Tác giả: Dani Mitchell, Jean-Pierre Dodel, và Pallavi Nargund
Ngày phát hành: 20 JAN 2026
Chuyên mục: Amazon Bedrock, Amazon Bedrock Knowledge Bases, Announcements, Artificial Intelligence
Chúng tôi vui mừng thông báo về việc ra mắt rộng rãi tính năng truy xuất đa phương thức (multimodal retrieval) cho Amazon Bedrock Knowledge Bases. Khả năng mới này bổ sung hỗ trợ gốc cho nội dung video và âm thanh, bên cạnh văn bản và hình ảnh. Với tính năng này, bạn có thể xây dựng các ứng dụng Retrieval Augmented Generation (RAG) có khả năng tìm kiếm và truy xuất thông tin trên văn bản, hình ảnh, âm thanh và video—tất cả trong một dịch vụ được quản lý hoàn toàn.
Các doanh nghiệp hiện đại lưu trữ thông tin giá trị dưới nhiều định dạng. Tài liệu sản phẩm bao gồm sơ đồ và ảnh chụp màn hình, tài liệu đào tạo chứa video hướng dẫn, và thông tin chi tiết về khách hàng được ghi lại trong các cuộc họp. Cho đến nay, việc xây dựng các ứng dụng trí tuệ nhân tạo (AI) có thể tìm kiếm hiệu quả trên các loại nội dung này đòi hỏi cơ sở hạ tầng tùy chỉnh phức tạp và nỗ lực kỹ thuật đáng kể.
Trước đây, Bedrock Knowledge Bases sử dụng các mô hình nhúng dựa trên văn bản (text-based embedding models) để truy xuất. Mặc dù nó hỗ trợ tài liệu văn bản và hình ảnh, nhưng hình ảnh phải được xử lý bằng các foundation models (FM) hoặc Bedrock Data Automation để tạo mô tả văn bản—một phương pháp ưu tiên văn bản (text-first approach) làm mất ngữ cảnh hình ảnh và ngăn chặn khả năng tìm kiếm bằng hình ảnh. Video và âm thanh yêu cầu các pipeline tiền xử lý tùy chỉnh bên ngoài. Giờ đây, với multimodal embeddings, bộ truy xuất hỗ trợ gốc văn bản, hình ảnh, âm thanh và video trong một mô hình nhúng duy nhất.
Với tính năng truy xuất đa phương thức trong Bedrock Knowledge Bases, giờ đây bạn có thể nhập, lập chỉ mục và truy xuất thông tin từ văn bản, hình ảnh, video và âm thanh bằng một quy trình làm việc thống nhất duy nhất. Nội dung được mã hóa bằng multimodal embeddings giúp bảo toàn ngữ cảnh hình ảnh và âm thanh, cho phép các ứng dụng của bạn tìm thấy thông tin liên quan trên các loại phương tiện. Bạn thậm chí có thể tìm kiếm bằng hình ảnh để tìm nội dung tương tự về mặt hình ảnh hoặc định vị các cảnh cụ thể trong video.
Trong bài viết này, chúng tôi sẽ hướng dẫn bạn xây dựng các ứng dụng RAG đa phương thức. Bạn sẽ tìm hiểu cách hoạt động của các knowledge bases đa phương thức, cách chọn chiến lược xử lý phù hợp dựa trên loại nội dung của bạn, và cách cấu hình cũng như triển khai truy xuất đa phương thức bằng cả console và các ví dụ mã.
Tìm hiểu về các knowledge bases đa phương thức
Amazon Bedrock Knowledge Bases tự động hóa toàn bộ quy trình làm việc RAG: nhập nội dung từ các data sources của bạn, phân tích cú pháp và chia nhỏ thành các phân đoạn có thể tìm kiếm, chuyển đổi các chunk thành vector embeddings, và lưu trữ chúng trong một vector database. Trong quá trình truy xuất, các truy vấn của người dùng được nhúng và so khớp với các vector đã lưu trữ để tìm nội dung tương tự về mặt ngữ nghĩa, từ đó bổ sung cho prompt được gửi đến foundation model của bạn.
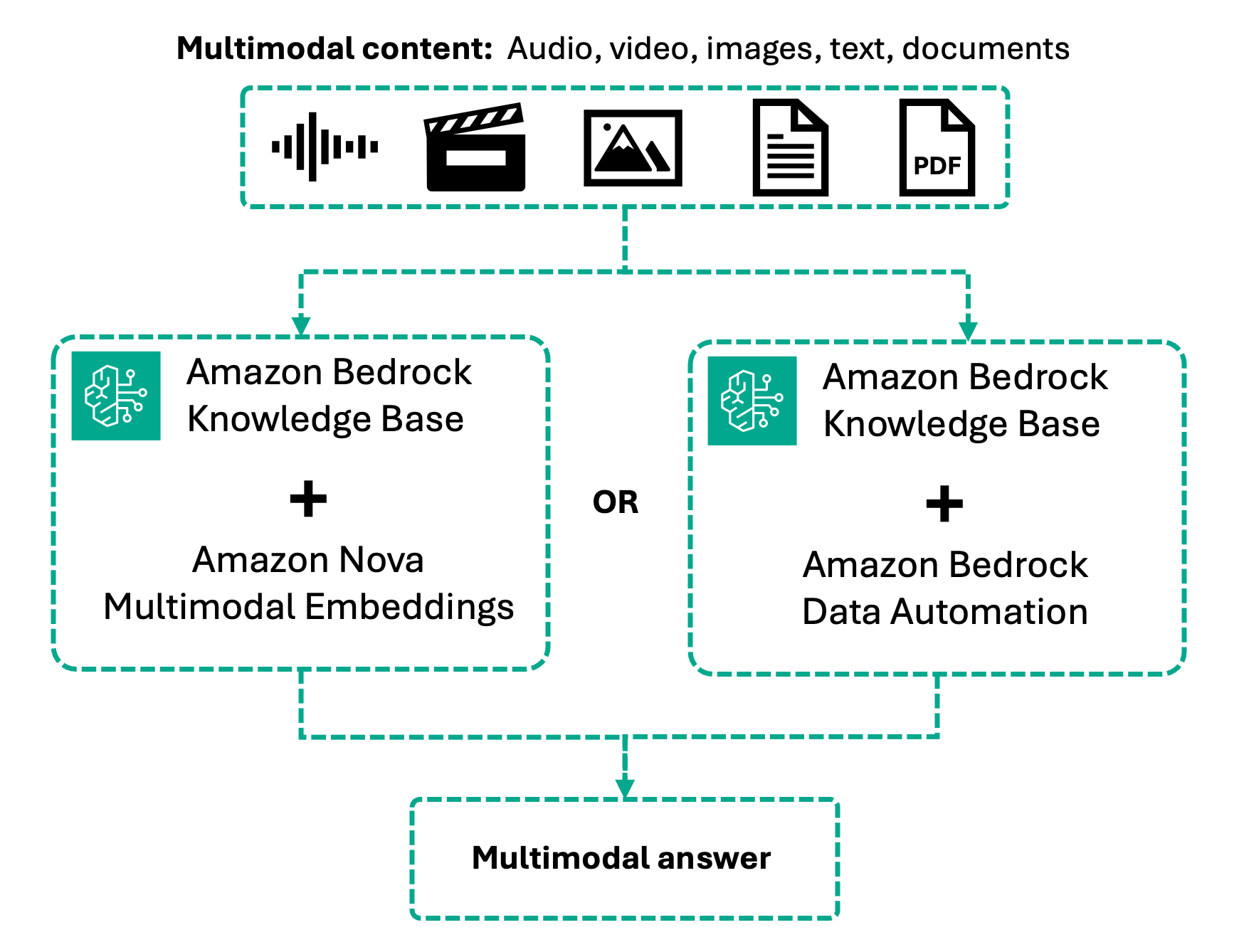
Với tính năng truy xuất đa phương thức, quy trình làm việc này giờ đây xử lý hình ảnh, video và âm thanh cùng với văn bản thông qua hai phương pháp xử lý. Amazon Nova Multimodal Embeddings mã hóa nội dung gốc vào một unified vector space, cho phép truy xuất đa phương thức (cross-modal retrieval) nơi bạn có thể truy vấn bằng văn bản và truy xuất video, hoặc tìm kiếm bằng hình ảnh để tìm nội dung trực quan.
