Tác giả: Harish Suvarna, Alec Ngo, Mark Azadpour, Suryanarayana Murthy Boddu, và Yoginder Sethi
Ngày phát hành: 20 JAN 2026
Chuyên mục: AWS Batch, Customer Solutions, High Performance Computing
Bài viết này được đóng góp bởi Harish Suvarna, Alec Ngo, và Suryanarayana Murthy Boddu từ Adobe, cùng Mark Azadpour, Yoginder Sethi từ AWS.
Adobe trao quyền cho mọi người ở mọi nơi để hình dung, sáng tạo và biến mọi trải nghiệm kỹ thuật số thành hiện thực. Với hơn 29 tỷ tài sản được tạo ra bằng Adobe Firefly và một hệ sinh thái Adobe Stock rộng lớn, khả năng tìm kiếm và khám phá hình ảnh hoặc video liên quan ở quy mô lớn là rất quan trọng.
Để đạt được điều này ở quy mô của Adobe đi kèm với các yêu cầu kỹ thuật phức tạp: chạy các mô hình AI xử lý hàng trăm triệu tài sản, quản lý hàng nghìn công việc suy luận song song và đảm bảo GPU được sử dụng tối đa mà không phá vỡ hiệu quả chi phí. Việc đáp ứng những thách thức này đòi hỏi một cơ sở hạ tầng có thể xử lý thông lượng dữ liệu khổng lồ, mở rộng linh hoạt và giảm thiểu chi phí vận hành.
Trong bài viết này, chúng tôi sẽ chia sẻ cách nhóm Adobe SDC đã giải quyết những thách thức này và tại sao AWS Batch—kết hợp với các phiên bản Amazon EC2 được tăng tốc bằng GPU—trở thành một lựa chọn phù hợp cho các khối lượng công việc suy luận phân tán quy mô lớn của chúng tôi. Quan trọng hơn, chúng tôi sẽ nêu bật những bài học đã học và các phương pháp đã giúp chúng tôi làm cho quá trình suy luận trở nên rất hiệu quả.
Cơ hội
Các tài sản hình ảnh từ nhiều nguồn khác nhau cung cấp năng lượng cho việc truy xuất, khám phá và đề xuất nội dung trên nhiều sản phẩm Adobe—như Adobe Acrobat, Adobe Express, Adobe Firefly và nhiều sản phẩm khác—và được hiển thị thông qua tìm kiếm ngữ nghĩa. Các mô hình nhúng liên tục phát triển, điều này làm cho việc tính toán lại định kỳ các nhúng cho các tập dữ liệu khổng lồ với hàng trăm triệu tài sản ngày càng trở nên quan trọng đối với xếp hạng và mức độ liên quan của tìm kiếm hiện đại. Khi các tính năng và trải nghiệm tìm kiếm tiếp tục phát triển, với một số thử nghiệm và đánh giá trong suốt chu trình phát triển, việc tính toán lại và cập nhật các nhúng trở nên lặp đi lặp lại.
Tính toán các nhúng hình ảnh tương tự như các quy trình làm việc cho văn bản, video và âm thanh và bao gồm việc tải hình ảnh vào bộ nhớ, chạy suy luận với các mô hình học máy độc quyền của Adobe và lưu trữ kết quả trong các hệ thống nội bộ cung cấp năng lượng cho tìm kiếm ngữ nghĩa, RAG và các khả năng khác. Với khối lượng dữ liệu, quá trình này chỉ có thể được triển khai dưới dạng một quy trình song song lớn thay vì xử lý tuần tự. AWS Batch, một dịch vụ được quản lý hoàn toàn giúp đơn giản hóa việc chạy các khối lượng công việc tính toán hàng loạt, đã giúp chúng tôi đạt được mục tiêu của mình.
Một số thách thức chính bao gồm:
- Đa dạng mô hình và dữ liệu: Các mô hình và kích thước tập dữ liệu khác nhau yêu cầu các kiến trúc GPU khác nhau để tối đa hóa hiệu suất và tốc độ. Vì vậy, các pipeline của chúng tôi cần linh hoạt để sử dụng các loại phiên bản EC2 khác nhau.
