Tác giả: Samit Kumbhani, David Mbonu, và Jhorlin De Armas
Ngày phát hành: 22 JAN 2026
Chuyên mục: Customer Solutions, Generative AI
PDI Technologies là công ty hàng đầu toàn cầu trong ngành bán lẻ tiện lợi và bán buôn xăng dầu. Họ giúp các doanh nghiệp trên toàn thế giới tăng hiệu quả và lợi nhuận bằng cách kết nối dữ liệu và hoạt động của họ một cách an toàn. Với 40 năm kinh nghiệm, PDI Technologies hỗ trợ khách hàng trong mọi khía cạnh kinh doanh của họ, từ việc hiểu hành vi người tiêu dùng đến việc đơn giản hóa hệ sinh thái công nghệ trên toàn chuỗi cung ứng.
Các doanh nghiệp phải đối mặt với thách thức đáng kể trong việc làm cho các cơ sở tri thức của họ có thể truy cập, tìm kiếm và sử dụng được bởi các hệ thống AI. Các nhóm nội bộ tại PDI Technologies đang gặp khó khăn với thông tin nằm rải rác trên các hệ thống khác nhau bao gồm trang web, trang Confluence, trang SharePoint và nhiều nguồn dữ liệu khác. Để giải quyết vấn đề này, PDI Technologies đã xây dựng PDI Intelligence Query (PDIQ), một trợ lý AI cung cấp cho nhân viên quyền truy cập vào tri thức công ty thông qua giao diện trò chuyện dễ sử dụng. Giải pháp này được cung cấp bởi một hệ thống Retrieval Augmented Generation (RAG) tùy chỉnh, được xây dựng trên Amazon Web Services (AWS) bằng cách sử dụng các công nghệ serverless. Việc xây dựng PDIQ đòi hỏi phải giải quyết các thách thức chính sau:
- Tự động trích xuất nội dung từ các nguồn đa dạng với các yêu cầu xác thực khác nhau
- Cần sự linh hoạt để chọn, áp dụng và hoán đổi mô hình ngôn ngữ lớn (LLM) phù hợp nhất cho các yêu cầu xử lý đa dạng
- Xử lý và lập chỉ mục nội dung để tìm kiếm ngữ nghĩa và truy xuất theo ngữ cảnh
- Tạo nền tảng tri thức cho phép các phản hồi AI chính xác, phù hợp
- Liên tục làm mới thông tin thông qua việc thu thập dữ liệu theo lịch trình
- Hỗ trợ ngữ cảnh dành riêng cho doanh nghiệp trong các tương tác AI
Trong bài đăng này, chúng tôi sẽ trình bày quy trình và kiến trúc của PDIQ, tập trung vào các chi tiết triển khai và kết quả kinh doanh mà nó đã giúp PDI đạt được.
Kiến trúc giải pháp
Trong phần này, chúng tôi khám phá thiết kế toàn diện từ đầu đến cuối của PDIQ. Chúng tôi xem xét quy trình nhập dữ liệu từ xử lý ban đầu qua lưu trữ đến khả năng tìm kiếm của người dùng, cũng như khung bảo mật zero-trust bảo vệ các vai trò người dùng chính trong suốt quá trình tương tác với nền tảng của họ. Kiến trúc bao gồm các yếu tố sau:
- Scheduler – Amazon EventBridge duy trì và thực thi bộ lập lịch crawler.
- Crawlers – AWS Lambda gọi các crawler được thực thi dưới dạng tác vụ bởi Amazon Elastic Container Service (Amazon ECS).
- Amazon DynamoDB – Duy trì cấu hình crawler và các siêu dữ liệu khác như vị trí hình ảnh Amazon Simple Storage Service (Amazon S3) và chú thích.
- Amazon S3 – Tất cả các tài liệu nguồn được lưu trữ trong Amazon S3. Các sự kiện Amazon S3 kích hoạt luồng tiếp theo cho mỗi đối tượng được tạo hoặc xóa.
- Amazon Simple Notification Service (Amazon SNS) – Nhận thông báo từ các sự kiện Amazon S3.
- Amazon Simple Queue Service (Amazon SQS) – Đăng ký Amazon SNS để giữ các yêu cầu đến trong một hàng đợi.
- AWS Lambda – Xử lý logic nghiệp vụ để phân đoạn, tóm tắt và tạo nhúng vector.