Thay vào đó, Bedrock Data Automation chuyển đổi nội dung đa phương tiện thành các mô tả văn bản phong phú và bản ghi trước khi nhúng, cung cấp khả năng truy xuất độ chính xác cao trên nội dung nói. Lựa chọn của bạn phụ thuộc vào việc ngữ cảnh hình ảnh hay độ chính xác của lời nói quan trọng hơn đối với use case của bạn.
Chúng tôi sẽ khám phá từng phương pháp này trong bài viết này.
Amazon Nova Multimodal Embeddings
Amazon Nova Multimodal Embeddings là mô hình nhúng thống nhất đầu tiên mã hóa văn bản, tài liệu, hình ảnh, video và âm thanh vào một shared vector space duy nhất. Nội dung được xử lý gốc mà không cần chuyển đổi văn bản. Mô hình hỗ trợ tới 8.172 token cho văn bản và 30 giây cho các phân đoạn video/âm thanh, xử lý hơn 200 ngôn ngữ và cung cấp bốn embedding dimensions (với 3072-dimension là mặc định, 1.024, 384, 256) để cân bằng độ chính xác và hiệu quả. Bedrock Knowledge Bases tự động phân đoạn video và âm thanh thành các chunk có thể cấu hình (5-30 giây), với mỗi phân đoạn được nhúng độc lập.
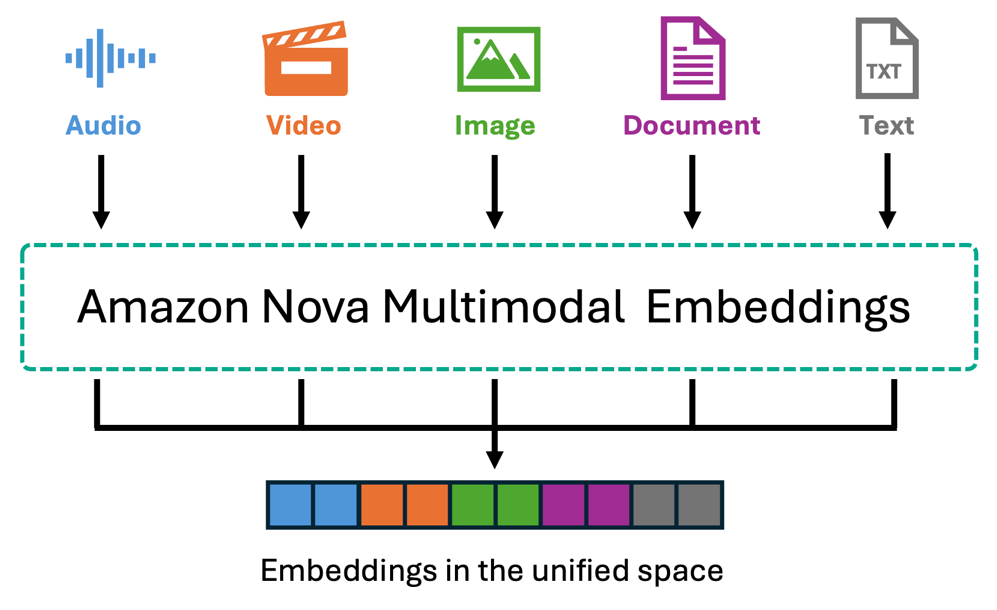
Đối với nội dung video, Nova embeddings thu thập các yếu tố hình ảnh—cảnh, đối tượng, chuyển động và hành động—cũng như các đặc điểm âm thanh như nhạc, âm thanh và tiếng ồn môi trường. Đối với các video mà lời thoại nói là quan trọng đối với use case của bạn, bạn có thể sử dụng Bedrock Data Automation để trích xuất bản ghi cùng với mô tả hình ảnh. Đối với các tệp âm thanh độc lập, Nova xử lý các tính năng âm thanh như nhạc, âm thanh môi trường và các mẫu âm thanh. Khả năng cross-modal cho phép các use case như mô tả một cảnh hình ảnh bằng văn bản để truy xuất các video phù hợp, tải lên một reference image để tìm các sản phẩm tương tự, hoặc định vị các hành động cụ thể trong cảnh quay—tất cả mà không cần mô tả văn bản có sẵn.
Tốt nhất cho: Product catalogs, visual search, video sản xuất, cảnh quay thể thao, camera an ninh, và các kịch bản mà nội dung hình ảnh là yếu tố chính thúc đẩy use case.
Amazon Bedrock Data Automation
Bedrock Data Automation áp dụng một phương pháp khác bằng cách chuyển đổi nội dung đa phương tiện thành các biểu diễn văn bản phong phú trước khi nhúng. Đối với hình ảnh, nó tạo ra các mô tả chi tiết bao gồm đối tượng, cảnh, văn bản trong hình ảnh và mối quan hệ không gian. Đối với video, nó tạo ra các bản tóm tắt từng cảnh, xác định các yếu tố hình ảnh chính và trích xuất văn bản trên màn hình. Đối với âm thanh và video có lời nói, Bedrock Data Automation cung cấp các bản ghi chính xác với timestamps và nhận dạng người nói, cùng với các bản tóm tắt phân đoạn nắm bắt các điểm chính đã thảo luận.