- Chi phí vận hành cao: Xây dựng và duy trì hệ thống điều phối container của riêng chúng tôi (như EKS) để thực hiện các công việc suy luận ad hoc này sẽ đòi hỏi nỗ lực kỹ thuật đáng kể, bao gồm quản lý máy chủ, nhóm tự động mở rộng (auto-scaling groups) và bộ cân bằng tải. Thay vào đó, một giải pháp tạm thời đơn giản sẽ phù hợp hơn.
- Phát hiện và phục hồi lỗi: Ngay cả với tự động hóa hoàn toàn việc thiết lập cluster, các cơ chế phát hiện lỗi và thử lại yêu cầu logic nghiệp vụ bổ sung.
- Độ phức tạp của phân mảnh dữ liệu: Phân vùng dữ liệu hiệu quả và gán công việc cho từng node trong data lake ngày càng trở nên thách thức ở quy mô lớn.
- Thời gian xử lý dài: Xử lý tuần tự có thể mất hàng tuần để hoàn thành đối với các khối lượng công việc lớn, hạn chế nghiêm trọng tốc độ lặp lại.
Giải pháp
Khi thiết kế các giải pháp, chúng tôi hướng tới việc đạt được:
- Truy cập tài nguyên ngay lập tức: Cung cấp quyền truy cập liền mạch vào GPU trên nhiều loại phiên bản (ví dụ: g6e, g5), được chọn dựa trên yêu cầu của mô hình.
- Sử dụng tài nguyên hiệu quả: Đảm bảo các tài nguyên được phân bổ được sử dụng một cách hiệu quả và có ích.
- Gửi công việc nhất quán: Cung cấp một giao diện tiêu chuẩn để thực hiện công việc, bất kể mức độ song song hóa hay loại phiên bản EC2.
- Tối ưu hóa chi phí: Tận dụng mô hình “trả tiền theo mức sử dụng” và tự động mở rộng tài nguyên lên hoặc xuống dựa trên nhu cầu. Giảm thiểu chi phí cho mỗi công việc để mang lại giá trị tốt nhất có thể.
- Trải nghiệm người dùng: Dân chủ hóa quá trình xử lý hàng loạt lớn thông qua trải nghiệm tự phục vụ hoàn toàn, trao quyền cho người dùng chạy các công việc mà không cần kiến thức sâu về cơ sở hạ tầng.
Chuẩn bị dữ liệu và suy luận phân tán
Tải dữ liệu hiệu quả là rất quan trọng để tối đa hóa việc sử dụng GPU trong quá trình suy luận quy mô lớn. Một nút thắt cổ chai phổ biến là dữ liệu không được tải đủ nhanh vào GPU, hoặc pipeline trở nên mất cân bằng, dẫn đến phần cứng không được sử dụng tối đa.
Đối với một trường hợp sử dụng khác, Adobe Research đã tùy chỉnh PyTorch Dataloader để truyền trực tiếp các mẫu từ Amazon S3 vào các container AWS Batch ở cấp độ node. Trong mỗi container, CPU xử lý tiền xử lý—như giải mã và chuyển đổi các mẫu thành tensor—trước khi cung cấp các batch được định dạng tốt cho GPU để suy luận. Nếu một node có 8 GPU, 8 dataloader được tạo, mỗi dataloader được ghép nối với công cụ mô hình riêng của nó. Mặc dù tất cả chúng đều trỏ đến cùng một tập dữ liệu, mỗi dataloader sử dụng thứ hạng được gán và số lượng dataloader mà host đang khởi tạo, còn được gọi là world rank, để biết chính xác phân đoạn nào của tập dữ liệu cần xử lý, tránh trùng lặp và đảm bảo thông lượng cân bằng.