- Amazon Bedrock – Cung cấp quyền truy cập API vào các mô hình nền tảng (FMs) được PDIQ sử dụng:
- Amazon Nova Lite để tạo chú thích hình ảnh
- Amazon Nova Micro để tạo tóm tắt tài liệu
- Amazon Titan Text Embeddings V2 để tạo nhúng vector
- Amazon Nova Pro để tạo phản hồi cho các yêu cầu của người dùng
- Amazon Aurora PostgreSQL-Compatible Edition – Lưu trữ nhúng vector.
Sơ đồ sau đây là kiến trúc giải pháp.
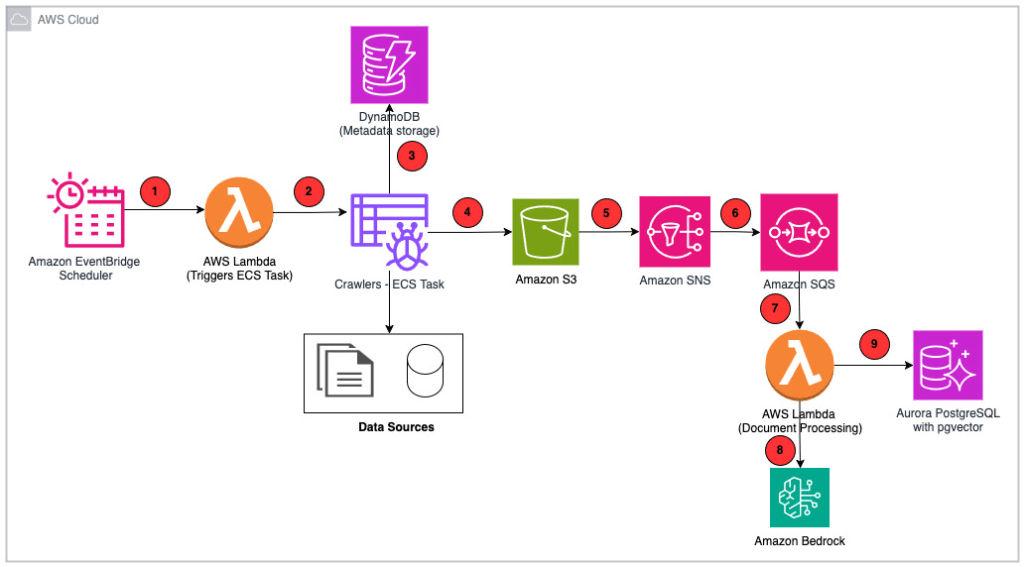
Hình 1: Sơ đồ kiến trúc giải pháp PDIQ
Tiếp theo, chúng tôi xem xét cách PDIQ triển khai mô hình bảo mật zero-trust với kiểm soát truy cập dựa trên vai trò cho hai vai trò chính:
- Quản trị viên cấu hình các cơ sở tri thức và crawler thông qua các nhóm người dùng Amazon Cognito được tích hợp với tính năng đăng nhập một lần của doanh nghiệp. Thông tin xác thực của crawler được mã hóa khi lưu trữ bằng AWS Key Management Service (AWS KMS) và chỉ có thể truy cập trong các môi trường thực thi biệt lập.
- Người dùng cuối truy cập các cơ sở tri thức dựa trên quyền nhóm được xác thực ở lớp ứng dụng. Người dùng có thể thuộc nhiều nhóm (chẳng hạn như nhân sự hoặc tuân thủ) và chuyển đổi ngữ cảnh để truy vấn các tập dữ liệu phù hợp với vai trò.
Luồng xử lý
Trong phần này, chúng tôi xem xét luồng xử lý từ đầu đến cuối. Chúng tôi chia nhỏ theo các phần để đi sâu hơn vào từng bước và giải thích chức năng.
