật vật lý, anh tập trung vào quản lý thay đổi, áp dụng công nghệ và xây dựng các giải pháp có khả năng mở rộng, có thể chuyển giao mang lại cải tiến liên tục trên các ngành. Ngoài công việc, anh thích đi du lịch vòng quanh thế giới cùng gia đình.

Carrie Song là Quản lý Chương trình cấp cao tại Amazon, làm việc về chất lượng nội dung và các sáng kiến trải nghiệm khách hàng được hỗ trợ bởi AI. Cô hợp tác với các nhóm khoa học ứng dụng, kỹ thuật và UX để chuyển đổi các hiểu biết sâu sắc về AI tạo sinh và học máy thành các giải pháp có khả năng mở rộng, hướng tới khách hàng. Công việc của cô tập trung vào việc cải thiện chất lượng nội dung và hợp lý hóa trải nghiệm mua sắm trên các trang chi tiết sản phẩm.