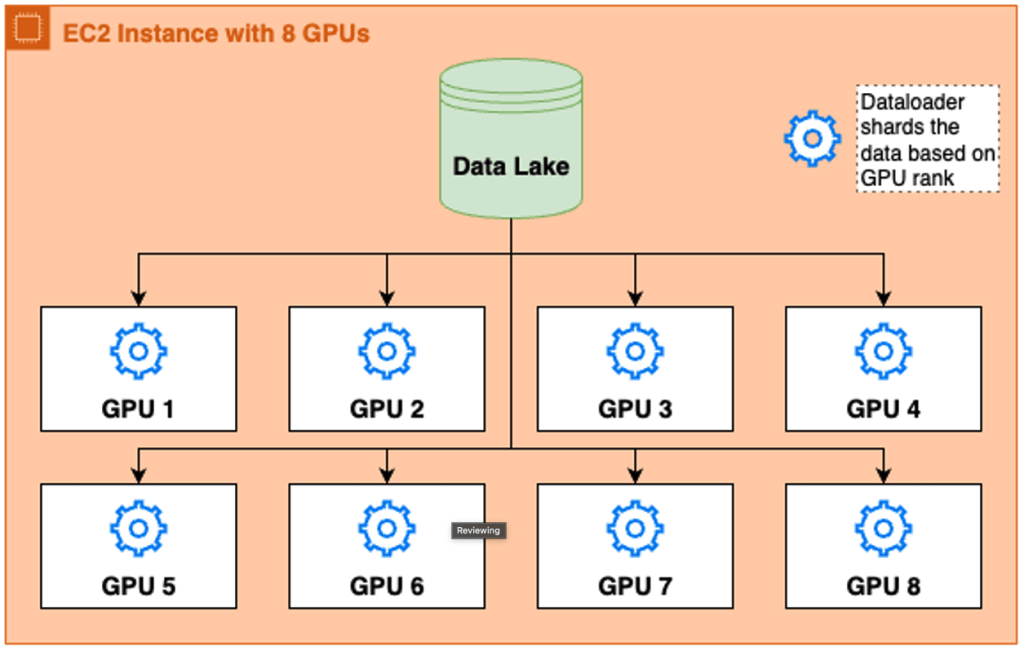
Hình 1: Hệ thống Dataloader cho suy luận.
Khi mở rộng quy trình sang nhiều node phân tán, điều quan trọng là mỗi node phải được cấp một phân vùng tập dữ liệu riêng biệt để xử lý. Một cách tiếp cận là tải xuống toàn bộ tập dữ liệu cho mỗi node và dựa vào thứ hạng/kích thước thế giới của dataloader để xử lý phân vùng. Tuy nhiên, với quy mô dữ liệu, điều này sẽ yêu cầu sử dụng đĩa bổ sung đáng kể. Đây là lúc chúng tôi tận dụng AWS Batch: Chúng tôi đã tách biệt việc chuẩn bị tập dữ liệu và chuyển đổi nó thành một công việc AWS Batch riêng. Công việc tiền xử lý này chạy nhiều worker để phân mảnh S3 bucket và nén địa chỉ đối tượng thành các tệp nhị phân nhỏ gọn.
Trong quá trình suy luận, mỗi node chỉ cần tải xuống phân đoạn nhị phân được gán cho nó—dựa trên AWS_BATCH_JOB_NODE_INDEX của nó—và đưa nó vào các dataloader của nó. Điều này làm giảm chi phí đĩa, loại bỏ các lần truyền dữ liệu dư thừa và đảm bảo rằng mỗi node xử lý một tập hợp con duy nhất của tập dữ liệu. Cùng với nhau, các kỹ thuật này giữ cho GPU được cung cấp đầy đủ các batch và duy trì hiệu quả cao trên hàng nghìn công việc đồng thời. Giai đoạn này cũng được thực hiện bởi dịch vụ AWS Batch, và chúng tôi đã tận dụng khả năng hỗ trợ loại phiên bản EC2 GPU của Batch.