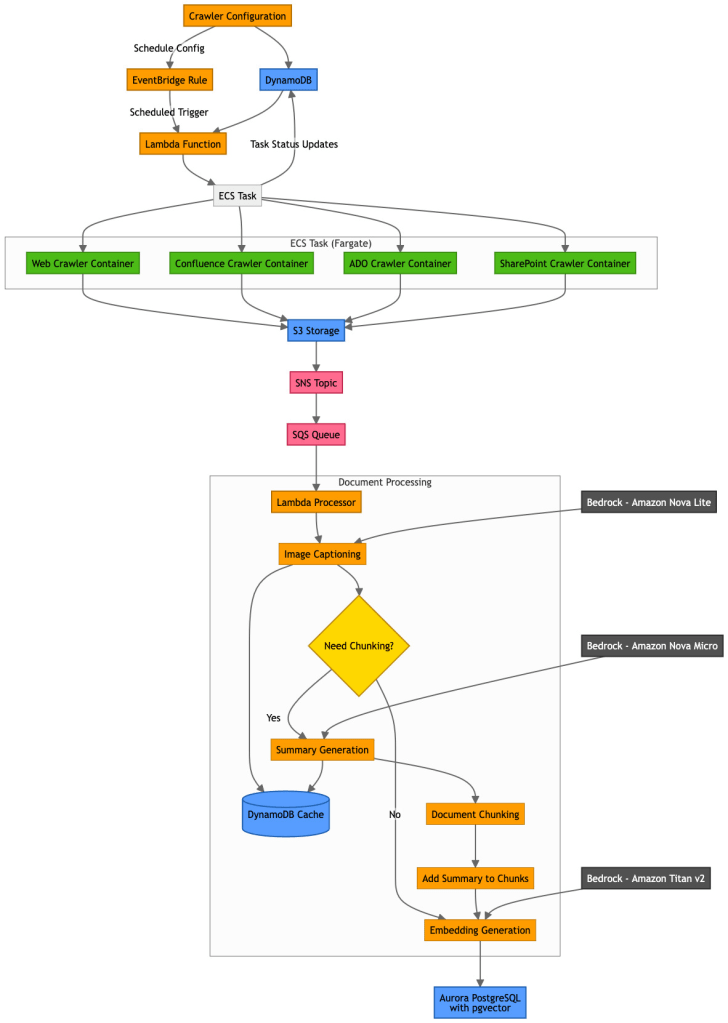
Hình 2: Sơ đồ luồng xử lý PDIQ
Crawlers
Crawlers được Quản trị viên cấu hình để thu thập dữ liệu từ nhiều nguồn mà PDI dựa vào. Crawlers đưa dữ liệu vào cơ sở tri thức để thông tin này có thể được người dùng cuối truy xuất. PDIQ hiện hỗ trợ các cấu hình crawler sau:
- Web crawler – Bằng cách sử dụng Puppeteer để tự động hóa trình duyệt không giao diện, crawler chuyển đổi các trang web HTML sang định dạng markdown bằng cách sử dụng turndown. Bằng cách theo dõi các liên kết nhúng trên trang web, crawler có thể nắm bắt toàn bộ ngữ cảnh và mối quan hệ giữa các trang. Ngoài ra, crawler tải xuống các tài sản như PDF và hình ảnh trong khi vẫn giữ nguyên tham chiếu gốc và cung cấp cho người dùng các tùy chọn cấu hình như giới hạn tốc độ.
- Confluence crawler – Crawler này sử dụng Confluence REST API với quyền truy cập được xác thực để trích xuất nội dung trang, tệp đính kèm và hình ảnh nhúng. Nó bảo toàn hệ thống phân cấp và mối quan hệ của trang, xử lý các yếu tố Confluence đặc biệt như hộp thông tin, ghi chú và nhiều hơn nữa.
- Azure DevOps crawler – PDI sử dụng Azure DevOps để quản lý cơ sở mã của mình, theo dõi các commit và duy trì tài liệu dự án trong một kho lưu trữ tập trung. PDIQ sử dụng Azure DevOps REST API với xác thực OAuth hoặc personal access token (PAT) để trích xuất thông tin này. Azure DevOps crawler bảo toàn hệ thống phân cấp dự án, mối quan hệ sprint và cấu trúc backlog cũng như ánh xạ các mối quan hệ mục công việc (chẳng hạn như mục cha/con hoặc mục được liên kết), từ đó cung cấp một cái nhìn hoàn chỉnh về tập dữ liệu.
- SharePoint crawler – Nó sử dụng Microsoft Graph API với xác thực OAuth để trích xuất thư viện tài liệu, danh sách, trang và nội dung tệp. Crawler xử lý các tài liệu MS Office (Word, Excel, PowerPoint) thành văn bản có thể tìm kiếm và duy trì lịch sử phiên bản tài liệu cũng như siêu dữ liệu quyền.
Bằng cách xây dựng các cấu hình crawler riêng biệt, PDIQ cung cấp khả năng mở rộng dễ dàng vào nền tảng để cấu hình thêm các crawler theo yêu cầu. Nó cũng cung cấp sự linh hoạt cho người dùng quản trị để cấu hình cài đặt cho các crawler tương ứng của họ (chẳng hạn như tần suất, độ sâu hoặc giới hạn tốc độ).