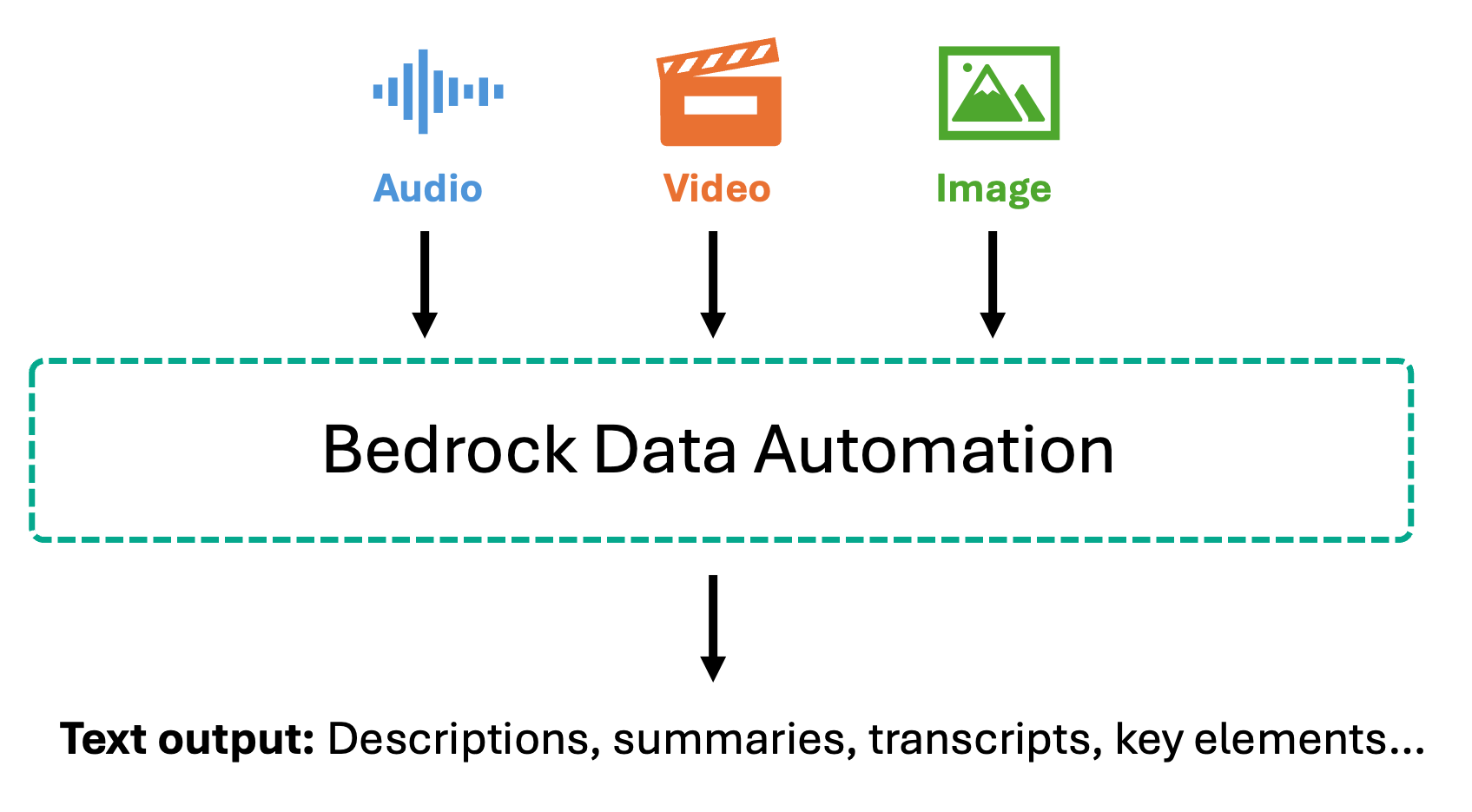
Sau khi được chuyển đổi thành văn bản, nội dung này được chia thành các chunk và nhúng bằng cách sử dụng các text embedding models như Amazon Titan Text Embeddings hoặc Amazon Nova Multimodal Embeddings. Phương pháp ưu tiên văn bản này cho phép trả lời câu hỏi với độ chính xác cao trên nội dung nói—khi người dùng hỏi về các specific statements được đưa ra trong một cuộc họp hoặc các topics discussed trong một podcast, hệ thống sẽ tìm kiếm thông qua các precise transcripts thay vì audio embeddings. Điều này làm cho nó đặc biệt có giá trị cho các compliance scenarios nơi bạn cần exact quotes và verbatim records cho audit trails, meeting analysis, customer support call mining, và các use cases nơi bạn cần truy xuất và xác minh specific spoken information.
Tốt nhất cho: Các cuộc họp, webinar, phỏng vấn, podcast, video đào tạo, cuộc gọi hỗ trợ, và các kịch bản yêu cầu truy xuất chính xác các specific statements hoặc discussions.
Kịch bản use case: Tìm kiếm sản phẩm trực quan cho thương mại điện tử
Các knowledge bases đa phương thức có thể được sử dụng cho các ứng dụng từ nâng cao trải nghiệm khách hàng và đào tạo nhân viên đến các hoạt động bảo trì và phân tích pháp lý. Tìm kiếm thương mại điện tử truyền thống dựa vào text queries, yêu cầu khách hàng phải diễn đạt những gì họ đang tìm kiếm bằng các keywords phù hợp. Điều này trở nên khó khăn khi họ đã thấy một sản phẩm ở nơi khác, có một bức ảnh về thứ họ thích, hoặc muốn tìm các items tương tự với những gì xuất hiện trong một video. Giờ đây, khách hàng có thể tìm kiếm product catalog của bạn bằng cách sử dụng text descriptions, tải lên một image của một item họ đã chụp, hoặc tham chiếu một scene từ một video để tìm các sản phẩm phù hợp. Hệ thống truy xuất các items tương tự về mặt hình ảnh bằng cách so sánh embedded representation của truy vấn của họ—cho dù là văn bản, hình ảnh hay video—với multimodal embeddings của product inventory của bạn. Đối với kịch bản này, Amazon Nova Multimodal Embeddings là lựa chọn lý tưởng. Khám phá sản phẩm về cơ bản là trực quan—khách hàng quan tâm đến màu sắc, kiểu dáng, hình dạng và các visual details. Bằng cách mã hóa product images và video của bạn vào Nova unified vector space, hệ thống sẽ khớp dựa trên visual similarity mà không cần dựa vào text descriptions có thể bỏ lỡ các visual characteristics tinh tế. Mặc dù một recommendation system hoàn chỉnh sẽ kết hợp customer preferences, purchase history và inventory availability, nhưng việc truy xuất từ một multimodal knowledge base cung cấp foundational capability: tìm kiếm các sản phẩm phù hợp về mặt hình ảnh bất kể khách hàng chọn cách tìm kiếm như thế nào.