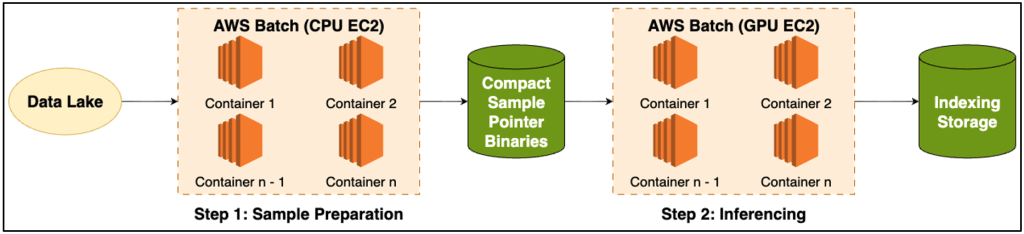
Hình 2: Sơ đồ hệ thống suy luận tổng thể.
Cách AWS Batch Hỗ Trợ Mục Tiêu Giải Pháp và Giải Quyết Thách Thức Mở Rộng Quy Mô
AWS Batch cung cấp một kiến trúc được quản lý giúp loại bỏ phần lớn gánh nặng vận hành của việc mở rộng quy mô khối lượng công việc suy luận lớn. Nó cho phép chúng tôi chạy hàng chục nghìn công việc đồng thời mà không cần duy trì cơ sở hạ tầng phức tạp, đồng thời hưởng lợi từ việc ghi nhật ký, giám sát, kiểm soát truy cập và tích hợp hệ thống tệp nhất quán.
Sau đây là một số yếu tố của quá trình xử lý song song AWS Batch.
Môi trường tính toán: Đây là nơi chúng tôi định nghĩa loại phiên bản EC2, launch template và số lượng node tối thiểu/tối đa. AWS Batch cung cấp một Auto Scaling Group (ASG) cho các node GPU và triển khai các container đến các node EC2 này dựa trên tính khả dụng và tình trạng của chúng. Sự trừu tượng này có nghĩa là chúng tôi hiếm khi chạm vào cơ sở hạ tầng cấp thấp. Việc mở rộng quy mô là tự động—nếu khối lượng công việc tăng hoặc giảm, ASG sẽ điều chỉnh số lượng node trong giới hạn đã định, đảm bảo chúng tôi không bao giờ phải trả tiền cho dung lượng nhàn rỗi.
Hàng đợi công việc: Điều này xác định thứ tự các công việc được thực hiện dựa trên Môi trường tính toán liên quan. Ví dụ, nếu hàng đợi A được ánh xạ tới môi trường tính toán (CE) A, các công việc trong hàng đợi đó sẽ được phân phối dựa trên dung lượng GPU khả dụng và mức độ ưu tiên của hàng đợi. Hàng đợi công việc cũng thực thi các quy tắc thực thi cấp cao, chẳng hạn như chấm dứt các công việc vượt quá thời gian chờ, thất bại do không đủ GPU khả dụng hoặc gặp các ràng buộc tài nguyên khác.
Định nghĩa công việc: Bản thiết kế thực thi của công việc, giống như một lệnh docker run. Điều này chỉ định Docker image, tài nguyên GPU/CPU cần thiết, disk mount và bất kỳ biến môi trường hoặc cấu hình thời gian chạy nào cần thiết để container chạy trên host EC2. Nó cũng định nghĩa số lần thử lại công việc, hoặc số lần thử khởi động lại container trong trường hợp thất bại.
Công việc: Quá trình gửi một định nghĩa công việc vào một hàng đợi công việc. Điều này kích hoạt việc cung cấp cơ sở hạ tầng cần thiết. Mỗi node trong một công việc đa node được tự động gán hai biến môi trường chính—AWS_BATCH_JOB_NODE_INDEX và AWS_BATCH_JOB_NUM_NODES—được sử dụng để phân mảnh dữ liệu để mỗi node xử lý phần cụ thể của khối lượng công việc.