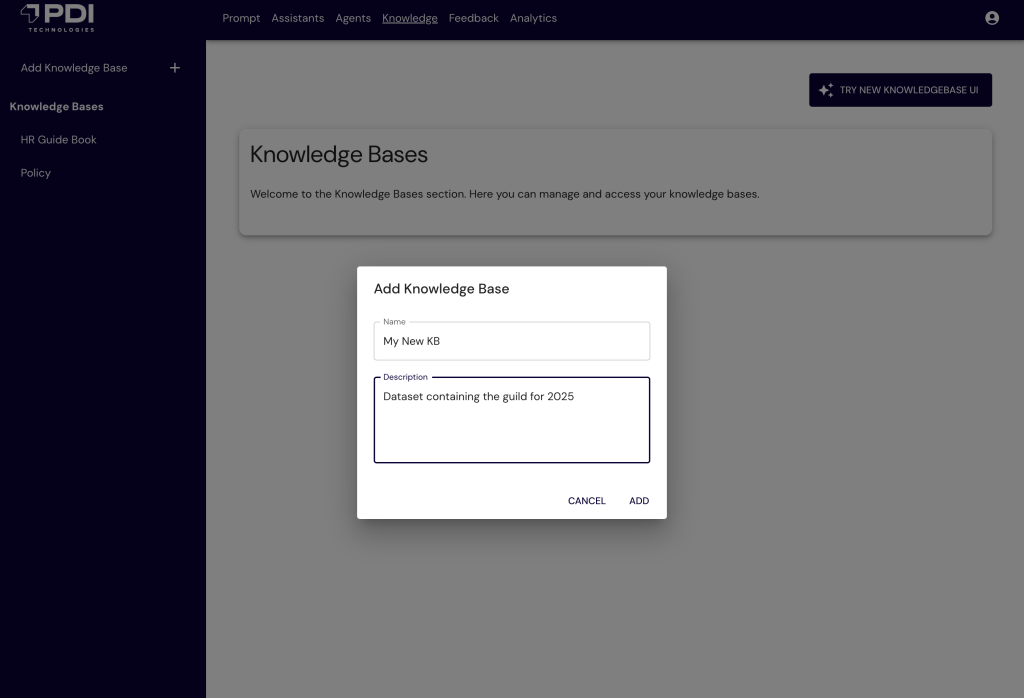
Hình sau đây cho thấy giao diện người dùng PDIQ để cấu hình cơ sở tri thức.
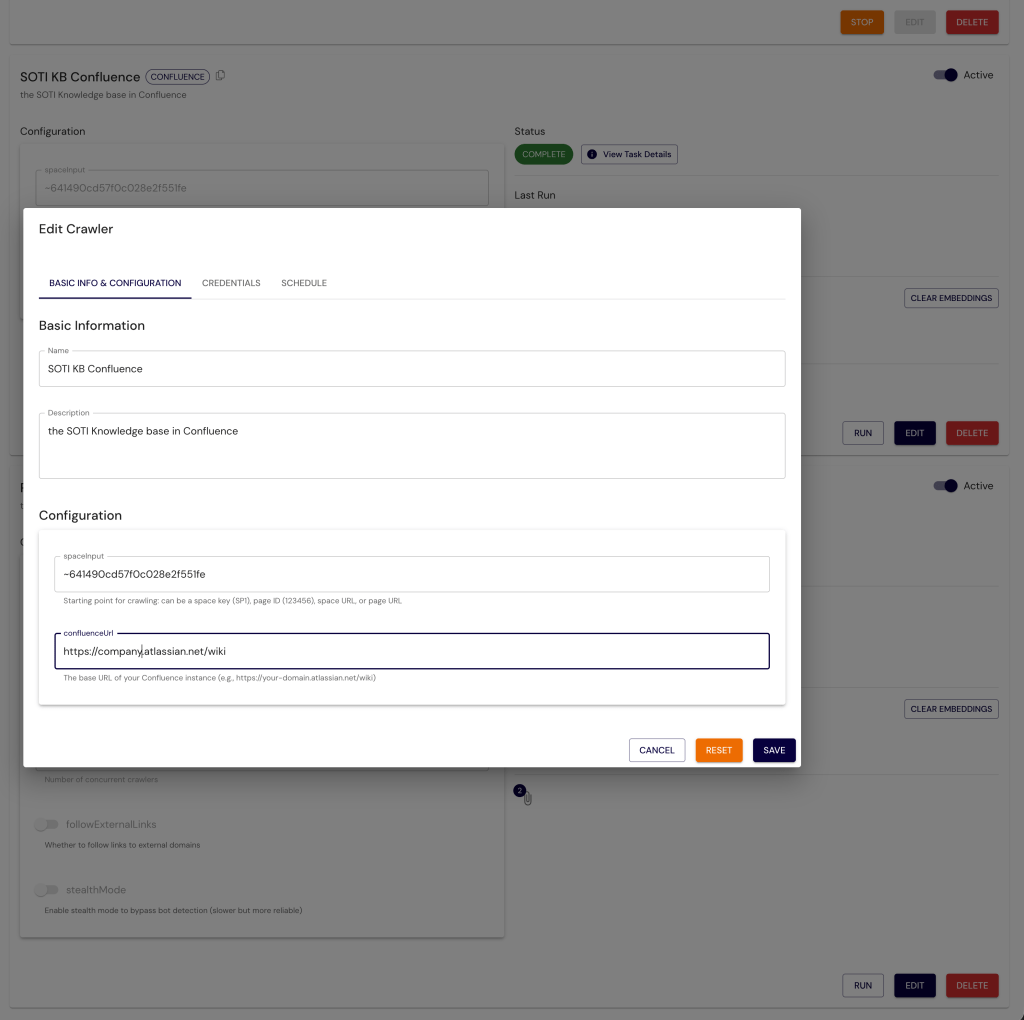
Hình sau đây cho thấy giao diện người dùng PDI để cấu hình crawler của bạn (chẳng hạn như Confluence).