Hướng dẫn sử dụng Console
Trong phần sau, chúng tôi sẽ hướng dẫn bạn các high-level steps để thiết lập và kiểm tra một multimodal knowledge base cho ví dụ tìm kiếm sản phẩm thương mại điện tử của chúng tôi. Chúng tôi sẽ tạo một knowledge base chứa smartphone product images và video, sau đó trình bày cách khách hàng có thể tìm kiếm bằng cách sử dụng text descriptions, uploaded images hoặc video references. GitHub repository cung cấp một guided notebook mà bạn có thể làm theo để deploy ví dụ này trong account của mình.
Điều kiện tiên quyết
Trước khi bắt đầu, hãy đảm bảo bạn có các điều kiện tiên quyết sau:
- Một AWS Account với service access phù hợp
- Một AWS Identity and Access Management (IAM) role với các permissions phù hợp để truy cập Amazon Bedrock và Amazon Simple Storage Service (Amazon S3)
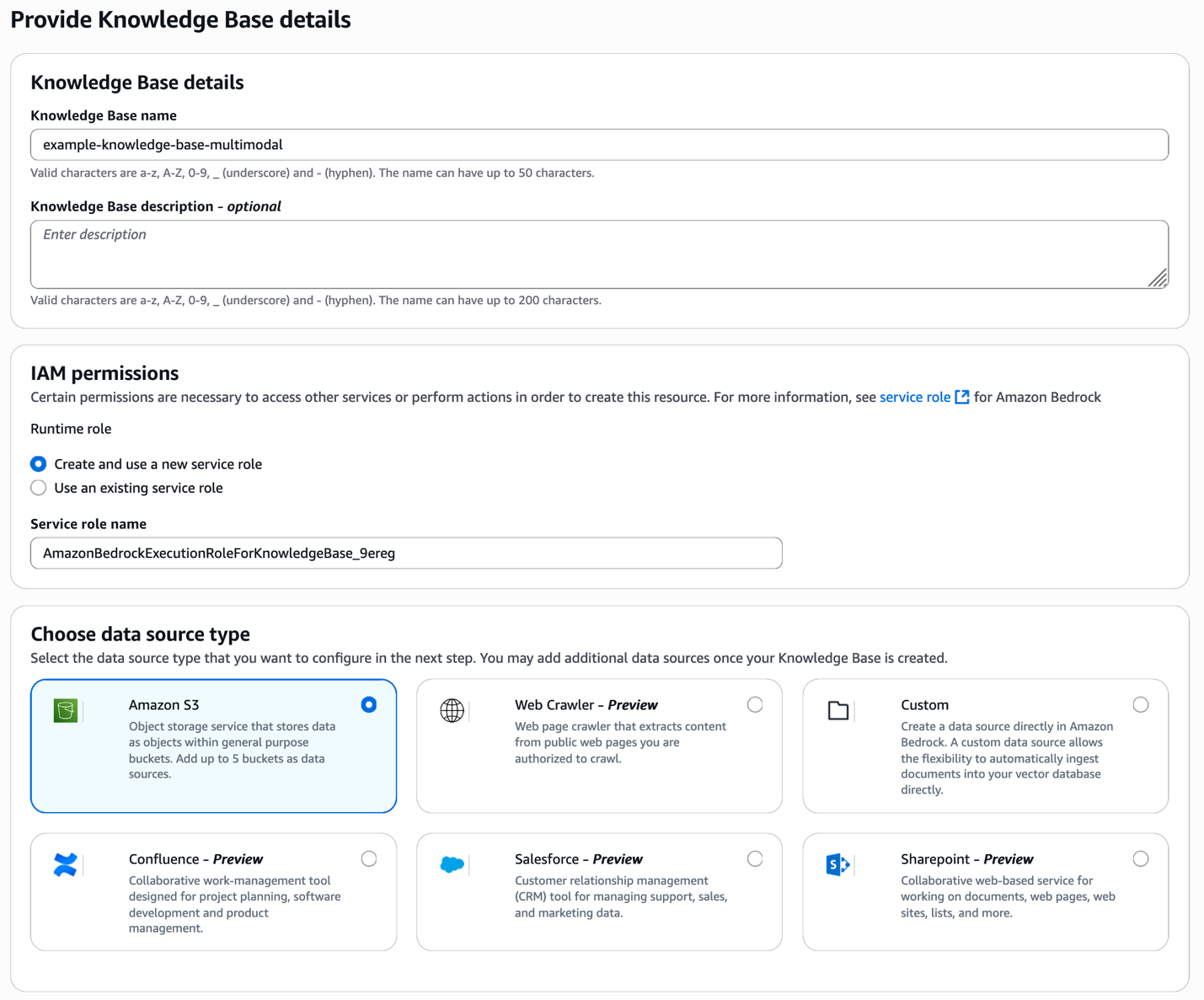
Cung cấp chi tiết knowledge base và loại data source
Bắt đầu bằng cách mở Amazon Bedrock console và tạo một knowledge base mới. Cung cấp một descriptive name cho knowledge base của bạn và chọn data source type của bạn—trong trường hợp này là Amazon S3 nơi lưu trữ product images và video của bạn.
Cấu hình data source
Kết nối S3 bucket của bạn chứa product images và video. Đối với parsing strategy, chọn Amazon Bedrock default parser. Vì chúng tôi đang sử dụng Nova Multimodal Embeddings, các hình ảnh và video được xử lý gốc và nhúng trực tiếp vào unified vector space, bảo toàn visual characteristics của chúng mà không cần chuyển đổi thành văn bản.