Khi một công việc được gửi đến AWS Batch, mỗi node công việc nhận được các biến môi trường giống nhau, bao gồm một S3 URI nơi tất cả dữ liệu được lưu trữ. Phiên bản EC2 từ ASG kéo Docker image chứa mô hình suy luận và logic của chúng tôi. Khi container hoạt động và khỏe mạnh, nó sử dụng các giá trị AWS_BATCH_JOB_NODE_INDEX và AWS_BATCH_JOB_NUM_NODES của node để xác định chính xác phân đoạn dữ liệu nào nó nên tải xuống và xử lý. Sau khi bước suy luận hoàn tất, kết quả được lưu trữ ngay lập tức trong chỉ mục tìm kiếm. Container sau đó thoát với mã thành công và chấm dứt, giải phóng host EC2. Nếu có thêm công việc đang chờ trong hàng đợi, host sẽ nhận công việc tiếp theo; nếu không, ASG sẽ thu nhỏ để giải phóng tài nguyên không sử dụng. Theo mặc định, mỗi chỉ mục công việc cũng tạo một luồng nhật ký AWS CloudWatch, cho phép chúng tôi quan sát hoạt động của container trong thời gian thực và gỡ lỗi các vấn đề khi cần.
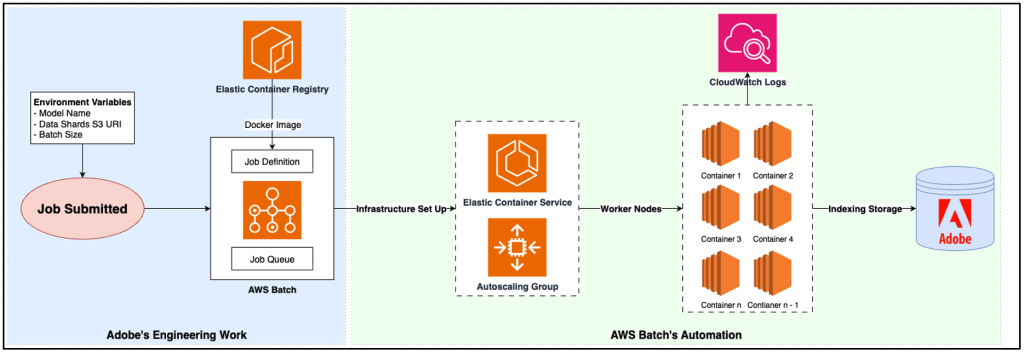
Hình 3 – Sơ đồ luồng dữ liệu AWS Batch được sử dụng với giải pháp của Adobe.
Kết quả
Bằng cách thiết kế lại một quy trình làm việc tuần tự thành một pipeline tính toán song song phân tán và phân mảnh nhiều bước, và bằng cách triển khai một cơ chế tải/dỡ tải dữ liệu hiệu quả cho GPU, chúng tôi đã đạt được tốc độ thực thi nhanh hơn 10 lần. Từ các bảng điều khiển giám sát của chúng tôi, chúng tôi thường thấy GPU của mình hiện chạy ổn định ở mức sử dụng 100%, mang lại thông lượng cực cao và tối đa hóa hiệu quả phần cứng.
AWS Batch cho phép chúng tôi hỗ trợ điều này ở quy mô lớn bằng cách cung cấp tính toán tạm thời mà không có cơ sở hạ tầng cố định hoặc chi phí cố định. AWS Batch xử lý các công việc vận hành nặng nhọc, và tính linh hoạt của nó để hỗ trợ cả khối lượng công việc CPU và GPU đã giúp chúng tôi tiết kiệm đáng kể nỗ lực kỹ thuật đồng thời giảm chi tiêu đám mây.
Trong một trong những lần chạy lớn nhất của chúng tôi—tính toán các nhúng hình ảnh cho Adobe Stock—chúng tôi đã giảm thời gian tính toán từ 30 ngày xuống dưới 20 giờ, đồng thời đạt được giảm chi phí hơn 95%, bao gồm không chỉ tính toán mà còn cả đầu tư kỹ thuật. Khả năng này trao quyền cho nhóm kỹ thuật của chúng tôi để tăng tốc khối lượng công việc sản xuất và chạy các thử nghiệm quy mô lớn một cách nhanh chóng và hiệu quả về chi phí.