Hình sau đây cho thấy giao diện người dùng PDIQ để lên lịch crawlers.
Xử lý hình ảnh
Dữ liệu được thu thập được lưu trữ trong Amazon S3 với các thẻ siêu dữ liệu phù hợp. Nếu nguồn ở định dạng HTML, tác vụ sẽ chuyển đổi nội dung thành các tệp markdown (.md). Đối với các tệp markdown này, có một bước tối ưu hóa bổ sung được thực hiện để thay thế hình ảnh trong tài liệu bằng vị trí tham chiếu Amazon S3. Các lợi ích chính của phương pháp này bao gồm:
- PDI có thể sử dụng khóa đối tượng S3 để tham chiếu duy nhất từng hình ảnh, từ đó tối ưu hóa quá trình đồng bộ hóa để phát hiện các thay đổi trong dữ liệu nguồn
- Bạn có thể tối ưu hóa lưu trữ bằng cách thay thế hình ảnh bằng chú thích và tránh nhu cầu lưu trữ các hình ảnh trùng lặp
- Nó cung cấp khả năng làm cho nội dung của hình ảnh có thể tìm kiếm và liên quan đến nội dung văn bản trong tài liệu
- Chèn liền mạch các hình ảnh gốc khi hiển thị phản hồi cho yêu cầu của người dùng
Sau đây là một tệp markdown mẫu trong đó hình ảnh được thay thế bằng vị trí tệp S3:
Xử lý tài liệu
Đây là bước quan trọng nhất của quá trình. Mục tiêu chính của bước này là tạo nhúng vector để chúng có thể được sử dụng để khớp tương tự và truy xuất hiệu quả dựa trên yêu cầu của người dùng. Quá trình này bao gồm nhiều bước, bắt đầu bằng việc tạo chú thích hình ảnh, sau đó là phân đoạn tài liệu, tạo tóm tắt và tạo nhúng. Để tạo chú thích cho hình ảnh, PDIQ quét các tệp markdown để định vị các thẻ hình ảnh <image>. Đối với mỗi hình ảnh này, PDIQ quét và tạo một chú thích hình ảnh giải thích nội dung của hình ảnh. Chú thích này được chèn lại vào tệp markdown, bên cạnh thẻ <image>, từ đó làm phong phú nội dung tài liệu. Phương pháp này cung cấp khả năng tìm kiếm theo ngữ cảnh được cải thiện. PDIQ tăng cường khả năng khám phá nội dung bằng cách nhúng thông tin chi tiết được trích xuất từ hình ảnh trực tiếp vào các tệp markdown gốc. Phương pháp này đảm bảo rằng nội dung hình ảnh trở thành một phần của văn bản có thể tìm kiếm, cho phép truy xuất ngữ cảnh phong phú hơn và chính xác hơn trong quá trình tìm kiếm và phân tích. Phương pháp này cũng tiết kiệm chi phí. Để tránh các cuộc gọi suy luận LLM không cần thiết cho cùng một hình ảnh, PDIQ lưu trữ siêu dữ liệu hình ảnh (vị trí tệp và chú thích được tạo) trong Amazon DynamoDB. Bước này cho phép tái sử dụng hiệu quả các chú thích đã được tạo trước đó, loại bỏ nhu cầu gọi tạo chú thích lặp lại đến LLM.