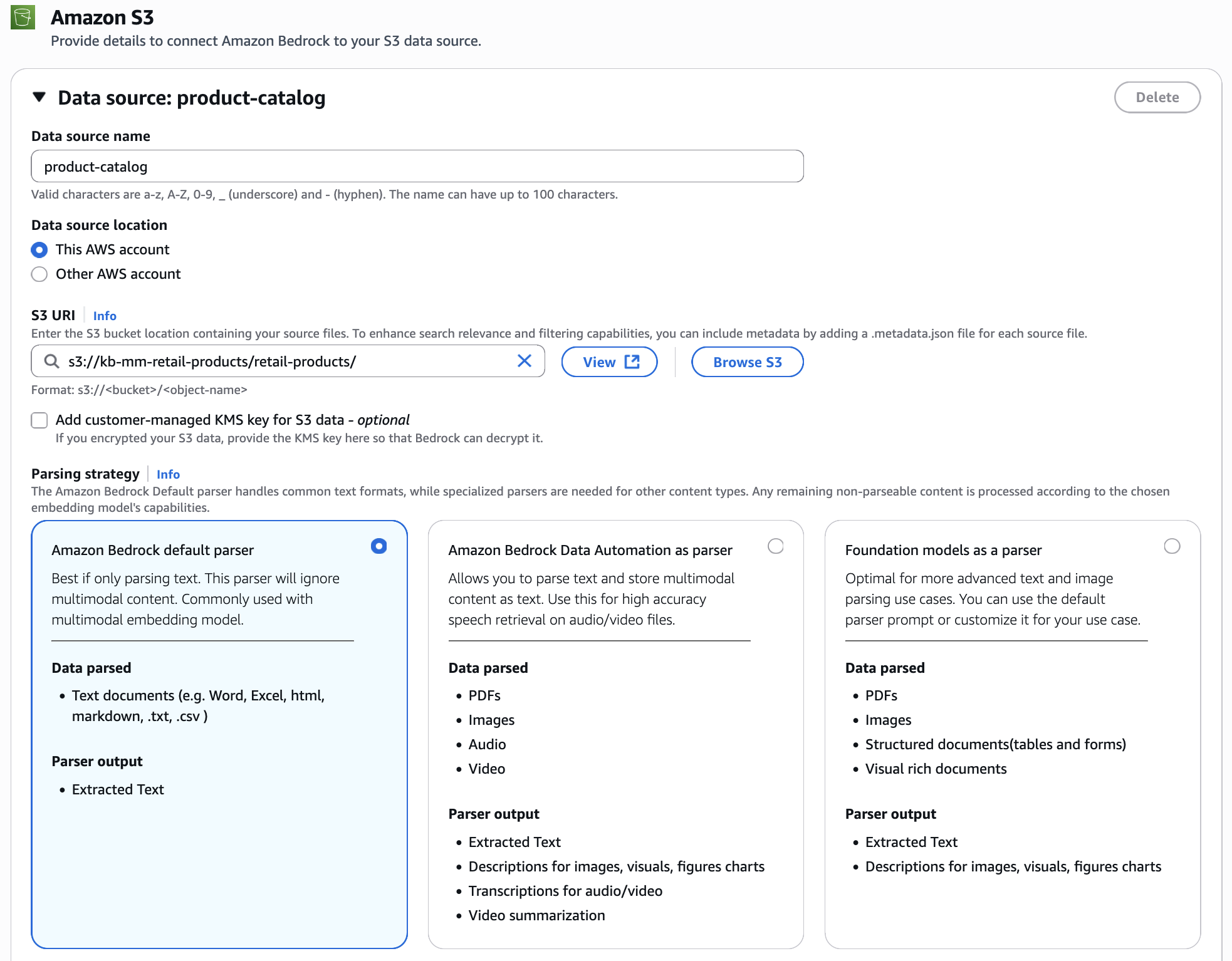
Cấu hình lưu trữ và xử lý dữ liệu
Chọn Amazon Nova Multimodal Embeddings làm embedding model của bạn. Embedding model thống nhất này mã hóa cả product images và customer queries của bạn vào cùng một vector space, cho phép cross-modal retrieval nơi text queries có thể truy xuất hình ảnh và image queries có thể tìm thấy các sản phẩm tương tự về mặt hình ảnh. Đối với ví dụ này, chúng tôi sử dụng Amazon S3 Vectors làm vector store (bạn có thể tùy chọn sử dụng các vector stores khác có sẵn), cung cấp durable storage hiệu quả về chi phí và được tối ưu hóa cho các large-scale vector data sets trong khi vẫn duy trì sub-second query performance. Bạn cũng cần cấu hình multimodal storage destination bằng cách chỉ định một S3 location. Knowledge Bases sử dụng location này để lưu trữ extracted images và các media khác từ data source của bạn. Khi người dùng query knowledge base, relevant media được truy xuất từ storage này.
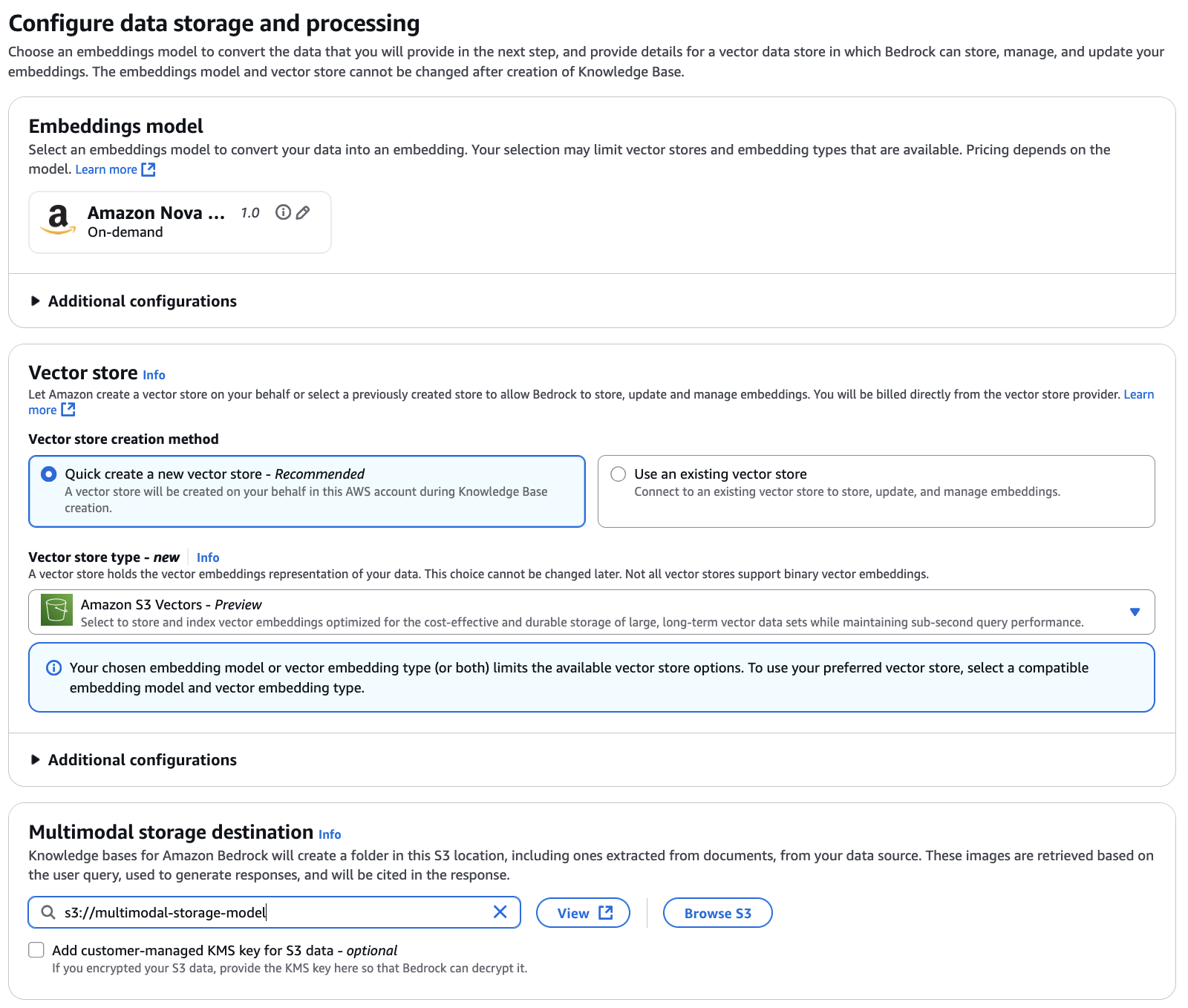
Xem xét và tạo
Xem lại các configuration settings của bạn bao gồm knowledge base details, data source configuration, embedding model selection—chúng tôi đang sử dụng Amazon Nova Multimodal Embeddings v1 với 3072 vector dimensions (dimensions cao hơn cung cấp richer representations; bạn có thể sử dụng dimensions thấp hơn như 1.024, 384 hoặc 256 để optimize cho storage và cost)—và vector store setup (Amazon S3 Vectors). Khi mọi thứ đã chính xác, hãy tạo knowledge base của bạn.