Bài học kinh nghiệm
Tổ chức dữ liệu
- Phân mảnh dữ liệu hiệu quả:
Để xử lý một số lượng lớn tài sản một cách hiệu quả, việc tổ chức trước dữ liệu thành các phân mảnh nhỏ hơn, dễ quản lý hơn là rất quan trọng. Nếu không có điều này, ngay cả các hoạt động đơn giản như liệt kê tài sản trong S3 cũng có thể mất hàng giờ hoặc có thể bị treo hoàn toàn. Bằng cách tổ chức dữ liệu thành các phân mảnh nhỏ hơn, chúng tôi đã cho phép các node song song tiêu thụ dữ liệu hiệu quả hơn. - Xử lý giới hạn tốc độ S3: Sau khi tổ chức dữ liệu, việc tải xuống song song bởi nhiều node ban đầu dẫn đến lỗi giới hạn tốc độ (HTTP 429). Để giải quyết vấn đề này:
- Chúng tôi đã hợp tác với nhóm AWS S3 để tăng thông lượng của S3 bucket, điều này đã giảm đáng kể các lỗi giới hạn tốc độ.
- Mặc dù đã có các biện pháp này, các lỗi 429 thỉnh thoảng vẫn xảy ra. Để giảm thiểu điều này:
- Chúng tôi đã triển khai các lần thử lại ngay lập tức trong cùng một vòng lặp xử lý.
- Chúng tôi đã thêm một cơ chế thử lại cuối cùng vào cuối quá trình xử lý. Đến giai đoạn này, mỗi node đang thực hiện ít cuộc gọi đến S3 hơn, giảm khả năng xảy ra lỗi 429.
- Xử lý hàng loạt trên GPU:
Khi làm việc với GPU, việc xử lý dữ liệu theo các batch tối ưu là bắt buộc. Điều này áp dụng cho tiền xử lý, xử lý và hậu xử lý. Kích thước batch tối ưu này thay đổi tùy theo ứng dụng. Chúng tôi đã thử nghiệm với nhiều kích thước batch khác nhau trước khi chạy lớn và tìm thấy một kích thước tối ưu. Xử lý hàng loạt đã tiết kiệm đáng kể thời gian GPU và giảm tổng thời gian xử lý. - Bản địa hóa dữ liệu: Chúng tôi đảm bảo rằng dữ liệu nằm trong cùng một AWS Region với các cluster tính toán hàng loạt. Cách tiếp cận này:
- Tránh các khoản phí truyền dữ liệu giữa các Region, vốn có thể rất lớn.
- Giảm độ trễ và cải thiện tổng thời gian hoạt động.
Tính toán
- Thách thức về tính khả dụng của GPU: Do nhu cầu ngày càng tăng về tính toán ML, việc có được số lượng lớn GPU theo yêu cầu là một thách thức. Để giải quyết vấn đề này:
- Chúng tôi đã tạo các định nghĩa tính toán cho các họ phiên bản GPU khác nhau như G5s, G6es và G6s.
- Chúng tôi đã tận dụng các định nghĩa tính toán lai trong AWS Batch để tối đa hóa tính linh hoạt.
- Tối ưu hóa thông lượng: Hiểu được thông lượng của một pod duy nhất là điều cần thiết. Dựa trên điều này:
- Chúng tôi đã định nghĩa số lượng vCPU/GPU tối thiểu và tối đa cần thiết.
- Điều này đảm bảo rằng ngay cả khi không có đủ dung lượng tính toán, AWS Batch vẫn có thể bắt đầu xử lý với các tài nguyên có sẵn và mở rộng quy mô khi có thêm tài nguyên tính toán.
Những điểm chính:
- Tổ chức dữ liệu: Phân mảnh và bản địa hóa dữ liệu đúng cách là rất quan trọng để xử lý hiệu quả và tối ưu hóa chi phí.
- Xử lý lỗi: Triển khai các cơ chế thử lại mạnh mẽ giúp giảm thiểu lỗi giới hạn tốc độ.