Sau đây là một ví dụ về lời nhắc chú thích hình ảnh:
You are a professional image captioning assistant. Your task is to provide clear, factual, and objective descriptions of images. Focus on describing visible elements, objects, and scenes in a neutral and appropriate manner.Sau đây là một đoạn tệp markdown chứa thẻ hình ảnh, chú thích do LLM tạo và vị trí tệp S3 tương ứng:
Giờ đây, các tệp markdown đã được chèn chú thích hình ảnh, bước tiếp theo là chia tài liệu gốc thành các đoạn phù hợp với cửa sổ ngữ cảnh của mô hình nhúng. PDIQ sử dụng mô hình Amazon Titan Text Embeddings V2 để tạo vector và lưu trữ chúng trong Aurora PostgreSQL-Compatible Serverless. Dựa trên thử nghiệm độ chính xác nội bộ và các phương pháp hay nhất về phân đoạn từ AWS, PDIQ thực hiện phân đoạn như sau:
- 70% số token cho nội dung
- 10% chồng chéo giữa các đoạn
- 20% cho các token tóm tắt
Sử dụng logic phân đoạn tài liệu từ bước trước, tài liệu được chuyển đổi thành nhúng vector. Quá trình này bao gồm:
- Tính toán các tham số đoạn – Xác định kích thước và tổng số đoạn cần thiết cho tài liệu dựa trên tính toán 70%.
- Tạo tóm tắt tài liệu – Sử dụng Amazon Nova Lite để tạo tóm tắt toàn bộ tài liệu, bị giới hạn bởi phân bổ 20% token. Tóm tắt này được tái sử dụng trên tất cả các đoạn để cung cấp ngữ cảnh nhất quán.
- Phân đoạn và thêm tóm tắt – Chia tài liệu thành các đoạn chồng chéo (10%), với tóm tắt được thêm vào đầu.
- Tạo nhúng – Sử dụng Amazon Titan Text Embeddings V2 để tạo nhúng vector cho mỗi đoạn (tóm tắt cộng với nội dung), sau đó được lưu trữ trong kho vector.
Bằng cách thiết kế một phương pháp tùy chỉnh để tạo phần tóm tắt trên tất cả các đoạn, PDIQ đảm bảo rằng khi một đoạn cụ thể được khớp dựa trên tìm kiếm tương tự, LLM có quyền truy cập vào toàn bộ tóm tắt của tài liệu chứ không chỉ đoạn đã khớp. Phương pháp này làm phong phú trải nghiệm người dùng cuối, dẫn đến tỷ lệ chấp thuận độ chính xác tăng từ 60% lên 79%.
Sau đây là một ví dụ về lời nhắc tóm tắt:
You are a specialized document summarization assistant with expertise in business and technical content.Your task is to create concise, information-rich summaries that:Preserve all quantifiable data (numbers, percentages, metrics, dates, financial figures)Highlight key business terminology and domain-specific conceptsExtract important entities (people, organizations, products, locations)Identify critical relationships between conceptsMaintain factual accuracy without adding interpretationsFocus on extracting information that would be most valuable for:Answering specific business questionsSupporting data-driven decision makingEnabling precise information retrieval in a RAG systemThe summary should be comprehensive yet concise, prioritizing specific facts over general descriptions.Include any tables, lists, or structured data in a format that preserves their relationships.Ensure all technical terms, acronyms, and specialized vocabulary are preserved exactly as written.Sau đây là một ví dụ về văn bản tóm tắt, có sẵn trên mỗi đoạn:
### Summary: PLC User Creation Process and Password Reset**Document Overview:**This document provides instructions for creating new users and resetting passwords **Key Instructions:** {Shortened for Blog illustration} This summary captures the essential steps, requirements, and entities involved in the PLC user creation and password reset process using Jenkins.---Đoạn 1 có một tóm tắt ở trên cùng, sau đó là các chi tiết từ nguồn:
{Summary Text from above}This summary captures the essential steps, requirements, and entities involved in the PLC user creation and password reset process using Jenkins.title: 2. PLC User Creation Process and Password ResetĐoạn 2 có một tóm tắt ở trên cùng, sau đó là phần tiếp theo của các chi tiết từ nguồn:
{Summary Text from above}This summary captures the essential steps, requirements, and entities involved in the PLC user creation and password reset process using Jenkins.---Maintains a menu with options such as PDIQ quét từng đoạn tài liệu và tạo nhúng vector. Dữ liệu này được lưu trữ trong cơ sở dữ liệu Aurora PostgreSQL với các thuộc tính chính, bao gồm ID cơ sở tri thức duy nhất, thuộc tính nhúng tương ứng, văn bản gốc (tóm tắt cộng với đoạn cộng với chú thích hình ảnh) và một đối tượng nhị phân JSON bao gồm các trường siêu dữ liệu để mở rộng. Để giữ cho cơ sở tri thức được đồng bộ hóa, PDI triển khai các bước sau:
- Thêm – Đây là các đối tượng nguồn mới hoàn toàn cần được nhập. PDIQ triển khai luồng xử lý tài liệu đã mô tả trước đó.