Tạo một ingestion job
Sau khi tạo, khởi tạo sync process để ingest product catalog của bạn. Knowledge base xử lý từng hình ảnh và video, tạo ra embeddings và lưu trữ chúng trong managed vector database. Giám sát sync status để xác nhận các documents đã được indexed thành công.
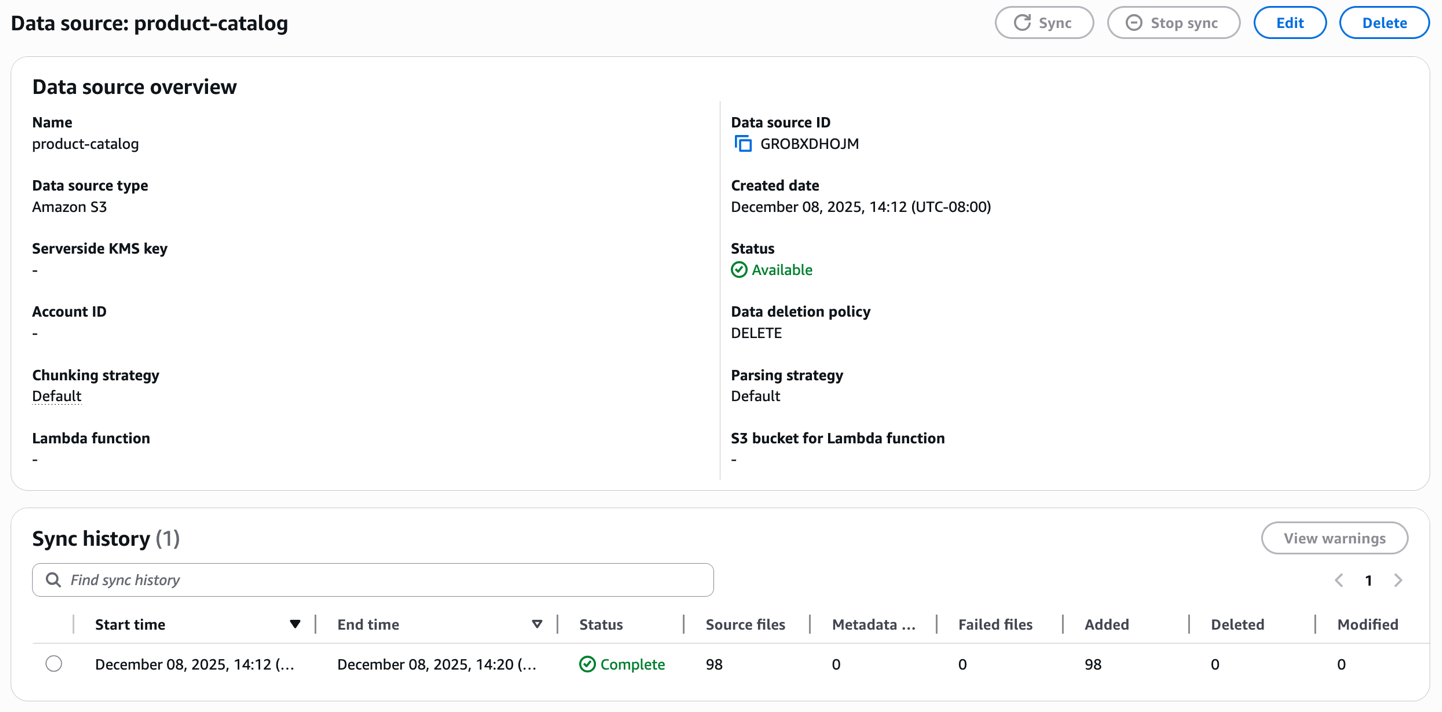
Kiểm tra knowledge base bằng cách sử dụng văn bản làm input trong prompt của bạn
Với knowledge base đã sẵn sàng, hãy kiểm tra nó bằng cách sử dụng một text query trong console. Tìm kiếm với product descriptions như “A metallic phone cover” (hoặc bất kỳ thứ gì tương đương có thể liên quan đến products media của bạn) để xác minh rằng text-based retrieval hoạt động chính xác trên toàn bộ catalog của bạn.

Kiểm tra knowledge base bằng cách sử dụng reference image và truy xuất các modalities khác nhau
Bây giờ là phần mạnh mẽ—visual search. Tải lên một reference image của một sản phẩm bạn muốn tìm. Ví dụ, hãy tưởng tượng bạn thấy một cell phone cover trên một website khác và muốn tìm các similar items trong catalog của bạn. Đơn giản chỉ cần tải lên hình ảnh mà không cần additional text prompt.