- Xử lý hàng loạt: Xử lý dữ liệu theo batch là điều cần thiết để GPU hoạt động hiệu quả.
- Tính linh hoạt của tính toán: Thích ứng với các tài nguyên tính toán có sẵn đảm bảo xử lý không bị gián đoạn và khả năng mở rộng.
Kết luận
Bằng cách tích hợp AWS Batch với Amazon ECS và các phiên bản EC2 dựa trên GPU, Adobe đã nâng cao đáng kể cơ sở hạ tầng xử lý tài sản (hình ảnh, video) của mình đồng thời mở rộng hỗ trợ cho các loại nội dung bổ sung, bao gồm văn bản và video. Kết quả là khả năng mở rộng, hiệu quả chi phí và sự đơn giản trong vận hành chưa từng có—cho phép thực hiện nhanh hơn các khối lượng công việc khổng lồ và tăng tốc đổi mới. Đối với các tổ chức muốn mở rộng quy mô tính toán hiệu năng cao và đẩy nhanh thời gian đưa sản phẩm ra thị trường, AWS Batch mang đến một con đường hấp dẫn để đạt được tổng chi phí sở hữu (TCO) tối ưu.
Về tác giả

Harish Suvarna
Harish là Kiến trúc sư MLOps cấp cao tại Adobe với hơn 30 năm kinh nghiệm xây dựng các nền tảng ML quy mô lớn, hệ thống xử lý nội dung và công cụ NLP. Ông đã dẫn dắt các sáng kiến về quy trình đào tạo, chấm điểm và dự đoán hàng loạt, kiến trúc môi trường ML trên Azure ML, SageMaker và các framework GPU nội bộ, đồng thời phát triển các hệ thống tìm kiếm, phân tích văn bản và NLP đa ngôn ngữ có khả năng mở rộng.

Alec Ngo
Alec là Kỹ sư Phần mềm tại Adobe Search, Discovery, and Content, nơi anh làm việc để thúc đẩy suy luận hàng loạt quy mô lớn nhằm cung cấp năng lượng cho trải nghiệm tìm kiếm và sáng tạo. Anh tập trung vào việc xây dựng các hệ thống đáng tin cậy giúp suy luận AI quy mô lớn hiệu quả hơn. Alec có bằng Cử nhân Khoa học Máy tính từ Berea College ở Kentucky.

Mark Azadpour
Mark Azadpour là Chuyên gia GTM cấp cao cho AWS Batch. Ông tập trung vào việc thúc đẩy chiến lược và các sáng kiến tiếp cận thị trường của AWS Batch, đồng thời ủng hộ việc sử dụng container trong HPC thay mặt khách hàng. Ông đã làm việc trong lĩnh vực Doanh nghiệp hơn 18 năm.

Suryanarayana Murthy Boddu
Surya là Giám đốc Kỹ thuật tại Adobe, tập trung vào MLOps, DevOps và kỹ thuật Nền tảng. Ông đã làm việc tại Adobe gần 9 năm, lãnh đạo và quản lý nhiều sáng kiến liên quan đến hoạt động học máy, điều phối quy mô lớn và độ tin cậy của nền tảng. Surya thúc đẩy các dự án đa chức năng cho phép các nhóm xây dựng, triển khai và mở rộng các giải pháp AI một cách hiệu quả, đồng thời thúc đẩy sự hợp tác và xuất sắc về kỹ thuật trên toàn Adobe.

Yoginder Sethi
Yoginder Sethi là Kiến trúc sư Giải pháp cấp cao làm việc trong nhóm Kiến trúc Giải pháp Tài khoản Chiến lược tại AWS. Ông có kinh nghiệm và kiến thức sâu rộng trong việc xây dựng và quản lý các kiến trúc đám mây quy mô lớn, Công cụ Devops và Khả năng quan sát. Ông sống ở khu vực Vịnh San Francisco, California và ngoài công việc, ông thích khám phá những địa điểm mới, nghe nhạc và đi bộ đường dài.