- Cập nhật – Nếu PDIQ xác định cùng một đối tượng có mặt, nó sẽ so sánh giá trị khóa băm từ nguồn với giá trị băm từ đối tượng JSON.
- Xóa – Nếu PDIQ xác định rằng một tài liệu nguồn cụ thể không còn tồn tại, nó sẽ kích hoạt một thao tác xóa trên S3 bucket (
s3:ObjectRemoved:*), dẫn đến một công việc dọn dẹp, xóa các bản ghi tương ứng với giá trị khóa trong bảng Aurora.
PDI sử dụng Amazon Nova Pro để truy xuất tài liệu phù hợp nhất và tạo phản hồi bằng cách làm theo các bước chính sau:
- Sử dụng tìm kiếm tương tự, truy xuất các đoạn tài liệu phù hợp nhất, bao gồm tóm tắt, dữ liệu đoạn, chú thích hình ảnh và liên kết hình ảnh.
- Đối với đoạn khớp, truy xuất toàn bộ tài liệu.
- LLM sau đó thay thế liên kết hình ảnh bằng hình ảnh thực tế từ Amazon S3.
- LLM tạo phản hồi dựa trên dữ liệu được truy xuất và lời nhắc hệ thống được cấu hình trước.
Sau đây là một đoạn lời nhắc hệ thống:
Support assistant specializing in PDI's Logistics(PLC) platform, helping staff research and resolve support cases in Salesforce. You will assist with finding solutions, summarizing case information, and recommending appropriate next steps for resolution.Professional, clear, technical when needed while maintaining accessible language.Resolution Process:Response Format template:Handle Confidential Information:Kết quả và các bước tiếp theo
Bằng cách xây dựng giải pháp RAG tùy chỉnh này trên AWS, PDI đã đạt được các lợi ích sau:
- Các tùy chọn cấu hình linh hoạt cho phép nhập dữ liệu theo tần suất ưu tiên của người tiêu dùng.
- Thiết kế có khả năng mở rộng cho phép nhập dữ liệu trong tương lai từ các hệ thống nguồn bổ sung thông qua các crawler dễ dàng cấu hình.
- Hỗ trợ cấu hình crawler bằng nhiều phương pháp xác thực, bao gồm tên người dùng và mật khẩu, cặp khóa bí mật và khóa API.
- Các trường siêu dữ liệu có thể tùy chỉnh cho phép lọc nâng cao và cải thiện hiệu suất truy vấn.
- Quản lý token động giúp PDI cân bằng thông minh các token giữa nội dung và tóm tắt, nâng cao phản hồi của người dùng.
- Hợp nhất các định dạng dữ liệu nguồn đa dạng thành một bố cục thống nhất để lưu trữ và truy xuất hợp lý.
PDIQ cung cấp các kết quả kinh doanh chính bao gồm:
- Cải thiện hiệu quả và tỷ lệ giải quyết – Công cụ này trao quyền cho các nhóm hỗ trợ PDI giải quyết các truy vấn của khách hàng nhanh hơn đáng kể, thường tự động hóa các vấn đề thường xuyên và cung cấp các phản hồi chính xác, tức thì. Điều này đã dẫn đến việc khách hàng ít phải chờ đợi giải quyết trường hợp hơn và các nhân viên làm việc hiệu quả hơn.
- Sự hài lòng và lòng trung thành của khách hàng cao – Bằng cách cung cấp các câu trả lời chính xác, phù hợp và cá nhân hóa dựa trên tài liệu trực tiếp và tri thức công ty, PDIQ đã tăng điểm hài lòng của khách hàng (CSAT), điểm quảng bá ròng (NPS) và lòng trung thành tổng thể. Khách hàng cảm thấy được lắng nghe và hỗ trợ, củng cố mối quan hệ thương hiệu PDI.