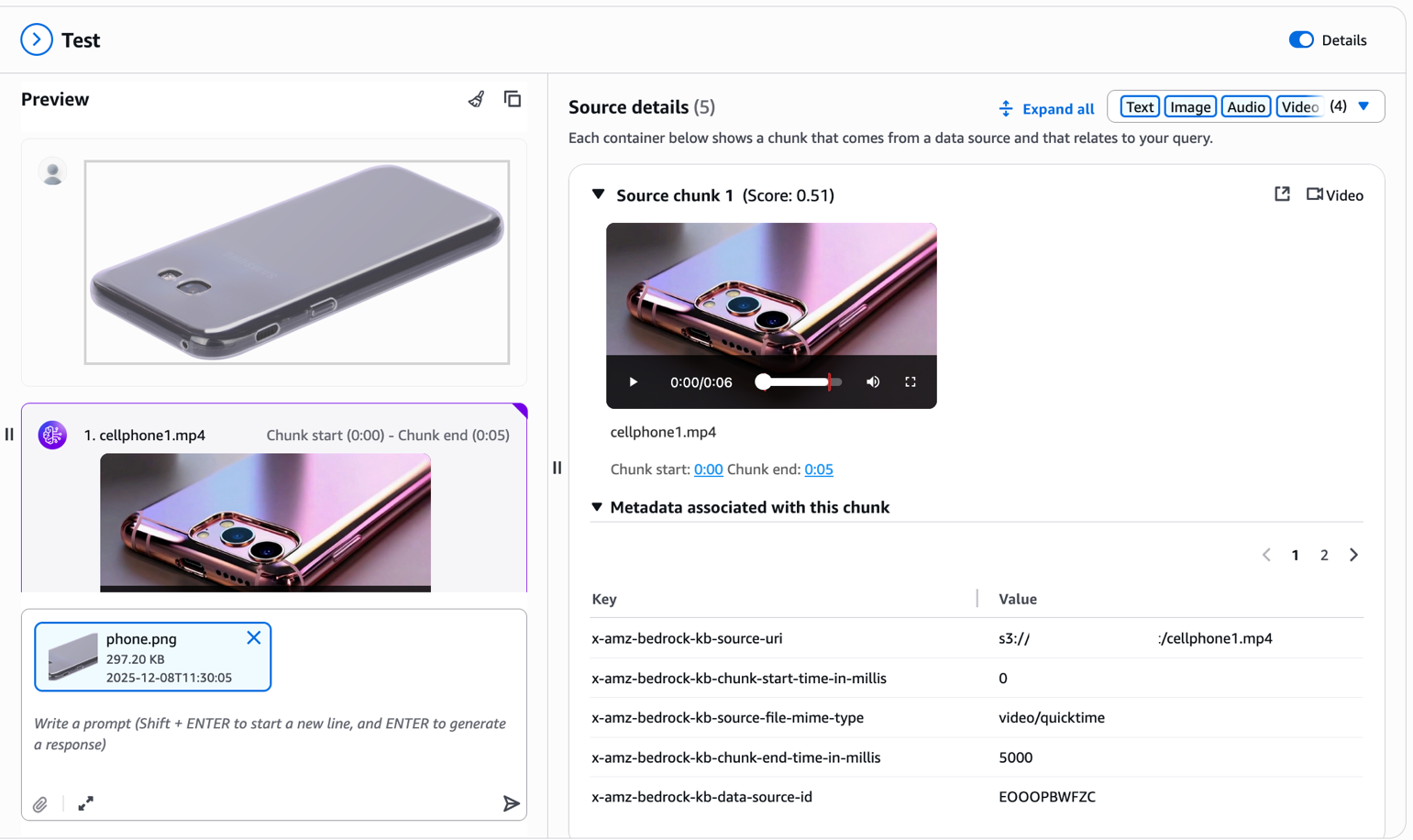
Multimodal knowledge base trích xuất visual features từ uploaded image của bạn và truy xuất các sản phẩm tương tự về mặt hình ảnh từ catalog của bạn. Như bạn có thể thấy trong kết quả, hệ thống trả về các phone covers với similar design patterns, colors, hoặc visual characteristics. Lưu ý metadata liên quan đến mỗi chunk trong bảng điều khiển Source details. Các trường x-amz-bedrock-kb-chunk-start-time-in-millis và x-amz-bedrock-kb-chunk-end-time-in-millis cho biết temporal location chính xác của phân đoạn này trong source video. Khi xây dựng các ứng dụng theo chương trình, bạn có thể sử dụng các timestamps này để trích xuất và hiển thị specific video segment khớp với query, cho phép các tính năng như “jump to relevant moment” hoặc clip generation trực tiếp từ source videos của bạn. Khả năng cross-modal này biến đổi shopping experience—khách hàng không còn cần mô tả những gì họ đang tìm kiếm bằng lời nói; họ có thể cho bạn xem.
Kiểm tra knowledge base bằng cách sử dụng reference image và truy xuất các modalities khác nhau bằng Bedrock Data Automation
Bây giờ chúng ta hãy xem kết quả sẽ như thế nào nếu bạn cấu hình Bedrock Data Automation parsing trong quá trình data source setup. Trong ảnh chụp màn hình sau, hãy chú ý đến phần transcript trong bảng điều khiển Source details.
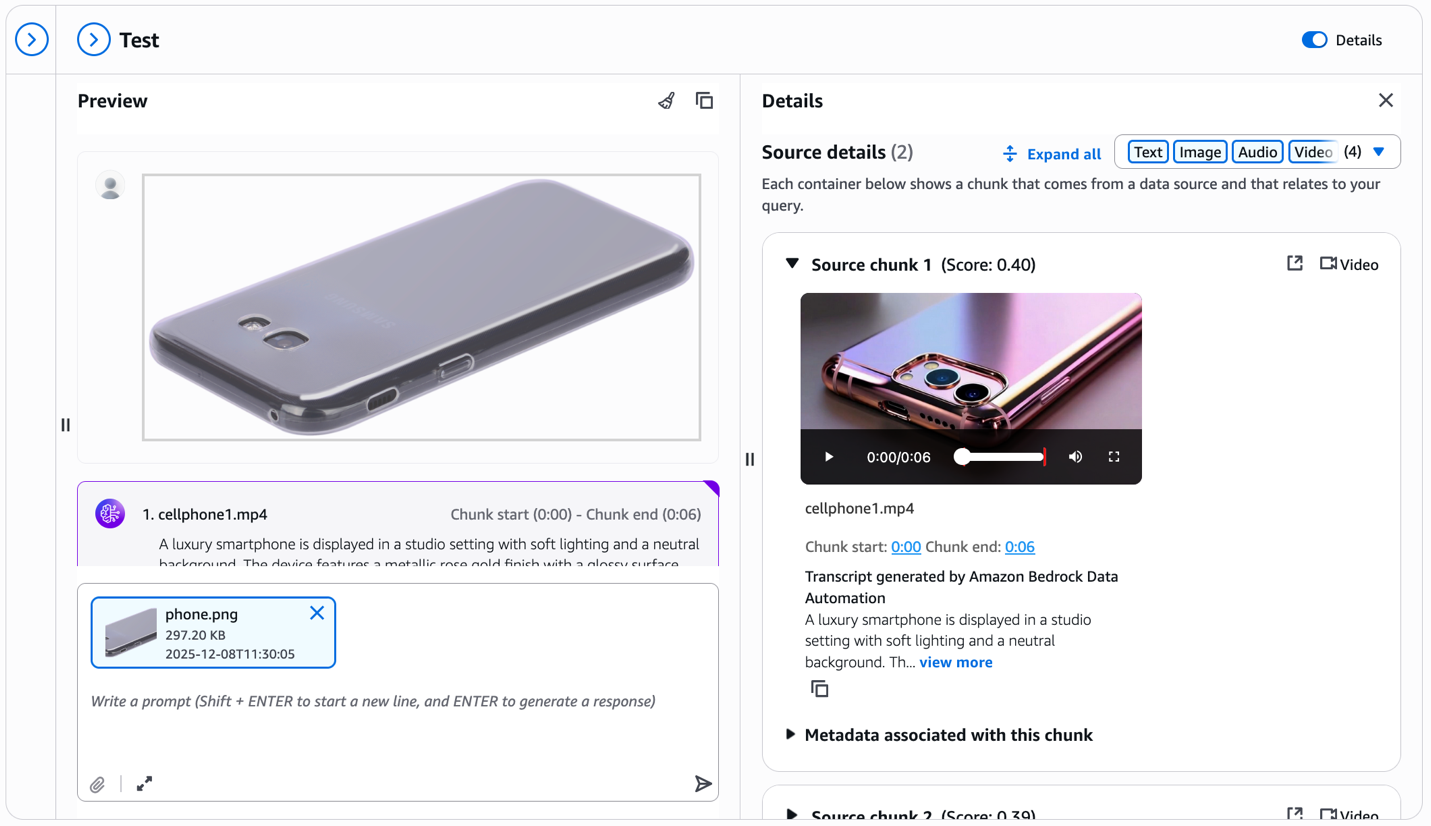
Đối với mỗi retrieved video chunk, Bedrock Data Automation tự động tạo ra một detailed text description—trong ví dụ này, mô tả lớp hoàn thiện màu vàng hồng kim loại của smartphone, studio lighting và visual characteristics. Transcript này xuất hiện trực tiếp trong test window cùng với video, cung cấp rich textual context. Bạn nhận được cả visual similarities khớp từ multimodal embeddings và detailed product descriptions có thể trả lời specific questions về features, colors, materials và các attributes khác có thể nhìn thấy trong video.
Dọn dẹp
Để clean up các resources của bạn, hãy hoàn thành các bước sau, bắt đầu bằng việc xóa knowledge base:
- Trên Amazon Bedrock console, chọn Knowledge Bases
- Chọn Knowledge Base của bạn và ghi lại cả IAM service role name và S3 Vector index ARN
- Chọn Delete và xác nhận
Để xóa S3 Vector làm vector store, hãy sử dụng các lệnh AWS Command Line Interface (AWS CLI) sau:
aws s3vectors delete-index --vector-bucket-name YOUR_VECTOR_BUCKET_NAME --index-name YOUR_INDEX_NAME --region YOUR_REGIONaws s3vectors delete-vector-bucket --vector-bucket-name YOUR_VECTOR_BUCKET_NAME --region YOUR_REGION
- Trên IAM console, tìm role đã ghi chú trước đó
- Chọn và xóa role
Để xóa sample dataset:
- Trên Amazon S3 console, tìm S3 bucket của bạn
- Chọn và xóa các files bạn đã uploaded cho tutorial này