- Giảm chi phí – PDIQ xử lý phần lớn các truy vấn lặp đi lặp lại, cho phép nhân viên hỗ trợ hạn chế tập trung vào các trường hợp cấp chuyên gia, điều này cải thiện năng suất và tinh thần. Ngoài ra, PDIQ được xây dựng trên kiến trúc serverless, tự động mở rộng quy mô trong khi giảm thiểu chi phí vận hành và chi phí.
- Tính linh hoạt trong kinh doanh – Một nền tảng duy nhất có thể phục vụ các đơn vị kinh doanh khác nhau, những người có thể quản lý nội dung bằng cách cấu hình các nguồn dữ liệu tương ứng của họ.
- Giá trị gia tăng – Mỗi nguồn nội dung mới bổ sung giá trị có thể đo lường được mà không cần thiết kế lại hệ thống.
PDI tiếp tục nâng cao ứng dụng với một số cải tiến đã được lên kế hoạch, bao gồm:
- Xây dựng cấu hình crawler bổ sung cho các nguồn dữ liệu mới (ví dụ: GitHub).
- Xây dựng triển khai tác nhân cho PDIQ để được tích hợp vào các quy trình kinh doanh phức tạp lớn hơn.
- Nâng cao khả năng hiểu tài liệu với trích xuất bảng và bảo toàn cấu trúc.
- Hỗ trợ đa ngôn ngữ cho các hoạt động toàn cầu.
- Cải thiện xếp hạng mức độ liên quan với các kỹ thuật truy xuất lai.
- Khả năng gọi PDIQ dựa trên các sự kiện (ví dụ: commit nguồn).
Kết luận
Dịch vụ PDIQ đã thay đổi cách người dùng truy cập và sử dụng tri thức doanh nghiệp tại PDI Technologies. Bằng cách sử dụng các dịch vụ serverless của Amazon, PDIQ có thể tự động mở rộng quy mô theo nhu cầu, giảm chi phí vận hành và tối ưu hóa chi phí. Phương pháp độc đáo của giải pháp đối với xử lý tài liệu, bao gồm quản lý token động và hệ thống chú thích hình ảnh tùy chỉnh, đại diện cho sự đổi mới kỹ thuật đáng kể trong các hệ thống RAG cấp doanh nghiệp. Kiến trúc đã cân bằng thành công hiệu suất, chi phí và khả năng mở rộng trong khi vẫn duy trì các yêu cầu bảo mật và xác thực. Khi PDI Technologies tiếp tục mở rộng khả năng của PDIQ, họ rất hào hứng khi thấy kiến trúc này có thể thích ứng với các nguồn, định dạng và trường hợp sử dụng mới như thế nào.
Về tác giả

Samit Kumbhani là Kiến trúc sư Giải pháp cấp cao của Amazon Web Services (AWS) tại khu vực New York City với hơn 18 năm kinh nghiệm. Hiện tại, anh hợp tác với các nhà cung cấp phần mềm độc lập (ISV) để xây dựng các giải pháp đám mây có khả năng mở rộng cao, sáng tạo và an toàn. Ngoài công việc, Samit thích chơi cricket, du lịch và đạp xe.

Jhorlin De Armas là Kiến trúc sư II tại PDI Technologies, nơi anh dẫn dắt thiết kế các nền tảng dựa trên AI trên Amazon Web Services (AWS). Kể từ khi gia nhập PDI vào năm 2024, anh đã kiến trúc một dịch vụ AI tổng hợp cho phép các trợ lý, tác nhân, cơ sở tri thức và hàng rào bảo vệ có thể cấu hình bằng Amazon Bedrock, Aurora Serverless, AWS Lambda và DynamoDB. Với hơn 18 năm kinh nghiệm xây dựng phần mềm doanh nghiệp, Jhorlin chuyên về kiến trúc tập trung vào đám mây, nền tảng serverless và các giải pháp AI/ML.

David Mbonu là Kiến trúc sư Giải pháp cấp cao tại Amazon Web Services (AWS), giúp khách hàng ISV ứng dụng kinh doanh ngang hàng xây dựng và triển khai các giải pháp chuyển đổi trên AWS. David có hơn 27 năm kinh nghiệm trong kiến trúc giải pháp doanh nghiệp và kỹ thuật hệ thống trên các công ty phần mềm, FinTech và đám mây công cộng. Các mối quan tâm gần đây của anh bao gồm AI/ML, chiến lược dữ liệu, khả năng quan sát, khả năng phục hồi và bảo mật. David và gia đình anh cư trú tại Sugar Hill, GA.