Kết luận
Multimodal retrieval cho Amazon Bedrock Knowledge Bases loại bỏ sự phức tạp trong việc xây dựng các ứng dụng RAG bao gồm văn bản, hình ảnh, video và âm thanh. Với hỗ trợ gốc cho nội dung video và âm thanh, giờ đây bạn có thể xây dựng các comprehensive knowledge bases giúp khai thác insights từ enterprise data của bạn—không chỉ là text documents.
Lựa chọn giữa Amazon Nova Multimodal Embeddings và Bedrock Data Automation mang lại cho bạn flexibility để optimize cho specific content của bạn. Nova unified vector space cho phép cross-modal retrieval cho các visual-driven use cases, trong khi phương pháp ưu tiên văn bản của Bedrock Data Automation mang lại precise transcription-based retrieval cho speech-heavy content. Cả hai phương pháp đều tích hợp seamlessly vào cùng một fully managed workflow, giảm bớt nhu cầu về custom preprocessing pipelines.
Khả dụng
Region availability phụ thuộc vào các features được chọn để hỗ trợ đa phương thức, vui lòng tham khảo documentation để biết chi tiết.
Các bước tiếp theo
Bắt đầu với multimodal retrieval ngay hôm nay:
- Khám phá tài liệu: Xem lại tài liệu Amazon Bedrock Knowledge Bases và Hướng dẫn sử dụng Amazon Nova để biết thêm technical details.
- Thử nghiệm với các ví dụ mã: Kiểm tra Amazon Bedrock samples repository để có các hands-on notebooks minh họa multimodal retrieval.
- Tìm hiểu thêm về Nova: Đọc thông báo Amazon Nova Multimodal Embeddings để có deeper technical insights.
Về tác giả

Dani Mitchell là Kiến trúc sư Giải pháp Chuyên gia AI Tạo sinh (Generative AI Specialist Solutions Architect) tại Amazon Web Services (AWS). Anh tập trung vào việc giúp các doanh nghiệp trên toàn thế giới tăng tốc hành trình AI tạo sinh của họ với Amazon Bedrock và Bedrock AgentCore.

Pallavi Nargund là Kiến trúc sư Giải pháp Chính (Principal Solutions Architect) tại AWS. Cô là trưởng nhóm AI tạo sinh cho US Greenfield và dẫn dắt nhóm AWS for Legal Tech. Cô đam mê phụ nữ trong công nghệ và là thành viên cốt lõi của Women in AI/ML tại Amazon. Cô thường phát biểu tại các hội nghị nội bộ và bên ngoài như AWS re:Invent, AWS Summits và các webinar. Pallavi có bằng Cử nhân Kỹ thuật từ Đại học Pune, Ấn Độ. Cô sống ở Edison, New Jersey, cùng chồng, hai con gái và hai chú chó của mình.

Jean-Pierre Dodel là Giám đốc Sản phẩm Chính (Principal Product Manager) cho Amazon Bedrock, Amazon Kendra và Amazon Quick Index. Anh mang 15 năm kinh nghiệm về Enterprise Search và AI/ML đến với nhóm, với kinh nghiệm làm việc trước đây tại Autonomy, HP và các startup tìm kiếm trước khi gia nhập Amazon 8 năm trước. JP hiện đang tập trung vào các đổi mới cho multimodal RAG, agentic retrieval và structured RAG.
